



知识图谱调研
一、什么是知识图谱
-
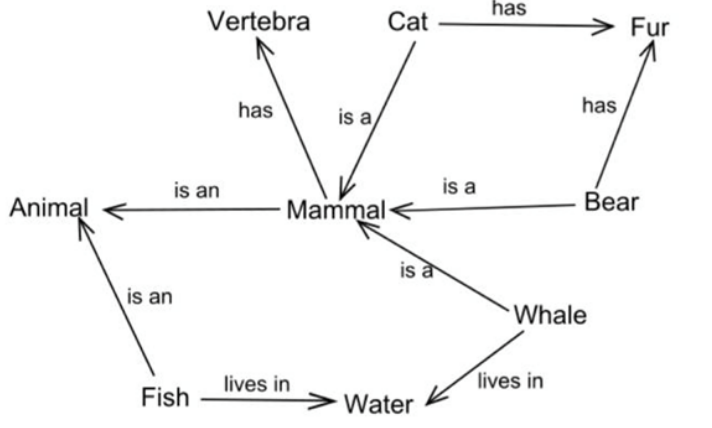
知识图谱(Knowledge Graph)是一种结构化的语义知识库,用于描述物理世界中的概念及其相互关系。它通过“实体-关系-实体”三元组来表示知识,并将实体间通过关系相互联结,形成网状的知识结构,如下图。
-
-
发展阶段:第五届国际人工智能会议上,美国计算机科学家B.A.Feigenbaum首次提出知识工程的概念。知识工程是通过存储现存的知识来实现对用户的提问进行求解的系统,其中最典型和成功的知识工程的应用是基于规则的专家系统。此后,以专家系统为代表的知识库系统开始被广泛研究和应用。
-
Google为了提升搜索引擎返回的答案质量和用户查询的效率,于2012年5月16日发布了知识图谱(Knowledge Graph)。2013年以后知识图谱开始在学术界和业界普及。
-
组成要素:
-
实体:客观存在并可以相互区别的事物,人、事、物、抽象概念等
-
关系:表示不同实体间存在的某种关系
-
属性:实体和关系都可以有各自的属性
-
-
应用范围:
-
语义搜索:通过推理实现概念检索,提高检索精确度
-
智能问答:为问答系统提供垂直领域的背景知识
-
推荐系统:通过实体间的关系推导出相关推荐
-
二、KG构建流程
1、知识建模
基于行业应用应用属性、知识特点、实际需求、依据知识图谱的模式schema设计,主要是实体定义、关系定义、属性定义、需要业务及领域专家参与设计。
2、知识存储
首先数据类型分为三大类:结构化数据(一般存储在现有的关系型数据库中,以二维表逻辑实现的数据)、非结构化数据(包括文本、图片、音频等)、半结构化数据(介于前两者之间,数据结构和内容混杂,例如HTML格式数据)。
3、知识抽取
-
实体抽取(Name Entity Recognition,NER):也叫命名实体识别,简称NER,从文本数据中自动识别命名实体。
-
关系抽取:为了方便得到语义信息,从相关语料提取实体间的关联关系,通过关系将实体链接,形成网状结构。
-
属性抽取:从不同信息源中采集特定领域的属性信息。
4、知识融合
将不同领域知识库中的同一类实体融合在一起,主要步骤包括:实体对齐,属性对齐,属性值融合。
5、知识计算
-
图挖掘计算:基于图论的相关算法,实现对图谱的探索和挖掘。(PageRank、最短路径、社区发现等)
-
本体推理:使用本体推理进行新知识发现或冲突检测,处理知识图谱之间关系值缺失,完成进一步的知识发现。
-
基于规则推理:使用规则引擎,编写相应的业务规则,通过推理辅助业务决策。
6、知识应用
问答系统、搜索引擎、推荐系统、医疗、司法、安全、教育等
三、什么时候使用知识图谱
知识图谱作为一种面向人机协同的开放知识管理机制,有特定价值和成本。对于具体业务问题而言,知识图谱并非唯一的解决方案,也不总是最优的解决方案,这就会引发以下问题:
-
这是一个封闭的系统还是开放的系统?涉及到融合外部数据,尤其是非结构化数据与结构化数据的融合,或者后续未知的数据修订,知识图谱会产生价值。
-
是否涉及复杂的关系查询?关系数据库同样可以处理关系查询,知识图谱结合图数据处理平台则可以高效处理对复杂子图(多层JOIN)的探索式查询。
-
是否要作为企业内部数据标准化的一部分?一个独立的业务系统可自洽运行,但是当和企业内部其他信息系统对接,需要标准化的可理解的数据接口。
-
能否承担实施知识图谱基础设施的成本?系统可以复用规则推理、图分析、机器学习等常见人工智能模块,知识图谱通过通用的数据接口和可复制的研发流程,提升系统构建效率。
四、开源的知识图谱工具
1、领域知识图谱
-
百科全书式知识图谱:YAGO、Freebase 、DBpedia、CN - DBpedia、Probase、Wikidata、CN - Probase
-
YAGO开源(基于维基百科数据)许可:CC-BY 3.0,如若商业使用,需要署名。
-
Freebase:目前项目停止,但数据可以访问;许可:CC-BY 4.0,如若商用,需要署名
-
DBpedia:开源(基于维基百科)许可:CCO(数据)、ODC-BY 1.0(元数据)
-
CN-DBpedia:开源(中文知识图谱)许可:CC-BY-SA 3.0,商用需要署名+相同方式共享
-
Probase:部分开放(微软发布),非商业用途,如若使用,应与微软联系或许商业许可
-
Wikidata:开源,许可:CCO(数据)、ODC-BY 1.0(元数据),须遵守元数据署名
-
CN-Probase:开源(中文概念图谱),大规模使用需联系获取APIkey
-
-
语言知识图谱:WordNet、ConceptNet、HowNet、Babelnet、THUOCL
-
WordNet:开源,许可:BSD-style,商用需保留版权声明
-
ConceptNet:开源,许可:MLT License,可商用无限制
-
HowNet:部分开放(中文知识库)商用需申请
-
BabelNet:数据开放,但API使用受限,许可:CC-BY-SA 3.0,商用需要署名+相同方式共享
-
THUOCL:清华大学开放中文词库,须遵守学术引用规范,商用要联系授权
-
-
常识知识图谱:OpenCyc、ASER、TransOMCS
-
OpenCyc:部分开放(完整需商业许可)许可:GPL 3.0(开源版本),需购买商业许可
-
ASER:开源,无限制,许可:Apache 2.0
-
TransOMCS:开源(多模态知识图谱)许可:MIT License,商用无限制
-
-
领域特定知识图谱 :PubMed、Drugbank、Huapu ASN、OAG、TransOMCS、COVID - 19 Concepts、Aminer COVID - 19 Open Data
