







摘要:
我们提出了用于社交媒体营销的图模式关联规则(GPAR)。 GPAR 扩展了项集的关联规则,帮助我们发现社交图中实体之间的规律,并通过探索社会影响力来识别潜在客户。我们研究发现topk多样化GPAR的问题。虽然这个问题是 NP 难题,但我们开发了一种具有精度限制的并行算法。我们还研究了利用 GPAR 识别潜在客户的问题。虽然它也是 NP 难的,但我们提供了一种并行可扩展算法,可以保证随着处理器的增加,相对于顺序算法的多项式加速。使用现实生活和合成图,我们通过实验验证了算法的可扩展性和有效性。
1. INTRODUCTION
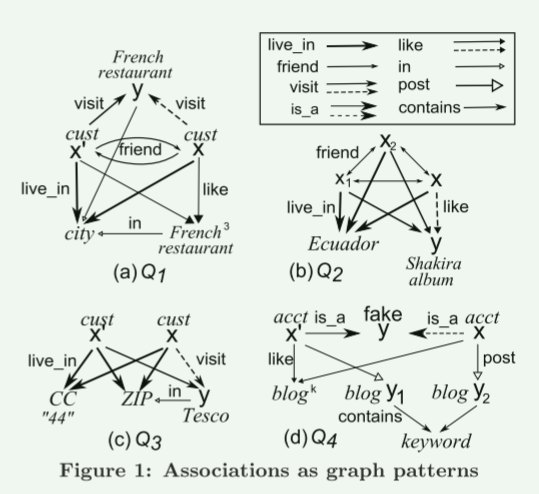
示例1:
(1) 社交图的关联规则是在图上而不是在项集上定义的。下面是一个例子。 ◦ 如果 (a) x 和 x′ 是住在同一个城市 c 的朋友,(b) c 中至少有 3 家 x 和 x′ 都喜欢的法国餐厅,并且如果 (c) x′ 访问一家新开的法国餐厅c 中的餐厅 y,则 x 也可能访问 y。
该规则的前件可以表示为图1(a)所示的图模式Q1(具有实线边缘),后件由虚线边缘visit(x,y)表示。 Q1 的简洁表示将整数 3 与“法国餐厅”相关联,以指示它的 3 个副本。与传统的关联规则不同,Q1 指定条件作为拓扑约束:客户之间的边(朋友关系)、客户和餐馆之间的边(喜欢、访问)、城市和餐馆之间的边(in)以及城市和客户之间的边(居住)。
在社交图G中,对于通过图模式匹配满足先行词Q1的x和y,我们可以将y推荐给x。
(2) 与项目集规则相反,社交图关联规则可能针对具有多个实体的社交群体: ◦ 如果 (a) x、x1 和 x2 是朋友,(b) 他们都住在厄瓜多尔,并且 (c) 如果x1,x2都喜欢夏奇拉的专辑y(哥伦比亚歌手),那么x可能也喜欢y。
该规则如图1(b)所示,其中图形模式Q2(不包括虚线边缘)指定(x,y)的条件作为前件,而像(x,y)这样的虚线边缘表示其结果。我们可以使用该规则来识别潜在客户 x 或 y,其特征是由三名成员组成的社交群体。
(3) 具有图模式的关联规则可以方便地扩展社交网络环境中的数据依赖关系,例如条件函数依赖关系(CFD)。 ◦ 如果 x 和 x′ 的地址具有相同的国家代码“44”和相同的邮政编码,并且如果 x′ 在具有相同邮政编码的 Tesco 商店 y 购物,则 x 也可能在 y 购物。
这样的规则(图 1(c))在其模式 Q3 中嵌入了相应的 CFD,表明如果 x 和 x′ 居住在英国,具有相同的邮政编码,那么他们就住在同一条街道上。该规则在英国有效,其中邮政编码决定街道。
(4)关联规则的应用不限于营销活动。他们还帮助我们检测诈骗。例如,下面的规则用于识别虚假帐户。 ◦ 如果 (a) 帐户 x′ 被确认是假的,(b) x 和 x′ 都像博客 P1,.... ,Pk,(c) x 发布博客 y1,(d) x′ 发布 y2,以及 (e) 如果 y1 和 y2 包含相同的特定内容(关键字),则 x 很可能是假帐户。
如图1(d)所示,其前件由图模式Q4给出(不包括虚线边缘),其结果是虚线边缘是a(x,fake)。在社交图 G 中,规则是识别虚假帐户的嫌疑人,即满足模式 Q4 的结构约束的帐户 x。
在社交媒体营销、社区结构分析、社交推荐、知识提取和链接预测中,对图模式关联规则(GPAR)的需求是显而易见的。然而,此类规则背离了项集的关联规则,并引入了一些挑战。 (1) 传统的支持度和置信度指标不再适用于 GPAR。 (2)传统规则和频繁图模式的挖掘算法不能用于发现实用的多样化GPAR。 (3) GPAR 的一个主要应用是识别社交图中的潜在客户。这是昂贵的:通过子图同构进行图模式匹配是很棘手的。更糟糕的是,现实生活中的社交图谱通常很大,例如 Facebook 拥有 131 亿个节点和 1 万亿个链接。
贡献:
(1)我们引入了社交媒体营销的图形模式关联规则(GPAR)(第 2 节)。 GPAR 在语法和语义上都不同于项集的常规规则。 GPAR 将其先行词定义为图模式,指定社交图中实体之间的关联,并探索社交链接、影响力和推荐。它通过值绑定(例如“44”)和子图同构的拓扑约束来强制执行条件。
