








目录
🌟我的其他文章也讲解的比较有趣😁,如果喜欢博主的讲解方式,可以多多支持一下,感谢🤗!
其他优质专栏: 【🎇SpringBoot】【🎉多线程】【🎨Redis】【✨设计模式专栏(已完结)】…等
如果喜欢作者的讲解方式,可以点赞收藏加关注,你的支持就是我的动力
✨更多文章请看个人主页: 码熔burning
看之前可以先了解一下MongoDB是什么:【MongoDB篇】万字带你初识MongoDB!
引言
嘿!各位csdn的大佬们!👋 咱们已经一起探索了 MongoDB 的数据基本操作(CRUD)、性能加速器(索引)、数据分析引擎(聚合框架)和一致性保障(事务)。这些都是单节点 MongoDB 的强大之处。
了解数据库操作请看:【MongoDB篇】MongoDB的数据库操作!
了解集合操作请看:【MongoDB篇】MongoDB的集合操作!
了解文档操作请看:【MongoDB篇】MongoDB的文档操作!
了解索引操作请看:【MongoDB篇】MongoDB的索引操作!
了解聚合操作请看:【MongoDB篇】MongoDB的聚合框架!
了解事务操作请看:【MongoDB篇】MongoDB的事务操作!
但是,作为一名负责任的程序员,我们必须正视一个残酷的现实:单点故障 (Single Point of Failure - SPOF) 的风险!💥
你的 MongoDB 数据库运行在一台服务器上?好,如果这台服务器的硬盘坏了、电源炸了、网线断了,甚至机房停电、着火了呢?😭 你的数据库是不是就访问不了了?你的应用是不是就“趴窝”了?如果硬件彻底损坏,你的宝贵数据可能就灰飞烟灭了!😱
这在任何严肃的生产环境中都是绝!对!无!法!接!受! 的!
我们需要一个机制,能够让我们在面对单点故障时依然能够“淡定一笑”,因为我们有“备胎”,我们有“数据双保险”!
没错,这个“双保险”,就是 MongoDB 实现高可用 (High Availability - HA) 和数据冗余 (Data Redundancy) 的核心功能——副本集 (Replica Set)!🛡️💪
理解并掌握副本集,是把 MongoDB 应用于生产环境的第一步,也是最关键的一步! 它能让你的数据不易丢失,让你的服务不轻易中断!🏆
第一节:副本集的核心概念:它是什么?为什么需要它?🤔🧠
1.1 定义:副本集是什么?
MongoDB 副本集是一个由一组 mongod 进程(通常运行在不同的服务器上)组成的集群,它们共同维护和管理着完全相同的数据集。这些成员之间是相互连接、相互通信的。你可以把它想象成一个“数据库镜像团队”,大家手里的数据都长得一模一样!👯♀️👯♂️
1.2 为什么需要副本集?解决单点故障的“救星”!
单个 MongoDB 实例的致命弱点就是单点故障。副本集正是为了解决这个问题而生!它通过在多个节点上保存数据副本,并提供自动故障转移机制,来保障你的数据和服务的持续可用性。
副本集就像给你的数据和数据库服务买了一份高额保险!💰🛡️
1.3 副本集提供哪些“超能力”?
部署了副本集后,你的 MongoDB 数据库将拥有以下关键能力:
- 高可用性 (High Availability - HA) 与自动故障转移 (Automatic Failover) 💪:这是副本集最核心、最直观的好处!当副本集的主节点(Primary)发生故障(例如,进程崩溃、服务器宕机、网络中断等),副本集能够自动检测到这个故障,并在剩余的健康成员中自动启动一个选举 (Election) 过程,快速选出一个新的主节点来接替工作。整个过程通常只需要几秒到几十秒,最大限度地减少了服务的停机时间!你的应用可以在很短的时间内重新连接到新的主节点,继续进行写操作。
- 数据冗余 (Data Redundancy) 🛡️💾:数据被实时复制到多个独立的节点上。这意味着即使某个节点的硬盘损坏、服务器物理损坏,你的数据依然在其他节点上安全地保存着。大大降低了硬件故障导致的数据丢失风险。数据安全性得到了显著提升!
- 读扩展能力 (Read Scaling) 📚:除了 Primary 节点,Secondary 节点也可以配置来处理读请求。在高并发读的场景下,你可以将读流量分散到多个 Secondary 节点上,有效分担 Primary 的压力,提高整个副本集的读吞吐能力。读能力可以随着 Secondary 节点的增加而线性扩展!
- 分布式读 (Distributed Reads) 🌍:如果你的应用用户分布在不同的地理区域,并且副本集成员也部署在靠近用户的不同地方,通过配置读偏好 (Read Preference)(比如
nearest),可以让用户从网络延迟最低的那个节点读取数据。这能显著提高用户的访问速度和体验! - 分片的基础 (Foundation for Sharding) 🧱:MongoDB 的分片 (Sharding) 是用于处理海量数据和实现水平扩展的终极解决方案。分片集群的每个“分片”本身,就是一个独立的副本集!所以,理解和掌握副本集,是进一步学习和部署分片集群的必备前置条件!
第二节:副本集的“骨架”:成员与数据同步机制 👑🔄❤️🔥
一个副本集由不同角色的成员组成,并通过特定的机制保持数据同步。
2.1 成员角色:Primary 和 Secondary
- 主节点 (Primary) 👑:副本集中唯一一个接收所有写操作(
insert,update,delete)的节点。它就像团队的“总指挥”,所有修改数据的命令都必须先经过它。一个副本集在任何时刻只能有一个 Primary 节点。 - 从节点 (Secondary) 🔄📚:副本集中的其他成员都是 Secondary 节点。它们从 Primary 节点那里复制数据,并确保自己的数据集与 Primary 保持一致。Secondary 节点默认不接收写操作,但可以根据配置处理读操作。它们也是 Primary 节点故障时的“替补队员”,可以被选举为新的 Primary。
2.2 神奇的 Oplog:复制的心跳 ❤️🔥ログ
Secondary 节点如何从 Primary 节点复制数据呢?这要归功于 Oplog (Operation Log)!
