






1.支持向量机分类原理
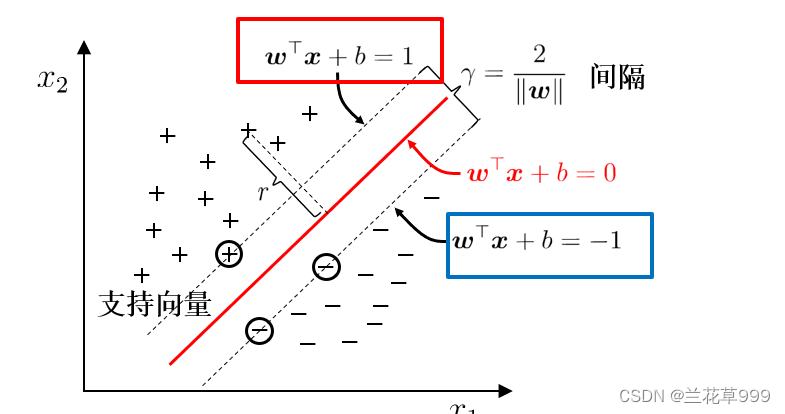
支持向量机,就是通过找出边际最大的决策边界,来对数据进行分类的分类器,因此,支持向量机分类器又叫做最大边际分类器。
支持向量机的分类方法,是在一组分布中找出一个超平面作为决策边界,使模型在数据上的分类误差尽量接近于0,尤其是在未知数据集上的分类误差尽量小

如上图,对于一个二分类场景,可以有无数线将其分开。被虚线截到的一个或者多个样本就叫做支持向量。
2.支持向量机的优缺点
优点:
支持向量机算法可以解决小样本情况下的机器学习问题,简化了通常的分类和回归等问题。
由于采用核函数方法克服了维数灾难和非线性可分的问题,所以向高维空间映射时没有增加计算的复杂性。换句话说,由于支持向量计算法的最终决策函数只由少数的支持向量所确定,所以计算的复杂性取决于支持向量的数目,而不是样本空间的维数。
支持向量机算法利用松弛变量可以允许一些点到分类平面的距离不满足原先要求,从而避免这些点对模型学习的影响。
缺点:
支持向量机算法对大规模训练样本难以实施。这是因为支持向量机算法借助二次规划求解支持向量,这其中会涉及m阶矩阵的计算,所以矩阵阶数很大时将耗费大量的机器内存和运算时间。
经典的支持向量机算法只给出了二分类的算法,而在数据挖掘的实际应用中,一般要解决多分类问题,但支持向量机对于多分类问题解决效果并不理想。
SVM算法效果与核函数的选择关系很大,往往需要尝试多种核函数,即使选择了效果比较好的高斯核函数,也要调参选择恰当的参数。另一方面就是现在常用的SVM理论都是使用固定惩罚系数C,但正负样本的两种错误造成的损失是不一样的。
3.最大间隔与分类
如果一个线性函数能够将样本分开,称这些数据样本是线性可分的。线性函数在二维空间中就是一条直线,在三维空间中就是一个平面,以此类推,如果不考虑空间维数,这样的线性函数统称为超平面。我们看一个简单的二维空间的例子,+代表正类,-代表负类,样本是线性可分的,但是很显然不只有这一条直线可以将样本分开,而是有无数条,我们所说的线性可分支持向量机就对应着能将数据正确划分并且间隔最大的直线。在样本空间中寻找一个超平面, 将不同类别的样本分开。
4.核函数:

5.SVM的一般流程:
1.收集数据:可以使用任何方法
2.准备数据:需要数值型数据
3.分析数据:有助于可视化分隔超平面
4.训练算法:SVM的大部分时间都源自训练,该过程主要实现两个参数的调优
5.测试算法:十分简单的过程就可以实现
6.使用算法:几乎所有分类问题都可以使用SVM,值得一提的是,SVM本身是一个二分类器,对多类问题应用SVM需要对代码做一些修改
6.python实现
数据集:
-0.017612 14.053064 0
-1.395634 4.662541 1
-0.752157 6.538620 0
-1.322371 7.152853 0
0.423363 11.054677 0
0.406704 7.067335 1
0.667394 12.741452 0
-2.460150 6.866805 1
0.569411 9.548755 0
-0.026632 10.427743 0
0.850433 6.920334 1
1.347183 13.175500 0
1.176813 3.167020 1
-1.781871 9.097953 0
-0.566606 5.749003 1
0.931635 1.589505 1
-0.024205 6.151823 1
-0.036453 2.690988 1
-0.196949 0.444165 1
1.014459 5.754399 1
1.985298 3.230619 1
-1.693453 -0.557540 1
-0.576525 11.778922 0
-0.346811 -1.678730 1
-2.124484 2.672471 1
1.217916 9.597015 0
-0.733928 9.098687 0
-3.642001 -1.618087 1
0.315985 3.523953 1
1.416614 9.619232 0
-0.386323 3.989286 1
0.556921 8.294984 1
1.224863 11.587360 0
-1.347803 -2.406051 1
1.196604 4.951851 1
0.275221 9.543647 0
0.470575 9.332488 0
-1.889567 9.542662 0
-1.527893 12.150579 0
-1.185247 11.309318 0
-0.445678 3.297303 1
