






1.需求描述
1.1 问题描述
以大学英语相关英语文章为语料素材,设计有效的数据结构及其存储结构表示英语单词表, 并建立相应的倒排索引,帮助英语学习者在遇到生词时能方便找到生词的相应例句,熟悉其 应用语境与地道的用法;设计有效的算法对语料进行清理与分句处理,实现基于索引的快速 例句搜索程序。
1.2 基本要求
(1)输入某一个(或若干个)英语单词,要求返回相应的英语例句。
(2)根据单词与语句建立倒排索引,并且索引要求物化到外存,以文件形式保存,每次启 动程序时不必重新建立索引,只需将索引文件导入内存。
(3)准备英语语料。寻找英语文章,可下载英语新闻,托福、GRE 文章,或 大学英语课文等。
(4)处理语料。对语料进行清理、分句、索引、生成字典。需要进行取 词干的操作,分句可以直接根据标点符号处理。
(5)根据索引进行查询。支持一个或多个 查询,基于对词干的处理,当查 go、going 等时也能够有返回(不要求特殊变换形式单词词根处理,只需考虑简单的单词形式变换)。
(6)由于查询的结果是语句, 如果直接按照词与文章的关系建立索引,这样需要从文章中找句子,太多的串匹配操作可能 导致查询较慢,所以要设计好索引的粒度
额外实现:查询单词的例句中的高亮显示
1.3 输入说明
输入界面设计
1、创建索引时的输入界面:
全部采用文件读取,因为找的语料所含的内容比较多(15篇大学英语文章),所以采用文件读取,加快读取速度。
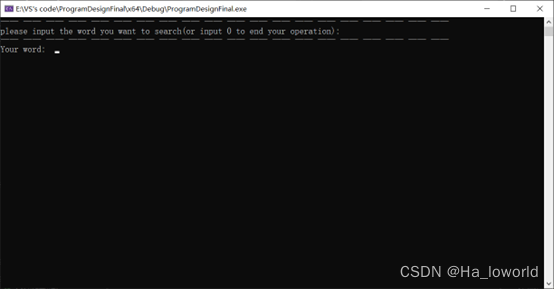
2、单词查询时的输入界面:
控制台每次操作都输出相应的提示信息,用户只需简单的输入要查询的单词,控制台便会展示相应的例句。
1.4 输出说明
输出界面设计
- 索引文件输出,前期处理语料之后生成的倒排索引文件需要以文件形式物化到外存,便于后面功能读取索引。
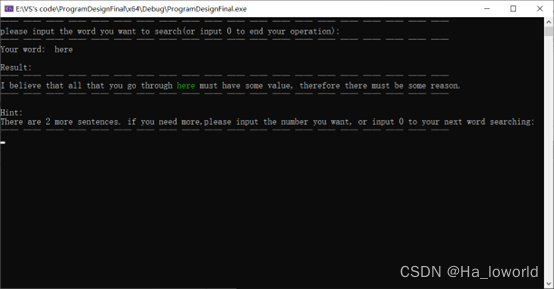
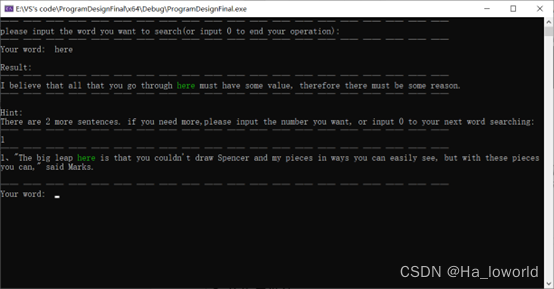
- 控制窗口输出,输入查询的单词后输出对应的例句,多个例句时询问是否要输出多个例句,之后输出用户指定的例句个数。每个例句中的查询单词高亮展示:
2.分析与设计
2.1 问题分析
1、英语单词小助手的总要求可以剖析成下面的子问题
①寻找语料
②清洗语料
③划分句子、划分单词
④为句子生成标号索引(哈希)
⑤为单词建立与句子的倒排索引
⑥将句子的标号索引以及单词的倒排索引输出、保存到外存
⑦读取索引文件,设计查询的输入输出界面
⑧输入单词的简单处理
⑨单词查询、查询不到时进行单词的词根及一般可能的变换形式进行查询
⑩输出例句、高亮句中显示要查询的单词
⑩①判断是否进行更多例句的输出,并进行下一次的单词查询使用
2.2 主程序设计
分为两个主程序,分别用来进行产生索引文件和进行单词的查询和使用。
- 产生索引文件的主程序设计:
(1)采用unordered_map<int,string>作为句子的哈希索引存储容器
(2)采用unordered_map<string,unordered_map<set>>作为单词倒排索引存储容器。
(3)读入语料,根据Ascii码去除段前缩进。
(4)根据语料中的标点进行语句划分。
(5)划分好语句后建立语句的哈希索引。
(6)对每一个语句进行单词划分,对单词进行清洗,所有大写转换为小写,带有标点(’)的单词直接舍弃。
(7)清洗好的单词建立倒排索引,将所属句子的句子编号加入单词的倒排索引容器中。
(8)将建立好的句子哈希索引以及单词倒排索引输出到外存,生成索引文件。
- 用户进行单词例句查询的主程序设计:
- 首先读取索引文件,依旧利用unordered_map<int,string>作为句子的哈希索引存储容器,采用unordered_map<string,unordered_map<set>>作为单词倒排索引存储容器。
- 然后设计输出提示语句和分割线、输入位置、输出位置,使得界面美观
- 设计处理查询的函数。考虑查询到的直接输出,查询不到时对于单词规则形式变换的查询即对词根的处理,例如goes查不到查go,wanted查不到查want,sort查不到查sorting、sorts、sorted……
- 处理查询到的例句中的单词,对句中用户查询的单词进行高亮显示。
2.3 设计思路
1、语料的清洗:
进行句子划分之前的语料清洗比较简单,经过实验测试发现只有每一自然段之前的段前缩进需要进行处理,读入每一段之后将每一段的段前缩进删除即可。其他的语料清洗在下面相应步骤中按需清洗。
2、划分句子、建立句子的哈希索引:
利用istringstream 按照英文每一句的句末标志标点划分语句。划分语句之后分配标号,标号分配按照普通的num++分配即可,建立标号与句子的哈希索引。
3、划分单词、清洗单词、建立单词与句子的哈希索引:
利用istringstream,不加参数,按照空格划分字符串即单词块。划分单词块后进行的单词块的清洗,若句中有(’)引号的直接舍弃该单词块,没有的话进行单词头单词尾部标点的处理,利用string s(s.begin()+..,s.begin()+..)用法在判断完单词首和单词尾后根据位置舍弃标点。舍弃完标点后,由单词块转化为标准单词。对单词中所有大写字母转化为小写字母,然后将单词所在句子加入到单词的倒排索引表中即可。
4、输出索引文件物化到外存:
有序输出即可。因为我们的存储结构是:
![]()
所以我们只需要有序输出到文件即可。先输出句子个数,再每一行输出句子的编号和句子。再输出单词的个数,再输出单词,再输出单词的倒排索引的个数,再输出倒排索引即可,这样生成了相当有序的索引文件,并且物化到了外存。
当然读取索引文件跟输出索引文件步骤相同,只是反操作而已。
索引结构展示:
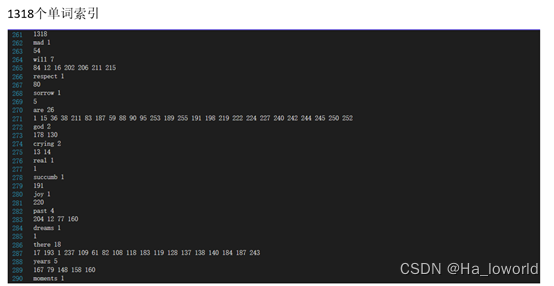