- Oplog 是什么? Oplog 是 Primary 节点上的一个特殊的、固定大小的(capped collection)集合。它以一种紧凑的格式记录了所有对 Primary 数据进行修改的写操作。这些操作记录是幂等的,这意味着无论在 Secondary 节点上重复应用多少次同一个 Oplog 条目,结果都是一样的。
- Oplog 如何工作? Secondary 节点会定期从 Primary 节点拉取 Oplog 中的新条目,然后在自己的数据集上按顺序“回放”这些操作,从而保持与 Primary 的数据同步。如果 Secondary 落后太多,或者 Primary 节点宕机,Secondary 还可以从其他同步较好的 Secondary 节点拉取 Oplog。
- Oplog 大小的重要性: Oplog 的大小决定了 Secondary 节点能够在 Primary 节点宕机或断开连接后,最长能够“追赶”多久的数据。如果 Oplog 太小,Secondary 节点可能在 Primary 恢复之前就已经“追不上”了,需要重新进行全量数据同步(resync),这个过程比较耗时。合理规划 Oplog 大小非常重要!你可以通过修改副本集配置来调整 Oplog 大小。
2.3 成员数量的讲究:为啥推荐奇数个?仲裁者是啥? 🧱🧱🧱🗳️
- 为啥至少需要 3 个成员? 为了在 Primary 故障时能够进行可靠的自动选举,副本集需要大多数成员“同意”才能选出新的 Primary。如果只有 2 个成员(1 Primary, 1 Secondary),Primary 故障后只剩 1 个成员,无法形成“大多数”,就无法自动选举。至少 3 个成员(例如 1 Primary, 2 Secondary),Primary 故障后还剩 2 个成员,2 是 3 的大多数,可以进行选举。
- 为啥推荐奇数个? 奇数个成员(如 3, 5, 7 个)可以更好地避免选举时出现平票僵局,确保能够选出唯一的 Primary。偶数个成员在特定情况下可能导致平票,需要额外的仲裁者来打破僵局。
- 仲裁者 (Arbiter) 🏠🗳️:仲裁者是副本集的一个特殊成员。它不存储数据,不处理读写请求,它的唯一作用就是参与选举投票!仲裁者资源消耗非常低,适合用于以下场景:
- 当你只有偶数个数据节点时,可以添加一个仲裁者组成奇数个投票成员,避免平票。
- 当你的数据节点部署在资源受限的环境时,可以减少数据节点数量,但增加仲裁者来维持足够的投票数。
注意: 仲裁者没有数据副本,不能提高数据冗余度。它也不能提供读扩展。
第三节:生死攸关的时刻:选举流程全解析 🗳️👑➡️👑
了解选举过程,才能理解副本集如何实现自动故障转移。
3.1 选举的触发条件
选举不是随时发生的,它在以下情况可能被触发:
- 当前 Primary 节点宕机、崩溃或失联。🚨
- 管理员手动将 Primary 节点降级 (
rs.stepDown())。 - 一个新的优先级更高的 Secondary 节点加入副本集。
- 初始化副本集 (
rs.initiate()) 时。
3.2 选举过程
当选举被触发时,Secondary 成员(包括仲裁者)会启动一个分布式共识过程:
- 检测 Primary 故障: Secondary 成员定期向 Primary 发送心跳信号。如果在设定的时间内没有收到 Primary 的心跳,Secondary 会认为 Primary 失联,标记其为
DOWN。 - 发起选举: 某个 Secondary 节点(通常是 Oplog 最新的那个)会发起一次选举,向其他成员发送请求投票 (
requestVote) 消息。 - 成员投票: 接收到投票请求的成员,会评估投票资格。一个成员只会给它看到的第一个发起选举的有效请求投票。投票资格包括:
- 发起者的 Oplog 必须足够新(不能落后 Primary 太多)。
- 发起者的优先级 (priority) 必须符合要求。
- 成员自己必须健康。
- 选出新的 Primary: 第一个获得大多数投票(包括自己的投票)的成员,就成功当选为新的 Primary!👑
- 接管写操作: 新的 Primary 节点会开始接收客户端的写请求,并向其他 Secondary 节点发送心跳和 Oplog。
- 其他成员降级: 其他 Secondary 成员发现新的 Primary 已经出现,就会降级为 Secondary 角色,并开始从新的 Primary 复制数据。
- 旧 Primary 恢复: 如果原先的 Primary 节点恢复了,它会发现已经有新的 Primary 存在,自己就会降级为 Secondary,并从当前 Primary 复制数据以赶上同步。
3.3 影响选举的因素
- 优先级 (priority): 可以在成员配置中设置优先级(0 到 1000)。优先级越高的成员越有可能被选为 Primary(如果其他条件相同)。优先级为 0 的成员永远不会被选为 Primary,也不会参与选举。
- Oplog 状态: Oplog 最新的成员越有可能被选为 Primary,因为它们的数据最新,成为 Primary 后数据丢失的可能性最低。
- 网络延迟: 成员之间的网络延迟会影响心跳检测、投票消息的传递速度,进而影响选举过程的时间。
- 选举超时时间: 副本集有配置项控制 Primary 失联后多久触发选举,以及选举过程的超时时间。
3.4 故障转移时间
故障转移时间(从 Primary 宕机到新的 Primary 选举成功并开始接收写操作)取决于多种因素,但主要受网络延迟、选举超时配置以及成员的健康状况影响。理想情况下,这个时间可以非常短,实现快速恢复。🚀
第四节:数据流动的艺术:读写分离与一致性考量 ✍️➡️📚🛡️✅
在副本集中,理解读写操作的流向以及数据一致性非常重要。
4.1 写操作:永远指向 Primary! ✍️➡️👑🛡️
- 所有客户端发起的写操作(
insert,update,delete)必须连接到当前的 Primary 节点来执行。 - 客户端驱动程序通常能够自动发现副本集的 Primary 节点,并将写操作路由到正确的节点。
- 写关注 (Write Concern) 是写操作的关键配置!它决定了你的写操作在返回成功之前,需要等待数据被多少个节点确认。这直接影响了数据的持久性和写操作的延迟。
{ w: 1 }(默认): 只需 Primary 节点确认写入即可。速度快,但 Primary 刚写入数据就宕机可能丢失数据。{ w: 'majority' }: 需要大多数投票成员确认写入(数据已写入其内存和 journal 日志)。这是生产环境常用的配置,提供了强大的数据持久性保证!即使 Primary 宕机,只要大多数成员确认了,数据就不会丢失。🛡️{ w: <number> }: 需要指定数量的成员确认写入。{ j: true }: 需要成员将数据写入 journal 日志。{ wtimeout: <milliseconds> }: 写操作等待确认的超时时间。
4.2 读操作:Primary 还是 Secondary? 📚➡️👑 or 📚➡️🔄? ✅
-
默认情况下,读操作也发送到 Primary 节点,以确保读到的是最新的数据(
readConcern: 'local')。 -
但是,你可以通过配置读偏好 (Read Preference) 来控制读操作发送到副本集中的哪个成员!这是实现读扩展和分布式读的关键!
