






1、问题描述:
这个报错的原因是代码运行时遇到了 CUDA内存不足(Out of Memory) 的问题,具体是在 ResNet.py调用模型的 forward 方法进行相关Tensor分配内存时,GPU上的显存已经被占用了大部分,无法再为新的张量或计算分配所需的内存空间。
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 10.78 GiB (GPU 0; 23.48 GiB total capacity; 22.08 GiB already allocated; 997.44 MiB free; 22.09 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF但是在终端输入nvidia-smi查看相关显卡状态时,当前的 GPU 显存几乎没有占用,但仍然遇到 CUDA out of memory 错误,这使得本人一度陷入自我怀疑.......具体如下:
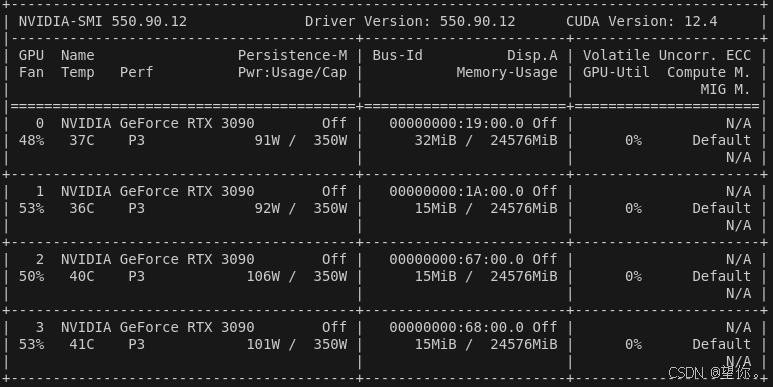
2、解决方法尝试
1)当看到所有的显卡都没有被使用时,笔者第一时间想到的可能就是没有调用到正确的GPU,于是直接在代码的开头强势添加如下代码(结果以失败告终,但仍然可以尝试,前提是pytorch可以正常使用,避免有时候没有调用GPU的问题):
os.environ["CUDA_VISIBLE_DEVICES"] = "0,1,2,3"2)第二个方法应该是比较通用且肯定能解决相关问题的,但是笔者一般不建议使用,会影响模型的性能和精确程度,该方法就是减小批量大小,较大的批量大小意味着在一次迭代中需要同时处理更多的数据样本,这会导致在计算梯度、存储中间结果等过程中占用更多的显存空间,减小批量可以有效缓解显存不足的问题。一般都是在config 文件或模型训练代码初始化参数定义中,可以找到 batch_size 设置,减小它的值一般都能解决问题,16不行就设置成8。
1、config.batch_size = 16
2、train_loader = DataLoader(dataset, batch_size=16, shuffle=True, ...)
3、第三个可能的原因是笔者第一次接触到的,叫做内存碎片化问题,是指在长时间的计算过程中,显存可能会因为频繁的分配和释放操作而出现内存碎片,即使总的空闲显存看起来足够,但由于碎片的存在,无法分配出连续的大块显存来满足新的内存需求。
可以通过设置 max_split_size_mb 参数解决:根据错误提示中提到的,如果 reserved memory(保留内存)远大于 allocated memory(已分配内存),可以尝试设置 PYTORCH_CUDA_ALLOC_CONF 环境变量中的 max_split_size_mb 参数来避免内存碎片。例如,可以在代码开头添加如下设置:
import os
os.environ["PYTORCH_CUDA_ALLOC_CONF"] = "max_split_size_mb:128"这个方法笔者亲自试验过,也调整到256和512进行尝试过,只能说在某些场景下是可行的,如果其他方法都尝试过了,可以尝试一下,“死马当活马医”。
4、还可以启用梯度累积(Gradient Accumulation)如果需要较大的有效批量,但显存不足,可以采用梯度累积的方法,逐步累积多个小批量的梯度,再更新一次模型。具体实现如下:
accumulation_steps = 4
for i, (data, target) in enumerate(train_loader):
output = model(data)
loss = criterion(output, target)
loss = loss / accumulation_steps
loss.backward()
if (i + 1) % accumulation_steps == 0:
optimizer.step()
optimizer.zero_grad()
5、多 GPU 的自动分配问题,类似于方法1,电脑的系统可能有多个 GPU,但 PyTorch 默认只使用 GPU:0,可以尝试通过指定的方式看是否能够使用:
device = torch.device("cuda:1" if torch.cuda.is_available() else "cpu")
model.to(device)
6、定期清理显存:在训练过程中,可以定期执行 torch.cuda.empty_cache() 来清理未使用的显存,释放出一些可利用的空间。不过要注意的是,过度频繁地使用此操作可能会导致性能下降,所以需要合理掌握清理的频率。通常可以在训练结束后或者测试开始前定义:
import torch, gc
gc.collect()
torch.cuda.empty_cache()
torch.cuda.reset_peak_memory_stats() 7、使用 Mixed Precision(混合精度)训练,混合精度训练可以有效降低显存使用量,同时提高计算效率。可以使用 PyTorch 的 AMP(Automatic Mixed Precision)工具进行实现,实现方式为:
scaler = torch.cuda.amp.GradScaler()
for data, target in train_loader:
optimizer.zero_grad()
with torch.cuda.amp.autocast():
output = model(data)
loss = criterion(output, target)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
但是要注意一个问题,笔者曾经在实现的时候只在训练过程中定义了混合精度,但是在验证阶段没有使用类似的方式进行梯度的反向传播,造成了模型的训练loss和验证loss产生了较大的偏差,具体的原因和解释笔者后续会出一个新的文章解释GradScaler的传播机制,切忌要一致!!!
8、终极大招(笔者曾遇到过两次任务都用该方式解决显存不足的问题):使用DataParallel在PyTorch 中用于在多个 GPU 上并行处理数据以加速模型训练,Tensorflow中有类似的工具和函数。DataParallel 的核心思想是将输入数据划分成多个子部分(通常是按照批次维度进行划分),然后将这些子部分分别分发到不同的可用 GPU 上进行并行计算。每个 GPU 独立地对分配到的数据执行模型的前向传播、计算损失、反向传播等操作,最后将各个 GPU 上的计算结果(如梯度等)进行汇总和合并,以完成整个训练过程中的一次迭代。通过将数据并行地分配到多个 GPU 上进行处理,可以充分利用多个 GPU 的计算能力,大大缩短模型训练所需的时间。尤其是对于大规模数据集和复杂模型,这种并行计算的优势更加明显。实现的方式类似于下方:
import torch.nn as nn
def train_model(model, train_loader, val_loader, optimizer, criterion, config):
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = nn.DataParallel(model, device_ids=[0,1,2,3])
model.to(device)
其实也可以尝试一些别的分布式训练方法,例如DistributedDataParallel,它是一种更高级的分布式训练方法,它在处理多 GPU 训练时具有更好的性能和灵活性。可以在不同的机器节点上的 GPU 之间进行分布式训练,而 DataParallel 通常是在同一台机器上的多个 GPU 上进行并行训练,它处理数据划分、梯度同步等方面更加精细,能够更好地解决负载均衡和显存利用效率等问题。但它的使用相对复杂一些,需要更多的配置和设置步骤,比如要处理好不同节点之间的通信等问题。
如果上述问题都不能解决您的问题的话,欢迎补充指正~或者,换显卡叭!!!


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









