









目录
数据集概述
GQA,这是一个用于真实世界视觉推理和组合问答的新数据集。2200万个不同的推理问题,所有这些问题都带有表示其语义的功能程序。答案分布受到严格控制。
11.3万张图像、2200万个问题,推理能力有对象和属性识别、传递关系跟踪、空间推理、逻辑推理和比较。
详述
出发点
先前数据集的缺点:
- 语言先验。也就是说答案分布中统计偏差和趋势,规避了对真实视觉场景理解的需求。
- 数据集中多数问题没有用到组合式的语言,从而仅仅测试了模型的物体识别能力,模型缺乏基于视觉的推理能力。
- 先前的数据集缺乏将问题中的关键词与图中的区域相联系的标记信息,使得研究者难以定位模型出错的原因。
具体步骤
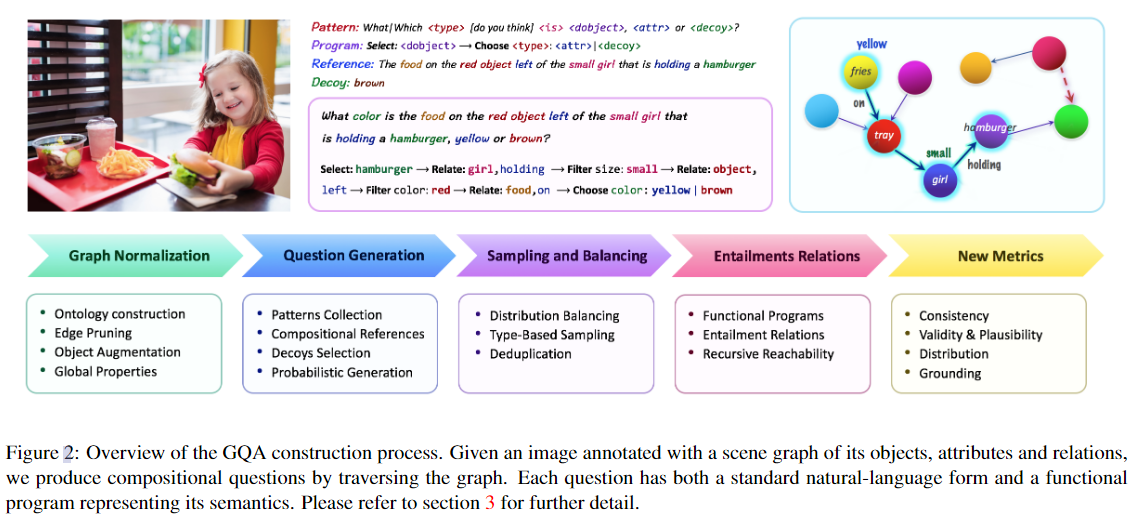
GQA 问题引擎和四步数据集构建过程:
(1)首先,我们彻底清理、规范化、巩固和增强与每个图像相关联的 Visual Genome 场景图 。
(2)然后,我们遍历图中的对象和关系,并将它们与从 VQA 2.0 [11] 和 sundry 概率语法规则中收集的语法模式进行匹配,以产生语义丰富多样的问题集。
(3)在第三阶段,我们使用潜在的语义形式来减少条件答案分布中的偏差从而产生一个平衡的数据集,该数据集对快捷方式和猜测更为稳健。
(4)最后,我们讨论了问题函数表示,并解释了如何使用它来计算问题之间的蕴涵,支持新的评估度量。
Scene Graph Normalization
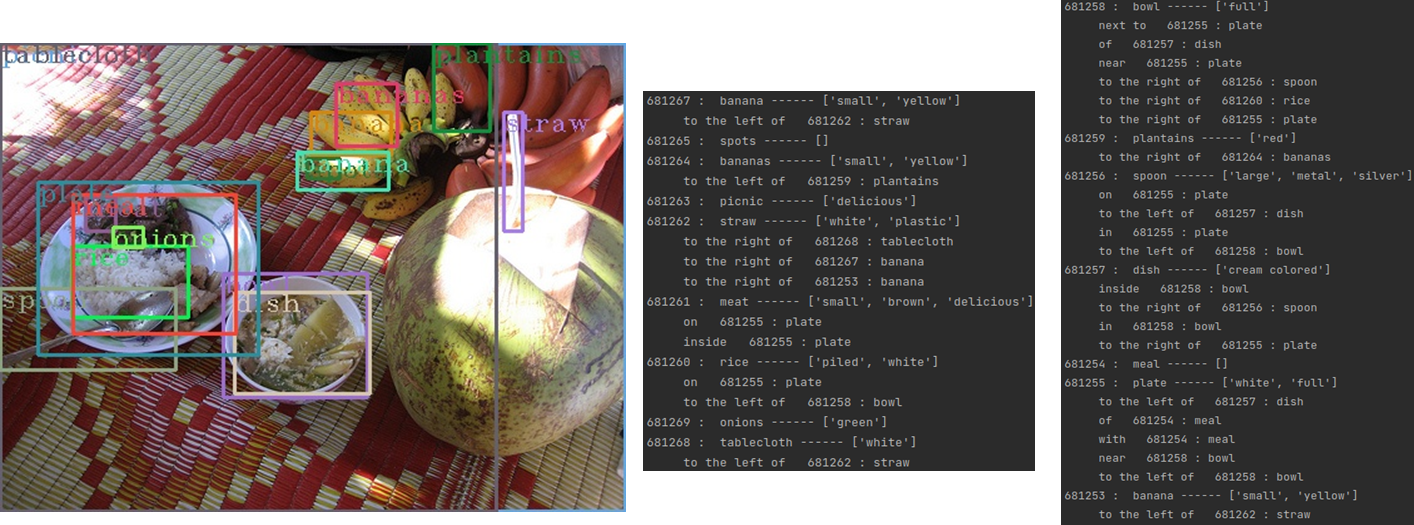
