







如今,大语言模型(LLM)像是超级智能助手,在自然语言处理领域大显身手,能完成从写文章、翻译到回答复杂问题等诸多任务。但这些模型刚训练出来时,就像一个啥都懂一点的 “通才”,虽然知识储备丰富,却不一定能在特定任务上做到尽善尽美。这就好比一个学霸,虽然各个学科都了解,但要在某一门学科竞赛中夺冠,还需要针对这门学科进行专门训练,这时候,微调(Fine-Tuning)就派上用场了。
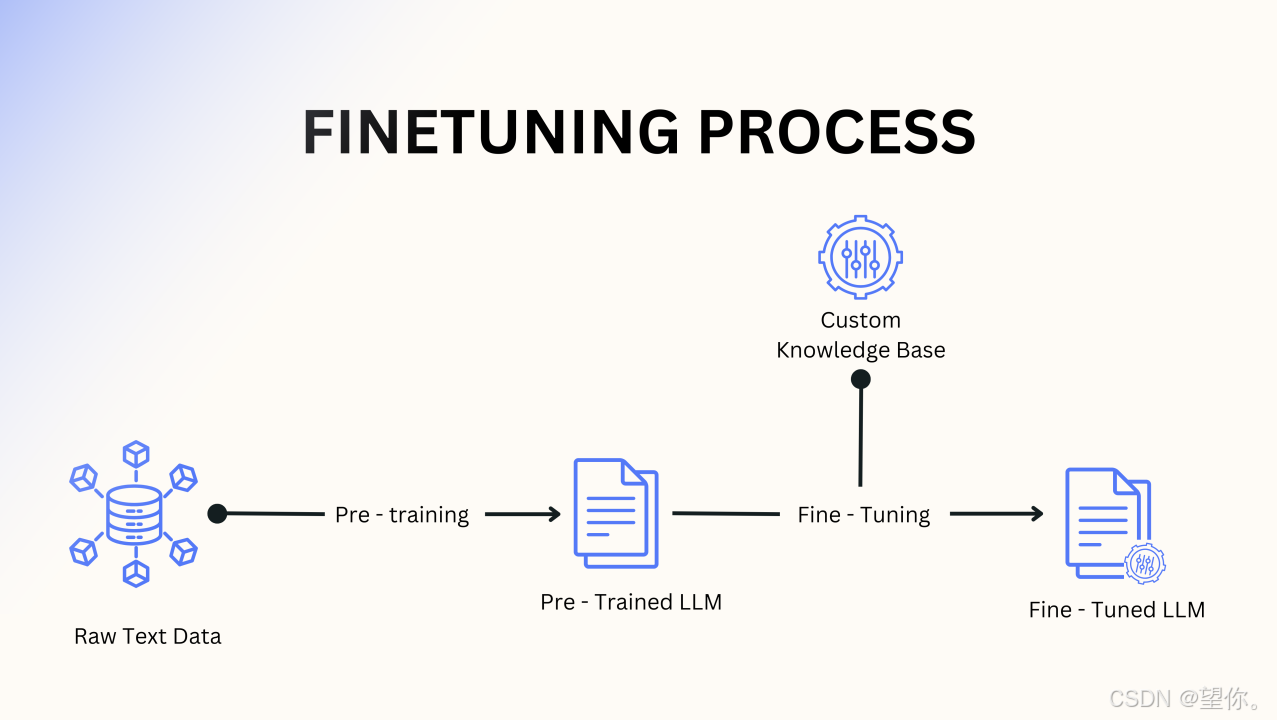
图片来源:谷歌
在大语言模型(LLM)的应用领域,微调是提升模型针对特定任务或领域表现的关键技术。微调,简单来说,就是把已经预训练好的大语言模型,针对特定任务再优化一下,让它能更好地完成像文本分类(判断一篇文章是体育新闻还是科技报道)、情感分析(分析一段文字表达的是开心还是难过)、机器翻译(把中文句子准确翻译成英文)等具体工作。
通过微调,预训练的大语言模型能够更好地适应如文本分类、情感分析、机器翻译等多样化的下游任务需求。接下来,本文将深入探讨大模型的主流微调方法。现有大模型(如BERT、GPT、Vision Transformer等)的主流微调方法主要集中在如何有效调整预训练模型以适应特定下游任务。这些方法目前大致可以分为全参数微调、部分参数微调、基于适配器的微调、基于提示学习的微调等等。
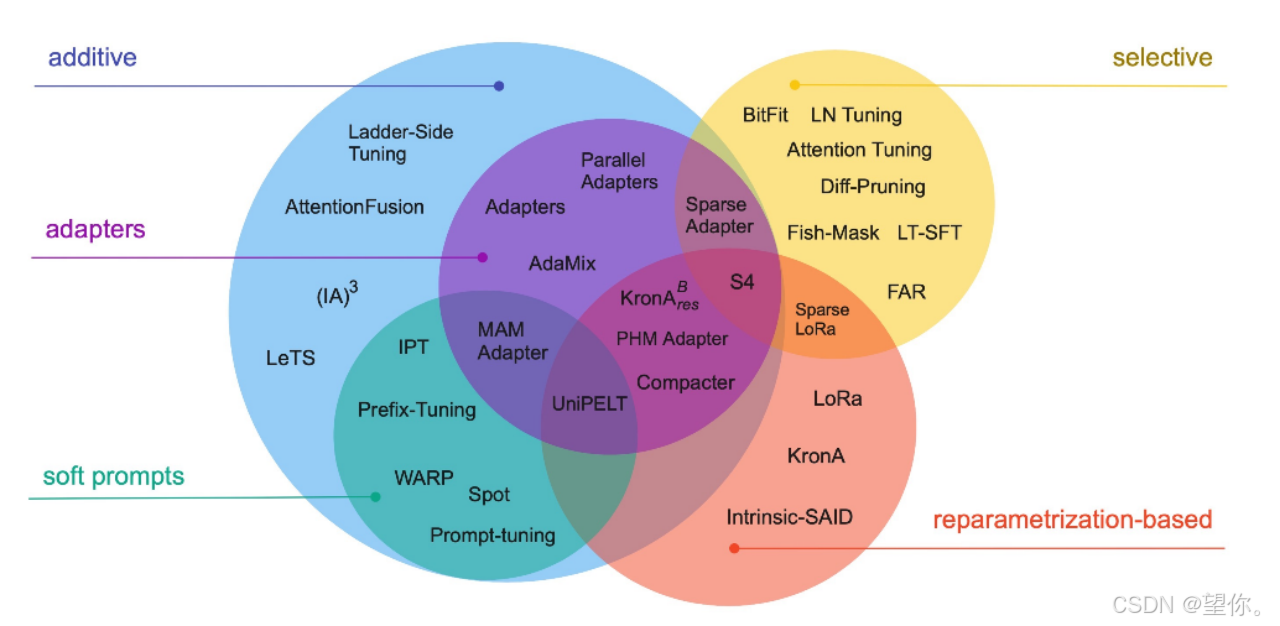
图片来源:大模型参数高效微调技术原理综述 - Stanlei - 博客园
一、全参数微调(Fine-tuning Entire Model)
全参数微调是指对预训练大模型的所有参数进行微调,在新的任务或数据集上进行训练,使模型能够更好地适应特定的应用场景。在这种方法中,预训练模型的所有层和参数都会被更新和优化,以适应目标任务的需求。这种微调方法通常适用于任务和预训练模型之间存在较大差异的情况,或者任务需要模型具有高度灵活性和自适应能力的情况。
该方法能充分挖掘预训练模型知识,在数据与计算资源充足时,性能提升显著。比如在图像领域,利用大规模图像数据集对预训练的卷积神经网络(CNN)进行全参数微调,可显著提升其在特定图像分类任务上的准确率。在自然语言处理方面,针对通用语言模型在金融领域文本分类任务中,通过全参数微调,能有效提升模型对金融专业术语和语义的理解与分类能力。但它计算成本高,且数据量少易过拟合。Full Fine-tuning计算成本高,需要大量的计算资源和时间来完成微调过程;容易过拟合,尤其是在数据量相对较少的情况下,对新数据中的噪声等较为敏感。
基于 PyTorch 框架,给出一旦简单的使用预训练的 BERT 模型为例进行全参数微调的案例。假设使用的数据集为简单的文本分类数据集,利用BERT对文本分类任务进行微调:
import torch
from torch import nn
from torch.utils.data import DataLoader, TensorDataset
from transformers import BertTokenizer, BertForSequenceClassification
from sklearn.model_selection import train_test_split
import numpy as np
# 加载预训练模型和tokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=2)
# 模拟数据加载
texts = ["This is a positive sentence", "This is a negative sentence"]
labels = [1, 0]
input_ids = []
attention_masks = []
for text in texts:
encoded_dict = tokenizer(text, add_special_tokens=True, max_length=128,
padding='max_length', truncation=True)
input_ids.append(encoded_dict['input_ids'])
attention_masks.append(encoded_dict['attention_mask'])
input_ids = torch.tensor(input_ids)
attention_masks = torch.tensor(attention_masks)
labels = torch.tensor(labels)
# 划分训练集和测试集
train_inputs, test_inputs, train_masks, test_masks, train_labels, test_labels = train_test_split(
input_ids, attention_masks, labels, test_size=0.2, random_state=42)
train_dataset = TensorDataset(train_inputs, train_masks, train_labels)
train_dataloader = DataLoader(train_dataset, batch_size=2)
# 定义优化器和损失函数
optimizer = torch.optim.AdamW(model.parameters(), lr=2e-5)
loss_fn = nn.CrossEntropyLoss()
# 微调训练
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
for epoch in range(3):
model.train()
total_loss = 0
for batch in train_dataloader:
batch = tuple(t.to(device) for t in batch)
b_input_ids, b_input_mask, b_labels = batch
optimizer.zero_grad()
outputs = model(b_input_ids, token_type_ids=None,
attention_mask=b_input_mask, labels=b_labels)
loss = outputs[0]
loss.backward()
optimizer.step()
