







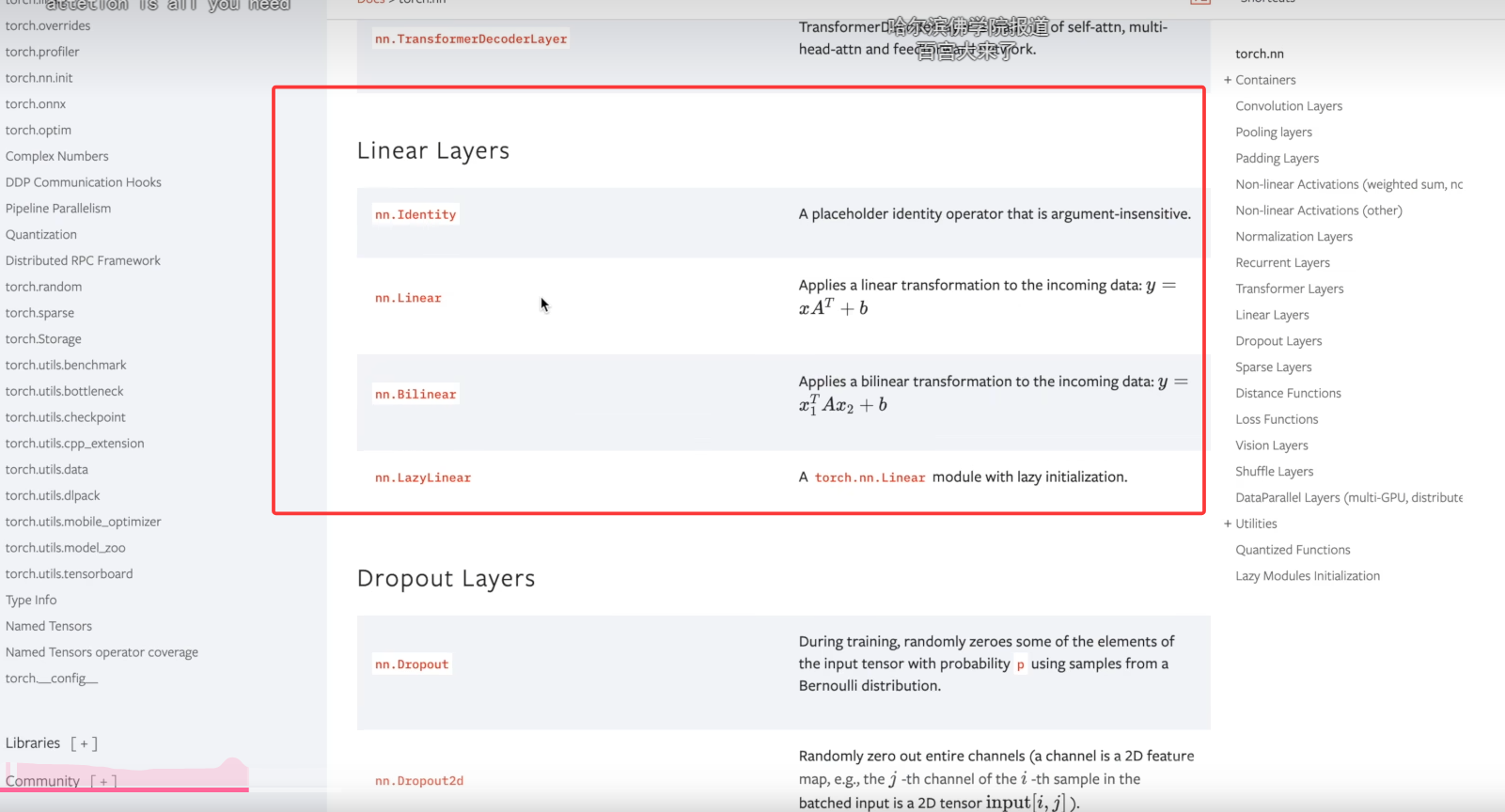
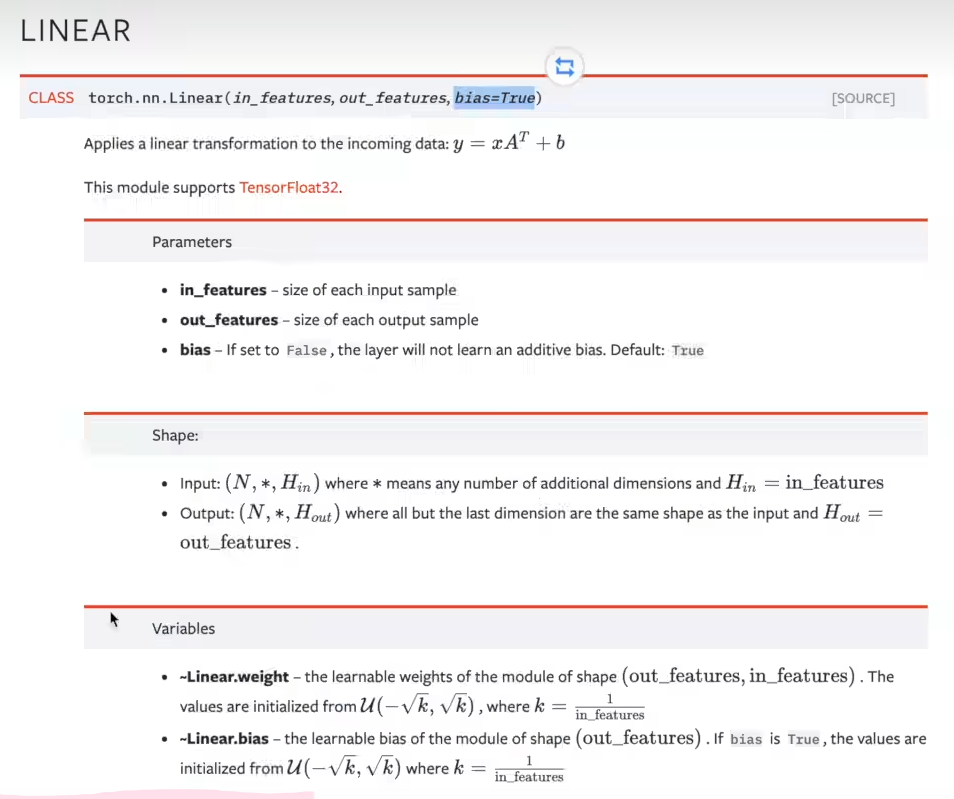
线性层
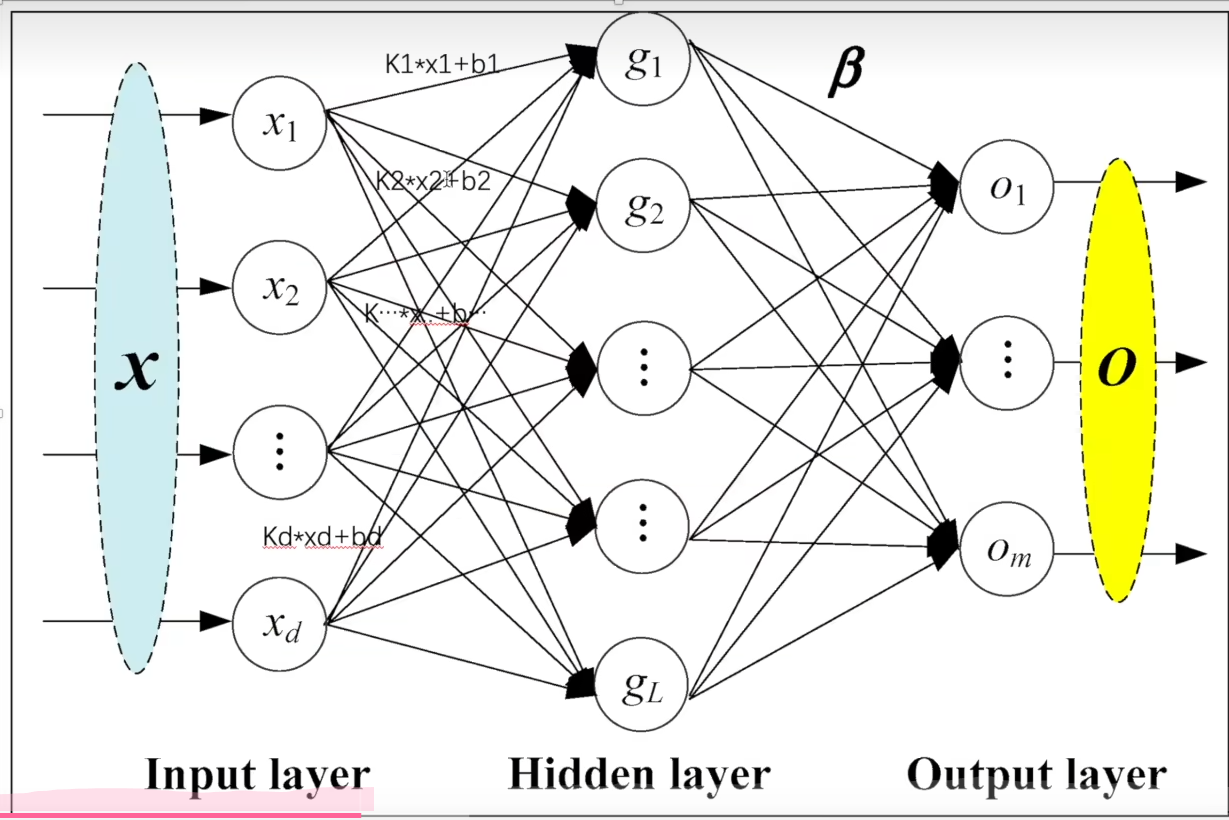

前面1,1,1是你想要的,后面我们不知道这个值是多少,取-1让Python自己计算
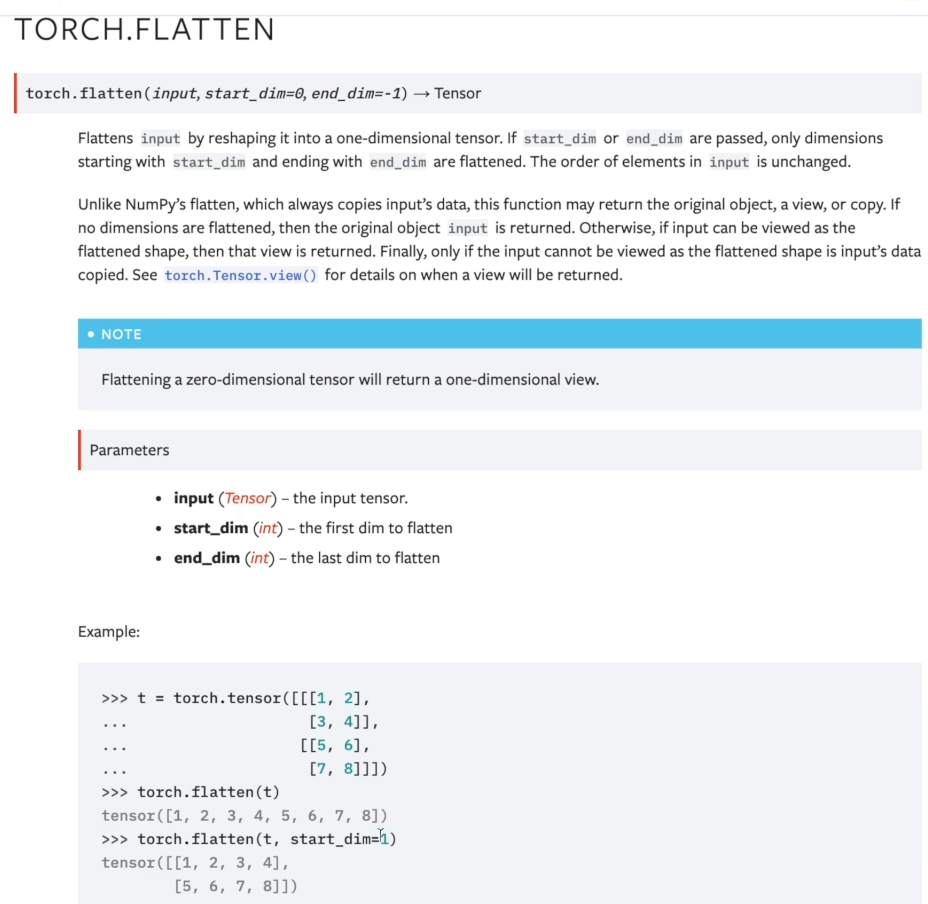
import torch
import torchvision
from torch import nn
from torch.nn import Linear
from torch.utils.data import DataLoader
# 加载CIFAR-10测试数据集并转换为Tensor格式
dataset = torchvision.datasets.CIFAR10("./data", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
