






前言
pandas是用于数据分析的开源python库,可以实现数据加载,清洗,转换,统计处理,可视化等功能。而DataFrame和Series是pandas最基本的两种数据结构。DataFrame用来处理结构化数据,Series用来处理单列数据,也可以把DataFrame看作Series对象组成的字典或集合。
一、创建series对象
import pandas as pd
import numpy as np
# 创建numpy.ndarray对象
# n1 = np.array([1, 2, 3])
# print(n1)
# print(type(n1))
# # 创建Series对象
# s1 = pd.Series(data=n1)
# print(s1)
# print(type(s1))
# 直接创建
s2 = pd.Series(['banana', 42])
print(s2)
print(type(s2))# 不用ndarray方式,直接传入列表,元组,字典
s2=pd.Series([1,2,3],index=['a','b','c'])
print(s2)
print(type(s2))
print('------------')
s3=pd.Series((4,5,6),index=['a','b','c'])
print(s3)
print(type(s3))
print('------------')
s4=pd.Series({'a':7, 'b':8, 'c':9})
print(s4)
print(type(s4))二、创建DataFrame对象
1.指定行索引和列的位置
# 指定行索引,和 列的位置
import pandas as pd
df=pd.DataFrame({'id':[1,2,3],'name':['zhangsan','lisi','wangwu'],'age':[12,13,12]},index=['A','B','C'],columns=['age','id','name'])
print(df)2.列表嵌套元组
# 传入列表嵌套元组
df1=pd.DataFrame(data=[(1,'zhangsan','23'),(2,'lisi','23'),(3,'wangwu','23')],index=['A','B','C'],columns=['id','name','age'])
print(df1)三、Series属性-索引-运算
一、series属性和方法
import pandas as pd
# 设置id列为索引列
data=pd.read_csv('./nobel_prizes.csv',index_col='id')
data.head()first_row=data.loc[941] # 按照行索引获取行数据
print(first_row)
two_row=data.iloc[1] # 按照行号获取行数据
print(two_row)- append 连接两个或多个Series
- corr 计算与另一个Series的相关系数
- cov 计算与另一个Series的协方差
- describe 计算常见统计量
- drop_duplicates 返回去重后的Series
- equals 判断两个Series 是否相同
- get_values 获取Series的值,作用与values属性相同
- hist 绘制直方图
- isan Series中是否包含某些值
- min 返回最小值
- max 返回最大值
- median 返回中位数
- mean 返回平均值
- mode 返回众数
- quantile 返回指定位置的分位数
- replace 用指定值代替Series中的值
- sample 返回Series 的随机采样值
- sort_values 对值进行排序
- to_frame 把Series 转换为DataFrame
- unique 去重返回数组
- values_counts 统计不同值数量
- keys 获取索引值
- head 查看前5个值
- tail 查看后5个值
-
import pandas as pd # 创建s对象 s1 = pd.Series(data=[1, 2, 3, 4, 2, 3], index=['A', 'B', 'C', 'D', 'E', 'F']) # 查看s对象值数量 print(len(s1)) # 查看s对象前5个值, n默认等于5 print(s1.head()) print(s1.head(n=2)) # 查看s对象后5个值, n默认等于5 print(s1.tail()) print(s1.tail(n=2)) # 获取s对象的索引 print(s1.keys()) # s对象转换成python列表 print(s1.tolist()) print(s1.to_list()) # s对象转换成df对象 print(s1.to_frame()) # s对象中数据的基础统计信息 print(s1.describe()) # s对象最大值、最小值、平均值、求和值... print(s1.max()) print(s1.min()) print(s1.mean()) print(s1.sum()) # s对象数据值去重, 返回s对象 print(s1.drop_duplicates()) # s对象数据值去重, 返回数组 print(s1.unique()) # s对象数据值排序, 默认升序 print(s1.sort_values(ascending=True)) # s对象索引值排序, 默认升序 print(s1.sort_index(ascending=False)) # s对象不同值的数量, 类似于分组计数操作 print(s1.value_counts())布尔索引
import pandas as pd
data=pd.read_csv('./scientists.csv')
data
# 统计所有大于平均年龄的数据
# 1. 获取所有的年龄.
ages = data.Age
# 2. 获取所有年龄的 平均值
age_mean = ages.mean()