-
PubMed:数据开放需要遵守NCBI使用政策,默认仅允许研究用途,商用需要申请
-
Drugbank:免费学术许可(需注册),需购买商业许可
-
Huapu ASN:开源(中药成分图谱)许可:CC-BY 4.0,商用需要署名
-
OAG:开源,许可:ODC-BY 1.0,商用需署名
-
TransOMCS:开源,可商用
-
COVID - 19 Concepts:开源(疫情相关图谱)许可:CC-BY 4.0,商用需要署名
-
Aminer COVID - 19 Open Data:开源,商用需署名
-
-
联邦知识图谱:GEDmatch、OpenKG.cn
-
GEDmatch:不开源,(基因数据平台需要授权访问),严格限制
-
OpenKG.cn:知识图谱开源社区(托管多个项目),需查看具体图谱许可协议
-
2、开源的各类图谱工具
(1)知识图谱可视化工具
-
D3.js:它是一个用于根据数据操作文档的JavaScript库,强调Web标准,提供了关于图网络的不同图层样式可供选择,还提供现代浏览器的全部功能。与Echarts、HighCharts、vis.js等大多数基于Canvas实现图形绘制不同,D3.js同时支持SVG和Canvas两种方案。不过,D3js提供的API偏底层,需要实现的代码较多,具有一定的门槛,并且对图谱而言,每个节点、边都有对应的DOM元素,当节点数很多的时候,对内存不是很友好,还影响性能。地址:Observable: Explore and visualize data together@d3/gallery
-
Vis.js:Vis.js 是一个动态的基于浏览器的可视化库,特点是易用,并与这些数据进行交互操作,该库包含DataSet、Timeline、Graph等插件类型,对于小规模项目比较实用。地址:Vis Network Examples
-
Echarts:基于JavaScript的数据可视化图表库,提供直观,生动,可交互,可个性化定制的数据可视化图表,ECharts最初由百度团队开源,echarts中内置了关于图可视化方的插件,也是一个比较简单的图谱可视化开源库,地址:Examples - Apache ECharts
-
AntvG6:蚂蚁金服全新一代数据可视化解决方案,推出了G2、G6等可视化插件。其中,AntvG6是由蚂蚁开发的一个简单、易用、完备的图可视化引擎,G6的6来自于《六度分隔理论》,表达了对关系数据,关系网络的敬畏。它在高定制能力的基础上,提供了一系列设计优雅、便于使用的图可视化解决方案。能帮助开发者搭建属于自己的图进行图分析应用或者图编辑器应用。特点:开发代码量小,嵌入方便,官网文档详细,易上手。地址:快速上手 · 语雀
(2)文本标注工具
-
Chinese-Annotator:开源可商用;专注于中文文本标注,支持实体识别、关系抽取等;使用场景:医疗,金融领域实体标注;项目地址:https://github.com/deepwel/Chinese-Annotator使用方法写的很详细,直接拉取,跟着步骤就好,也可以参考:【亲测免费】 Chinese-Annotator 安装和配置指南-CSDN博客
-
优点:中文友好,支持多任务类型
-
缺点:项目目前停止更新,只能依赖旧技术栈。
-
-
IEPY:开源不可商用;信息抽取工具,支持关系抽取和事件标注;使用场景:学术研究和小规模信息抽取项目;项目地址:https://github.com/machinalis/iepy;
-
优点:规则引擎灵活,适合复杂逻辑
-
缺点:社区不活跃,仅支持python2
-
-
DeepDive (Mindtagger):开源可商用;用于提取实体之间复杂的关系,并对涉及这些实体的事实进行推断,与DeepDive知识库构建工具集成。2017年后不再更新,使用情况可参考:Labeling DeepDive Data with Mindtagger - DeepDive;
-
优点:高效校对和迭代标注,支持多用户操作
-
缺点:学习成本高,需要搭配DeepDive使用
-
-
BRAT:开源可商用;基于web的文本标注工具,主要用于对文本的结构化标注,用BRAT生成的标注结果能够把无结构化的原始文本结构化;最大的特点是在标注实体的同时可以进行关系的标注。项目地址:https://github.com/nlplab/brat;入门可参考:Installation - brat rapid annotation tool;
-
优点:可视化强,支持复杂标注类型
-
缺点:配置复杂,需要部署BRAT服务器,无预训练模型集成,不支持中文
-
-
SUTDAnnotator:开源可商用;是YEDDA的前身,开发用于在文本(几乎所有语言,包括英语、中文)、符号甚至表情符号上注释块/实体/事件,支持快捷注释,手工注释文本非常有效。用户只需选中文本并按快捷键,就会自动标注;还支持命令注释模型,该模型可以批量注释多个实体,并支持将带注释的文本导出为序列文本;另外更新版本还包括智能推荐和管理员分析,与所有主流操作系统兼容,在win10可以直接用,但是是基于python2开发的,所以安装需要用python2。项目地址直接参考:https://github.com/jiesutd/YEDDA;
-
优点:轻量易用,标注方便,可以实现同一实体多个标签;
-
缺点:功能较为单一,支持基础标注类型,快捷键不宜设置过多
-
-
Snorkel:开源可商用;用于快速创建、建模,弱监督标注工具,通过编程生成标签;适用于缺乏标注数据的大规模任务;项目地址:https://github.com/snorkel-team/snorkel
