








目录
🌟我的其他文章也讲解的比较有趣😁,如果喜欢博主的讲解方式,可以多多支持一下,感谢🤗!
其他优质专栏: 【🎇SpringBoot】【🎉多线程】【🎨Redis】【✨设计模式专栏(已完结)】…等
如果喜欢作者的讲解方式,可以点赞收藏加关注,你的支持就是我的动力
✨更多文章请看个人主页: 码熔burning
前言
各位在代码江湖乘风破浪的船长们,大家好啊!又是我,你们的老朋友,数据库界的“相声演员”,BUG的“专业劝退师”。今天,咱们不聊“上古神器”(比如MySQL 5.7那些事儿),咱来聊聊“当红炸子鸡”——MySQL 8.0!这货可不仅仅是版本号+1那么简单,它简直是进行了一次“基因突变”式的大升级!
你可能还在用着“五点几”的版本,心里嘀咕:“新版本?稳定吗?香吗?升级麻烦不?” 别急,今天这篇“万字血泪史”(哦不,是“万字爆笑科普”),我就带你把MySQL 8.0那些让人“直呼卧槽”的新特性,从头到脚,从里到外,盘个底朝天!准备好你的小板凳和瓜子,老司机要飙车了,目的地——MySQL 8.0的“新大陆”!🏎️💨
温馨提示:建议使用8.0.17及之后的版本,因为这些版本修复了不少小“坑”,增加了更多“甜点”。 咱们今天聊的,也基本是基于这个前提。
开篇:MySQL 8.0——老树开新花,还是猛虎换獠牙?🐅🌸
MySQL 5.7,一代经典,犹如当年的诺基亚,皮实耐用。但时代在进步,需求在发展,逆水行舟,不进则退嘛!MySQL 8.0的发布,就像是给这棵“老树”嫁接了各种高科技“新枝”,又像是给这头“猛虎”换上了一副更锋利的“獠牙”。它在性能、安全性、易用性、SQL功能等多个方面都带来了翻天覆地的变化。
不吹不黑,有些新特性,简直是“程序员的福音”、“DBA的初恋”,用了就回不去的那种!不信?跟我来瞅瞅!
第一章:索引篇——那些让你“欲罢不能”的优化骚操作 🛠️✨
索引,MySQL的“速度与激情”之源。MySQL 8.0在索引这块儿,可是下了不少功夫,推出了几个“杀手锏”级别的新玩意儿。
1.1 降序索引 (Descending Indexes):“反向操作”也能起飞!🚀
-
“那些年我们一起被‘忽悠’的降序”:
在MySQL 5.7以及更早的版本,你可以在创建索引时写上DESC关键字,比如INDEX idx_c1_c2(c1 ASC, c2 DESC)。你以为你创建了一个c2字段降序的索引? No ! MySQL会默默地忽略你的DESC,实际上还是按照ASC(升序)来存储。
当你执行ORDER BY c1 ASC, c2 DESC时,虽然优化器可能也会尝试使用这个“假降序”索引,但往往不得不在Extra列里给你一个尴尬的Using filesort(文件排序),性能嘛,你懂的。😭-- ====MySQL 5.7 演示==== -- 你以为的降序: CREATE TABLE t1_57 (c1 INT, c2 INT, INDEX idx_c1_c2(c1, c2 DESC)); -- 实际上的样子: SHOW CREATE TABLE t1_57; -- ... KEY `idx_c1_c2` (`c1`,`c2`) -- 看到没?还是升序!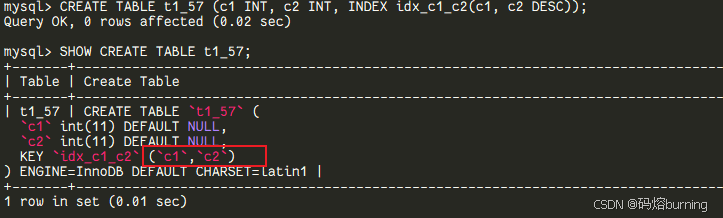
EXPLAIN SELECT * FROM t1_57 ORDER BY c1, c2 DESC; -- Extra: Using index; Using filesort -- 文件排序,效率打折
-
MySQL 8.0的“拨乱反正”:
从MySQL 8.0开始(特指InnoDB存储引擎),DESC关键字终于“名正言顺”了!你定义了降序索引,它就老老实实地给你按降序存储和排序。-- ====MySQL 8.0 演示 ==== CREATE TABLE t1_80 (c1 INT, c2 INT, INDEX idx_c1_c2(c1 ASC, c2 DESC)); -- c2显式降序 SHOW CREATE TABLE t1_80; -- ... KEY `idx_c1_c2` (`c1`,`c2` DESC) -- 降序索引,童叟无欺!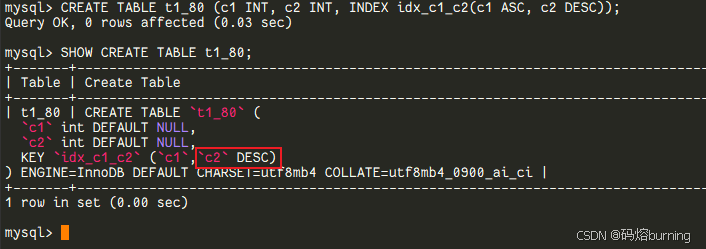
EXPLAIN SELECT * FROM t1_80 ORDER BY c1 ASC, c2 DESC; -- Extra: Using index -- filesort消失了!索引直接搞定,美滋滋!
-
“反向扫描”的智慧:
更有意思的是,如果你定义了INDEX(c1 ASC, c2 DESC),然后查询ORDER BY c1 DESC, c2 ASC(所有字段排序方向都相反),MySQL 8.0 优化器也可能足够聪明地进行“反向索引扫描”(Backward index scan),避免文件排序。-- ====MySQL 8.0 演示 ==== -- 索引是 (c1 ASC, c2 DESC) EXPLAIN SELECT * FROM t1_80 ORDER BY c1 DESC, c2 ASC; -- Extra: Backward index scan; Using index -- 反向扫描,依然给力!
-
但是,别乱来!:
如果你的ORDER BY子句中的字段排序方式,既不是索引定义的方式,也不是完全相反的方式,那文件排序可能还是免不了的。-- ====MySQL 8.0 演示 ==== -- 索引是 (c1 ASC, c2 DESC) EXPLAIN SELECT * FROM t1_80 ORDER BY c1 DESC, c2 DESC; -- c1反了,c2没反 -- Extra: Using index; Using filesort -- 还是得文件排序
EXPLAIN SELECT * FROM t1_80 ORDER BY c1 ASC, c2 ASC; -- c1对了,c2反了 -- Extra: Using index; Using filesort -- 同样文件排序
-
段子手辣评:
MySQL 5.7的降序索引:“我支持降序了哦(才怪,演给你看的)!”
MySQL 8.0的降序索引:“这次是真家伙!正着反着,只要姿势对,都能让你爽!”
