







目录
2. FUNDAMENTALS AND PRELIMINARY CONCEPTS
3. MATRIX FACTORIZATION BASED IMC(基于矩阵分解的IMC)
4. KERNEL LEARNING BASED IMC(基于内核学习的IMC)
5.GRAPH LEARNING BASED IMC(基于图学习的IMC)
6.DEEP LEARNING BASED IMC(基于深度学习的IMC)
写在前面(知识补充)
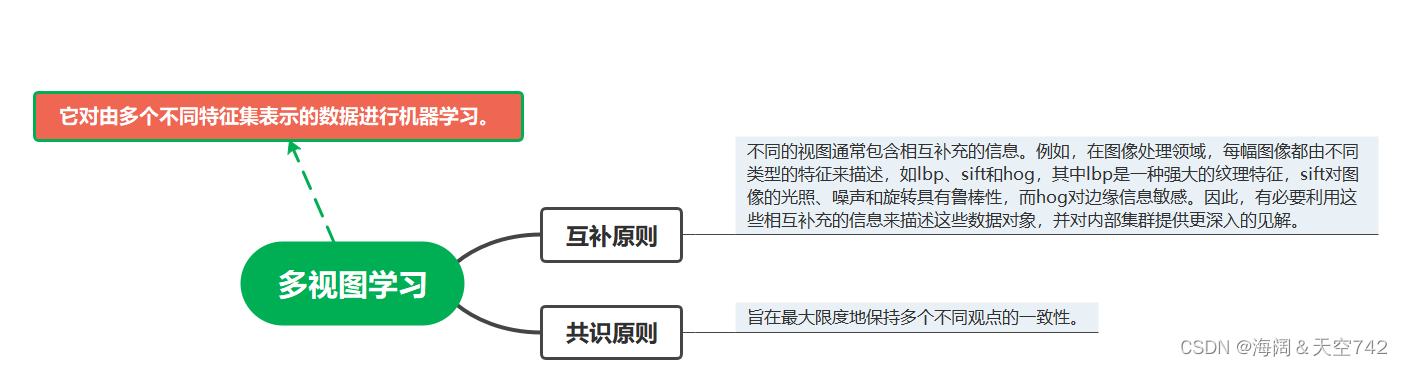
多视图学习:多视图学习也称作多视角学习(Multi-view learning)是陶大成提出的一个研究方向。在实际应用问题中,对于同一事物可以从多种不同的途径或不同的角度进行描述,这些不同的描述构成了事物的多个视图。事物的多视图数据在真实世界中广泛存在并且影响着人们生活的方方面面。例如:在与人们生活息息相关的互联网中,网页数据既可以用网页本身包含信息的特征集描述,也可以用超链接包含的信息描述。此外,同一事物由于数据采集方式不同,也可以有不同的表达方法。例如:使用不同传感器采集一个人的指纹就形成了多种不同的印痕,构成了指纹数据的多个视图。
多视图学习:引入了一个函数去模型化一个特定的视角,并且利用相同输入的冗余视角去联合优化所有函数,最终提高学习效果。其包含2个原则
0.Abstract
动机(提出问题)
传统的多视图聚类基于所有视图都被完全观察到的假设,试图将数据划分到各自的组中。然而,在疾病诊断、多媒体分析和推荐系统等实际应用中,通常会观察到在许多情况下并非所有样本视图都可用,这导致了传统的多视图聚类方法的失败。
引出的定义:对这种不完整的多视图数据进行聚类称为不完整的多视图聚类。
聚类就是依据给定的相似性度量,将无标记的数据集样本划分成若干个子集或簇,使得簇内相似度和簇间相异度最大。多视图聚类的目标是利用多视图数据中的一致和互补信息对数据进行聚类并得到更好的聚类结果。如何通过分析结合不同视图的信息,减少视图样本缺失造成的影响,达到更好的学习效果就是不完整多视图聚类(Incomplete Multi-view Clustering,IMC)的目标。
我们的工作(对于近期关于IMC研究的汇总):鉴于广阔的应用前景,不完全多视图聚类的研究近年来取得了显着进展。然而,没有调查总结当前的进展并指出未来的研究方向。为此,我们回顾了最近对不完整多视图聚类的研究。重要的是,我们提供了一些框架来统一相应的不完整的多视图聚类方法, 并从理论和实验的角度对一些有代表性的方法进行了深入的对比分析。
1.Introduction
近年来,从不同来源收集的多视图数据随处可见。如图 1 所示,医生通常结合磁共振成像 (MRI)、正电子发射断层扫描 (PET) 和脑脊液 (CSF) 的信息来诊断阿尔茨海默病 。通过不同的特征提取器获得的特征,例如纹理、颜色和局部二值模式,也可以被视为图像的不同视图。一般来说,不同的观点不仅包含互补信息和一致信息,而且还存在许多冗余信息和不一致信息。这表明在实际应用中将不同的视图堆叠成一个长向量或单独处理这些视图并不是一个好的方法。为了解决这个问题,研究多视图学习出现,旨在针对不同任务共同探索多个视图的信息。