age_mean
# 3. 查询所有 大于平均年龄的数据.
ages[ages > age_mean] # [False, True, True, True, False, False, False, True]
# 上述需求, 一行既能搞定, 写法如下
# df['Age'][df['Age'] > df['Age'].mean()]
data.Age[data.Age > data.Age.mean()] 二、运算
ages = df['Age']
print(ages + 10)
print(ages * 2)
print(ages + ages)
print('=' * 20)
print(pd.Series([1, 100]))
print('=' * 20)
print(ages + pd.Series([1, 100]))四、DataFrame属性-索引(更改)
一、DataFrame属性
import pandas as pd
df=pd.read_csv('./movie.csv')
df
print(df.shape) #维度
print(df.size) #长度
print(df.ndim) #数组轴,二维表
print(df.index)
print(df.values)
print(df.dtypes)
# print(df.info) #查看内容信息
df.describe() # 查看完整信息 #默认只展示数值型特征列
# df.describe(exclude=['int']) #过滤掉,不展示
# df.describe(exclude=['int','float']) # “过滤掉”,不展示
df.describe(include='all') # “过滤出”,展示所有列
# len(df) #统计行数
# df.count() #统计每列非空值行数
df.duration.max()
# df.num_voted_users.min()
# df.max() #统计每列最大值
# df.min() #统计每列最小值
# df.mean() #统计每列平均值,只针对于数字列有效
df.director_facebook_likes.max() 二、DataFrame索引相关
# 2. df对象, 也支持 布尔索引, 入门案例如下.
df.head()[[False, True, False, True, False]]
# 3. 查询 电影时长 > 电影平均时长 所有的电影信息.
df[df.duration > df.duration.mean()]
# 4. 查询 主演在脸书的点赞数 > 主演在脸书的平均点赞数 所有的电影信息.
df[df.actor_1_facebook_likes > df.actor_1_facebook_likes.mean()] # df对象.列名
df[df['actor_1_facebook_likes'] > df['actor_1_facebook_likes'].mean()] # df对象['列名']
# 情况1: df对象 和 数值运算, 则: 数值 会依次和 df对象的每个值进行运算.
movie_df = df.head(3)
movie_df
movie_df * 2 # df对象中的每个值, 都会依次 和 2相乘.
# 情况2: df对象 和 df对象直接做运算.
movie_df + movie_df # 对应索引做操作.
# 两个df做运算, 但是: 行索引不一致.
movie_df[:2] # 类似于Python的切片, 即: 获取 索引 0 ~ 2的数据, 包左不包右, 最终: 索引为0, 1的数据
movie_df + movie_df[:2] # 索引一致就运算, 不一致就用NaN填充.
1.读取文件后设置索引列
import pandas as pd
movie=pd.read_csv('./movie.csv')
movie
# 读取后指定某一列为行索引
movie2=movie.set_index('movie_title')
movie2.head()
movie.set_index('movie_title',inplace=True) #在原始df对象上修改,不返回新值
movie.head()2.读取文件时,直接指定索引列
# 方式3: 在读取 csv文件的时候, 直接设定索引列.
movie_df = pd.read_csv('./movie.csv', index_col='movie_title')
movie_df.head()
# # 取消自定义的索引列, 改为系统自动填充的 0 ~ n
# movie_df.reset_index(inplace=True)
# movie_df.head()
3.DataFrame修改行名和列名
# 打印下源数据, df对象, 防止df在某个 单元格中已经被 修改了.
movie_df.head()
# 方式1: rename()函数进行修改, 格式为: df对象.rename(index=新的索引列-列表形式, columns=新的列名-列表形式)
# 1. 加载出 前5个: 行索引名(这里是: 电影名 前5个值), 列名
movie_df.index[:5] # ['Avatar', 'Pirates of the Caribbean: At World's End', ....]
movie_df.columns[:5] # ['color', 'director_name', ... ]
# 2. 修改 行索引名
idx_new = {'Avatar': '阿凡达', "Pirates of the Caribbean: At World's End": '加勒比海盗: 直到世界尽头'}
# 3. 修改 列名
col_new = {'color': '颜色', 'director_name': '导演名'}
# 4. 用新的 行索引名 和 列名, 来替换: 就的 行索引名 和 列名.
movie_df.rename(index=idx_new, columns=col_new).head()