核心价值:对于经常需要混合升降序排序的查询,或者纯降序排序的查询,8.0的真·降序索引能显著提升性能,告别不必要的filesort。妈妈再也不用担心我的排序慢了!🥳
1.2 隐藏索引 (Invisible Indexes):“隐身即无敌?不,是战略性撤退!” 👻
-
“索引的‘薛定谔’状态”:
有时候,你会怀疑某个索引是不是“多余”的,或者想看看禁用掉某个索引后,查询性能会有啥变化。在以前,你可能得狠心DROP INDEX,如果发现不对劲,又得吭哧吭哧ADD INDEX,表大的话,那简直是“生命不可承受之重”。 -
MySQL 8.0的“隐身衣”:
现在,你可以给索引穿上“隐身衣”了!通过INVISIBLE关键字,可以将一个索引设置为“隐藏”状态。-- 创建t2表,里面的c2字段为隐藏索引 CREATE TABLE t2 ( c1 INT, c2 INT, INDEX idx_c1(c1), INDEX idx_c2(c2) INVISIBLE -- 把idx_c2藏起来! ); SHOW INDEX FROM t2; -- ... idx_c2 ... Visible: NO ... -- idx_c2果然“隐身”了
-
隐藏的奥秘:
-
优化器“无视”:默认情况下,查询优化器会假装看不见这个隐藏索引,即使你用
FORCE INDEX“威逼利诱”,它也“不为所动”。 -
后台依然“辛勤”:虽然优化器不用它,但这个索引在后台还是会被正常维护的(增删改数据时,索引数据会更新)。 这意味着,如果你把它重新“显形”,它立刻就能投入战斗,不需要重建。
-
“解除隐身”很简单:
ALTER TABLE t2 ALTER INDEX idx_c2 VISIBLE; -- 出来吧,皮卡丘! ALTER TABLE t2 ALTER INDEX idx_c2 INVISIBLE; -- 回去吧,神隐! -
“特殊通道”让优化器看见它:如果你非要在当前会话测试一下隐藏索引的效果,可以通过修改
optimizer_switch来实现:-- 默认情况下,隐藏索引c2不会被使用 EXPLAIN SELECT * FROM t2 WHERE c2 = 1; -- 会走全表扫描或报错(取决于表是否有数据)
-- 让当前会话的优化器“看见”隐藏索引 SET SESSION optimizer_switch = "use_invisible_indexes=on"; EXPLAIN SELECT * FROM t2 WHERE c2 = 1; -- 嘿,idx_c2被用上了! SET SESSION optimizer_switch = "use_invisible_indexes=off"; -- 恢复默认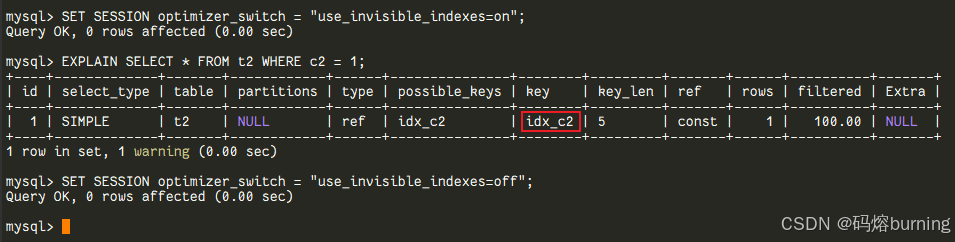
-
主键的“倔强”:主键索引是不能被设置为隐藏的,人家是“中流砥柱”,不能随便玩消失!
-
-
段子手辣评:
隐藏索引:“我就是那个‘召之即来,挥之即去’的预备役。老板想测试没我的日子好不好过?行,我先‘狗带’一会儿,数据我还偷偷维护着,随时听候差遣!”
核心价值:- “软删除”索引:想删某个索引又怕删错?先把它
INVISIBLE了,观察一段时间,如果应用一切安好,再真删;如果发现性能抖动或报错,赶紧VISIBLE回来,秒级恢复,简直是DBA的“后悔药”! - 无风险测试索引效果:评估移除某个索引对查询计划的影响,而无需承担删除和重建的巨大成本和风险。
- 在线Schema变更的“好基友”:在某些复杂的在线表结构变更场景中,可以配合使用隐藏索引,实现更平滑的过渡。
- “软删除”索引:想删某个索引又怕删错?先把它
1.3 函数索引 (Functional Indexes):“列上加函数?索引照样跑酷!” 🤸♀️
-
“函数魔咒”的痛:
我们都知道一个“潜规则”:如果在WHERE子句中对索引列使用了函数,比如WHERE UPPER(username) = 'ADMIN',那么username列上的普通索引基本上就“废了”,优化器很可能直接放弃索引走全表扫描。这让很多需要对字段进行某种转换后再比较的场景非常头疼。 -
MySQL 8.0的“破咒丹”:
从MySQL 8.0.13开始,你可以直接在函数或表达式的结果上创建索引了!这玩意儿叫“函数索引”(也叫表达式索引)。-- 创建表和函数索引 CREATE TABLE t3 (c1 VARCHAR(10), c2 VARCHAR(10)); CREATE INDEX idx_c1 ON t3(c1); -- 普通索引 CREATE INDEX func_idx_upper_c2 ON t3((UPPER(c2))); -- 在UPPER(c2)的结果上创建索引 SHOW INDEX FROM t3; -- ... Key_name: func_idx_upper_c2 ... Expression: upper(`c2`) ... -- 看到那个Expression了吗?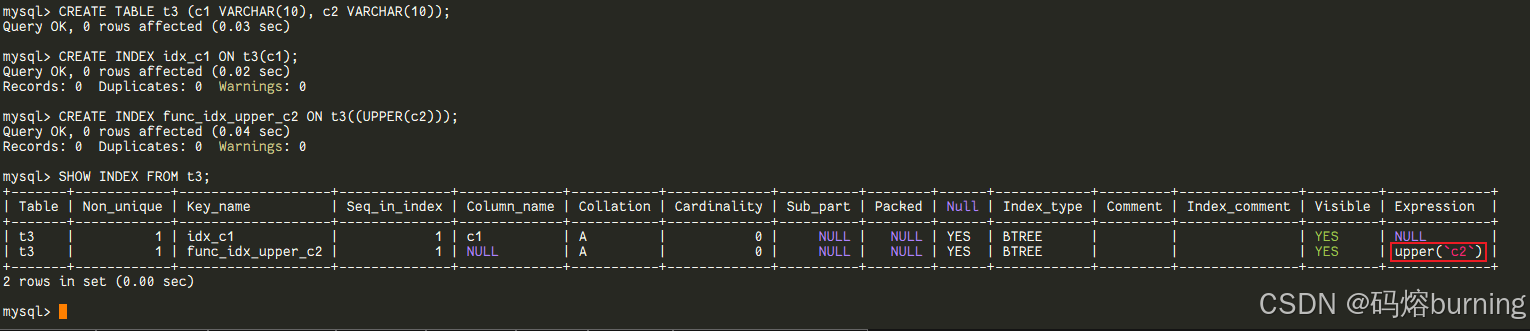
-
如何“显灵”:
当你查询时,WHERE子句中的表达式必须和函数索引定义的表达式完全匹配(文本上一致),优化器才能愉快地使用它。-- 查询 -- c1上有普通索引,但查询条件用了函数,索引失效 EXPLAIN SELECT * FROM t3 WHERE UPPER(c1) = 'ZHUGE'; -- 走全表扫描,因为idx_c1不是函数索引
-- c2上建了UPPER(c2)的函数索引,查询条件完美匹配,索引生效! EXPLAIN SELECT * FROM t3 WHERE UPPER(c2) = 'ZHUGE'; -- 用上了func_idx_upper_c2!