读偏好模式详解:
primary:只从 Primary 读取。保证读到最新、最一致的数据。牺牲读扩展性。primaryPreferred:优先从 Primary 读取,如果 Primary 不可用,则从 Secondary 读取。兼顾一致性和可用性。secondary:只从 Secondary 读取。用于分散读负载,提高读吞吐量。注意: 可能读到旧数据,因为 Secondary 的复制是异步的,存在复制延迟 (Replication Lag)。这涉及到数据一致性和延迟的权衡。secondaryPreferred:优先从 Secondary 读取,如果 Secondary 不可用,则从 Primary 读取。nearest:读取网络延迟最低的成员(无论主从)。用于多数据中心部署,降低用户访问延迟。🌍
-
读关注 (Read Concern) 在读取中的作用: 读关注决定了你从 MongoDB 读取数据时,能看到的数据级别,影响读取的数据是否已经持久化或已被大多数成员确认。
'local'(默认): 读取成员本地的数据,可能是未被大多数确认的数据。速度最快。'majority':读取已经被大多数投票成员确认的数据。保证读到的数据不会因为后续回滚而消失,提供了更强的一致性保证。常用于需要较高一致性的场景。'linearizable':提供最高级别的一致性保证,保证读到的数据反映了所有写关注为'majority'的已提交写操作的最新状态。性能开销最大。'snapshot':仅在事务中使用,保证事务内部读到的是事务开始时的数据快照。
合理地结合读偏好和读关注,可以让你在数据一致性、持久性、性能和延迟之间找到最佳平衡点,满足不同业务场景的需求。
第五节:副本集的“身份证”与“体检报告”:配置与状态管理 🛠️🩺
管理一个副本集,你需要了解如何配置它以及如何查看它的健康状况。
5.1 成员配置项详解 (在 rs.initiate() 或 rs.reconfig() 中使用):
members 数组中的每个成员都是一个配置文档,包含以下常用项:
_id: <int>:成员在副本集中的唯一 ID,从 0 开始。host: "<hostname>:<port>":成员的网络地址和监听端口。这个地址必须是其他副本集成员能够访问到的!在单服务器演示中用127.0.0.1:port,在生产环境应该用实际的 IP 或主机名。priority: <number>:成员的选举优先级 (0-1000)。默认是 1。优先级高的成员在选举中更有可能成为 Primary。优先级为 0 的成员永远不会被选为 Primary,也不会参与投票。votes: <int>:成员在选举中拥有的投票权 (0 或 1)。默认是 1。仲裁者的votes默认为 1,但priority为 0。hidden: <boolean>:如果设置为true,这个成员对客户端是“隐藏”的,不会接收读请求,也不会出现在rs.status()的客户端视图中。通常用于搭建一个额外的 Secondary 节点用于数据备份或离线分析,而不影响主流程。buildIndexes: <boolean>:如果设置为false,这个成员不会自动构建在其上创建的索引。tags: <document>:给成员打标签,例如{ "dc": "east", "use": "reporting" }。可以配合读偏好({ mode: "nearest", tags: { "dc": "east" } })将读请求定向到具有特定标签的成员。
5.2 初始化副本集:rs.initiate(configuration) 🤝🛠️
在启动了多个带有相同 --replSet 参数的 mongod 实例后,连接到其中任意一个实例的 Shell,执行 rs.initiate() 命令来组建副本集。
// 连接到某个 mongod 实例的 Shell
mongosh --host <hostname> --port <port>
// 执行初始化命令
rs.initiate({
_id: "myReplicaSet", // 复制集名称,必须与 mongod 启动参数一致
members: [
{ _id: 0, host: "host1:27017", priority: 10 }, // 指定优先级,让它优先成为 Primary
{ _id: 1, host: "host2:27017" },
{ _id: 2, host: "host3:27017", votes: 0 } // 这个成员不参与投票
],
settings: { // 其他可选设置
electionTimeoutMillis: 5000 // 选举超时时间,单位毫秒
}
});
5.3 查看副本集状态:rs.status() 🩺
这是监控副本集健康状况的必备命令!在副本集任意成员的 Shell 中执行即可。
rs.status();
rs.status() 的输出是一个包含大量信息的文档,关注以下关键字段:
set: 副本集名称。date: 当前命令执行时间。myState: 当前成员的状态代码(1 Primary, 2 Secondary, 0 Starting, 3 Recovering, 5 Startup2 等)。members: 一个数组,包含副本集每个成员的详细状态:name: 成员的host:port地址。stateStr: 成员的可读状态字符串(PRIMARY, SECONDARY, STARTUP2, RECOVERING, ARBITER 等)。health: 成员健康状况(1 健康,0 不健康)。optimeDate: 成员最近应用 Oplog 操作的时间。比较不同成员的optimeDate可以判断复制延迟。lastHeartbeat,lastHeartbeatRecv: 最后一次发送/接收心跳的时间。configVersion: 成员当前的配置版本。electionTime/electionDate: 最近一次选举的时间。uptime: 成员运行时间。self: 是否是当前连接的成员。
通过 rs.status(),你可以轻松了解谁是 Primary,谁是 Secondary,是否有成员失联,复制是否滞后等等!
5.4 修改副本集配置:rs.conf(), rs.reconfig(configuration) ⚙️
rs.conf():在副本集任意成员的 Shell 中执行,获取当前副本集的配置文档。rs.reconfig(configuration):在副本集Primary 成员的 Shell 中执行,用新的配置文档替换当前配置。这是一个非常敏感的操作,错误的配置可能导致副本集不稳定甚至宕机!通常在添加/移除成员、修改成员优先级/投票权等场景下使用。
5.5 添加/移除成员:rs.add(member), rs.remove(member) 🔄🧹
在副本集Primary 成员的 Shell 中执行:
rs.add("<hostname>:<port>"): 添加一个新成员。rs.remove("<hostname>:<port>"): 移除一个成员。
添加新成员后,新成员会自动开始从其他成员同步数据。移除成员则会停止该成员的数据同步并将其从副本集中移除。
第六节:MongoDB 实验室:手把手教你在单服务器上用 Docker 搭建副本集模拟环境!💻🐳🔬🤓
副本集原理听起来很酷,但把它在自己的电脑里跑起来,那种成就感是无可替代的!今天,咱们就利用 Docker 这个强大的容器化工具,在一台机器上构建一个迷你的 MongoDB 副本集实验室!🔬✨
这个实验室将帮助你直观地理解副本集的主从结构、数据同步和故障转移过程。
准备工作:确保你的实验环境就绪!
- 安装 Docker Engine 和 Docker Compose: 这是进行本次实验的“魔法工具”!如果你还没装,赶紧去 Docker 官网 (https://www.docker.com/) 下载安装。Docker Compose 让我们能用一个简单的 YAML 文件定义和管理多个 Docker 容器。
- 足够的硬件资源: 即使是模拟环境,同时运行 3 个 MongoDB 容器也需要一定的内存和 CPU。确保你的机器不是“老掉牙”的!👴💻➡️🚀💻
- 文本编辑器: 用于编写 Docker Compose 文件。
- 终端或命令行工具: 用于执行 Docker 命令。
核心工具:Docker Compose 🐳📝
Docker Compose 允许我们通过一个 docker-compose.yml 文件来定义多个服务(也就是容器),以及它们之间的网络、卷等。对于搭建多容器的应用(比如微服务、或者像副本集这样的集群),Docker Compose 比手动一个一个 docker run 方便太多了!
