







VGG网络结构
VGG网络(Visual Geometry Group Network)是一种经典的深度学习卷积神经网络(CNN)架构,由牛津大学的视觉几何组(Visual Geometry Group)在2014年提出。VGG网络在ImageNet挑战赛2014中取得了优异的成绩,因此受到了广泛的关注和应用。本文的结构与常规不同,关于其内部结构详解参考:https://zhuanlan.zhihu.com/p/69281173
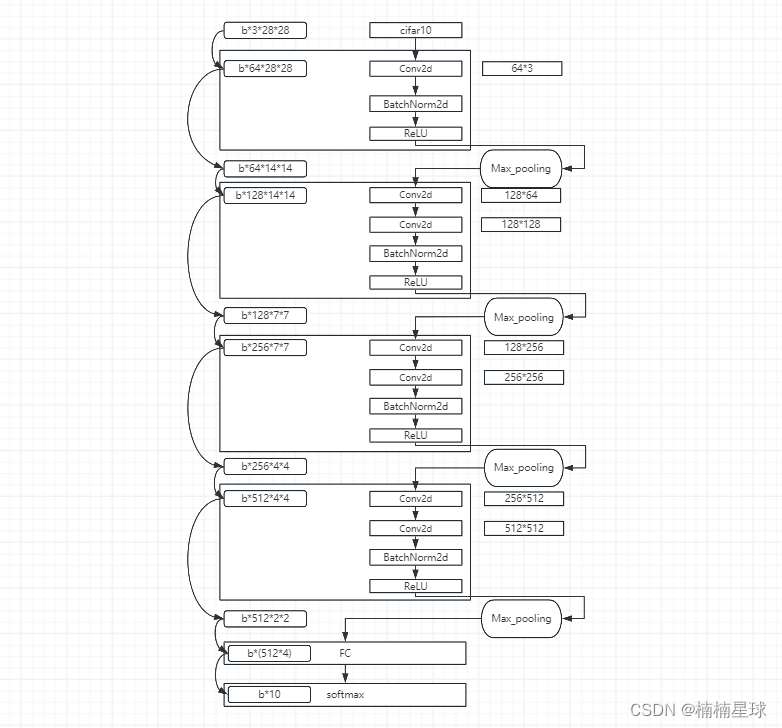
代码详细解释
#!/usr/bin/env python
# -*- coding:utf-8 -*-
"""
@author: LF
@time: 2024/5/9 10:41
@file: GetVGGnet.py
@project: pythonProject
@describe: TEXT
@# ------------------------------------------(one)--------------------------------------
@# ------------------------------------------(two)--------------------------------------
"""
import torch.nn as nn
import torch.nn.functional as F
class GetVGGnet(nn.Module): #定义一个继承nn.Module的类
# nn.Module是torch中搭建网络的基础类
# ------------------------------------------( 初始函数定义网络)--------------------------------------
def __int__(self): #网络搭建过程
super(GetVGGnet,self).__int__() #对GetVGGnet进行初始化
# ------------------------------------------(第一个卷积层:一次卷积操作)--------------------------------------
# ------------------------------------------[输入cifar10的数据大小为3*28*28]--------------------------------------
self.conv_1 = nn.Sequential(
# 上面的nn.Sequential为序列(顺序)容器,搭建网络时会按照里面的顺序进行
# in_channels表示输入的通道数或者叫深度,由于cifar10数据集是RGB格式,因此通道数是3
# out_channels表示输出的通道数,VGGnet第一次输出的通道数为64,这与网络结构有关
# kernel_size表示卷积时的卷积核(卷积窗口)的边长,VGGnet的卷积核大小为3*3
# stride表示卷积核移动时的步长,这里默认为1
# padding表示图像边缘填充,根据公式28-->28+2=30-->30-3+1= 28,加入之后图像的尺寸不变,此处有个坑,就是网络上说
# padding=1是在图像边缘填充了一圈0,所以在这里触发了“SAME”属性(也就是图像输入输出的大小不变)
# 这里说一下总结:如果卷积核边长为n,则padding = n//2,此时3奇数卷积的padding = 1,4偶数卷积为2即可保证输入输出不变
nn.Conv2d(3,64,kernel_size=3,stride=1,padding=1),
# 添加BatchNorm2d进行数据的归一化处理,这使得数据在进行Relu之前不会因为数据过大而导致网络性能的不稳定,64表示特征的数量
nn.BatchNorm2d(64),
# 激活层(relu函数)也可以采用Sigmoid激活函数,Tanh激活函数,目的是增强对网络的输出的表达能力
nn.ReLU()
)
# ------------------------------------------ [上一步输出以及下一步的输入数据大小为batchsize*64*28*28]]--------------------------------------
# ------------------------------------------(第一个最大池化层)--------------------------------------
# kernel_size表示最大池化时的卷积核大小,每次卷积时取2*2大小窗口中的像素最大值
# stride表示最大池化的步长,与卷积时不同,这里的最大池化,每一个卷积核里面的像素不相关
self.Max_pooling_1 = nn.MaxPool2d(kernel_size=2,stride=2)
# ------------------------------------------ [上一步输出以及下一步的输入数据大小为batchsize*64*14*14]--------------------------------------
# ------------------------------------------(第二个卷积层)--------------------------------------
self.conv_2_1 = nn.Sequential(
# 14-->14+2-->16-3+1 = 14
nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(128),
nn.ReLU()
)
self.conv_2_2 = nn.Sequential(
# 14-->14+2-->16-3+1 = 14
nn.Conv2d(128, 128, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(128),
nn.ReLU()
)
# ------------------------------------------ [上一步输出以及下一步的输入数据大小为batchsize*128*14*14]--------------------------------------
# ------------------------------------------(第二个最大池化层)--------------------------------------
self.Max_pooling_2 = nn.MaxPool2d(kernel_size=2, stride=2)