-
幕后真相:函数索引在MySQL内部通常是通过“虚拟列”(Generated Columns)来实现的。当你创建一个函数索引时,MySQL可能会(也可能不会,取决于实现细节)隐式地创建一个虚拟列,该列的值就是函数表达式的计算结果,然后在这个虚拟列上建立一个普通的B-Tree索引。
-
段子手辣评:
函数索引:“以前你们老说我(普通索引)娇气,列上套个函数我就不认识了。现在好了,我进化了!你们尽管在列上玩花样(函数),只要提前跟我打好招呼(创建对应的函数索引),我照样让你们的查询快到飞起!”
核心价值:- 拯救“函数魔咒”:极大地扩展了索引的使用场景,对于那些必须在列上使用函数进行查询的业务,性能提升是肉眼可见的。
- 简化查询:可能不再需要为了走索引而创建额外的、存储函数结果的物理列。
- 支持更复杂的索引逻辑:比如可以对JSON字段中的特定路径的值建立索引。
索引篇的这三板斧,是不是已经让你对MySQL 8.0刮目相看了?别急,好戏还在后头呢!
第二章:查询与性能篇——让你的SQL跑得更快、更稳!⚡️🛡️
MySQL 8.0不仅在索引上做文章,在查询处理和整体性能调优方面也带来了不少惊喜。
2.1 GROUP BY不再“自作多情”搞排序 🚫
-
历史遗留的“好意”:
在MySQL 5.7及更早版本中,当你使用GROUP BY子句时,MySQL往往会“好心”地帮你对分组的结果进行排序。比如你GROUP BY C2,结果集通常会按照C2的升序排列。这在某些情况下挺方便,但也可能是不必要的开销,特别是当你并不需要这个排序结果时。-- ====MySQL 5.7 演示==== -- 给t1表插入一些数据数据:INSERT t1_57 VALUES (1,10), (2,50), (3,50), (4,100), (5,80); SELECT COUNT(*), c2 FROM t1_57 GROUP BY c2; -- 结果通常是按c2升序的: -- (1, 10) -- (2, 50) -- (1, 80) -- (1, 100)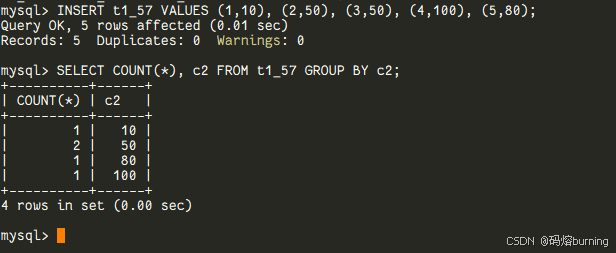
-
MySQL 8.0的“直男行为”:
从MySQL 8.0开始,GROUP BY回归了它的“初心”——只负责分组,不再“自作主张”地进行隐式排序。如果你需要排序,请明确地、大声地(用ORDER BY子句)告诉它!-- ====MySQL 8.0 演示==== -- 同样的给 t1_80 插入数据 INSERT t1_80 VALUES (1,10), (2,50), (3,50), (4,100), (5,80); SELECT COUNT(*), c2 FROM t1_80 GROUP BY c2; -- 结果可能是无序的,或者按照某种内部处理顺序(比如按插入顺序或索引顺序,但不保证按c2排序): -- (1, 10) -- (2, 50) -- (1, 100) -- 注意80和100的顺序可能和5.7不一样了! -- (1, 80)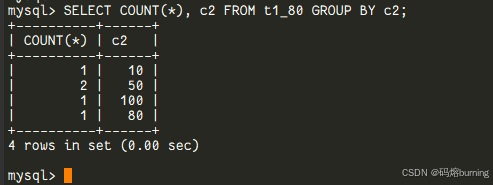
-- 如果你需要按c2排序,请手动加上: SELECT COUNT(*), c2 FROM t1_80 GROUP BY c2 ORDER BY c2; -- 这下就跟5.7的结果一样有序了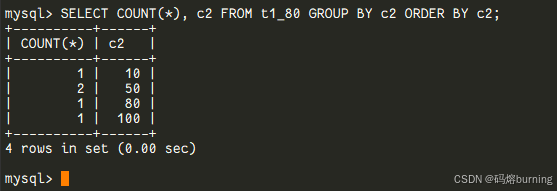
-
段子手辣评:
MySQL 5.7的GROUP BY:“兄弟,你只管分组,排序的事包在我身上,一条龙服务!”
MySQL 8.0的GROUP BY:“我只负责分组,排序?那是ORDER BY的事,别找我,我很忙!”
核心价值:- 性能提升:如果业务逻辑本身不需要
GROUP BY后的结果有序,那么取消这个隐式排序可以避免不必要的排序开销,提升查询性能。 - 行为更标准:更符合SQL标准中
GROUP BY的定义,减少了MySQL的“方言”特性,让SQL行为更可预测。 - 代码更清晰:需要排序就显式写
ORDER BY,意图更明确。
- 性能提升:如果业务逻辑本身不需要
2.2 SELECT … FOR UPDATE/SHARE 跳过锁等待:“急性子”的福音!🏃♀️💨
-
“等到花儿也谢了”的锁等待:
在并发场景下,当你使用SELECT ... FOR UPDATE(加排他锁)或SELECT ... FOR SHARE(MySQL 8.0新增的共享锁语法,兼容LOCK IN SHARE MODE)试图锁定某些行时,如果这些行恰好被其他事务锁住了,那么你的查询就会进入漫长的等待,直到锁被释放,或者达到innodb_lock_wait_timeout设定的超时时间。这对于那些需要快速响应的业务来说,简直是“灾难”。-- ====MySQL 5.7 及之前演示==== -- Session 1: BEGIN; UPDATE t1_57 SET c2 = 60 WHERE c1 = 2; -- 锁住c1=2的行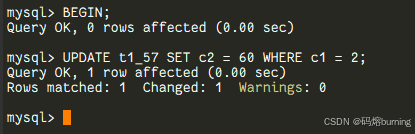
-- Session 2: SELECT * FROM t1_57 WHERE c1 = 2 FOR UPDATE; -- 这条语句会一直卡住,直到Session 1提交/回滚或超时 -- (可能会报 ERROR 1205: Lock wait timeout exceeded)
-
MySQL 8.0的“不跟你玩了”选项:
MySQL 8.0给这些“急性子”的锁请求提供了两个新选项:NOWAIT和SKIP LOCKED。-
NOWAIT:“不等了,再见!”