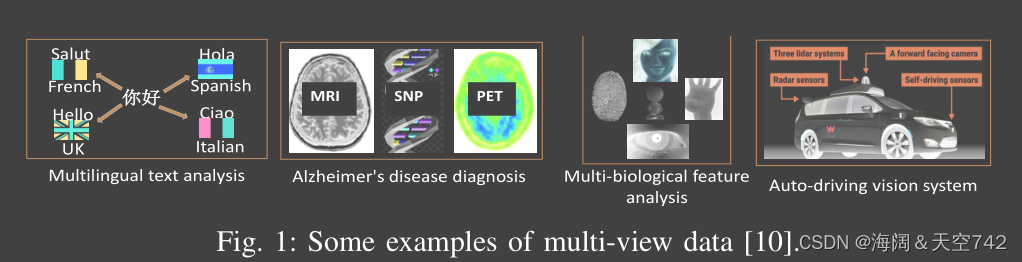
在过去的几十年中,基于所有视图都被完全观察到的共同假设,提出了许多多视图聚类方法。然而,在当今的许多实际应用中,要处理的多视图数据通常是不完整的,即一些样本并不具有所有视图。例如,由于患者脱落和数据质量差,一些与 PET 和 CSF 对应的图像对于某些个体不可用,这会生成不完整的阿尔茨海默病多视图数据。当某些视图丢失时, 多视图的自然对齐属性将被严重破坏,不利于互补信息和一致性信息的挖掘。此外,观点的缺失导致了严重的信息丢失,加剧了不同观点之间的信息不平衡。这些表明不完全学习问题具有挑战性。在多视图聚类领域,对这种不完整的多视图数据进行聚类称为不完整多视图聚类(IMC)。
对于IMC,两种朴素的方法是:
1.删除具有缺失视图的样本,然后对具有完整观察视图的剩余样本执行聚类。
缺点:违背了聚类的目的,聚类的目的是将所有数据点划分到各自的集群中。
2.将缺失视图设置为0或平均实例,然后通过传统的多视图聚类方法处理数据。
缺点:填充的缺失实例将在聚类过程中起到负面作用,因为填充在同一个向量中的所有缺失实例 将自然地分割到同一个簇中。在缺失视图率很高的情况下,性能很差。
两种较先进的方法
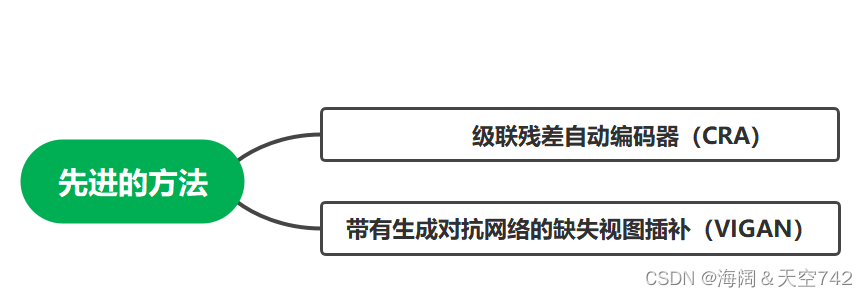
CRA堆叠了许多残差自动编码器,并通过最小化预测和原始数据之间的残差来恢复丢失的视图。VIGAN结合了去噪自动编码器和生成对抗网络(GAN),其中去噪自动编码器用于根据GAN的输出重建缺失的视图。(不适合处理多于三个视图的不完整数据。此外,恢复丢失的视图是解决不完整学习问题的一种很有前途的方法,但性能将在很大程度上取决于恢复数据的质量。)
现有方法的分类:现有的IMC方法可以从不同的角度进行分类。例如,从“缺失视图恢复”的角度来看,现有的IMC方法可以分为两组,其中一组是通过恢复样本之间缺失的视图或缺失的连接来解决不完整的学习问题,另一组是不恢复缺失的信息w.r.t.缺少的视图,但只关注可用视图中部分对齐的信息。 从这些方法所采用的主要方法和学习模型来看,我们可以将现有的IMC方法分为四类,即基于矩阵分解(MF)的IMC、基于核学习的IMC、基于图学习的IMC和基于深度学习的IMC。为了总结更多的IMC方法,并提供一个直观的比较,我们将根据本文的第二种分类方案对现有的IMC方法进行分析。具体来说,在我们的工作中,我们认为所有利用深度网络的IMC方法都是基于深度学习的IMC,因为这些方法与其他方法相比非常罕见。基于MF的IMC通常寻求将多视图数据分解为所有视图共享的共识表示。基于核学习的IMC试图从不完全核数据中获得共识表示。基于图学习的IMC基于谱聚类,目的是从不完整的多视图数据中获得共识图(或多个视图特定图),或直接从不完整图中计算共识表示。