5、单词查询、单词词根查找:
输入单词,先直接查找输入的单词,找到了则输出单词的例句,若找不到,进行单词词根的查找与判断:
根据单词形式,若结尾带有s、ing、ed,尝试进行去除后查找,结尾es的需要判断es前一个字符是否为s、x、ch、sh(简化规则变换的规则),去除查找找到后停止继续查找。(当然这样会有小问题,即单词本来可能是以s结尾,但是我们没找到,去除s后变为另外的单词导致错误的查询结果,但是这一点我们的课设要求是简单的词根处理,因上述情况以及不规则的形式变换目前的技术只能手动录入,而手动录入的工作量太大,所以容忍这种小问题,是符合课设的要求的。)若还未找到,直接再单词后加s、ing、ed进行再次查找,若单词结尾为s、x、ch、sh加es进行查找。这样我们就实现了对词根的简单处理。

6、单词在例句中的高亮输出。
高亮输出我们并不需要进行标记所有单词所在的位置,我们只需要在找到例句后利用istringstream对单词进行划分清洗,找到查询的单词高亮输出,其他的单词普通输出即可,高亮输出利用:即可实现。
![]()
展示:
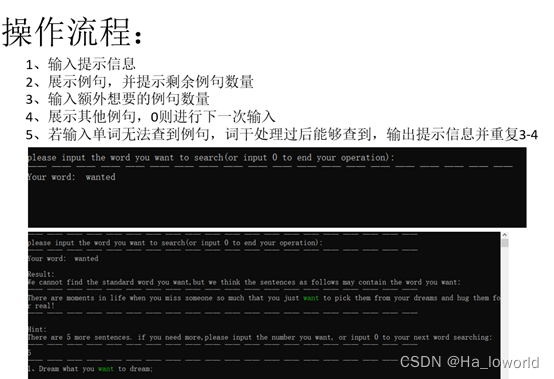
2.4 数据及数据类(型)定义
采用最直接最简洁的数据结构、查询效率最高的数据结构:
哈希表 unordered_map
![]()
上面也分析过,这两个哈希表足以解决所有课设中的问题。
2.5.算法设计及分析
1、索引的建立采用哈希+遍历的方式,因为要处理语料中的所有单词,所以遍历是不可避免的,而我采用遍历一遍句子、遍历一遍单词将建立索引的复杂度降到了O(2*n),其中n为语料中的字符数量。建立索引和倒排索引利用哈希表,也满足了我们对于本课设最基本的要求----高效的查询。
同时,索引粒度我们也控制到了极致,我们只存储了一遍句子,一遍单词,索引文件中没有一个重复的单词和句子,句子也用标号表示,减小了倒排索引的粒度,从而大大提高了查询效率和索引所占用的存储空间以及读取索引文件的时间。
2、查询时,由于我们数据结构用的均为哈希表,所以查询利用倒排索引进行一次哈希,找到倒排索引中的句子标号再用一次哈希,整体只有O(1)的复杂度,性能是相当高的。满足课设的要求。
3、此外,我们对于语料的清洗从索引文件看是全部正确且高效的,额外增添的高亮展示操作也是正确的,且大大提高了用户的使用感受。
4. 分析与探讨
1、由于没有外国标准的语料文章,我们所找的语料文章都是网络随意的网站copy下来的文章,因此不可避免存在中文的字符,所以我们语料清洗过程中除了英文的字符外也处理了中文的字符,防止了错误的出现。
2、对于倒排索引采用unordered_map<string,unordered_set<int>>,value的值为什么是unordered_set<int>, 这里其实并没有什么特殊的用意,因为无论采用什么数据结构(除了堆和红黑树或者其他我还不知道的数据结构),访问的效率都是O(1)的,感觉用哈希用到底会比较规整,因此采用了unordered_set<int>容器存储倒排索引中的句子标号。
3、单词高亮显示:这里处理起来其实也是比较简单,我们只需要一边判断一边输出即可,所以这里并没有增添不可接受或者说明显降低查询效率的复杂度,且提高了视觉感受,所以感觉这里设计的还是比较不错的。
附录代码
1、创建索引cpp
makeIndex.cpp
#include<iostream>
#include<vector>
#include<unordered_map>
#include<unordered_set>
#include<string>
#include<queue>
#include<sstream>
#include<cstdio>
#include <conio.h>
using namespace std;
int main()
{
FILE* stream1, * stream2;
freopen_s(&stream1, "source.in", "r", stdin);
freopen_s(&stream2, "index.in", "w", stdout);
unordered_map<int, string> sentence; //句子编号-句子
unordered_map<string, unordered_set<int>> word; //单词-句子编号集合(倒排索引)
string ss; //读入语料
string temp; //装载单词
queue<pair<int, string> > smid; //装载句子
int num = 1; //句子编号
while (getline(cin, ss)) //分句处理
{
string inter;
int begin = 0;
for (int i = 0; i != ss.size(); ++i)
if ((ss[i] < 'a' && ss[i]>'Z') || (ss[i] < 'A') || ss[i] > 'z');
else
{ //处理段前缩进
begin = i;
break;
}
for (int i = begin; i != ss.size(); ++i)
{
if (ss[i] == '.' || ss[i] == '?' || ss[i] == ';' || ss[i] == '!')
{ //分句处理
inter = string(ss.begin() + begin, ss.begin() + i + 1);
begin = i + 1;
smid.push({ num++,inter });
}
}
ss.clear();
while (!smid.empty())
{ //建立索引与句子的哈希表
pair<int, string> midload = smid.front();
string msecond = midload.second;