1.042222 6.105155 1
-0.618787 10.320986 0
1.152083 0.548467 1
0.828534 2.676045 1
-1.237728 10.549033 0
-0.683565 -2.166125 1
0.229456 5.921938 1
-0.959885 11.555336 0
0.492911 10.993324 0
0.184992 8.721488 0
-0.355715 10.325976 0
-0.397822 8.058397 0
0.824839 13.730343 0
1.507278 5.027866 1
0.099671 6.835839 1
-0.344008 10.717485 0
1.785928 7.718645 1
-0.918801 11.560217 0
-0.364009 4.747300 1
-0.841722 4.119083 1
0.490426 1.960539 1
-0.007194 9.075792 0
0.356107 12.447863 0
0.342578 12.281162 0
-0.810823 -1.466018 1
2.530777 6.476801 1
1.296683 11.607559 0
0.475487 12.040035 0
-0.783277 11.009725 0
0.074798 11.023650 0
-1.337472 0.468339 1
-0.102781 13.763651 0
-0.147324 2.874846 1
0.518389 9.887035 0
1.015399 7.571882 0
-1.658086 -0.027255 1
1.319944 2.171228 1
2.056216 5.019981 1
-0.851633 4.375691 1
-1.510047 6.061992 0
-1.076637 -3.181888 1
1.821096 10.283990 0
3.010150 8.401766 1
-1.099458 1.688274 1
-0.834872 -1.733869 1
-0.846637 3.849075 1
1.400102 12.628781 0
1.752842 5.468166 1
0.078557 0.059736 1
0.089392 -0.715300 1
1.825662 12.693808 0
0.197445 9.744638 0
0.126117 0.922311 1
-0.679797 1.220530 1
0.677983 2.556666 1
0.761349 10.693862 0
-2.168791 0.143632 1
1.388610 9.341997 0
0.317029 14.739025 0
import matplotlib.pyplot as plt
import numpy as np
import random
def loadDataSet(fileName):
dataMat = [];
labelMat = []
fr = open(fileName)
for line in fr.readlines(): # 逐行读取,滤除空格等
lineArr = line.strip().split()
dataMat.append([float(lineArr[0]), float(lineArr[1])]) # 添加数据
labelMat.append(float(lineArr[2])) # 添加标签
return dataMat, labelMat
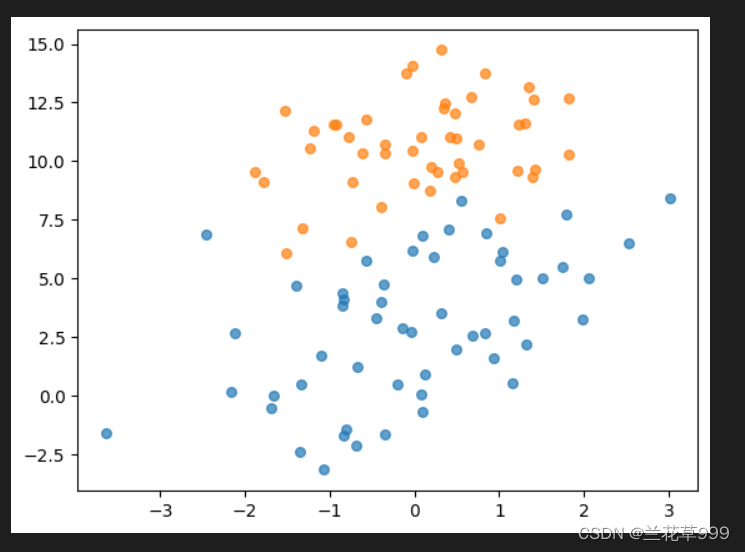
def showDataSet(dataMat, labelMat):
data_plus = [] # 正样本
data_minus = [] # 负样本
for i in range(len(dataMat)):
if labelMat[i] > 0:
data_plus.append(dataMat[i])
else:
data_minus.append(dataMat[i])
data_plus_np = np.array(data_plus) # 转换为numpy矩阵
data_minus_np = np.array(data_minus) # 转换为numpy矩阵
plt.scatter(np.transpose(data_plus_np)[0], np.transpose(data_plus_np)[1]) # 正样本散点图
