







THEORY OF THE DEVELOPED DRSNS
Basic Components
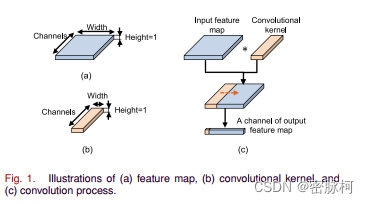
图一
深度残差收缩网络的基本组件,因为这篇文章的输入是一维震动信号,所以它的height维度等于1
知识点:
GAP(global average pooling) : 计算特征图每个channel的平均值,一般用在最后一个输出层前面。
GAP的作用:
1.可以减少全连接输出层的权重数,这样可以对抗过拟合
2.可以处理shift variant(协变量偏移)问题,不会因为一些局部数据的变化而影响整个网络的学习效果
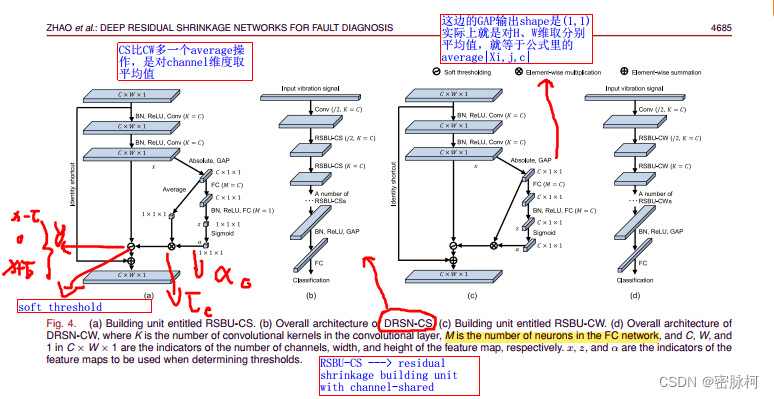
图二
其中 C代表channel,W代表输入特征图的宽度,输入特征图的高度是1,K=C表示卷积核的个数是C个,M表示全连接层的out_features,identity shortcut包含的两层卷积层,在它们每层之前都要加bn和Relu并且两层卷积层的输出结果是x
软阈值:
 公式一
公式一
求导后:
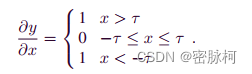
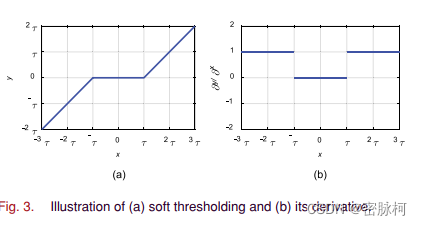
求导后的数值不是0就是1,这样可以有效的阻止梯度爆炸或者梯度消失问题
 公式二
公式二
其中u表示图二中的x也就是输入,a代表下图中的![]() 就是软阈值中的阈值,用代码实现采用公式二,自己理解采用公式一,本质上两个公式相等,在信号诊断算法里软阈值需要人工设置,但是在DRSN网络中它可以通过模型学习得到
就是软阈值中的阈值,用代码实现采用公式二,自己理解采用公式一,本质上两个公式相等,在信号诊断算法里软阈值需要人工设置,但是在DRSN网络中它可以通过模型学习得到
RSBU-CS:

RSBU-CW:
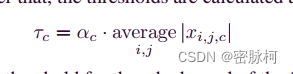
公式中的![]() 就是GAP,GAP在RSBU中的作用就是把W维度去了均值降到1维
就是GAP,GAP在RSBU中的作用就是把W维度去了均值降到1维
通道共享和通道wise的区别:
RSBU-CS:把多个Channel转化为一个Channel然后相乘,所以叫通道共享
RSBU-CW:channel与channel相乘
下表是从原论文中截取的DRSN的配置表,作者尝试了不同其他的网络:
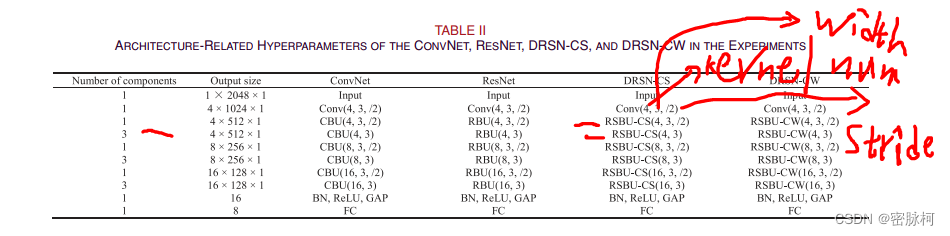
conv(4,3,/2):第一个参数表示卷积核个数,第二个参数表示卷积核大小,第三个参数表示stride
文中表示DRSN-CW的acc比DRSN-CS的要好并且计算时间也少:
原因1:特征图不同通道包含不同数量的噪声相关信息
原因2:DRSN-CS比DRSN-CW要多一个average步骤
附上Pytorch实现的代码:
import torch
from torch import nn
class RSBU_CW(nn.Module):
def __init__(self,
downsample,
in_channel,
out_channel,
kernel_size, **kwargs):
super(RSBU_CW, self).__init__()
if downsample:
stride = 2
self.downsample = nn.Sequential(
nn.Conv2d(in_channels=in_channel, out_channels=out_channel,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channel)
)
else:
stride = 1
self.downsample = nn.Sequential()
self.conv = nn.Sequential(
nn.BatchNorm2d(in_channel),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=in_channel, out_channels=out_channel,
kernel_size=kernel_size, stride=stride,
padding=1, bias=False),
nn.BatchNorm2d(out_channel),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=out_channel, out_channels=out_channel,
kernel_size=kernel_size, stride=1,
padding=1, bias=False))
self.gap = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Sequential(
nn.Linear(in_features=out_channel, out_features=out_channel),
nn.BatchNorm1d(out_channel),
nn.ReLU(inplace=True),
nn.Linear(in_features=out_channel, out_features=out_channel),
nn.Sigmoid())
def forward(self, input):
identity = self.downsample(input)
