






对比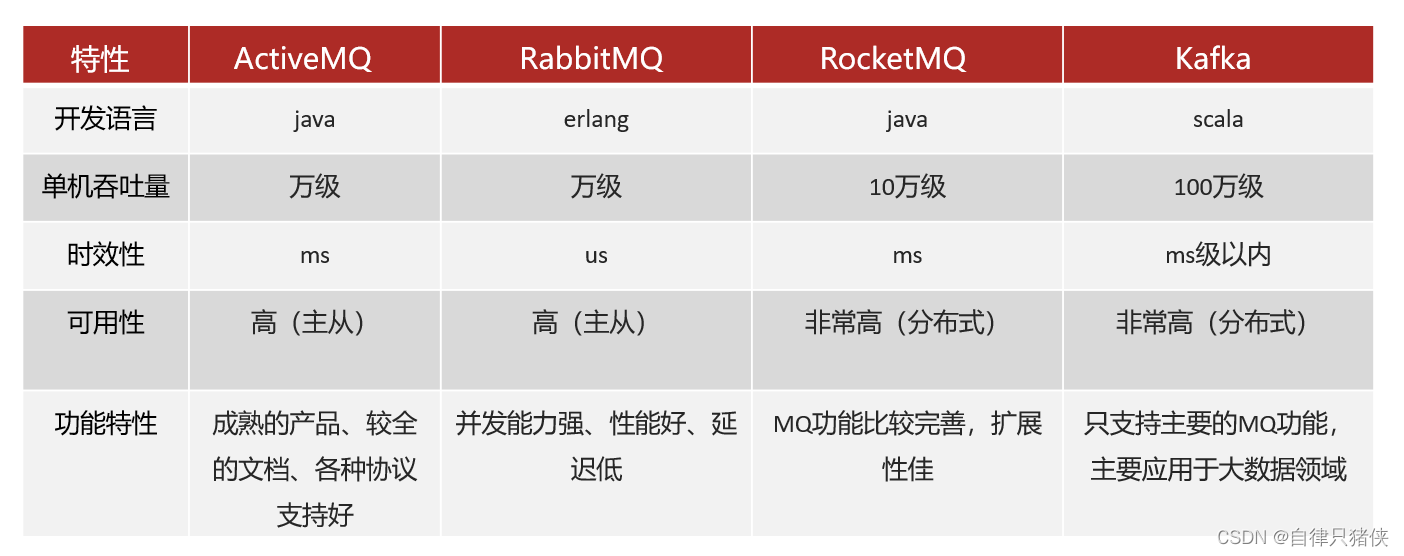

架构对比
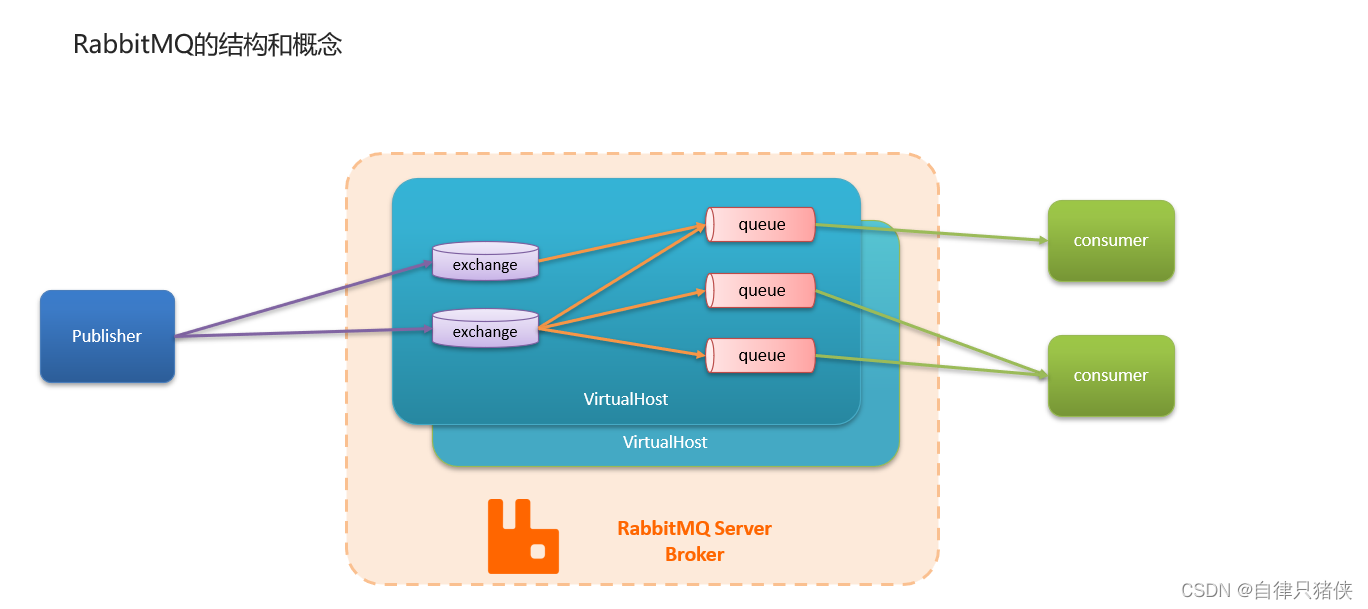
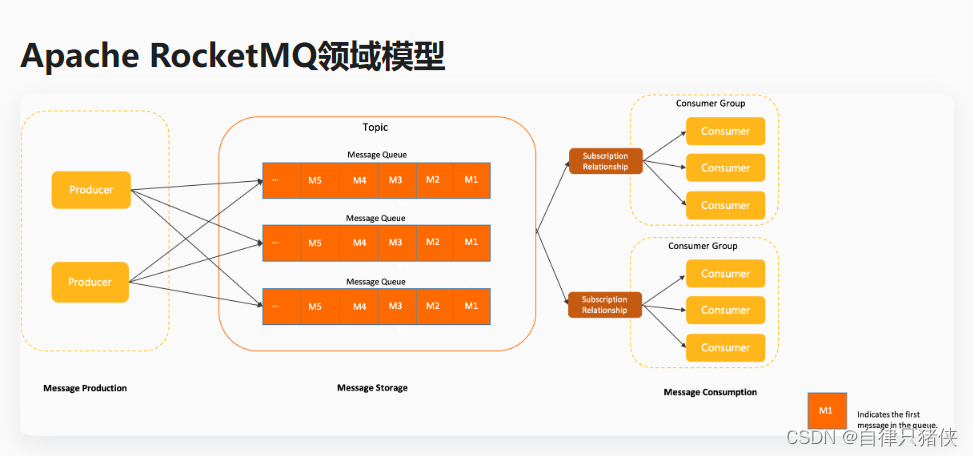
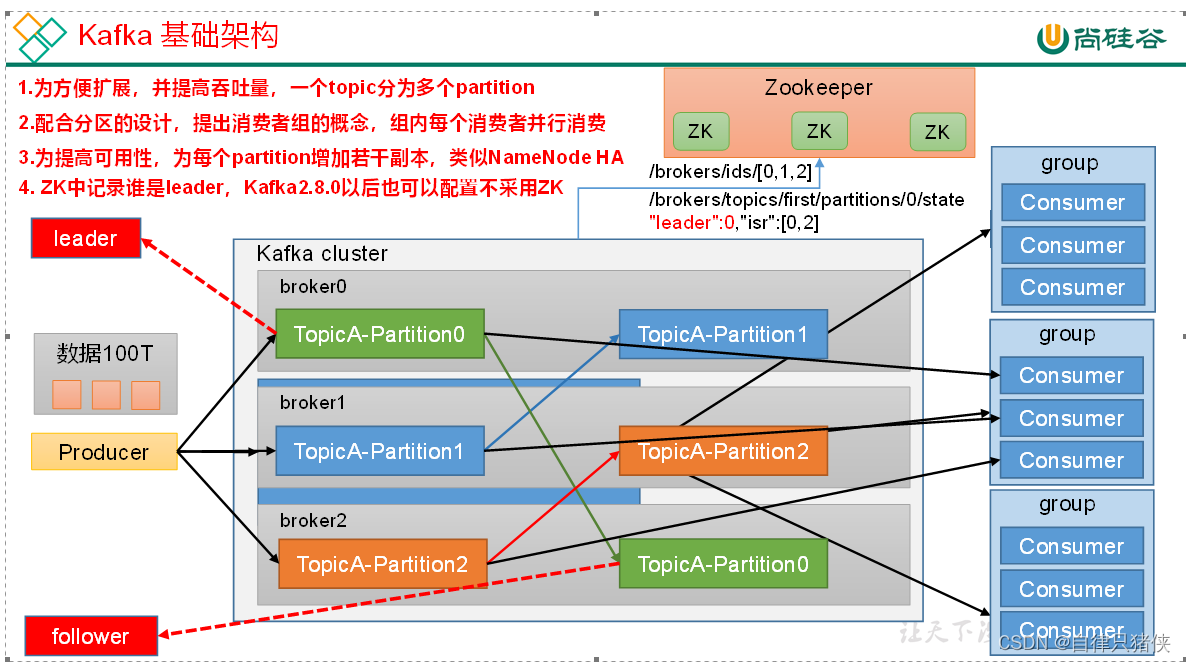
从架构可以看出三者有些类似,但是在细节上有很多不同。下面我们就从它们的各个组件,介绍它们:
RabbitMQ
是一种开源的消息队列中间件。下面是RabbitMQ中与其相关的几个概念:
1.生产者(Producer):生产者是消息的发送者,将消息发送到RabbitMQ的消息队列中。
2.消费者(Consumer):消费者是消息的接收者,从RabbitMQ的消息队列中获取消息并进行处理。
3.消息队列(Message Queue):消息队列是RabbitMQ的核心组件,用于存储待处理的消息。生产者将消息发送到队列中,消费者从队列中获取消息进行处理。
4.交换机(Exchange):交换机负责接收生产者发送的消息,并根据一定的规则将消息路由到一个或多个消息队列中。常见的交换机类型包括直连交换机(direct exchange)、主题交换机(topic exchange)、扇形交换机(fanout exchange)等。
5.绑定(Binding):绑定是指将交换机和消息队列进行关联,定义了交换机将消息路由到哪些队列中。绑定通常使用规则(routing key)来匹配消息和队列。
6.路由键(Routing Key):路由键是生产者在将消息发送给交换机时附带的关键字,用于指定消息的路由规则。
RocketMQ
是阿里巴巴开源的分布式消息中间件,下面是 RocketMQ 中与其相关的一些概念:
1.生产者(Producer):生产者负责生成并发送消息到 RocketMQ 中。
2.消费者(Consumer):消费者从 RocketMQ 中订阅并消费消息。
3.主题(Topic):主题是消息的逻辑分类,每个消息都属于一个特定的主题。生产者将消息发送到指定的主题,消费者通过订阅主题来接收相关的消息。
4.消息队列(Message Queue):主题被拆分成多个消息队列,每个消息队列按照顺序存储消息。消费者从消息队列中拉取消息进行消费。
5.消费者组(Consumer Group):消费者组是一组具有相同 Group ID 的消费者实例。每个消息只会被消费者组中的其中一个消费者实例消费,实现负载均衡和高可用性。