4.添加或删除列
# 2. 添加列, 默认是在: 末尾添加列的.
# 格式为: df对象['列名'] = 值
movie_df['has_seen'] = 1 # 表示: 是否看过该电影
# 新增列: 导演 和 演员 在脸书 总的点赞数 = 导演在脸书的被点赞数 + 1号演员在脸书的被点赞数 + 2号演员在脸书的被点赞数 + 3号演员在脸书的被点赞数
movie_df['director_actor_fb_likes'] = movie_df['director_facebook_likes'] + movie_df['actor_1_facebook_likes'] + movie_df['actor_2_facebook_likes'] + movie_df['actor_3_facebook_likes']
movie_df.head()
# 3. 删除列.
# 格式: df对象.drop('列名', axis = 'columns') # 按列删除
# movie_df.drop('color', axis='columns', inplace = True)
# movie_df.drop('duration', axis=1, inplace = True) # columns => 可以写成 1(表示列)
# movie_df.drop('director_name', axis=0, inplace = True) # 报错.
# 格式: df对象.drop([行索引值1, 行索引值2...]) # 按行索引删除
# movie_df.drop(['Avatar', "Pirates of the Caribbean: At World's End"], inplace=True) # movie_df.drop([0, 1], inplace=True)
#
# movie_df.head()
# insert(), 在指定位置插入列, 参1: 插入位置(索引, 从0开始), 参2: 列名, 参3: 列值
# 细节: insert()函数没有 inplace参数, 它也是默认在原df对象上 做修改.
# movie_df.insert(loc=1, column = 'ai_class', value='北京AI 19期')
# 插入: 总盈利字段 profit = gross 总收入 - budget 总预算
movie_df.insert(loc=3, column = 'profit', value=movie_df['gross'] - movie_df['budget'])
movie_df.head()五、加载指定行和列的数据
1.保存数据到文件
格式如下:
df对象.to_数据格式(路径)
# 例如:
df.to_csv('data/abc.csv')
# output文件夹必须存在
df.to_pickle('output/scientists.pickle') # 保存为 pickle文件
df.to_csv('output/scientists.csv') # 保存为 csv文件
df.to_excel('output/scientists.xlsx') # 保存为 Excel文件
df.to_excel('output/scientists_noindex.xlsx', index=False) # 保存为 Excel文件
df.to_csv('output/scientists_noindex.csv', index=False) # 保存为 Excel文件
df.to_csv('output/scientists_noindex.tsv', index=False, sep='\t')
print('保存成功')2. 读取数据
格式如下:
pd对象.read_数据格式(路径)
# 例如:
pd.read_csv('data/movie.csv')
# pd.read_pickle('output/scientists.pickle') # 读取Pickle文件中的内容
# pd.read_excel('output/scientists.xlsx') # 多1个索引列
# pd.read_csv('output/scientists.csv') # 多1个索引列
pd.read_csv('output/scientists_noindex.csv') # 正常数据3.加载数据
按列加载数据
import pandas as pd
df=pd.read_csv('dataset/gapminder.tsv',sep='\t')
df
df.describe().T # 查看数值型特征列分布
# 1. 加载一列数据.
# 格式: df.列名 或者 df['列名']
df.year
df['year']
# 2. 加载多列数据
# 格式: df[[列名1, 列名2, 列名3]] 需要传入: 列名的列表形式, 即: 1个参数
df[['country', 'year', 'lifeExp']]
# df['country', 'year', 'lifeExp'] # 报错按行加载数据
# 1. 按行加载数据
df.head() # 获取前5条, 最左侧是一列行号, 也是 df的行索引, 即: Pandas默认使用行号作为 行索引.
# 2. 使用 tail()方法, 获取最后一行数据
df.tail(n=1)
# 3. 演示 iloc属性 和 loc属性的区别, loc属性写的是: 行索引值. iloc写的是行号.
df.tail(n=1).loc[1703]
df.tail(n=1).iloc[0] # 效果同上.
# loc传入的是行索引,iloc传入的是行号
# 4. loc属性 传入行索引, 来获取df的部分数据(一行, 或多行)
df.loc[0] # 获取 行索引为 0的行
df.loc[99] # 获取 行索引为 99的行
df.loc[[0, 99, 999]] # loc属性, 根据行索引值, 获取多条数据.