int mfirst = midload.first;
sentence[mfirst] = msecond;
smid.pop();
istringstream input(msecond); //建立单词与句子的倒排哈希索引
string midtemp;
// ---------------------------------------------
while (input >> midtemp)
{
while (midtemp.size()&&( midtemp[0] < 'A' || midtemp[0] > 'z' || (midtemp[0] > 'Z' && midtemp[0] < 'a')))
midtemp = string(midtemp.begin() + 1, midtemp.end());
istringstream laststream(midtemp);
while (getline(laststream, temp, ',')) //分小句,处理逗号标点
{
bool judge = 0;
for (auto& c : temp)
{
if ((c >= 'A' && c <= 'Z'))
c += 'a' - 'A';
if (c < 'a' || c > 'z')
judge = 1;
}
if(judge)
continue;
word[temp].insert(mfirst);
}
}
}
}
cout << sentence.size() << endl;
for (auto& c : sentence) //创建索引文件
cout << c.first << " " << c.second << endl;
cout << word.size() << endl;
for (auto& c : word)
{
cout << c.first << " " << c.second.size() << endl;
for (auto& m : c.second)
cout << m << " ";
cout << endl;
}
fclose(stream1);
fclose(stream2);
freopen_s(&stream1, "CONIN$", "r", stdin);
freopen_s(&stream2, "CONOUT$", "w", stdout);
cin.clear();
}
2、查询应用cpp
#include<iostream>
#include<vector>
#include<unordered_map>
#include<string>
#include<queue>
#include<unordered_set>
#include<sstream>
#include<cstdio>
#include <conio.h>
using namespace std;
vector<string> vec;
unordered_map<int, string> sentence; //句子编号-句子
unordered_map<string, unordered_set<int>> word; //单词-句子编号集合(倒排索引)
string ss; //读入语料
int sentencenum, wordnum, snum, wnum, index;
//句子数目、单词数目,句子标号、单词拥有的例句数目,单词所在的句子标号
int stringToNum(string sss) //字符串转换成数字
{
stringstream midds;
midds << sss;
int ans;
midds >> ans;
return ans;
}
bool check(string x)
{
for (auto& c : x) //检查是否需要继续展示例句
{
if (c < '0' || c > '9')
return false;
}
return true;
}
void line() //输出标识线
{
for (int i = 0; i < 20; ++i)
cout << "—— ";
cout << endl;
}
void output(string& s, string& finds) //高亮输出
{
istringstream ss(s); //句子放入ss
string inter; //inter保存单词
while (ss >> inter) //利用空格查找单词
{
string midinter; //保存全部小写之后的单词
for (int i = 0; i < inter.size(); ++i) //将单词小写,便于之后查找
{
if (inter[i] > 'A' && inter[i] < 'Z')
midinter.push_back(inter[i] + 'a' - 'A');
else if (inter[i] <= 'z' && inter[i]>='a')
midinter.push_back(inter[i]);
}
if (inter == finds || midinter == finds) //如果找到单词,高亮输出,否则正常输出
cout << "\033[32;1m" << inter << "\033[0m";
else cout << inter;
cout << " ";
}
cout << endl;
}
void find(string finds) //单词查找
{
cout << "Result: \n";
if (finds.size() == 1 && finds != "a") //如果查找的单词只有一个字母且不是a,那肯定没有这个单词
{
cout << "the word connot be found in the dictionary!" << endl;
