







文章目录
课程资料《pandas数据处理与分析》、github地址、讲解视频、习题参考答案 、pandas官网
传送门:
第一章、预备知识
1.1 Python基础
1.1.1 列表推导式与条件赋值
- 在生成一个数字序列的时候,利用列表推导式书写更加简洁:
In [5]: [my_func(i) for i in range(5)]
Out[5]: [0, 2, 4, 6, 8]
列表表达式还支持多层嵌套,如下面的例子中第一个 for 为外层循环,第二个为内层循环:
In [6]: [m+'_'+n for m in ['a', 'b'] for n in ['c', 'd']]
Out[6]: ['a_c', 'a_d', 'b_c', 'b_d']
- 除了列表推导式,另一个实用的语法是if 选择的条件赋值,其形式为
value = a if condition else b :。下面举一个例子,截断列表中超过 5 的元素:
In [9]: L = [1, 2, 3, 4, 5, 6, 7]
In [10]: [i if i <= 5 else 5 for i in L]
Out[10]: [1, 2, 3, 4, 5, 5, 5]
1.1.2 lambda匿名函数与map方法
例如上面列表推导式中的例子,用户不关心函数的名字,只关心这种映射的关系:
In [15]: [(lambda x: 2*x)(i) for i in range(5)]
Out[15]: [0, 2, 4, 6, 8]
对于上述的这种列表推导式的匿名函数映射, Python 中提供了 map 函数来完成,它返回的是一个 map 对象,需要通过 list 转为列表:
In [16]: list(map(lambda x: 2*x, range(5)))
Out[16]: [0, 2, 4, 6, 8]
对于多个输入值的函数映射,可以通过追加迭代对象实现:
In [17]: list(map(lambda x, y: str(x)+'_'+y, range(5), list('abcde')))
Out[17]: ['0_a', '1_b', '2_c', '3_d', '4_e']
1.1.3 zip对象与enumerate方法
zip函数能够把多个可迭代对象打包成一个元组构成的可迭代对象,它返回了一个 zip 对象,通过 tuple, list 可以得到相应的打包结果:
In [18]: L1, L2, L3 = list('abc'), list('def'), list('hij')
In [19]: list(zip(L1, L2, L3))
Out[19]: [('a', 'd', 'h'), ('b', 'e', 'i'), ('c', 'f', 'j')]
In [20]: tuple(zip(L1, L2, L3))
Out[20]: (('a', 'd', 'h'), ('b', 'e', 'i'), ('c', 'f', 'j'))
- 往往会在循环迭代的时候使用到 zip 函数:
In [21]: for i, j, k in zip(L1, L2, L3):
....: print(i, j, k)
....:
a d h
b e i
c f j
- 当需要对两个列表建立字典映射时,可以利用 zip 对象:
In [25]: dict(zip(L1, L2))
Out[25]: {'a': 'd', 'b': 'e', 'c': 'f'}
- Python 也提供了
*操作符和zip联合使用来进行解压操作:
In [26]: zipped = list(zip(L1, L2, L3))
In [27]: zipped
Out[27]: [('a', 'd', 'h'), ('b', 'e', 'i'), ('c', 'f', 'j')]
In [28]: list(zip(*zipped)) # 三个元组分别对应原来的列表
Out[28]: [('a', 'b', 'c'), ('d', 'e', 'f'), ('h', 'i', 'j')]
enumerate是一种特殊的打包,它可以在迭代时绑定迭代元素的遍历序号。
1.1.4 如何把多层嵌套的列表展平
- 用递归和循环来实现:
def flat(deep_list, result):
for element in deep_list:
if isinstance(element, list):
flat(element, result)
else:
result.append(element)
a = [1, 2, [3, 4, [5, 6, 7], 8], 9, [10, 11]]
result = []
flat(a, result)
print(result)
这样做确实能达到目的,但是需要把储存结果的列表作为参数不停递归传入。实际上,如果使用生成器,这个问题就会变得简单很多:
def flat(deep_list):
for element in deep_list:
if isinstance(element, list):
yield from flat(element)
else:
yield element
a = [1, 2, [3, 4, [5, 6, 7], 8], 9, [10, 11]]
result = [x for x in flat(a)]
print(result)
在这个解法里面,使用了 yield和 yieldfrom实现生成器,当我们直接对生成器进行迭代的时候,就得到了结果。其中, yieldfrom是从Python 3.3开始引入的写法:
yield from x
# 等价于
for g in x:
yield g
所以,当代码运行到[x for x in flat(a)]的时候,每一次循环都会进入到 flat生成器里面。在 flat里面,对传入的参数使用for循环进行迭代,如果拿到的元素不是列表,那么就直接抛出,送到上一层。如果当前已经是最上层了,那么就再一次抛出给外面的列表推导式。如果当前元素是列表,那么继续生成一个生成器,并对这个新的生成器进行迭代,并把每一个结果继续往上层抛出。
最终,每一个数字都会被一层一层往上抛出给列表推导式,从而获得需要的结果。
1.2 Numpy基础
见课程《第一章 预备知识》。不写笔记了,内容太多了。
- np 数组的构造
1.2.1 基础知识
np.linspace(1,5,11) # 起始、终止(包含)、样本个数
np.arange(1,5,2) # 起始、终止(不包含)、步长
np.zeros((2,3)) # 传入元组表示各维度大小
np.eye(3) # 3*3 的单位矩阵
np.full((2,3), 10) # 元组传入大小,10 表示填充数值
np.full((2,3), [1,2,3]) # 通过传入列表填充每列的值
- 随机矩阵:np.random
np.random.rand(3) # 生成服从 0-1 均匀分布的三个随机数
np.random.rand(3, 3) # shape=[3,3] 。注意这里传入的不是元组,每个维度大小分开输入
(b - a) * np.random.rand(3) + a # 服从区间 a 到 b 上的均匀分布
#标准正态分布
np.random.randn(3)
np.random.randn(2, 2)
mu + np.random.randn(3) * sigma # 服从方差为sigma平方,均值为mu的一元正态分布
#生成随机整数
np.random.randint(low, high, size)# 例如low,high,size =5,15,(2,2)
np.random.seed(0) # 随机种子,它能够固定随机数的输出结果
"""
choice 可以从给定的列表中,以一定概率和方式抽取结果,
当不指定概率时为均匀采样,默认抽取方式为有放回抽样
"""
my_list = ['a', 'b', 'c', 'd']
np.random.choice(my_list, 2, replace=False, p=[0.1, 0.7, 0.1 ,0.1])
- 向量与矩阵计算
- 向量内积:
a.dot(b),类似两个向量对应位置的元素加权求和,结果是一个标量。 - 矩阵乘法: A m , n @ B n , k = C m , k A_{m,n}@B_{n,k}=C_{m,k} Am,n@Bn,k=Cm,k,就是线性代数里面矩阵乘法,A的行×B的列
- 矩阵普通乘法 :
A*B=C,矩阵A和B对应元素相乘,结果是一个矩阵C,三个矩阵形状不变
- 向量内积:
详细解释可以参考《PyTorch学习笔记1——基本概念、模块简介、张量操作、自动微分》2.6章节。
- numpy数据的算术运算,参考《Numpy 使用教程–Numpy 数学函数及代数运算》
1.2.2 numpy 差集、异或集、并集、交集
参考《numpy 差集、异或集、并集、交集 setdiff1d() setxor1d() union1d() intersect1d()》
-
求差集
numpy.setdiff1d(array1, array2, assume_unique=False)- 功能:用于获得 array1 和 array2 的差集,返回在 array1 中但不在 array2 中的值;
- 实现:将 array1 和 array2 扁平化到1维后判断 array2 元素是否在 array1 中 再取反
assume_unique默认 False,假定输入值不是唯一的,会先分别对 array1 和 array2 执行一个 unique 操作,而且 unique 的结果本身就是排序后的;
assume_unique 为 True 时,假定输入值是唯一的,不会先对 array1 和 array2 执行 unique 操作;
-
异或元素
numpy.setxor1d(array1, array2, assume_unique=False) :即仅存在于一个 array 中的值,结果是排序后的 -
求并集
numpy.union1d(array1, array2):结果是排序后且去重的。- 实现:该函数通过将 array1 和 array2 合并为一个 array,再使用 unique 进行操作;
-
求交集
numpy.intersect1d(array1, array2, assume_unique=False, return_indices=False):结果是排序后的;- 实现:该函数通过将 array1 和 array2 合并为一个 array,排序后求交集;
-
numpy.in1d(array1, array2, assume_unique=False, invert=False)
- 功能:判断 array1 中元素是否存在于 array2 中,存在返回 True,不存在返回 False,结果形状为一维 array;
- 实现:array1 和 array2 如果不是 array 则会被转换为 array ;该函数通过将 array1 和 array2
1.2.3 numpy中计算各种范数、距离的方法
1.2.4 排名函数np.argsort()
np.argsort(a, axis=-1, kind='quicksort', order=None)功能:将a中的元素从小到大排列,提取其在排列前对应的index(索引)输出。(这个还不是实际的排名)
import numpy as np
x=np.array([1,4,3,-1,6,9])
y=np.argsort(x)
print('一维数组的排序结果:{}'.format(y))
一维数组的排序结果:[3 0 2 1 4 5]
1.3 习题
1.3.1 Ex1:利用列表推导式写矩阵乘法
一般的矩阵乘法根据公式,可以由三重循环写出:
In [138]: M1 = np.random.rand(2,3)
In [139]: M2 = np.random.rand(3,4)
In [140]: res = np.empty((M1.shape[0],M2.shape[1]))
In [141]: for i in range(M1.shape[0]):
.....: for j in range(M2.shape[1]):
.....: item = 0
.....: for k in range(M1.shape[1]):
.....: item += M1[i][k] * M2[k][j]
.....: res[i][j] = item
.....:
In [142]: ((M1@M2 - res) < 1e-15).all() # 排除数值误差
Out[142]: True
请将其改写为列表推导式的形式。
1.3.2 Ex2:更新矩阵

1.3.3 Ex3:卡方统计量

In [143]: np.random.seed(0)
In [144]: A = np.random.randint(10, 20, (8, 5))
1.3.4 Ex4:改进矩阵计算的性能

In [145]: np.random.seed(0)
In [146]: m, n, p = 100, 80, 50
In [147]: B = np.random.randint(0, 2, (m, p))
In [148]: U = np.random.randint(0, 2, (p, n))
In [149]: Z = np.random.randint(0, 2, (m, n))
In [150]: def solution(B=B, U=U, Z=Z):
.....: L_res = []
.....: for i in range(m):
.....: for j in range(n):
.....: norm_value = ((B[i]-U[:,j])**2).sum()
.....: L_res.append(norm_value*Z[i][j])
.....: return sum(L_res)
.....:
In [151]: solution(B, U, Z)
Out[151]: 100566
1.3.5 连续整数的最大长度
输入一个整数的 Numpy 数组,返回其中递增连续整数子数组的最大长度。例如:
- 输入 [1,2,5,6,7],[5,6,7] 为具有最大长度的递增连续整数子数组,因此输出 3;
- 输入 [3,2,1,2,3,4,6],[1,2,3,4] 为具有最大长度的递增连续整数子数组,因此输出 4。
请充分利用 Numpy 的内置函数完成。(提示:考虑使用 nonzero, diff 函数)
1.3.6 作答
也可见kaggle nootbook《pandas》
- Ex1:利用列表推导式写矩阵乘法,代码为;
#三层for循环就用三层列表,最外层for循环写在列表推导式的最外面
res=[
[
sum([
M1[i][k]*M2[k][j] for k in range(M1.shape[1])
]) for j in range(M2.shape[1])
] for i in range(M1.shape[0])
]
res=np.array(res)
res.shape, ((M1@M2 - res) < 1e-15).all()
((2, 4), True)
- Ex2:更新矩阵
#对A所有元素求倒数,然后每一行求和得到a,这个就是1/A_{ik}的累加和。
# a是行向量,应转为列向量再与A用普通乘法
A=np.random.rand(3, 3)
B=A*(np.full(A.shape,np.sum(np.reciprocal(A),axis=1)).T)
A,B
array([[0.75156347, 0.97603014, 0.56223833],
[0.34680203, 0.88921533, 0.02455252],
[0.14087899, 0.30807796, 0.27352437]])
array([[ 3.10675542, 43.66475559, 7.87145115],
[ 1.43358365, 39.78091286, 0.34374025],
[ 0.58235476, 13.78251348, 3.82939685]])
参考答案:B= A*(1/A).sum(1).reshape(-1,1)。我写的太麻烦了,忘了numpy可以广播。另外倒数直接用1/A就行,反而使用np.reciprocal函数,对整型只会返回整型,结果都是0和1就不对了。
- Ex3:卡方统计量
# 矩阵B的每个元素是A的(元素所在的行之和×元素所在的列之和)/元素。
# 和上一题一样,分别对行和列求和,再填充到一样的形状,得到A_col和A_row
np.random.seed(0)
A = np.random.randint(10, 20, (8, 5))
A_col=np.full(A.shape,np.sum(A,0))
A_row=(np.full(A.T.shape,np.sum(A,1)).T)
B=(A_col*A_row)/A.sum()
result=((A-B)**2/B).sum()
result
11.842696601945802
参考答案:B= A.sum(0)*A.sum(1).reshape(-1, 1)/A.sum(),第二步计算一样 。
- Ex4:改进矩阵计算的性能
Y=(B.sum(1)**2)[:,None]+(U.sum(0)**2)[None,:]-2*B@U #第一次做的答案,是错的
# 正确答案如下:
Y=((B**2).sum(1))[:,None]+((U**2).sum(0))[None,:]-2*B@U
(Y*Z).sum()
参考答案:(((B**2).sum(1).reshape(-1,1) + (U**2).sum(0) - 2*B@U)*Z).sum()。
我一开始也是想难道要展开类似
(
B
−
U
)
2
(B-U)^2
(B−U)2,但是发现维度不一致没有深究。后来又我先求和再做平方,确实是想岔了,半天检查不出错误。前者是每一行之和的平方,而不是每个元素的平方的和。
- 连续整数的最大长度
参考答案:对于数组x,连续整数的最大长度为np.diff(np.nonzero(np.r_[1,np.diff(x)!=1,1])).max()
"""
6. 所有元素做差,np.diff(x)!=1表示与前面差值为1的元素,对应位置返回0,其余位置返回1.