我们将使用 Docker Compose 文件来定义副本集的 3 个成员,让它们跑在各自独立的容器里,但通过同一个 Docker 网络互相通信。
第一步:编写 Docker Compose 文件——定义你的副本集小分队!🐳📝
创建一个名为 docker-compose.yml 的新文件,然后将以下内容粘贴进去:
# 定义服务 (这里的每个服务就是一个 Docker 容器)
services:
# 复制集成员 1
mongo1:
image: mongo:latest # 使用官方最新的 MongoDB 镜像
container_name: mongo1 # 给容器起个名字
command: mongod --replSet rs0 --port 27017 --bind_ip_all --dbpath /data/db # 容器启动时执行的命令
ports: # 端口映射:将宿主机的 27017 端口映射到容器内部的 27017 端口
- "27017:27017"
volumes: # 数据卷:将命名卷 'mongo1-data' 挂载到容器内部的 '/data/db' 路径,用于持久化数据
- mongo1-data:/data/db
networks: # 将容器连接到 'mongo-replica-net' 这个自定义网络
- mongo-replica-net
# 复制集成员 2
mongo2:
image: mongo:latest
container_name: mongo2
command: mongod --replSet rs0 --port 27017 --bind_ip_all --dbpath /data/db
ports: # 端口映射:将宿主机的 27018 端口映射到容器内部的 27017 端口
- "27018:27017"
volumes:
- mongo2-data:/data/db
networks:
- mongo-replica-net
# 复制集成员 3
mongo3:
image: mongo:latest
container_name: mongo3
command: mongod --replSet rs0 --port 27017 --bind_ip_all --dbpath /data/db
ports: # 端口映射:将宿主机的 27019 端口映射到容器内部的 27017 端口
- "27019:27017"
volumes:
- mongo3-data:/data/db
networks:
- mongo-replica-net
# 定义数据卷 (用于数据持久化)
volumes:
mongo1-data: # 定义一个名为 'mongo1-data' 的命名卷
mongo2-data:
mongo3-data:
# 定义自定义网络 (让容器能够通过名称互相通信)
networks:
mongo-replica-net:
driver: bridge # 使用桥接网络模式
文件解释:
services: 定义了我们将要创建的三个 MongoDB 容器,分别命名为mongo1,mongo2,mongo3。image: mongo:latest: 告诉 Docker 使用最新的官方 MongoDB 镜像来创建容器。container_name: 给每个容器指定一个人类可读的名称。command: 这是容器启动时会执行的命令。mongod: 启动 MongoDB 数据库进程。--replSet rs0: 指定这个mongod实例属于一个名为rs0的副本集。这三个实例必须使用相同的副本集名称!--port 27017:mongod进程在容器内部监听的端口。在容器内部,所有 MongoDB 实例都监听 27017 端口。--bind_ip_all: 允许容器内部所有 IP 地址连接到 MongoDB。在 Docker 网络中,这通常是必要的。--dbpath /data/db: 指定 MongoDB 存储数据的路径,这是 Docker 镜像的默认数据路径。
ports: 这是一个关键设置,用于端口映射。语法是宿主机端口:容器内部端口。- 我们将容器内部的 27017 端口分别映射到宿主机的 27017, 27018, 27019 端口。这样,我们就可以通过访问宿主机的这些端口来访问不同的 MongoDB 容器了!在单服务器演示中,这是区分不同实例的方式。
volumes: 这是一个非常关键的设置,用于数据持久化。语法是命名卷名称:容器内部路径。- 我们将不同的命名卷 (
mongo1-data,mongo2-data,mongo3-data) 分别挂载到每个容器内部的/data/db路径。Docker 会在宿主机上管理这些命名卷的数据。这样,即使容器被停止或删除,只要命名卷还在,数据就不会丢失!每个容器都有自己独立的数据存储,互不影响。🛡️💾
- 我们将不同的命名卷 (
networks: 将所有容器连接到一个自定义的 Docker 网络mongo-replica-net。这使得容器可以通过容器名称互相通信(比如mongo1可以通过mongo2:27017访问到mongo2容器内部的 MongoDB 服务),这是副本集成员之间相互发现和通信的基础。
volumes: 定义了上面services部分引用的命名卷。Docker 会自动创建和管理这些命名卷的生命周期。networks: 定义了一个名为mongo-replica-net的自定义桥接网络。
第二步:启动容器——让副本集小分队“活”起来!🏃♂️🏃♂️🏃♂️
保存好 docker-compose.yml 文件。打开你的终端或命令行工具,进入文件所在的目录,执行以下命令:
docker compose up -d

docker compose up: 根据docker-compose.yml文件创建并启动服务(容器)。-d: 让容器在后台运行 (detached mode),不会占用你的终端。
执行命令后,Docker 会:
- 拉取
mongo:latest镜像(如果本地没有的话)。 - 创建
mongo-replica-net网络(如果不存在的话)。 - 创建
mongo1-data,mongo2-data,mongo3-data命名卷(如果不存在的话)。 - 创建并启动
mongo1,mongo2,mongo3三个容器。
你可以使用 docker compose ps 命令查看容器的运行状态。你应该看到 mongo1, mongo2, mongo3 三个容器的状态都是 running。

第三步:初始化副本集——给小分队“组队”!🤝🛠️
现在三个 mongod 实例已经在各自的容器里跑起来了,并且知道自己属于 rs0 这个副本集。但是,它们之间还没有正式“认识”并组建团队!我们需要连接到其中任意一个容器内部的 Shell,然后执行初始化命令!
我们连接到 mongo1 容器内部的 MongoDB Shell。
docker exec -it mongo1 mongosh --port 27017
docker exec: 在运行中的容器里执行命令。-it: 获得一个交互式的终端。mongo1: 要连接的容器名称。mongosh --port 27017: 在容器内部执行的命令,启动 MongoDB Shell 并连接到容器内部的 27017 端口。
进入 Shell 后,执行以下命令来初始化副本集:
rs.initiate({
_id: "rs0", // 复制集名称,必须与 docker-compose.yml 中指定的名称一致!
members: [
{ _id: 0, host: "mongo1:27017" }, // 成员 0,使用容器名称和内部端口
{ _id: 1, host: "mongo2:27017" }, // 成员 1
{ _id: 2, host: "mongo3:27017" } // 成员 2
]
});
rs.initiate(...): MongoDB Shell 的命令,用于初始化一个副本集。_id: "rs0": 副本集的名称,必须与你在docker-compose.yml文件中--replSet指定的名称完全一致!members: 一个数组,列出副本集的所有成员。_id: 0, 1, 2: 每个成员在副本集内部的唯一 ID,通常从 0 开始。host: "<容器名称>:<内部端口>": 这是关键!在 Docker 网络中,容器可以通过它们的容器名称互相访问。所以这里我们填写容器名称 (mongo1,mongo2,mongo3) 加上它们在容器内部监听的端口 (27017)。不要填写localhost或宿主机的 IP!