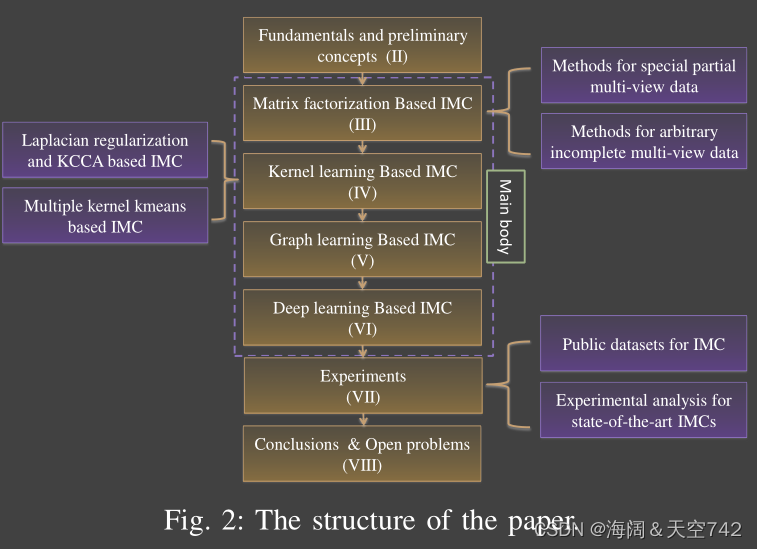
文章架构:
2. FUNDAMENTALS AND PRELIMINARY CONCEPTS
B.单视图/多视图聚类的基本背景
考虑到很多IMC方法都是从基于MF的多视点聚类和多视点谱聚类衍生出来的,我们简单介绍一些相关的基础知识。
基于MF的多视图聚类:对于多视图数据,一个基本假设是不同视图的标签分布相同。这也是所谓的多视图语义一致性。一种基于朴素MF的方法是得到如下的共识表示P
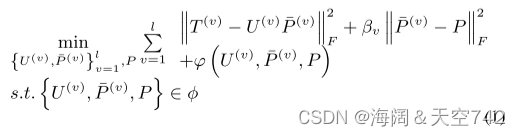
多视图谱聚类:与基于MF的方法相似,多视图光谱聚类的目的也在于获得多视图数据的一致性表示。不同的是,多视图谱聚类是通过共同探索所有图的信息来实现这一目标的,其中一个朴素框架可以表示为:
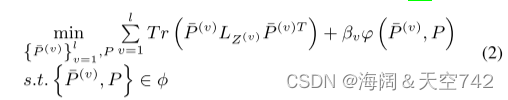
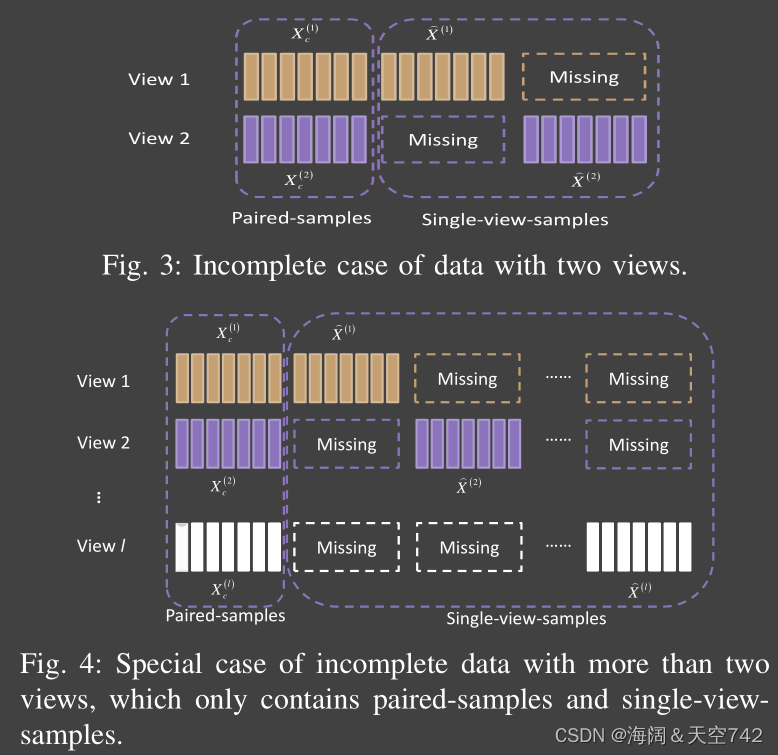
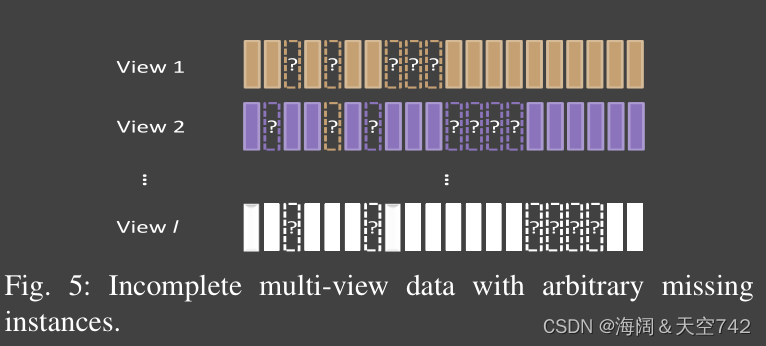
C.不完全多视图数据的分类
在本文中,我们将不完全多视图数据分为如图所示的三种情况,其中图3和图4分别显示了特殊的两视图和两视图以上的不完全多视图数据。对于这两种不完全数据,样本只包含一个视图,所有视图分别视为单视图样本和成对样本。图5为任意缺失视图的不完全多视图数据。
3. MATRIX FACTORIZATION BASED IMC(基于矩阵分解的IMC)
从传统的基于MF的多视图聚类框架(1)中我们可以发现,当某些视图缺失时,通过该模型无法直接获得一致性表示。对于不完全多视图数据,关键问题是如何设计一种能从不完全多视图数据中获得公共聚类指标矩阵或一致性表示的IMC模型。
近年来,基于MF理论设计IMC模型的方法有两种,一种是挖掘部分对齐视图之间的一致信息,另一种是通过恢复缺失视图来挖掘完全对齐的信息。本文从应用场景的角度将现有的基于MF的内模控制方法分为两类,一类是针对特殊的局部多视图数据的MF方法,如图3-4所示;另一类是针对任意不完整数据的加权MF方法,如图5所示。
A.基于MF的特殊局部多视图数据处理方法
早期的大部分研究,如部分多视图聚类(PMVC)[19]、不完全多模态分组(IMG)[20]、部分多视图子空间聚类(PMSC)[35],都以图3所示的不完全多视图数据为例设计模型。PMVC方法是其中的先锋性工作,它寻求分别获得成对样本{X(v) c}2 v=1和单视图样本,
的潜在公共表示
,
和
。但它忽略了数据的几何结构,而几何结构对无监督表示学习至关重要。IMG和PMSC是PMVC的两个扩展,它们进一步引入了图形嵌入技术来捕获几何结构。特别地,以上三种方法可以统一为以下广义模型,称为局部多视图聚类框架(partial multi-view clustering framework, PMVCF).