然后前后都填充1,这样所有为0的位置就是递增的位置,所有为1的位置就是递增的边界处
"""
x=np.array([1,2,3,5,7,8,9,10])
np.r_[1,np.diff(x)!=1,1]
"""2. 得到递增边界点索引"""
np.nonzero(np.r_[1,np.diff(x)!=1,1])
"""3. 各个边界的距离差"""
np.diff(np.nonzero(np.r_[1,np.diff(x)!=1,1]))#下面取个max就是最大连续递增长度了
第二章、pandas基础
2.1 文件的读取和写入
数据读取
pandas 可以读取的文件格式有很多,这里主要介绍读取 csv, excel, txt 文件。
df_csv = pd.read_csv('data/my_csv.csv')
df_txt = pd.read_table('data/my_table.txt')
df_excel = pd.read_excel('data/my_excel.xlsx')
这里有一些常用的公共参数:
- header=None 表示第一行不作为列名
- index_col 表示把某一列或几列作为索引,索引的内容将会在第三章进行详述
- usecols 表示读取列的集合,默认读取所有的列
- parse_dates 表示需要转化为时间的列,关于时间序列的有关内容将在第十章讲解
- nrows 表示读取的数据行数。
- 在读取 txt 文件时,经常遇到分隔符非空格的情况, read_table 有一个分割参数 sep ,它使得用户可以自定义分割符号,进行 txt 数据的读取。例如,下面的读取的表以 |||| 为分割:
pd.read_table('data/my_table_special_sep.txt',
sep=' \|\|\|\| ', engine='python')
在使用 read_table 的时候需要注意,参数
sep中使用的是正则表达式,因此需要对 | 进行转义变成 | ,否则无法读取到正确的结果
数据写入
pandas 中没有定义 to_table 函数,但是 to_csv 可以保存为 txt 文件,并且允许自定义分隔符,常用制表符 \t 分割:
# index=False 表示去除索引,当索引没有特殊意义的时候。
df_txt.to_csv('data/my_txt_saved.txt', sep='\t', index=False)
如果想要把表格快速转换为 markdown 和 latex 语言,可以使用 to_markdown 和 to_latex 函数,此处需要安装 tabulate 包。
print(df_csv.to_markdown())
| col1 | col2 | col3 | col4 | col5 | |
|---|---|---|---|---|---|
| 0 | 2 | a | 1.4 | apple | 2020/1/1 |
| 1 | 3 | b | 3.4 | banana | 2020/1/2 |
| 2 | 6 | c | 2.5 | orange | 2020/1/5 |
| 3 | 5 | d | 3.2 | lemon | 2020/1/7 |
print(df_csv.to_latex())
\begin{tabular}{lrlrll}
\toprule
{} & col1 & col2 & col3 & col4 & col5 \\
\midrule
0 & 2 & a & 1.4 & apple & 2020/1/1 \\
1 & 3 & b & 3.4 & banana & 2020/1/2 \\
2 & 6 & c & 2.5 & orange & 2020/1/5 \\
3 & 5 & d & 3.2 & lemon & 2020/1/7 \\
\bottomrule
\end{tabular}
2.2 基本数据结构
2.2.1 Series
Series 一般由四个部分组成,分别是序列的值 data 、索引 index 、存储类型 dtype 、序列的名字 name 。其中,索引也可以指定它的名字,默认为空。对于这些属性,可以通过 . 的方式来获取。
In [22]: s = pd.Series(data = [100, 'a', {'dic1':5}],
....: index = pd.Index(['id1', 20, 'third'], name='my_idx'),
....: dtype = 'object',
....: name = 'my_name')
....:
In [23]: s
Out[23]:
my_idx
id1 100
20 a
third {'dic1': 5}
Name: my_name, dtype: object
object 代表了一种混合类型,正如上面的例子中存储了整数、字符串以及 Python 的字典数据结构。此外,目前 pandas 把纯字符串序列也默认认为是一种 object 类型的序列,但它也可以用 string 类型存储,文本序列的内容会在第八章中讨论。
In [24]: s.values
Out[24]: array([100, 'a', {'dic1': 5}], dtype=object)
In [25]: s.index
Out[25]: Index(['id1', 20, 'third'], dtype='object', name='my_idx')
In [26]: s.dtype
Out[26]: dtype('O')
In [27]: s.name
Out[27]: 'my_name'
In [28]: s.shape
Out[28]: (3,)
2.2.2 DataFrame
DataFrame 在 Series 的基础上增加了列索引,一个数据框可以由二维的 data 与行列索引来构造:
In [30]: data = [[1, 'a', 1.2], [2, 'b', 2.2], [3, 'c', 3.2]]
In [31]: df = pd.DataFrame(data = data,
....: index = ['row_%d'%i for i in range(3)],
....: columns=['col_0', 'col_1', 'col_2'])
....:
In [32]: df
Out[32]:
col_0 col_1 col_2
row_0 1 a 1.2
row_1 2 b 2.2
row_2 3 c 3.2
一般而言,更多的时候会采用从列索引名到数据的映射来构造数据框,同时再加上行索引:
In [33]: df = pd.DataFrame(data = {'col_0': [1,2,3], 'col_1':list('abc'),
....: 'col_2': [1.2, 2.2, 3.2]},
....: index = ['row_%d'%i for i in range(3)])
....:
In [34]: df
Out[34]:
col_0 col_1 col_2
row_0 1 a 1.2
row_1 2 b 2.2
row_2 3 c 3.2
2.2.3 修改行列索引/值&列排序
列排序
列排序有三种方法,下面进行演示:
data = {
'brand':['Python数据之道','价值前瞻','菜鸟数据之道','Python','Java'],
'B':[4,6,8,12,10],
'A':[10,2,5,20,16],
'D':[6,18,14,6,12],
'years':[4,1,1,30,30],
'C':[8,12,18,8,2],
}
df = pd.DataFrame(data=data)
data
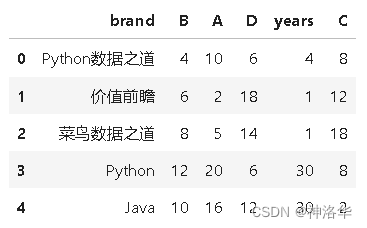
- 暴力列表调整:就是自己将列的名称按需要进行手动排序
df[['B','A','D','years','C','brand']]
B A D years C brand
0 4 10 6 4 8 Python数据之道
1 6 2 18 1 12 价值前瞻
2 8 5 14 1 18 菜鸟数据之道
3 12 20 6 30 8 Python
4 10 16 12 30 2 Java
列表也可用其它方式排序,比如:
cols = list(df.columns).reverse() # 转为列表后倒序排列
df[cols]
- 使用 .iloc 方法,通过列的位置来进行排序,比如
df.iloc[:,[0,2,3,1,4,5]] - 使用 .loc 方法,通过列的名称来进行排序,比如
df.loc[:,'B','A','D','years','C','brand']]
修改行列索引名字
- 有原索引名 :通过
rename_axis可以对索引层的名字进行修改,常用的修改方式是传入字典的映射:
df_ex.rename_axis(index={'Upper':'Changed_row'},
columns={'Other':'Changed_Col'}).head()
- 没有原索引名 :有时候我们stack或unstack方法转换了行列索引,或者groupby分组统计时等情况会出现索引名没有,此时无法通过字典传入原索引名进行修改。
- 如果是单级索引没有名字,可直接使用
df.rename_axis('name',axis=axis)来修改。其中axis默认为0,即行索引(也就是修改行索引不用传入axis的值);如果修改列索引,指定axis=1就行。 - 多级索引没有索引名:等我遇到再搞
- 如果是单级索引没有名字,可直接使用
修改列名
- 暴力修改列名,即重新命名列名:
df.columns=['a','B','c',...] rename指定修改某列或某几列名字:df.rename(columns={'a':'A','b':'B'})
修改某一列的值
df['id']=list/n,直接修改选取的列为一个列表(长度得相同)或者唯一值n。- 使用loc筛选后赋值:
df.loc[condition1|(condition2&condition3),'col']=list/n
2.3 常用基本函数
为了进行举例说明,在接下来的部分和其余章节都将会使用一份 learn_pandas.csv 的虚拟数据集,它记录了四所学校学生的体测个人信息。
df = pd.read_csv('data/learn_pandas.csv')
2.3.1 汇总函数
- head, tail 函数分别表示返回表或者序列的前 n 行和后 n 行,其中 n 默认为 5。
- info, describe 分别返回表的 信息概况和表中 数值列对应的主要统计量
2.3.2 统计函数
统计函数,操作后返回的是标量,所以又称为聚合函数,它们有一个公共参数 axis ,默认为0 代表逐列聚合,如果设置为 1 则表示逐行聚合:
- 最常见的是 sum, mean, median, var, std, max, min
- quantile, count, idxmax 这三个函数,它们分别返回的是分位数、非缺失值个数、最大值对应的索引
2.3.3 唯一值函数
- unique 和 nunique 可以分别得到其唯一值组成的列表和唯一值的个数
In [57]: df['School'].unique()
Out[57]:
array(['Shanghai Jiao Tong University', 'Peking University',
'Fudan University', 'Tsinghua University'], dtype=object)
In [58]: df['School'].nunique()
Out[58]: 4
- value_counts 可以得到唯一值和其对应出现的频数:
In [59]: df['School'].value_counts()
Out[59]:
Tsinghua University 69
Shanghai Jiao Tong University 57
Fudan University 40
Peking University 34
Name: School, dtype: int64
- 如果想要观察多个列组合的唯一值,可以使用 drop_duplicates 。其中的关键参数是 keep ,默认值 first 表示每个组合保留第一次出现的所在行,last 表示保留最后一次出现的所在行,False 表示把所有重复组合所在的行剔除。
In [60]: df_demo = df[['Gender','Transfer','Name']]
In [62]: df_demo.drop_duplicates(['Gender', 'Transfer'], keep='last')
Out[62]:
Gender Transfer Name
147 Male NaN Juan You
150 Male Y Chengpeng You
169 Female Y Chengquan Qin
194 Female NaN Yanmei Qian
197 Female N Chengqiang Chu
199 Male N Chunpeng Lv
- 此外,duplicated 和 drop_duplicates 的功能类似,但前者返回了是否为唯一值的布尔列表,其 keep 参数与后者一致。其返回的序列,把重复元素设为 True ,否则为 False 。drop_duplicates 等价于把 duplicated 为True 的对应行剔除。
df_demo.duplicated(['Gender', 'Transfer']).head()
0 False
1 False
2 True
3 True
4 True
dtype: bool
2.3.4 替换函数
一般而言,替换操作是针对某一个列进行的,因此下面的例子都以 Series 举例。pandas 中的替换函数可以归纳为三类:映射替换、逻辑替换、数值替换。
映射替换包含 replace 方法、第八章中的 str.replace 方法以及第九章中的 cat.codes 方法,此处介绍 replace 的用法。在 replace 中,可以通过字典构造,或者传入两个列表来进行替换:
df.head()
School Grade Name Gender Height Weight Transfer
0 A Freshman Gaopeng Yang Female 158.9 46.0 N
1 B Freshman Changqiang You Male 166.5 70.0 N
2 A Senior Mei Sun Male 188.9 89.0 N
3 C Sophomore Xiaojuan Sun Female NaN 41.0 N
4 C Sophomore Gaojuan You Male 174.0 74.0 N
df['Gender']=df['Gender'].replace({'Female':0, 'Male':1})
# 也可以写作下面的代码
# df['Gender']=df['Gender'].replace(['Female', 'Male'], [0, 1])
df.head()
School Grade Name Gender Height Weight Transfer
0 A Freshman Gaopeng Yang 0 158.9 46.0 N
1 B Freshman Changqiang You 1 166.5 70.0 N
2 A Senior Mei Sun 1 188.9 89.0 N
3 C Sophomore Xiaojuan Sun 0 NaN 41.0 N
4 C Sophomore Gaojuan You 1 174.0 74.0 N
** str.replace**
几乎所有 Python 内置的字符串方法都被复制到 Pandas 的向量化字符串方法中。下面的表格列举了 Pandas 的 str 方法借鉴 Python 字符串方法的内容:
len() lower() translate() islower()
ljust() upper() startswith() isupper()
rjust() find() endswith() isnumeric()
center() rfind() isalnum() isdecimal()
zfill() index() isalpha() split()
strip() rindex() isdigit() rsplit()
rstrip() capitalize() isspace() partition()
lstrip() swapcase() istitle() rpartition()
需要注意的是,这些方法的返回值不同,例如 lower() 方法返回一个字符串 Series :
monte.str.lower()
Out[7]:
0 graham chapman
1 john cleese
2 terry gilliam
3 eric idle
4 terry jones
5 michael palin
dtype: object
但是有些方法返回数值:
In[8]: monte.str.len()
Out[8]:
0 14
1 11
2 13
3 9
4 11
5 13
dtype: int64
逻辑替换包括了 where 和 mask ,这两个函数是完全对称的。
- where 函数在传入条件为 False 的对应行进行替换
- mask 在传入条件为 True 的对应行进行替换
- 当不指定替换值时,替换为缺失值。
In [72]: s = pd.Series([-1, 1.2345, 100, -50])
In [73]: s.where(s<0,100)
Out[73]:
0 -1.0
1 100
2 100
3 -50.0
dtype: float64
传入的条件只需是与被调用的 Series 索引一致的布尔序列即可:
In [77]: s_condition= pd.Series([True,False,False,True],index=s.index)
In [78]: s.mask(s_condition, -50)
Out[78]:
0 -50.0000
1 1.2345
2 100.0000
3 -50.0000
dtype: float64
数值替换包含了 round, abs, clip 方法,它们分别表示取整、取绝对值和截断:
In [79]: s = pd.Series([-1, 1.2345, 100, -50])
In [80]: s.round(2)
Out[80]:
0 -1.00
1 1.23
2 100.00
3 -50.00
dtype: float64
In [81]: s.abs()
Out[81]:
0 1.0000
1 1.2345
2 100.0000
3 50.0000
dtype: float64
In [82]: s.clip(0,2) # 前两个数分别表示上下截断边界
Out[82]:
0 0.0000
1 1.2345
2 2.0000
3 0.0000
dtype: float64
2.3.5 排序函数&排名函数rank
排序共有两种方式,其一为值排序,其二为索引排序,对应的函数是 sort_values 和 sort_index。为了演示排序函数,下面先利用 set_index 方法把年级和姓名两列作为索引,多级索引的内容和索引设置的方法将在第三章进行详细讲解。
排序函数
- 对身高进行排序,默认参数 ascending=True 为升序:
In [83]: df_demo = df[['Grade', 'Name', 'Height','Weight']].set_index(['Grade','Name'])
In [84]: df_demo.sort_values('Height').head()
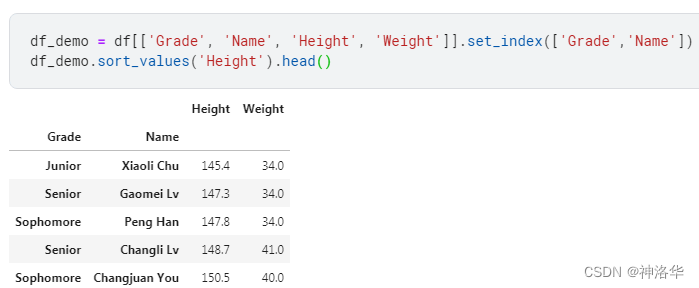
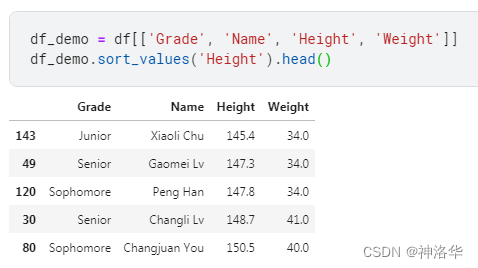
如果不设置索引列,则:
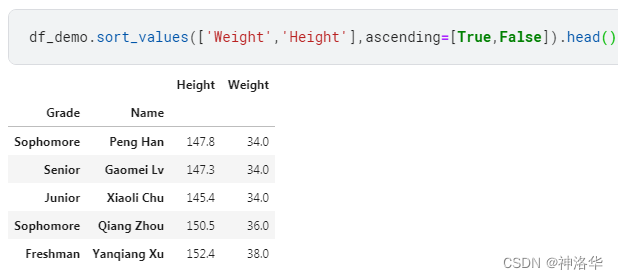
- 多列排序:比如保持身高降序排列,体重升序排列
In [86]: df_demo.sort_values(['Weight','Height'],ascending=[True,False]).head()
sort_values()提供了参数kind用来指定排序算法。这里有三种排序算法:
- mergesort(归并排序):最稳定
- heapsort(堆排序)
- quicksort(快速排序):默认算法
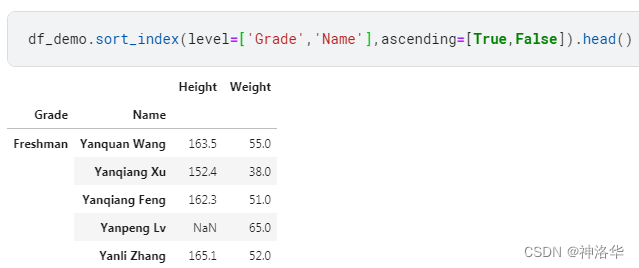
- 索引排序 :用法和值排序完全一致,只不过元素的值在索引中,此时需要指定索引层的名字或者层号,用参数 level 表示。另外,需要注意的是字符串的排列顺序由字母顺序决定。
df_demo.sort_index(level=['Grade','Name'],ascending=[True,False]).head()
排名函数rank
参考《pandas数据分析之排序和排名(sort和rank)》
rank()函数原型:rank(axis=0, method: str = 'average', numeric_only: Union[bool, NoneType] = None, na_option: str = 'keep', ascending: bool = True, pct: bool = False)
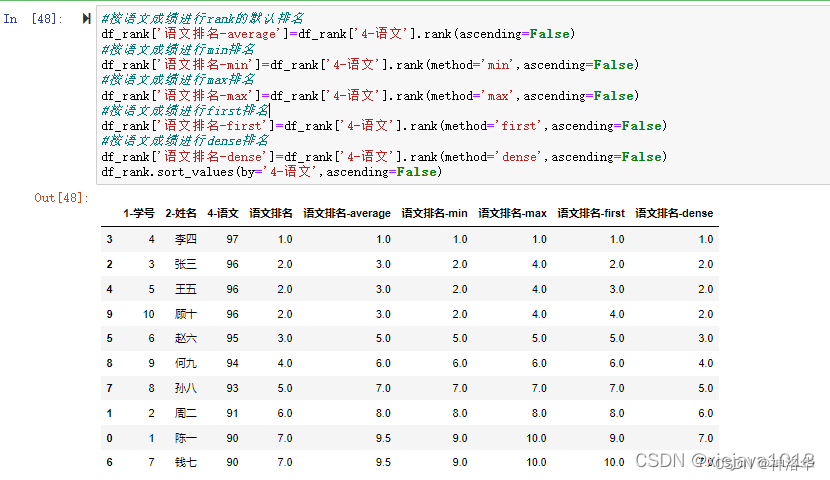
排名和排序的区别在于排序一定是有顺序,而排名分先后并列。method取值可以为’average’,‘first’,‘min’, ‘max’,‘dense’,用来打破排名中的平级关系的:
| method | 说明 |
|---|---|
| average | 默认:在每个组中分配平均排名 |
| min | 对整个组使用最小排名 |
| max | 对整个组使用最大排名 |
| first | 值相同时按索引排序 |
| dense | 类似于method=‘min’,但组件排名总是加1,而不是一个组中的相等元素的数量 |
最后不同method的排名对比:
#按语文成绩进行rank的默认排名
df_rank['语文排名-average']=df_rank['4-语文'].rank(ascending=False)
#按语文成绩进行min排名
df_rank['语文排名-min']=df_rank['4-语文'].rank(method='min',ascending=False)
#按语文成绩进行max排名
df_rank['语文排名-max']=df_rank['4-语文'].rank(method='max',ascending=False)
#按语文成绩进行first排名
df_rank['语文排名-first']=df_rank['4-语文'].rank(method='first',ascending=False)
#按语文成绩进行dense排名
df_rank['语文排名-dense']=df_rank['4-语文'].rank(method='dense',ascending=False)
df_rank.sort_values(by='4-语文',ascending=False)
2.3.6 apply 方法
apply 方法常用于 DataFrame 的行迭代或者列迭代,参数 axis =0 代表逐列操作,为 1 则表示逐行操作。下面两种写法结果是一样的:
df = pd.read_csv('data/learn_pandas.csv')
df_demo = df[['Height', 'Weight']]
#df_demo.mean(1),df_demo.apply(lambda x:x.mean(),axis=1)
df_demo.mean(0),df_demo.apply(lambda x:x.mean(),axis=0)
(Height 163.218033
Weight 55.015873
dtype: float64,
Height 163.218033
Weight 55.015873
dtype: float64)
这里再举一个例子: mad 函数返回的是一个序列中偏离该序列均值的绝对值大小的均值,例如序列1,3,7,10中,均值为5.25,每一个元素偏离的绝对值为4.25,2.25,1.75,4.75,这个偏离序列的均值为3.25。现在利用 apply 计算升高和体重的 mad 指标:
df_demo.apply(lambda x:(x-x.mean()).abs().mean())
Height 6.707229
Weight 10.391870
dtype: float64
这与使用内置的 mad 函数计算结果一致:
df_demo.mad()
Height 6.707229
Weight 10.391870
dtype: float64
谨慎使用apply:
apply 的自由度很高,但这是以性能为代价的。一般而言,使用 pandas 的内置函数处理和 apply 来处理同一个任务,其速度会相差较多,因此只有在确实存在自定义需求的情境下才考虑使用 apply 。
2.4 窗口对象
pandas 中有3类窗口,分别是滑动窗口 rolling 、扩张窗口 expanding 以及指数加权窗口 ewm 。需要说明的是,以日期偏置为窗口大小的滑动窗口将在第十章讨论,指数加权窗口见本章练习。
2.4.1 滑窗对象
- 要使用滑窗函数,就必须先要对一个序列使用 .rolling 得到滑窗对象,其最重要的参数为窗口大小 window 。
s = pd.Series([1,2,3,4,5])
roller = s.rolling(window = 3)
roller
Rolling [window=3,center=False,axis=0]
- 在得到了滑窗对象后,能够使用相应的聚合函数进行计算,需要注意的是窗口包含当前行所在的元素,例如在第四个位置进行均值运算时,应当计算(2+3+4)/3,而不是(1+2+3)/3。
- 支持使用 apply 传入自定义函数,其传入值是对应窗口的 Series
roller.mean()# 数组中有一个缺失值,就返回缺失值,有些方法可以绕过这个
# 也可以用下面的写法得到同样的结果
# roller.apply(lambda x:x.mean())
0 NaN
1 NaN
2 2.0
3 3.0
4 4.0
dtype: float64
- 对于滑动相关系数或滑动协方差的计算,可以如下写出:
s2 = pd.Series([1,2,6,16,30])
roller.cov(s2)
0 NaN
1 NaN
2 2.5
3 7.0
4 12.0
dtype: float64
- 滑窗函数:公共参数为 periods=n ,默认为1。可以为负,表示反方向的类似操作。
- shift:取向前第 n 个元素的值
- diff:与向前第 n 个元素做差
- pct_change:与向前第 n 个元素相比计算增长率
- 将其视作类滑窗函数的原因是,它们的功能可以用窗口大小为 n+1 的 rolling 方法等价代替:
s = pd.Series([1,3,6,10,15])
s.shift(2) # 等价于s.rolling(3).apply(lambda x:list(x)[0])
Out[105]:
0 NaN
1 NaN
2 1.0
3 3.0
4 6.0
dtype: float64
s.diff(3) # s.rolling(4).apply(lambda x:list(x)[-1]-list(x)[0])
Out[106]:
0 NaN
1 NaN
2 NaN
3 9.0
4 12.0
dtype: float64
s.pct_change() # s.rolling(2).apply(my_pct)
Out[107]:
0 NaN
1 2.000000
2 1.000000
3 0.666667
4 0.500000
dtype: float64
s.shift(-1)
Out[108]:
0 3.0
1 6.0
2 10.0
3 15.0
4 NaN
dtype: float64
2.4.2 扩张窗口
扩张窗口又称累计窗口,可以理解为一个动态长度的窗口,其窗口的大小就是从序列开始处到具体操作的对应位置,其使用的聚合函数会作用于这些逐步扩张的窗口上。具体地说,设序列为a1, a2, a3, a4,则其每个位置对应的窗口即[a1]、[a1, a2]、[a1, a2, a3]、[a1, a2, a3, a4]。
s = pd.Series([1, 3, 6, 10])
s.expanding().mean()
0 1.000000
1 2.000000
2 3.333333
3 5.000000
dtype: float64
2.5 练习
代码见kaggle nootbook《pandas》
2.5.1 Ex1:口袋妖怪数据集
现有一份口袋妖怪的数据集,下面进行一些背景说明:
df = pd.read_csv('data/pokemon.csv')
- # 代表全国图鉴编号,不同行存在相同数字则表示为该妖怪的不同状态
- 妖怪具有单属性和双属性两种,对于单属性的妖怪, Type 2 为缺失值
- Total, HP, Attack, Defense, Sp. Atk, Sp. Def, Speed 分别代表种族值、体力、物攻、防御、特攻、特防、速度,其中种族值为后6项之和
- 对
HP, Attack, Defense, Sp. Atk, Sp. Def, Speed进行加总,验证是否为 Total 值。
# 得到全为True的数据
columns=['HP','Attack','Defense','Sp. Atk','Sp. Def','Speed']
df.apply(lambda x : x['Total']==x[columns].sum(),axis=1)
(df[columns].sum(1)!=df['Total']).mean() # 参考答案
- 对于 # 重复的妖怪只保留第一条记录,解决以下问题:
- 求第一属性的种类数量和前三多数量对应的种类
- 求第一属性和第二属性的组合种类
- 求尚未出现过的属性组合
# 求第一属性的种类数量
df2['Type 1'].nunique() # 18
# 前三多数量对应的种类
# value_counts()默认降序排列,结果是一个series。
df2['Type 1'].value_counts()[:3].index # Index(['Water', 'Normal', 'Grass'], dtype='object')
# 求第一属性和第二属性的组合种类
df_2_type.drop_duplicates(['Type 1', 'Type 2']) # drop_duplicates函数得到第一属性和第二属性的组合种类,共143种
type1_all=df_2_type['Type 1'].unique() # type1所有种类,18种
type2_all=df_2_type['Type 2'].unique() # type2所有种类,19种
all_type=[(x,y) for x in type1_all for y in type2_all] # 所有的两种属性的组合
df_real=df_2_type.drop_duplicates(['Type 1', 'Type 2']) # 实际组合125种
real_type=[(x,y) for x ,y in zip(df_real['Type 1'],df_real['Type 2'])] # 实际有的143种组合
no_type=list(set(all_type) ^ set(real_type)) # 求两个列表的差集,199种
- 按照下述要求,构造
Series:- 取出物攻,超过120的替换为 high ,不足50的
替换为low ,否则设为 mid - 取出第一属性,分别用 replace 和 apply 替换所有字母为大写
- 求每个妖怪六项能力的离差,即所有能力中偏离中位数最大的值,添加到 df 并从大到小排序
- 取出物攻,超过120的替换为 high ,不足50的
df['Attack'].mask(df['Attack']>120,'high').mask(df['Attack']<50,'low').mask((50<=df['Attack'])&(df['Attack']<=120),'mid')
df['Type 1'].apply(lambda x: x.upper())
df['Type 1'].str.upper() # 向量化字符串,还有很多操作
columns=['HP','Attack','Defense','Sp. Atk','Sp. Def','Speed']
df['new']=df[columns].apply(lambda x: (x-x.quantile()).abs().max(),axis=1)
df.sort_values('new',ascending=False)
2.5.2 指数加权窗口
- 作为扩张窗口的 ewm 窗口
在扩张窗口中,用户可以使用各类函数进行历史的累计指标统计,但这些内置的统计函数往往把窗口中的所有元素赋予了同样的权重。事实上,可以给出不同的权重来赋给窗口中的元素,指数加权窗口就是这样一种特殊的扩张窗口。
其中,最重要的参数是alpha,它决定了默认情况下的窗口权重为
w
i
=
(
1
−
α
)
i
,
i
∈
{
0
,
1
,
.
.
.