print(identity.shape)
x = self.conv(input)
abs = torch.abs(x)
gap = self.gap(abs) # gap的输出为1,1时做的就是取所在维度的平均值 torch.Size([8, 32, 1, 1])
gap_flatten = torch.flatten(input=gap, start_dim=1) # torch.Size([8, 32])
alpha = self.fc(gap_flatten)
alpha = alpha.unsqueeze(2).unsqueeze(2) # torch.Size([8, 32, 1, 1])
t = torch.mul(gap, alpha)
# soft thresholding
sub = abs - t
zeros = sub - sub
n_sub = torch.max(sub, zeros)
soft_threshold = torch.mul(torch.sign(x), n_sub)
# print('soft thresholding ---> ', x.shape)
x = torch.add(soft_threshold, identity)
return x
class RSBU_CS(nn.Module):
def __init__(self,
downsample,
in_channel,
out_channel,
kernel_size, **kwargs):
super(RSBU_CS, self).__init__()
if downsample:
stride = 2
self.downsample = nn.Sequential(
nn.Conv2d(in_channels=in_channel, out_channels=out_channel,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channel)
)
else:
stride = 1
self.downsample = nn.Sequential()
self.conv = nn.Sequential(
nn.BatchNorm2d(in_channel),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=in_channel, out_channels=out_channel,
kernel_size=kernel_size, stride=stride,
padding=1, bias=False),
nn.BatchNorm2d(out_channel),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=out_channel, out_channels=out_channel,
kernel_size=kernel_size, stride=1,
padding=1, bias=False))
self.gap = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Sequential(
nn.Linear(in_features=out_channel, out_features=out_channel),
nn.BatchNorm1d(out_channel),
nn.ReLU(inplace=True),
nn.Linear(in_features=out_channel, out_features=out_channel),
nn.Sigmoid())
def forward(self, input):
identity = self.downsample(input)
# print(identity.shape)
x = self.conv(input)
# print(x.shape)
abs = torch.abs(x)
gap = self.gap(abs) # gap的输出为1,1时做的就是取所在维度的平均值 torch.Size([8, 32, 1, 1])
gap_flatten = torch.flatten(input=gap, start_dim=1) # torch.Size([8, 32])
alpha = self.fc(gap_flatten)
alpha = alpha.unsqueeze(2).unsqueeze(2) # torch.Size([8, 32, 1, 1])
average = torch.mean(input=gap, dim=1, keepdim=True) # 比CW多的一步 torch.Size([8, 1, 1, 1])
t = torch.mul(average, alpha)
# soft thresholding
sub = abs - t
zeros = sub - sub
n_sub = torch.max(sub, zeros)
soft_threshold = torch.mul(torch.sign(x), n_sub)
# print('soft thresholding ---> ', x.shape)
x = torch.add(soft_threshold, identity)
return x
