







- 学习:知识的初次邂逅
- 复习:知识的温故知新
- 练习:知识的实践应用
目录
一,原题力扣链接
二,题干
书籍表
Books:+----------------+---------+ | Column Name | Type | +----------------+---------+ | book_id | int | | name | varchar | | available_from | date | +----------------+---------+ book_id 是这个表的主键(具有唯一值的列)。订单表
Orders:+----------------+---------+ | Column Name | Type | +----------------+---------+ | order_id | int | | book_id | int | | quantity | int | | dispatch_date | date | +----------------+---------+ order_id 是这个表的主键(具有唯一值的列)。 book_id 是 Books 表的外键(reference 列)。编写解决方案,筛选出过去一年中订单总量 少于
10本 的 书籍,并且 不考虑 上架距今销售 不满一个月 的书籍 。假设今天是2019-06-23。返回结果表 无顺序要求 。
结果格式如下所示。
示例 1:
输入: Books 表: +---------+--------------------+----------------+ | book_id | name | available_from | +---------+--------------------+----------------+ | 1 | "Kalila And Demna" | 2010-01-01 | | 2 | "28 Letters" | 2012-05-12 | | 3 | "The Hobbit" | 2019-06-10 | | 4 | "13 Reasons Why" | 2019-06-01 | | 5 | "The Hunger Games" | 2008-09-21 | +---------+--------------------+----------------+ Orders 表: +----------+---------+----------+---------------+ | order_id | book_id | quantity | dispatch_date | +----------+---------+----------+---------------+ | 1 | 1 | 2 | 2018-07-26 | | 2 | 1 | 1 | 2018-11-05 | | 3 | 3 | 8 | 2019-06-11 | | 4 | 4 | 6 | 2019-06-05 | | 5 | 4 | 5 | 2019-06-20 | | 6 | 5 | 9 | 2009-02-02 | | 7 | 5 | 8 | 2010-04-13 | +----------+---------+----------+---------------+ 输出: +-----------+--------------------+ | book_id | name | +-----------+--------------------+ | 1 | "Kalila And Demna" | | 2 | "28 Letters" | | 5 | "The Hunger Games" | +-----------+--------------------+
三,建表语句
import pandas as pd
data = [[1, 'Kalila And Demna', '2010-01-01'], [2, '28 Letters', '2012-05-12'], [3, 'The Hobbit', '2019-06-10'], [4, '13 Reasons Why', '2019-06-01'], [5, 'The Hunger Games', '2008-09-21']]
books = pd.DataFrame(data, columns=['book_id', 'name', 'available_from']).astype({'book_id':'Int64', 'name':'object', 'available_from':'datetime64[ns]'})
data = [[1, 1, 2, '2018-07-26'], [2, 1, 1, '2018-11-05'], [3, 3, 8, '2019-06-11'], [4, 4, 6, '2019-06-05'], [5, 4, 5, '2019-06-20'], [6, 5, 9, '2009-02-02'], [7, 5, 8, '2010-04-13']]
orders = pd.DataFrame(data, columns=['order_id', 'book_id', 'quantity', 'dispatch_date']).astype({'order_id':'Int64', 'book_id':'Int64', 'quantity':'Int64', 'dispatch_date':'datetime64[ns]'})四,分析



表格大法 先过滤在左连接 最后在分组过滤
第一步:过滤掉books表中上架时间距离如今一个月的书籍;
第二步:过滤 掉 订单表中 非近一年的订单;
第三步:以书籍表左连接订单表 统计书籍的销售数量 而非订单的,书籍有可能没有销售; 第四步:null值转为0
第五步,分组聚合过滤
第六步:映射指定的列 并输出;
解题过程
代码实现 上述表格的逻辑:
第一步:过滤掉books表中上架时间距离如今一个月的书籍;
在pandas中
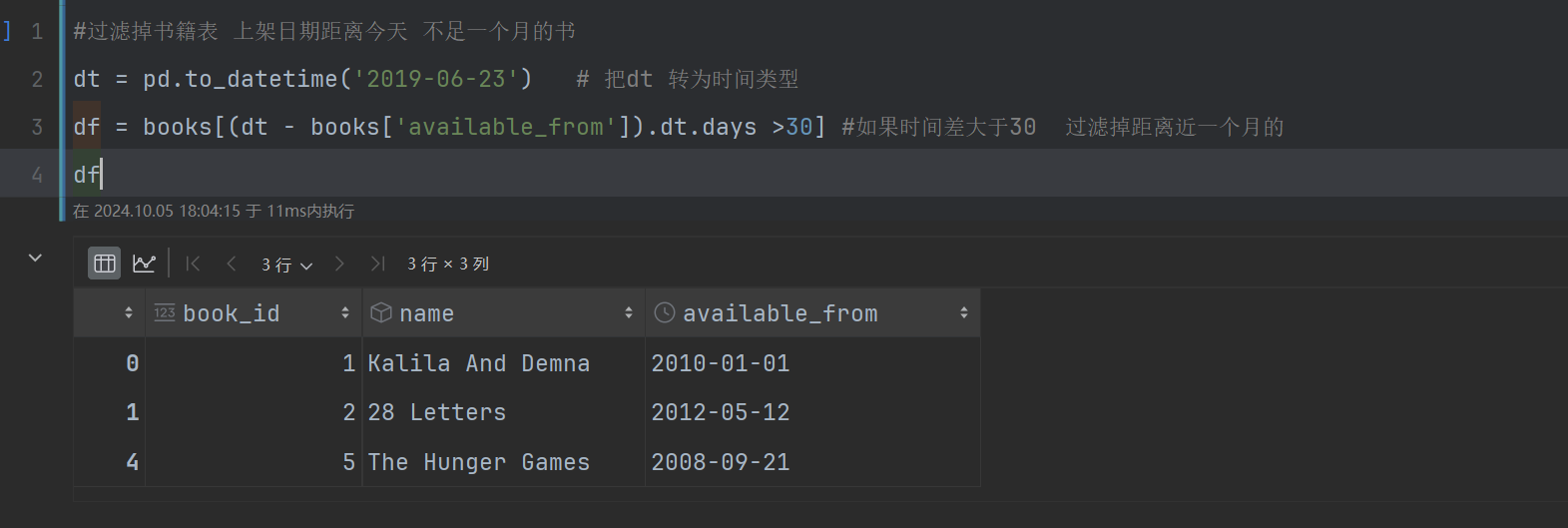
第二步:过滤 掉 订单表中 非近一年的订单;