# 5. 获取最后一条数据
# df.loc[-1] # 报错
df.iloc[-1] # 正确获取指定行和列
# loc形式获取指定行和列的内容,获取列时只能输入列名
df.loc[[0,1,2],['SepalLength','PetalLength']] #行索引,列名
df.loc[:,['SepalLength','PetalLength']] #获取这两列的所有行
# 以下需要注意,范围“包左包右”
df.loc[1:3,['SepalLength','PetalLength']] # 获取这两列的1-3行df.loc[1:3,['SepalLength','PetalLength']] # 获取这两列的1-3行
#%%
# iloc形式获取指定行和列内容,获取列时不能输入列名要输如索引
df.iloc[[0,1,2],[0,2,4]] # 行索引,列编号
df.iloc[:,[0,2,4]] # 获取这三列的所有行
df.iloc[:,range(1,5,2)] # 1-5列以步长2获取,包左不包右
df.iloc[:,list(range(1,5,2))] # 效果同上
# 此处注意和loc做区分!!!
df.iloc[1:4,1:5:2] # 获取上面列的1-4行包左不包右六、分组聚合
格式:
df.groupby('分组字段')['要聚合的字段'].聚合函数()
df.groupby(['分组字段','分组字段2'])[['要聚合的字段','要聚合的字段2']].聚合函数()
1.分组聚合演示
import pandas as pd
# 1. 加载文件.
df = pd.read_csv('dataset/gapminder.tsv', sep='\t')
df
# 根据单列进行分组统计
# pandas写法: df.groupby(['分组列1', '分组列2'...])[[要进行聚合的列1, 列2...]].聚合函数()
# pandas写法: df.groupby(['分组列1', '分组列2'...]).agg({'列名':'聚合函数名', '列名':'聚合函数名'}) # aggregate: 聚合
# 需求1: 统计 每年 平均预期寿命.
df.groupby('year')['lifeExp'].mean()
# 上述格式, 拆解分析
df.groupby('year') # 获取的是一个: DataFrameGroupBy df的分组对象, 记录: 分组后的信息
df.groupby('year')['lifeExp'] # 获取的是一个: SeriesGroupBy Series的分组对象, 记录: 具体要进行聚合操作的 数据.
df.groupby('year')['lifeExp'].mean() # 对数据进行 求平均值计算. 默认: 分组字段会充当索引列.上面运行之后发现分组字段作为了索引列,那么可以利用as_index取消作为索引列。
2.ax_index参数演示
# 通过 as_index 属性, 可以取消 分组字段作为 索引列. 当然你也可以 分组之后, 再 reset_index()也可以.
# 方式1: as_index属性实现.
df.groupby('year', as_index=False)['lifeExp'].mean() # as_index = False 表示不作为索引
# 方式2: 分组后, 取消设置 行索引列.
df.groupby('year')['lifeExp'].mean().reset_index()运行结果:
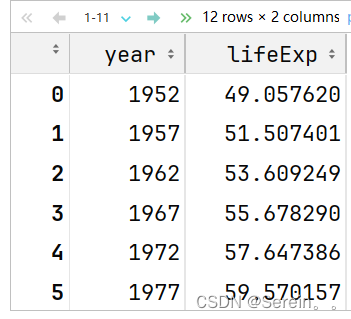
3.对多组进行聚合
# 需求2: 求每年的 平均人口 和 平均GDP
df.groupby('year', as_index=False)[['pop', 'gdpPercap']].mean()
# 需求3: 求每年的 平均人口 和 最大GDP
df.groupby('year', as_index=False).agg({'pop':'mean', 'gdpPercap':'max'})4.对多组不同列进行不同的聚合
# 需求4: 统计 每年, 每个大洲, 平均预期寿命, 最低人口数, 最高GDP
# df.groupby(['year', 'continent'])[['lifeExp', 'pop', 'gdpPercap']].mean()
df.groupby(['year', 'continent']).agg({
'lifeExp':'mean',
'pop':'min',
'gdpPercap':'max'
})七、pandas常见的排序方式
nlargest(): 获取某个字段取值最大的前n条数据.
nsmallest(): 获取某个字段取值最大的前n条数据.
# 需求1: 找小成本, 高口碑电影, 即: 评分较高, 但是成本较低.
# 1. 从 movie 这个原始的df对象中, 提取出我们要的: 列的信息, 组成新的 df对象.
# movie.columns
movie_df = movie[['movie_title', 'imdb_score', 'budget']] # 电影名, 电影评分, (成本)预算
movie_df.head()
# 2. 根据 评分 降序排列, 获取 前100条 数据.
# 方式1: sort_values()方式 实现.
movie_df.sort_values('imdb_score', ascending=False).head(100)
# 方式2: nlargest(数据条数, '要统计的列') 获取某列值, 最大的前 n 条数据
movie_df.nlargest(100, 'imdb_score')
