







目录
查询
(1)数据准备
dept.txt
10 ACCOUNTING 1700
20 RESEARCH 1800
30 SALES 1900
40 OPERATIONS 1700emp.txt
7369 SMITH CLERK 7902 1980-12-17 800.00 20
7499 ALLEN SALESMAN 7698 1981-2-20 1600.00 300.00 30
7521 WARD SALESMAN 7698 1981-2-22 1250.00 500.00 30
7566 JONES MANAGER 7839 1981-4-2 2975.00 20
7654 MARTIN SALESMAN 7698 1981-9-28 1250.00 1400.00 30
7698 BLAKE MANAGER 7839 1981-5-1 2850.00 30
7782 CLARK MANAGER 7839 1981-6-9 2450.00 10
7788 SCOTT ANALYST 7566 1987-4-19 3000.00 20
7839 KING PRESIDENT 1981-11-17 5000.00 10
7844 TURNER SALESMAN 7698 1981-9-8 1500.00 0.00 30
7876 ADAMS CLERK 7788 1987-5-23 1100.00 20
7900 JAMES CLERK 7698 1981-12-3 950.00 30
7902 FORD ANALYST 7566 1981-12-3 3000.00 20
7934 MILLER CLERK 7782 1982-1-23 1300.00 10(2)建表
dept
create table if not exists dept(
deptno int,
dname string,
loc int)
row format delimited fields terminated by ' ';emp
create table if not exists emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int)
row format delimited fields terminated by ' ';(3)导入数据
#dept
load data local inpath '/root/datas/dept.txt' into table dept;
#emp
load data local inpath '/root/datas/emp.txt' into table emp;Join语句
等值Join
hive支持通常的SQL JOIN语句。
例子:根据员工表和部门表中的部门编号相等,查询员工编号、员工名称和部门名称
select e.empno, e.ename, d.deptno, d.dname from emp e
join dept d on e.deptno = d.deptno;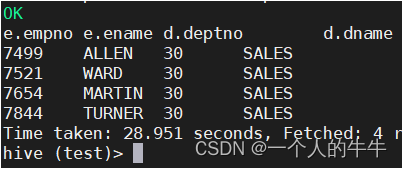
表的别名
使用别名可以简化查询;使用表名前缀可以提高执行效率。
select e.empno, e.ename, d.deptno, d.dname
from emp e join dept d on e.deptno = d.deptno;内连接
