



链表的原理与应用
大家可以知道对于顺序表的数据增加和删除是比较麻烦,因为都需要移动一片连续的内存。
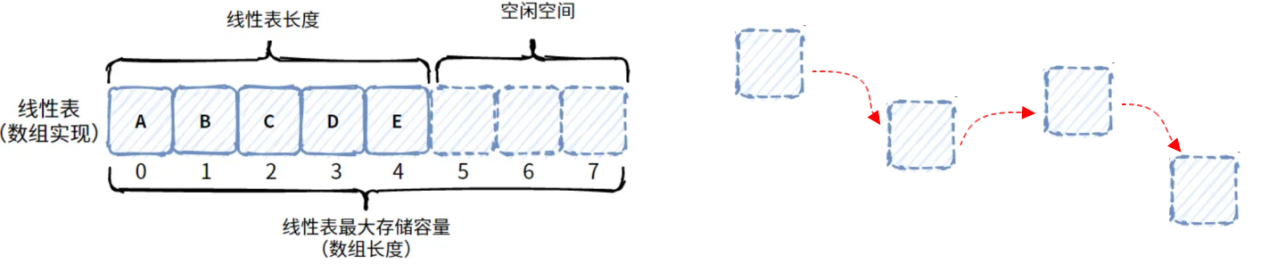
顺序表的优点是:由于顺序表数据元素的内存地址都是连续的,所以可以实现随机访问,而且不需要多余的信息来描述相关的数据,所以存储密度高。
顺序表的缺点是:顺序表的数据在进行增删的时候,需要移动成片的内存,另外,当数据元素的数量较多的时候,需要申请一块较大的连续的内存,同时当数据元素的数量的改变比较剧烈,顺序表不灵活。
思考:既然顺序表实现数据的增加和删除比较麻烦,又占用连续内存,请问有没有更好方案?
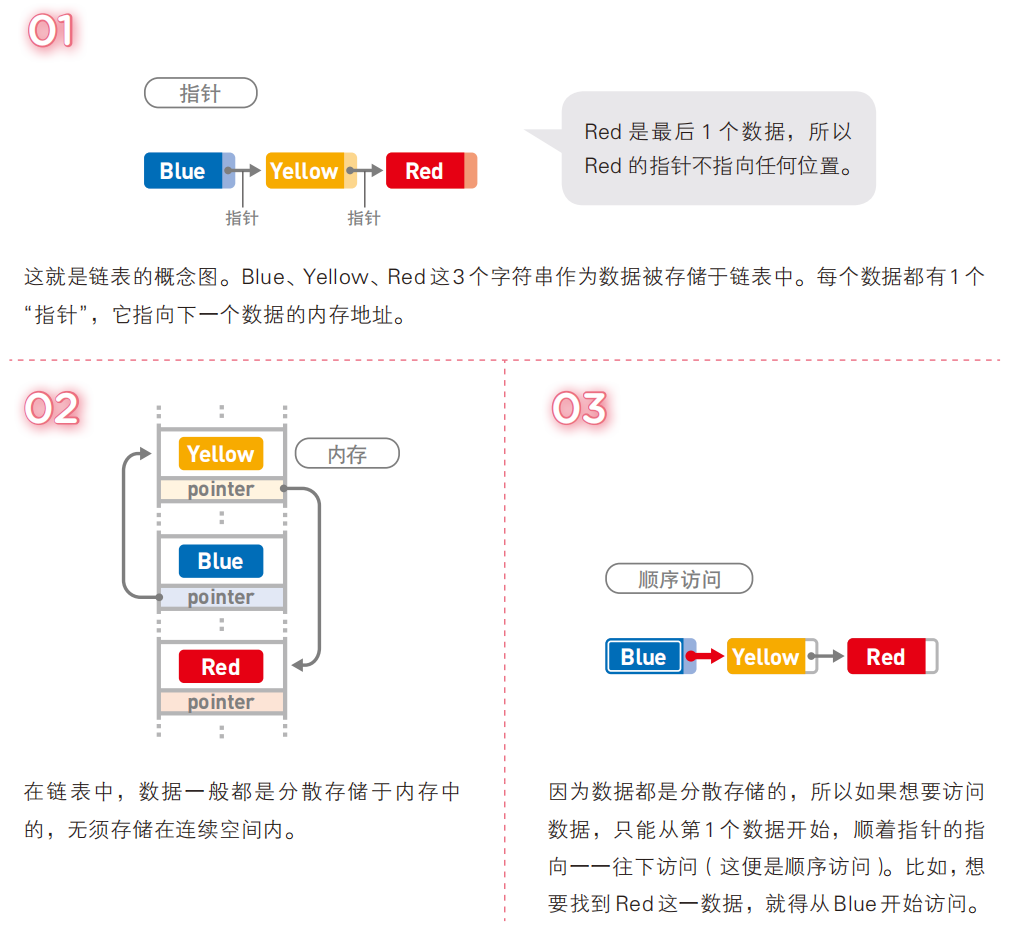
回答:有的兄弟,有的,可以利用链式存储的线性表实现,链式存储指的是采用离散的内存单元来存储数据元素,用户需要使用某种方式把所有的数据元素连接起来,这样就可以变为链式线性表,简称为链表,链表可以高效的使用碎片化内存。