如果在FOR UPDATE或FOR SHARE后面加上NOWAIT,当请求的行已被其他事务锁定时,查询不会等待,而是立即报错返回 (ERROR 3572)。-- ====MySQL 8.0 演示==== -- (前提同上,Session 1锁住了c1=2的行) -- Session 2: SELECT * FROM t1_80 WHERE c1 = 2 FOR UPDATE NOWAIT; -- ERROR 3572 (HY000): Statement aborted because lock(s) could not be acquired immediately and NOWAIT is set. -- 立刻报错,不墨迹!
-
SKIP LOCKED:“锁住的不要,剩下的都给我!”
如果加上SKIP LOCKED,当请求的行中有部分被锁定时,查询也不会等待,而是立即返回结果,但结果集中会自动跳过(不包含)那些被锁定的行。-- ====MySQL 8.0 演示==== -- (前提同上,Session 1锁住了c1=2的行) -- 假设t1表数据:(1,10), (2,60<-被锁), (3,50), (4,100), (5,80) -- Session 2: SELECT * FROM t1 FOR UPDATE SKIP LOCKED; -- 结果会是: -- (1,10) -- (3,50) -- (4,100) -- (5,80) -- c1=2那行被华丽丽地跳过了!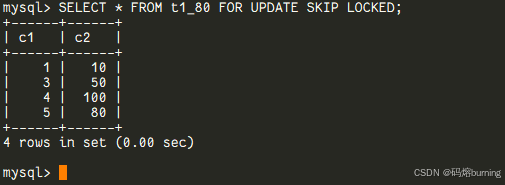
-
-
段子手辣评:
NOWAIT:“爷没工夫等你!要么立刻给锁,要么拉倒,我先走了!”
SKIP LOCKED:“锁住的都是‘烫手山芋’,我不要!把那些‘干净’的、没人抢的赶紧给我端上来!”
核心价值:- 提高并发处理能力:在高并发的“抢占式”场景(如任务队列、秒杀、抢票系统)中非常有用。
SKIP LOCKED可以让多个工作线程同时从任务表中获取未被其他线程锁定的任务进行处理,避免了线程间的无效等待。NOWAIT可以让应用快速知道资源是否可用,从而决定是重试、放弃还是走其他逻辑。
- 避免长时间阻塞:防止因为个别热点行被长时间锁定而导致大量请求堆积。
- 更灵活的并发控制:给了开发者在应用层面实现更精细化并发策略的能力。
- 提高并发处理能力:在高并发的“抢占式”场景(如任务队列、秒杀、抢票系统)中非常有用。
2.3 innodb_dedicated_server:“一键超频”模式?(小白慎用)🚀
-
“选择困难症”的福音?:
对于很多新手DBA或者开发者来说,面对MySQL(尤其是InnoDB)那一大堆复杂的配置参数(比如innodb_buffer_pool_size,innodb_log_file_size等),简直头大如斗,不知道该怎么调。 -
MySQL 8.0的“傻瓜式”优化:
MySQL 8.0引入了一个新参数innodb_dedicated_server(默认OFF)。如果你把它设置为ON,那么InnoDB会根据服务器上检测到的内存大小,自动配置一些关键参数,目标是尽可能多地利用系统资源来提升性能。- 比如,它可能会自动把
innodb_buffer_pool_size设置为一个接近总内存75%的值(具体比例取决于检测到的内存量),自动调整innodb_log_file_size等。
SHOW VARIABLES LIKE '%innodb_dedicated_server%'; -- 默认是OFF -- SET GLOBAL innodb_dedicated_server = ON; -- 需要在配置文件中修改并重启生效 - 比如,它可能会自动把
-
段子手辣评:
innodb_dedicated_server = ON:“别问我该调多少内存,也别问我日志文件该多大!只要你这台服务器是给MySQL‘包圆儿’的,我就帮你自动安排得明明白白,榨干每一滴性能!”
核心价值:- 简化配置:对于那些服务器专门用于运行单个MySQL实例的场景,这个参数可以大大简化初始配置的复杂度,避免因为参数设置不当(尤其是默认值偏低)导致的性能问题。
- 开箱即用高性能(理论上):在合适的环境下,能让MySQL启动后就处于一个相对较优的性能状态。
-
重要警告 ⚠️:
- “专用”是前提! 这个参数的“专用”(dedicated)两个字是灵魂!如果你的服务器上还跑了其他重要的应用程序,或者运行了多个MySQL实例,千万不要轻易开启这个参数! 否则,MySQL可能会“贪婪地”吃掉大部分系统资源,导致其他应用饿死,或者多实例之间互相“打架”。
- 不是万能丹:自动配置不一定永远是最佳配置。对于有经验的DBA来说,手动精调参数往往能达到更好的效果。这个参数更像是一个“快速启动”和“基础保障”。
2.4 死锁检查控制 (innodb_deadlock_detect):“高并发下的性能‘双刃剑’” ⚔️
-
死锁的“烦恼丝”:
死锁是并发系统中一个老生常谈的问题。InnoDB有自己的死锁检测机制,当检测到死锁时,它会自动回滚其中一个(通常是代价较小的)事务,打破死锁。这个检测过程本身是需要消耗CPU资源的。 -
MySQL 8.0的“鸵鸟策略”选项:
MySQL 8.0 (实际上从5.7.15开始) 增加了一个动态变量innodb_deadlock_detect(默认ON),允许你关闭InnoDB的死锁检测功能。SHOW VARIABLES LIKE '%innodb_deadlock_detect%'; -- 默认是ON -- SET GLOBAL innodb_deadlock_detect = OFF; -- 可以动态修改 -
为何要关闭?何时关闭?
- 性能考量:在极高并发、事务极短小、且业务逻辑设计上能够很大程度避免死锁的系统中,死锁检测本身可能成为一个性能瓶颈。因为每次加锁操作都可能触发一次潜在的死锁检测图遍历。如果死锁发生的概率远低于死锁检测的开销,关闭它可能会带来一些性能提升。
-
段子手辣评:
innodb_deadlock_detect = OFF:“死锁?什么死锁?我看不见,我听不见!只要我跑得够快,死锁就追不上我!出了问题?别找我,找innodb_lock_wait_timeout去!”
核心价值与巨大风险:- 潜在性能提升(特定场景):在上述极端条件下,可能榨取最后一点性能。
- 巨大风险:如果关闭了死锁检测,而你的应用又确实发生了死锁,那么这些死锁的事务将不会被自动回滚,它们会一直持有锁,直到达到
innodb_lock_wait_timeout设定的超时时间后才会因锁等待超时而失败。这期间,会造成大量的阻塞,甚至拖垮整个系统。
-
使用前提:
- 对业务代码和SQL有极强的信心,确信死锁发生概率极低。
- 必须配合调整
innodb_lock_wait_timeout:将其设置成一个非常短的值(比如几秒),以便在万一发生死锁时,能够快速让事务超时失败,而不是无限期地阻塞。 - 充分的压力测试和监控:在关闭前,务必进行详尽的测试。
- 一般不推荐关闭! 对于绝大多数应用,保持默认
ON是更安全的选择。优化业务逻辑和SQL来避免死锁,比关闭检测要靠谱得多。
性能篇的这些新特性,是不是让你感觉MySQL 8.0越来越像个“变形金刚”了?能文能武,能屈能伸!