执行 rs.initiate() 命令后,等待片刻。副本集成员会开始互相通信,并进行选举!最终会有一个成员被选为 Primary,其他成员成为 Secondary。
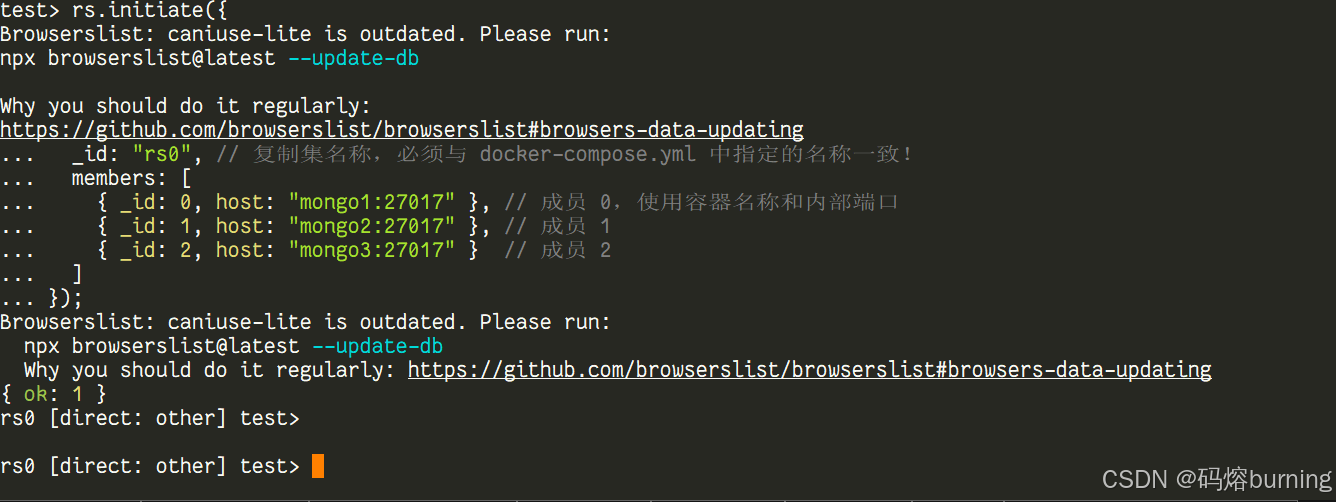
第四步:验证状态——看看副本集是否健康工作!🩺👑
初始化完成后,你需要确认副本集是否正常运行。在刚才执行 rs.initiate() 的 Shell 中,或者连接到副本集任意成员的 Shell(比如连接宿主机端口 27017, 27018, 27019 中的任意一个),执行 rs.status() 命令。
# 在 Shell 中执行
rs.status();
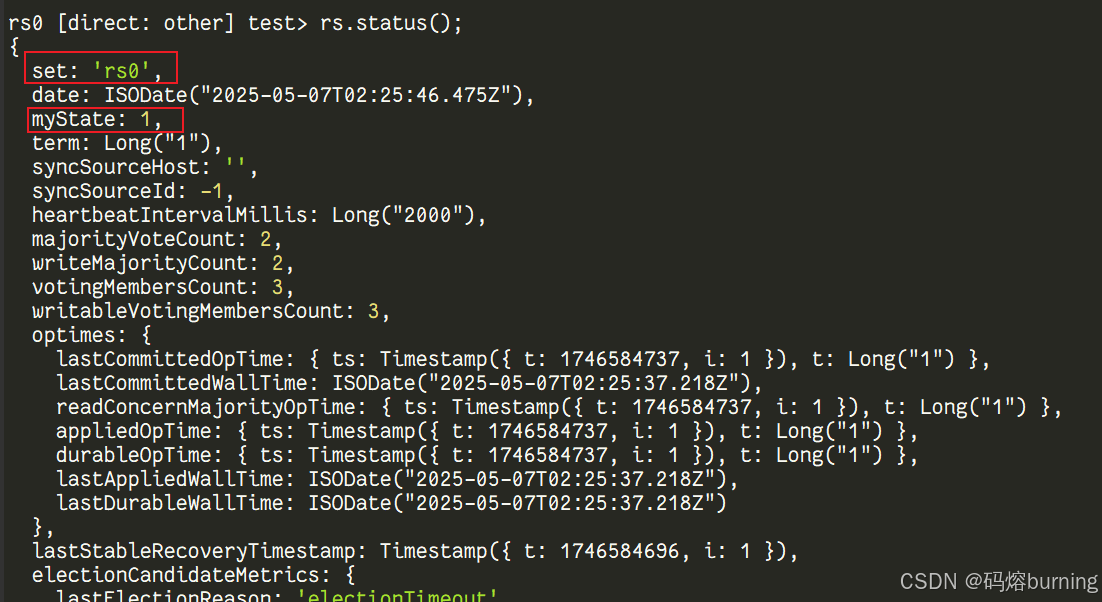
rs.status() 的输出会告诉你副本集的详细状态。关注以下关键信息:
set: 副本集名称(应该是rs0)。myState: 当前连接的成员的状态代码(1 表示 Primary,2 表示 Secondary)。members: 一个数组,列出所有成员的状态:name: 成员的地址和端口(应该是容器名称和内部端口)。stateStr: 成员的可读状态(PRIMARY, SECONDARY, STARTUP2, RECOVERING 等)。当三个成员的状态都是PRIMARY或SECONDARY时,表示副本集正常组建并运行了!🥳health: 如果是 1 表示健康。optimeDate: 成员最近同步操作的时间。比较不同成员的这个时间可以大致判断复制延迟。
当看到一个成员是 PRIMARY,其他成员是 SECONDARY,并且 health 都是 1 时,恭喜你!你的模拟副本集已经成功搭建并运行了!Shell 的提示符也会变成 rs0:PRIMARY> 或 rs0:SECONDARY>。
第五步:数据操作——写入 Primary,从 Secondary 读取!✍️📚✅
现在,副本集正常运行,来测试一下数据的复制!记住:所有写操作必须发往 Primary 节点! 读操作默认也发往 Primary,但可以配置从 Secondary 读取。
-
连接到 Primary 节点写入数据: 找到当前副本集的 Primary 节点(通过
rs.status()或 Shell 提示符确认),连接到它的宿主机端口。# 连接到 Primary 节点 (假设是宿主机端口 27017) mongosh --port 27017进入 Shell 后,提示符应该是