plt.scatter(np.transpose(data_minus_np)[0], np.transpose(data_minus_np)[1]) # 负样本散点图
plt.show()
def smoSimple(dataMatIn, classLabels, C, toler, maxIter):
# 转换为numpy的mat存储
dataMatrix = np.mat(dataMatIn);
labelMat = np.mat(classLabels).transpose()
# 初始化b参数,统计dataMatrix的维度
b = 0;
m, n = np.shape(dataMatrix)
# 初始化alpha参数,设为0
alphas = np.mat(np.zeros((m, 1)))
# 初始化迭代次数
iter_num = 0
# 最多迭代matIter次
while (iter_num < maxIter):
alphaPairsChanged = 0
for i in range(m):
# 步骤1:计算误差Ei
fXi = float(np.multiply(alphas, labelMat).T * (dataMatrix * dataMatrix[i, :].T)) + b
Ei = fXi - float(labelMat[i])
# 优化alpha,设定一定的容错率。
if ((labelMat[i] * Ei < -toler) and (alphas[i] < C)) or ((labelMat[i] * Ei > toler) and (alphas[i] > 0)):
# 随机选择另一个与alpha_i成对优化的alpha_j
j = selectJrand(i, m)
# 步骤1:计算误差Ej
fXj = float(np.multiply(alphas, labelMat).T * (dataMatrix * dataMatrix[j, :].T)) + b
Ej = fXj - float(labelMat[j])
# 保存更新前的aplpha值,使用深拷贝
alphaIold = alphas[i].copy();
alphaJold = alphas[j].copy();
# 步骤2:计算上下界L和H
if (labelMat[i] != labelMat[j]):
L = max(0, alphas[j] - alphas[i])
H = min(C, C + alphas[j] - alphas[i])
else:
L = max(0, alphas[j] + alphas[i] - C)
H = min(C, alphas[j] + alphas[i])
if L == H: print("L==H"); continue
# 步骤3:计算eta
eta = 2.0 * dataMatrix[i, :] \
* dataMatrix[j,:].T - dataMatrix[i,:]\
* dataMatrix[i,:].T - dataMatrix[j,:]\
* dataMatrix[j, :].T
if eta >= 0: print("eta>=0"); continue
# 步骤4:更新alpha_j
alphas[j] -= labelMat[j] * (Ei - Ej) / eta
# 步骤5:修剪alpha_j
alphas[j] = clipAlpha(alphas[j], H, L)
if (abs(alphas[j] - alphaJold) < 0.00001): print("alpha_j变化太小"); continue
# 步骤6:更新alpha_i
alphas[i] += labelMat[j] * labelMat[i] * (alphaJold - alphas[j])
# 步骤7:更新b_1和b_2
b1 = b - Ei - labelMat[i] * (alphas[i] - alphaIold) * dataMatrix[i, :] * dataMatrix[i, :].T - labelMat[
j] * (alphas[j] - alphaJold) * dataMatrix[i, :] * dataMatrix[j, :].T
b2 = b - Ej - labelMat[i] * (alphas[i] - alphaIold) * dataMatrix[i, :] * dataMatrix[j, :].T - labelMat[
j] * (alphas[j] - alphaJold) * dataMatrix[j, :] * dataMatrix[j, :].T