total_loss += loss.item()
print(f'Epoch {epoch + 1} average loss: {total_loss / len(train_dataloader)}')二、部分参数微调(Frozen Backbone + Task-specific Head)
在大模型微调的技术体系中,基于冻结部分参数的微调(也常被称为部分微调)是一种极为有效的策略。该方法在微调进程里,仅对模型的顶层或者少数几层参数进行更新,而让预训练模型的底层参数保持固定不变。
从模型学习特性来看,预训练模型的底层参数主要负责学习各类通用特征。以自然语言处理中的 Transformer 架构模型为例,底层参数能够捕捉到语言的基础语法结构、词汇语义等通用信息;在计算机视觉领域的卷积神经网络(CNN)中,底层参数则可提取图像的边缘、纹理等基础视觉特征。这些通用特征是模型在大规模数据上进行预训练的成果,具有广泛的适用性。通过冻结底层参数,不仅能够避免在微调过程中对这些已学习到的通用知识进行不必要的修改,而且还能显著减少计算量。因为需要参与计算和更新的参数数量大幅降低,所以模型的微调速度得以加快。同时,这在一定程度上还能避免过拟合现象的发生,尤其是当用于微调的数据集规模相对较小时,过拟合的风险会显著降低。
这种微调方式通常适用于两种典型场景。一是目标任务与预训练模型所基于的任务之间存在一定相似性的情况。例如,在自然语言处理中,若预训练模型是基于大规模通用文本训练而成,而目标任务是对新闻领域的文本进行情感分析,由于新闻文本同样属于自然语言范畴,与预训练任务有共通之处,此时采用部分微调,利用预训练模型的底层通用语言知识,仅对顶层参数进行针对新闻情感分析任务的调整,就能高效地使模型适应新任务。二是当任务数据集较小时,有限的数据量难以支撑对整个模型的全面微调,部分微调便成为一种更为合适的选择。因为它减少了需要拟合的数据量,降低了模型对数据规模的依赖。
下面给出基于相同的任务利用冻结前n层参数的方式进行微调的代码示例:
import torch
from torch import nn
from torch.utils.data import DataLoader, TensorDataset
from transformers import BertTokenizer, BertForSequenceClassification
from sklearn.model_selection import train_test_split
import numpy as np
# 加载预训练模型和tokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=2)
# 冻结前n层参数
n = 6
for name, param in model.bert.named_parameters():
if 'layer' in name and int(name.split('.')[2]) < n:
param.requires_grad = False
# 模拟数据加载
texts = ["This is a positive sentence", "This is a negative sentence"]
labels = [1, 0]
input_ids = []
attention_masks = []
for text in texts:
encoded_dict = tokenizer(text, add_special_tokens=True, max_length=128,
padding='max_length', truncation=True)
input_ids.append(encoded_dict['input_ids'])
attention_masks.append(encoded_dict['attention_mask'])
input_ids = torch.tensor(input_ids)
attention_masks = torch.tensor(attention_masks)
labels = torch.tensor(labels)
# 划分训练集和测试集
train_inputs, test_inputs, train_masks, test_masks, train_labels, test_labels = train_test_split(
input_ids, attention_masks, labels, test_size=0.2, random_state=42)
train_dataset = TensorDataset(train_inputs, train_masks, train_labels)
train_dataloader = DataLoader(train_dataset, batch_size=2)
# 定义优化器和损失函数
optimizer = torch.optim.AdamW(filter(lambda p: p.requires_grad, model.parameters()), lr=2e-5)
loss_fn = nn.CrossEntropyLoss()
# 微调训练
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
for epoch in range(3):
model.train()
total_loss = 0
for batch in train_dataloader:
batch = tuple(t.to(device) for t in batch)
b_input_ids, b_input_mask, b_labels = batch
optimizer.zero_grad()
outputs = model(b_input_ids, token_type_ids=None,
attention_mask=b_input_mask, labels=b_labels)
loss = outputs[0]
loss.backward()
optimizer.step()
total_loss += loss.item()
print(f'Epoch {epoch + 1} average loss: {total_loss / len(train_dataloader)}')2.1 PEFT(Parameter-Efficient Fine-Tuning)
2.1.1 什么是PEFT?