rs0:PRIMARY>。执行一些写操作:use testdb; // 切换或创建数据库 db.mycollection.insertOne({ greeting: "Hello, Replica Set World!", source: "Primary" }); db.mycollection.insertMany([ { user: "Alice", city: "New York" }, { user: "Bob", city: "London" }, { user: "Charlie", city: "Tokyo" } ]);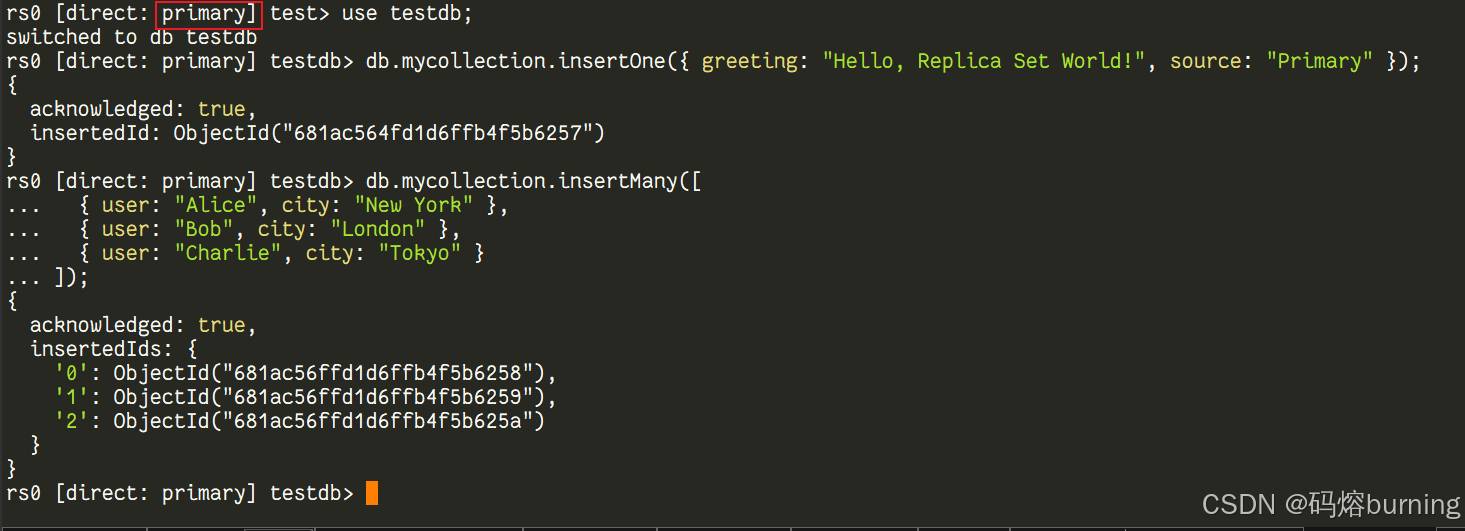
这些数据已经被写入到 Primary 节点的数据目录中,并记录在 Primary 的 Oplog 里。
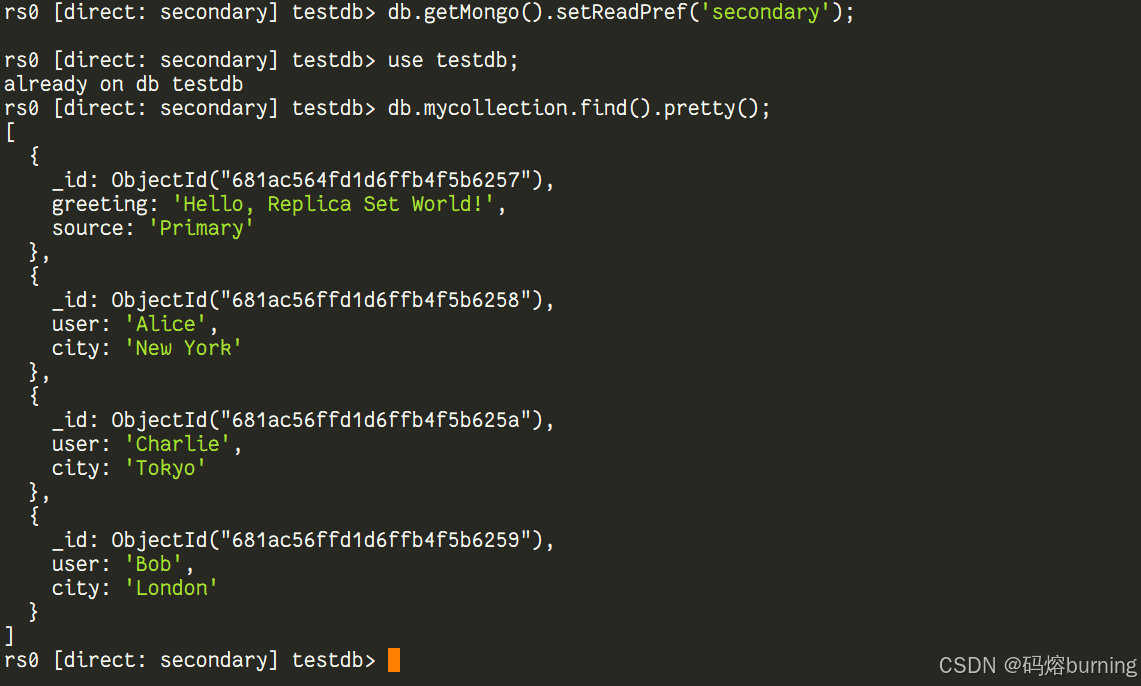
-
连接到 Secondary 节点读取数据并验证复制: 连接到副本集的一个 Secondary 节点的宿主机端口(比如 27018)。
# 连接到 Secondary 节点 docker exec -it mongo2 bash mongosh --port 27017进入 Shell 后,提示符应该是
rs0:SECONDARY>。

默认情况下,从节点不能直接读取数据。 如果你直接执行
db.mycollection.find(),可能会看到错误。你需要执行db.getMongo().setReadPref('secondary');命令,告诉这个 Shell 会话允许从 Secondary 读取数据。db.getMongo().setReadPref('secondary'); use testdb; // 切换到相同的数据库 db.mycollection.find().pretty(); // 执行读操作你会看到,刚才在 Primary 节点写入的所有数据,都已经成功同步到这个 Secondary 节点上了!🥳 数据复制成功!
你可以连接到另一个 Secondary 节点(宿主机端口 27019),重复上述步骤,验证数据在所有 Secondary 节点之间的一致性。
第六步:模拟故障与自动转移——亲手见证 HA 的力量!💥👑➡️👑🗳️
这是副本集最酷炫的时刻!咱们来模拟一下 Primary 节点“挂掉”的情况,看看副本集是如何自动恢复的!
-
停止 Primary 容器: 找到当前副本集的 Primary 容器的名称(通常是
mongo1如果它一直是 Primary,但最好通过rs.status()确认)。使用docker compose stop命令停止它。# 停止 Primary 容器 (假设 mongo1 是 Primary) docker compose stop mongo1
这个命令会向容器发送停止信号,模拟进程崩溃或服务器关机。
-
观察选举过程: 连接到剩余的 Secondary 节点(比如连接宿主机端口 27018 或 27019)。反复执行