line();
{cin.clear();;return;};
}
if (word.find(finds) == word.end()) //如果没有找到,进行所有可能的判断查找
{
if (finds[finds.size() - 1] == 's') //对于复数的判断,如果最后一位为s,考虑为复数的可能
{
string midfinds = string(finds.begin(), finds.end() - 1); //查找单词变为查找单词单数
if (word.find(midfinds) == word.end()) //如果仍然没找到
{
if (midfinds[midfinds.size() - 1] == 'e') //最后一位为e,考虑es复数的查找
{
string midfinds2 = string(midfinds.begin(), midfinds.end() - 1);
if (word.find(midfinds2) == word.end()) //仍然没找到,等待输出查找错误信息
{
;
}
else
{ //如果找到了,进行输出
cout << "We cannot find the standard word you want,but we think the sentences as follows may contain the word you want:" << endl;
line();
output(sentence[*word[midfinds2].begin()], midfinds2);
line();
if (word[midfinds2].size() > 1)
{ //如果多个例句,输出提示信息
cout << "\nHint:\nThere are " << word[midfinds2].size() - 1 <<
" more sentences. if you need more,please input the number you want, or input 0 to your next word searching:"
<< endl;
line();
string x;
cin >> x; //输入要输入的例句个数
if (!check(x))
{cin.clear();;return;}
int xnum = stringToNum(x); //转数字
line();
int i = 1;
for (auto it = word[midfinds2].begin(); i < word[midfinds2].size(); ++i)
{ //输出例句
++it;
cout << i << "、";
output(sentence[*it], midfinds2);
cout << endl;
if (i == xnum) //输出max(xnum,例句个数)个例句
break;
}
line();
}
{cin.clear();;return;};
}
}
}
else
{
cout << "We cannot find the standard word you want,but we think the sentences as follows may contain the word you want:" << endl;
line();
output(sentence[*word[midfinds].begin()], midfinds);
line();
{cin.clear();;return;};
}
}
//对于现在进行时的判断
if (finds.size() >= 4 && finds[finds.size() - 1] == 'g' && finds[finds.size() - 2] == 'n' && finds[finds.size() - 3] == 'i')
{
string midfinds = string(finds.begin(), finds.end() - 3);
if (word.find(midfinds) == word.end()) //如果没找到
{
;
}
else
{ //找到了进行输出
cout << "We cannot find the standard word you want,but we think the sentences as follows may contain the word you want:" << endl;
line();
output(sentence[*word[midfinds].begin()], midfinds);
line();
if (word[midfinds].size() > 1)
{ //判断输出更多的例句
cout << "\nHint:\nThere are " << word[midfinds].size() - 1 <<
" more sentences. if you need more,please input the number you want, or input 0 to your next word searching:"
<< endl;
line();
string x;
cin >> x;
if (!check(x))
{cin.clear();;return;};
int xnum = stringToNum(x);
line();
int i = 1;
for (auto it = word[midfinds].begin(); i < word[midfinds].size(); ++i)
{ //输出所要求的例句个数
++it;
cout << i << "、";
output(sentence[*it], midfinds);