PMVCF、PMVC、IMG和PMSC之间的连接如图6所示
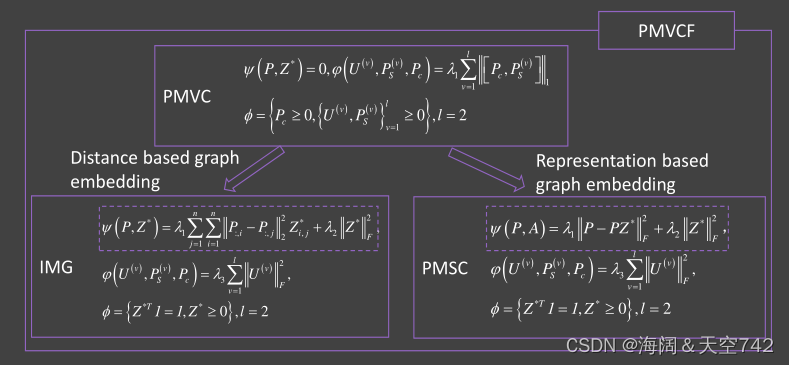
他们解决不完全学习问题的动机是相同的,即使用成对样本的部分对齐信息作为约束,以获得所有视图共享的共识表示。
它们的主要区别是约束和边界约束的定义。与PMVC相比,IMG和PMSC通过引入不同的约束进一步探索了数据的不同类型的结构信息。
B.基于MF方法的不完整数据与任意缺失视图
为了处理如图5所示的任意缺失视图的不完整数据,提出了许多基于加权MF的不完整多视图聚类方法,通过将所有视图的缺失视图信息预先构造的一些权重矩阵施加到MF项上,减少缺失视图的负面影响。其代表著作有:不完全多视图聚类(MIC)、在线多视图聚类(OMVC)、双对齐不完全多视图聚类(DAIMC)和单通道不完全多视图聚类(OPIMC)。除此之外,Rai等人提出的图正则化局部多视图聚类(GPMVC)也可以看作是基于加权MF的IMC方法的一种变体。在本文中,从实现共识表示的策略出发,我们可以将现有的基于加权MF的IMC方法统一为以下两个框架,分别称为WMF _IMCF1和WMF_IMCF2:
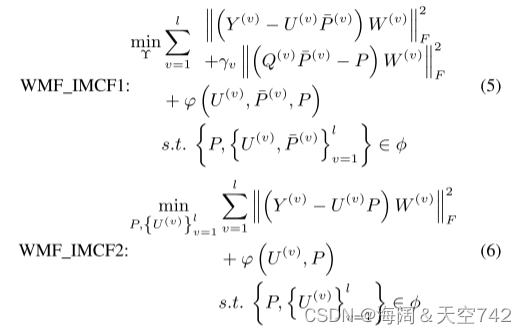
对两种框架的分析:
对MIC、OMVC和GPMVC是WMF IMCF1中最具代表性的作品。WMF IMCF2最具代表性的方法是DAIMC和OPIMC。从模型(5)和(6)可以发现,WMF_IMCF1从所有视图派生的潜在表示中获得一致表示,而WMF_IMCF2直接将原始多视图数据分解为一个一致表示和多个基矩阵。直观地说,与WMF_IMCF2相比,WMF_IMCF1在学习共识表示方面提供了更多的自由。然而,WMF IMCF1引入了至少一个额外的可调超参数γv,这增加了最优参数选择的复杂性。
4. KERNEL LEARNING BASED IMC(基于内核学习的IMC)
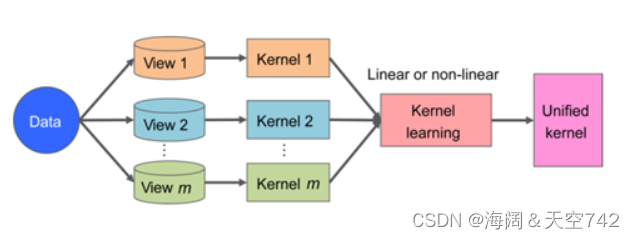
多核聚类(Multiple kernel clustering, MKC)通常寻求从所有视图预先构造的多个核中学习对应于所有视图的一致表示或多个潜在表示,然后使用kmeans来实现聚类结果。
为了提高线性核、多项式核和高斯核等可能的核函数的搜索空间容量,最初开发了多核学习,以实现良好的泛化。由于多核学习的内核自然对应不同的视图,因此多核学习在处理多视图数据方面得到了广泛的应用。多核学习方法的一般过程如下图所示,其中不同的预定义内核用于处理不同的视图。然后将这些核线性地或非线性地组合在一起,得到一个统一的核。在MVC环境下,基于多核学习的MVC为了提高聚类性能,打算对一组预先定义的内核进行优化组合。在这种方法中,一个重要的问题是找到一种选择合适的内核函数的方法,并将这些内核进行优化组合。
传统的mkc都要求输入内核是完整的。换句话说,现有的传统MKCs无法处理由于缺少视图而导致的某些行和列缺失的内核集群任务。为了解决这一问题,近十年来许多研究人员对多重不完全内核聚类(MIKC)进行了研究。
大多数mikc解决不完全学习问题的基础上恢复缺失的行和列的核矩阵。针对现有的解决不完全问题的主要技术,我们将现有的MIKCs分为两组,第一组基于拉普拉斯正则化和核典型相关分析(KCCA),第二组基于多核kmeans。
A.基于Laplacian正则化和KCCA的IMC
通常先完成核矩阵补全,然后通过KCCA学习所有视图的潜在表示。例如,基于从视图中预先构造的不缺失实例的完整内核,Trivedi等人通过求解以下拉普拉斯正则化问题来恢复不完整内核中缺失的元素:
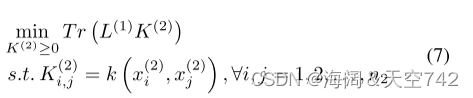
式中,表示第一个视图中不缺实例的
核的拉普拉斯矩阵。k (
,
)是由核函数k(∗,∗)计算得到的值。
然后,Trivedi等对完整核进行KCCA,恢复完整核
,得到两个视图的潜在表示,然后进行kmeans聚类。在本文中,我们将Trivedi等人提出的方法称为一个完整核的多个不完整核聚类(MIKC_OCK)。