,
t
}
w_i=(1−\alpha)^i,i\in\{0,1,...,t\}
wi=(1−α)i,i∈{0,1,...,t},其中
i
=
t
i=t
i=t表示当前元素,
i
=
0
i=0
i=0表示序列的第一个元素。
从权重公式可以看出,离开当前值越远则权重越小,若记原序列为
x
x
x,更新后的当前元素为
y
t
y_t
yt,此时通过加权公式归一化后可知:
y
t
=
∑
i
=
0
t
w
i
x
t
−
i
∑
i
=
0
t
w
i
=
x
t
+
(
1
−
α
)
x
t
−
1
+
(
1
−
α
)
2
x
t
−
2
+
.
.
.
+
(
1
−
α
)
t
x
0
1
+
(
1
−
α
)
+
(
1
−
α
)
2
+
.
.
.
+
(
1
−
α
)
t
\begin{split}y_t &=\frac{\sum_{i=0}^{t} w_i x_{t-i}}{\sum_{i=0}^{t} w_i} \\ &=\frac{x_t + (1 - \alpha)x_{t-1} + (1 - \alpha)^2 x_{t-2} + ...+ (1 - \alpha)^{t} x_{0}}{1 + (1 - \alpha) + (1 - \alpha)^2 + ...+ (1 - \alpha)^{t}}\\\end{split}
yt=∑i=0twi∑i=0twixt−i=1+(1−α)+(1−α)2+...+(1−α)txt+(1−α)xt−1+(1−α)2xt−2+...+(1−α)tx0
对于Series而言,可以用ewm对象如下计算指数平滑后的序列:
np.random.seed(0)
s = pd.Series(np.random.randint(-1,2,30).cumsum())
s.head()
Out[120]:
0 -1
1 -1
2 -2
3 -2
4 -2
dtype: int32
s.ewm(alpha=0.2).mean().head()
Out[121]:
0 -1.000000
1 -1.000000
2 -1.409836
3 -1.609756
4 -1.725845
dtype: float64
请用 expanding 窗口实现。
def ls_mean(x,a):
le=len(x)
mean_up=pd.Series([float( x[i]*(1-a)**(le-i)) for i in range(le)]).sum()
mean_down=pd.Series([float((1-a)**(le-i)) for i in range(le)]).sum()
return mean_up/mean_down
s.expanding().apply(lambda x : ls_mean(x,0.2))
参考答案:
def ewm_func(x, alpha=0.2):
win = (1-alpha)**np.arange(x.shape[0])[::-1]
res = (win*x).sum()/win.sum()
return res
s.expanding().apply(ewm_func).head()
Out[49]:
0 -1.000000
1 -1.000000
2 -1.409836
3 -1.609756
4 -1.725845
dtype: float64
- 作为滑动窗口的 ewm 窗口
从第1问中可以看到, ewm 作为一种扩张窗口的特例,只能从序列的第一个元素开始加权。现在希望给定一个限制窗口 n ,只对包含自身的最近的 n 个元素作为窗口进行滑动加权平滑。请根据滑窗函数,给出新的 与 的更新公式,并通过 rolling 窗口实现这一功能。
# 参考答案
s.rolling(window=4).apply(ewm_func).head() # 无需对原函数改动
Out[50]:
0 NaN
1 NaN
2 NaN
3 -1.609756
4 -1.826558
dtype: float64
第三章、索引
3.1 索引器
3.1.1 列索引&行索引
列索引:
- 通过 [列名] 可以从 DataFrame 中取出相应的列,返回值为 Series
- 如果要取出多个列,则可以通过 [列名组成的列表] ,其返回值为一个 DataFrame
df = pd.read_csv('data/learn_pandas.csv', usecols = ['School', 'Grade', 'Name', 'Gender','Weight', 'Transfer'])
df[['Gender', 'Name']].head()
字符串行索引:
- 单行索引:可以使用 [item]取出单个索引的对应元素
- 多行索引:使用 [items的列表]取出多个索引的对应元素
- 切片(端点索引不重复):如果想要取出某两个索引之间的元素,并且这两个索引是在整个索引中唯一出现,则可以使用切片,同时需要注意这里的切片会包含两个端点:
- 切片(端点索引重复):如果前后端点的值存在重复,即非唯一值,那么需要经过排序才能使用切片:
s = pd.Series([1, 2, 3, 4, 5, 6], index=['a', 'b', 'a', 'a', 'a', 'c'])
s['c': 'b': -2]
c 6
a 4
b 2
dtype: int64
s['c': 'b': -2]
c 6
a 4
b 2
dtype: int64
s.sort_index()['a': 'b']
a 1
a 3
a 4
a 5
b 2
dtype: int64
整数行索引:
- 使用 [int] 或 [int_list] ,则可以取出对应索引 元素 的值
- 如果使用整数切片,则会取出对应索引 位置 的值,注意这里的整数切片同 Python 中的切片一样不包含右端点:
s[1:-1:2]
3 b
2 d
dtype: object
3.1.2 loc索引器
loc 索引器的一般形式是 loc[*, ] ,其中第一个 * 代表行的选择,第二个 * 代表列的选择。 的位置一共有五类合法对象,分别是:单个元素、元素列表、元素切片、布尔列表以及函数,下面将依次说明。
- * 为单个元素
- * 为元素列表,此时,取出列表中所有元素值对应的行或列
- * 为切片:端点索引不管是字符串索引还是整数索引,都不能有重复,否则报错。切片时要从上往下切,反过来返回空。
df_demo = df.set_index('Name')
df_demo.loc[['Qiang Sun','Quan Zhao'], ['School','Gender']] # 取出多个行和列
df_demo.loc['Gaojuan You':'Gaoqiang Qian', 'School':'Gender'] # 字符串索引切片
df_loc_slice_demo = df_demo.copy()
df_loc_slice_demo.index = range(df_demo.shape[0],0,-1) # 重设索引为整数索引
df_loc_slice_demo.loc[5:3] # 整数索引切片。如果是.loc[3:5]反着切,返回为空
- * 为布尔列表,即条件筛选
- 条件来筛选行是极其常见的,此处传入 loc 的布尔列表与 DataFrame 长度相同,且列表为 True 的位置所对应的行会被选中, False 则会被剔除。
- 传入元素列表,也可以通过 isin 方法返回的布尔列表等价写出。
- 对于复合条件而言,可以用 |(或), &(且), ~(取反) 的组合来实现
select_dtypes函数相应类型的列。例如若要选出所有数值型的列,只需使用.select_dtypes('number')- 报错
Cannot perform 'ror_' with a dtyped [object] array and scalar of type [bool]:这是因为条件表达式没有加括号,涉及到运算优先级的问题。参考此帖。如果其中筛选列为数字,结果不会报错,但是结果明显有问题。因为数值类型是可以直接和bool类型数据进行运算,所以没有报错。
df_demo.loc[df_demo.Weight>70].head() # 选出体重超过70kg的学生
df_demo.loc[df_demo.Grade.isin(['Freshman', 'Senior'])].head() # 选出所有大一和大四的同学信息
# 选出多个值也可以这样写。中间两个条件的括号不能省,否则报错,涉及到运算符优先级的问题
df_demo.loc[(df_demo.Grade == 'Freshman') | (df_demo.Grade == 'Senior')].head()
# 选出复旦大学中体重超过70kg的大四学生,或者北大男生中体重超过80kg的非大四的学生
condition_1_1 = df_demo.School == 'Fudan University'
condition_1_2 = df_demo.Grade == 'Senior'
condition_1_3 = df_demo.Weight > 70
condition_1 = condition_1_1 & condition_1_2 & condition_1_3
condition_2_1 = df_demo.School == 'Peking University'
condition_2_2 = df_demo.Grade == 'Senior'
condition_2_3 = df_demo.Weight > 80
condition_2 = condition_2_1 & (~condition_2_2) & condition_2_3
df_demo.loc[condition_1 | condition_2]
School Grade Gender Weight Transfer
Name
Qiang Han Peking University Freshman Male 87.0 N
Chengpeng Zhou Fudan University Senior Male 81.0 N
Changpeng Zhao Peking University Freshman Male 83.0 N
Chengpeng Qian Fudan University Senior Male 73.0 Y
- * 为函数
函数返回值必须是前面的四种合法形式之一,并且函数的输入值为 DataFrame 本身。上述复合条件筛选的例子,可以把逻辑写入一个函数中再返回,需要注意的是函数的形式参数 x 本质上即为 df_demo :
def condition(x):
condition_1_1 = x.School == 'Fudan University'
condition_1_2 = x.Grade == 'Senior'
condition_1_3 = x.Weight > 70
condition_1 = condition_1_1 & condition_1_2 & condition_1_3
condition_2_1 = x.School == 'Peking University'
condition_2_2 = x.Grade == 'Senior'
condition_2_3 = x.Weight > 80
condition_2 = condition_2_1 & (~condition_2_2) & condition_2_3
result = condition_1 | condition_2
return result
df_demo.loc[condition]
School Grade Gender Weight Transfer
Name
Qiang Han Peking University Freshman Male 87.0 N
Chengpeng Zhou Fudan University Senior Male 81.0 N
Changpeng Zhao Peking University Freshman Male 83.0 N
Chengpeng Qian Fudan University Senior Male 73.0 Y
此外,还支持使用 lambda 表达式,由于函数无法返回如 start: end: step 的切片形式,故返回切片时要用 slice 对象进行包装:
# 下面二者返回结果一样
df_demo.loc[lambda x: slice('Gaojuan You', 'Gaoqiang Qian')]
df_demo.loc['Gaojuan You':'Gaoqiang Qian']
- 条件赋值:在对表或者序列赋值时,应当在使用一层索引器后直接进行赋值操作,这样做是由于进行多次索引后赋值是赋在临时返回的
copy副本上的,而没有真正 修改元素从而报出SettingWithCopyWarning警告。例如,下面给出的例子:
df_chain = pd.DataFrame([[0,0],[1,0],[-1,0]], columns=list('AB'))
df_chain
A B
0 0 0
1 1 0
2 -1 0
# 以下两种都会报错,报错提示Try using .loc[row_indexer,col_indexer]=value instead
df_chain[df_chain.A!=0].B = 1
df_chain.loc[df_chain.A!=0].B = 1
df_chain.loc[df_chain.A!=0,'B'] = 1 # 省掉.loc会报错
3.1.3 iloc索引器
loc 的使用与 loc 完全类似,只不过是针对位置进行筛选。在使用布尔列表的时候要特别注意,不能传入 Series 而必须传入序列的 values ,否则会报错。因此,在使用布尔筛选的时候还是应当优先考虑 loc 的方式。
# 注意,iloc后面接的中括号不是小括号
df_demo.iloc[[0, 1], [0, 1]] # 前两行前两列
df_demo.iloc[1: 4, 2:4] # 切片不包含结束端点
df_demo.iloc[(df_demo.Weight>80).values].head()
df_demo.School.iloc[1:5:2]
3.1.4 query方法(后续重点讲)
在 pandas 中,支持把字符串形式的查询表达式传入 query 方法来查询数据,其表达式的执行结果必须返回布尔列表。例如,将 loc 一节中的复合条件查询例子可以如下改写:
df.query('((School == "Fudan University")&'
' (Grade == "Senior")&'
' (Weight > 70))|'
'((School == "Peking University")&'
' (Grade != "Senior")&'
' (Weight > 80))')
- 在 query 表达式中,帮用户注册了所有来自 DataFrame 的列名,所有属于该 Series 的方法都可以被调用,和正常的函数调用并没有区别,例如查询体重超过均值的学生:
df.query('Weight > Weight.mean()').head()
对于含有空格的列名,需要使用
col name的方式进行引用。
- 在 query 中还注册了若干英语的字面用法,帮助提高可读性,例如: or, and, or, in, not in 。例如,筛选出男生中不是大一大二的学生:
df.query('(Grade not in ["Freshman", "Sophomore"]) and''(Gender == "Male")').head()
- 在字符串中出现与列表的比较时, == 和 != 分别表示元素出现在列表和没有出现在列表,等价于 in 和 not in,例如查询所有大三和大四的学生:
df.query('Grade == ["Junior", "Senior"]').head()
- query 中的字符串,如果要引用外部变量,只需在变量名前加 @ 符号。例如,取出体重位于70kg到80kg之间的学生:
low, high =70, 80
df.query('(Weight >= @low) & (Weight <= @high)').head()
3.1.5 随机抽样
如果把 DataFrame 的每一行看作一个样本,或把每一列看作一个特征,再把整个 DataFrame 看作总体,想要对样本或特征进行随机抽样就可以用 sample 函数。
sample 函数中的主要参数为 n, axis, frac, replace, weights ,前三个分别是指抽样数量、抽样的方向(0为行、1为列)和抽样比例(0.3则为从总体中抽出30%的样本)。
replace 和 weights 分别是指是否放回和每个样本的抽样相对概率,当 replace = True 则表示有放回抽样。例如,对下面构造的 df_sample 以 value 值的相对大小为抽样概率进行有放回抽样,抽样数量为3。
df_sample = pd.DataFrame({'id': list('abcde'), 'value': [1, 2, 3, 4, 90]})
df_sample.sample(3, replace = True, weights = df_sample.value)
id value
4 e 90
4 e 90
4 e 90
3.2 多级索引
3.2.1 多级索引结构
下面新构造一张表,更加清晰地说明具有多级索引的 DataFrame 结构。
df = pd.read_csv('../input/learn-pandas/learn_pandas.csv')
df = df[df.columns[:7]]
np.random.seed(0)
multi_index = pd.MultiIndex.from_product([list('ABCD'),
df.Gender.unique()], names=('School', 'Gender'))
multi_column = pd.MultiIndex.from_product([['Height', 'Weight'],
df.Grade.unique()], names=('Indicator', 'Grade'))
df_multi = pd.DataFrame(np.c_[(np.random.randn(8,4)*5 + 163).tolist(),
(np.random.randn(8,4)*5 + 65).tolist()],
index = multi_index,
columns = multi_column).round(1)
df_multi
Indicator Height Weight
Grade Freshman Senior Sophomore Junior Freshman Senior Sophomore Junior
School Gender
A Female 171.8 165.0 167.9 174.2 60.6 55.1 63.3 65.8
Male 172.3 158.1 167.8 162.2 71.2 71.0 63.1 63.5
B Female 162.5 165.1 163.7 170.3 59.8 57.9 56.5 74.8
Male 166.8 163.6 165.2 164.7 62.5 62.8 58.7 68.9
C Female 170.5 162.0 164.6 158.7 56.9 63.9 60.5 66.9