cout<< endl;
if (i == xnum)
break;
}
line();
}
{cin.clear();;return;};
}
}
//对于过去时的判断
if (finds.size() >= 3 && finds[finds.size() - 1] == 'd' && finds[finds.size() - 2] == 'e')
{
string midfinds = string(finds.begin(), finds.end() - 2);
if (word.find(midfinds) == word.end())
{
;
}
else
{
cout << "We cannot find the standard word you want,but we think the sentences as follows may contain the word you want:" << endl;
line();
output(sentence[*word[midfinds].begin()],midfinds);
line();
if (word[midfinds].size() > 1)
{
cout << "\nHint:\nThere are " << word[midfinds].size() - 1 <<
" more sentences. if you need more,please input the number you want, or input 0 to your next word searching:"
<< endl;
line();
string x;
cin >> x;
if (!check(x))
{cin.clear();;return;};
int xnum = stringToNum(x);
line();
int i = 1;
for (auto it = word[midfinds].begin(); i < word[midfinds].size(); ++i)
{
++it;
cout << i << "、";
output(sentence[*it], midfinds);
cout << endl;
if (i == xnum)
break;
}
line();
}
{cin.clear();;return;};
}
}
//对于比较级或者er表示一类人的判断
if (finds.size() >= 3 && finds[finds.size() - 1] == 'r' && finds[finds.size() - 2] == 'e')
{
string midfinds = string(finds.begin(), finds.end() - 2);
if (word.find(midfinds) == word.end())
{ //没找到
;
}
else
{ //找到询问是否需要输出更多的例句
cout << "We cannot find the standard word you want,but we think the sentences as follows may contain the word you want:" << endl;
line();
output(sentence[*word[midfinds].begin()],midfinds) ;
line();
if (word[midfinds].size() > 1)
{
cout << "\nHint:\nThere are " << word[midfinds].size() - 1 <<
" more sentences. if you need more,please input the number you want, or input 0 to your next word searching:"
<< endl;
line();
string x;
cin >> x;
if (!check(x))
{cin.clear();;return;};
int xnum = stringToNum(x);
line();
int i = 1;
for (auto it = word[midfinds].begin(); i < word[midfinds].size(); ++i)
{ //输出所要求的例句个数
++it;
cout << i << "、"; output(sentence[*it],midfinds);
cout<< endl;
if (i == xnum)
break;
}
line();
}
{cin.clear();;return;};
}
}
//对于最高级的判断est
if (finds.size() >= 4 && finds[finds.size() - 1] == 't' && finds[finds.size() - 2] == 's' && finds[finds.size() - 3] == 'e')
{
string midfinds = string(finds.begin(), finds.end() - 3);
if (word.find(midfinds) == word.end())
{
;
}
else
{
cout << "We cannot find the standard word you want,but we think the sentences as follows may contain the word you want:" << endl;
line();
output(sentence[*word[midfinds].begin()], midfinds);
line();
if (word[midfinds].size() > 1)
{
