






摘要
今天的人工智能仍然面临两大挑战。一个是,在大多数行业中,数据以孤立的岛屿形式存在。另一个是加强数据隐私和安全。我们为这些挑战提出了一个可能的解决方案∶安全联邦学习。除了谷歌在2016年首次提出的联邦学习框架外,我们引入了一个全面的安全联邦学习框架,其中包括横向联邦学习、纵向联邦学习和联邦转移学习。该论文为联邦学习框架提供了定义、架构和应用,并对该主题的现有工作进行了全面调查。此外,我们建议在组织间建立基于联邦机制的数据网络,作为一种有效的解决方案,在不损害用户隐私的情况下允许知识的共享。
1 简介
2016年是人工智能(AI)时代到来的一年。随着AlphaGo击败人类顶级围棋选手,人工智能的巨大潜力显现无疑,并开始期待更复杂、更尖端的人工智能技术在许多应用领域的应用,包括无人驾驶汽车、医疗和金融。然而,现实世界的情况却让人有些失望: 除少数行业外,大多数领域只有有限的数据或质量较差的数据,使人工智能技术的应用比我们想象的更加困难。这是因为在大多数行业中,数据是以孤立的岛屿形式存在的。由于行业竞争、隐私安全和复杂的行政程序,即使是同一公司的不同部门之间的数据整合也面临着巨大的阻力。要整合分散在全国各地和机构的数据几乎是不可能的,或者成本是禁止的。而联邦学习的提出正是为上述问题提供了一个解决方案。我们调查了现有的关于联邦学习的工作,并为一个全面的安全联邦学习框架提出了定义、分类和应用,并讨论了如何将联邦学习框架成功地应用到各种业务中。
2 联邦学习的概述
联邦学习的概念是2016年由谷歌提出的。其主要想法是基于分布在多个设备上的数据集建立机器学习模型,同时防止数据泄露。最近的改进主要集中在克服联合学习中的统计挑战和提高安全性。还有一些研究工作是为了使联邦学习更加个性化。
上述工作都集中在设备上的联邦学习,其中分布式的移动用户交互被纳入其中,大量分布中的通信成本、不平衡的数据分布和设备可靠性是一些主要的优化因素。此外,数据是按用户ID或设备ID划分的,因此,在数据空间中是横向的。这方面的工作与隐私保护的机器学习高度相关,它考虑了分散的协作学习环境中的数据隐私。为了将联邦学习的概念扩展到组织间的协作学习场景,我们将原来的"联邦学习"扩展为所有保护隐私的分散式协作机器学习技术的一般概念。
2.1 联邦学习的定义
确定N个数据所有者{F1, ... ,FN },他们都希望通过整合各自的数据{D1, ... ,DN}来训练一个机器学习模型。一个传统的方法是把所有的数据放在一起,用D=D1U···UDN来训练一个模型MSUM。联邦学习系统是一个学习过程,在这个过程中,数据所有者协同训练一个模型MFED,在这个过程中,任何数据所有者Fi都不会将其数据Di暴露给其他人。此外,MFED的准确性,表示为VFED,应该非常接近MSUM、VSUM的性能。形式上,让δ是一个非负的实数;如果
![]()
我们说联合学习算法有δ-精度损失。
2.2 联邦学习的隐私
隐私是联合学习的基本属性之一。这需要安全模型和分析来提供有意义的隐私保证。在本节中,我们简要地回顾和比较了 不同的联合学习的隐私技术。我们还确定了防止间接泄漏的方法和潜在的挑战防止间接泄漏。
安全多方计算(SMC) SMC安全模型涉及多方,并在定义明确的仿真框架中提供安全证明,以确保完全零知识,也就是说,除了输入和输出之外,各方一无所知。零知识是非常需要的,但是这种期望的属性通常需要复杂的计算协议,并且可能无法有效地实现。在某些情况下,如果提供安全保证,部分知识的披露可能被认为是可以接受的。可以在较低的安全性要求下使用SMC构建安全模型以换取效率。最近,有研究使用SMC框架来训练具有两个服务器和半诚实假设的机器学习模型。Kilbertus等人使用MPC协议进行模型训练和验证,无需用户泄露敏感数据。其中一个最先进的SMC框架之一是Sharemind。Payman Mohassel提出了一个3PC 模型,以诚实的多数,并考虑了在半诚实和恶意假设中的安全性。这些工作要求参与者的数据在非协作服务器之间秘密共享。