进行连接的两个表中都存在与连接条件相匹配的数据。
select e.empno, e.ename, d.deptno from emp e join dept d
on e.deptno = d.deptno;左外连接
JOIN操作符左边表中符合WHERE子句的所有记录会被返回。
select e.empno, e.ename, d.deptno from emp e left join dept d
on e.deptno = d.deptno; 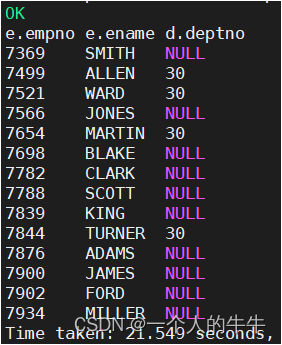
右外连接
JOIN操作符右边表中符合WHERE子句的所有记录会被返回。
select e.empno, e.ename, d.deptno from emp e right join dept d
on e.deptno = d.deptno;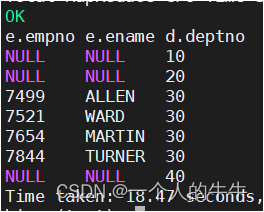
满外连接
返回所有表中符合WHERE语句条件的所有记录。如果任一表的指定字段没有符合条件的值,就使用NULL值替代。
select e.empno, e.ename, d.deptno from emp e full join dept d
on e.deptno = d.deptno;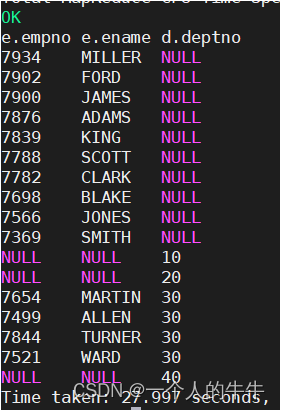
多表连接
(1)准备数据
location.txt
1700 Beijing
1800 London
1900 Tokyo(2)建表
create table if not exists location(
loc int,
loc_name string)
row format delimited fields terminated by ' ';
(3)加载数据
load data local inpath '/root/datas/location.txt' into table location;(4)多表连接
select e.ename,d.dname,l.loc_name from emp e join dept d on d.deptno=e.deptno
join location l on d.loc=l.loc;
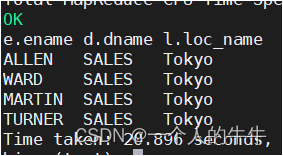
注:连接n个表,至少需要n-1个连接条件;
例如:连接三个表,至少需要两个连接条件。
大多数情况下,Hive会对每对JOIN连接对象启动一个MapReduce任务。
Hive总是从左到右顺序执行,第一个MapReduce job对表e和表d进行连接操作,再启动一个MapReduce job将表d和表l进行连接操作。
优化:当对3个或者更多表进行join连接时,如果每个on子句都使用相同的连接键的,那么只会产生一个MapReduce job。
笛卡尔集
(1)笛卡尔集会在下面条件下产生:
1)省略连接条件;
2)连接条件无效;
3)所有表中的所有行互相连接;
例子:
select empno,dname from emp,dept;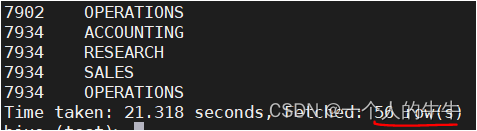
排序
全局排序
order by:全局排序,只有一个reducer;
ASC(ascend):升序(默认);
DESC(descend):降序;
order by子句在select语句结尾。