可以看到,顺序表和链式表的区别:顺序表使用连续的内存,链式表使用离散的内存空间。
思考:既然链表中的每个数据元素的地址都是不固定的,请问用户如何访问某个元素呢???
回答:由于链表中的每个数据元素的地址是不固定的,所以每个数据元素都应该使用一个指针指向直接后继的内存地址,当然最后一个数据元素没有直接后继,所以最后一个数据元素指向NULL即可,作为用户只需要知道第一个数据元素的内存地址,就可以访问后继元素了。
注意:如果采用链式存储,则线性表中每一个数据元素除了存储自身数据之外,还需要额外存储直接后继的地址,所以链表中的每一个数据元素都是由两部分组成:存储自身数据的部分被称为数据域,存储直接后继地址的部分被称为指针域,数据域和指针域组成的数据元素被称为结点(Node)。
注意:链表的工作原理其实很简单,只要大家搞清楚链表的使用流程就可以很轻松的理解,链表具体的操作步骤如下所示:
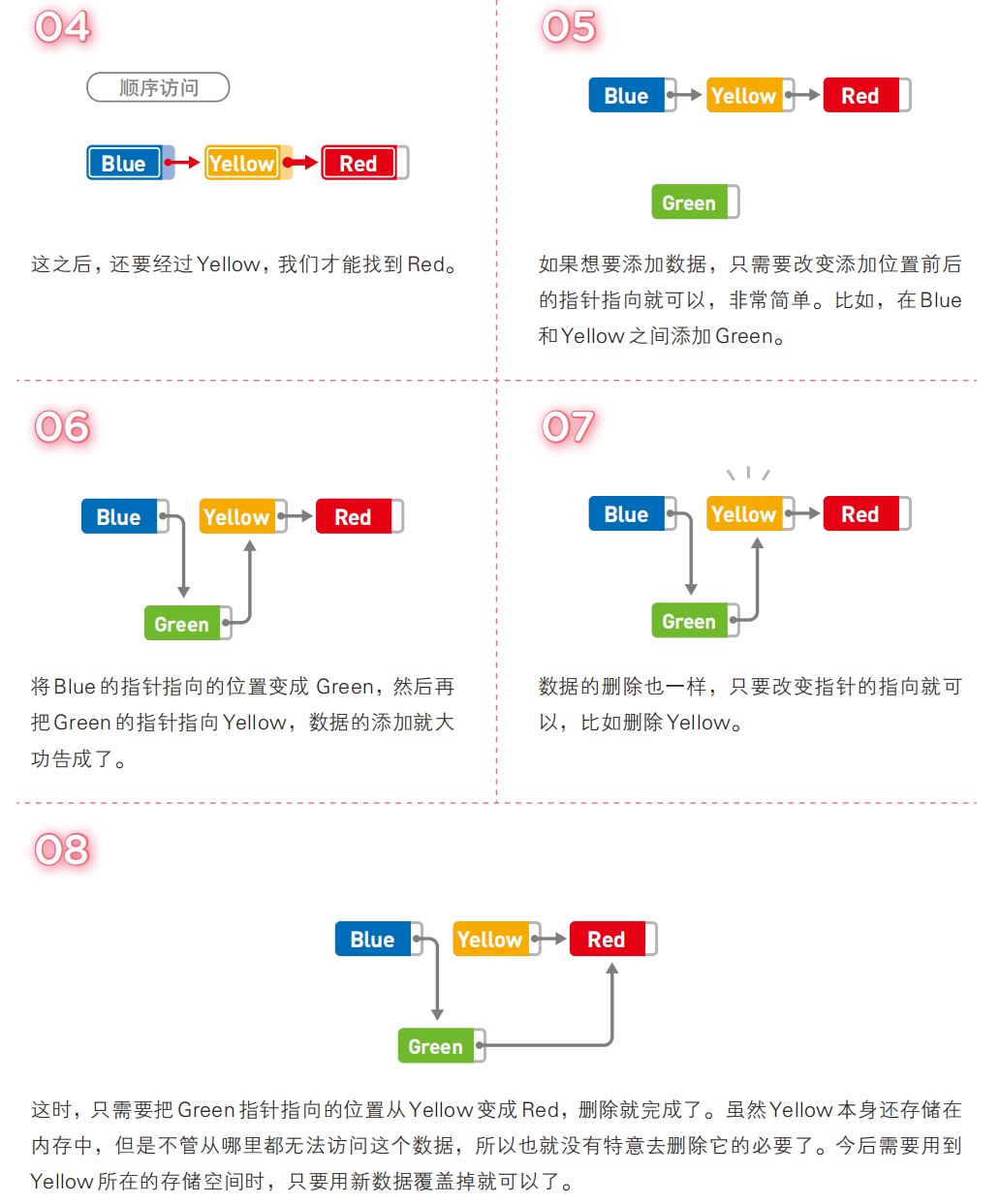
根据链表的结点的指针域的数量以及根据链表的首尾是否相连,把链式线性表分为以下几种:单向链表、单向循环链表、双向链表、双向循环链表、内核链表。这几种链表的使用规则差不多,只不过指针域数量不同。


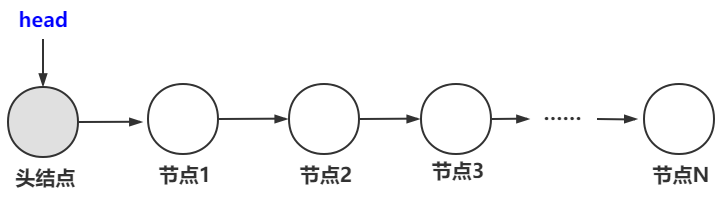
上图就是最简单的单向链表的内部结构,可以看到每一个结点都保存了一个地址,每个地址都是逻辑上相邻的下一个结点的地址,只不过末尾结点的指针指向NULL。
另外注意:可以看到链表中是有一个头指针的,头指针只指向第一个元素的地址,想要访问链表中的某个元素只需要通过头指针即可。
思考:使用顺序表的时候需要创建一个管理结构体来管理顺序表,请问链表需不需要创建???