第三步:以书籍表左连接订单表 统计书籍的销售数量 而非订单的,书籍有可能没有销售;
在pandas中
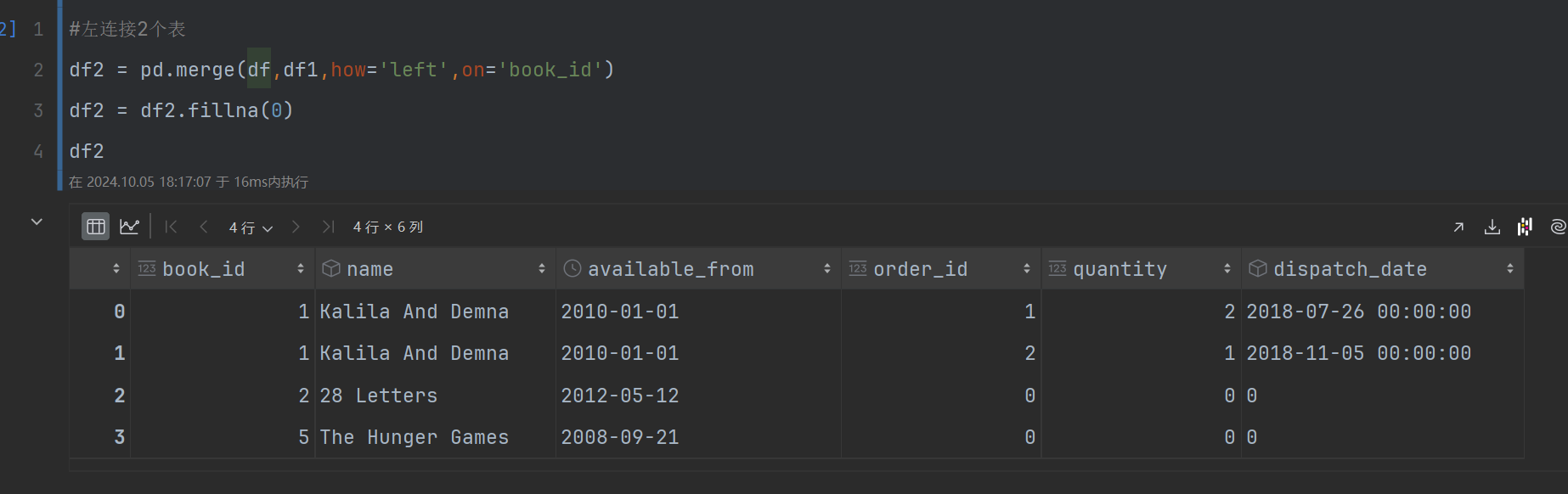
第四步:null值转为0
在pandas中

第五步,分组聚合过滤
在pandas中

第六步:映射指定的列 并输出;
五,Pandas解答
import pandas as pd
def unpopular_books(books: pd.DataFrame, orders: pd.DataFrame) -> pd.DataFrame:
#过滤掉书籍表 上架日期距离今天 不足一个月的书
dt = pd.to_datetime('2019-06-23') # 把dt 转为时间类型
df = books[(dt - books['available_from']).dt.days >30] #如果时间差大于30 过滤掉距离近一个月的
#过滤出订单表中 近一年的订单
new_date = dt - pd.offsets.DateOffset(years = 1) # new_date #2018-06-23
df1 = orders[orders['dispatch_date'] >=new_date] #大于等于一年前 2018-06-23
df1 = df1[df1['dispatch_date'] <= '2019-06-23'] #小于等于 今天 2019-06-23
#左连接2个表
df2 = pd.merge(df,df1,how='left',on='book_id')
df2 = df2.fillna(0) #处理null值
#分组聚合
res =df2.groupby(['book_id','name'])['quantity'].sum().reset_index()
res1= res[res['quantity']<10]
res2= res1[['book_id','name']]
return res2
unpopular_books(books,orders)六,验证

七,知识点总结
- Pandas中时间函数的运用 API pd.to_datetime
- Pandas中时间函数的运用 API:offsets.Dateoffset
- Pandas中过滤的运用
- Pandas中左连接的运用 merge
- Pandas中NAN值的转换
- Pandas中分组 过滤的运用
- Pandas中充值索引的运用 reset_index()
- Pandas中映射指定的列的运用
- 学习:知识的初次邂逅
- 复习:知识的温故知新
- 练习:知识的实践应用















 4239
4239

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