差分隐私 另一项工作使用差分隐私技术或k-匿名来保护数据隐私。差异隐私、k-匿名和多样化的方法涉及在数据中添加噪声,或使用泛化方法来模糊某些敏感属性,直到第三方无法区分个体,从而使数据无法还原来保护用户隐私。然而,这些方法的根源仍然要求数据传输到别处,而这些工作通常涉及准确性和隐私之间的权衡。在《Differentially private federated learning: A client level perspective》中,作者介绍了联邦学习的差异隐私方法,以便通过在训练期间隐藏客户的贡献来增加对客户机端数据的保护。
同态加密 在机器学习过程中,也可以采用同态加密的方法,通过加密机制下的参数交换来保护用户数据隐私。与差分隐私保护不同,数据和模型本身不会被传输,也不能通过另一方的数据对其进行推测。因此,原始数据级别的泄漏可能性很小。最近的工作采用同态加密来集中和训练云上的数据。在实践中,加法同态加密被广泛使用,需要进行多项式近似来评估机器学习算法中的非线性函数,从而在准确性和隐私性之间进行权衡。
2.2.1间接信息泄露
联邦学习的先驱工作揭示了诸如随机梯度下降(SGD)等优化算法的参数更新等中间结果,但是没有提供安全保证。当这些梯度与数据结构(如图像像素)一起曝光时,实际上可能泄漏重要的数据信息。研究人员已经考虑到这样一种情况:联邦学习系统的一个成员通过植入后门来学习其他人的数据,恶意攻击其他人。
在《How To Backdoor Federated Learning》中,作者证明了在一个联邦全局模型中植入隐藏后门的可能性,并提出了一种新的“约束和缩放”模型中毒法来减少数据中毒。
在《Inference attacks against collaborative learning》中,研究人员发现了协作机器学习系统中存在的潜在漏洞,在该系统中,不同参与方在协作学习中使用的训练数据容易受到推理攻击。他们表明,一个敌对的参与者可以推断成员资格以及与训练数据子集相关的属性。他们还讨论了针对这些攻击的可能防御措施。
在《Securing distributed machine learning in high dimensions》中,作者揭示了与不同方之间的梯度交换有关的潜在安全问题,并提出了梯度下降法的一种安全变体,并表明它可以容忍一定常数比例的拜占庭用户(参见拜占庭将军问题)。
研究人员也开始考虑将区块链作为促进联邦学习的平台。在《On-Device Federated Learning via Blockchain and its Latency Analysis》中,研究人员考虑了一种区块链联邦学习(BlockFL)结构,其中移动设备的本地学习模型更新通过区块链进行交换和验证。他们考虑了最佳块生成、网络可扩展性和鲁棒性问题。
2.3联合学习的分类
在本节中,我们将讨论如何根据数据的分布特征对联合学习进行分类。让矩阵Di表示每个数据所有者i所持有的数据。矩阵的每一行代表一个样本,每一列代表一个特征。同时,一些数据集还可能包含标签数据。我们将特征空间表示为X,标签空间表示为Y,我们用I来表示样的ID空间。例如,在金融领域,标签可能是用户的信用;在营销领域,标签可能是用户的购买欲望;在教育领域,if可能是学生的学位。特征X、标签Y和样本I构成完整的训练数据集(I,X, Y)。数据各方的特征和样本空间可能不尽相同,我们根据数据在特征和样本ID空间中各方的分布方式,将联合学习分为横向联合学习、纵向联合学习和联邦迁移学习。图2显示了两方场景下的各种联合学习框架。
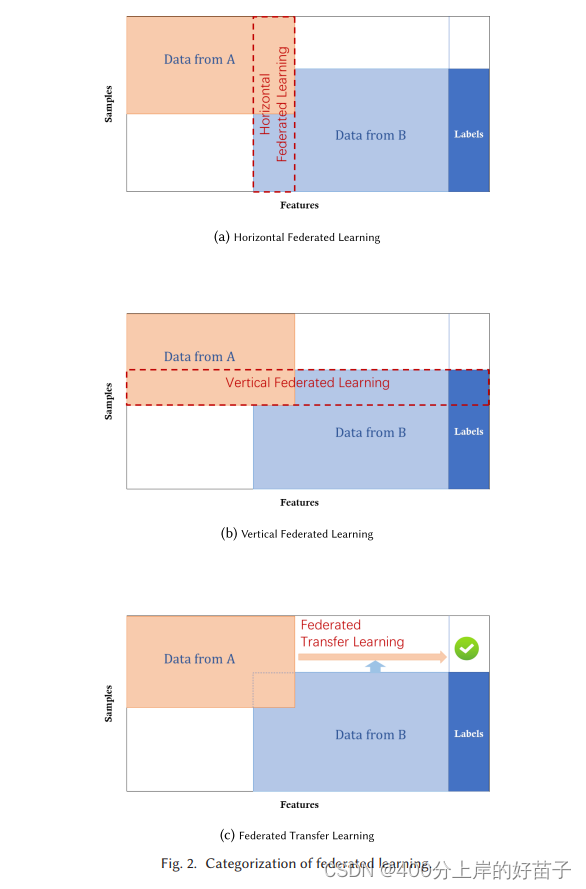
2.3.1 横向联合学习
横向联邦学习,又称为基于样本的联邦学习
特点:有相同的特征空间,但是样例空间不同,见图2a红色区域
例如,两个区域性银行的用户组可能由于各自的区域非常不同,其用户的交叉集非常小。但是,它们的业务非常相似,因此特征空间是相同的。
我们将横向联邦学习总结为:
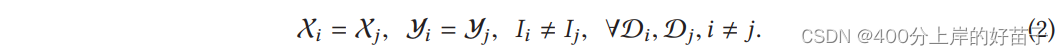
·目前关于横向联邦学习的相关研究:
《Privacy-preserving deep learning》提出了一个协作式深度学习方案,参与者独立训练,只共享参数更新的子集。https://doi. org/10.1145/2810103.2813687
2017年,谷歌提出了一个横向联邦学习解决方案,用于Android手机模型更新《Federated learning of deep networks using model averaging》。在该框架中,使用Android手机的单个用户在本地更新模型参数,并将参数上传到Android云,从而与其他数据所有者共同训练集中式模型。http://arxiv.org/abs/1602.05629
《Practical secure aggregation for privacy-preserving machine learning》还介绍了一种安全的聚合方案,以保护在联邦学习框架下聚合用户更新的隐私。https://doi.org/10.1145/3133956.3133982
《Privacy-preserving deep learning via additively homomorphic encryption》对模型参数聚合使用加法同态加密来提供对中央服务器的安全性。
《Federated multi-task learning》提出了一种多任务风格的联邦学习系统,允许多个站点在共享知识和维护安全的同时完成不同的任务。他们提出的多任务学习模型还可以解决高通信成本、分散和容错问题。http://papers.nips.cc/paper/ 7029-federated-multi-task-learning.pdf
在《Federated learning of deep networks using model averaging》中,作者提出构建一个安全的客户机-服务器结构,在该结构中,联邦学习系统按用户划分数据,并允许在客户机设备上构建的模型,用来在服务器站点上协作,以构建一个全局联邦模型。模型的建立过程确保了数据不泄漏。http://arxiv.org/abs/1602.05629.
同样,在《Federated optimization: Distributed machine learning for on-device intelligence》中,作者提出了提高通信成本的方法,以便于基于分布在移动客户端上的数据对训练得到集中式模型。http://arxiv.org/abs/1610. 02527
近年来,为了在大规模分布式训练中大幅度降低通信带宽,《Deep gradient compression: Reducing the communication bandwidth for distributed training》提出了一种称为深度梯度压缩的压缩方法。http://arxiv.org/ abs/1712.01887
安全定义:
一般假设建立在诚实的参与节点中,只有服务器能够破坏参与者的隐私.
最近,另一种考虑恶意用户的安全模型也被提出,但是这给隐私带来了额外的挑战,它在训练结束时,将通用模型和所有模型参数暴露给所有参与者。
2.3.2纵向联合学习
纵向联邦学习,又称为基于特征的联邦学习,针对纵向划分的数据,提出了保护隐私的机器学习算法, 包括合作统计分析,关联规则挖掘,安全线性回归,分类,梯度下降。进来,有研究提出了一个纵向联邦学习计划,训练一个隐私保护的逻辑回归模型。研究了实体分辨率对学习性能的影响,并对损失函数和梯度函数应用泰勒近似,从而使同态加密能够用于隐私保护计算。
适用于两个数据集有相同的样例ID空间,但特征空间不同的情况。例如,考虑同一城市中的两家不同的公司:一家是银行,另一家是电子商务公司。他们的用户集可能包含该地区的大多数居民;因此,它们的用户空间的交集很大。但是,由于银行记录了用户的收支行为和信用评级,电子商务保留了用户的浏览和购买历史,两者的特征空间有很大的不同.假设我们希望双方都有一个基于用户和产品信息的产品购买预测模型.