-
优点:减少人工标注成本,支持噪声标签处理
-
缺点:需要编程能力,标注质量依赖与规则的设计
-
-
Slate:开源可商用;基于React的标注工具框架,支持自定义界面,Slate 提供极高的定制化能力,开发者可以根据需求自由扩展功能,还提供 Vue 和 Angular 的社区版本,适用于多种前端框架;项目地址:https://github.com/jackyzha0/slate;
-
优点:高度可定制,适合特定需求
-
缺点:需要前端开发经验,没有预置功能
-
-
Prodigy:不开源,很贵;商业级别标注工具,支持主动学习和预训练模型集成;适合需求高精度的图像标注类;项目地址:https://prodi.gy;
-
优点:标注精度高,支持模型实时反馈
-
缺点:价格昂贵,不开源
-
-
doccano:开源可商用;多功能标注工具,支持文本分类、序列标注等,适合团队协作标注;项目地址:https://github.com/doccano/doccano
-
优点:支持团队协作,好上手,导出文件格式丰富,性价比较高
-
缺点:复杂任务配置比较复杂
总结:BRAT是当前功能较为全面的一款标注工具,提供了事件标注、实体标注、关系标注等多个标注功能,而doccano具有较好的使用体验,但不支持关系标注。不过,由于开源的标注工具在协同标注、标注任务协调与管理、标注任务的性能上考虑的不是特别周到,因此还是建议在可视化标注平台的构建上,能够基于已有的平台进行二次开发,或者自行根据财力、人力、物力的实际情况,开发高可用的平台。
-
(3)数据采集工具
数据采集一般包括几个基本流程:先获得目标数据的URL、并向对应的URL提交HTTP请求,解析HTTP响应,存储解析结果。在每个阶段都有成熟的开源工具来支持,例如python自带的urllib组件、Requests组件等,均可以完成向目标URL发起不同种类的HTTP请求。
-
Selenium:开源可商用;适用于自动化浏览器,网页测试和数据采集,支持主流的Chrome、Firefox、Safari浏览器,通常可搭配phantomJS作为渲染方式;项目地址:https://www.selenium.dev
-
优点:支持主流浏览器,可模拟真实用户操作
-
缺点:资源消耗高,速度慢,不适合大规模数据集
-
-
curl.trillworks:可商用;可将某个网页的curl请求转换成可执行的python爬虫脚本;项目地址: https://curl.se
-
优点:轻量级,速度快,支持多种协议,无需依赖,适合脚本集成
-
缺点:无法处理JavaScript渲染的页面,数据也需要手动解析
-
-
scrapy:可商用;python框架,专为高效爬虫打造设计,支持大规模数据采集,用户只需定制开发几个模块就可以轻松实现爬虫;项目地址:https://scrapy.org
-
优点:异步网络请求,性能高,有数据管道
-
缺点:需理解框架结构,不支持动态页面渲染
-
(4)文本处理工具
-
NLTK:开源可商用;该组件支持英文文本的处理,内置了数据集、处理以及分析模块,支持语料库获取、字符串处理、语义分析等功能。例如nltk.corpus提供了例如gutenberg、brown语料库和词典wordnet等的标准化接口,可以通过wordnet获取给定词的定义、例句、同义词、反义词、上下位词等数据,nltk.toknnize和nltk.stem用于分词和提取主干(词性还原),ntltk.collocations提供了基于t-检验、卡方和点间互信息的搭配算法,nltk.chunk用于正则表达式和命名实体识别。项目地址:https://www.nltk.org
-
优点:功能全面,支持多种语言处理任务
-
缺点:处理速度慢,中文支持弱,模型较老旧
-
-
Spacy:开源可商用;最流行的NLP开发包之一,处理速度快,预置词性标注、句法分析、NER等必备的模型、spacy的document可以在tokenized过程中分割成单句,便于后续操作;(性价比真的很高)项目地址:https://spacy.io
-
优点:速度快,预训练模型丰富,API设置简洁
-
缺点:中文支持可能受限
-
-
Jieba:开源可商用;目前中文分词应用最广泛,包含多种分词模式,比如:全模式、精确模式、搜索引擎模式、paddle模式(需要利用深度学习框架)这种模式可以指定自己的词典,还提供了基于TF-IDF算法以及TextRank关键词抽取能力;项目地址:https://github.com/fxsjy/jieba;
-
优点:轻量级,中文分词效果好
-
缺点:功能单一,不支持句法分析
-
-
LTP:开源,部分功能收费,商用须遵守附加条款;哈工大自研,制定了基于XML的语言处理表示,并提供了丰富高效、高精度的中文NLP模块,包含词法、句法、语义等五项核心处理技术,接口功能完备。项目地址:https://github.com/HIT-SCIR/ltp;
-
优点:哈工大自研,中文处理精度顶尖
-
缺点:部分功能收费,社区支持弱
-
-
DDParser:开源可商用;百度自研,基于深度学习平台PaddlePaddle和大规模标注数据研发的依存句法分析工具,数据覆盖场景丰富,使用简便。项目地址:https://github.com/baidu/DDParser;
-
优点:百度自研,中文精度高
-
缺点:功能单一,只能中文
-
-
Standfordparser:开源,学术免费,商用付费;是StandNLP小组提供的一系列工具之一,适用于语法分析任务,它可以找出句中词语间的关系,输出有向图等形式,有特定处理模块的API可调用,支持多语言,项目地址:Stanford NLP
-