# 创建数据加载器,每批次包含64个样本
dataloader = DataLoader(dataset, batch_size=64)
# 定义神经网络模型TY
class TY(nn.Module):
def __init__(self):
super(TY, self).__init__()
# 定义全连接层:输入维度196608,输出维度10(对应10个类别)
self.Linear1 = Linear(196608, 10)
def forward(self, input):
# 前向传播:将输入数据通过全连接层
output = self.Linear1(input)
return output
# 实例化模型
ty = TY()
# 遍历数据加载器中的每个批次
for data in dataloader:
# 获取图像数据和对应的标签
imgs, target = data
# 打印原始图像张量形状:[批次大小, 通道数, 高度, 宽度]
print(imgs.shape)
# 将图像张量展平为一维向量
# 注意:此处reshape参数(1,1,1,-1)会导致维度错误,正确应为(-1, 196608)
output = torch.reshape(imgs, (1, 1, 1, -1))
# 打印展平后的张量形状
print(output.shape)
# 将展平后的数据输入模型
output = ty(output)
# 打印模型输出形状:[批次大小, 类别数]
print(output.shape)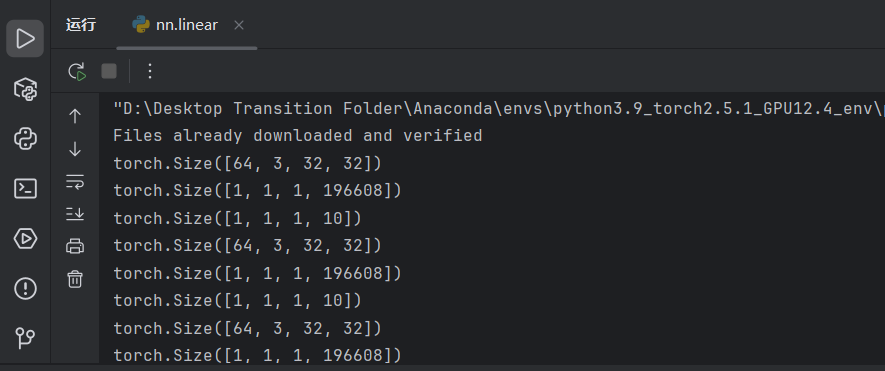
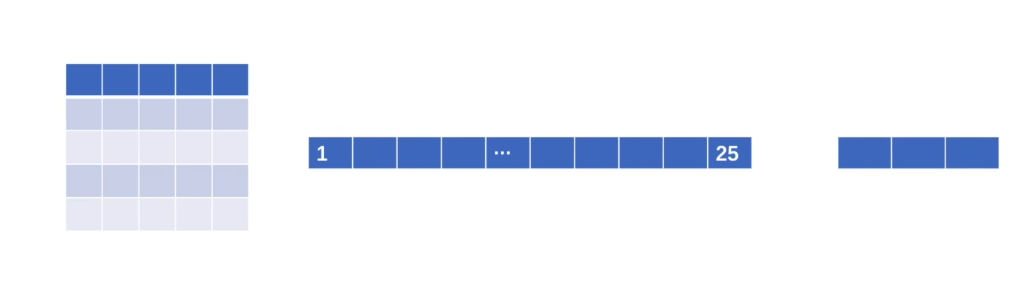
另一种表达 flatten展平

import torch
import torchvision
from torch import nn
from torch.nn import Linear
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("./data",train=False,transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset,batch_size=64)
class TY(nn.Module):
def __init__(self):
super(TY,self).__init__()
self.Linear1 = Linear(196608,10)
def forward(self,input):
output = self.Linear1(input)
return output
ty = TY()
for data in dataloader:
imgs,target = data
print(imgs.shape)
output=torch.flatten(imgs)
print(output.shape)
output = ty(output)
print(output.shape)
















 626
626

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