场景图:作为图像的形式化表示,每个节点表示一个对象,图像中的一个视觉实体,如人、苹果、草或云。它链接到一个指定其位置和大小的边界框,并用大约1-3个属性、对象的属性进行标记:例如,其颜色、形状、材质或活动。对象由关系边连接,表示动作(动词)、空间关系(介词)和比较词。
场景图用自由形式的自然语言进行注释。为了将它们用于问题生成,我们首先必须规范化图及其词汇表。我们在这里简要概述了归一化过程,并在补充中提供了更详细的描述。首先,我们在图上创建一个干净、合并和明确的本体,其中包含 2690 个类别,包括各种对象、属性和关系。我们进一步用语义和语言信息对其进行扩充,这将有助于我们创建语法问题。然后,我们结合对象检测置信度、n-gram 频率、共现统计、词嵌入距离、基于类别的规则和手动管理来修剪不准确或不自然的边缘。最后,我们用位置信息(绝对和相对)以及语义属性(位置、天气)来丰富图。在这个阶段结束时,生成的场景图对节点和边都具有干净、统一、丰富且明确的语义。
The Question Engine(问题引擎)
我们管道的核心是问题引擎,负责产生具有不同程度的组合性的各种相关和语法问题。生成过程利用了两种资源:一种是以丰富内容推动引擎的场景图——有关对象、属性和关系的信息;另一种是结构模式,一种塑造内容的模型,将其转换为问题。
我们的引擎对 524 个模式进行操作,涵盖 117 个问题组和 1878 个基于场景图的答案。每组都与三个组件相关联:
(1)表示其语义的功能程序;
(2) 一组用自然语言表达它的文本改写e.g.,“What|Which [do you think] ?”
(3)一对长短两个答案e.g.attribute and “The object is attribute.”