6.Broker:Broker 是 RocketMQ 的核心组件,它负责接收、存储和转发消息。一个 RocketMQ 系统通常由多个 Broker 组成,每个 Broker 负责管理若干个消息队列。每个消息队列只属于一个 Broker,但一个 Broker 可以管理多个消息队列。
7.Name Server:Name Server 是 RocketMQ 的命名服务组件,用于管理整个 RocketMQ 系统的元数据信息。生产者和消费者通过 Name Server 定位到对应的 Broker 服务器。Name Server 还负责管理主题、消费者组、路由信息等。
运行流程:
1.生产者和消费者在启动时会向Name Server注册自己的信息,包括IP地址、端口号等基本信息,以便于Name Server能够为它们提供服务路由信息,此外broker节点通过心跳机制将自己的信息定时上报到Name Server中
2.当生产者要发送消息时,首先需要通过Name Server获取指定Topic目前可用的Broker(可以是多个),然后根据负载均衡算法选择其中一个Broker发送消息。消息会被刷盘机制持久化存储
3.消息在经过同步刷盘或异步刷盘机制持久化存储之后,会被放入该Topic对应的队列中。
4.消费者在订阅指定的Topic和Tag之后,会从Broker服务器中拉取消息进行消费。消费者首先会向Name Server获取指定Topic目前可用的Broker,然后根据自身消费能力获取消息
Kafka
是由 Apache 软件基金会开源的分布式流处理平台,其核心组件包括以下几个:
1.Broker:Kafka 的核心组件之一,负责存储和处理数据。一个 Kafka 系统通常由多个 Broker 组成,每个 Broker 负责管理一部分数据副本。
2.Topic:Topic 是指数据的类别或主题,每条消息都属于一个特定的主题。生产者将消息发送到指定的主题,消费者通过订阅主题来接收相关的消息。
3.Partition:Partition 是将一个 Topic 分割成多个较小的、有序的数据单元。每个 Partition 存储了 Topic 对应的部分消息数据。分区的好处是可以提高并发处理能力和扩展性。
4.生产者(Producer):生产者负责生成并发送消息到 Kafka 的 Broker。Producer 可以选择将消息发送到指定的 Topic 和 Partition。
5.消费者(Consumer):消费者从 Kafka 的 Broker 订阅并消费消息。可以通过消费者组的方式对消息进行分组,每个消费者组中的消费者共同消费一个 Topic。