优点:精度高,支持多语言
-
缺点:速度慢,依赖java,商用需要付费
-
-
Hannlp:开源可商用;由一系列模型和算法徐成的java工具包,功能完善、性能高效、架构清晰、语料时新、面向中文领域功能完备,支持多语言分词,词性标注,NER,关键词提取、文本分类聚类、Word2vec等多个接口。项目地址:https://github.com/hankcs/HanNLP;
-
优点:功能全面,支持预训练模型
-
缺点:依赖Pytorch/TensoFflow,资源消耗高
总结:中文分词选jieba比较有性价比,轻量级,好上手,也可尝试Hannlp适合多任务和DDParser精度高功能全面;英文领域SpaCy和NLTK功能丰富。
-
(5)开源本体构建工具
-
protégé:开源可商用;当前流行的一套开源知识建模可视化工具,由斯坦福大学开发,但工业界使用存在较大差距,用它建模的较少;项目地址:https://protege.stanford.edu;页面老旧,全英文,教程也可参考:知识图谱学习与实践(5)——Protégé使用入门 - cooldream2009 - 博客园和Protege入门的第一个保姆级实例-CSDN博客
-
优点:免费,社区活跃,插件丰富
-
缺点:界面老旧,大规模本体性能受限
-
-
NeOn Toolkit:开源可商用;适用于负责本体工程,多本体协同开发,提供丰富插件可以帮助开发人员本体调试,评估等,基于Eclipse平台安装插件,项目地址:NeOn Toolkit, The Open University;
-
优点:支持本体模块化复用,适合团队协作
-
缺点:目前停止更新维护,不建议使用
-
-
Altova SemanticWorks:可商用,需要购买;它属于一个RDF/OWL编辑器,用于构建语义Web的开创性图形RDF、OWL编辑器,项目地址:ECU | Dr Leslie Sikos : Staff : Science : Schools;
-
优点:图形化界面友好,适合非技术用户,支持XSD、json-LD等格式转换
-
缺点:太贵,无法处理大规模本体
-
-
TopBraid Composer:可商用,需付费;集成多种推理引擎,可以设定引擎执行顺序,还支持带推理能力的SPARQL查询;项目地址:TopQuadrant – Making Sense of Your Data
-
优点:上手还算简单,直接导入本体数据源,具体参考官网文档
-
缺点:贵,企业级定价
-
-
XMind思维导图:可商用,部分功能收费,但性价比还是挺高的;本体定义可以借助可视化工具,百度脑图,MindManager,XMind都可以辅助建模,他们提供了节点,项目地址: 免费下载 Xmind思维导图 | Xmind中文官方网站;
-
优点:简单易用,适合快速原型设计,至此多平台
-
缺点:非专业本体工具,无法导出OWL/RDF格式,高级功能需付费
总结:本体构建,从工程角度来看,知识本体是面向知识图谱的构建者和使用者的,作为知识抽取的依据,不一定要将本体存储在数据库中,也可放到json字典中直接调用;构建本体前需要跟客户沟通好,架构,统一标准,方便后续开发中搜索,意图、槽位的秩序性。
-
(6)图谱存储工具
-
Neo4j图数据库:开源可商用;高性能的图引擎,具有成熟数据库的所有特性,目前最流行,且社区活跃生态成熟,利用Cypher语言以及自带可视化工具;Cypher语言很友好,通过箭头和节点,让查询语句很生动,项目地址:Neo4j Graph Database & Analytics | Graph Database Management System;
-
优点:社区活跃,适合中小型企业快速开发
-
缺点:社区版无分布式集群功能需要付费企业版,不适合百亿级别大规模数据
-
-
HugeGraph:开源可商用;百度开源的图数据库,基于Apache TinkerPop3框架,支持Gremlin查询语句,提供可视化工具,还可以基于SparkGraphX图分析工具,在图上做并行计算,再导入数据方面支持txt,csv,json等格式,具备独立的Schema元数据信息,项目地址:HugeGraph
-
优点:原生分布式框架,支持水平扩展,插件丰富
-
缺点:社区生态小,商业支持有限,运维难度高与Neo4j
-
-
NebulaGraph:开源可商用;高性能的分布式图数据库,shared-nothing分布式架构,企业可根据具体业务扩缩容,同样提供可视化工具NebulaGraphStudio,项目地址:https://github.com/vesoft-inc/nebula
-
优点:性能卓越,适合大规模数据,支持多引擎(Mysql等)
-
缺点:可视化工具较弱,需依赖第三方工具
-
(7)知识抽取工具
-
Hugging Face Transformers:代码可商用,具体模型部分可能需要遵循协议;支持Bert等模型进行实体识别、关系抽取,再结合深度学习等算法,可以实现信息抽取任务,适合高精度抽取,项目地址:https://github.com/huggingface/transformers;
-
优点:集成Bert、RoBerta等数万个预训练模型,支持自定义训练
-
缺点:部分模型商用须遵循协议,运行大模型需GPU支持
-
-
PaddleNLP:可商用,针对于中文实体识别,信息抽取,预训练模型丰富;项目地址:https://github.com/PaddlePaddle/PaddleNLP
-
优点:百度自研,中文友好,覆盖数据标注,训练到部署全流程
-
缺点:英文支持弱,需结合paddlepaddle框架使用
-
-