PEFT,即 Parameter-Efficient Fine-Tuning(高效参数微调),是在深度学习领域针对大规模预训练模型(如自然语言处理中的 BERT、GPT 系列,计算机视觉中的 ViT 等)所提出的一种极具创新性的微调策略。在传统的模型微调过程中,往往需要对预训练模型的所有参数进行调整,这不仅会消耗大量的计算资源,包括高昂的 GPU 算力成本和漫长的训练时间,还对存储设备提出了较高的要求,需要存储大量的参数更新信息。
而 PEFT 的出现,打破了这一困境。它通过巧妙的设计,冻结预训练模型中的大部分参数,使其不再参与微调过程中的梯度更新。仅针对少量关键参数进行调整,或者添加额外的轻量模块,如 Adapter Tuning 中的 Adapter 结构、Prefix Tuning 中的前缀模块等,以此来使模型适应各种不同的下游任务。这种方式极大地减少了在微调过程中所需的计算量和存储量,使得在资源有限的情况下,也能够高效地对大规模预训练模型进行任务适配。
2.1.2 PEFT的核心思想
大规模预训练模型的参数空间极其庞大,但在迁移到特定任务时,只有一部分参数对任务表现起到关键作用。PEFT的核心思想是减少任务相关参数的调整范围,通过训练少量额外参数或对某些权重模块进行有效调整,实现与全模型微调(Fine-tuning Entire Model)接近的性能。现有的基于Transformer结构的各微调方法的原理和作用位置如下图所示:
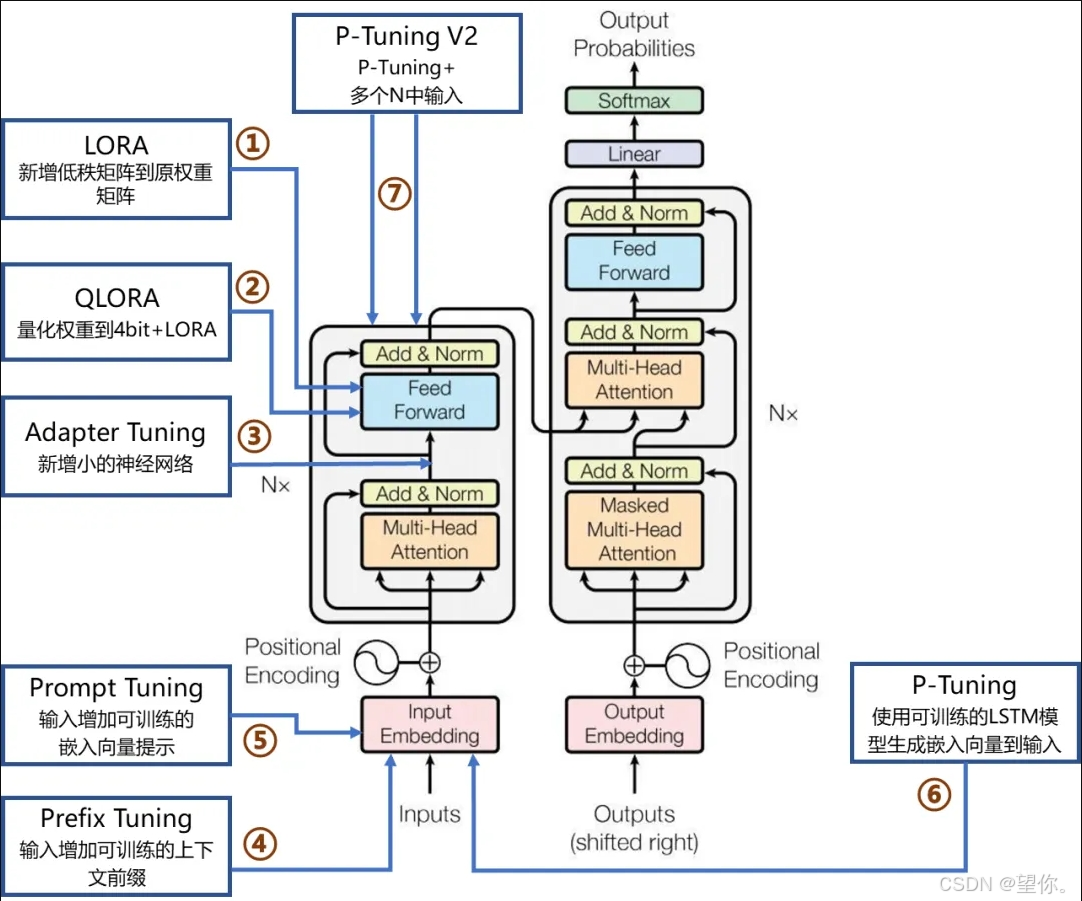
图片来源:大模型微调的几种方法 - 小飞侠
2.2 常见的PEFT方法
2.2.1 Adapter Tuning(基于适配器的方法)
谷歌的研究人员在 2019 年发表的论文《Parameter-Efficient Transfer Learning for NLP》中,针对 BERT 提出了一种名为 Adapter Tuning(自适应调整)的微调方式,正式开启了高效参数迁移学习(PEFT)的研究。
在当时的背景下,面对特定的下游任务,传统的 Full-fintuning(全量微调)方法虽然能够使模型充分适应新任务,但由于需要对预训练模型中的所有参数进行调整,计算成本极高,效率低下。而另一种方法,固定预训练模型的某些层,仅微调接近下游任务的那几层参数,虽然在一定程度上减少了计算量,却往往难以达到令人满意的效果。在这种情况下,Adapter Tuning 方法应运而生。
Adapter Tuning 在模型的每一层插入适配模块(Adapter),该模块通常由一个小型的瓶颈结构组成,仅训练这些模块,冻结其余参数。Adapter 结构设计精巧,为减少额外参数,先通过 down-project 层将高维特征映射为低维,降低计算复杂度,接着经非线性层增强表达能力,再用 up-project 层将低维特征映射回高维以适配后续计算。此外,还设有 skip-connection 结构,在 Adapter 学习不佳时,让模型能退化为原本状态,保障稳定性与可靠性。其结构如下所示:
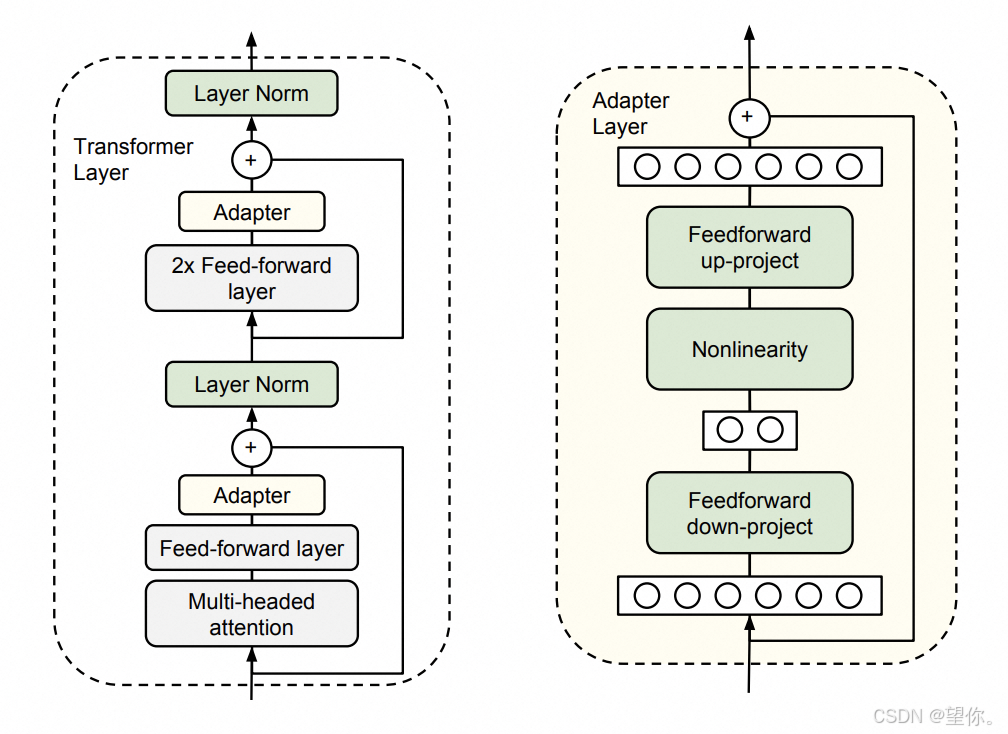
论文链接:https://proceedings.mlr.press/v97/houlsby19a/houlsby19a.pdf
其适配模块结构可以表达为:

给出相应的代码示例:
from transformers.adapters import BertAdapterModel
# 加载BERT模型并添加Adapter模块
model = BertAdapterModel.from_pretrained("bert-base-uncased")
# 添加任务适配器
model.add_adapter("task_adapter")
model.train_adapter("task_adapter")
# 仅更新Adapter模块参数
optimizer = torch.optim.Adam(model.get_adapter("task_adapter").parameters(), lr=5e-5)
基于同样的文本分类任务利用适配器进行微调:
from transformers import AutoTokenizer, AutoModelForSequenceClassification
from datasets import load_dataset
from adapter_transformers import AdapterTrainer, AdapterConfig
import torch
# 加载数据集
dataset = load_dataset('glue', 'mrpc')
tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')
def tokenize_function(examples):
return tokenizer(examples["sentence1"], examples["sentence2"], padding="max_length", truncation=True)
tokenized_datasets = dataset.map(tokenize_function, batched=True)
small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(100))
small_eval_dataset = tokenized_datasets["validation"].shuffle(seed=42).select(range(50))
# 加载模型并添加适配器
model = AutoModelForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=2)
adapter_config = AdapterConfig(mh_adapter=True, output_adapter=True)
model.add_adapter("mrpc_task", config=adapter_config)
model.train_adapter("mrpc_task")
# 定义训练器
trainer = AdapterTrainer(
model=model,
args=torch.optim.AdamW(model.parameters(), lr=2e-5),
train_dataset=small_train_dataset,
eval_dataset=small_eval_dataset,
tokenizer=tokenizer,
)
# 微调训练
trainer.train()2.2.2 LoRA (Low-Rank Adaptation):低秩适配
低秩适配方法致力于将模型权重的改变限制在一个低秩子空间内。这通常涉及对模型的权重矩阵进行分解,只微调其中的一小部分参数。这样可以有效减少计算资源的消耗,同时仍然允许模型有足够的灵活性来学习新任务。LoRA和它的变种,如Q-LoRA、Delta-LoRA、LoRA-FA等,都属于这个类别。LoRA 是通过在模型中的特定权重矩阵上引入低秩分解来实现微调的一种方法。它假设模型权重变化可以通过两个低秩矩阵的乘积来近似。其图示如下:
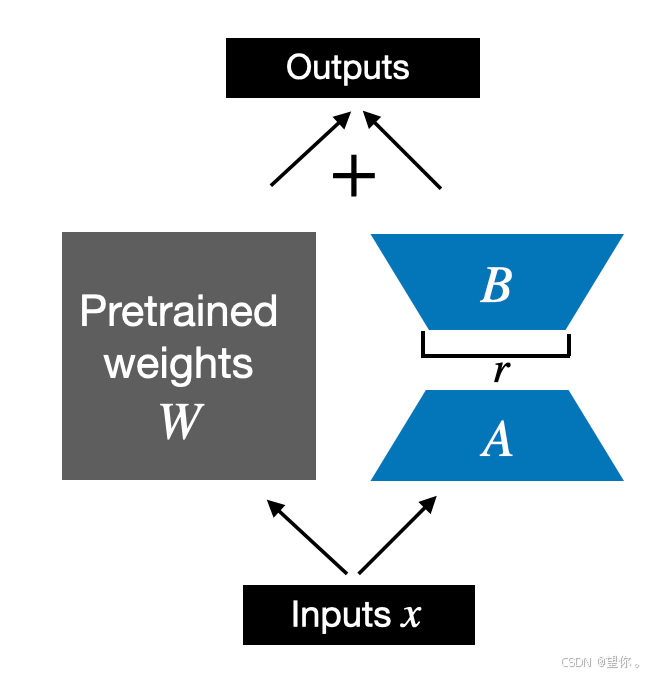
LoRA的核心思想为:
- 低秩分解:在不改变预训练模型原始权重的基础上,把模型中高维度的权重矩阵分解为两个低秩矩阵的乘积。举例来说,对于一个形状为(m * n)的权重矩阵(W),将其分解为一个(m * r)的矩阵(A)和一个(r * n)的矩阵(B),其中(r)远小于(m)和(n),即(W = AB) 。
- 参数冻结与更新:冻结预训练模型的原始参数,在微调时仅对新引入的低秩矩阵(A)和(B)进行训练更新,保持原始权重矩阵(W)不变。在推理阶段,再通过(AB)的乘积重构权重矩阵(W),进而进行模型推理。
其核心公式和原理为:


利用lora的简单代码示例:
from peft import LoraConfig, get_peft_model
# 配置LoRA
config = LoraConfig(r=8, lora_alpha=16, target_modules=["query", "value"], lora_dropout=0.1)
# 获取LoRA模型
model = get_peft_model(pretrained_model, config)
# 正常微调LoRA模块
optimizer = torch.optim.AdamW(model.parameters(), lr=5e-5)
2.2.3 Prefix Tuning