回答:可以根据用户的需要来选择,一般把链表分为两种:一种是不带头结点的链表,一种是带头结点的链表,头结点指的是管理结构体,只不过头结点只存储第一个元素的内存地址,头结点并不存储有效数据,头结点的意义只是为了方便管理链表。
不带头结点的链表
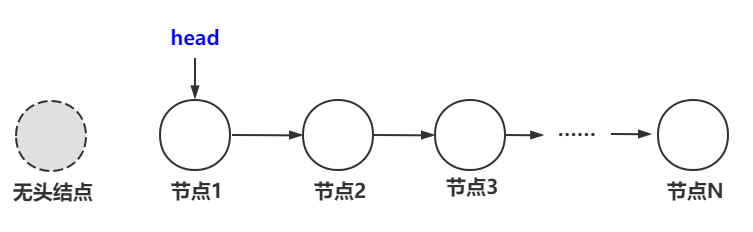
附带头结点的链表
可以知道,头指针是必须的,因为通过头指针才可以访问链表的元素,头结点是可选的,只是为了方便管理链表而已。
注意:在链表中,还有两个专业名称,一个是首结点,一个是尾结点,三者之前的区别如下:
头结点:是不存储有效数据的,只存储第一个数据元素的地址,头指针只指向头结点。
首结点:是存储有效数据的,也存储直接后继的内存地址,首结点就是第一个结点,首结点是唯一一个只指向别的结点,不被别的结点指向的结点。
尾结点:是存储有效数据的,尾结点就是链表的最后一个结点,所以尾结点中存储的地址一般指向NULL,尾结点是唯一一个只被别的结点指向,不能指向别的结点的结点。
为了方便管理单向链表,所以需要构造头结点的数据类型以及构造有效结点的数据类型,如下:
//指的是单向链表中的结点有效数据类型,用户可以根据需要进行修改
typedef int DataType_t;
//构造链表的结点,链表中所有结点的数据类型应该是相同的
typedef struct LinkedList
{
DataType_t data; //结点的数据域
struct LinkedList *next; //结点的指针域
}LList_t;
创建一个空链表,由于是使用头结点,所以就需要申请头结点的堆内存并初始化即可。
//创建一个空链表,空链表应该有一个头结点,对链表进行初始化
LList_t * LList_Create(void)
{
//1.创建一个头结点并对头结点申请内存
LList_t *Head = (LList_t *)calloc(1,sizeof(LList_t));
if (NULL == Head)
{
perror("Calloc memory for Head is Failed");
exit(-1);
}
//2.对头结点进行初始化,头结点是不存储有效内容的!!!
Head->next = NULL;
//3.把头结点的地址返回即可
return Head;
}
创建一个新结点,并为新结点申请堆内存以及对新结点的数据域和指针域进行初始化。
//创建新的结点,并对新结点进行初始化(数据域 + 指针域)
LList_t * LList_NewNode(DataType_t data)
{
//1.创建一个新结点并对新结点申请内存
LList_t *New = (LList_t *)calloc(1,sizeof(LList_t));