cout << "\nHint:\nThere are " << word[midfinds].size() - 1 <<
" more sentences. if you need more,please input the number you want, or input 0 to your next word searching:"
<< endl;
line();
string x;
cin >> x;
if (!check(x))
{cin.clear();;return;};
int xnum = stringToNum(x);
line();
int i = 1;
for (auto it = word[midfinds].begin(); i < word[midfinds].size(); ++i)
{
++it;
cout << i << "、";
output(sentence[*it],midfinds);
cout<< endl;
if (i == xnum)
break;
}
line();
}
{cin.clear();;return;};
}
}
//对于加入现在进行时的判断(词根-》现在进行时)
if (0)
;
else
{ //考虑查找该单词的现在进行时
string midfinds = finds + "ing";
if (word.find(midfinds) == word.end())
;
else
{
cout << "We cannot find the standard word you want,but we think the sentences as follows may contain the word you want:" << endl;
line();
output(sentence[*word[midfinds].begin()], midfinds);
line();
if (word[midfinds].size() > 1)
{
cout << "\nHint:\nThere are " << word[midfinds].size() - 1 <<
" more sentences. if you need more,please input the number you want, or input 0 to your next word searching:"
<< endl;
line();
string x;
cin >> x;
if (!check(x))
{cin.clear();;return;};
int xnum = stringToNum(x);
line();
int i = 1;
for (auto it = word[midfinds].begin(); i < word[midfinds].size(); ++i)
{
++it;
cout << i << "、";
output(sentence[*it],midfinds);
cout<< endl;
if (i == xnum)
break;
}
line();
}
{cin.clear();;return;};
}
}
//对于搜索,模糊搜找最高级
if (0);
else
{
string midfinds = finds + "est";
if (word.find(midfinds) == word.end())
; //如果没找到
else
{
cout << "We cannot find the standard word you want,but we think the sentences as follows may contain the word you want:" << endl;
line();
output(sentence[*word[midfinds].begin()],midfinds);
line();
if (word[midfinds].size() > 1)
{ //如果倒排索引多于1个,输出提示信息
cout << "\nHint:\nThere are " << word[midfinds].size() - 1 <<
" more sentences. if you need more,please input the number you want, or input 0 to your next word searching:"
<< endl;
line();
string x;
cin >> x;
if (!check(x))
{cin.clear();;return;};
int xnum = stringToNum(x);
line();
int i = 1;
for (auto it = word[midfinds].begin(); i < word[midfinds].size(); ++i)
{ //输出所要求的例句个数
++it;
cout << i << "、" ;output(sentence[*it],midfinds);cout<<endl;
if (i == xnum)
break;
}
line();
}
{cin.clear();;return;};
}
}
//对于搜索,模糊搜索比较级
if (0);
else
{
string midfinds = finds + "er";
if (word.find(midfinds) == word.end())
; //没找到
else
{ //判断是否需要更多例句
cout << "We cannot find the standard word you want,but we think the sentences as follows may contain the word you want:" << endl;
line();