想要更好地理解Prefix Tuning 便不得不提及 Pattern-Exploiting Training(PET)。PET 主要思想是借助由自然语言构成的模版(英文常称 Pattern 或 Prompt),将下游任务转化为一个完形填空任务,这样就可以用 BERT 的 MLM(Masked Language Model)模型来进行预测。例如在情感分析任务中,通过设计 “这个句子表达的是 [MASK] 情感” 这样的模板,将文本填充进去,然后利用 BERT 模型预测 [MASK] 处的内容,以此判断情感倾向。
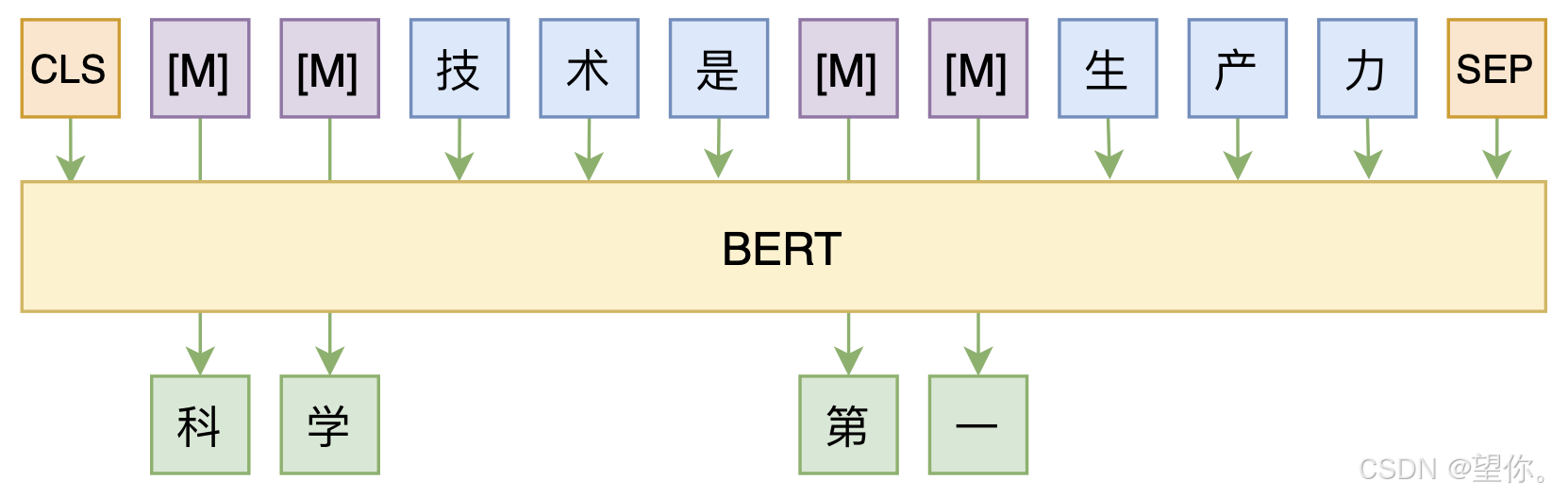
Prefix Tuning 是一种针对大规模预训练语言模型的参数高效微调技术,旨在解决传统全量微调计算成本高、资源消耗大的问题。它通过在输入序列前添加可训练的前缀向量,引导模型在特定任务中关注相关信息,从而在不改变模型主体参数的情况下,实现对不同下游任务的适配,在自然语言处理的各类任务,如文本分类、问答系统、文本生成等中广泛应用。
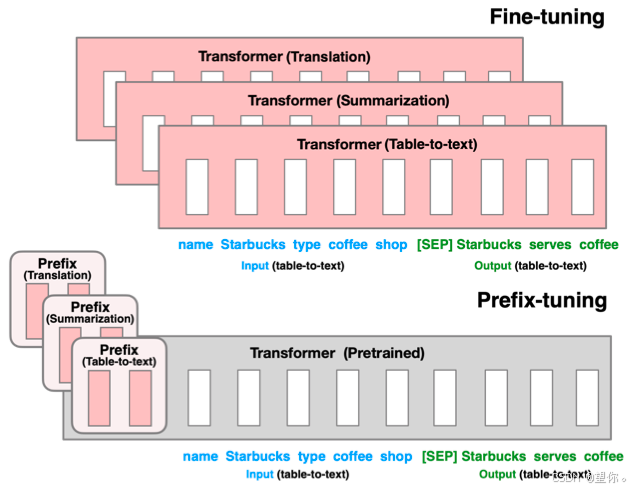
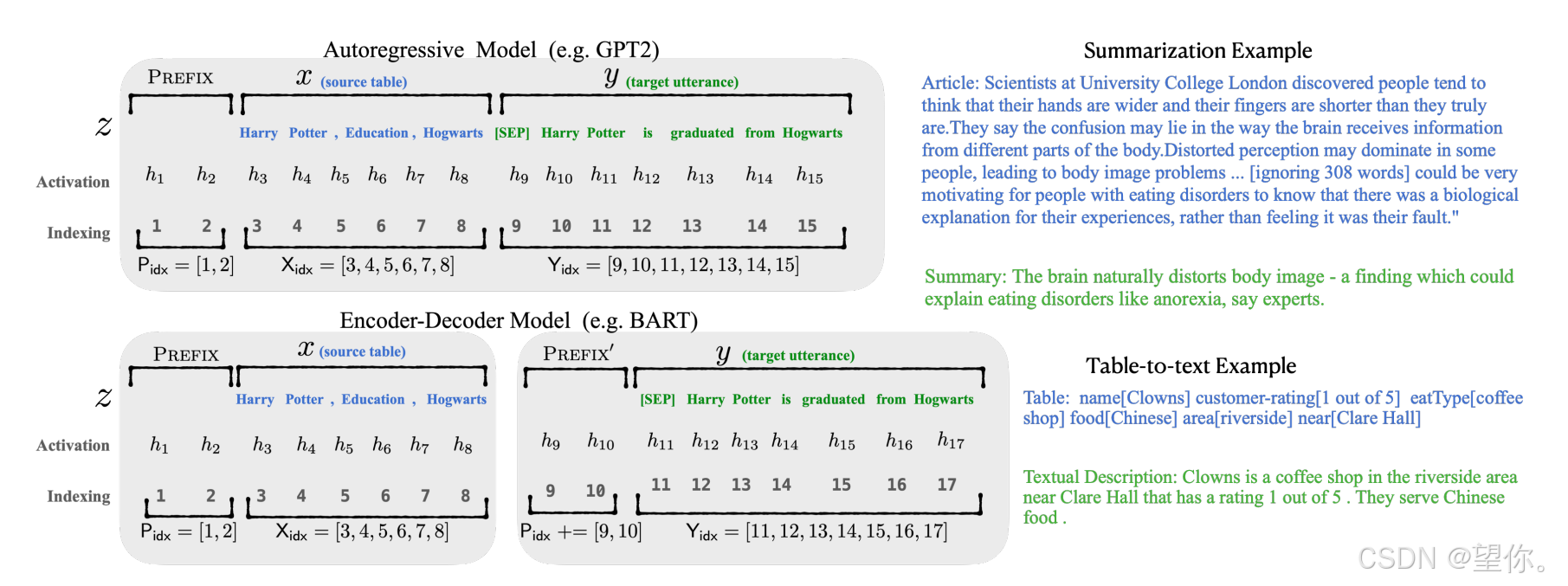
图片来源:https://aclanthology.org/2021.acl-long.353.pdf
与Full-finetuning 更新所有参数的方式不同,该方法是在输入 token 之前构造一段任务相关的 virtual tokens 作为 Prefix,然后训练的时候只更新 Prefix 部分的参数,而 Transformer 中的其他部分参数固定。其核心思想为:
- 前缀添加:在模型输入的 token 序列前,添加一段长度固定的可训练前缀向量。这些前缀向量就像是为模型提供的特定任务 “说明书”,包含了任务相关的关键信息和引导信号。以文本分类任务为例,前缀向量可以包含关于类别标签的语义线索,帮助模型更好地理解任务需求。
- 模型主体冻结:在微调过程中,保持预训练模型的主体参数不变,仅对添加的前缀向量进行训练。这样既充分利用了预训练模型在大规模数据上学习到的通用语言知识,又避免了对大量主体参数的调整,大大降低了计算成本和过拟合风险。
以下是使用 Prefix Tuning 进行文本分类微调的代码示例,基于 Hugging Face 的transformers库,以 BERT 模型为例,使用的数据集为 IMDB 影评数据集,判断影评的情感倾向。
import torch
from torch.utils.data import DataLoader, TensorDataset
from transformers import AutoTokenizer, AutoModelForMaskedLM, AdamW
import datasets
# 加载IMDB数据集
imdb = datasets.load_dataset('imdb')
# 加载预训练的BERT模型和tokenizer
tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')
model = AutoModelForMaskedLM.from_pretrained('bert-base-uncased')
# 前缀长度
prefix_length = 10
# 初始化前缀参数,可训练
prefix_embeddings = torch.nn.Parameter(torch.randn(prefix_length, model.config.hidden_size))
# 冻结模型主体参数
for param in model.parameters():
param.requires_grad = False
# 数据预处理
def preprocess_function(examples):
inputs = tokenizer(examples["text"], truncation=True, padding='max_length')
labels = [1 if label == "positive" else 0 for label in examples["label"]]
return {**inputs, "labels": labels}
tokenized_datasets = imdb.map(preprocess_function, batched=True)
train_dataset = tokenized_datasets["train"]
test_dataset = tokenized_datasets["test"]
# 创建数据加载器
train_dataloader = DataLoader(
TensorDataset(
torch.tensor(train_dataset["input_ids"]),
torch.tensor(train_dataset["attention_mask"]),
torch.tensor(train_dataset["labels"])
),
batch_size=16,
shuffle=True
)
test_dataloader = DataLoader(
TensorDataset(
torch.tensor(test_dataset["input_ids"]),
torch.tensor(test_dataset["attention_mask"]),
torch.tensor(test_dataset["labels"])
),
batch_size=16,
shuffle=False
)
# 定义优化器,只优化前缀参数
optimizer = AdamW([prefix_embeddings], lr=2e-5)
# 训练模型
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
prefix_embeddings = prefix_embeddings.to(device)
for epoch in range(3):
model.train()
total_loss = 0
for batch in train_dataloader:
input_ids, attention_mask, labels = batch
input_ids = input_ids.to(device)
attention_mask = attention_mask.to(device)
labels = labels.to(device)
# 拼接前缀向量和输入
prefix_inputs = torch.cat([prefix_embeddings.unsqueeze(0).repeat(input_ids.size(0), 1, 1), input_ids.unsqueeze(1).float()], dim=1)
prefix_attention_mask = torch.cat([torch.ones(input_ids.size(0), prefix_length, dtype=torch.long).to(device), attention_mask.unsqueeze(1).float()], dim=1)
outputs = model(prefix_inputs, attention_mask=prefix_attention_mask, labels=labels)
loss = outputs.loss
total_loss += loss.item()
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f'Epoch {epoch + 1}, Average Loss: {total_loss / len(train_dataloader)}')
# 评估模型
model.eval()
correct = 0
total = 0
with torch.no_grad():
for batch in test_dataloader:
input_ids, attention_mask, labels = batch
input_ids = input_ids.to(device)
attention_mask = attention_mask.to(device)
labels = labels.to(device)
prefix_inputs = torch.cat([prefix_embeddings.unsqueeze(0).repeat(input_ids.size(0), 1, 1), input_ids.unsqueeze(1).float()], dim=1)
prefix_attention_mask = torch.cat([torch.ones(input_ids.size(0), prefix_length, dtype=torch.long).to(device), attention_mask.unsqueeze(1).float()], dim=1)