为了解决MIKC OCK的完全视图问题,提出了集体核学习(collective kernel learning, CoKL),通过在不同视图上优化类似(7)的问题,交互式地恢复不完全核矩阵。
CoKL的局限性之一是它只适用于带有两个视图的不完整数据。综上所述,基于Laplacian正则化和KCCA的IMC方法不适合实际应用,因为这些方法只能处理一种不完全情况。此外,基于核矩阵补全和潜表示学习的两步法不能保证全局最优核矩阵和潜表示。
B.基于多内核kmeans的IMC
与基于Laplacian正则化和KCCA的内模c方法相比,基于多核kmeans的IMC方法寻求在一个联合框架内同时恢复核矩阵和学习一致性表示或聚类索引矩阵。
为方便起见,我们将[45]中提出的方法称为不完全多核kmeans聚类(IMKKC)。IMKKC的主要思想是将融合后的核与理想核对齐。与IMKKC不同的是,[46]中提出的另一个类似的基本模型,称为基于共识核kmeans的IMC (CKKIMC),它通过引入基于不相似度的正则化项,从的潜在表示中获得共识P。主要问题是这两种方法忽略了数据的局部结构,没有充分考虑视图的互补信息。此外,IMKKC还具有相对较高的计算复杂度。在IMKKC的基础上,提出了局部不完全多核kmeans聚类(LIMKKC)[32]和互核补全不完全多核kmeans (MKKM-IK-MKC)[28]等改进方法。其中,LIMKKC主要在IMKKC中引入一些邻域指示矩阵来保存数据的局部信息。为了更好地恢复核矩阵缺失的行和列,MKKM-IK-MKC在模型(8)中引入了基于稀疏重构的约束,从核中捕获更多的互补信息。
通常,上述基于内核补全的方法需要为第vv视图恢复1/2 (n−nv) (n + nv + 1)个元素。但是,恢复如此大量的元素可能会使模型陷入局部最小值,从而影响集群性能。在[29]中,Liu等人提出了另一种基于多核的方法,即efficient and effective incomplete multi-view clustering (EEIMVC),来解决IMC问题。与上述基于多核kmeans的方法不同,EE-IMVC不专注于核矩阵的恢复。联合计算每个视图缺失实例对应的潜在表示,得到一致表示P∈Rn×c.
与其他基于多核kmeans的方法相比,EE-IMVC大大降低了计算复杂度和内存开销。然而,它不能把最近的样本对拉近,而把其他样本对推远(问题,忽略局部结构)。
5.GRAPH LEARNING BASED IMC(基于图学习的IMC)
与传统的多视图谱聚类相似,基于图学习的IMC的目的是从数据构造的多个不完全图中获得一个共识图或共识表示,其中,几乎所有现有的方法都是基于预先构造的不完全图,并将缺失的相似度元素设置为0或平均值。具体来说,我们可以将现有的方法分为三大类,如图8所示。
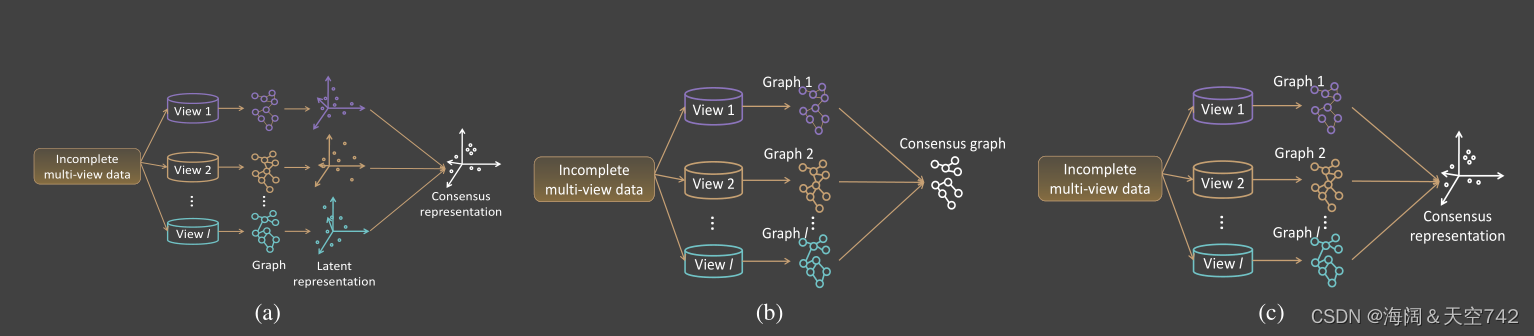
三种基于图学习的IMC方法,其中(a)和(c)侧重于获得一致表示,(b)寻求从不完全数据中获得一致图。
作为图8(a)的代表方法,基于谱聚类的IMC (SCIMC)利用一种非常简单的协同训练方法来恢复缺失实例的潜在表示,并获得共识表示[47]。
从(10)和传统的多视图光谱聚类模型(2)可以发现,SCIMC将传统模型(2)划分为几个独立的步骤,并通过借用其他视图的信息,寻求交替恢复缺失视图对应的潜在表示。然后结合所有观点的潜在表征,通过最小化不同观点之间的分歧来实现共识表征。在(10)中,前两个步骤可以看作是初始化步骤。虽然SCIMC可以处理IMC问题,但它存在三个问题:
1)不能通过独立优化四个问题来实现最优的共识表示。
2)将缺失项设置为列的平均值来初始化相似度图是不合理的。
3) SCIMC对预先构造的相似图敏感。
PIC:对于任何不完整的数据,PIC主要采用以下三步来获得光谱聚类的共识图。
1)最近邻图的构建与完成。 PIC提供了一种图学习方法,可以直接获得一些最近邻图。