rs.status()命令!# 连接到剩余的 Secondary 节点 (比如 mongo2) docker exec -it mongo2 mongosh --port 27017 # 在 Shell 中反复执行 rs.status();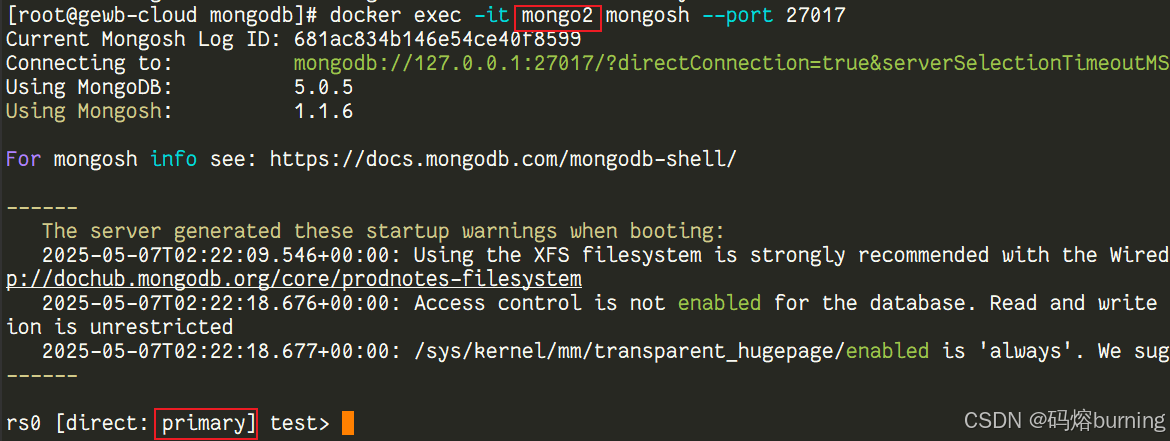
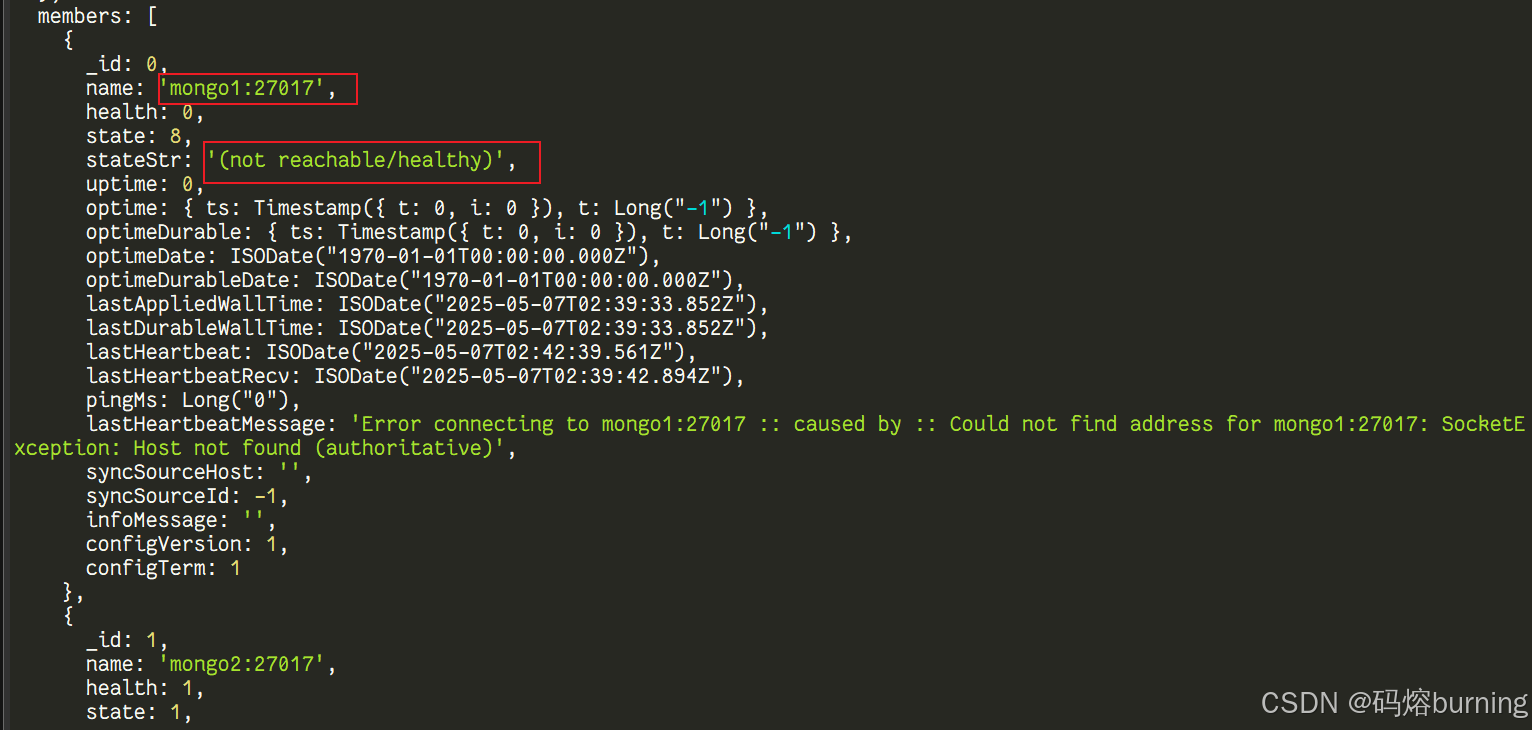
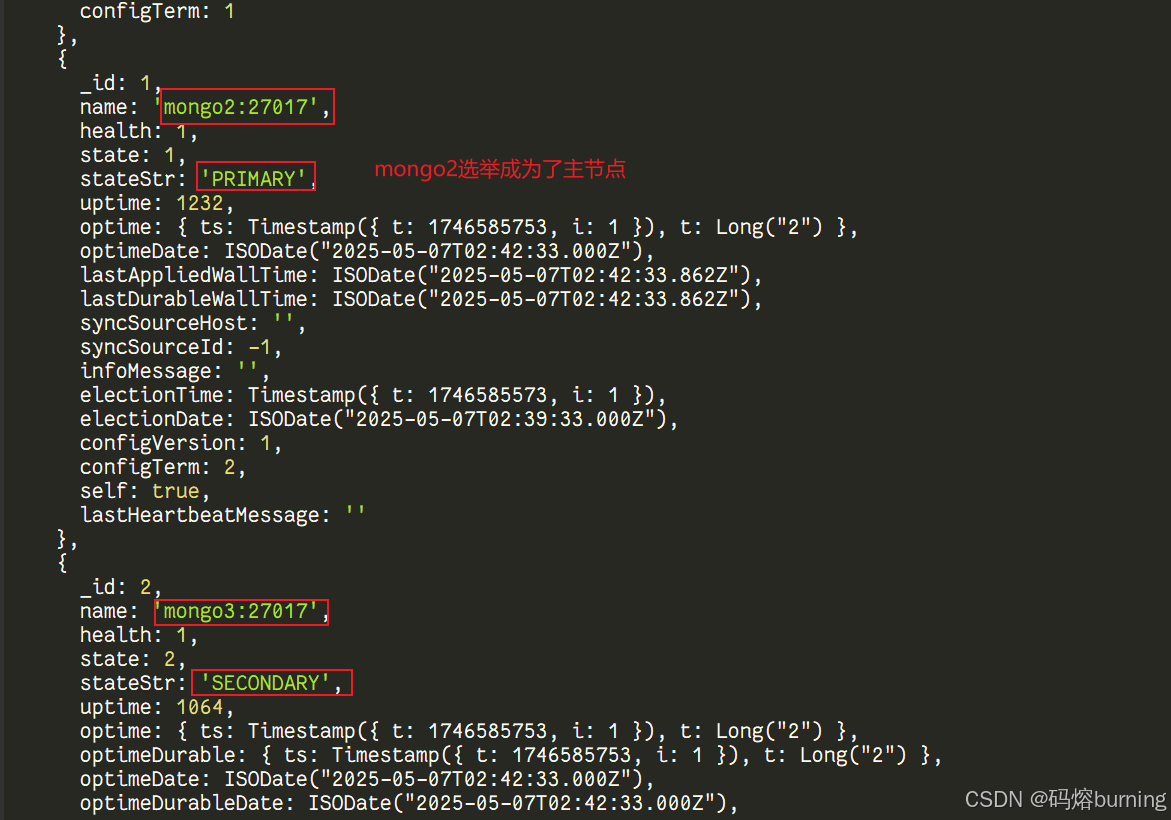
你会看到
rs.status()的输出发生变化!原先的 Primary 节点 (mongo1) 的状态变为了(not reachable/healthy)。剩下的 Secondary 节点 (mongo2,mongo3) 会开始相互通信,状态可能在STARTUP2,RECOVERING等之间切换,它们正在进行选举!🗳️最终,其中一个 Secondary 节点会获得多数投票,并成功当选为新的 Primary!🥳 你会看到它的
stateStr变成PRIMARY,Shell 提示符也会变成rs0:PRIMARY>! -
测试写入新的 Primary: 连接到新的 Primary 节点(通过
rs.status()确认是哪个端口),验证是否可以正常进行写操作。# 连接到新的 Primary 节点 (通过 rs.status() 确认端口) docker exec -it mongo2 mongosh --port 27017 use testdb; db.mycollection.insertOne({ message: "Hello from the NEW Primary!", timestamp: new Date() });
写操作应该会成功!这证明了副本集的自动故障转移能力!👍
-
恢复旧的 Primary (可选): 你可以将之前停止的 Primary 容器重新启动。
# 启动之前停止的容器 docker compose start mongo1它会作为 Secondary 成员重新加入副本集,并自动从当前 Primary 追赶数据同步。再次使用
rs.status()观察状态。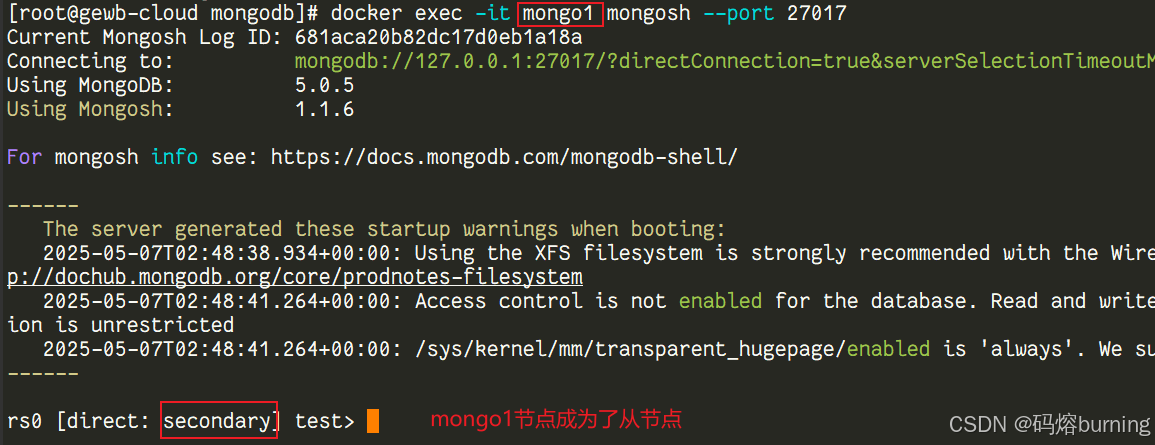
第七步:清理实验环境——不留痕迹!🧹🔥
实验完成,别忘了清理掉创建的 Docker 容器、网络和数据卷,释放资源。
在 docker-compose.yml 文件所在的目录,执行以下命令:
docker compose down
docker compose down 命令会停止并移除 docker-compose.yml 文件中定义的所有服务(容器)、删除 Docker 网络。默认情况下,它也会删除 Docker Compose 创建的命名卷(除非你在 volumes 部分指定了外部卷或其他保留策略)。删除命名卷意味着你的数据会被清除,所以请确保你不再需要这些数据!