第三章:数据字典与DDL篇——更“原子”更可靠的操作!⚛️🔩
数据字典(存储数据库元数据的地方)和DDL(数据定义语言,如CREATE, ALTER, DROP)操作的可靠性和原子性,对于数据库的稳定至关重要。MySQL 8.0在这方面也搞了不少“大动作”。
3.1 Undo文件独立自主,不再寄人篱下(系统表空间)🏠
-
曾经的“蜗居岁月”:
在MySQL 5.7及以前,Undo日志(用于事务回滚和MVCC)是存储在系统表空间(通常是ibdata1文件)中的。这会导致系统表空间容易膨胀,且管理不便。 -
MySQL 8.0的“分家单过”:
从MySQL 8.0开始,Undo日志默认会创建在独立的Undo表空间中(比如undo_001,undo_002等文件,默认创建2个)。 你可以在MySQL的数据目录下看到这些新面孔。 -
段子手辣评:
Undo日志:“以前我跟系统表空间挤一个大通铺,现在我终于有自己的独立小套间了!清爽!敞亮!想扩容想收缩(未来可能支持在线收缩),都方便多啦!”
核心价值:- 更好的空间管理:独立的Undo表空间可以更灵活地管理,避免系统表空间因Undo日志而过度膨胀。
- 性能潜力:未来可能支持更高级的Undo表空间操作,如在线收缩、移动等。
- 减少系统表空间IO压力:将Undo的IO从系统表空间分离出来。
3.2 MyISAM系统表“下岗再就业”,InnoDB全面接管!🔄
-
MyISAM的“历史包袱”:
在MySQL的早期版本中,很多系统表(存储在mysql数据库中,用于用户权限、存储过程、事件等元数据)都是使用MyISAM存储引擎的。MyISAM不支持事务,崩溃恢复能力也较弱,这给系统表的可靠性带来了一些隐患。 -
MySQL 8.0的“大一统”:
MySQL 8.0将所有系统表(包括数据字典表)都迁移到了InnoDB存储引擎。 这意味着,默认情况下,一个全新的MySQL 8.0实例将不再包含任何MyISAM表(除非你自己手动创建)。 -
段子手辣评:
InnoDB:“报告组织!系统表这块儿阵地,我已全面占领!从今往后,元数据的安全稳定,由我InnoDB保驾护航!MyISAM老哥?他可以安心退休,去享受‘非事务型’的悠闲生活了。”
核心价值:- ACID特性赋能系统表:系统表的修改也支持事务了,更可靠。
- 提升系统表崩溃恢复能力:InnoDB的崩溃恢复机制比MyISAM强太多。
- 统一存储引擎管理:简化了DBA的管理工作,不用再操心两种引擎的备份恢复和优化策略差异。
3.3 元数据存储“大搬家”,.frm文件成历史文物 🏛️
-
.frm的“峥嵘岁月”:
熟悉MySQL历史的同学都知道,以前每创建一个表,都会在对应的数据库目录下生成一个.frm文件,这个文件存储了表的结构定义(元数据)。这种基于文件的元数据存储方式,在某些情况下(比如DDL操作的原子性、崩溃恢复)会比较脆弱。 -
MySQL 8.0的“中央集权”:
在MySQL 8.0中,.frm文件彻底消失了! 所有表的元数据现在都统一存储在InnoDB引擎内部的事务性数据字典表中(这些表本身也位于mysql.ibd这个新的系统表空间文件中)。
(上图显示了数据库目录下没有了.frm文件) -
段子手辣评:
.frm文件:“我曾是表结构的‘身份证’,风光无限。如今廉颇老矣,被统一收编进‘数据字典大厦’集中管理了。也好,以后再也不用担心DDL操作搞到一半,我和表数据‘失联’了。”
核心价值:- 支持原子DDL:这是实现原子DDL(下面会讲)的基础。元数据和数据的变更可以在同一个事务中进行。
- 更可靠的元数据管理:事务性的数据字典比文件系统更不容易损坏。
- 查询元数据更快:通过SQL查询数据字典表,可能比以前解析
.frm文件更快、更方便。 - 减少文件系统依赖:降低了因文件系统层面的问题导致元数据不一致的风险。
3.4 自增(AUTO_INCREMENT)值“刻骨铭心”,重启不“失忆”!🧠🔒
-
重启“失忆”的痛:
在MySQL 5.7及更早版本中,InnoDB表的AUTO_INCREMENT计数器是存储在内存中的。当你执行DELETE FROM table WHERE id = MAX(id),然后再插入新数据,新ID会从MAX(id) + 1开始。但如果此时你重启MySQL服务器,AUTO_INCREMENT计数器会根据表中当前实际的最大ID值重新初始化为MAX(id) + 1。
这意味着,如果你删除了表中ID最大的几条记录,然后重启了MySQL,之后再插入新数据时,可能会重新使用那些你刚刚删除过的ID值!这在某些业务场景下(比如依赖ID的唯一性做某些外部关联)可能会导致数据冲突或逻辑错误。这个问题在MySQL的bug系统里存在已久 (Bug #199)。-- ====MySQL 5.7 演示==== CREATE TABLE t_57 (id INT AUTO_INCREMENT PRIMARY KEY, c1 VARCHAR(20)); INSERT INTO t_57 (c1) VALUES ('zhuge1'), ('zhuge2'), ('zhuge3'); -- id为1,2,3 DELETE FROM t_57 WHERE id = 3; -- 现在最大id是2 -- 此时重启MySQL 5.7服务 INSERT INTO t_57 (c1) VALUES ('zhuge4'); -- 新插入的id会是3! (因为重启后按MAX(id)+1初始化) -- 如果你再手动把某条记录的id改成5 (比如 UPDATE t SET id = 5 WHERE c1 = 'zhuge1';) -- 然后再插入 INSERT INTO t_57 (c1) VALUES ('zhuge5'); 此时id可能变成4 -- 再插入 INSERT INTO t_57 (c1) VALUES ('zhuge6'); 可能就报主键冲突了(如果前面改的5正好是下一个要生成的)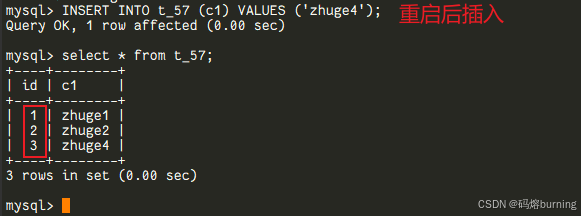
-
MySQL 8.0的“持久化记忆”:
从MySQL 8.0开始,AUTO_INCREMENT计数器的当前值会被持久化(写入Redo Log并在Checkpoint时更新到数据字典)。这意味着,即使MySQL重启,它也能准确地记住上次分配到的ID值,并从那个值继续往上增,而不会因为表中最大ID的变化而“回退”。-- ====MySQL 8.0 演示==== CREATE TABLE t_80 (id INT AUTO_INCREMENT PRIMARY KEY, c1 VARCHAR(20)); INSERT INTO t_80 (c1) VALUES ('zhuge1'), ('zhuge2'), ('zhuge3'); -- id为1,2,3 DELETE FROM t_80 WHERE id = 3; -- 现在最大id是2,但计数器可能仍然认为是3或更高 -- 此时重启MySQL 8.0服务 INSERT INTO t_80 (c1) VALUES ('zhuge4'); -- 新插入的id会是4! (而不是3,它记得上次分配到3了) -- 后续操作也不会轻易出现ID“回退”或意外冲突的问题。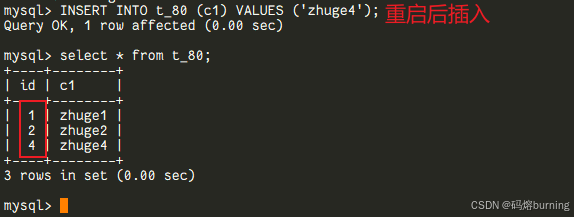
-
段子手辣评:
MySQL 5.7的自增ID:“哎呀,重启了一下,我好像忘了刚才数到几了?哦,看看现在最大的号是多少,我从它下一个开始吧!”