纵向联邦学习是将这些不同的特征聚集起来,并以一种隐私保护的方式计算训练损失和梯度,从而利用来自双方的数据协作构建模型的过程。在这样的联邦机制下,参与各方的身份和地位都是相同的,联邦系统帮助每个人建立“共同财富”战略,这就是为什么这个系统被称为联邦学习。因此,在这样一个系统中,我们有:
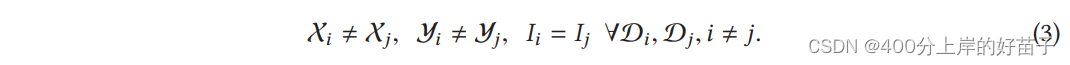
安全定义:
纵向联合学习系统通常会假设诚实但好奇的参与者。例如,在两方案件中,两方不勾结,最多一方被对手妥协。安全性的定义是,对手只能从它破坏的客户机上了解数据,而不能从其他客户端那里了解超出输入和输出的数据。
为了促进两方之间的安全计算,有时会引入一个半诚实的第三方(STP)。在这种情况下,假设STP不与任何一方串通。SMC为这些协议提供正式的隐私证明。在学习结束时,每一方只持有与自己的特征相关的模型参数。因此,在预测时,双方还需要协作来生成输出。
2.3.3 联邦迁移学习
联邦迁移学习适用于两个数据集不仅在样本上不同,在特征空间上也不同的场景
考虑两家机构:一家是位于中国的银行,另一家是位于美国的电子商务公司。由于地理上的限制,这两个机构的用户群有一个较小的交叉点。另一方面,由于业务的不同,双方的特征空间只有一小部分重叠。
在这种情况下,迁移学习技术可以被用于在联邦下为整个样本和特征空间提供解决方案。
特别是,使用有限的共同样本集来学习两个特征空间之间的共同表示,然后应用于只有一侧特征的样本的预测。FTL是对现有联邦学习系统的重要扩展,因为它处理的问题超出了现有联邦学习算法的范围:
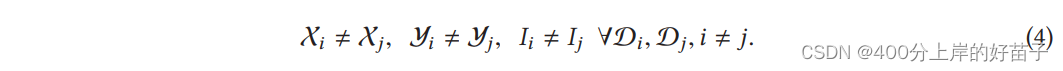
安全定义:
一个迁移联邦学习需要包含两个部分.后面将会详细的介绍,它的协议类似于纵向联邦学习中的协议,在这种情况下,纵向联合学习的安全定义可以在这里扩展.
2.4 联邦学习系统的体系结构
在本节中,我们将举例说明联合学习系统的一般架构。请注意,横向和纵向联邦学习系统的架构在设计上有很大不同,我们将分别介绍它们。
2.4.1 横向联合学习
横向联邦学习系统的典型体系结构如图3所示。在该系统中,具有相同数据结构的k个参与者在参数或云服务器的帮助下共同学习机器学习模型。一个典型的假设是参与者是诚实的,而服务器是诚实但好奇的;因此,不允许任何参与者向服务器泄露信息。这种系统的训练过程通常包含以下四个步骤。