Male 150.2 166.3 167.3 159.3 62.4 59.1 64.9 67.1
D Female 174.3 155.7 163.2 162.1 65.3 66.5 61.8 63.2
Male 170.7 170.3 163.8 164.9 61.6 63.2 60.9 56.4
- 下图通过颜色区分,标记了 DataFrame 的结构。与单层索引的表一样,具备元素值、行索引和列索引三个部分。
- 这里的行索引和列索引都是 MultiIndex 类型,只不过 索引中的一个元素是元组 而不是单层索引中的标量。例如,行索引的第四个元素为 (“B”, “Male”) ,列索引的第二个元素为 (“Height”, “Senior”) ,
- 这里需要注意,外层连续出现相同的值时,第一次之后出现的会被隐藏显示,使结果的可读性增强。
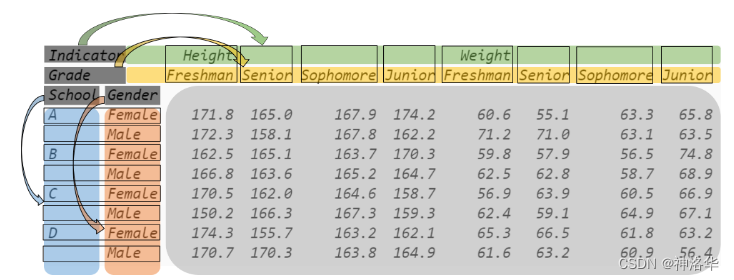
- MultiIndex 也具有名字和值属性,分别可以通过 names 和 values 获得。图中的 School 和 Gender 分别对应了表的第一层和第二层行索引的名字, Indicator 和 Grade 分别对应了第一层和第二层列索引的名字。
- 如果想要得到某一层的索引,则需要通过 get_level_values 获得
df_multi.index.names
Out[75]: FrozenList(['School', 'Gender'])
df_multi.columns.names
Out[76]: FrozenList(['Indicator', 'Grade'])
df_multi.index.values
Out[77]:
array([('A', 'Female'), ('A', 'Male'), ('B', 'Female'), ('B', 'Male'),
('C', 'Female'), ('C', 'Male'), ('D', 'Female'), ('D', 'Male')],
dtype=object)
df_multi.columns.values
Out[78]:
array([('Height', 'Freshman'), ('Height', 'Senior'),
('Height', 'Sophomore'), ('Height', 'Junior'),
('Weight', 'Freshman'), ('Weight', 'Senior'),
('Weight', 'Sophomore'), ('Weight', 'Junior')], dtype=object)
df_multi.index.get_level_values(0)
Out[79]: Index(['A', 'A', 'B', 'B', 'C', 'C', 'D', 'D'], dtype='object', name='School')
3.2.2 多级索引中的loc索引器
将原表学校和年级设为索引,此时的行为多级索引,列为单级索引。
- 多级索引
- 多级索引中的单个元素以元组为单位,因此之前在第一节介绍的 loc 和 iloc 方法完全可以照搬,只需把标量的位置替换成对应的元组。
- 传入元组列表或单个元组或返回前二者的函数时,需要先进行索引排序以避免性能警告
df_multi = df.set_index(['School', 'Grade'])
df_sorted = df_multi.sort_index()
df_sorted.loc[('Fudan University', 'Junior')].head()
df_sorted.loc[lambda x:('Fudan University','Junior')].head()
df_sorted.loc[df_sorted.Weight > 70].head() # 布尔列表也是可用的
- 索引切片
- 切片时,无论元组在索引中是否重复出现,都必须经过排序才能使用切片,否则报错
df_sorted.loc[('Fudan University', 'Senior'):].head() # 索引重复
df_unique = df.drop_duplicates(subset=['School','Grade']
).set_index(['School', 'Grade']) # 索引不重复
df_unique.sort_index().loc[('Fudan University', 'Senior'):].head() # 仍需要先排序
- 交叉索引
- 对多层的元素进行交叉组合后索引,需要指定 loc 的列。全选则用 : 表示。其中,每一层需要选中的元素用列表存放,传入 loc 的形式为 [(level_0_list, level_1_list), cols] 。
df_multi.loc[(['Peking University', 'Fudan University'],
['Sophomore', 'Junior']), :] # 所有北大和复旦的大二大三学生
df_multi.loc[[('Peking University', 'Junior'),
('Fudan University', 'Sophomore')]] # 没有指定列,表示的是选出北大的大三学生和复旦的大二学生
3.2.3 IndexSlice对象
- IndexSlice 对象可以对每层进行切片,而不只是对元组整体进行切片。还可以将切片和布尔列表混合使用。
- Slice 对象一共有两种形式,第一种为
loc[idx[*,*]]型,第二种为loc[idx[*,*],idx[*,*]]型。
下面将进行介绍。为了方便演示,下面构造一个 索引不重复的 DataFrame :
np.random.seed(0)
L1,L2 = ['A','B','C'],['a','b','c']
mul_index1 = pd.MultiIndex.from_product([L1,L2],names=('Upper', 'Lower'))
L3,L4 = ['D','E','F'],['d','e','f']
mul_index2 = pd.MultiIndex.from_product([L3,L4],names=('Big', 'Small'))
df_ex = pd.DataFrame(np.random.randint(-9,10,(9,9)),
index=mul_index1,
columns=mul_index2)
df_ex
Big D E F
Small d e f d e f d e f
Upper Lower
A a 3 6 -9 -6 -6 -2 0 9 -5
b -3 3 -8 -3 -2 5 8 -4 4
c -1 0 7 -4 6 6 -9 9 -6
B a 8 5 -2 -9 -8 0 -9 1 -6
b 2 9 -7 -9 -9 -5 -4 -3 -1
c 8 6 -5 0 1 -8 -8 -2 0
C a -6 -3 2 5 9 -9 5 -6 3
b 1 2 -5 -3 -5 6 -6 3 -5
c -1 5 6 -6 6 4 7 8 -4
使用 silce 对象,先要进行定义:idx = pd.IndexSlice
loc[idx[*,*]]型:- 此时并不能进行多层分别切片,前一个 * 表示行的选择,后一个 * 表示列的选择,与单纯的 loc 是类似的。
- 也支持布尔序列的索引
df_ex.loc[idx['C':, ('D', 'f'):]]
Big D E F
Small f d e f d e f
Upper Lower
C a 2 5 9 -9 5 -6 3
b -5 -3 -5 6 -6 3 -5
c 6 -6 6 4 7 8 -4
df_ex.loc[idx[:'A', lambda x:x.sum()>0]] # 列和大于0 。这里没看懂
Big D F
Small d e e
Upper Lower
A a 3 6 9
b -3 3 -4
c -1 0 9
loc[idx[*,*],idx[*,*]]型:能够分层进行切片,前一个 idx 指代的是行索引,后一个是列索引。需要注意的是,此时不支持使用函数。
df_ex.loc[idx[:'A', 'b':], idx['E':, 'e':]] # A行范围里面的b行之后,EF列的e列之后
Big E F
Small e f e f
Upper Lower
A b -2 5 -4 4
c 6 6 9 -6
3.2.4 多级索引的构造
除了使用 set_index 之外,如何自己构造多级索引呢?常用的有 from_tuples, from_arrays, from_product 三种方法,它们都是 pd.MultiIndex 对象下的函数。
- from_tuples 指根据传入由元组组成的列表进行构造
- from_arrays 指根据传入列表中,对应层的列表进行构造
- from_product 指根据给定多个列表的笛卡尔积进行构造
以下三种写法结果都是一样的:
my_tuple = [('a','cat'),('a','dog'),('b','cat'),('b','dog')]
pd.MultiIndex.from_tuples(my_tuple, names=['First','Second'])
my_array = [['a', 'a', 'b', 'b'], ['cat','dog']*2]
pd.MultiIndex.from_arrays(my_array, names=['First','Second'])
pd.MultiIndex.from_product([['a', 'b'],['cat','dog']],
names=['First','Second'])
MultiIndex([('a', 'cat'),
('a', 'dog'),
('b', 'cat'),
('b', 'dog')],
names=['First', 'Second'])
3.3 索引的常用方法
3.3.1 索引层的交换和删除
为了方便理解交换的过程,这里构造一个三级索引的例子:
np.random.seed(0)
L1,L2,L3 = ['A','B'],['a','b'],['alpha','beta']
mul_index1 = pd.MultiIndex.from_product([L1,L2,L3],names=('Upper', 'Lower','Extra'))
L4,L5,L6 = ['C','D'],['c','d'],['cat','dog']
mul_index2 = pd.MultiIndex.from_product([L4,L5,L6],names=('Big', 'Small', 'Other'))
df_ex = pd.DataFrame(np.random.randint(-9,10,(8,8)),
index=mul_index1,
columns=mul_index2)
df_ex
Out[129]:
Big C D
Small c d c d
Other cat dog cat dog cat dog cat dog
Upper Lower Extra
A a alpha 3 6 -9 -6 -6 -2 0 9
beta -5 -3 3 -8 -3 -2 5 8
b alpha -4 4 -1 0 7 -4 6 6
beta -9 9 -6 8 5 -2 -9 -8
B a alpha 0 -9 1 -6 2 9 -7 -9
beta -9 -5 -4 -3 -1 8 6 -5
b alpha 0 1 -8 -8 -2 0 -6 -3
beta 2 5 9 -9 5 -6 3 1
- 索引交换:
swaplevel和reorder_levels都可以完成。前者只能交换两个层,而后者可以交换任意层。两者都可以指定交换的是轴是哪一个。
这里只涉及行或列索引内部的交换,不同方向索引之间的交换将在第五章中被讨论
df_ex.swaplevel(0,2,axis=1).head() # 列索引的第一层和第三层交换,结果这里就不写了
df_ex.reorder_levels([2,0,1],axis=0)# 列表数字指代原来索引中的层
Out[131]:
Big C D
Small c d c d
Other cat dog cat dog cat dog cat dog
Extra Upper Lower
alpha A a 3 6 -9 -6 -6 -2 0 9
beta A a -5 -3 3 -8 -3 -2 5 8
alpha A b -4 4 -1 0 7 -4 6 6
beta A b -9 9 -6 8 5 -2 -9 -8
alpha B a 0 -9 1 -6 2 9 -7 -9
- 索引删除:可以使用
droplevel方法
df_ex.droplevel(1,axis=1) # 删除列索引的第二级索引
Out[132]:
Big C D
Other cat dog cat dog cat dog cat dog
Upper Lower Extra
A a alpha 3 6 -9 -6 -6 -2 0 9
beta -5 -3 3 -8 -3 -2 5 8
b alpha -4 4 -1 0 7 -4 6 6
beta -9 9 -6 8 5 -2 -9 -8
B a alpha 0 -9 1 -6 2 9 -7 -9
beta -9 -5 -4 -3 -1 8 6 -5
b alpha 0 1 -8 -8 -2 0 -6 -3
beta 2 5 9 -9 5 -6 3 1
3.3.2 索引属性的修改
a. 修改某一层的索引
- 修改索引名:通过
rename_axis可以对索引层的名字进行修改,常用的修改方式是传入字典的映射:
# 行索引'Upper'改为'Changed_row',列索引'Other'改为'Changed_Col'。
df_ex.rename_axis(index={'Upper':'Changed_row'},
columns={'Other':'Changed_Col'}).head()
Out[134]:
Big C D
Small c d c d
Changed_Col cat dog cat dog cat dog cat dog
Changed_row Lower Extra
A a alpha 3 6 -9 -6 -6 -2 0 9
beta -5 -3 3 -8 -3 -2 5 8
b alpha -4 4 -1 0 7 -4 6 6
beta -9 9 -6 8 5 -2 -9 -8
B a alpha 0 -9 1 -6 2 9 -7 -9
- 修改索引值:通过 rename 可以对索引的值进行修改,如果是多级索引需要指定修改的层号 level :
df_ex.rename(columns={'cat':'not_cat'},level=2).head(3)
Big C D
Small c d c d
Other not_cat dog not_cat dog not_cat dog not_cat dog
Upper Lower Extra
A a alpha 3 6 -9 -6 -6 -2 0 9
beta -5 -3 3 -8 -3 -2 5 8
b alpha -4 4 -1 0 7 -4 6 6
- 传入参数也可以是函数,其输入值就是索引元素:
df_ex.rename(index=lambda x:str.upper(x),level=2).head(3)
Big C D
Small c d c d
Other cat dog cat dog cat dog cat dog
Upper Lower Extra
A a ALPHA 3 6 -9 -6 -6 -2 0 9
BETA -5 -3 3 -8 -3 -2 5 8
b ALPHA -4 4 -1 0 7 -4 6 6
练一练:尝试在 rename_axis 中使用函数完成与例子中一样的功能,即把 Upper 和 Other 分别替换为 Changed_row 和 Changed_col。
df_ex.rename_axis(index=lambda x:x.replace('Upper','Changed_row'),
columns=lambda x:x.replace('Other','Changed_col')).head()
- 对于整个索引的元素替换,可以利用迭代器实现
new_values = iter(list('abcdefgh'))
df_ex.rename(index=lambda x:next(new_values),level=2)
Out[138]:
Big C D
Small c d c d
Other cat dog cat dog cat dog cat dog
Upper Lower Extra
A a a 3 6 -9 -6 -6 -2 0 9
b -5 -3 3 -8 -3 -2 5 8
b c -4 4 -1 0 7 -4 6 6
d -9 9 -6 8 5 -2 -9 -8
B a e 0 -9 1 -6 2 9 -7 -9
f -9 -5 -4 -3 -1 8 6 -5
b g 0 1 -8 -8 -2 0 -6 -3
h 2 5 9 -9 5 -6 3 1
b. 多级索引中修改某一位置的索引
- 若想要对某个位置的索引元素进行修改,在单层索引时容易实现,即先取出索引的 values 属性,再给对得到的列表进行修改,最后再对 index 对象重新赋值。比如:
df = pd.read_csv('../input/learn-pandas/learn_pandas.csv')
df = df[df.columns[:7]]
idx=df.index.values
idx[0]=300
df.index=idx
df.head()
School Grade Name Gender Height Weight Transfer
300 A Freshman Gaopeng Yang Female 158.9 46.0 N
1 B Freshman Changqiang You Male 166.5 70.0 N
2 A Senior Mei Sun Male 188.9 89.0 N
3 C Sophomore Xiaojuan Sun Female NaN 41.0 N
4 C Sophomore Gaojuan You Male 174.0 74.0 N
- 但是如果是多级索引的话就有些麻烦,一个解决的方案是先把某一层索引临时转为表的元素,然后再进行修改,最后重新设定为索引(下节将介绍这些操作)。
c. map函数:多级索引的压缩和解压
map函数是定义在 Index 上的方法,与前面 rename 方法中层的函数式用法是类似的,只不过它传入的不是层的标量值,而是直接传入索引的元组例如,可以等价地写出上面的字符串转大写的操作:
df_temp = df_ex.copy()
new_idx = df_temp.index.map(lambda x: (x[0],
x[1],
str.upper(x[2])))
df_temp.index = new_idx
df_temp.head()
Out[142]:
Big C D
Small c d c d
Other cat dog cat dog cat dog cat dog
Upper Lower Extra
A a ALPHA 3 6 -9 -6 -6 -2 0 9
BETA -5 -3 3 -8 -3 -2 5 8
b ALPHA -4 4 -1 0 7 -4 6 6
BETA -9 9 -6 8 5 -2 -9 -8