DeepKE:可商用;浙江大学开发的开源组件,以统一的接口实现了目前主流的关系抽取模型,包括,卷积神经网络,循环神经网络,注意力机制,图卷积等,项目地址:https://github.com/zjunlp/deepke
-
优点:支持实体、关系、事件抽取三位一体,提供中文医疗、金融等领域数据集
-
缺点:需要自行封装API,社区不支持主流框架
-
-
OpenNRE:可商用;清华大学NLP实验室推出的开源神经网络关系抽取工具包,包括多款常用的关系抽取模型,项目地址:https://github.com/thunlp/OpenNRE.git
-
优点:模型灵活性高,中文支持友好
-
缺点:依赖标注数据,成本较高,需自行封装API
-
-
DeepDive:斯坦福大学开发的开源知识抽取系统,通过弱监督学习,从非结构化文本中抽取结构化关系数据,现在支持中英文了,项目地址:https://www.openkg.cn/dataset/cn-deepdive
-
优点:支持复杂逻辑,处理噪声数据能力强,全流程支持
-
缺点:部署复杂,依赖PostgreSQL数据库和Java环境,配置维护成本高
-
(7)知识融合工具
-
Dedupe:开源可商用;提供实体匹配工具和实体消解功能,使用时通过选择少量数据,指定谓词集合和相似度函数,训练相似性的计算方法后,可对结构化数据快速执行模糊匹配,完成重复数据删除和实体对齐。项目地址:https://github.com/dedupeio/dedupe
-
优点:支持半监督学习,仅需标注少量数据,提供交互式标注页面,低资源、高回报
-
缺点:仅使用结构化数据,无法处理文本语义,大规模数据内存占用高
-
-
Falcon-Ao:开源可商用;是web应用程序的基础设施,目的是提供基础技术来发现,对齐和学习本体,其中Model Pool通过Jena工具解析输入本体到模型当中,项目地址:http://ws.nju.edu.cn/falcon-ao/;
-
优点:对齐精度高
-
缺点:部署维护复杂,对非RDF数据支持有限
-
-
LIMES:开源可商用;基于Java开发的实体匹配发现框架,利用度量空间的三角不等式特征过滤大量不满足映射条件的实例对,从而减少比较次数,内部提供超级丰富的相似度计算方法,如:Cosine、ExactMatch、Jaccard、Jaro、Jaro Winkler、Levenshtein、MongeElkan、Overlap、Qgrams、RatcliffObershelp、Soundex、Trigram;项目地址:https://github.com/dice-group/LIMES
-
优点:适合动态数据源
-
缺点:不适合流式数据处理,调试困难
-
-
OpenEA:开源可商用;南京大学万维网软件研究组开发的知识图谱实体对齐开源软件库,基于python、Tensorflow开发,集成了12种有代表性的基于嵌入的实体对齐方法,对齐模块提供余弦距离,欧几里得距离和曼哈顿距离三种策略。项目地址:https://github.com/nju-websoft/OpenEA
-
优点:跨语言对齐效果领先,提供预训练模型和标准数据集
-
缺点:训练依赖GPU集群,仅支持知名知识库(如DBpedia等)
-
-
PRASEMap:目前不开源,可根据论文自行实现;腾讯推出的知识图谱对齐工具,基于PRASE框架工具开发,用C++重构了中间复杂的计算部分,有全自动模式和半自动模式(需额外人工标注)项目地址:https://github.com/qizhyuan/PRASEMap
-
优点:基于概念推理,可解释性强
-
缺点:计算复杂度高,难以扩展
-
(8)知识计算工具
-
PyTorch Geometric(PyG)开源可商用
由德国多特蒙德工业大学推出的基于PyTorch的几何深度学习扩展库,PyG在学术中是比较热门的框架,但是PyG对于异构图以及大规模的图的学习存在着较大的局限性。项目地址: https://github.com/rusty1s/
-
优点:易于与深度学习模型结合,更新频繁,文档完善
-
缺点:需要熟悉PyTorch,对于大规模计算图不如专业的图框架
-
-
tf_geometric 开源可商用
受到PyG启发,为GNN创建了TensoFlow版本。在其Github开源的demo中,可以看到GAE、GCN、GAT等主流的模型已经实现。项目地址: https://github.com/CrawlScript/tf_geometric
-
优点:与TensorFlow深度集成,支持动态图和静态图计算,灵活性较高
-
缺点:社区规模和文档不如PyG
-
-
Deep Graph Library(DGL) 开源可商用
由New York University(NYU)和Amazon Web Services(AWS)联合推出的图神经网络框架。如今已发布至0.4版本的DGL更是全面上线对于异质图支持模块,复现并开源了相关异质图神经网络的代码,如HAN、Metapath2vec等,此外,DGL也发布了训练知识图谱嵌入专用包DGL-KE,并在许多经典的图嵌入模型上进一步优化了性能。项目地址: https://github.com/dmlc/dgl
-
优点:支持多种后端,灵活性强,提供高效的图操作和GNN实现,性能较好,教程丰富
-
缺点:超大规模图,性能可能仍需优化
-
-
CogDL 开源可商用
清华大学知识工程研究室推出了一个大规模图表示学习工具包 CogDL,可以让研究者和开发者更加方便地训练和对比用于节点分类、链路预测以及其他图任务的基准或定制模型。该工具包采用 PyTorch 实现,集成了Deepwalk、LINE、node2vec、GraRep、NetMF、NetSMF、ProNE 等非图神经网络和GCN、GAT、GraphSage、DrGCN、NSGCN、GraphSGAN 等图神经网络模型基准模型的实现。项目地址: https://github.com/THUDM/cogdl
