







 本文对比了支持向量机(SVM)与K近邻(KNN)两种机器学习算法。SVM通过训练得到超平面进行高效分类,适合高维数据,而KNN依赖于所有训练样本进行距离计算,预测效率较低。SVM的目标是找到最佳决策边界,以最大化间隔。高斯核函数是SVM中常用的核函数,具有良好的局部性和抗噪能力。
本文对比了支持向量机(SVM)与K近邻(KNN)两种机器学习算法。SVM通过训练得到超平面进行高效分类,适合高维数据,而KNN依赖于所有训练样本进行距离计算,预测效率较低。SVM的目标是找到最佳决策边界,以最大化间隔。高斯核函数是SVM中常用的核函数,具有良好的局部性和抗噪能力。
一、区别
SVM
KNN
SVM:先在训练集上训练一个模型,然后用这个模型直接对测试集进行分类。
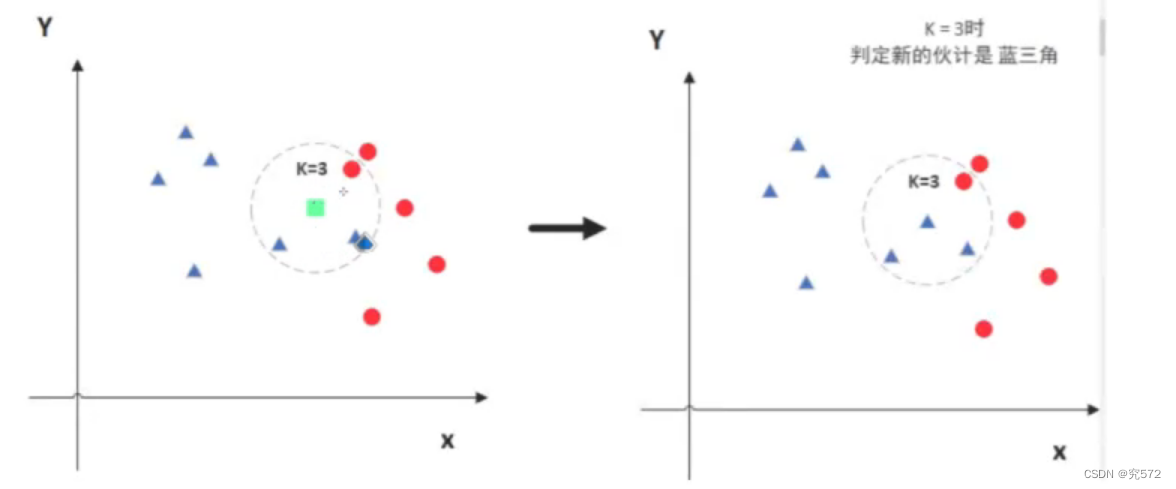
KNN:没有训练过程,只是将训练数据与训练数据进行距离度量来实现分类。
SVM:训练完直接得到超平面函数,根据超平面函数直接判定预测点的label,预测效率很高
KNN:预测过程需要挨个计算每个训练样本和测试样本的距离,当训练集和测试集很大时,预测效率低。
SVM:SVM是要去找一个函数把达到样本可分。
KNN:KNN对每个样本都要考虑。
SVM:SVM处理高纬度数据比较优秀
KNN:KNN不能处理样本维度太高的东西
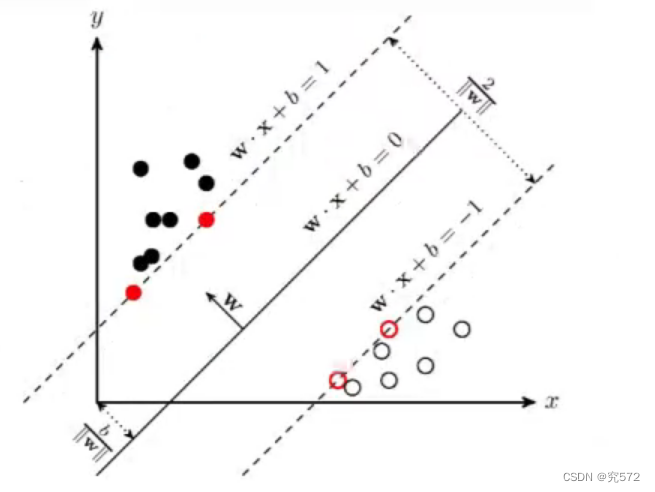
二、SVM原理
支持向量积
支持向量
选出最好的决策边界
决策边界要大的,宽的道路行动更快
支持寻找向量
支持向量要小的,考虑自己最近的雷才最安全
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1263
1263

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