# 步骤8:根据b_1和b_2更新b
if (0 < alphas[i]) and (C > alphas[i]):
b = b1
elif (0 < alphas[j]) and (C > alphas[j]):
b = b2
else:
b = (b1 + b2) / 2.0
# 统计优化次数
alphaPairsChanged += 1
# 打印统计信息
print("第%d次迭代 样本:%d, alpha优化次数:%d" % (iter_num, i, alphaPairsChanged))
# 更新迭代次数
if (alphaPairsChanged == 0):
iter_num += 1
else:
iter_num = 0
print("迭代次数: %d" % iter_num)
return b, alphas
def selectJrand(i, m):
j = i # 选择一个不等于i的j
while (j == i):
j = int(random.uniform(0, m))
return j
def clipAlpha(aj, H, L):
if aj > H:
aj = H
if L > aj:
aj = L
return aj
def showClassifer(dataMat, w, b):
# 绘制样本点
data_plus = [] # 正样本
data_minus = [] # 负样本
for i in range(len(dataMat)):
if labelMat[i] > 0:
data_plus.append(dataMat[i])
else:
data_minus.append(dataMat[i])
data_plus_np = np.array(data_plus) # 转换为numpy矩阵
data_minus_np = np.array(data_minus) # 转换为numpy矩阵
plt.scatter(np.transpose(data_plus_np)[0], np.transpose(data_plus_np)[1], s=30, alpha=0.7) # 正样本散点图
plt.scatter(np.transpose(data_minus_np)[0], np.transpose(data_minus_np)[1], s=30, alpha=0.7) # 负样本散点图
# 绘制直线
x1 = max(dataMat)[0]
x2 = min(dataMat)[0]
a1, a2 = w
b = float(b)
a1 = float(a1[0])
a2 = float(a2[0])
y1, y2 = (-b - a1 * x1) / a2, (-b - a1 * x2) / a2
plt.plot([x1, x2], [y1, y2])
# 找出支持向量点
for i, alpha in enumerate(alphas):
if abs(alpha) > 0:
x, y = dataMat[i]
plt.scatter([x], [y], s=150, c='none', alpha=0.7, linewidth=1.5, edgecolor='red')
plt.show()
def get_w(dataMat, labelMat, alphas):
alphas, dataMat, labelMat = np.array(alphas), np.array(dataMat), np.array(labelMat)
w = np.dot((np.tile(labelMat.reshape(1, -1).T, (1, 2)) * dataMat).T, alphas)
return w.tolist()
if __name__ == '__main__':
dataMat, labelMat = loadDataSet('D:\\dataset\\testSet.txt')
b, alphas = smoSimple(dataMat, labelMat, 0.6, 0.001, 40)
w = get_w(dataMat, labelMat, alphas)
showClassifer(dataMat, w, b)
结果
7.总结
支持向量机的泛化错误率较低,也就说它具有良好的学习能力,且学到的结果具有较好的推广性。这些优点是的支持向量机十分流行,被认为是监督学习中最好的定式算法之一。















 6977
6977











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