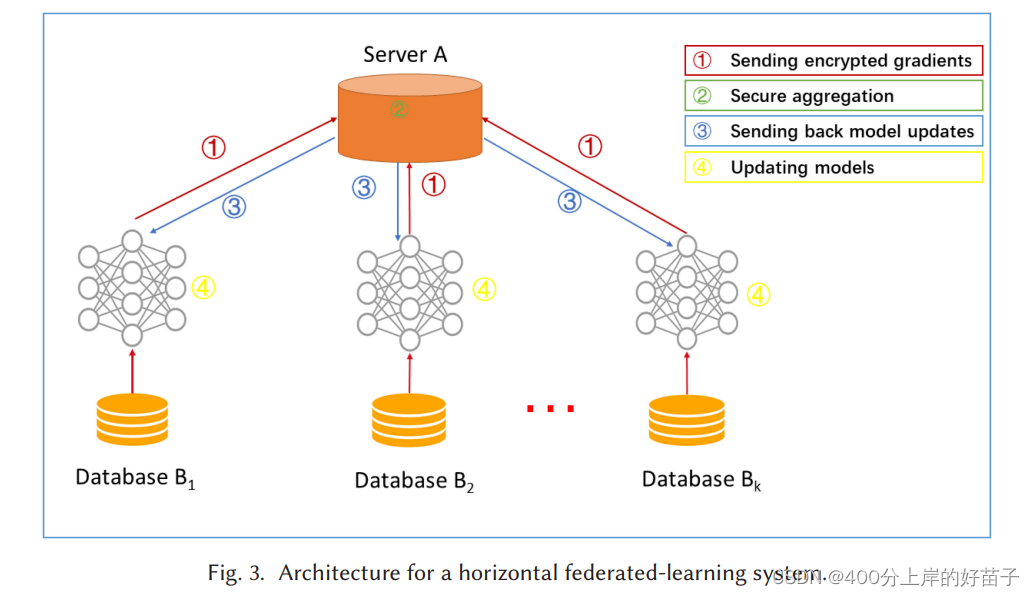
·第1步:参与者本地计算训练梯度; 使用加密,差分隐私或秘密共享技术屏蔽梯度的选择;并将屏蔽结果发送到服务器。
·第2步:服务器执行安全聚合,而无需学习任何参与者的信息。
·第3步:服务器将汇总结果发回给参与者。
·第4步:参与者使用解密的梯度更新各自的模型。
通过上述步骤继续迭代,直到损失函数收敛,从而完成整个训练过程。该体系结构独立于特定的机器学习算法 (逻辑回归,DNN等),所有参与者将共享最终的模型参数。
安全分析
如果使用SMC或同态加密进行梯度聚合,则上述体系结构被证明可以保护数据泄漏免受半诚实服务器的侵害。但是,在协作学习过程中,恶意参与者训练了生成型对抗网络(GAN),可能会在另一种安全模型中受到攻击。
2.4.2 垂直联合学习
假设公司A和B想联合训练一个机器学习模型,他们的业务系统都有自己的数据。此外,B公司也有该模型需要预测的标签数据。出于数据隐私和安全原因,A和B不能直接交换数据。为了确保训练过程中数据的保密性,一个第三方合作者C参与其中。在此,我们假设合作者C是诚实的,不与A或B串通,且A方和B方是诚实的,但彼此之间是好奇的。可信的第三方C是一个合理的假设,因为C方可以由政府等权威机构扮演,也可以由英特尔软件防护扩展(SGXs)等安全计算节点取代。联邦学习系统由两部分组成,如图4所示。
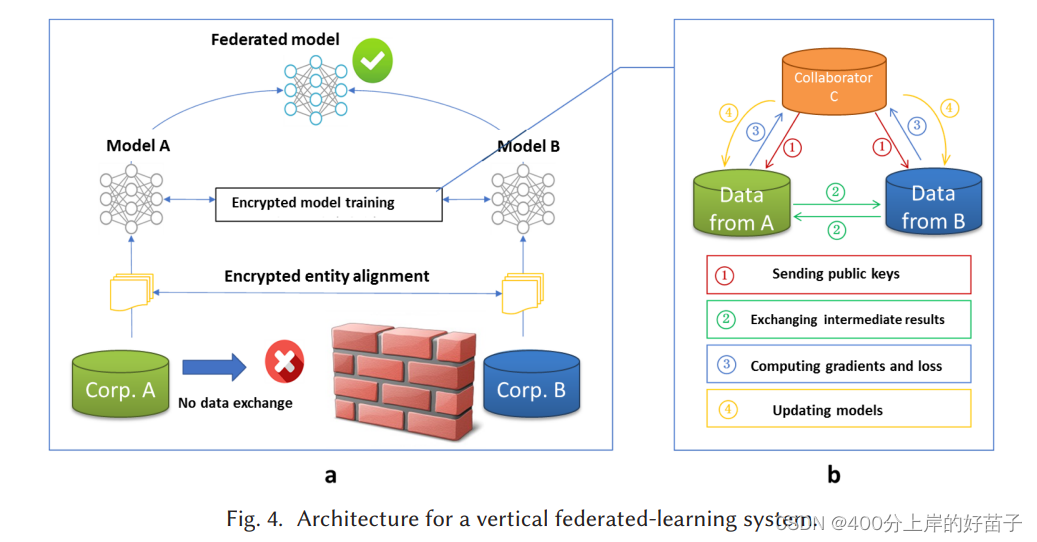
Part 1 加密的实体对齐。由于两家公司的用户群不一样、 系统使用基于加密的用户ID对齐技术,如确认双方的共同用户,而不需要A和B暴露他们各自的数据。在实体对齐过程中,系统不会暴露彼此不重合的用户。
Part 2加密的模型训练。在确定共同实体后,我们可以使用这些共同实体的数据来训练机器学习模型。训练过程可以分为分为以下四个步骤(如图4所示)。
·第1步:协作者C创建加密对,并向a和B发送公钥。
·第2步:A和B加密并交换中间结果以进行梯度和损耗计算。
·第3步:A和B分别计算加密梯度并添加一个附加掩码。B也计算加密丢失。A和B向C发送加密值。
·第4步:C解密并将解密的梯度和损失发送回A和B。A和B去掉梯度上的遮照(unmask)并且随后更新模型的参数.