MySQL 8.0的自增ID:“重启?小场面!我用小本本(Redo Log)都记着呢,上次数到N,这次就从N+1开始,绝不含糊!”
核心价值:- 更可靠的ID生成:避免了因重启导致的自增ID“回退”和潜在的数据冲突。
- 行为更可预测:
AUTO_INCREMENT的行为不再受当前表中最大值的影响(除非是ALTER TABLE重置)。 - 解决了多年的一个痛点,提升了数据一致性的保障。
3.5 DDL操作“原子化”——要么全成,要么全败!⚛️✅
-
DDL的“半途而废”风险:
在MySQL 8.0之前,很多DDL操作(比如DROP TABLE t1, t2;)并不是原子的。如果t1存在但t2不存在,执行这条语句时,t1可能会被成功删除,然后因为找不到t2而报错。结果就是,一个DDL语句执行了一半,留下一个不完整的状态。这对于需要精确控制schema变更的场景来说,是个不大不小的麻烦。-- ====MySQL 5.7 演示==== -- 假设表t1_57存在,表t2不存在 SHOW TABLES; -- 显示有t1_57 DROP TABLE t1_57, t2; -- ERROR 1051 (42S02): Unknown table 'test.t2' -- 报错了 SHOW TABLES; -- 再次查看,发现t1已经被删除了!DDL没有回滚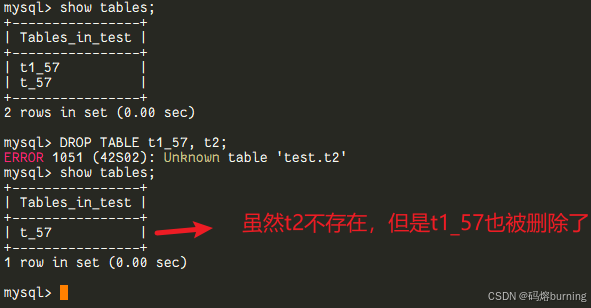
-
MySQL 8.0的“说到做到,不成拉倒”:
MySQL 8.0对很多DDL操作(特别是针对InnoDB存储引擎的表)实现了原子性。这意味着,一个DDL语句要么完全成功执行,要么在执行过程中遇到任何错误就完全回滚,数据库状态恢复到DDL执行前的样子。
这得益于前面提到的,元数据也存储在事务性的数据字典中了。-- ====MySQL 8.0 演示 (来自用户提供的 "MySQL8.0新特性.md" 文件)==== -- 假设表t1_80存在,表t2不存在 SHOW TABLES; -- 显示有t1_80 DROP TABLE t1_80, t2; -- ERROR 1051 (42S02): Unknown table 'test.t2' -- 同样报错 SHOW TABLES; -- 再次查看,发现t1依然存在!DDL成功回滚了!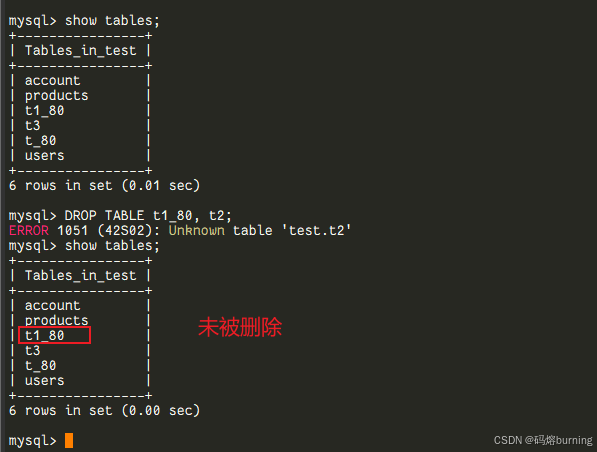
支持原子DDL的操作包括:数据库、表空间、表、索引的
CREATE、ALTER、DROP以及TRUNCATE TABLE;存储过程、触发器、视图、UDF的CREATE、DROP、ALTER;用户和角色的CREATE、ALTER、DROP、RENAME等。 -
段子手辣评:
MySQL 5.7的DDL:“我先干着,干到哪儿算哪儿,中间出错了?前面的我也懒得管了,你自己收拾烂摊子吧!”
MySQL 8.0的DDL:“要么把事儿漂漂亮亮办完,要么就当啥也没发生过!我,MySQL 8.0 DDL,讲究!”
核心价值:- Schema变更更安全可靠:大大降低了因DDL执行失败导致数据库schema处于不一致状态的风险。
- 简化错误处理:应用程序在执行DDL时,如果失败了,不需要再费心去判断哪些部分成功了哪些失败了,可以直接认为操作未生效。
- 提升DBA操作信心:执行复杂DDL时更有底气。
3.6 参数修改“持久化” (SET PERSIST):“改完配置不用慌,重启依然是你样!”💾🔄
-
SET GLOBAL的“临时工”身份:
DBA们经常需要在线调整MySQL的全局参数,比如用SET GLOBAL max_connections = 1000;。但这种修改是“临时”的,只在当前MySQL实例的生命周期内有效。一旦MySQL重启,这些在线修改的参数值就会丢失,MySQL会重新从my.cnf(或my.ini)配置文件中加载参数。要想让修改永久生效,还得手动去改配置文件,然后再找机会重启服务,比较繁琐。 -
MySQL 8.0的“记忆药水”——
SET PERSIST:
MySQL 8.0提供了一个新命令SET PERSIST,它不仅能在线修改全局参数(效果类似SET GLOBAL),还能把这个修改自动持久化到一个名为mysqld-auto.cnf的新配置文件中(通常位于数据目录下)。
当MySQL重启时,它会先读取my.cnf,然后再读取mysqld-auto.cnf。如果同一个参数在两个文件中都有配置,那么mysqld-auto.cnf中的值会覆盖my.cnf中的值(优先级更高)。-- 假设当前 innodb_lock_wait_timeout 是默认的50秒 SET PERSIST innodb_lock_wait_timeout = 25; -- 在线修改并持久化 -- MySQL会在数据目录下生成或更新 mysqld-auto.cnf 文件。 -- 内容类似这样 (JSON格式): -- { -- "Version": 1, -- "mysql_server": { -- "innodb_lock_wait_timeout": { -- "Value": "25", -- "Metadata": { -- "Timestamp": 1675290252103863, -- 修改时的时间戳 -- "User": "root", -- 修改者 -- "Host": "localhost" -- 修改主机 -- } -- } -- } -- } -- 如果只想持久化,不立即在当前实例生效,可以用 SET PERSIST_ONLY ... -- SET PERSIST_ONLY max_connections = 1200; -- 如何清除 mysqld-auto.cnf 中的持久化设置? -- RESET PERSIST innodb_lock_wait_timeout; -- 清除特定参数的持久化设置 -- RESET PERSIST; -- 清除所有参数的持久化设置(清空mysqld-auto.cnf) -
段子手辣评:
SET GLOBAL:“我只是个临时工,重启就跟我没关系了哈!”