outputs = model(prefix_inputs, attention_mask=prefix_attention_mask)
logits = outputs.logits
predictions = torch.argmax(logits, dim=-1)
total += labels.size(0)
correct += (predictions == labels).sum().item()
print(f'Accuracy: {correct / total}')
2.2.4 Prompt Tuning-v1
Prompt Tuning(也被称为 P-Tuning)是谷歌在 2021 年论文《The Power of Scale for Parameter-Efficient Prompt Tuning》中提出的参数高效微调方法。其通过固定模型前馈层参数,仅更新部分 embedding 参数,实现对大模型的低成本微调,且不涉及底层模型参数更新,主要通过精心设计输入提示来引导预训练模型输出。与传统全量微调不同,它无需对模型的所有参数进行更新,而是侧重于调整提示部分的参数或与提示相关的参数,从而实现模型在不同下游任务上的高效适配。
P-Tuning v1 主要利用 prompt encoder(BiLSTM + MLP)将 pseudo prompt 编码(离散 token)后与 input embedding 拼接,同时借助 LSTM 进行 Reparamerization 加速训练,还会引入少量自然语言提示的锚字符(如 “Britain”)提升效果。不过,P-Tuning v1 存在任务不通用和规模不通用的缺点,在复杂自然语言理解(NLU)任务上效果欠佳,且要求预训练模型参数量不能过小。
其效果受多种因素影响:当模型参数达到一定量级,Prompt 长度为 1 也能有不错效果,长度为 20 效果极好;Random Uniform 初始化方式在模型参数较小时明显弱于其他方式,但参数足够大时差异消失;LM Adaptation 预训练方式在模型较小时效果好,规模大时差异不明显;模型参数较小时,微调步数越多效果越好,参数达到一定规模时,zero shot 也能取得不错效果,当参数达到 100 亿规模时,与全参数微调效果相当。
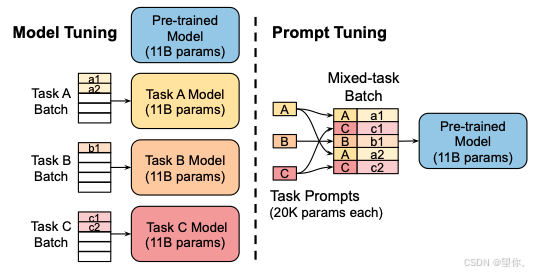
其核心思想为:
- 提示构建:围绕特定任务构建具有引导性的文本提示。这些提示通常以自然语言形式存在,嵌入在输入文本中,用来为模型提供任务相关的背景信息、操作指令等。例如在情感分析任务中,可能会使用 “请判断以下文本的情感倾向是正面、负面还是中性:[文本内容]” 这样的提示,明确告知模型需要完成的任务。
- 参数微调:在微调过程中,主要对提示中的可训练参数进行调整。这些参数可以是提示中的特定标记、向量表示,或者是与提示生成和处理相关的模块参数。通过调整这些参数,让模型能够更好地理解提示的意图,进而在任务中表现更优。同时,保持预训练模型的大部分参数不变,减少计算成本和过拟合风险。
以下为利用P-Tuning v1 进行文本分类任务,基于BERT模型进行微调的代码示例:
import torch
import torch.nn as nn
from torch.utils.data import DataLoader, TensorDataset
from transformers import AutoTokenizer, AutoModel, AdamW
import numpy as np
texts = ["这是一条商务文档", "这是一条生活记录", "这是一条娱乐新闻"]
labels = [0, 1, 2]
tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')
# 定义提示
prompt = "这篇文档属于[商务/生活/娱乐]类别:"
# 数据预处理
input_ids_list = []
attention_masks_list = []
for text in texts:
new_text = prompt + text
encoded_dict = tokenizer(new_text, add_special_tokens=True, max_length=128,
padding='max_length', truncation=True)
input_ids_list.append(encoded_dict['input_ids'])
attention_masks_list.append(encoded_dict['attention_mask'])
input_ids = torch.tensor(input_ids_list)
attention_masks = torch.tensor(attention_masks_list)
labels = torch.tensor(labels)
# 创建数据集和数据加载器
dataset = TensorDataset(input_ids, attention_masks, labels)
dataloader = DataLoader(dataset, batch_size=2)
# 加载预训练模型
model = AutoModel.from_pretrained('bert-base-uncased')
# 假设prompt encoder的BiLSTM和MLP
class PromptEncoder(nn.Module):
def __init__(self, hidden_size):
super(PromptEncoder, self).__init__()
self.bilstm = nn.LSTM(hidden_size, hidden_size // 2, bidirectional=True)
self.mlp = nn.Linear(hidden_size, hidden_size)
def forward(self, x):
out, _ = self.bilstm(x)
out = self.mlp(out)
return out
prompt_encoder = PromptEncoder(model.config.hidden_size)
# 固定BERT模型参数
for param in model.parameters():
param.requires_grad = False
# 定义优化器,只优化prompt encoder的参数
optimizer = AdamW(prompt_encoder.parameters(), lr=2e-5)
criterion = nn.CrossEntropyLoss()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
prompt_encoder.to(device)
for epoch in range(3):
model.train()
prompt_encoder.train()
running_loss = 0.0
for i, batch in enumerate(dataloader):
input_ids_batch, attention_masks_batch, labels_batch = batch
input_ids_batch = input_ids_batch.to(device)
attention_masks_batch = attention_masks_batch.to(device)
labels_batch = labels_batch.to(device)
with torch.no_grad():
bert_outputs = model(input_ids_batch, attention_mask=attention_masks_batch)
sequence_output = bert_outputs.last_hidden_state
# 编码pseudo prompt
prompt_embedding = prompt_encoder(sequence_output)
new_sequence_output = torch.cat([prompt_embedding, sequence_output], dim=1)
logits = nn.Linear(new_sequence_output.size(-1), 3)(new_sequence_output[:, 0, :])
loss = criterion(logits, labels_batch)
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f'Epoch {epoch + 1}, Loss: {running_loss / len(dataloader)}')