除了使用对象和属性的同义词外,还使用概率部分整合到模式中。例如theObject替换为"the apple to the left of the white refrigerator"。
为了实现这种组合性,我们为每一个对象计算一组候选引用,这些引用可以是直接的或者间接的,例如the bear,this animal,the white bear,the bear on the left,the animal behind the tree,who is looking at the animal that is wearing the red coat in front of the window?。
为场景图元素计算一组诱饵。负面问题或涉及逻辑推理的问题,属于没有对象或不正确的属性。
为生成问题所做的准备有:(1)干净的场景图,(2)结构模式,(3)对象引用,(4)诱饵。生成步骤为遍历场景图,对于每个对象、对象属性对或主题-关系-对象三元组,我们通过实例化随机选择的问题模式来生成相关问题e.g."what type is the Object,attribute or cAttribute?,用匹配信息填充所有字段。注意:在选择匹配信息时,我们避免选择那些披露答案或重复的信息。
Functional Representation and Entailment
每个问题模式都与功能程序形式的结构化表示相关联。例如:问题What color is the apple on the white table?在语义上等同于以下程序:select:table->filter:white->relate(subject,on):apple->query:color。这些程序由原子操作组成,然后将其链接在一起以创建具有挑战性的推理问题。
抽样和平衡
现有的 VQA 数据集的主要问题之一是流行的问题条件偏差,它允许学习者在不真正理解所呈现的图像的情况下做出有根据的猜测。然而,问题语义的精确表示可以允许对这些偏差进行更严格的控制,有可能极大地缓解问题。
根据问题的类型对问题进行下采样,以控制数据集类型组合。
数据集对比分析
GQA:包含22669678个问题和对应的113018张图片组成。词汇量为3097和1878个可能的答案。
新的评估指标