# 3. 在评分高的电影的基础上, 找 成本最低的 前 5 条数据.
# nsmallest(数据条数, '要统计的列') 获取某列值, 最小的前 n 条数据
# movie_df.nsmallest(100, 'imdb_score')
# 方式1: nlargest() + nsmallest()
movie_df.nlargest(100, 'imdb_score').nsmallest(5, 'budget')
# 方式2: sort_values() + head()
# movie_df.sort_values('imdb_score', ascending=False).head(100).sort_values('budget').head(10)八、 数据组合
-
连接是指把某行或某列追加到数据中, 数据被分成了多份可以使用连接把数据拼接起来
-
把计算的结果追加到现有数据集,也可以使用连接
df对象与df对象拼接:行拼接参考: 列名, 列拼接参考: 行号
concat连接方式:concat是一种用于连接两个或多个数组或数据框的方法,它将它们按照指定的轴进行连接。在Python中,可以使用pandas库中的concat函数来实现数组或数据框的连接。
merge连接方式:merge是一种用于合并两个数据框的方法,它将它们按照指定的键进行合并。在Python中,可以使用pandas库中的merge函数来实现数据框的合并操作。
join连接方式:join是一种用于将两个数据框按照它们的索引进行连接的方法。在Python中,可以使用pandas库中的join方法来实现数据框的连接操作。
1.concat连接
import pandas as pd
df1=pd.read_csv('dataset03/concat_1.csv')
df2=pd.read_csv('dataset03/concat_2.csv')
df3=pd.read_csv('dataset03/concat_3.csv')
df1
df2
df3
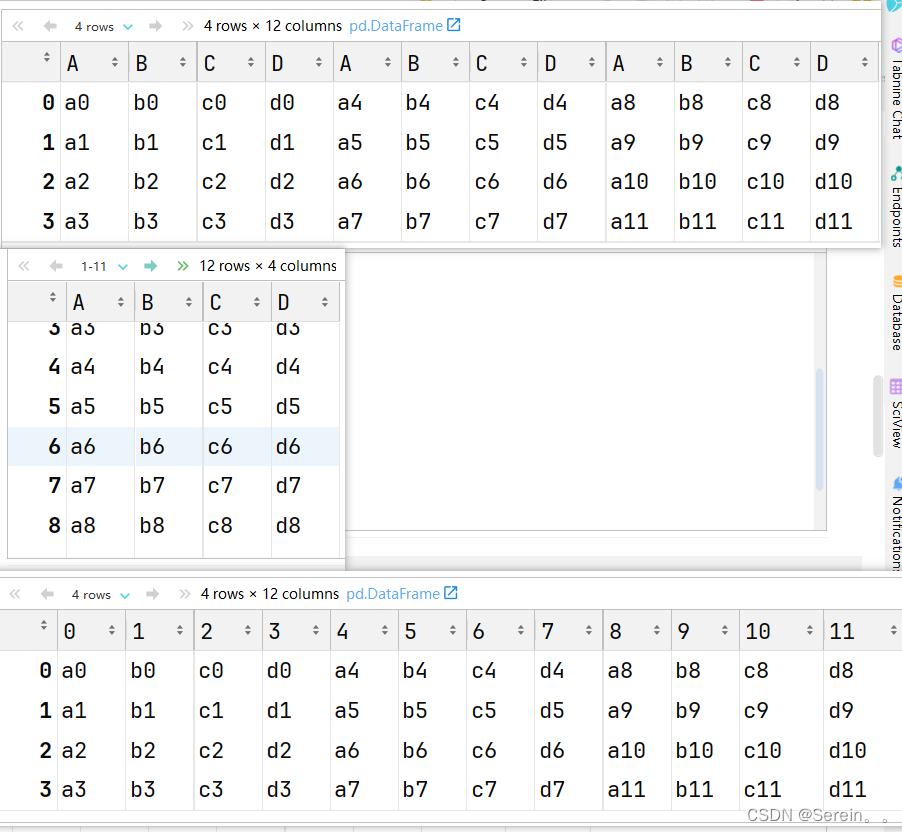
# 格式:pd.concat([data1,...]) axis=1列
pd.concat([df1,df2,df3]) #默认垂直(行,纵向)拼接,参考列名
pd.concat([df1,df2,df3],axis='rows') #效果同上
pd.concat([df1,df2,df3],axis='columns') #水平(列,横向)拼接,参考行号
# 行拼接后获取数据
pd.concat([df1,df2,df3],axis='rows').loc[3] # 三条数据
pd.concat([df1,df2,df3],axis='rows').iloc[3] # 一条数据
pd.concat([df1,df2,df3],axis='columns').loc[3] # 一条数据
pd.concat([df1,df2,df3],axis='columns').iloc[3] # 一条数据
# 行拼接时忽略 行索引 或 列名 “ignore_index=True”
pd.concat([df1,df2,df3],axis='rows',ignore_index=True)
# 列拼接时忽略 行索引 或 列名 “ignore_index=True”
pd.concat([df1,df2,df3],axis='columns',ignore_index=True)
运行结果:
2.merge连接
import sqlite3
# 1. 创建连接对象, 关联: Sqlite文件.
con = sqlite3.connect('data/chinook.db')
# 2. 读取SQL表数据, 参1: SQL语句, 参2: 连接对象
tracks = pd.read_sql_query('select * from tracks', con) # track: 歌曲表
# 3. 查看数据.
tracks.head()
# 4. read_sql_query()函数, 从数据库中读取表, 参1: SQL语句, 参2: 连接对象.
genres = pd.read_sql_query('select * from genres', con) #genre:(歌曲流派)歌曲类别表
genres.head() # 数据介绍, 列1: 风格id, 列2: 风格名(爵士乐, 金属...)# 5. 从track表(歌曲表)提取部分数据, 使其不含重复的'GenreID'值
tracks_subset = tracks.loc[[0, 62, 76, 98, 110, 193, 204, 281, 322, 359], ]
tracks_subset一对一合并
# 一对一合并
# on关联条件,how 关联方式
# 歌曲id,分类id,歌曲时长
#左外连接
genres.merge(tracks_subset[['TrackId','GenreId','Milliseconds']],on='GenreId',how='left')
#右外连接
genres.merge(tracks_subset[['TrackId','GenreId','Milliseconds']],on='GenreId',how='right')
#满外连接
genres.merge(tracks_subset[['TrackId','GenreId','Milliseconds']],on='GenreId',how='outer')
# 内连接,交集
genres.merge(tracks_subset[['TrackId','GenreId','Milliseconds']],on='GenreId',how='inner')多对一合并
# 1. 获取连接数据, 本次是: tracks(歌曲表) 所有的数据
genre_track = genres.merge(tracks[['TrackId', 'GenreId', 'Milliseconds']], on='GenreId', how='left')
genre_track.head()
# 2. 转换时间单位.
# 需求1: 计算每种类型音乐的 平均时长.
# 2.1 根据 类型名分组, 统计时长 平均值即可.
genre_time = genre_track.groupby('Name')['Milliseconds'].mean()
# 2.2 代码解释
# pd.to_timedelta(genre_time, unit='ms'): 把 genre_time 转成 timedelta 时间类型.
# dt.floor('s') 日期类型数据, 按指定单位截断数据, s 表示: 秒
pd.to_timedelta(genre_time, unit='ms').dt.floor('s').sort_values()3.join连接
依据两个数据表的行索引
# 1. 加载源数据
import pandas as pd
stock_2016 = pd.read_csv('data/stocks_2016.csv')
stock_2017 = pd.read_csv('data/stocks_2017.csv')
stock_2018 = pd.read_csv('data/stocks_2018.csv')
# 2. 查看数据.
stock_2016
stock_2017
stock_2018
# 3. 演示join()合并
# 需求: 拼接 stock_2016 和 stock_2017
# 写法1: 不指定关联字段, 则: 默认用 行索引列.
# 参数解释: lsuffix 给左表重名字段加后缀.
# 参数解释: rsuffix 给右表重名字段加后缀.
# 参数解释: how = 'left' 默认: 左外连接
# 参数解释: on = 关联字段, 不写: 默认就用 行索引列
stock_2016.join(stock_2017, lsuffix='_2016', rsuffix='_2017', how='left')
# 写法2: 设置两个df的 Symbol 分别为自身的 行索引列.
stock_2016.set_index('Symbol').join(stock_2018.set_index('Symbol'), lsuffix='_2016', rsuffix='_2018', how='left')
stock_2016.set_index('Symbol').join(stock_2018.set_index('Symbol'), lsuffix='_2016', rsuffix='_2018', how='right')
stock_2016.set_index('Symbol').join(stock_2018.set_index('Symbol'), lsuffix='_2016', rsuffix='_2018', how='inner')
stock_2016.set_index('Symbol').join(stock_2018.set_index('Symbol'), lsuffix='_2016', rsuffix='_2018', how='outer')