执行后,你的单服务器 Docker 副本集模拟环境就被彻底清除了!干净利落!
第八步:从模拟到真实——迈向生产环境!🤔💾👁️🗨️🚨
通过这个详细的 Docker 演示,你已经对 MongoDB 副本集的工作原理有了非常直观的理解。但是,要将副本集应用于生产环境,你还需要考虑更多:
- 真正的独立服务器: 生产环境的每个副本集成员必须运行在独立的物理或虚拟服务器上,以避免单点故障。
- 网络环境: 确保成员之间的网络连接稳定、延迟低、带宽充足。
- 资源规划: 为每个成员分配足够的 CPU、内存和高速存储(SSD 是强烈推荐的!)。
- 监控与告警: 部署全面的监控系统,持续关注副本集状态、复制延迟、资源使用等,并设置告警,以便在出现问题时及时知晓并处理。
- 备份策略: 副本集不是备份的替代品!必须实施定期备份策略,防止逻辑错误导致的数据丢失。
- 安全性: 启用认证和授权,限制网络访问。
第七节:生产环境的“保驾护航”:运维与监控 🤔💾👁️🗨️
将副本集应用于生产环境,除了搭建,日常的运维和监控至关重要!
- 资源规划: 每个副本集成员都需要独立的、稳定可靠的服务器资源。不要把多个数据成员部署在同一台物理机上!考虑 CPU、内存、尤其是存储 IO 和网络带宽!
- 网络环境: 副本集成员之间的网络连接是生命线!确保低延迟、高带宽、高可靠的网络。跨数据中心部署需要考虑跨地域网络延迟对复制和选举的影响。避免网络分区!
- 监控: 必须!必须!必须! (重要的事情说三遍)持续监控副本集的健康状况!
rs.status():最直接的命令,查看成员状态、复制延迟 (optimeDate差异)、选举次数等。- 日志文件: 查看每个成员的日志文件,了解启动、连接、同步、选举过程中的详细信息。
- 指标监控: 监控每个
mongod进程的资源使用(CPU、内存、磁盘 IO)、网络流量、连接数、操作计数、队列长度等等。 - 复制延迟监控: 专门监控 Primary 和 Secondary 之间的复制延迟,如果延迟过大,Primary 故障时 Secondary 可能无法及时接管,甚至丢失数据。
- 使用专业工具: MongoDB Cloud Manager / Ops Manager 提供了强大的监控、告警、自动化运维功能。第三方监控工具如 Prometheus + Grafana, Zabbix, Nagios 等也有成熟的 MongoDB 监控方案。设置关键指标告警,及时发现和处理问题!🚨📈
- 备份策略: 副本集 != 备份! 副本集防硬件故障,不防逻辑错误(比如应用代码 bug 删错了数据)或人为误操作。定期进行全量和增量备份是数据安全的最后一道防线!使用
mongodump/mongorestore,或者 MongoDB Enterprise 版本的mongobackup,或者云服务商的备份服务。💾🔒 - 版本升级: 副本集支持在线滚动升级,可以在不停机的情况下逐步升级每个成员的版本。
- 安全: 必须启用 MongoDB 的认证和授权机制!限制只有授权的用户才能连接和操作数据库。配置防火墙,限制只有应用服务器才能访问数据库端口。🔐🧱
- 故障演练: 定期模拟副本集故障(比如手动停止 Primary)进行演练,熟悉故障转移过程,验证监控告警是否正常,提高团队应对故障的能力。
第八节:总结副本集操作!🎉💪
太棒了!我们用一篇超详细的文章,从里到外、从理论到实践、从概念到运维,把 MongoDB 的副本集彻彻底底地剖析了一遍!
我们理解了它在高可用、数据冗余和读扩展中的核心作用,掌握了主从角色、Oplog 同步、选举原理,学习了丰富的配置选项、状态查看和管理命令。更重要的是,我们还亲手搭建了一个模拟环境进行了演练,对这些概念有了直观的认识!
核心要点:
- 副本集是解决单点故障、实现高可用和数据冗余的关键。
- 包含 Primary (写) 和 Secondary (读和复制) 成员。
- Oplog 是实现数据同步的机制。
- 需要至少 3 个成员,推荐奇数个,仲裁者用于增加投票权。
- 选举在 Primary 故障时自动触发。
- 写操作必须到 Primary,读操作可通过读偏好分发到 Secondary。
- 写关注保证写操作的持久性,读关注保证读操作的一致性。
rs.initiate,rs.status,rs.add,rs.remove,rs.conf,rs.reconfig是常用管理命令。- 单服务器演示仅用于学习,生产环境必须多服务器部署。
- 生产运维关注资源、网络、监控、备份、安全、故障演练。
掌握了副本集,你就掌握了将 MongoDB 部署到生产环境的入场券!你的应用将变得更稳定、更可靠、数据更安全!🏆
接下来,如果你想挑战处理 PB 级数据、实现几乎无限的水平扩展,那么 MongoDB 的终极分布式方案——分片 (Sharding) 就在前方等着你!🤯 那将是另一个充满挑战和机遇的领域!
继续加油!让你的 MongoDB 数据库在副本集的保护下,又快又稳,坚不可摧吧!🚀🔥

















 1175
1175

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