6.消费者组(Consumer Group):消费者组是一组具有相同 Group ID 的消费者实例。每个消息只会被消费者组中的其中一个消费者实例消费,实现负载均衡和高可用性。
7.ZooKeeper:Kafka 使用 ZooKeeper 来进行集群管理、元数据存储和领导者选举等操作。ZooKeeper 负责协调 Broker 和其他组件之间的通信。
不同:
在发送消息和拉取消息方面,Kafka、RocketMQ 和 RabbitMQ 有一些区别。
1.RabbitMQ:
发送消息:RabbitMQ 中的生产者(Producer)将消息发送到指定的 Exchange。生产者发送消息时可以指定消息的 Routing Key,Exchange 根据 Routing Key 将消息路由到相应的队列。
拉取消息:RabbitMQ 中的消费者(Consumer)通过订阅队列来拉取消息。消费者可以按照默认顺序或自定义顺序消费队列中的消息。消费者可以选择轮询方式拉取消息,也可以使用 Basic.Consume RPC 方法主动拉取消息。
2.RocketMQ:
发送消息:RocketMQ 的生产者(Producer)将消息发送到指定的 Topic,并不能直接选择要发送到的队列,而是由 Broker 负责将消息分发到相应的队列中。发送消息时可以选择同步或异步方式。
拉取消息:RocketMQ 的消费者(Consumer)通过订阅 Topic 和指定消费者组(Consumer Group)来拉取消息。RocketMQ 提供了两种消费模式:集群模式(负载均衡消费)和广播模式(每个消费者都会收到全部消息)。消费者可以按照默认顺序拉取消息或指定顺序拉取消息。
3.Kafka:
发送消息:Kafka 中的生产者(Producer)将消息发送到指定的 Topic,并选择要发送到的 Partition。生产者可以异步发送消息,不必等待消息被写入磁盘。
拉取消息:Kafka 中的消费者(Consumer)通过订阅 Topic 来拉取消息。消费者可以自主控制从哪个 Offset(偏移量)开始拉取消息,并可以按照自己的速度消费消息。Kafka 提供了高性能的批量拉取机制,可以一次性拉取多条消息。
前二者可以实现延迟队列,死信队列,而kafka不行。
经典面试题:
1.如何保证消息的可靠性?
本质上都是解决 生成者 ----> mq -----> 消费者 消息在链路中不会被丢失
rabbitmq:
1.生产者确认机制:实现两个方法ReturnCallback,ConfirmCallback 。ReturnCallback是保证消息从交换机到队列。每次发送消息时都需要实现ConfirmCallback,该方式需要生成一个唯一ID,避免ack冲突,ConfirmCallback:保证了消息从生产者到交换机再到队列中,如果没有到队列中会返回nack。
2.队列中消息持久化:RabbitMQ会将消息持久化到磁盘,以确保消息在服务器重启或发生故障时能够得到恢复。前提是在发送消息时,将消息标记为持久化,即设置 MessageProperties.PERSISTENT_TEXT_PLAIN 属性。
3.消费者确认机制:默认确认机制是自动的,消费后自动ack,ack会删除队列指定的消息
4.失败重试机制:发送重试,消费重试
rocketmq:
1.发消息时,重要的消息可以使用同步发送,内部已经实现了ack机制,该发送会有返回值可以获取消息的发送状态,增加重试机制
2.消息到达了rockemq之后它内部已经实现了持久化机制,RocketMQ 将消息以日志形式持久化到磁盘中(使用同步刷盘机制)
3.消费者通过手动确认机制(ACK)
4.失败重试机制:消费失败默认会回到队列中重新投递
2.如何解决消息重复消费的问题
rabbitmq:
1.消费端手动ACK确认机制
在消费端使用RabbitMQ提供的手动ACK确认机制,在消费者成功处理消息后,手动将消息从队列中删除。这样可以确保消息只会被处理一次,避免了重复消费的问题。
2.消费端去重保证机制
可以在消费端处理每条消息之前,通过分布式锁或者数据库唯一索引等方式,判断当前消息是否已经被处理过。如果已经处理过,则忽略该消息;否则正常处理,并将消息标记为已处理。
rocketmq:因为内部的重试机制,很难避免重复消费。一般需要消费端去重保证机制(同上)
3.如何解决消息堆积
一般
限流:限制消息的生产速度
增加消费速度:增加消费者(rocketmq中:<=队列数量),增加线程数消费
增加队列容量
rabbit:惰性队列 增加队列容量
从RabbitMQ的3.6.0版本开始,就增加了Lazy Queues的概念,也就是惰性队列。惰性队列的特征如下:
接收到消息后直接存入磁盘而非内存
消费者要消费消息时才会从磁盘中读取并加载到内存
支持数百万条的消息存储
惰性队列是一种用于减少内存占用的优化策略,它的设计目的是在队列中存在大量未消费的消息时,只有当消息被消费者拉取时才将它们加载到内存中。这样可以降低内存使用,并提高系统的性能和吞吐量。














 325
325











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