# 写法3: 将2018的Symbol设置为索引列, 关联 2016的 Symbol列.
stock_2016.join(stock_2018.set_index('Symbol'), lsuffix='_2016', rsuffix='_2018', how='outer', on='Symbol')
九、缺失值的处理
通常我们处理准备数据时会发现数据中常有缺失数据,可能是数据表合并时出现缺失,也有可能是因为原始数据自带缺失值,但为了数据处理和模型训练时,最终结果更加准确,对于少量缺失值我们可以进行删除处理,对于大量缺失值,我们要先查看数据是否准确,从多方便考虑,是删除或是填充,以什么方式填充,填充什么值。
1.缺失值的表示形式区分
# 导包
import numpy as np
# 1. 缺失值不是 True, False, 空字符串, 0等, 它"毫无意义"
print(np.NaN == False)
print(np.NaN == True)
print(np.NaN == 0)
print(np.NaN == '')
# 2. np.nan np.NAN np.NaN 都是缺失值, 这个类型比较特殊, 不同通过 == 方式判断, 只能通过API
print(np.NaN == np.nan)
print(np.NaN == np.NAN)
print(np.nan == np.NAN)
# 3. Pandas 提供了 isnull() / isna()方法, 用于测试某个值是否为缺失值
import pandas as pd
print(pd.isnull(np.NaN)) # True
print(pd.isnull(np.nan)) # True
print(pd.isnull(np.NAN)) # True
print(pd.isna(np.NaN)) # True
print(pd.isna(np.nan)) # True
print(pd.isna(np.NAN)) # True
# isnull() / isna()方法 还可以判断数据.
print(pd.isnull(20)) # False
print(pd.isnull('abc')) # False
# 4. Pandas的notnull() / notna() 方法可以用于判断某个值是否为缺失值
print(pd.notnull(np.NaN)) # False
print(pd.notnull('abc')) # True2.缺失值的处理
加载数据时处理缺失值
# 加载数据时直接加载缺失值,用NaN填充
df=pd.read_csv('dataset03/survey_visited.csv')
df
# 加载数据时,忽略缺失值,留空
df=pd.read_csv('dataset03/survey_visited.csv',keep_default_na=False)
df
# 加载数据时,指定某些值为缺失值
df=pd.read_csv('dataset03/survey_visited.csv',keep_default_na=False,na_values=['734','844','DR-1'])
df3.可视化查看缺失值
train=pd.read_csv('dataset03/titanic_train.csv')
train
# 查看获救情况
train['Survived'].value_counts() #获救人数342
# 可视化 查看缺失值
import matplotlib as plt
import missingno as msno #查看缺失值需要导的包
msno.bar(train) # 柱状图
# 查看缺失值的相关性
msno.heatmap(train)4.缺失值处理---删除缺失值
删除缺失值,使用dropna()函数,具体传入的参数解释如下:
-
subset=None 默认是: 删除有缺失值的行, 可以通过这个参数来指定, 哪些列有缺失值才会被删除
-
例如: subset = ['Age'] 只有当年龄有缺失才会被删除
-
inplace=False 通用参数, 是否修改原始数据默认False
-
axis=0 通用参数 按行按列删除 默认行
-
how='any' 只要有缺失就会删除 还可以传入'all' 全部都是缺失值才会被删除
train=pd.read_csv('dataset03/titanic_train.csv')
train.shape #(891, 12)
# 默认按行删除缺失值,只要这行有缺失值就删除这行
train.dropna() # 183行,12列
# how:表示如何删除,any:只要有一个nan就删除这行或这列
# all:这行或这列只要全空就删除这行或这列
train.dropna(axis=0,how='any') #183行12列
train.dropna(axis=0,how='all') #891行12列
# 删除是仅参考某列的值,该列值为空就删除该行
train.dropna(subset=['Age']) # 714行12列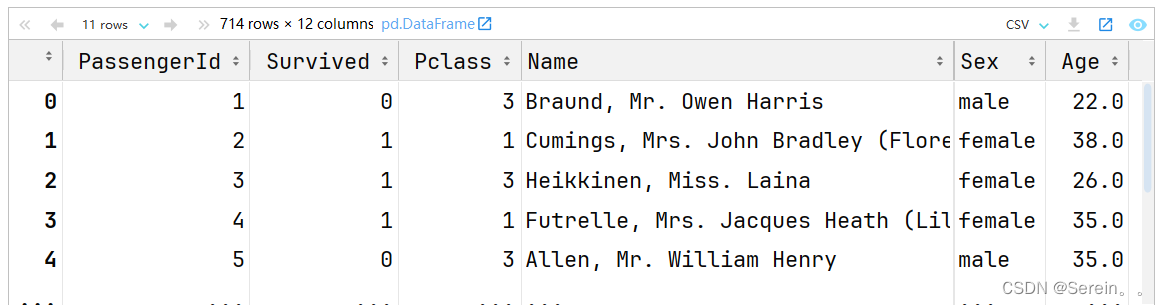 可以看出删除缺失值后,剩714行,12列
可以看出删除缺失值后,剩714行,12列
5.非时序数据填充
非时序数据的缺失值填充, 直接使用fillna(值, inplace=True)函数
-
可以使用统计量 众数 , 平均值, 中位数 ...