output(sentence[*word[midfinds].begin()],midfinds);
line();
if (word[midfinds].size() > 1)
{
cout << "\nHint:\nThere are " << word[midfinds].size() - 1 <<
" more sentences. if you need more,please input the number you want, or input 0 to your next word searching:"
<< endl;
line();
string x;
cin >> x;
if (!check(x))
{cin.clear();;return;};
int xnum = stringToNum(x);
line();
int i = 1;
for (auto it = word[midfinds].begin(); i < word[midfinds].size(); ++i)
{
++it;
cout << i << "、" ;output(sentence[*it],midfinds);cout<<endl;
if (i == xnum)
break;
}
line();
}
{cin.clear();;return;};
}
}
//对于过去时的搜索
if (0);
else
{
string midfinds = finds + "ed";
if (word.find(midfinds) == word.end())
;
else
{
cout << "We cannot find the standard word you want,but we think the sentences as follows may contain the word you want:" << endl;
line();
output(sentence[*word[midfinds].begin()],midfinds);
line();
if (word[midfinds].size() > 1)
{
cout << "\nHint:\nThere are " << word[midfinds].size() - 1 <<
" more sentences. if you need more,please input the number you want, or input 0 to your next word searching:"
<< endl;
line();
string x;
cin >> x;
if (!check(x))
{cin.clear();;return;};
int xnum = stringToNum(x);
line();
int i = 1;
for (auto it = word[midfinds].begin(); i < word[midfinds].size(); ++i)
{
++it;
cout << i << "、" ;output(sentence[*it],midfinds);cout<<endl;
if (i == xnum)
break;
}
line();
}
{cin.clear();;return;};
}
}
//对于单数的搜索
if (0);
else
{
if (finds[finds.size() - 1] != 's')
{
string midfinds = finds + "s";
if (word.find(midfinds) == word.end())
;
else
{
cout << "We cannot find the standard word you want,but we think the sentences as follows may contain the word you want:" << endl;
line();
output(sentence[*word[midfinds].begin()],midfinds);
line();
if (word[midfinds].size() > 1)
{
cout << "\nHint:\nThere are " << word[midfinds].size() - 1 <<
" more sentences. if you need more,please input the number you want, or input 0 to your next word searching:"
<< endl;
line();
string x;
cin >> x;
if (!check(x))
{cin.clear();;return;};
int xnum = stringToNum(x);
line();
int i = 1;
for (auto it = word[midfinds].begin(); i < word[midfinds].size(); ++i)
{
++it;
cout << i << "、" ;output(sentence[*it],midfinds);cout<<endl;
if (i == xnum)
break;
}
line();
}
{cin.clear();;return;};
}
}
if (finds[finds.size() - 1] == 'x' || finds[finds.size() - 1] == 's' || finds[finds.size() - 1] == 'z'
|| (finds.size() >= 3 && finds[finds.size() - 1] == 'h' && (finds[finds.size() - 2] == 'c' || finds[finds.size() - 1] == 's')))