(2) 我们定义 GPAR 的拓扑支持和置信度度量(第 3 节)。对项集的传统支持对于 GPAR 来说不再是反单调的。我们通过修改[7]提出的措施来定义不同“潜在客户”的支持。我们通过修改贝叶斯因子[31]以纳入局部封闭世界假设[11, 17],提出了 GPAR 的置信度度量。这使我们能够处理(不完整的)社交图,并识别具有相关前因和后果的有趣 GPAR。
(3)我们研究了一个新的挖掘问题,称为多样化挖掘问题,用DMP表示(第4节)。发现 top-k GPAR 是一个双标准优化问题。虽然 DMP 很有用,但它是 NP 难的。尽管如此,我们开发了一种具有恒定精度范围的并行近似算法。我们还提供优化方法来尽早过滤冗余或无希望的规则。
(4)我们还研究了如何应用GPAR来识别潜在客户,称为实体识别问题,用EIP表示(第5节)。给定社交图 G 和与事件 p(x, y) 相关的 GPAR 集合 Σ,我们通过使用 Σ 中的 GPAR,以高于给定界限 η 的置信度识别 G 中 y 的潜在客户 x。我们证明,甚至决定这样的 x 是否存在也是 NP 困难的。
(5) 使用现实生活和合成图,我们通过实验验证了我们算法的可扩展性和有效性(第 6 节)。我们发现以下内容。 (a) 我们的 DMP 和 EIP 算法随着处理器 (n) 的增加而很好地扩展:当 n 从 4 增加到 20 时,它们在现实社交网络上的平均速度分别快了 3.2 和 3.53 倍。(b)在大型图上工作得相当好:DMP 在具有 3000 万个节点和边的图上花费不到 9 分钟(533.2 秒),而 EIP 在具有 1.5 亿个节点和 24 个 GPAR 的边的图上花费 45 秒, 20 个处理器。 (c) DMP 算法从现实生活中的社交图中找到有趣的 GPAR。 (d) 我们的优化方法是有效的:它们在现实图表上分别将 DMP 和 EIP 处理速度提高了 1.52 倍和 1.27 倍。因此,尽管 GPAR 很复杂,但通过并行化在实践中应用和发现 GPAR 是可行的。
相关工作:
Association rules.在[4]中介绍,关联规则是在交易数据的关系上定义的。先前关于社交网络关联规则 [41] 和 RDF 知识库的工作诉诸于从社交图中提取属性的元组上挖掘传统规则和 Horn 规则(作为连接二元谓词)[17],而不是利用图模式。虽然[6]通过图模式研究时间相关规则,但它侧重于演化图,因此采用不同的语义来提供支持和置信度。
GPAR 将关联规则从关系扩展到图。 (a) 它需要拓扑支持和置信度度量。此外,不完整的信息在社交图中很常见[11, 17],必须纳入指标中。 (b) GPAR 使用同构函数进行解释,因此不能表示为联合查询,联合查询不支持函数所需的否定或不等式。 (c) 应用 GPAR 成为大图中多模式查询处理的一个棘手问题。 (d) 挖掘(多样化)GPAR 超出了项目集的规则挖掘[46]。
Graph pattern mining.图数据库中已有模式挖掘算法[22,24](有关调查,请参阅[25])。大规模挖掘技术也在单个图中进行了研究 [13],特别是 top-k 算法 [16,27,42,44]。为了降低成本,可以采用可扩展的子图同构算法(例如[38])来生成模式候选。那里没有研究图形模式的多样性。
然而,(a) 图数据库 [24,27] 上的模式挖掘不能用于挖掘 GPAR,因为它们的反单调属性在单个图中不成立 [25]。 (b) 虽然挖掘单图仅基于同构计数 [13],但除 [16,44] 之外,DMP 是 GPAR 置信度和多样性的双标准优化问题。我们不知道之前有关于发现多样化图模式的工作。
Graph pattern matching.已经开发了几种用于子图同构的并行算法,例如[28,37,38],以及用于多模式优化的并行算法,例如[23,32]。我们的 EIP 算法与之前的工作有以下不同之处。 (a) EIP 不是枚举同构匹配,而是在找到一个匹配后识别潜在客户,并计算其相关置信度。也就是说,EIP 超越了传统的子图
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