if (NULL == New)
{
perror("Calloc memory for NewNode is Failed");
return NULL;
}
//2.对新结点的数据域和指针域进行初始化
New->data = data;
New->next = NULL;
return New;
}
根据情况把新结点插入到链表中,此时可以分为尾部插入、头部插入、指定位置插入。
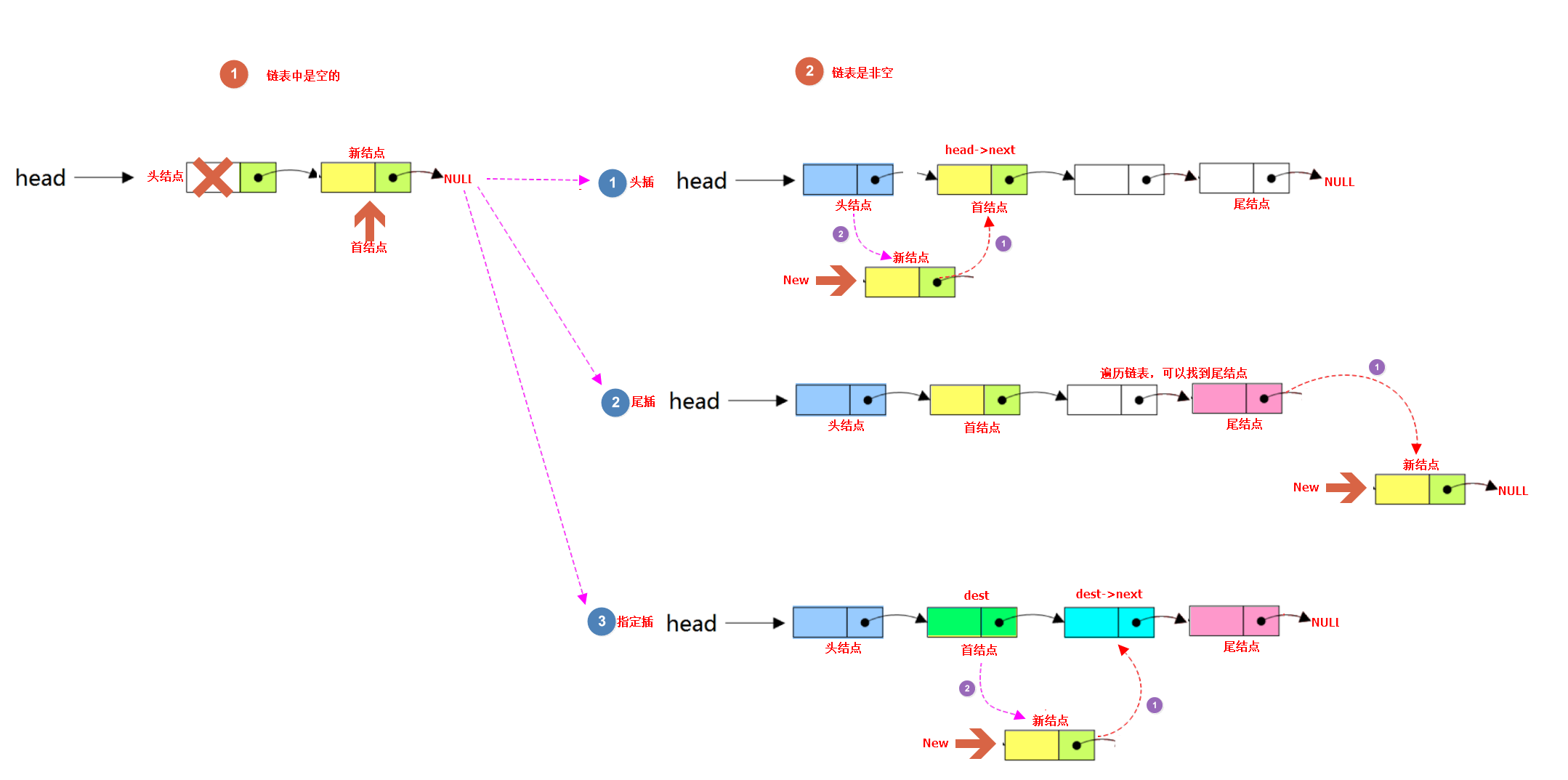
//头插
bool LList_HeadInsert(LList_t *Head,DataType_t data)
{
//1.创建新的结点,并对新结点进行初始化
LList_t *New = LList_NewNode(data);
if (NULL == New)
{
printf("can not insert new node\n");
return false;
}
//2.判断链表是否为空,如果为空,则直接插入即可
if (NULL == Head->next)
{
Head->next = New;
return true;
}
//3.如果链表为非空,则把新结点插入到链表的头部
New->next = Head->next;
Head->next = New;
return true;
}
//尾插
bool LList_TailInsert(LList_t *Head, DataType_t data)
{
LList_t *Phead = Head;
//1.创建新的结点,并对新结点进行初始化
LList_t *New = LList_NewNode(data);
if (NULL == New) {
printf("can not insert new node\n");
return false;
}
//2.判断链表是否为空,如果为空,则直接插入即可
if (NULL == Head->next) {
Head->next = New;
return true;
}
//3.如果链表为非空,则把新结点插入到链表的尾部
while (Phead->next) {
Phead = Phead->next;
}
Phead->next = New;
return true;
}
//指定位置插入
bool LList_DestInsert(LList_t *Head, DataType_t destval, DataType_t data) {
LList_t *Phead = Head;
//1.创建新的结点,并对新结点进行初始化
LList_t *New = LList_NewNode(data);
if (NULL == New) {
printf("can not insert new node\n");