2.2.5 Prompt Tuning-v2
P-Tuning v2基于P-Tuning和Prefix Tuning技术,引入Deep Prompt Encoding和Multi-task Learning等策略优化。实验表明,仅精调0.1%参数量,在330M到10B不同参数规模的语言模型(LM)上,都能取得与Fine-tuning媲美的性能,目标是让Prompt Tuning在不同参数规模的预训练模型和不同下游任务中都能达到与全量微调相匹敌的效果。
与P-Tuning v1相比,v2将continuous prompt加在序列前端,且每一层都加入可训练的prompts,避免了可训练参数受句子长度限制的问题。此外,P-Tuning v2还有以下关键设计因素:Reparameterization方面,面对不同任务和数据集,MLP构造可训练embedding的方法可能产生相反结论;Prompt Length因任务而异,简单分类任务length = 20最佳,复杂任务需要更长长度;Multi-task Learning是可选策略,可提供更好初始化以提升性能;Classification Head摒弃使用LM head预测动词的方式,采用和BERT一样在第一个token处应用随机初始化的分类头。
下图为v1版本到v2版本的可视化:蓝色部分为参数冻结,橙色部分为可训练部分,可以看到右侧的p-tuning v2中,将continuous prompt加在序列前端,并且每一层都加入可训练的prompts。在左图v1模型中,只将prompt插入input embedding中,会导致可训练的参数被句子的长度所限制。
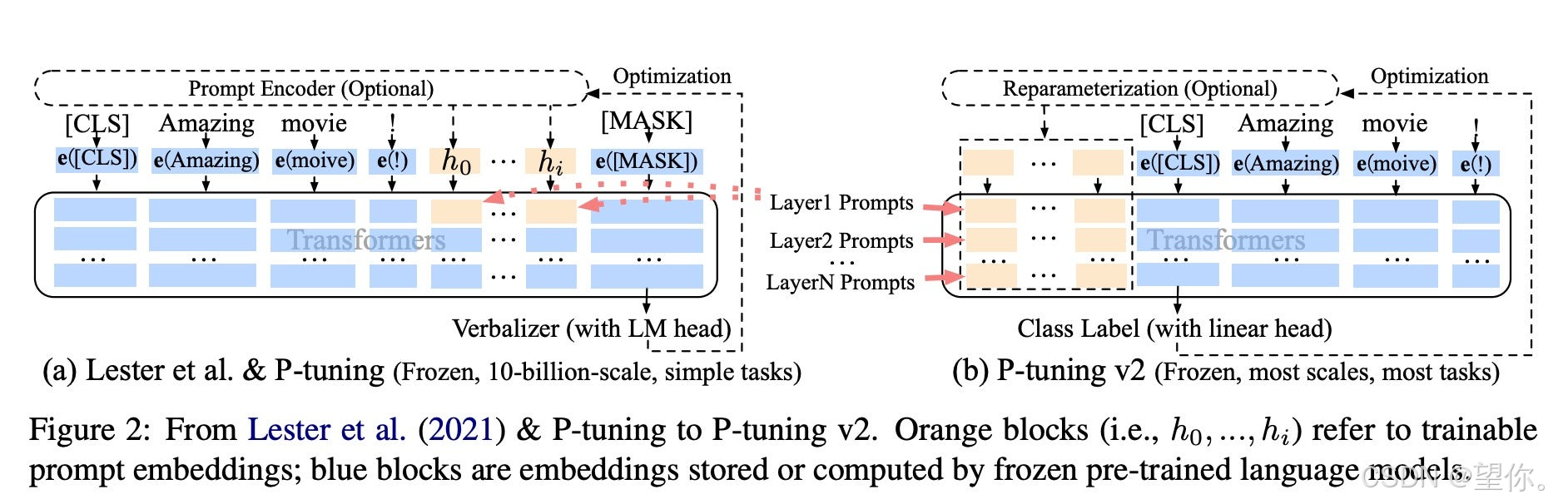
图片来源:https://arxiv.org/pdf/2110.07602
以下为利用P-Tuning v2 进行文本分类任务,基于BERT模型进行微调的代码示例:
import torch
import torch.nn as nn
from torch.utils.data import DataLoader, TensorDataset
from transformers import AutoTokenizer, AutoModel, AdamW
import numpy as np
texts = ["这是一条商务文档", "这是一条生活记录", "这是一条娱乐新闻"]
labels = [0, 1, 2]
tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')
# 数据预处理
input_ids_list = []
attention_masks_list = []
for text in texts:
encoded_dict = tokenizer(text, add_special_tokens=True, max_length=128,
padding='max_length', truncation=True)
input_ids_list.append(encoded_dict['input_ids'])
attention_masks_list.append(encoded_dict['attention_mask'])
input_ids = torch.tensor(input_ids_list)
attention_masks = torch.tensor(attention_masks_list)
labels = torch.tensor(labels)
# 创建数据集和数据加载器
dataset = TensorDataset(input_ids, attention_masks, labels)
dataloader = DataLoader(dataset, batch_size=2)
# 加载预训练模型
model = AutoModel.from_pretrained('bert-base-uncased')
# 假设连续prompt向量和多层可训练prompts
class DeepPromptEncoder(nn.Module):
def __init__(self, hidden_size, prompt_length, num_layers):
super(DeepPromptEncoder, self).__init__()
self.prompt_length = prompt_length
self.prompt_embeddings = nn.Parameter(torch.randn(num_layers, prompt_length, hidden_size))
self.mlp = nn.ModuleList([nn.Linear(hidden_size, hidden_size) for _ in range(num_layers)])
def forward(self, x, attention_mask):
batch_size = x.size(0)
new_x = []
for i in range(len(self.prompt_embeddings)):
prompt_embedding = self.prompt_embeddings[i].unsqueeze(0).repeat(batch_size, 1, 1)
x_with_prompt = torch.cat([prompt_embedding, x], dim=1)
attention_mask_with_prompt = torch.cat([torch.ones(batch_size, self.prompt_length, dtype=torch.long).to(x.device),
attention_mask], dim=1)
x_with_prompt = self.mlp[i](x_with_prompt)
new_x.append(x_with_prompt)
return torch.stack(new_x, dim=1)
prompt_length = 10
num_layers = 3
deep_prompt_encoder = DeepPromptEncoder(model.config.hidden_size, prompt_length, num_layers)
# 固定BERT模型参数
for param in model.parameters():
param.requires_grad = False
# 定义优化器,只优化deep_prompt_encoder的参数
optimizer = AdamW(deep_prompt_encoder.parameters(), lr=2e-5)
criterion = nn.CrossEntropyLoss()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
deep_prompt_encoder.to(device)
for epoch in range(3):
model.train()
deep_prompt_encoder.train()
running_loss = 0.0
for i, batch in enumerate(dataloader):
input_ids_batch, attention_masks_batch, labels_batch = batch
input_ids_batch = input_ids_batch.to(device)
attention_masks_batch = attention_masks_batch.to(device)
labels_batch = labels_batch.to(device)
with torch.no_grad():
bert_outputs = model(input_ids_batch, attention_mask=attention_masks_batch)
sequence_output = bert_outputs.last_hidden_state
new_sequence_output = deep_prompt_encoder(sequence_output, attention_masks_batch)
logits = nn.Linear(new_sequence_output.size(-1), 3)(new_sequence_output[:, -1, 0, :])
loss = criterion(logits, labels_batch)
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f'Epoch {epoch + 1}, Loss: {running_loss / len(dataloader)}')