2)核聚变重量计算。PIC建立了一个摄动模型来学习一些用于图融合的系数。
3)共识图学习。PIC通过将这些多数图与学习到的系数进行融合,得到共识图。
PIC可以处理各种不完全的多视图数据。然而,由于图的构造、权值的计算和共识图的学习是相互独立的,PIC对预先构造的图的质量也很敏感。
CGL_IMC:与PIC不同,CGL_IMC提供了一种加权图学习方法来构造所有不完全视图的相似图。然而,与PIC相似,CGL_IMC对预先构造的图的质量也很敏感。
IMSC_AGL:如图8(c)所示,IMSC_AGL尝试从不完全数据中自适应学习多个图中直接获得共识表示。特别是与SCIMC和PIC不同的是,IMSC_AGL将自适应图构建和基于谱的共识表示学习集成到一个联合优化框架中,可以很自然地解决PIC和SCIMC的问题。IMSC_AGL的学习模型如下
IMSC_AGL没有引入任何不确定信息来指导像SCIMC和PIC那样的共识表示学习。这确保IMSC AGL获得更合理的共识代表。但IMSC AGL存在计算复杂度高的问题,不适合大规模数据集。
SRLC:上述基于图学习的方法通常将模型优化和聚类划分为两个独立的步骤,需要实现kmeans作为后处理,将数据划分为各自的组。在[49]中,诸葛等人提出了一个统一的框架,称为同步表示学习和聚类(simultaneous representation learning and clustering, SRLC),该框架将基于图的表示学习和标签预测集成到一个联合框架中。与之前的工作相比,SRLC具有获得全局最优聚类标签的潜力。然而,它的性能也对由数据预先构造的图的质量敏感。
总的来说,与基于MF的方法相比,基于图学习的方法可以更好地挖掘数据的几何信息。然而,由于基于图学习的方法需要实现一些比较耗时的操作,如特征值计算、奇异值分解、矩阵逆运算等,这些方法可能不适用于大规模数据集。因此,有必要开发一些有效的IMC图学习算法。
6.DEEP LEARNING BASED IMC(基于深度学习的IMC)
表示学习在现有的大多数IMC方法中扮演着重要的角色。学习一种更有区别的共识表示对于获得更好的表现是至关重要的。近年来,由于深度学习在学习高级特征表示方面的良好性能,它已成功地应用于计算机视觉和模式分类的许多领域。为此,研究人员寻求将深度学习和传统的IMC方法相结合来提高性能,其中最具代表性的作品是通过深度语义映射的不完全多视图聚类(IMC DSM)[50]、通过一致生成对抗网络(PMVC CGAN)的部分多视图聚类(PMVC CGAN)[51]、对抗不完全多视图聚类(AIMC)[52]。
IMC_DSM将基于深度神经网络(DNN)的特征提取、PMVC和局部图正则化集成到如图9所示的框架中。IMC_DSM的目标函数表示如下:
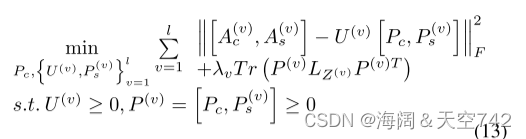
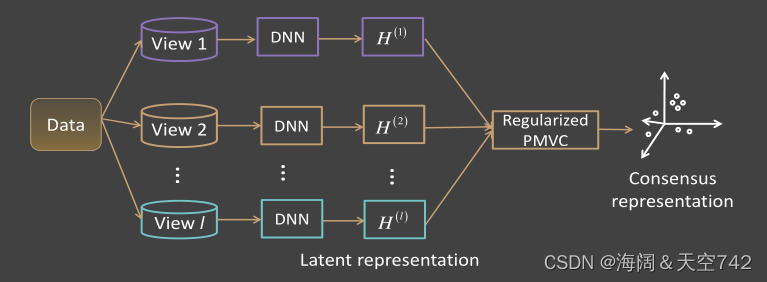
很容易观察到:
1)目标函数(13)是我们统一框架(5)的一个特例。
2)IMC_DSM通过探索可用视图之间的部分对齐信息来解决不完全学习问题,就像前一节中介绍的传统PMVCF一样。在IMC_DSM中,DNN可以从数据中提取高级特征,局部图正则化项有利于获得更合理的结构化表示。
PMVC_CGAN提供了另一种基于自动编码器(AE)和GAN的不完全双视图数据聚类方法。PMVC CGAN主要包含三个组成部分:1)利用AE生成所有视图的潜在表示。2)引入GAN生成缺失视图。3)引入基于“KL散度”的损失函数,保证学习到的潜在表示适合于聚类任务。特别是PMVC_CGAN与IMC_DSM等现有作品相比,提供了许多有趣的点。例如,现有的方法需要对得到的表示实现kmeans才能得到聚类结果,而PMVC_CGAN可以直接根据“KL-散度”生成最终的聚类结果。此外,现有的研究几乎都忽略了缺失视图的信息,而PMVC_CGAN可以充分利用缺失视图信息通过GAN进行模型训练。此外,PMVC_CGAN与现有作品最大的区别在于,PMVC_CGAN专注于聚类,而其他作品专注于学习共识表示或图。