B a ALPHA 0 -9 1 -6 2 9 -7 -9
关于 map 的另一个使用方法是对多级索引的压缩:
df_temp = df_ex.copy()
new_idx = df_temp.index.map(lambda x: (x[0]+'-'+
x[1]+'-'+
x[2]))
df_temp.index = new_idx
df_temp.head() # 单层索引
Out[146]:
Big C D
Small c d c d
Other cat dog cat dog cat dog cat dog
A-a-alpha 3 6 -9 -6 -6 -2 0 9
A-a-beta -5 -3 3 -8 -3 -2 5 8
A-b-alpha -4 4 -1 0 7 -4 6 6
A-b-beta -9 9 -6 8 5 -2 -9 -8
B-a-alpha 0 -9 1 -6 2 9 -7 -9
同时,也可以反向地展开:
new_idx = df_temp.index.map(lambda x:tuple(x.split('-')))
df_temp.index = new_idx
df_temp.head() # 三层索引,和原来解压前是一样的
3.3.3 索引的设置与重置
为了说明本节的函数,下面构造一个新表:
df_new = pd.DataFrame({'A':list('aacd'),
'B':list('PQRT'),
'C':[1,2,3,4]})
df_new
Out[151]:
A B C
0 a P 1
1 a Q 2
2 c R 3
3 d T 4
- 索引的设置:可以使用
set_index完成,这里的主要参数是append ,表示是否来保留原来的索引,直接把新设定的添加到原索引的内层:
df_new.set_index('A', append=True)
# 可以同时指定多个列作为索引:
df_new.set_index(['A', 'B'])
如果想要添加索引的列没有出现在其中,那么可以直接在参数中传入相应的 Series :
my_index = pd.Series(list('WXYZ'), name='D')
df_new = df_new.set_index(['A', my_index])
df_new
Out[157]:
B C
A D
a W P 1
X Q 2
c Y R 3
d Z T 4
- 重置索引:
reset_index是set_index的逆函数,其主要参数是 drop ,表示是否要把去掉的索引层丢弃,而不是添加到列中:
df_new.reset_index(['D'])
Out[158]:
D B C
A
a W P 1
a X Q 2
c Y R 3
d Z T 4
df_new.reset_index(['D'], drop=True)
Out[159]:
B C
A
a P 1
a Q 2
c R 3
d T 4
如果重置了所有的索引,那么 pandas 会直接重新生成一个默认索引:
df_new.reset_index()
Out[160]:
A D B C
0 a W P 1
1 a X Q 2
2 c Y R 3
3 d Z T 4
3.3.4 索引的变形
- 在某些场合下,需要对索引做一些扩充或者剔除,更具体地要求是给定一个新的索引,把原表中相应的索引对应元素填充到新索引构成的表中。
- 例如,下面的表中给出了员工信息,需要重新制作一张新的表,要求增加一名员工的同时去掉身高列并增加性别列:
df_reindex = pd.DataFrame({"Weight":[60,70,80],
"Height":[176,180,179]},
index=['1001','1003','1002'])
df_reindex
Out[162]:
Weight Height
1001 60 176
1003 70 180
1002 80 179
df_reindex.reindex(index=['1001','1002','1003','1004'],
columns=['Weight','Gender'])
Out[163]:
Weight Gender
1001 60.0 NaN
1002 80.0 NaN
1003 70.0 NaN
1004 NaN NaN
还有一个与 reindex 功能类似的函数是 reindex_like ,其功能是仿照传入的表索引来进行被调用表索引的变形。例如,现在已经存在一张表具备了目标索引的条件,那么上述功能可采用下述代码得到:
df_existed = pd.DataFrame(index=['1001','1002','1003','1004'],
columns=['Weight','Gender'])
df_reindex.reindex_like(df_existed)
Out[165]:
Weight Gender
1001 60.0 NaN
1002 80.0 NaN
1003 70.0 NaN
1004 NaN NaN
3.4 索引运算
3.4.1 集合的运算法则
- 经常会有一种利用集合运算来取出符合条件行的需求,例如有两张表 A 和 B ,它们的索引都是员工编号,现在需要筛选出两表索引交集的所有员工信息,此时通过 Index 上的运算操作就很容易实现。
- 在此之前,不妨先复习一下常见的四种集合运算:

3.4.2 一般的索引运算
由于集合的元素是互异的,但是索引中可能有相同的元素,先用 unique 去重后再进行运算。下面构造两张最为简单的示例表进行演示:
In [151]: df_set_1 = pd.DataFrame([[0,1],[1,2],[3,4]],
.....: index = pd.Index(['a','b','a'],name='id1'))
.....:
In [152]: df_set_2 = pd.DataFrame([[4,5],[2,6],[7,1]],
.....: index = pd.Index(['b','b','c'],name='id2'))
.....:
In [153]: id1, id2 = df_set_1.index.unique(), df_set_2.index.unique()
In [154]: id1.intersection(id2)
Out[154]: Index(['b'], dtype='object')
In [155]: id1.union(id2)
Out[155]: Index(['a', 'b', 'c'], dtype='object')
In [156]: id1.difference(id2)
Out[156]: Index(['a'], dtype='object')
In [157]: id1.symmetric_difference(id2)
Out[157]: Index(['a', 'c'], dtype='object')
上述的四类运算还可以用等价的符号表示代替如下:
In [158]: id1 & id2
Out[158]: Index(['b'], dtype='object')
In [159]: id1 | id2
Out[159]: Index(['a', 'b', 'c'], dtype='object')
In [160]: (id1 ^ id2) & id1
Out[160]: Index(['a'], dtype='object')
In [161]: id1 ^ id2 # ^ 符号即对称差
Out[161]: Index(['a', 'c'], dtype='object')
若两张表需要做集合运算的列并没有被设置索引,一种办法是先转成索引,运算后再恢复,另一种方法是利用 isin 函数,例如在重置索引的第一张表中选出 id 列交集的所在行:
In [162]: df_set_in_col_1 = df_set_1.reset_index()
In [163]: df_set_in_col_2 = df_set_2.reset_index()
In [164]: df_set_in_col_1
Out[164]:
id1 0 1
0 a 0 1
1 b 1 2
2 a 3 4
In [165]: df_set_in_col_2
Out[165]:
id2 0 1
0 b 4 5
1 b 2 6
2 c 7 1
In [166]: df_set_in_col_1[df_set_in_col_1.id1.isin(df_set_in_col_2.id2)]
Out[166]:
id1 0 1
1 b 1 2
3.5 高性能Pandas: eval() 与 query()
本节参考《python数据科学手册》一书。
Python 数据科学生态环境的强大力量建立在 NumPy 与 Pandas 的基础之上,并通过直观的语法将基本操作转换成 C 语言:在 NumPy 里是向量化 / 广播运算,在 Pandas 里是分组型的运算。虽然这些抽象功能可以简洁高效地解决许多问题,但是它们经常需要创建临时中间对象,这样就会占用大量的计算时间与内存。
Pandas 从 0.13 版开始(2014 年 1 月)就引入了实验性工具,让用户可以直接运行 C 语言速度的操作,不需要十分费力地配置中间数组。它们就是 eval() 和 query() 函数 ,都依赖于 Numexpr (https://github.com/pydata/numexpr) 程序包。
3.5.1 query() 与 eval() 的设计动机:复合代数式
前面已经介绍过,NumPy 与 Pandas 都支持快速的向量化运算。例如,你可以对下面两个数组进行求和:
In[1]: import numpy as np
rng = np.random.RandomState(42)
x = rng.rand(1E6)
y = rng.rand(1E6)
%timeit x + y
100 loops, best of 3: 3.39 ms per loop
这样做比普通的 Python 循环或列表综合要快很多:
In[2]:
%timeit np.fromiter((xi + yi for xi, yi in zip(x, y)),dtype=x.dtype, count=len(x))
1 loop, best of 3: 266 ms per loop
但是这种运算在处理复合代数式(compound expression)问题时的效率比较低,例如下面的表达式:
In[3]: mask = (x > 0.5) & (y < 0.5)
由于 NumPy 会计算每一个代数子式,因此这个计算过程等价于:
In[4]: tmp1 = (x > 0.5)
tmp2 = (y < 0.5)
mask = tmp1 & tmp2
也就是说,每段中间过程都需要显式地分配内存。如果 x 数组和 y 数组非常大,这么运算就会占用大量的时间和内存消耗。Numexpr 程序库可以让你在不为中间过程分配全部内存的前提下,完成元素到元素的复合代数式运算。虽然 Numexpr 文档(https://github.com/pydata/numexpr)里提供了更详细的内容,但是简单点儿说,这个程序库其实就是用一个NumPy 风格的字符串代数式进行运算:
In[5]: import numexpr
mask_numexpr = numexpr.evaluate('(x > 0.5) & (y < 0.5)')
np.allclose(mask, mask_numexpr)
Out[5]: True
这么做的好处是,由于 Numexpr 在计算代数式时不需要为临时数组分配全部内存,因此计算比 NumPy 更高效,尤其适合处理大型数组。马上要介绍的 Pandas 的 eval() 和 query()工具其实也是基于 Numexpr 实现的。
3.5.2 用 pandas.eval() 实现高性能运算
Pandas 的 eval() 函数用字符串代数式实现了 DataFrame 的高性能运算,例如下面的DataFrame :
In[6]: import pandas as pd
nrows, ncols = 100000, 100
rng = np.random.RandomState(42)
df1, df2, df3, df4 = (pd.DataFrame(rng.rand(nrows, ncols))
for i in range(4))
如果要用普通的 Pandas 方法计算四个 DataFrame 的和,可以这么写:
In[7]: %timeit df1 + df2 + df3 + df4
10 loops, best of 3: 87.1 ms per loop
也可以通过 pd.eval 和字符串代数式计算并得出相同的结果:
In[8]: %timeit pd.eval('df1 + df2 + df3 + df4')
10 loops, best of 3: 42.2 ms per loop
这个 eval() 版本的代数式比普通方法快一倍(而且内存消耗更少),结果也是一样的:
# np.allclose:判断两个向量是否相近
In[9]: np.allclose(df1 + df2 + df3 + df4,
pd.eval('df1 + df2 + df3 + df4'))
Out[9]: True
pd.eval() 支持的运算
从 Pandas v0.16 版开始, pd.eval() 就支持许多运算了。为了演示这些运算,创建一个整数类型的 DataFrame :
In[10]: df1, df2, df3, df4, df5 = (pd.DataFrame(rng.randint(0, 1000, (100, 3)))
for i in range(5))
- 算术运算符。 pd.eval() 支持所有的算术运算符,例如:
In[11]: result1 = -df1 * df2 / (df3 + df4) - df5
result2 = pd.eval('-df1 * df2 / (df3 + df4) - df5')
np.allclose(result1, result2)
Out[11]: True
- 比较运算符。 pd.eval() 支持所有的比较运算符,包括链式代数式(chained expression):
In[12]: result1 = (df1 < df2) & (df2 <= df3) & (df3 != df4)
result2 = pd.eval('df1 < df2 <= df3 != df4')
np.allclose(result1, result2)
Out[12]: True
- 位运算符。 pd.eval() 支持 & (与)和 | (或)等位运算符:
In[13]: result1 = (df1 < 0.5) & (df2 < 0.5) | (df3 < df4)
result2 = pd.eval('(df1 < 0.5) & (df2 < 0.5) | (df3 < df4)')
np.allclose(result1, result2)
Out[13]: True
另外,你还可以在布尔类型的代数式中使用 and 和 or 等字面值:
In[14]: result3 = pd.eval('(df1 < 0.5) and (df2 < 0.5) or (df3 < df4)')
np.allclose(result1, result3)
Out[14]: True
4. 对象属性与索引。 pd.eval() 可以通过 obj.attr 语法获取对象属性,通过 obj[index] 语法获取对象索引:
In[15]: result1 = df2.T[0] + df3.iloc[1]
result2 = pd.eval('df2.T[0] + df3.iloc[1]')
np.allclose(result1, result2)
Out[15]: True
- 其他运算
3.5.3 用 DataFrame.eval() 实现列间运算
由于 pd.eval() 是 Pandas 的顶层函数,因此 DataFrame 有一个 eval() 方法可以做类似的运算。使用 eval() 方法的好处是可以借助列名称进行运算,示例如下:
In[16]: df = pd.DataFrame(rng.rand(1000, 3), columns=['A', 'B', 'C'])
df.head()
Out[16]: A B C
0 0.375506 0.406939 0.069938
1 0.069087 0.235615 0.154374
2 0.677945 0.433839 0.652324
3 0.264038 0.808055 0.347197
4 0.589161 0.252418 0.557789
如果用前面介绍的 pd.eval() ,就可以通过下面的代数式计算这三列:
In[17]: result1 = (df['A'] + df['B']) / (df['C'] - 1)
result2 = pd.eval("(df.A + df.B) / (df.C - 1)")
np.allclose(result1, result2)
Out[17]: True
而 DataFrame.eval() 方法可以通过列名称实现简洁的代数式:
In[18]: result3 = df.eval('(A + B) / (C - 1)')
np.allclose(result1, result3)
Out[18]: True
请注意,这里用列名称作为变量来计算代数式,结果同样是正确的。
- 用 DataFrame.eval() 新增列
除了前面介绍的运算功能, DataFrame.eval() 还可以创建新的列。还用前面的 DataFrame
来演示,列名是 ’ A ’ 、 ’ B ’ 和 ’ C ’ :
In[19]: df.head()
Out[19]: A B C
0 0.375506 0.406939 0.069938
1 0.069087 0.235615 0.154374
2 0.677945 0.433839 0.652324
3 0.264038 0.808055 0.347197
4 0.589161 0.252418 0.557789
可以用 df.eval() 创建一个新的列 ’ D ’ ,然后赋给它其他列计算的值:
In[20]: df.eval('D = (A + B) / C', inplace=True)
df.head()
Out[20]: A B C D
0 0.375506 0.406939 0.069938 11.187620
1 0.069087 0.235615 0.154374 1.973796
2 0.677945 0.433839 0.652324 1.704344
3 0.264038 0.808055 0.347197 3.087857
4 0.589161 0.252418 0.557789 1.508776
- 修改已有的列:
In[21]: df.eval('D = (A - B) / C', inplace=True)
df.head()
Out[21]: A B C D
0 0.375506 0.406939 0.069938 -0.449425
1 0.069087 0.235615 0.154374 -1.078728
2 0.677945 0.433839 0.652324 0.374209
3 0.264038 0.808055 0.347197 -1.566886
4 0.589161 0.252418 0.557789 0.603708