- 一致性。顾名思义,这是在考察模型回答问题的一致性:对于同一张图片,当面对一个新问题时,模型给出的答案不应该与过去的回答相矛盾。在GQA中,由于问题数据的高度结构化,这种逻辑等同的问题很容易通过程序被聚集在一起,形成一组组entailed questions(当得知了其中任何一个问题的答案时,其余问题的答案都可以被直接推断出来)。随后,当一个问题被模型回答正确时,模型回答其对应的entailed questions的平均准确率则可以衡量出该模型的Consistency。
- 有效性。这个指标考察模型的回答是否在问题涉及的范围里,比如,当面对一个颜色的问题时,模型的回答必须是一种颜色。由于GQA内部维护了一个分类的词汇表,所以可以计算该指标。
- 合理性。与Validity类似,同样考察模型回答的合理范围,但更加严格,要求模型的回答必须是符合常识的。通过统计答案是否曾和问题的主语一同在训练数据中出现过,我们可以计算出该指标。
- 分布分数。衡量模型预测的答案分布与真实答案分布的距离,当模型只预测常见的答案而忽略那些少见的答案时,这一指标的得分就会比较低。
- Grounding:针对那些使用了attention机制的模型,这个指标考察了模型是否将注意力集中到了准确的区域。
对比图