# input = torch.rand([8, 4, 1, 1024]) # B C H W
# s = RSBU_CS(downsample=True, in_channel=4, out_channel=4, kernel_size=3)
# print('output shape ---> ', s(input).shape)
# print('-' * 100)
class DRSN_CS(nn.Module):
def __init__(self, RSBU_CS):
super(DRSN_CS, self).__init__()
self.conv = nn.Conv2d(in_channels=1, out_channels=4,
kernel_size=3, stride=2, padding=1)
self.bn = nn.BatchNorm2d(16)
self.Relu = nn.ReLU(inplace=True)
self.GAP = nn.AdaptiveAvgPool2d((1,1))
self.fc = nn.Linear(in_features=16, out_features=10)
self.layer1 = RSBU_CS(downsample=True, in_channel=4, out_channel=4, kernel_size=3)
self.layer2 = RSBU_CS(downsample=False, in_channel=4, out_channel=4, kernel_size=3)
self.layer3 = RSBU_CS(downsample=True, in_channel=4, out_channel=8, kernel_size=3)
self.layer4 = RSBU_CS(downsample=False, in_channel=8, out_channel=8, kernel_size=3)
self.layer5 = RSBU_CS(downsample=True, in_channel=8, out_channel=16, kernel_size=3)
self.layer6 = RSBU_CS(downsample=False, in_channel=16, out_channel=16, kernel_size=3)
def forward(self, input):
x = self.conv(input)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.layer5(x)
x = self.layer6(x)
x = self.GAP(self.Relu(self.bn(x)))
x = torch.flatten(x,start_dim=1)
x = self.fc(x)
return x
class DRSN_CW(nn.Module):
def __init__(self, RSBU_CW):
super(DRSN_CW, self).__init__()
self.conv = nn.Conv2d(in_channels=1, out_channels=4,
kernel_size=3, stride=2, padding=1)
self.bn = nn.BatchNorm2d(16)
self.Relu = nn.ReLU(inplace=True)
self.GAP = nn.AdaptiveAvgPool2d((1,1))
self.fc = nn.Linear(in_features=16, out_features=10)
self.layer1 = RSBU_CW(downsample=True, in_channel=4, out_channel=4, kernel_size=3)
self.layer2 = RSBU_CW(downsample=False, in_channel=4, out_channel=4, kernel_size=3)
self.layer3 = RSBU_CW(downsample=True, in_channel=4, out_channel=8, kernel_size=3)
self.layer4 = RSBU_CW(downsample=False, in_channel=8, out_channel=8, kernel_size=3)
self.layer5 = RSBU_CW(downsample=True, in_channel=8, out_channel=16, kernel_size=3)
self.layer6 = RSBU_CW(downsample=False, in_channel=16, out_channel=16, kernel_size=3)
def forward(self, input):
x = self.conv(input)
print(x.shape)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.layer5(x)
x = self.layer6(x)
x = self.GAP(self.Relu(self.bn(x)))
x = torch.flatten(x,start_dim=1)
x = self.fc(x)
return x
input = torch.rand([8,1,1,2048])
model = DRSN_CW(RSBU_CS)
print(model(input).shape)













 1388
1388











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