例子:
查询员工信息(按工资升序排序)
select * from emp order by sal;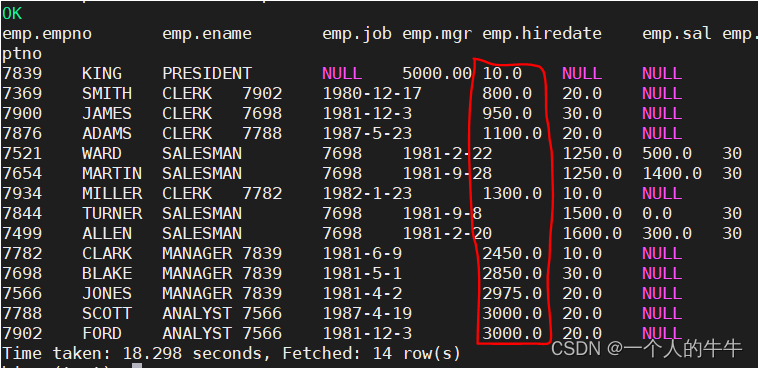
查询员工信息(按工资降序排序)
select * from emp order by sal desc;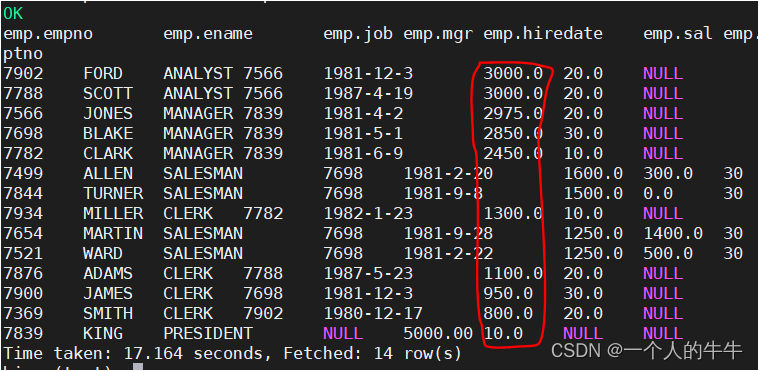
按照别名排序
例子:按照工资2倍排序
select ename,sal*2 twosal from emp order by twosal;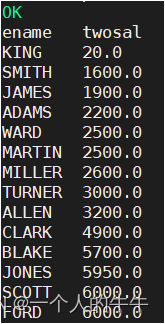
多个列排序
例子:按照部门和工资升序排序
select ename,deptno,sal from emp order by deptno,sal;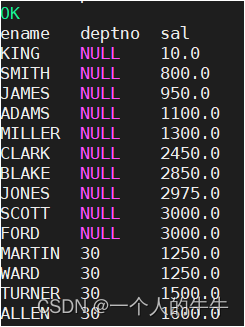
reduce内部排序(sort by)
对于大规模的数据集order by的效率较低,不需要全局排序;
sort by:为每一个reducer产生一个排序文件,每个reducer内部进行排序,对全局结果集来说不是排序。
#设置reduce个数
set mapreduce.job.reduces=3;
#查看设置reduce个数
set mapreduce.job.reduces;
#根据部门编号降序查看员工信息
select * from emp sort by deptno desc;
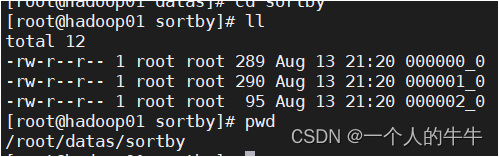
#将查询结果导入到文件中(按照部门编号降序排序)
insert overwrite local directory '/root/datas/sortby'
select * from emp sort by deptno desc; 
分区(distribute by)
(1)distribute by类似MR的自定义分区(partition)进行分区,结合sort by使用;
(2)测试distribute by要分配多个reducer进行处理,不然无法看到distribute by的效果;
例子:先按照部门号进行分区,再按照员工编号降序排序
select * from emp distribute by deptno sort by empno desc;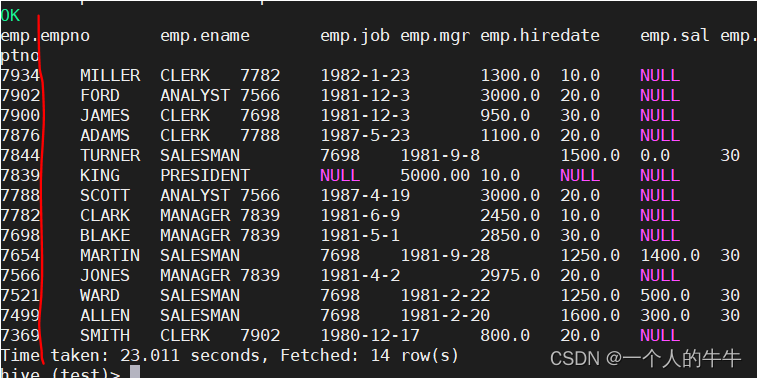
注:
distribute by的分区规则是根据分区字段的hash码与reduce的个数进行模除后,余数相同的分到一个区。
hive要求distribute by语句要写在sort by语句之前。
cluster by
cluster by:具有distribute by和sort by的功能。但是排序只能是升序排序。
select * from emp cluster by deptno;
select * from emp distribute by deptno sort by deptno;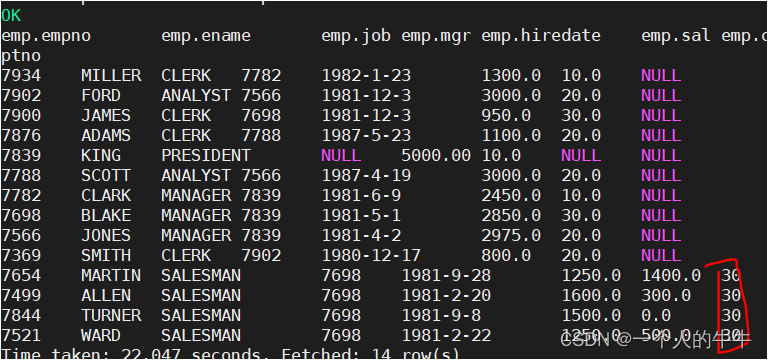
本文仅仅是学习笔记!!!















 818
818











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