从上面的介绍中,我们可以看到:
1)利用深度神经网络有利于学习更多的区别表示,从而提高聚类性能。
2)基于批处理的训练方式使得深度方法可以应用于大规模的数据集。
3)现有的基于深度的方法最大的缺点是不能适用于各种不完全情况。
通过这些方法的介绍,我们可以得到以下两点:1)在传统的多视图聚类方法中加入由视图缺失信息构造的加权矩阵是解决不完全学习问题的一种有效而灵活的方法。2)设计一些鲁棒模型来恢复内核或图中缺失的视图或缺失的元素是解决IMC问题的一个有价值的研究方向。在第二种方法中,一个具有挑战性的问题是如何在理论上保证缺失视角或缺失要素恢复的合理性。
7. EXPERIMENTS(实验部分)
在这一节中,我们主要做了几个实验来比较和分析前几节中有代表性的IMC方法。
A. Datasets
我们首先列出一些公共可用的多视图数据集及其url供研究人员使用。我们将公共数据集分为两类:
1)多特征:在这一类中,从同一对象中提取一些特征,如文档和图像,作为不同的视图。代表性的公共多特征多视图数据集包括:手写数字图像、Corel图像检索数据集、Caltech101和NUSWIDE对象识别数据集,动物属性(AWA)数据集,一些文档数据集,如Cora, CiteSeer, WebKB, Newsgroup datasets6和BBCSport dataset。
2)多重模式:这类数据来自不同的域或不同的张量。具有代表性的基于多模式的多视图数据集包括:哥伦比亚消费者视频(CCV)消费者视频/音频分析数据集、BUAA-visnir人脸数据集(BUAA)、伯克利果蝇基因组计划(BDGP)基因表达分析数据集、路透社大规模多语言文本分析数据集和3 Sources数据集。在这些数据集中,BBCSport和3 Sources的数据集是天然不完整的。
在我们的实验中,我们选择了以下5个具有代表性的公共数据集来比较不同的IMC方法,在补充文件的表I中简要总结了它们的信息
| BUAA | BUAA数据集中的人脸图像是由视觉相机和近红外相机采集的,自然可以认为是同一个人的两种视图。在实验中,我们从前10类中选取90幅视觉图像和近红外图像组成的子集作为的子集,对上述代表性IMC方法进行评价。 |
| BDGP | BDGP是为研究基因表达而设计的。在实验中,我们选择了Cai等人收集的多视图BDGP数据集,其中每个样本分别用纹理特征和从侧面、背侧和腹侧图像中提取的三种词袋特征来表示。 |
| Caltech101 | Caltech101是一个流行的对象数据集,包含102个类别的9144张图像,包括背景和101个对象,如飞机、蚂蚁、鲈鱼和海狸。在我们的实验中,我们选择Li等人提取的四种特征集,即cenist、Hog、Gist和LBP作为四个视图。 |
| BBCSport | BBCSport是从BBCSport网站收集的文本数据集,对应于5种体育新闻文章(即,田径、板球、足球、橄榄球和网球)。我们选择一个包含由4个视图表示的116个样本的子集13来评估。 |
| NUSWIDE | NUSWIDE是一个真实世界的网络图像数据集,由新加坡国立大学的研究人员收集。在实验中,我们采用了一个包含3万张图像和31类的多视图子集,每个图像由5种低级特征表示,即颜色直方图、颜色相关图、边缘方向直方图、小波纹理和逐块颜色矩。 |
B. Experimental setting
评价指标:选用聚类精度(ACC)、归一化互信息(NMI)、纯度(purity)和调整rand指数(ARI)四个知名指标对上述方法进行评价[28,62 -64]。
不完全多视图数据构建:对于BUAA数据集,我们随机选择p%的样本作为同时拥有两个视图的成对样本,其中p定义为{10,30,50}。对于剩下的(1-p%)样本,我们去掉一半样本的近红外视图,并去除另一半样本的视觉视图。对于其他4个数据集,在所有样本至少有一个视图的条件下,我们从每个视图中随机删除p%的实例来构造不完全数据。具体来说,对于每一个缺失率或配对率p%,我们实现了所有的比较方法在几组随机构造的不完整数据,然后报告的平均和标准偏差的聚类结果。