SET PERSIST:“领导放心!您吩咐的,我不仅当场办了,还写进了‘备忘录’(mysqld-auto.cnf),下次开机保证还是这个样!”
核心价值:- 在线持久化配置:无需手动修改
my.cnf和计划重启,就能安全地在线调整并固化全局参数,大大提升了运维的灵活性和便捷性。 - 配置变更可追溯:
mysqld-auto.cnf中记录了修改的时间、用户和主机,方便审计。 - 避免配置漂移:防止在线修改的参数在重启后意外丢失,导致性能问题或行为不一致。
- 在线持久化配置:无需手动修改
数据字典和DDL的这些改进,让MySQL 8.0在“修炼内功”的道路上又前进了一大步,变得更加稳健和可靠。
第四章:SQL新玩法——窗口函数与字符集进化 📊🥳
除了底层优化,MySQL 8.0在SQL语言层面也引入了一些激动人心的新功能,尤其是窗口函数,简直是数据分析人员的“大杀器”!
4.1 窗口函数 (Window Functions):“数据分析师的瑞士军刀!”🔪
-
曾经“望洋兴叹”的复杂分析:
在MySQL 8.0之前,如果你想进行一些稍微复杂点的分析查询,比如计算排名、累计总和、同比环比等,往往需要写非常复杂的自连接查询、嵌套子查询,或者把数据拖到应用层去处理。SQL写起来费劲,跑起来也慢。 -
MySQL 8.0的“降维打击”:
MySQL 8.0终于正式支持了SQL标准中的窗口函数(也叫分析函数)。这玩意儿,简单来说,就是允许你在当前行的“上下文窗口”内进行计算,而不需要像GROUP BY那样把多行聚合成一行。
它的标志性语法就是聚合函数(如SUM(),COUNT(),AVG()等)或专用窗口函数(如ROW_NUMBER(),RANK()等)后面跟一个OVER()子句。OVER()子句可以定义分区(PARTITION BY)和排序(ORDER BY)来控制计算的“窗口”范围。基本用法:
SUM(balance) OVER (PARTITION BY name):计算每个name分组下的balance总和,并将这个总和作为新的一列附加到每一行。原始行数不变。ROW_NUMBER() OVER (ORDER BY balance DESC):对所有行按balance降序进行排名,生成一个从1开始的连续序号。
示例表
account_channel:CREATE TABLE `account_channel` ( `id` int NOT NULL AUTO_INCREMENT, `name` varchar(255) DEFAULT NULL COMMENT '姓名', `channel` varchar(20) DEFAULT NULL COMMENT '账户渠道', `balance` int DEFAULT NULL COMMENT '余额', PRIMARY KEY (`id`) ); INSERT INTO `account_channel` VALUES (1,'zhuge','wx',100),(2,'zhuge','alipay',200),(3,'zhuge','yinhang',300),(4,'lilei','wx',200),(5,'lilei','alipay',100),(6,'hanmeimei','wx',500);普通聚合 vs 窗口函数:
-- 普通GROUP BY,结果只有3行 SELECT name, SUM(balance) FROM account_channel GROUP BY name;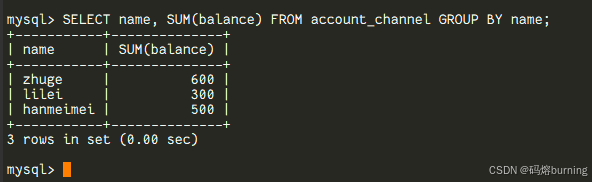
-- 使用窗口函数SUM() OVER(),结果还是6行,但多了每个人的总余额 SELECT name, channel, balance, SUM(balance) OVER (PARTITION BY name) AS total_balance_for_name FROM account_channel;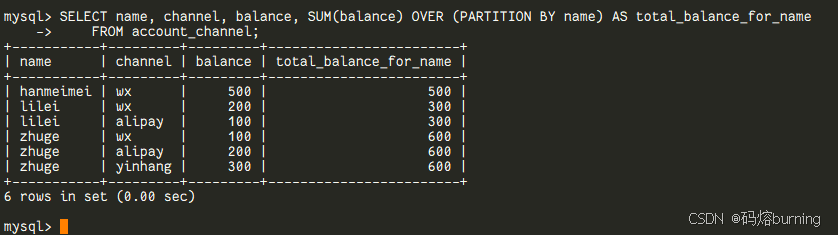
窗口函数还可以带排序,实现“累计”效果:
-- 计算每个人按渠道余额排序后的累计余额 SELECT name, channel, balance, SUM(balance) OVER (PARTITION BY name ORDER BY balance ASC) AS cumulative_balance FROM account_channel; -- +-----------+---------+---------+--------------------+ -- | name | channel | balance | cumulative_balance | -- +-----------+---------+---------+--------------------+ -- | hanmeimei | wx | 500 | 500 | -- | lilei | alipay | 100 | 100 | -- lilei的第1笔 -- | lilei | wx | 200 | 300 | -- lilei的100+200 -- | zhuge | wx | 100 | 100 | -- zhuge的第1笔 -- | zhuge | alipay | 200 | 300 | -- zhuge的100+200 -- | zhuge | yinhang | 300 | 600 | -- zhuge的300+300 -- +-----------+---------+---------+--------------------+
如果
OVER()里啥也不加,就是对整个结果集进行操作:-- 计算所有人的总余额,并附加到每一行 SELECT name, channel, balance, SUM(balance) OVER () AS grand_total_balance FROM account_channel; -- ...每一行的 grand_total_balance 都是 1400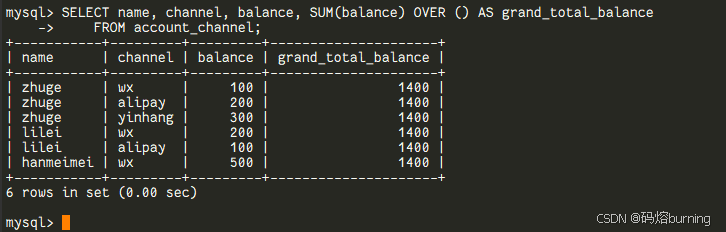
专用窗口函数:
除了常见的聚合函数可以配合OVER()使用外,还有很多专用的窗口函数:- 序号函数:
ROW_NUMBER()(不重复排名),RANK()(并列跳号排名),DENSE_RANK()(并列不跳号排名) - 分布函数:
PERCENT_RANK()(百分比排名),CUME_DIST()(累积分布) - 前后函数:
LAG(col, N, default)(取上前N行的col值),LEAD(col, N, default)(取下后N行的col值) - 头尾函数:
FIRST_VALUE(col)(取分区内排序后的第一个col值),LAST_VALUE(col)(取分区内排序后的最后一个col值) - 其它:
NTH_VALUE(col, N)(取分区内排序后的第N个col值),NTILE(N)(将分区数据切分成N个桶)
序号函数示例:
-- 按余额排名 SELECT name, channel, balance, ROW_NUMBER() OVER (ORDER BY balance ASC) AS row_num, -- 连续排名 RANK() OVER (ORDER BY balance ASC) AS rnk, -- 跳跃排名(如有并列) DENSE_RANK() OVER (ORDER BY balance ASC) AS dense_rnk -- 连续排名(如有并列) FROM account_channel; -- 假设数据有 (A,100), (B,100), (C,200) -- row_num: 1, 2, 3 -- rnk: 1, 1, 3 (100并列第1,下一个200是第3) -- dense_rnk:1, 1, 2 (100并列第1,下一个200是第2)(上面示例根据文档中
row_number()的例子 和对RANK/DENSE_RANK的理解进行了扩充) -
段子手辣评:
窗口函数:“以前你们想做个复杂报表,得写几百行SQL,还得求爷爷告奶奶让DBA给跑。现在,我来了!排名、占比、同比环比、移动平均…一行OVER()子句,轻松搞定!腰不酸了,腿不疼了,写SQL也有劲儿了!”