在这里,我们以线性回归和同态加密为例来说明训练过程。为了用梯度下降法训练线性回归模型,我们需要对其损耗和梯度进行安全计算。

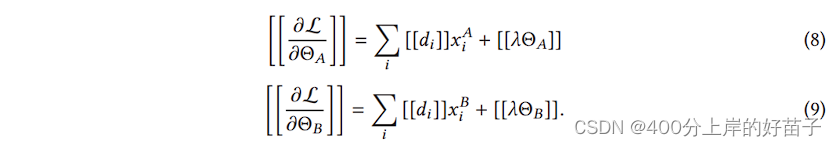
有关详细步骤,请参见表1和表2。在实体对齐和模型训练期间,a和B的数据保存在本地,并且训练中的数据交互不会导致数据隐私泄漏。请注意,潜在的信息泄露给C可能被认为是侵犯隐私,也可能不被认为是。在这种情况下,为了进一步防止C从A或B那里得知信息,A和B可以通过添加加密的随机掩码来进一步向C隐藏他们的梯度.因此,在联邦学习的帮助下,双方合作实现了共同模型的训练。因为,在训练过程中,每一方收到的损失和梯度与他们收到的损失和梯度完全相同,如果用在一个地方收集的数据联合建立一个模型,没有隐私约束,也就是说,这个模型是无损的。该模型的效率取决于加密数据的通信成本和计算成本。在每次迭代中,A和B之间发送的信息随着重叠样本的数量而增加。因此,该算法的效率可以通过采用分布式并行计算技术进一步提高。
安全性分析:
表1所示的训练协议并没有向C透露任何信息,因为C学习到的都是添加掩码的梯度,并且掩码矩阵的随机性和保密性都得到了保证。
在上述协议中,A在每一步中学习其梯度,但这不足以使A根据式:
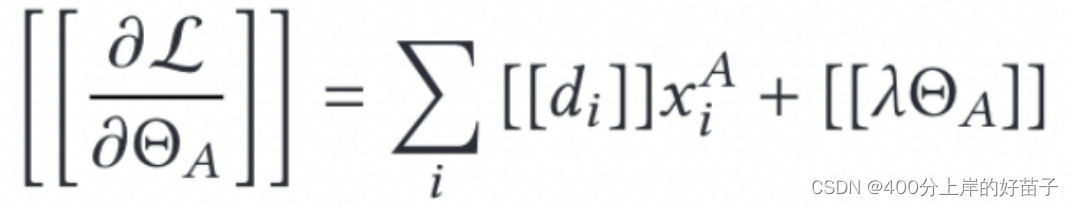
从B中学习到任何信息。
因为点积协议(scalar product protocol)的安全性是建立在不能求解n个方程中超过n个未知数的基础上的。也就是这里,我们假设样本的数量NA要比特征的数量nA大得多.
同样,B也无法从A处获取任何信息,从而证明了协议的安全性。
注意:我们假设双方之间都是半诚实的.
如果一方是恶意的,并且通过伪造输入来欺骗系统——例如,一方只提交了一个非零的输入,并且只有一个非零的特征——它就可以告诉这个样本的特征的值为![]() ,但是他仍然无法告知
,但是他仍然无法告知![]() 或者ΘB。然而,这种偏差会扭曲下一次迭代的结果,使另一方警觉,他们将终止学习过程。
或者ΘB。然而,这种偏差会扭曲下一次迭代的结果,使另一方警觉,他们将终止学习过程。
直到训练过程的最后,每一方(A或B)都不知道另一方的数据结构,只获得与自己的特征相关的模型参数。在推断时,双方需要按照表2所示的步骤协同计算预测结果,仍然不会导致信息泄露.
2.4.3 联邦迁移学习
假设在上述纵向联合学习的例子中,甲方和乙方只有很小的重叠样本集,我们对学习甲方整个数据集的标签感兴趣。为了将其覆盖范围扩大到整个样本空间,我们引入了迁移学习。具体来说,迁移学习通常涉及学习甲方和乙方的特征之间的共同表示,并通过利用源域方(本例中为乙方)的标签,使预测目标域方的标签的误差最小。因此,甲方和乙方的梯度计算与纵向联合学习的情况不同。在推理时间,它仍然需要双方计算预测结果。
2.4.4 激励机制
为了在不同的组织之间充分实现联合学习的商业化,需要开发一个公平的平台和激励机制。模型建立后,模型的性能将在实际应用中体现出来。这种表现可以记录在一个永久性的数据记录机制中(如区块链)。提供更多数据的组织将获得更好的收益,而模型的有效性取决于数据提供者对系统的贡献。这些模型的有效性是基于联邦机制的分布式拓扑,并继续激励更多的组织加入数据联合。
上述架构的实施不仅要考虑隐私保护和协同建模的有效性,而且还考虑了如何在多个组织之间进行奖励贡献更多数据的组织,以及如何通过共识机制实施激励措施。因此,联邦学习是一种 "闭环 "学习机制。
3 相关工作
联邦学习使多方能够协作构建一个机器学习模型,同时对他们的私人训练数据保密。作为一项新颖的技术,联邦学习有几条原创性的线索,其中一些是植根于现有领域的。下面,我们将从多个角度解释联合学习与其他相关概念之间的关系。
3.1 隐私保护机器学习
联邦学习可以被认为是保护隐私的、去中心化的协作式机器学习。因此,它与多方的、保护隐私的机器学习紧密相关。在过去,许多研究工作都致力于这一领域。
例如,Wenliang Du and Zhijun Zhan、Jaideep Vaidya and Chris Clifton提出了垂直分割数据的安全多方决策树的算法。(http://dl.acm.org/citation.cfm?id=850782.850784)
Vaidya和Clifton提出了用于垂直分区数据的安全关联挖掘规则、安全K-means和纳夫-贝叶斯分类器。