-
也可以使用默认值来填充
# 填充缺失值, 填充缺失值是指用一个估算的值来去替代缺失数
# 非时间序列数据, 可以使用常量来替换(默认值)
#查看填充前每列缺失值情况
train.isnull().sum()
# 用 0 来填充 空值.
train.fillna(0)
# 查看填充后, 每列缺失值 情况.
train.fillna(0).isnull().sum()
# 需求: 用平均年龄, 来替换 年龄列的空值.
train['Age'].fillna(train['Age'].mean())6.时序数据填充
(1)fillna()函数中有ffill和bfill表示参考空值前一个值和后一个值填充
# 查看平均值.
city_day['Xylene'].mean() # 3.0701278234985114
# 用平均值来填充.
city_day.fillna(city_day['Xylene'].mean())[50:64]['Xylene']
# 使用ffill 填充,用时间序列中空值的上一个非空值填充
# NaN值的前一个非空值是0.81,可以看到所有的NaN都被填充为0.81
city_day.fillna(method='ffill')[50:64]['Xylene']
# 使用bfill填充,用时间序列中空值的下一个非空值填充
# NaN值的后一个非空值是209,可以看到所有的NaN都被填充为209
city_day.fillna(method='bfill')[50:64]['Xylene'](2)线性插值
线性插值法是一种插补缺失值技术,它假定数据点之间存在线性关系,利用相邻数据点中的非缺失值来计算缺失数据点的值。参数limit_direction: 表示线性填充时, 参考哪些值(forward: 向前, backward:向后, both:前后均参考)
city_day.interpolate(limit_direction="both")[50:64]['Xylene']十、 apply方法
当Pandas自带的API不能满足需求, 例如: 我们需要遍历的对Series中的每一条数据/DataFrame中的一列或一行数据做相同的自定义处理, 就可以使用Apply自定义函数,它可以接收一个自定义函数,将DataFrame的行列数据传递给自定义函数处理,它类似于一个for循环,遍历行列的每一个元素,但比for循环效率高很多。
1.Series的apply方法
import pandas as pd
# 1. 准备数据
df = pd.DataFrame({'a': [10, 20, 30], 'b': [20, 30, 40]})
df
# 2. 创建1个自定义函数.
def my_func(x):
# 求平方
return x ** 2
def my_func2(x, e):
# 求x的e次方
return x ** e
# 3. apply方法有一个func参数, 把传入的函数应用于Series的每个元素
# 注意, 把 my_func 传递给apply的时候,不要加上小括号.
df['a'].apply(my_func) # 传入函数对象.
df['a'].apply(my_func2, e = 2) # 传入函数对象, e次幂(这里是平方)
df['a'].apply(my_func2, e = 3) # 传入函数对象, e次幂(这里是立方)2.DataFrame的apply方法
# 1. 把上面创建的 my_func, 直接应用到整个DataFrame中
df.apply(my_func) # my_func函数会作用到 df对象的每一个值.
# 2. 报错, df对象是直接传入一列数据的, 并不是 一个值一个值传入的
def avg_3(x, y, z):
return (x + y + z) / 3
df.apply(avg_3)
# 3. 演示 df对象, 到底传入啥.
def my_func3(x):
print(x)
print(f'x的数据类型是: {type(x)}')
# 每次传入 1 列
# df.apply(my_func3, axis=0) # 0(默认): 列, 1: 行
# 每次传入 1 行
df.apply(my_func3, axis=1) # 0(默认): 列, 1: 行















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