核心价值:- 大大简化复杂分析查询的SQL编写难度。
- 提升分析查询的执行效率(相比于冗长的自连接和子查询)。
- 让数据库承担更多的计算任务,减轻应用层的压力。
- 解锁了许多以前在MySQL中难以实现或效率低下的查询模式。数据分析和报表开发的“超级福音”!
4.2 默认字符集“鸟枪换炮”:latin1再见,utf8mb4你好!🌏😊
-
latin1的“历史局限”与utf8mb3的“尴尬”:
在MySQL 8.0之前,默认的字符集是latin1(ISO-8859-1),这对于存储中文、日文、韩文以及各种奇奇怪怪的emoji表情来说,简直是“灾难”,各种乱码问题层出不穷。
后来大家开始用utf8,但MySQL中的utf8实际上是utf8mb3的别名,它只用了1到3个字节来编码字符,这意味着它无法存储需要4个字节的Unicode字符,比如很多emoji表情 (😂👍🎉) 和一些生僻汉字。 -
MySQL 8.0的“国际范儿”:
从MySQL 8.0开始,默认字符集和默认排序规则都改成了utf8mb4和utf8mb4_0900_ai_ci。utf8mb4使用1到4个字节编码,能够完美支持包括emoji在内的所有Unicode字符。并且,现在utf8也直接作为utf8mb4的别名了。 -
段子手辣评:
MySQL 5.7:“中文?Emoji?那是什么?我只认识拉丁字母和一些符号…啥?你非要存?行吧,你用utf8mb4,但别怪我默认不支持哈!”
MySQL 8.0:“你好世界!こんにちは!안녕하세요!😂👍🎉 所有语言,所有表情,放马过来!我,utf8mb4,默认罩着你!”
核心价值:- 开箱即用地支持全球化字符和emoji,大大减少了新项目因字符集配置不当导致的乱码问题。
- 简化了字符集选择,对于新项目,直接使用默认的
utf8mb4通常就是最佳实践。 - 与时俱进,更好地适应了现代互联网应用对多语言和富文本内容的需求。
第五章:日志系统的小调整 📝
日志系统是MySQL的“黑匣子”和“飞行记录仪”,8.0也对它进行了一些微调。
5.1 Binlog日志过期更“精准”,精确到秒!⏱️
-
expire_logs_days的“粗线条”:
在8.0之前的版本,如果你想让MySQL自动清理旧的二进制日志(Binlog),你用的是expire_logs_days参数,它指定了Binlog文件保留的天数。这个单位是“天”,对于某些需要更精细控制Binlog磁盘占用的场景,可能不够灵活。 -
MySQL 8.0的“秒级掌控”:
MySQL 8.0引入了一个新参数binlog_expire_logs_seconds,允许你以秒为单位来设置Binlog的过期时间。expire_logs_days参数在8.0中已被标记为“过时”(但为了兼容性可能依然有效,只是优先使用新参数)。
默认情况下,binlog_expire_logs_seconds的值是 2592000 秒,也就是30天。 -
段子手辣评:
Binlog:“以前我按天‘退休’,现在我能按秒‘掐点下班’了!老板想让我多干几分钟或者少待一会儿,都好商量!”
核心价值:- 更精细化的Binlog保留策略:可以更准确地控制Binlog占用的磁盘空间,尤其是在Binlog产生速度非常快的系统中。
- 灵活适应不同的备份和恢复需求。
总结:MySQL 8.0 —— 是时候拥抱变化,迎接“真香”了!🌟
哇塞!一口气盘了这么多MySQL 8.0的“黑科技”和“贴心小棉袄”,是不是感觉信息量有点大,但又有点小兴奋?😂
从“真·降序索引”到“隐身索引”,从“函数索引”到“窗口函数”,从“原子DDL”到“自增持久化”,再到各种性能和易用性上的改进……MySQL 8.0可以说是在努力地让自己变得更强、更快、更稳、更智能、也更懂开发者。
当然,任何版本的升级都伴随着学习成本和潜在的兼容性风险(虽然MySQL在这方面已经做得很好了)。但从长远来看,拥抱MySQL 8.0带来的这些新特性,无疑能让你的数据库应用开发和运维工作如虎添翼,效率倍增。
给船长们的最后忠告:
- 别只看不练:光看“航海图”是学不会开船的。赶紧找个测试环境,把这些新特性操练起来!
- 小步快跑,大胆假设,小心求证:升级有风险,操作需谨慎。充分测试,逐步迁移。
- 官方文档是永远的“灯塔”:遇到疑惑,多查官方手册,那里的信息最权威。
好了,今天的“MySQL 8.0新特性吐槽大会(暨大型种草现场)”就到这里了!希望各位船长在MySQL 8.0这片更广阔的“新大陆”上,能够乘风破浪,挖掘出更多的宝藏!
如果觉得这篇“万字相声”对你有所帮助,别忘了点赞、收藏、转发,让更多的小伙伴加入我们的“8.0探索小分队”!有任何关于MySQL 8.0的问题、心得或者独门秘籍,也热烈欢迎在评论区激情开麦,咱们一起交流,共同进步!👋😉

















 2698
2698

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