Murat Kantarcioglu and Chris Clifton提出了一种水平分区数据的关联挖掘规则的算法。(DOI:https://doi.org/10.1109/ TKDE.2004.45)
安全支持向量机算法已被开发用于垂直分区数据]和水平分区数据。
Wenliang Du等人提出了用于多方线性回归和分类的安全协议。
Li Wan等人提出了安全的多方梯度下降方法。这些工作都使用SMC来保证隐私。(DOI:https://doi.org/10.1145/1281192.1281275)
Nikolaenko等人使用同态加密和Yao的乱码电路,在水平分区的数据上实现了一个保护隐私的线性回归协议。(DOI:https://doi.org/10.1109/SP.2013.30)
Adrià Gascón、Irene Giacomelli等人的作者提出了一种用于垂直分割数据的线性回归方法。这些系统直接解决了线性回归问题。https://eprint.iacr. org/2017/979
Payman Mohassel and Yupeng Zhang用SGD处理了这个问题,还提出了逻辑回归和神经网络的隐私保护协议。
最近,有人提出了一个三服务器模型的后续工作。
(https://doi.org/10.1145/3243734.3243760)
Aono等人提出了一个使用同态加密的安全逻辑回归协议。(DOI:https://doi.org/10.1145/2857705.2857731)
Shokri和Shmatikov提出了水平分割数据的神经网络训练,并进行了更新参数的交换。(DOI:https://doi. org/10.1145/2810103.2813687)
M. Sadegh Riazi等人使用加法同态加密来保护梯度的隐私并增强系统的安全性。
随着近年来深度学习的发展,隐私保护神经网络推理也受到了很多研究关注。
3.2联邦学习与分布式机器学习的对比
乍一看的话,横向联合学习与分布式机器学习有些相似。分布式机器学习涵盖了很多方面,包括训练数据的分布式存储、计算任务的分布式操作以及模型结果的分布式分发。参数服务器是分布式机器学习中的典型元素。作为加速训练过程的工具,参数服务器将数据存储在分布式工作节点上,并通过中央调度节点分配数据和计算资源,以更有效地训练模型。对于水平联合学习,工作节点代表数据所有者。它对本地数据具有完全的自治性;在参数服务器中,中心节点总是进行控制;它可以决定何时以及如何加入联邦学习。在参数服务器中,中心节点总是进行控制; 因此,联合学习面临着更加复杂的学习环境。此外,联合学习强调在模型训练过程中对数据所有者的数据隐私保护。保护数据隐私的有效措施可以更好地应对未来日益严格的数据隐私和数据安全监管环境。
与分布式机器学习设置一样,联合学习也需要解决非IID数据问题。[77] 的作者表明,对于非IID本地数据,联合学习的性能会大大降低。针对这一问题,作者提出了一种类似于迁移学习的新方法。
3.3 联邦学习与边缘计算
联合学习可以看作是边缘计算的操作系统,因为它提供了用于协调和安全性的学习协议。Shiqiang Wang(http://arxiv.org/abs/1804.05271)考虑了使用基于梯度下降的方法训练的一类通用的机器学习模型。他们从理论角度分析了分布式梯度下降的收敛界限,在此基础上提出了一种控制算法,该算法确定了局部更新和全局参数聚合之间的最佳折衷,以在给定资源预算下最小化损失函数。
3.4联邦学习与联邦数据库系统的比较
联邦数据库系统是整合多个数据库单元并将整合后的系统作为一个整体进行管理的系统。联合数据库概念的提出是为了实现与多个独立数据库的互操作性。联邦数据库系统通常使用数据库单元的分布式存储,在实践中,每个数据库单元的数据是异质的。因此,在数据的类型和存储方面,它与联合学习有很多相似之处。
但是,联邦数据库系统在相互交互的过程中不涉及任何隐私保护机制,所有的数据库单元对管理系统来说是完全可见的。此外,联邦数据库系统的重点是数据的基本操作--包括插入、删除、搜索和合并,而联邦学习的目的是在保护数据隐私的前提下,为每个数据所有者建立一个联合模型,使数据所包含的各种价值和规律更好地服务于我们。
4 应用
作为一种创新的建模机制,联合学习可以在不损害这些数据的隐私和安全的情况下对来自多方的数据进行联合训练,在销售、金融和其他许多行业有很好的应用前景,在这些行业中,由于知识产权、隐私保护和数据安全等因素,数据不能直接聚集在一起训练机器学习模型。