- DataFrame.eval() 使用局部变量
DataFrame.eval() 方法还支持通过 @ 符号使用 Python 的局部变量,如下所示:
In[22]: column_mean = df.mean(1)
result1 = df['A'] + column_mean
result2 = df.eval('A + @column_mean')
np.allclose(result1, result2)
Out[22]: True
@ 符号表示“这是一个变量名称而不是一个列名称”,从而让你灵活地用两个“命名空间”的资源(列名称的命名空间和 Python 对象的命名空间)计算代数式。需要注意的是, @ 符号只能在 DataFrame.eval() 方法中使用,而不能在 pandas.eval() 函数中使用,因为 pandas.eval() 函数只能获取一个(Python)命名空间的内容。(pd.eval()是计算多个pd对象,而pd. DataFrame是计算一个对象。一个对象可以使用列名空间和python空间)
3.5.4 DataFrame.query() 方法
DataFrame 基于字符串代数式的运算实现了另一个方法,被称为 query() ,例如:
#DataFrame.eval()的列间运算只能得到一个列,而这里是过滤得到整个数据集(全部列)的结果
In[23]: result1 = df[(df.A < 0.5) & (df.B < 0.5)]
result2 = pd.eval('df[(df.A < 0.5) & (df.B < 0.5)]')
np.allclose(result1, result2)
Out[23]: True
和前面介绍过的 DataFrame.eval() 一样,这是一个用 DataFrame 列创建的代数式,但是不能用 DataFrame.eval() 语法不过,对于这种过滤运算,你可以用query() 方法:
In[24]: result2 = df.query('A < 0.5 and B < 0.5')
np.allclose(result1, result2)
Out[24]: True
除了计算性能更优之外,这种方法的语法也比掩码代数式语法更好理解。需要注意的是,query() 方法也支持用 @ 符号引用局部变量:
# eval不行就用query
In[25]: Cmean = df['C'].mean()
result1 = df[(df.A < Cmean) & (df.B < Cmean)]
result2 = df.query('A < @Cmean and B < @Cmean')
np.allclose(result1, result2)
Out[25]: True
3.5.5 性能决定使用时机
在考虑要不要用这两个函数时,需要思考两个方面:计算时间和内存消耗,而内存消耗是更重要的影响因素。就像前面介绍的那样,每个涉及 NumPy 数组或 Pandas 的 DataFrame的复合代数式都会产生临时数组,例如:
In[26]: x = df[(df.A < 0.5) & (df.B < 0.5)]
它基本等价于:
In[27]: tmp1 = df.A < 0.5
tmp2 = df.B < 0.5
tmp3 = tmp1 & tmp2
x = df[tmp3]
如果临时 DataFrame 的内存需求比你的系统内存还大(通常是几吉字节),那么最好还是使用 eval() 和 query() 代数式。你可以通过下面的方法大概估算一下变量的内存消耗:
In[28]: df.values.nbytes
Out[28]: 32000
在性能方面,即使你没有使用最大的系统内存, eval() 的计算速度也比普通方法快。现在的性能瓶颈变成了临时 DataFrame 与系统 CPU 的 L1 和 L2 缓存(在 2016 年依然是几兆字节)之间的对比了——如果系统缓存足够大,那么 eval() 就可以避免在不同缓存间缓慢地移动临时文件。
在实际工作中,我发现普通的计算方法与 eval / query 计算方法在计算时间上的差异并非总是那么明显,普通方法在处理较小的数组时反而速度更快! eval / query 方法的优点主要是节省内存,有时语法也更加简洁。
我们已经介绍了 eval() 与 query() 的绝大多数细节,若想了解更多的信息,请参考 Pandas文档。尤其需要注意的是,可以通过设置不同的解析器和引擎来执行这些查询,相关细节请 参 考 Pandas 文 档 中“Enhancing Performance”(http://pandas.pydata.org/pandas-docs/dev/enhancingperf.html)节。
3.6 练习
Ex1:公司员工数据集
现有一份公司员工数据集:
df = pd.read_csv('../data/company.csv')
df.head(3)
EmployeeID birthdate_key age city_name department job_title gender
0 1318 1/3/1954 61 Vancouver Executive CEO M
1 1319 1/3/1957 58 Vancouver Executive VP Stores F
2 1320 1/2/1955 60 Vancouver Executive Legal Counsel F
- 分别只使用
query和loc选出年龄不超过四十岁且工作部门为Dairy或Bakery的男性。 - 选出员工
ID号 为奇数所在行的第1、第3和倒数第2列。 - 按照以下步骤进行索引操作:
- 把后三列设为索引后交换内外两层
- 恢复中间层索引
- 修改外层索引名为
Gender - 用下划线合并两层行索引
- 把行索引拆分为原状态
- 修改索引名为原表名称
- 恢复默认索引并将列保持为原表的相对位置
import numpy as np
import pandas as pd
- 选出年龄不超过四十岁且工作部门为 Dairy 或 Bakery 的男性。
#df.loc[(df.age<=40)&(df.department.isin (['Dairy','Bakery']))&(df.gender=='M')]
df.query('(age<=40)&'
'(department==["Dairy","Bakery"])&'
'(gender=="M")')
- 选出员工 ID 号 为奇数所在行的第1、第3和倒数第2列。
#df.iloc[(df.EmployeeID % 2==1).values].iloc[:,[1,3,-2]]
#df.loc[(df.EmployeeID % 2==1)].iloc[:,[1,3,-2]]
df.query('(EmployeeID % 2==1)').iloc[:,[1,3,-2]]
- 索引操作:
#df.set_index(['department','job_title','gender']).swaplevel(0,2,axis=0) # 把后三列设为索引后交换内外两层
# 恢复中间层索引
df2=df.set_index(['department','job_title','gender']).swaplevel(0,2,axis=0).reset_index(['job_title'])
df2.rename_axis(index={"gender":"Gender"}) # 修改外层索引名为 Gender
new_idx = df2.index.map(lambda x: (x[0]+'_'+x[1]))
df2.index = new_idx # 用下划线合并两层行索引
new_idx2 = df2.index.map(lambda x:tuple(x.split('_')))
df2.index = new_idx2 # 把行索引拆分为原状态
#df2.index.names=['gender','department'] # 修改索引名为原表名称
df2 = df2.rename_axis(index=['gender', 'department']) # 修改索引名为原表名称,参考答案写法
df2=df2.reset_index() # 恢复默认索引
df2=df2[df.columns] # 保持为原表的相对位置
"""
参考答案
df2 = df2.reset_index().reindex(df.columns, axis=1)
"""
df2
Ex2:巧克力数据集
现有一份关于巧克力评价的数据集:
df = pd.read_csv('../data/chocolate.csv')
df.head(3)
Company Review\r\nDate Cocoa\r\nPercent Company\r\nLocation Rating
0 A. Morin 2016 63% France 3.75
1 A. Morin 2015 70% France 2.75
2 A. Morin 2015 70% France 3.00
- 把列索引名中的
\n替换为空格。 - 巧克力
Rating评分为1至5,每0.25分一档,请选出2.75分及以下且可可含量Cocoa Percent高于中位数的样本。 - 将
Review Date和Company Location设为索引后,选出Review Date在2012年之后且Company Location不属于France, Canada, Amsterdam, Belgium的样本。
# 把列索引名中的 \n 替换为空格
"""
col=list(df.columns)
col=[x.replace('\n',' ') for x in col]
df.columns=col
"""
df.columns = [' '.join(i.split('\n')) for i in df.columns] # 参考答案

# Cocoa Percent 要转为数字类型,坑死我了
df['Cocoa Percent']=df['Cocoa Percent'].apply(lambda x: round(float(x.strip("%"))/100,2))
# Cocoa Percent有空格,要加反引号
#df.loc[(df.Rating<=2.75)&(df['Cocoa Percent']>df['Cocoa Percent'].median())]
df.query('(Rating<=2.75)&(`Cocoa Percent`>`Cocoa Percent`.median())')
- 将 Review Date 和 Company Location 设为索引后,选出 Review Date 在2012年之后且 Company Location 不属于 France, Canada, Amsterdam, Belgium 的样本
这个明显是分层索引切片。构建idx = pd.IndexSlice后可以使用
loc[idx[*,*],idx[*,*]]型进行分成切片。只是此时不能使用lambda函数。
ls=[x for x in df['Company Location'].unique()]
s=set(ls)^set(['France','Canada', 'Amsterdam','Belgium'])
ls=[x for x in s]
df_sort=df.set_index(['Review Date','Company Location']).sort_index()
idx = pd.IndexSlice
df_sort.loc[idx[2012:,ls],idx[:]]
# 参考答案
idx = pd.IndexSlice
exclude = ['France', 'Canada', 'Amsterdam', 'Belgium']
res = df.set_index(['Review Date', 'Company Location']).sort_index(level=0)
res.loc[idx[2012:,~res.index.get_level_values(1).isin(exclude)],:].head(3)
四、分组
分组一般使用groupby函数完成,有三大操作:聚合、变换和过滤。
- 内置聚合函数和.agg()方法,每组返回的是一个 标量
- transform变换函数,每组返回的是一个 Series 类型
- filter 函数进行过滤,返回整个组所在行的本身,即返回了 DataFrame 类型
4.1分组模式及其对象
- 分组代码的一般模式即:
df.groupby(分组依据)[数据来源].使用操作。例如:
df = pd.read_csv('data/learn_pandas.csv')
df.groupby('Gender')['Height'].median() # 按照性别统计身高中位数
Female 159.6
Male 173.4
Name: Height, dtype: float64
- 多维度分组:只需在 groupby 中传入相应列名构成的列表即可
# 根据学校和性别进行分组,统计身高的均值
df.groupby(['School', 'Gender'])['Height'].mean()
School Gender
Fudan University Female 158.776923
Male 174.212500
Peking University Female 158.666667
Male 172.030000
Shanghai Jiao Tong University Female 159.122500
Male 176.760000
Tsinghua University Female 159.753333
Male 171.638889
Name: Height, dtype: float64
- 复杂逻辑条件分组:先写出分组条件,然后将其传入 groupby 中
# 根据学生体重是否超过总体均值来分组,同样还是计算身高的均值
condition = df.Weight > df.Weight.mean()
df.groupby(condition)['Height'].mean()
# 根据上下四分位数分割,将体重分为high、normal、low三组,统计身高的均值
condition2=[df.Weight>df.Weight.quantile(0.75),df.Weight<df.Weight.quantile(0.25)]
df.groupby(condition2)['Height'].mean()
- 分组的本质:分组的本质是按照条件列表中元素的值(此处是 True 和 False )来分组。如果传入多个序列进入 groupby ,那么最后分组的依据就是这两个序列对应行的唯一组合。
item = np.random.choice(list('abc'), df.shape[0])
array(['a', 'a', 'c', 'b', 'c', 'a', 'c', 'b', 'c', 'c', 'a', 'c', 'b',
'a', 'c', 'b', 'b', 'c', 'b', 'c', 'a', 'c', 'b', 'a', 'b', 'a',
'c', 'a', 'c', 'c', 'b', 'b', 'a', 'c', 'c', 'a', 'c', 'c', 'b',
'c', 'b', 'b', 'a', 'a', 'c', 'a', 'a', 'a', 'c', 'a', 'b', 'a',
'c', 'b', 'c', 'c', 'b', 'c', 'a', 'c', 'b', 'b', 'c', 'a', 'b',
'a', 'c', 'c', 'a', 'c', 'a', 'a', 'c', 'c', 'c', 'a', 'b', 'c',
'a', 'c', 'c', 'a', 'a', 'c', 'a', 'c', 'b', 'b', 'b', 'b', 'c',
'a', 'b', 'b', 'a', 'a', 'a', 'c', 'a', 'c', 'a', 'b', 'c', 'b',
'a', 'b', 'b', 'b', 'c', 'b', 'b', 'b', 'c', 'a', 'a', 'b', 'b',
'c', 'c', 'c', 'b', 'c', 'b', 'c', 'c', 'a', 'a', 'a', 'c', 'a',
'c', 'b', 'c', 'b', 'c', 'a', 'b', 'a', 'b', 'b', 'c', 'c', 'c',
'b', 'b', 'c', 'c', 'c', 'a', 'b', 'b', 'c', 'a', 'c', 'b', 'c',
'a', 'b', 'c', 'c', 'b', 'b', 'c', 'a', 'b', 'a', 'a', 'a', 'b',
'c', 'c', 'c', 'b', 'a', 'c', 'c', 'c', 'c', 'a', 'b', 'a', 'a',
'a', 'b', 'b', 'c', 'b', 'c', 'b', 'a', 'c', 'a', 'b', 'a', 'c',
'b', 'c', 'b', 'b', 'c'], dtype='<U1')
df.groupby(item)['Height'].mean()
a 163.924242
b 162.928814
c 162.708621
Name: Height, dtype: float64
可以看出,即使不传入条件,而是一个形状一样的列表,也可以分组。
df.groupby([condition, item])['Height'].mean()
Weight
False a 160.193617
b 158.921951
c 157.756410
True a 173.152632
b 172.055556
c 172.873684
Name: Height, dtype: float64
- 由此可以看出,之前传入列名只是一种简便的记号,事实上等价于传入的是一个或多个列,最后分组的依据来自于数据来源组合的unique值,通过 drop_duplicates 就能知道具体的组类别。
# 二者返回的组别是一样的
df[['School', 'Gender']].drop_duplicates()
df.groupby([df['School'], df['Gender']])['Height'].mean()
4.2 Groupby对象
groupby 对象上定义了许多方法,也具有一些方便的属性。
- gb.ngroups:可以得到分组个数
- gb.groups:可以返回从组名 映射到组索引列表的字典,也就是每一组对应哪些行。
- gb.size():统计每个组的元素个数。(类似value_count方法)
- gb.get_group(x):x表示具体组名,这样可以得到这个组对应的所有行。.get_group()一次只能查看一组数据
- 注意:gb传入分组名用[],传入具体的分组值用()
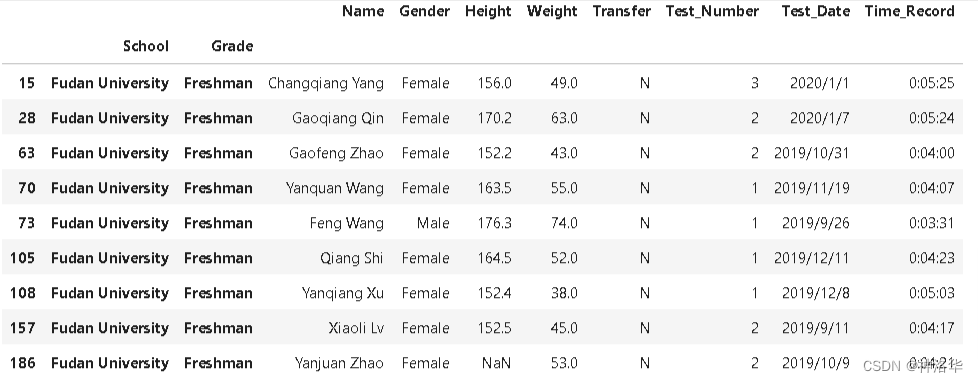
gb = df.groupby(['School', 'Grade'])
gb.ngroups # 分组个数=16
gb.groups
{('Fudan University', 'Freshman'): [15, 28, 63, 70, 73, 105, 108, 157, 186],
......