-
优点:提供多种图嵌入和GNN算法,易于实验,轻量级,适合快速原型开发
-
缺点:社区规模小,文档和支持不如DGL和PyG
-
-
GraphEmbedding 开源可商用
github上开源的图embedding算法实现,包括DeepWalk、LINE、Node2Vec、SDNE和Struc2Vec项目地址: https://github.com/shenweichen/GraphEmbedding
-
优点:算法简单,易于理解和实现,计算开销低,适合中小规模图
-
缺点:功能单一,仅限于图嵌入,不支持复杂GNN任务,性能有限
-
-
Spark GraphX 开源可商用
企业对庞大网络中社区结构的洞察需求也越发迫切,基于分布式架构的图处理引擎应运而生,比如Google的Pregel, Apache的开源的图计算框架Giraph,以及卡内基梅隆大学主导的GraphLab等。Spark GraphX是一个分布式图处理框架,它是基于Spark平台针对图计算和图挖掘提供了简洁、易用、丰富的接口,包括连通子图算法、标签传播算法和louvain算法。极大的方便了对分布式图处理任务的需求。项目地址: GraphX | Apache Spark
-
优点:分布式计算能力强,适合处理超大规模图
-
缺点:需要熟悉Spark和Scala,对于GNN等深度学习任务支持有限
-
-
networkx 开源可商用
networkx是一个用Python语言开发的图论与复杂网络建模工具,内置了常用的图与复杂网络分析算法,可以方便的进行复杂网络数据分析、仿真建模等工作。利用networkx可以以标准化和非标准化的数据格式存储网络、生成多种随机网络和经典网络、分析网络结构、建立网络模型、设计新的网络算法、进行网络绘制,通常配合matplotlib一同使用。项目地址: NetworkX — NetworkX documentation
-
优点:简单易用,python实现,适合初学者,可视化功能强大
-
缺点:性能较差,不适合大规模,不支持分布式计算
-
-
Plato 开源可商用
图计算的发展和应用有井喷之势,各大公司也相应推出图计算平台,例如Google Pregel、Facebook Graph、阿里GraphScope等。Plato是腾讯开源的一款高性能图计算框架。Plato 的算法库中的图特征、节点中心性指标、连通图、社团识别、图表示学习等多种算法都已经开源。项目地址: https://github.com/tencent/plato
-
优点:高性能,支持分布式计算,适合工业级应用,支持多种图算法和嵌入方法
-
缺点:需熟悉分布式系统
-
(9)知识图谱表示/推理框架
-
DGL-KE:亚马逊团队开发针对大规模知识图谱嵌入表示的新训练框架,工业界使用方便,能快速在大规模知识图谱数据集上进行机器学习训练任务,项目地址:https://github.com/awslabs/dgl-ke
-
优点:基于DGL开发,支持高效图操作和分布式训练,包含多种经典KGE模型,性能好
-
缺点:主要聚焦于嵌入和推理,不支持更复杂的知识图谱查询,需熟悉DGL和知识图谱嵌入的概念
-
-
OpenKE:基于Tensorflow,Pytorch开发的用于将知识图谱嵌入到低维连续向量空间中表示的开源框架,它提供了快速稳定的各类接口,提供大量预训练向量,可以直接用于下游任务,项目地址: https://github.com/thunlp/OpenKE
-
优点:提供多种KGE模型,轻量级,易于集成到现有项目中,灵活性较高
-
缺点:性能上不如DGL-KE,社区支持弱,文档更新不频繁
-
-
Pytorch-BigGraph:facebook发布的分布式系统,用于学习大型图形嵌入,特别是多达数十亿实体和边的大型web交互图,项目地址:https://github.com/facebookresearch/PyTorch-BigGraph
-
优点:针对超大规模图优化,支持分布式训练,性能极高
-
缺点:部署复杂,适合有技术团队支持的场景
-
-
GraphVite:通用图形嵌入引擎,专用于各种应用中的高速和大规模嵌入学习,全部由C++实现,项目地址:https://github.com/DeepGraphLearning/graphvite
-
优点:性能极高,针对GPU加速优化,支持超大规模嵌入,包含多种嵌入算法
-
缺点:需熟悉底层优化和GPU配置,主针对学术用户
-
-
pykg2vec:集成了当前大部分主流KGE算法的开源库,基于Pytorch实现,代码结构清晰,适用于KGE算法实现的学习,项目地址:https://github.com/Sujit-O/pykg2vec
-
优点:提供丰富KGE模型,易于扩展,支持自定义模型
-
缺点:性能不如DGL-KE,适合中小型规模图谱
-
(10)图谱搜索工具
-
Elasticsearch:Es基于Java语言开发、高扩展、高实时的搜索与数据分析引擎。它提供了一个分布式多用户能力的全文搜索引擎,目前Es是最受欢迎的企业搜索引擎。在具体实现原理上,将需要进行匹配检索的知识图谱数据如实体知识、属性知识等提交到Elasticsearch 数据库中,再通过分词控制器去将对应的语句分词,将其权重和分词结果一并存入数据,当用户搜索数据时候,再根据权重将结果排名和打分,再将返回结果呈现给用户。但Elasticsearch版本更新较快,不不同的版本在语法和使用方式上存在一些差异,这是实际开发中需要注意的问题。项目地址: Elastic — 搜索 AI 公司 | Elastic