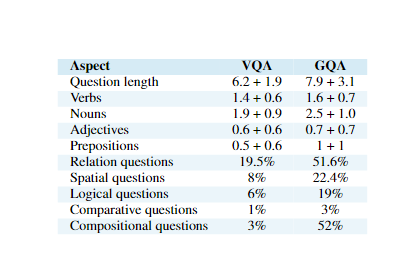
可视化
GQA数据表示形式
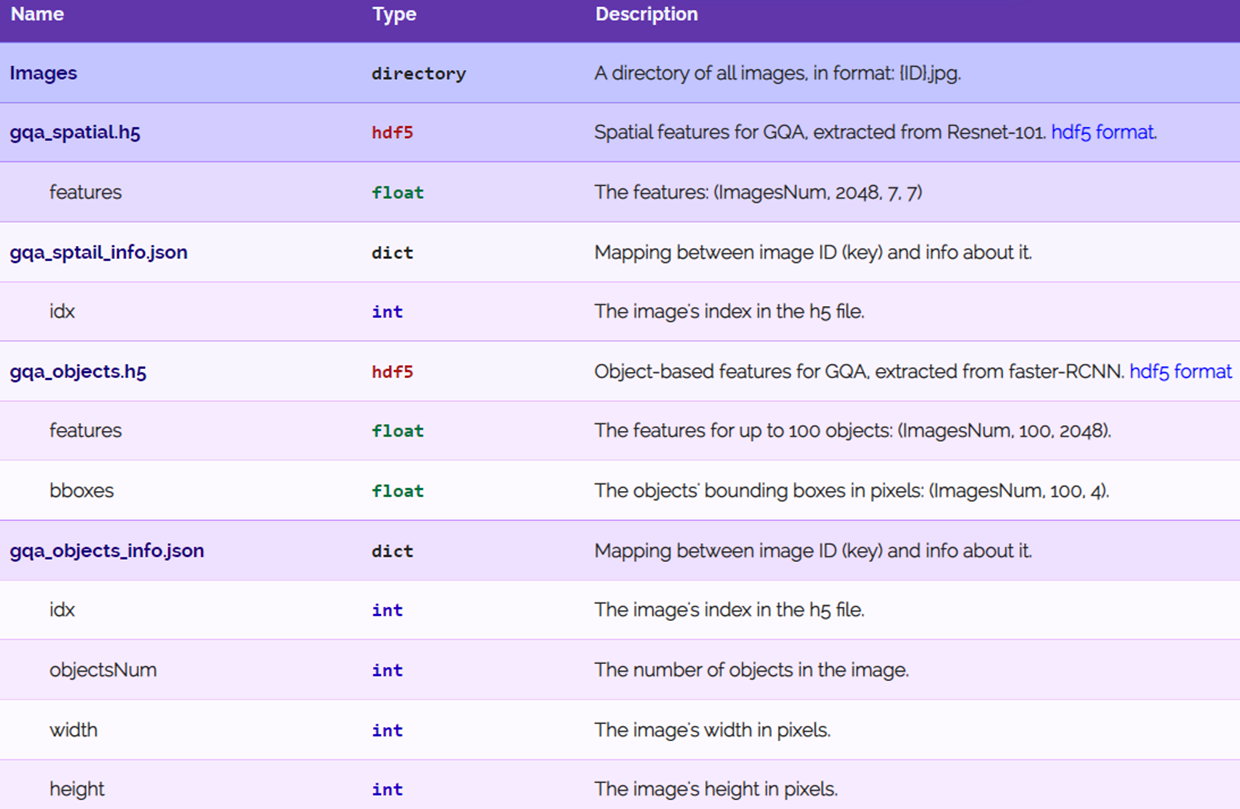
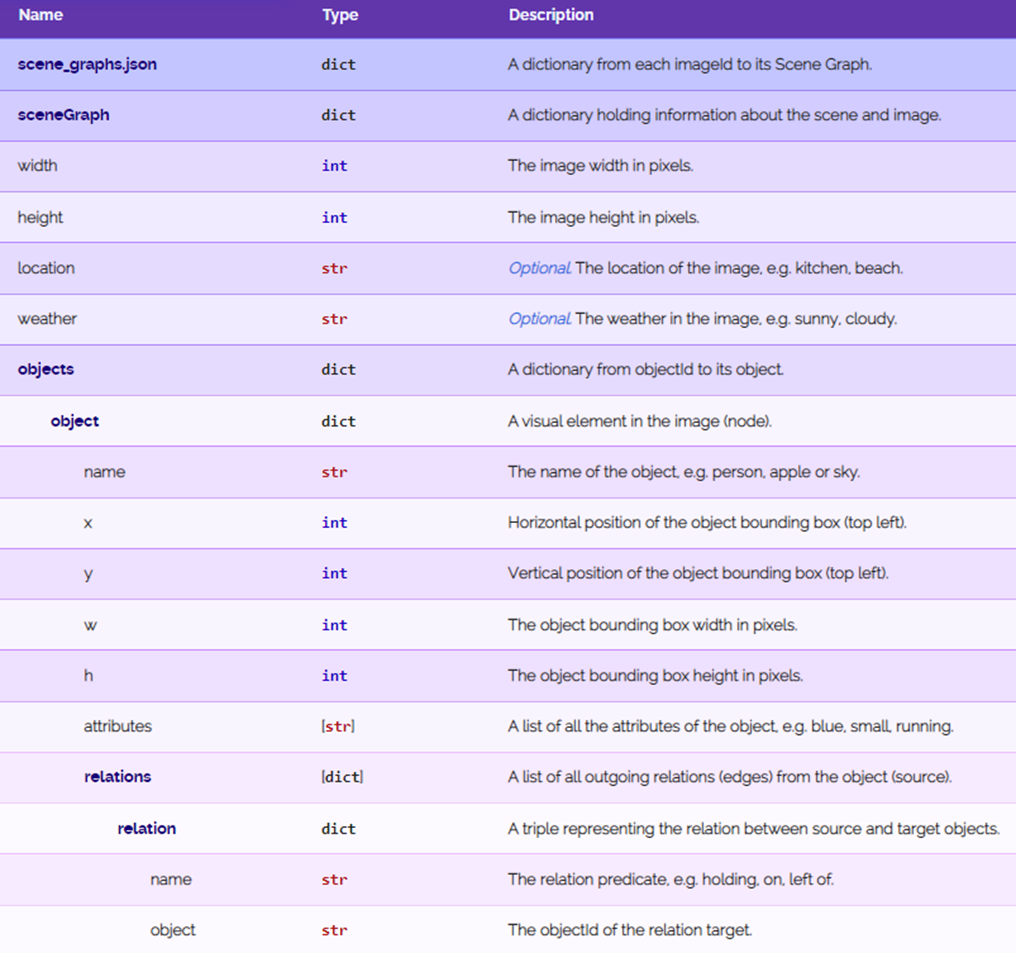
场景图
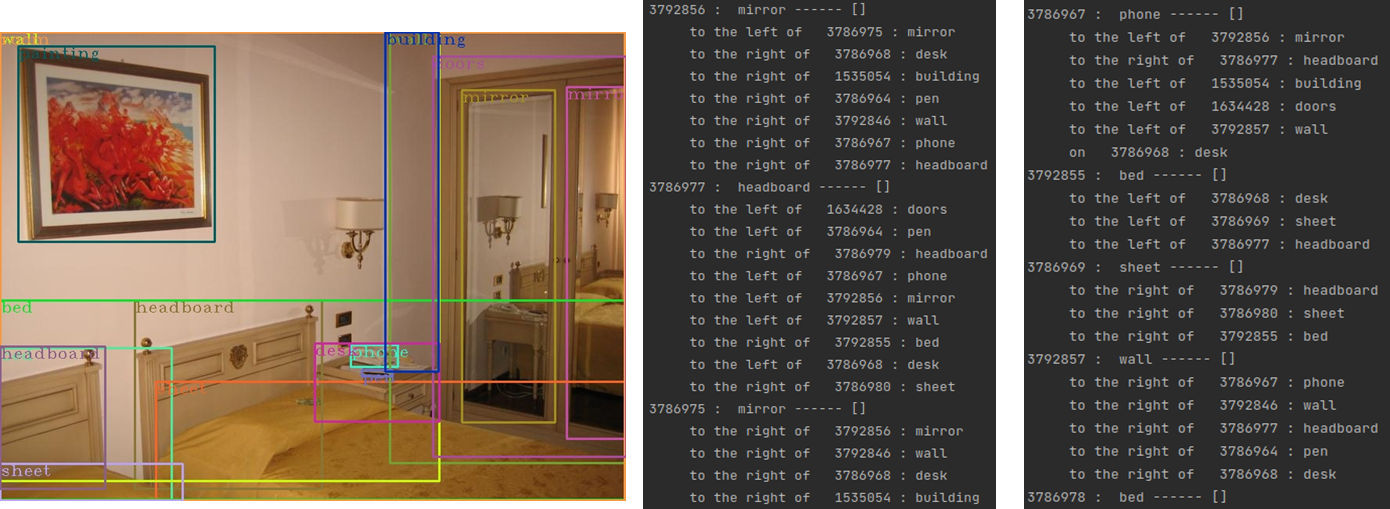
问题
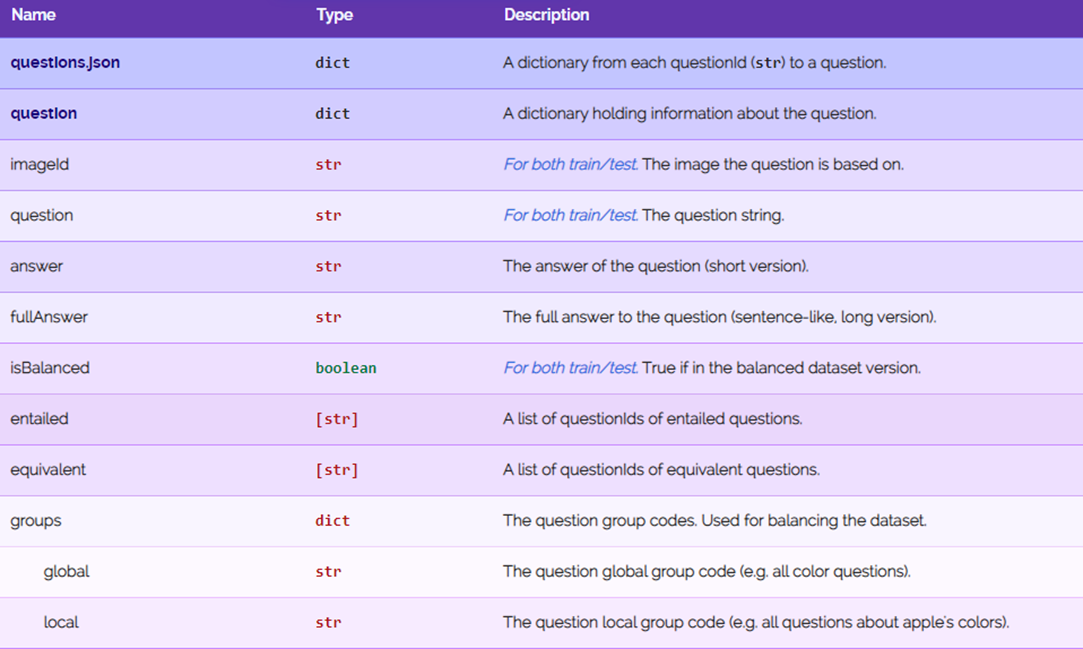
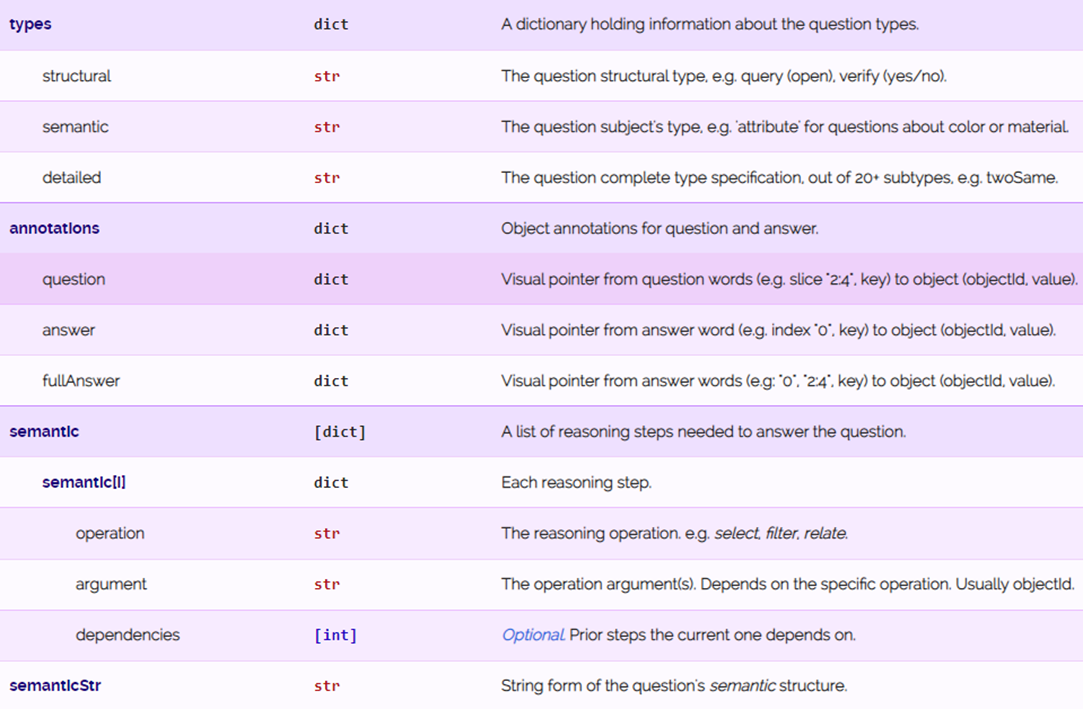
对于问题信息的标注,GQA数据集针对每个问题都标注了上述表中这些信息,除了包含必须要有的图片id、问题和答案,这里还有问题分组信息、问题类型、语义信息、回答该问题的推理过程等。这里面很多的参数其实是在构建数据集的时候使用的,比如说用于控制数据分布均衡。同时可以用来计算新的指标。
















 1350
1350











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