{
string midfinds = finds + "es";
if (word.find(midfinds) == word.end())
{
;
}
else
{
cout << "We cannot find the standard word you want,but we think the sentences as follows may contain the word you want:" << endl;
line();
output(sentence[*word[midfinds].begin()],midfinds);
line();
if (word[midfinds].size() > 1)
{
cout << "\nHint:\nThere are " << word[midfinds].size() - 1 <<
" more sentences. if you need more,please input the number you want, or input 0 to your next word searching:"
<< endl;
line();
string x;
cin >> x;
if (!check(x))
{cin.clear();;return;};
int xnum = stringToNum(x);
line();
int i = 1;
for (auto it = word[midfinds].begin(); i < word[midfinds].size(); ++i)
{
++it;
cout << i << "、" ;output(sentence[*it],midfinds);cout<<endl;
if (i == xnum)
break;
}
line();
}
{cin.clear();;return;};
}
}
}
cout << "the word connot be found in the dictionary!" << endl;
line();
{cin.clear();;return;};
}
line();
output(sentence[*word[finds].begin()], finds);
line();
if (word[finds].size() > 1)
{ //如果有更多例句,进行提示并输出
cout << "\nHint:\nThere are " << word[finds].size() - 1 <<
" more sentences. if you need more,please input the number you want, or input 0 to your next word searching:"
<< endl;
line();
string x;
cin >> x;
if (!check(x) )
{cin.clear();;return;};
int xnum = stringToNum(x);
line();
int i = 1;
for (auto it = word[finds].begin(); i < word[finds].size(); ++i)
{
++it;
cout << i << "、" ;output(sentence[*it],finds);cout<<endl;
if (i == xnum)
break;
}
line();
}
}
int main()
{
FILE* stream1;
freopen_s(&stream1, "index.in", "r", stdin); //读入索引文件
cin >> sentencenum; //读入所有的句子个数
for (int i = 0; i != sentencenum; ++i) //读取所有句子
{
cin >> snum; //读取句子编号
getline(cin, ss); //读取句子
sentence[snum] = ss; //创建句子索引
cin.clear();
}
cin.clear();
cin >> wordnum; //读入所有不同的单词个数
for (int i = 0; i != wordnum; ++i)
{
cin >> ss >> wnum; //读取单词、单词倒排索引个数
cin.clear();
for (int j = 0; j != wnum; ++j)
{
cin >> index; //读取倒排索引
word[ss].insert(index); //建立倒排索引
cin.clear();
}
}
fclose(stream1);
freopen_s(&stream1, "conin$", "r", stdin);
cin.clear();
string finds;
line();
cout << "please input the word you want to search(or input 0 to end your operation):" << endl;
line();
cout << "Your word: ";
while (cin >> finds) //展开单词查询的功能
{
if (finds.size() == 0)
continue;
if (finds == "0")
{
cout << "thanks for your using! bye!" << endl;
break;
}
cout << "\n";
find(finds);
cout << "Your word: ";
continue;
}
}
















 584
584

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