-
FAISS:FAISS 是 Facebook AI 开源的针对聚类和相似性搜索库,是当前使用较为广泛的一个框架,带有 Python / numpy 的完整封装,支持 c++ 与 python 调用。支持多种索引方式以及CPU和GPU计算,Faiss 支持多种向量检索方式,包括内积、欧氏距离等,同时支持精确检索与模糊搜索,并使用 GPU 来获得更高的内存带宽和计算吞吐量。但是Faiss本身只是一个能够单机运行的支持各种向量检索模型的机器学习算法基础库,不支持分布式实时索引和检索,同时也不支持标量字段的存储和索引等功能。项目地址: https://github.com/facebookresearch/faiss
-
Milvus:Milvus 是一款国产开源的、针对海量特征向量的相似性搜索引擎。它能够很好应对海量向量数据,集成了目前在向量相似性计算领域的几个开源库,并针对性做了定制,支持结构化查询、多模查询等业界比较急需的功能,并支持cpu、gpu、arm等多种类型的处理器,能够PC(16GB内存)上实现 1 亿级向量(数据来自SIFT1billion)的搜索。与FAISS相比,Milvus多平台通用,mac,windows和linux都是支持的,可以通过docker部署,在平台通用性上好了不少,并且支持Java,c,c++和python等多种编程语言。还提供了如何进行 Milvus 性能测评,搭建智能问答机器人、推荐系统、以图搜图系统、分子式检索系统。(性价比超高,目前大部分都在用与问答系统等领域检索数据)项目地址: Milvus | High-Performance Vector Database Built for Scale
-
SPTAG:SPTAG(空间分区树和图)是微软开源的BING搜索算法库,作为一种分布式近似最近邻域搜索(ANN)库,可用于大规模矢量搜索场景提供高质量矢量的索引构建,搜索和分布式在线服务。SPTAG内置L2 距离或余弦距离来计算向量之间的相似度,并提供KD-Tree 和相对邻域图(SPTAG-KDT)、以及平衡 k-means 树和相对邻域图(SPTAG-BKT)两种搜索算法。项目地址: https://github.com/microsoft/SPTAG
-
Vearch:Vearch 是由京东开源的一个分布式向量搜索系统,vearch 中的 Master,Router 和 PS 均采用 GO 语言编写。性能方面,核心的存储检索引擎 gamma 基于 faiss 采用 c++ 语言实现, 提供了快速的向量检索功能,以及类似 Elasticsearch 的 Restful API 可以方便地对数据及表结构进行管理查询等工作,Vearch 还提供了算法插件服务模块,通过选择默认的 VGG,Resnet 或自定义算法模型等,能够提供端到端的图像检索,视频流智能监控等业务应用场景的实现。项目地址: https://github.com/vearch/vearch
总结:
关于知识图谱的构建,调查发现,没有完全能保证全流程一体的功能,但可以根据开源的工具搭配使用;比如:前期的文本标注,实体识别,关系抽取等,可以利用Doccano和Chinese-Annotator,还支持团队协作,但人为标注的成本肯定大,如果实在不行就训练模型吧,pipeline和CasRel模型都可以;但paddlepaddle开源的label-studio,里面带有NER,关系抽取,事件抽取,实体/评价分类等模块供使用,可以一试,当然DeepKE也支持实体关系时间抽取三位一体;中文分词jieba比较好,看具体项目中需不需要用得到;实体对齐建议OpenEA,图计算选Pytorch,知识表示推理建议pykg2vec,图谱检索建议Faiss和Milvus,并且这两款数据库现在很流行应用于RAG里面,图谱存储建议Neo4j,性价比最高。
五、RAG
首先,传统RAG结合了信息检索和生成模型,通常是先使用检索模块从一个大型文档集合中找到相关信息,然后由生成模块生成自然语言结果,生成过程会参考检索到的文档。
-
优点:能够快速地从大量信息中找到相关内容,并通过生成模型给出流畅、自然的回答。
-
缺点:
-
缺乏复杂关系建模:传统RAG主要关注直接检索到的文档,而不擅长处理信息之间的复杂关系和网络结构。
-
上下文局限性:对于需要在不同资源之间进行深层次关联和推理的问题,以及总结概要,传统RAG可能表现不佳。
-
传统RAG在以下场景可能表现不好:
1.复杂推理:需要跨多个文档进行复杂信息推理
2.关系网络:信息间需要建立图结构关系才能解决
3.非线性关系:需要分析和理解多个条目之间的非线性关系师可能会受限
4.动态信息更新:信息网络频繁更新、必须实时分析变化,保持上下文准确性面临挑战
(1)GraphRAG
微软团队研发的GraphRag在传统的架构中引入了图结构,能更好的表达信息间的关系;通过使用知识图谱对文本中的实体和关系进行结构化建模,从而捕捉信息间的复杂关联。Graph首先在整个私有数据集上创建实体和关系引用,再采用自底向上的聚类方法,将数据层次化组织为语义簇。
项目开源地址:https://github.com/microsoft/graphrag
项目帮助文档:https://microsoft.github.io/graphrag/posts/get_started/
GraphRAG包括两个处理阶段,分别是:索引阶段和查询阶段。索引阶段利用LLM来自动化构建知识图谱,查询阶段汇总所有与之相关的社区摘要最后汇总生成答案。但是也有一定局限性,比如数据集中加入新知识时,它需要重新执行整个图构建流程,对于动态更新的数据集来说效率低成本高。