return false;
}
//2.判断链表是否为空,如果为空,则直接返回false,因为不存在目标节点
if (NULL == Head->next) {
return false;
}
//3.遍历链表,目的是找到目标结点,比较结点的数据域
while (Phead->next != NULL && destval != Phead->next->data) {
Phead = Phead->next;
}
if (Phead->next == NULL) {
return false;
}
//4.说明找到目标结点,则把新结点加入到目标的前面
New->next = Phead->next;
Phead->next = New;
return true;
}
根据情况可以从链表中删除某结点,此时可以分为尾部删除、头部删除、指定元素删除。
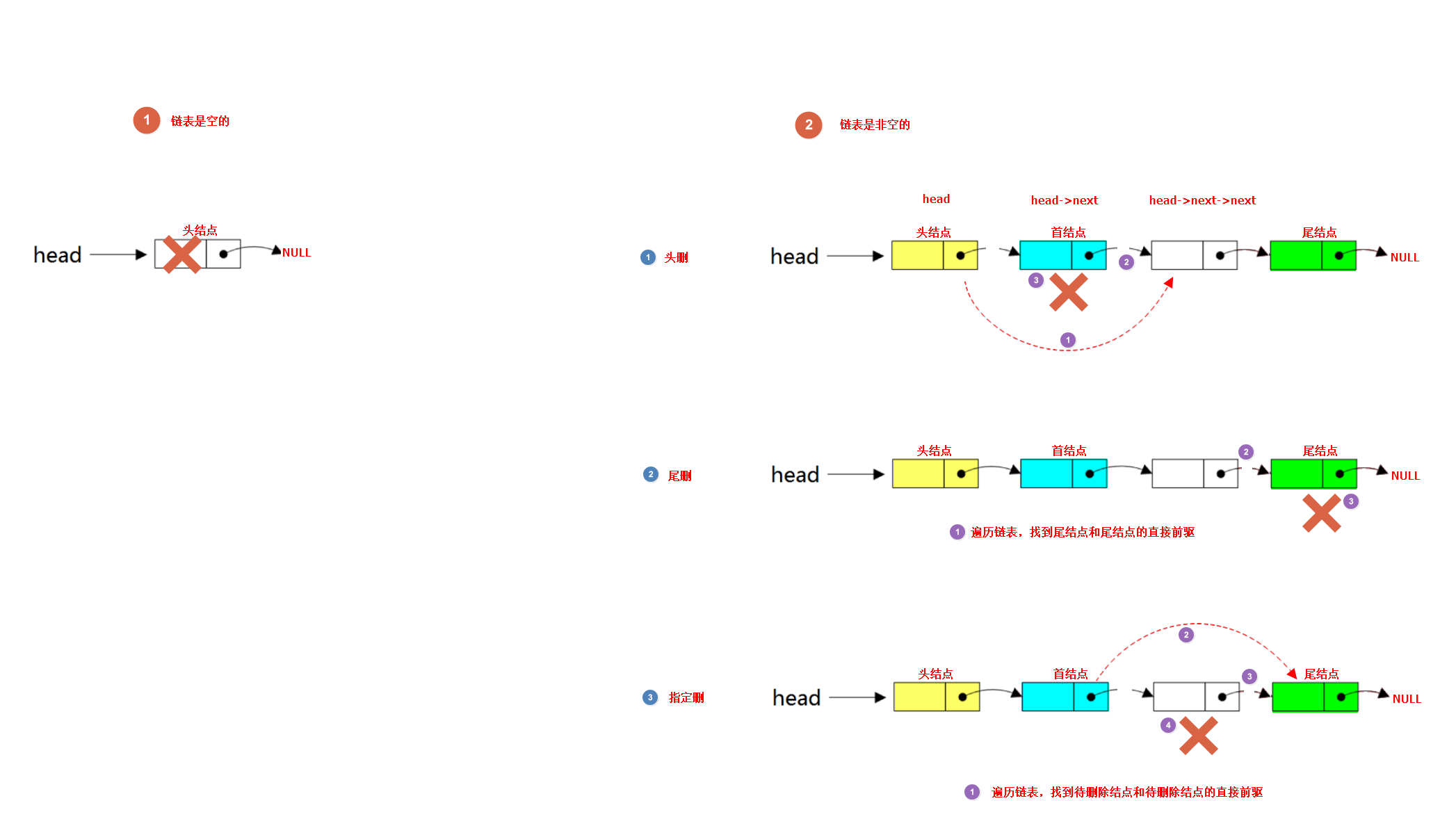
//头删
bool LList_HeadDel(LList_t *Head) {
//对链表的头指针进行备份
LList_t *Phead = Head;
//2.判断链表是否为空,如果为空,则直接退出
if (NULL == Head->next) {
return false;
}
//3.链表非空,则直接删除首结点
LList_t *temp = Phead->next; // 保存要删除的首结点
Phead->next = temp->next; // 调整头指针指向首结点的下一个结点
free(temp); // 释放首结点内存
return true;
}

B

D

B

void LList_DelMin(LList_t * Head) {
// 检查头指针是否为空
if (Head == NULL) {
return;
}
LList_t *min_prev = Head; // 记录最小值结点的直接前驱地址,初始化为头节点
LList_t *min = Head->next; // 记录最小值结点的地址
LList_t *phead = Head->next; // 记录当前结点的地址
LList_t *phead_prev = Head; // 记录当前结点的直接前驱地址
// 1. 遍历链表,目的是找到最小值结点
while (phead) {
// 比较链表中结点的数据域的大小
if (min == NULL || min->data > phead->data) {
min = phead;
min_prev = phead_prev;
}
phead_prev = phead;
phead = phead->next;
}
// 2. 删除当前的最小值结点,前提是让最小值结点的直接前驱指向最小值结点的直接后继