2.3 Huggingface上的PEFT库介绍
2.3.1 Prefix Tuning 的封装
学习网址:https://huggingface.co/docs/peft/package_reference/prefix_tuning
PEFT 库通过PrefixTuning类对 Prefix Tuning 进行封装。
- 实现方式:PrefixTuning类在模型输入层前添加可训练的前缀向量。在输入序列进入模型之前,将前缀向量与输入序列进行拼接。并且,在训练过程中,仅更新前缀向量的参数,而保持原模型参数不变。这一过程通过定义新的前向传播方法,将前缀向量的计算融入到模型的输入流程中。
- 关键参数:prefix_length(前缀长度)是一个重要参数,它决定了前缀向量的长度,合适的前缀长度能有效引导模型学习任务相关信息。此外,还有prefix_projection(是否对前缀进行投影变换)等参数,用于调整前缀向量的处理方式。
- 使用优势:借助 PEFT 库的封装,用户可以方便地在不同预训练模型上应用 Prefix Tuning,无需关注底层的实现细节。同时,库中提供的工具函数可以帮助用户快速构建和训练 Prefix Tuning 模型,提高开发效率。
2.3.2 LoRA 的封装
学习网址:https://huggingface.co/docs/peft/package_reference/lora
在 PEFT 库中,对 LoRA 的封装主要体现在LoraModel类。通过这个类,用户可以轻松将 LoRA 应用到预训练模型中。
- 实现方式:LoraModel在原预训练模型的基础上,为指定的层插入低秩矩阵。例如,在 Transformer 架构中,会在注意力机制模块的查询(Query)、键(Key)和值(Value)矩阵前向传播时,添加低秩矩阵的计算。这一过程是在不改变原模型结构的前提下,通过修改前向传播函数实现的。
- 关键参数:主要包括r(低秩矩阵的秩)、lora_alpha(缩放因子)和lora_dropout(Dropout 概率)。r决定了低秩矩阵的维度,较小的r意味着更少的可训练参数和更低的计算成本,但可能会影响模型的表达能力;lora_alpha用于调整低秩矩阵对模型输出的影响程度;lora_dropout则用于防止过拟合。
- 使用优势:用户无需手动实现复杂的低秩矩阵分解和参数更新逻辑,只需简单配置参数,即可快速应用 LoRA 进行模型微调。同时,PEFT 库还提供了模型保存和加载的功能,方便用户在不同环境中使用微调后的模型。
2.3.3 P-Tuning 的封装
学习网址:https://huggingface.co/docs/peft/package_reference/lora
对于 P-Tuning,PEFT 库提供了PromptTuning类进行封装。
- 实现方式:PromptTuning类根据 P-Tuning 的原理,在输入中添加可训练的提示(Prompt)。它通过在模型输入层插入提示向量,并在训练过程中优化这些提示向量,从而引导模型生成符合任务要求的输出。与 Prefix Tuning 不同的是,P-Tuning 的提示向量可以更灵活地分布在输入序列中,而不仅仅是在序列前端。
- 关键参数:包括prompt_length(提示长度)、prompt_init(提示初始化方式)等。prompt_length决定了提示向量的长度,而prompt_init则影响提示向量的初始值,不同的初始化方式可能会对模型的收敛速度和性能产生影响。
- 使用优势:PEFT 库使得 P-Tuning 的应用变得简单直观,用户可以通过配置参数快速实现提示向量的添加和训练。同时,库中的优化工具和回调函数可以帮助用户更好地监控和调整训练过程,提高模型的训练效果。
三、大模型微调流程及步骤总结
3.1 任务前期准备
- 明确任务:确定微调模型的具体应用场景,如文本分类、情感分析、图像识别等,明确任务目标和要求。
- 选择数据集:根据任务收集合适的数据集,确保数据的质量、多样性和相关性。如果是公开数据集,要了解其特点和适用范围;若是自己收集的数据,需进行清洗、标注等预处理工作。
- 确定预训练模型:依据任务类型和数据特点,选择合适的预训练大模型,如自然语言处理中的BERT、GPT系列,计算机视觉中的ResNet、ViT等。考虑模型的性能、规模、适用性以及训练成本等因素。
以文本生成任务为例,使用的预训练模型为 GPT-Neo,深度学习框架为 Hugging Face 的transformers库,相关数据集加载和预训练模型的加载代码如下所示:
from datasets import load_dataset
from transformers import AutoTokenizer, AutoModelForCausalLM
# 加载wikitext-2数据集
dataset = load_dataset('wikitext', name='wikitext-2-raw-v1')
# 加载预训练的GPT-Neo模型和tokenizer
tokenizer = AutoTokenizer.from_pretrained('EleutherAI/gpt-neo-1.3B')
model = AutoModelForCausalLM.from_pretrained('EleutherAI/gpt-neo-1.3B')
tokenizer.pad_token = tokenizer.eos_token3.2 数据处理
- 数据预处理:对收集到的数据集进行预处理,使其符合模型输入的要求。在自然语言处理中,包括分词、标记化、添加特殊标记、填充或截断序列长度等操作;在计算机视觉中,包括图像的缩放、裁剪、归一化等操作。
- 数据划分:将预处理后的数据集划分为训练集、验证集和测试集。通常按照一定比例(如70%训练集、15%验证集、15%测试集)进行划分,用于模型的训练、调优和评估。
- 数据加载:使用数据加载器(如PyTorch的DataLoader)将划分好的数据加载到内存中,并按照批次(batch)的方式输入到模型中进行训练,以提高训练效率。
相同任务下的相关代码示例如下:
from torch.utils.data import DataLoader, TensorDataset
import torch
def preprocess_function(examples):
inputs = tokenizer(examples["text"], truncation=True, padding='max_length', max_length=128)
return inputs
tokenized_dataset = dataset.map(preprocess_function, batched=True)
# 划分数据集
train_dataset = tokenized_dataset["train"]
validation_dataset = tokenized_dataset["validation"]
test_dataset = tokenized_dataset["test"]
# 将数据集转换为TensorDataset
train_dataset = TensorDataset(
torch.tensor(train_dataset["input_ids"]),
torch.tensor(train_dataset["attention_mask"])
)
validation_dataset = TensorDataset(
torch.tensor(validation_dataset["input_ids"]),
torch.tensor(validation_dataset["attention_mask"])
)
test_dataset = TensorDataset(
torch.tensor(test_dataset["input_ids"]),
torch.tensor(test_dataset["attention_mask"])
)
# 数据加载
train_dataloader = DataLoader(train_dataset, batch_size=4, shuffle=True)
validation_dataloader = DataLoader(validation_dataset, batch_size=4, shuffle=False)
test_dataloader = DataLoader(test_dataset, batch_size=4, shuffle=False)3.3 微调设置
- 选择微调方法:根据任务需求、计算资源和模型特点,选择合适的微调方法。常见的有全量微调(对模型所有参数进行训练)、部分微调(固定部分层参数,只训练特定层)以及参数高效微调方法(如LoRA、Prefix Tuning、P-Tuning等)。