目前如果条件不允许使用GraphRAG,可以使用LlamaIndex+Neo4j+Langchain结合实现;LlamaIndex支持文档构建为知识图谱,Neo4j经上面的调研,是很好的图数据库存储实体关系的工具,而Langchain与RAG结合使用,就构建成了编排检索与生成流程。
(2)Haystack(开源可商用)
项目地址:https://github.com/deepset-ai/haystack
Haystack有模块化设计,包含文档检索、问答和文本摘要组件。支持多种文档存储解决方案,如 Elasticsearch、FAISS 和 SQL,在医疗、金融和客户支持等领域广泛用于构建问答系统和搜索引擎,具有简单的 API 和丰富的文档,非常用户友好,适合初学者和有经验的开发者。
适合对象:构建端到端问答和搜索系统的开发者、研究人员和组织。
文档检索:使用各种索引方法高效检索相关文档。
问答:利用预训练语言模型基于检索到的文档生成答案。
文本摘要:提供用于总结大型文档的工具。
社区支持:Haystack 拥有强大的社区和活跃的开发,确保不断改进和更新。
(3)RAGFlow(开源可商用)
项目地址:https://github.com/infiniflow/ragflow
官方Demo地址:RAGFlow,可以简单体验一下
RAGFlow具有简化的工作流程设计,配备了预构建组件,且能与向量数据库实现集成,应用于聊天机器人和即时问答系统等实时应用程序,用户友好且高效,降低了学习和开发时间,由于它简单性和有效性,越来越受欢迎,更新进度也挺频繁,目前已对接了硅基流动和DS-R1、DS-V3,目前很火爆。
适合对象:希望快速构建 RAG 应用程序的开发者和组织。
工作流程设计:具有直观的界面,可用于设计和配置 RAG 工作流程。
预配置工作流程:为常见场景提供即用型工作流程。
向量数据库集成:与向量数据库无缝集成,实现高效检索。
(4)LightRAG
项目地址:https://github.com/HKUDS/LightRAG
是港大Data Lab提出一种基于知识图谱结构的RAG方案,相比GraphRAG具有更快更经济的特点。
适用对象:基于图的索引,并且包含双层检索框架
知识检索:查询时,仅适用于索引相同的LLM从文本块中检索实体和关系
新知识录入:无缝接入,可快速整合到现有图谱中,经济便捷
(5)txtai
项目地址:https://github.com/neuml/txtai
TxTai是一个用于语义搜索、语言模型工作流程和文档处理管道的一体化平台,用于客户服务、内容推荐和数据分析等领域,高度集成且易于使用,适用于小型和大型项目,官网还提供详细的文档和示例,帮助用户快速上手。
适合对象:需要为多个 AI 任务提供综合解决方案的组织。
语义搜索:使用嵌入式数据库进行高效的相似性搜索。
语言模型工作流程:易于与各种语言模型和 AI 服务集成。
文档处理:支持多语言和多格式数据。
(6)FlashRAG(开源可商用)
项目地址:https://github.com/RUC-NLPIR/FlashRAG
中国人民大学开发的轻量级且高效的 RAG 框架,针对推理速度进行了优化,采用了各种加速技术,降低推理延迟的同时不影响准确性,与流行的语言模型和向量存储系统集成。
适合对象:需要实时 RAG 应用程序的开发者和组织。
多种检索模型:支持多种检索模型。
优化的重排序器:用于改进文档排名的算法。
高效生成器:高性能生成模型。
(7)STORM
项目地址:https://github.com/stanford-oval/storm
斯坦福开源 RAG 框架,专注于高效的检索机制和生成过程,提升检索机制的准确率和效率,适用于学术研究,附带详细的文档和研究论文。
适合对象:需要快速、准确的文本检索和响应生成的开发者和组织。
高度可配置的检索:支持多种检索策略和嵌入模型。
优化的生成:与生成模型灵活集成,以提高响应质量。
(8)LLM-app
项目地址:https://github.com/pathwaycom/llm-app
LLM-app是一个用于文档解析、索引、检索和响应生成的综合工具链,用于法律、医疗和客户服务等领域构建问答系统和搜索引擎较多,即用型Docker容器,支持快速部署,动态数据源的实时更新,用户友好,有详细的文档和示例,方便设置和使用。
适合对象:使用大型语言模型构建 RAG 应用程序的企业和开发者。
文档解析:提供解析和预处理文档的工具。
索引:支持多种文档存储解决方案。
检索和生成:集成了高效检索和高质量响应生成模块。
总结:
知识图谱与RAG相辅相成,在当前大模型技术火热阶段,利用大模型再将知识图谱与RAG结合增强了检索知识时大模型的输出幻觉问题,并且他们都适合做垂直领域的信息检索,无论是基于知识图谱搭建问答系统,还是构建RAG的问答系统,前期一定要制定好工作流,可以利用dify,coze等低代码平台简单搭建demo,具体流程看似简单,但是聚焦到每一模块都很耗时,前期数据处理就很浪费时间,后期模型训练,参数调整,指标提升都有着巨大考量,需投入大量精力和成本;这里找到一篇基于deepseek+ragflowde的问答系统教程https://juejin.cn/post/7477105518039121971,还有关于知识图谱自动构建的两个基于大模型的知识图谱自动构建开源工具:兼看AutoKG轻量化关键词KG构建和混合增强问答思路 - 53AI-AI知识库|大模型知识库|大模型训练|智能体开发

















 2699
2699

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