('Tsinghua University', 'Sophomore'): [40, 53, 55, 74, 76, 80, 91, 97, 106, 110, 139, 151, 178, 181, 182, 199]}
例如,我们验证第一组,结果是筛选出9行。其索引和和gb.groups返回字典的第一个value是一样的。
df_index=df.set_index(['School', 'Grade'],append=True).sort_index()
df_index.loc[:,'Fudan University', 'Freshman']
# 下面gb.get_group的写法结果等价于上面的结果,但是写起来简单一点
gb.get_group(('Fudan University', 'Freshman'))
4.3 聚合
内置聚合函数或者agg传入的函数,都是逐列计算的。比如df.groupby('Gender')[['Height', 'Weight']],当进行聚合计算时,分别计算df.Height和df.Weight这两列。
4.3.1 内置聚合函数
下面都是直接定义在groupby对象的聚合函数,它的速度基本都会经过内部的优化,使用功能时应当优先考虑。max/min/mean/median/count/all/any/idxmax/idxmin/mad/nunique/skew/quantile/sum/std/var/sem/size/prod
all:如果组中的所有值都是真实的,则返回 True,否则返回 False。
idxmax:返回axis维度上第一次出现的最大值的索引
mad:平均绝对偏差
nunique:返回分组的唯一值出现的次数
这些聚合函数当传入的数据来源包含多个列时,将按照列进行迭代计算:
gb = df.groupby('Gender')[['Height', 'Weight']]
gb.max()
Out[24]:
Height Weight
Gender
Female 170.2 63.0
Male 193.9 89.0
4.3.2 agg方法
虽然在 groupby 对象上定义了许多方便的函数,但仍然有以下不便之处:
- 无法同时使用多个函数
- 无法对特定的列使用特定的聚合函数
- 无法使用自定义的聚合函数
- 无法直接对结果的列名在聚合前进行自定义命名
下面说明如何通过 agg 函数解决这四类问题。
- 使用多个函数:当使用多个聚合函数时,需要用列表的形式把内置聚合函数对应的字符串传入,先前提到的所有字符串都是合法的。
gb.agg(['sum', 'idxmax', 'skew'])
Out[25]:
Height Weight
sum idxmax skew sum idxmax skew
Gender
Female 21014.0 28 -0.219253 6469.0 28 -0.268482
Male 8854.9 193 0.437535 3929.0 2 -0.332393
- 对特定的列使用特定的聚合函数
对于方法和列的特殊对应,可以通过构造字典传入 agg 中实现,其中字典以列名为键,以聚合字符串或字符串列表为值。
gb.agg({'Height':['mean','max'], 'Weight':'count'})
Out[26]:
Height Weight
mean max count
Gender
Female 159.19697 170.2 135
Male 173.62549 193.9 54
- 使用自定义函数
在 agg 中可以使用具体的自定义函数, 需要注意传入函数的参数是之前数据源中的列,逐列进行计算 。下面分组计算身高和体重的极差:
gb.agg(lambda x: x.max()-x.min())
Out[27]:
Height Weight
Gender
Female 24.8 29.0
Male 38.2 38.0
由于传入的是序列,因此序列上的方法和属性都是可以在函数中使用的,只需保证返回值是标量即可。下面的例子是指,如果组的指标均值,超过该指标的总体均值,返回High,否则返回Low。
# 这里传入的s就是df.Height或df.Weight。s.name就是Height或者Weight
def my_func(s):
res = 'High'
if s.mean() <= df[s.name].mean():
res = 'Low'
return res
gb.agg(my_func)
Out[29]:
Height Weight
Gender
Female Low Low
Male High High
- 聚合结果重命名
如果想要对聚合结果的列名进行重命名,只需要将上述函数的位置改写成元组,元组的第一个元素为新的名字,第二个位置为原来的函数,包括聚合字符串和自定义函数
gb.agg([('range', lambda x: x.max()-x.min()), ('my_sum', 'sum')])
Out[30]:
Height Weight
range my_sum range my_sum
Gender
Female 24.8 21014.0 29.0 6469.0
Male 38.2 8854.9 38.0 3929.0
使用对一个或者多个列使用单个聚合的时候,重命名需要加方括号,否则就不知道是新的名字还是手误输错的内置函数字符串:
gb.agg([('my_sum', 'sum')])
Out[32]:
Height Weight
my_sum my_sum
Gender
Female 21014.0 6469.0
Male 8854.9 3929.0
4.4 变换和过滤
4.4.1变换函数与transform方法
-
变换函数的返回值为同长度的序列,最常用的内置变换函数是累计函数: cumcount/cumsum/cumprod/cummax/cummin ,它们的使用方式和聚合函数类似,只不过完成的是组内累计操作。cumcount:相当于self.apply(lambda x: pd.Series(np.arange(len(x)), x.index))
-
用自定义变换时需要使用 transform 方法,被调用的自定义函数, 其传入值为数据源的序列 ,与 agg 的传入类型是一致的,其最后的返回结果是行列索引与数据源一致的 DataFrame。(简单说就是返回每一行的计算结果 )
# x还是df.Height或df.Weight
gb=df.groupby('Gender')[['Height', 'Weight']]
gb.transform(lambda x: (x-x.mean())/x.std()).head()
Out[35]:
Height Weight
0 -0.058760 -0.354888
1 -1.010925 -0.355000
2 2.167063 2.089498
3 NaN -1.279789
4 0.053133 0.159631

gb.transform(lambda x: (x-x.mean())/x.std()
if x.name=='Height' else
(x-x.min())/(x.max()-x))
- 标量广播:如果transform返回的是一个标量,就会广播到整个组
gb.transform('mean').head() # 传入返回标量的函数也是可以的
Out[36]:
Height Weight
0 159.19697 47.918519
1 173.62549 72.759259
2 173.62549 72.759259
3 159.19697 47.918519
4 173.62549 72.759259
4.4.2 组索引与过滤
- 在上一章中介绍了索引的用法,那么索引和过滤有什么区别呢?过滤在分组中是对于组的过滤,而索引是对于行的过滤。
- 组过滤作为行过滤的推广,指的是如果对一个组的全体所在行进行统计的结果返回 True 则会被保留, False 则该组会被过滤,最后把所有未被过滤的组其对应的所在行拼接起来作为 DataFrame 返回。
- 在 groupby 对象中,定义了 filter 方法进行组的筛选,其中自定义函数的输入参数为数据源构成的 DataFrame 本身,比如传入df[[‘Height’, ‘Weight’]]对应性别的那部分 DataFrame。只需保证自定义函数的返回为布尔值即可。
# df['Gender'].value_counts()可以统计出Male有59行,Female有141行
# 所以下面是根据性别分组,然后过滤出数量大于100的那一组的Height和Weight值
gb.filter(lambda x: x.shape[0] > 100)
Out[37]:
Height Weight
0 158.9 46.0
3 NaN 41.0
5 158.0 51.0
6 162.5 52.0
7 161.9 50.0
... ... ...
191 166.6 54.0
194 160.3 49.0
195 153.9 46.0
196 160.9 50.0
197 153.9 45.0
141 rows × 2 columns
4.5 apply跨列分组
之前介绍的聚合、变换和过滤,都是在某一列之内操作的。但事实上还有一种常见的分组场景,需要跨列操作。比如
B
M
I
=
W
e
i
g
h
t
H
e
i
g
h
t
2
BMI=\frac{Weight}{Height^{2}}
BMI=Height2Weight
此时,就需要用到apply函数。在设计上, apply 的自定义函数传入参数与 filter 完全一致,只不过后者只允许返回布尔值。现如下解决上述计算问题:
def BMI(x):
Height = x['Height']/100 # 将cm单位转为m
Weight = x['Weight']
BMI_value = Weight/Height**2
return BMI_value.mean()
gb.apply(BMI)
Out[39]:
Gender
Female 18.860930
Male 24.318654
dtype: float64
4.6 练习
4.6.1 汽车数据集
现有一份汽车数据集,其中 Brand, Disp., HP 分别代表汽车品牌、发动机蓄量、发动机输出。
df = pd.read_csv('../data/car.csv')
df.head(3)
Brand Price Country Reliability Mileage Type Weight Disp. HP
0 Eagle Summit 4 8895 USA 4.0 33 Small 2560 97 113
1 Ford Escort 4 7402 USA 2.0 33 Small 2345 114 90
2 Ford Festiva 4 6319 Korea 4.0 37 Small 1845 81 63
- 先过滤出所属 Country 数超过2个的汽车,即若该汽车的 Country 在总体数据集中出现次数不超过2则剔除,再按 Country 分组计算价格均值、价格变异系数、该 Country 的汽车数量,其中变异系数的计算方法是标准差除以均值,并在结果中把变异系数重命名为 CoV 。
- 按照表中位置的前三分之一、中间三分之一和后三分之一分组,统计 Price 的均值。
- 对类型 Type 分组,对 Price 和 HP 分别计算最大值和最小值,结果会产生多级索引,请用下划线把多级列索引合并为单层索引。
- 对类型 Type 分组,对 HP 进行组内的 min-max 归一化。
- 对类型 Type 分组,计算 Disp. 与 HP 的相关系数。
#df['Country'].value_counts()>2 # 得到次数大于2 的Country
# 我这样做行的位置变了
df_new=df.set_index('Country').loc[[('USA'),('Japan'),('Japan/USA'),('Korea')]].reset_index()
df_new=df_new[df.columns]
df_new.head()
Brand Price Country Reliability Mileage Type Weight Disp. HP
0 Eagle Summit 4 8895 USA 4.0 33 Small 2560 97 113
1 Ford Escort 4 7402 USA 2.0 33 Small 2345 114 90
2 Chevrolet Camaro V8 11545 USA 1.0 20 Sporty 3320 305 170
3 Dodge Daytona 9745 USA 1.0 27 Sporty 2885 153 100
4 Ford Mustang V8 12164 USA 1.0 19 Sporty 3310 302 225
df_new=df.groupby('Country').filter(lambda x: x.shape[0] > 2)
- 按 Country 分组计算价格均值、价格变异系数、该 Country 的汽车数量,其中变异系数的计算方法是标准差除以均值,并在结果中把变异系数重命名为 CoV
gb=df_new.groupby('Country')['Price']
gb.agg(['mean',(' CoV', lambda x: x.std()/x.mean()),'count'])
mean CoV count
Country
Japan 13938.052632 0.387429 19
Japan/USA 10067.571429 0.240040 7
Korea 7857.333333 0.243435 3
USA 12543.269231 0.203344 26
- 按照原表中位置的前三分之一、中间三分之一和后三分之一分组,统计 Price 的均值
le=df.shape[0] # 20
condition=[df.index>39,(df.index>19)&(df.index<40)]
df.groupby(condition).groups
# df_new.iloc[:18]['Price'].mean() # 查看前18行平均价格是11605
df.groupby(condition)['Price'].mean()
- 对类型Type分组,对Price和HP分别计算最大值和最小值,结果会产生多级索引,请用下划线把多级列索引合并为单层索引。
gb=df.groupby('Type')[['Price','HP']]
df_3=gb.agg({'Price':['max'],'HP':['min']}) # 单个聚合函数要加方括号
df_3.columns=df_3.columns.map(lambda x: (x[0]+'_'+x[1]))
# df_3.columns=df_3.columns.map(lambda x:'_'.join(x))
df_3
Price_max HP_min
Type
Compact 18900 95
Large 17257 150
Medium 24760 110
Small 9995 63
Sporty 13945 92
Van 15395 106
- 对类型Type分组,对HP进行组内的min-max归一化。
gb=df_new.groupby('Type')[['Price','HP']]
gb.transform(
lambda x: (x-x.min())/(x.max()-x.min())
).head()
- 对类型 Type 分组,计算 Disp. 与 HP 的相关系数
对于协方差和相关系数分别可以利用 cov, corrcoef计算。简单说就是跨列计算
gb=df.groupby('Type')[['HP','Disp.']]
# 为啥这里要加[0,1],看来是np.corrcoef函数的问题,要看文档
gb.apply(lambda x:np.corrcoef(x['Disp.'],x['HP'])[0,1])
Ex2:实现transform函数
groupby对象的构造方法是my_groupby(df, group_cols)- 支持单列分组与多列分组
- 支持带有标量广播的
my_groupby(df)[col].transform(my_func)功能 pandas的transform不能跨列计算,请支持此功能,即仍返回Series但col参数为多列- 无需考虑性能与异常处理,只需实现上述功能,在给出测试样例的同时与
pandas中的transform对比结果是否一致
请点击参考答案查看解答


















 2877
2877

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