if (min_prev != NULL && min != NULL) {
min_prev->next = min->next;
// 3. 释放最小值结点的内存
free(min);
}
}

(1)算法基本设计思想
利用双指针法。设置两个指针,一个快指针和一个慢指针。快指针先向前移动 k 步,然后快指针和慢指针同时移动,当快指针到达链表末尾时,慢指针所指向的位置就是链表倒数第 k 个位置的结点。这样只需要遍历一次链表,时间复杂度为 O(n),满足尽可能高效的要求。
(2)算法详细实现步骤
-
检查头指针
head是否为空,如果为空,直接返回0,表示查找失败。 -
初始化快指针
fast和慢指针slow,都指向头结点的下一个结点(即链表第一个有效结点)。 -
让快指针
fast先向前移动k步。在移动过程中,如果fast指针移动到NULL,说明链表长度小于k,返回0,表示查找失败。 -
当快指针
fast移动了k步后,同时移动快指针fast和慢指针slow,每次移动一步,直到快指针fast指向链表末尾(即fast->next == NULL)。 -
此时慢指针
slow所指向的结点就是链表倒数第k个位置的结点,输出该结点的data值,并返回1,表示查找成功。
#include <stdio.h>
#include <stdlib.h>
// 定义链表结点结构
typedef struct Node {
int data;
struct Node *next;
} Node;
// 查找链表中倒数第k个位置的结点
int findKthFromEnd(Node *head, int k) {
// 检查头指针是否为空
if (head == NULL) {
return 0;
}
Node *fast = head->next;
Node *slow = head->next;
// 快指针先移动k步
int i;
for (i = 0; i < k; i++) {
// 如果快指针移动到NULL,说明链表长度小于k
if (fast == NULL) {
return 0;
}
fast = fast->next;
}
// 快指针和慢指针同时移动,直到快指针到达链表末尾
while (fast != NULL) {
fast = fast->next;
slow = slow->next;
}
// 输出慢指针所指结点的data值,并返回1表示查找成功
printf("%d\n", slow->data);
return 1;
}

















 319
319

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