以智能零售为例。其目的是利用机器学习技术为客户提供个性化的服务,主要包括产品推荐和销售服务。智能零售业务涉及的数据特征主要包括用户购买力、用户个人偏好和产品特征。在实际应用中,这三个数据特征很可能分散在三个不同的部门或企业中。例如,用户的购买力可以从用户的银行储蓄中推断出来,个人偏好可以从用户的社交网络中分析出来,而产品的特征则由电子商店记录。在这种情况下,我们面临着两个问题。首先,为了保护数据隐私和数据安全,银行、社交网站和电子购物网站之间的数据壁垒难以打破。
因此,数据不能直接汇总来训练一个模型。其次,三方存储的数据通常是异质的,而传统的机器学习模型不能直接在异质数据上工作。目前,这些问题在传统的机器学习方法中还没有得到有效解决,这就阻碍了人工智能在更多领域的普及和应用。
联邦学习和迁移学习是解决这些问题的关键。首先,通过利用联合学习的特点,我们可以在不输出企业数据的情况下为三方建立机器学习模型,这不仅充分保护了数据隐私和数据安全,也为客户提供了个性化和有针对性的服务,从而实现了互利共赢。同时,我们可以利用迁移学习来解决数据的异质性问题,并突破传统人工智能技术的限制。因此,联邦学习为我们构建一个跨企业、跨数据、跨领域的大数据和人工智能生态圈提供了良好的技术支撑。
人们可以使用联邦学习框架进行多方数据库查询,而不需要对数据进行排查。例如,假设在一个金融应用中,我们对检测多方借款感兴趣,这一直是银行业的一个主要风险因素。这种情况发生在某些用户恶意从一家银行借款来支付另一家银行的贷款。多方借贷是对金融稳定的一种威胁,因为大量的这种非法行为可能会导致整个金融系统崩溃。为了找到这样的用户,而不将用户名单在银行A和B之间相互暴露,我们可以利用联邦学习框架。特别是,我们可以利用联合学习的加密机制,对每一方的用户名单进行加密,然后在联合体内取加密名单的交集。对最终结果的解密可以得到多方借款人的名单,而不会将其他的"好"用户暴露给另一方。正如我们将在下面看到的,这种操作对应于纵向联合学习框架。
智能医疗是另一个领域,我们预计它将从联邦学习技术的兴起中大大受益。诸如疾病症状、基因序列和医疗报告等医疗数据是非常敏感和私密的,但医疗数据集难以收集,而且存在于孤立的医疗中心和医院。数据源的不足和网络的缺乏导致机器学习模型的表现不尽人意,这已经成为当前智能医疗的瓶颈。我们设想,如果所有的医疗机构都联合起来,分享他们的数据,形成一个大型的医疗数据集,那么在这个大型医疗数据集上训练的机器学习模型的性能将得到明显的改善。与转移学习相结合的联合学习是实现这一愿景的主要途径。迁移学习可以用来填补缺失的标签,从而扩大可用数据的规模,进一步提高训练好的模型的性能。因此,联邦迁移学习将在智能医疗的发展中发挥举足轻重的作用,并有可能将人类的医疗水平提升到一个全新的高度。
5企业的联邦学习与数据联盟
联邦学习不仅是一种技术标准,也是一种商业模式。当人们意识到大数据的影响时,他们首先想到的是将数据汇总、计算的模型,然后下载结果供进一步使用。云计算就是在这种需求下产生的。也就是说,随着数据隐私和数据安全的日益重要,以及公司的利润和数据之间更紧密的关系,云计算模式受到了挑战。然而,联邦学习的商业模式为大数据的应用提供了一个新的范式。当每个机构孤立的数据不能产生一个理想的模型时,联邦学习的机制使机构和企业有可能在没有数据交换的情况下共享一个统一的模型。此外,联邦学习可以在区块链技术的共识机制帮助下制定公平的利润分配规则。数据拥有者,无论其拥有的数据规模大小,都会有动力加入到数据联盟中来,赚取自己的利润。我们认为,数据联盟的商业模式和联合学习的技术机制的建立应该一起进行。我们也会在各个领域制定联合学习的标准,使其尽快投入使用。
6 结论和展望
最近,数据的隔离和对数据隐私的重视成为人工智能的下一个挑战,但联邦学习给我们带来了新的希望。它可以为多个企业建立一个统一的模式,同时本地数据受到保护,这样企业就可以在数据安全方面进行合作。本文大致介绍了联邦学习的基本概念、架构和技术,并讨论了其在各种应用中的潜力。可以预见,在不久的将来,联邦学习将打破行业间的壁垒,建立一个可以安全分享数据和知识的社区,并根据每个参与者的贡献公平分配利益。人工智能的红利最终将被带到我们生活的每个角落。

















 2746
2746

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