C. Experimental results and analysis
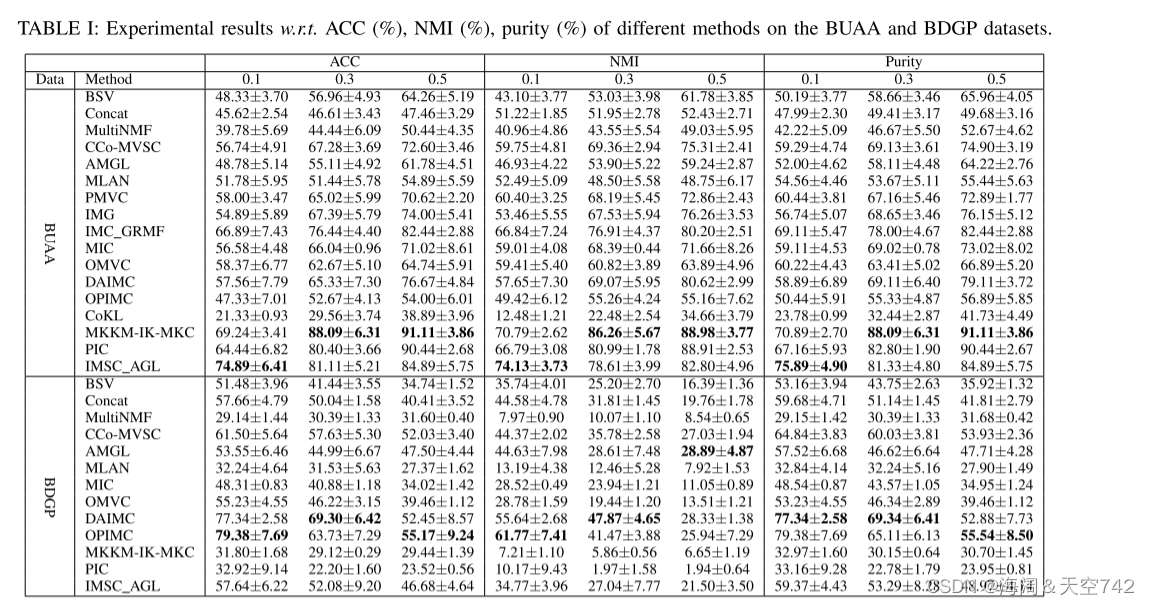
从实验结果可以看出:
(1)在大多数情况下,基于多视图学习的IMC方法在前四个数据集上的表现都优于BSV和Concat。此外,4种完整的多视图聚类方法,即multi- mf、CCo-MVSC、AMGL和MLAN的聚类性能都不如IMC方法,如DAIMC、IMC_GRMF、PIC和IMSC_AGL。
这两种现象表明:
1)所有基于多视图学习的IMC方法都比BSV和Concat更能从不完全多视图数据中捕获更多的信息。
2)简单地将缺失的实例或图设置为0或平均实例并不是解决不完全聚类问题的好方法。
3)充分挖掘现有观点之间的对齐信息是解决复杂整合营销任务学习不完全问题的有效途径。
(2)在BUAA、BBCSport和Caltech101数据集上,PIC和IMSC_AGL在ACC、NMI和纯度方面均优于基于MF的IMC方法。然而,在BDGP数据集上,这两种基于图学习的方法和基于核学习的方法,如mkmik - mkc,表现较差。此外,我们可以发现PIC、IMSC_AGR和MKKM-IK-MKC不适合在内存为64gb的计算机上执行NUSWIDE数据集的聚类任务。通过分析数据的原始特征,我们发现BDGP是一个与其他四个数据集非常不同的数据集,因为该数据集中的一些原始实例自然是不可用的,并被设置为零向量。在这种特殊的缺失视图数据集上,通过“高斯核”或基于距离的图构造方案难以获得高质量的核或图。这是导致基于内核和基于图的IMC方法性能较差的主要原因。根据这些现象,我们可以推断:1)在大多数情况下,基于图学习的聚类方法比基于MF的IMC方法具有更强的判别性。2)获取正确的数据几何结构信息对于无监督聚类任务至关重要。3)与基于MF的方法相比,基于图和核的方法需要为n个样本的数据计算几个n * n的图/核矩阵,这需要很大的存储空间。
此外,还可以观察到,没有一种IMC方法能够在各种数据集上保持一致的良好性能。因此,针对不同的数据集选择合适的算法是非常重要的。
8. CONCLUSION
不完全学习问题是多视图聚类中具有挑战性的问题,其研究具有重要的实际应用意义。本文综述了几乎所有具有代表性的IMC方法,并将其分为四类,即基于MF的IMC、基于核学习的IMC、基于图学习的IMC和基于深度学习的IMC。本文简要介绍了几种具有代表性的IMC方法,并深入探讨了它们之间的联系、差异和优缺点。对于基于MF的内模控制方法,给出了一些统一的集成框架。虽然在过去的几十年里已有许多IMC策略被提出,但仍有一些具有挑战性的问题没有得到很好的解决。例如:
综上所述,IMC的进展仍处于理论研究阶段。未来,研究者需要为实际应用设计更高效、高性能和鲁棒的IMC方法。
9.启发
1.不完整多视图聚类(处理缺失)
1)数据矩阵补全:假设一个视图完整,基于视图一致性的补全,MKIK算法(填充和聚类的交替迭代来达到一个好的聚类结果,然而这样的迭代会严重影响模型的外推能力)
2)利用对齐信息:视图之间存在着样本的对齐信息,样本的缺失可以通过这种对齐信息来刻画,于是对于两个视图就可以分为对齐部分和不对齐部分分开进行学习处理。对于对齐部分,可以看成一个两个完整视图的问题,可以用已有的多视图学习算法来解决,而对于每个视图的不对齐部分,可以看作是只有一个完整视图的问题,可以通过矩阵分解、降维等来解决。
2.没有一种IMC方法能够在各种数据集上保持一致的良好性能。因此,针对不同的数据集选择合适的算法是非常重要的。
10.问题
1.如何理解一致性表示?
2.不完全视图学习与长尾问题学习是否有相似之处?
3.视图缺失是否可以用半监督学习来解决?

















 8916
8916

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