- 设置超参数:确定微调过程中的超参数,如学习率、批次大小、训练轮数(epoch)、优化器类型(如Adam、SGD等)、损失函数(如交叉熵损失、均方误差损失等)。这些超参数的设置会影响模型的训练效果和收敛速度,通常需要通过实验进行调优。
from transformers import AdamW, get_scheduler, TrainingArguments, Trainer
from peft import LoraConfig, get_peft_model
# 全量微调
# 直接使用原始模型,对所有参数进行训练
full_finetune_model = model
optimizer = AdamW(full_finetune_model.parameters(), lr=2e-5)
# 部分微调
# 固定除最后一层全连接层外的所有层参数
for name, param in model.named_parameters():
if 'fc' not in name:
param.requires_grad = False
partial_finetune_model = model
optimizer = AdamW(partial_finetune_model.parameters(), lr=2e-5)
# LoRA微调
# 配置LoRA参数
lora_config = LoraConfig(
r=8,
lora_alpha=32,
target_modules=["query_key_value"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
lora_model = get_peft_model(model, lora_config)
optimizer = AdamW(lora_model.parameters(), lr=2e-5)
# 超参数设置
batch_size = 4
num_epochs = 3
learning_rate = 2e-5
warmup_steps = 100
# 使用TrainingArguments和Trainer进行训练管理
training_args = TrainingArguments(
output_dir='./results',
num_train_epochs=num_epochs,
per_device_train_batch_size=batch_size,
save_steps=10_000,
save_total_limit=2,
learning_rate=learning_rate,
warmup_steps=warmup_steps,
logging_steps=10
)
# 这里以全量微调模型为例创建Trainer
trainer = Trainer(
model=full_finetune_model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=validation_dataset,
optimizers=(optimizer, None)
)3.4 模型训练
- 启动训练:在设置好模型、数据和超参数后,开始模型的微调训练。在训练过程中,模型根据输入的数据计算前向传播结果,然后根据损失函数计算预测结果与真实标签之间的差异,并通过反向传播算法计算梯度,更新模型的参数。
- 监控训练过程:在训练过程中,实时监控模型的训练进度、损失值、准确率等指标。可以使用可视化工具(如TensorBoard)将这些指标绘制成图表,以便直观地观察模型的训练情况,及时发现问题并进行调整。
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
for epoch in range(3):
model.train()
running_loss = 0.0
for i, batch in enumerate(train_dataloader):
input_ids = batch[0].to(device)
attention_mask = batch[1].to(device)
optimizer.zero_grad()
outputs = model(input_ids, attention_mask=attention_mask, labels=input_ids)
loss = outputs.loss
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f'Epoch {epoch + 1}, Loss: {running_loss / len(train_dataloader)}')3.5 模型评估与优化
- 模型评估:在训练过程中或训练结束后,使用验证集对模型进行评估,计算模型在验证集上的性能指标,如准确率、召回率、F1值、均方误差等。通过评估结果了解模型的泛化能力和性能表现。
- 超参数调优:根据评估结果,调整超参数的值,重新进行训练和评估。可以使用网格搜索、随机搜索、贝叶斯优化等方法来寻找最优的超参数组合,以提高模型的性能。
- 模型选择:如果进行了多次训练和超参数调优,选择性能最优的模型作为最终的微调模型。可以根据验证集上的评估指标,或者结合模型的复杂度、训练时间等因素进行综合考虑。
model.eval()
total_loss = 0.0
total_length = 0
with torch.no_grad():
for batch in validation_dataloader:
input_ids = batch[0].to(device)
attention_mask = batch[1].to(device)
outputs = model(input_ids, attention_mask=attention_mask, labels=input_ids)
loss = outputs.loss
total_loss += loss.item() * input_ids.size(0)
total_length += input_ids.size(0)
perplexity = torch.exp(torch.tensor(total_loss / total_length))
print(f'Validation Perplexity: {perplexity.item()}')
new_learning_rate = 1e-5
optimizer = AdamW(model.parameters(), lr=new_learning_rate)
3.6 模型部署
- 保存模型:将最终确定的微调模型保存到本地文件系统,以便后续使用。保存的模型文件通常包含模型的结构和参数,以及一些必要的元数据。
- 部署模型:将保存的模型部署到实际应用环境中,如Web服务、移动设备、嵌入式系统等。在部署过程中,需要考虑模型的加载速度、推理效率、内存占用等因素,确保模型能够在实际应用中稳定运行。
# 保存模型
model.save_pretrained('finetuned_gpt_neo')
tokenizer.save_pretrained('finetuned_gpt_neo')
# 部署模型
new_model = AutoModelForCausalLM.from_pretrained('finetuned_gpt_neo')
new_tokenizer = AutoTokenizer.from_pretrained('finetuned_gpt_neo')
new_model.to(device)
new_model.eval()
# 假设新的输入文本
new_prompt = "Once upon a time"
input_ids = new_tokenizer(new_prompt, return_tensors='pt').input_ids.to(device)
with torch.no_grad():
output = new_model.generate(input_ids, max_length=50)
generated_text = new_tokenizer.decode(output[0], skip_special_tokens=True)
print(f'Generated Text: {generated_text}')写在最后:本文只介绍了集中常见的微调方式,现有很多优化版本和提出的方法并没有介绍到,若后续有需求笔者可以考虑继续补充相关学习内容和资料~感兴趣的小伙伴们请一键三连呀~欢迎补充指正和交流讨论!!!

















 1291
1291

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