# ------------------------------------------ [上一步输出以及下一步的输入数据大小为batchsize*128*7*7]--------------------------------------
# ------------------------------------------(第三个卷积层)--------------------------------------
self.conv_3_1 = nn.Sequential(
# 7-->7+2-->9-3+1=7
nn.Conv2d(128, 256, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(256),
nn.ReLU()
)
self.conv_3_2 = nn.Sequential(
# 7-->7+2-->9-3+1=7
nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(256),
nn.ReLU()
)
# ------------------------------------------ [上一步输出以及下一步的输入数据大小为batchsize*256*7*7]--------------------------------------
# ------------------------------------------(第三个最大池化层)--------------------------------------
# 注意此处的最大池化与前几个不同,因为前一个卷积后的结果长宽是7*7,所以加入padding之后就是8*8,这样最大池化输出为4*4
self.Max_pooling_3 = nn.MaxPool2d(kernel_size=2, stride=2,padding=1)
# ------------------------------------------ [上一步输出以及下一步的输入数据大小为batchsize*256*4*4]--------------------------------------
# ------------------------------------------(第四个卷积层)--------------------------------------
self.conv_4_1 = nn.Sequential(
# 4-->4+2-->6-3+1=4
nn.Conv2d(256, 512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(512),
nn.ReLU()
)
self.conv_4_2 = nn.Sequential(
# 4-->4+2-->6-3+1=4
nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(512),
nn.ReLU()
)
# ------------------------------------------ [上一步输出以及下一步的输入数据大小为batchsize*512*4*4]--------------------------------------
# ------------------------------------------(第四个最大池化层)--------------------------------------
self.Max_pooling_4 = nn.MaxPool2d(kernel_size=2, stride=2)
# ------------------------------------------ [上一步输出以及下一步的输入数据大小为batchsize*512*2*2]--------------------------------------
# ------------------------------------------(全连接层)--------------------------------------
# 在进行全连接之前,需要将输入张量转换转换一下维度:batchsize * 512 * 2 * 2 - --->batchsize * (512 * 4)
# 全连接层 in_features表示输入张量大小,out_features表示输出张量大小(你现在做的项目预测输出的种类)
self.fc = nn.Linear(in_features=512*4,out_features=10)
# ------------------------------------------( 对网络的输出进行处理)--------------------------------------
def forward(self, x): #自定义类函数,用于处理张量或者叫网络运行过程
out = self.conv_1(x)
out = self.Max_pooling_1(out)
out = self.conv_2_1(out)
out = self.conv_2_2(out)
out = self.Max_pooling_2(out)
out = self.conv_3_1(out)
out = self.conv_3_2(out)
out = self.Max_pooling_3(out)
out = self.conv_4_1(out)
out = self.conv_4_2(out)
out = self.Max_pooling_4(out)
# 下面的batchsize表示每次迭代需要使用的数据量
# x就是我们将图像转换为张量的结果,关于这一步的处理过程,请参考博客(https://blog.csdn.net/qq_55750626/article/details/138585829?spm=1001.2014.3001.5501)
# x.size(0) 这一步的意思是先获取tensor张量的大小,第一个值就是我们张量数据的大小,这里直接一次将数据全部喂入网络
batchsize = x.size(0)
# 将out转换维度,用于fc,注意fc的in_features参数大小为512*4
out = out.view(batchsize,-1)
# 全连接处理
out = self.fc(out)
# 直接用torch中的softmax概率分布函数处理,将预测值out(batchsize*10)转化为预测正确类的概率
out = F.log_softmax(out,dim=1)
return out















 307
307











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











