 LangChain常用文件加载方式介绍
LangChain常用文件加载方式介绍





LangChain官网、LangChain官方文档 、langchain Github、langchain API文档、llm-universe
本章参考官方文档《document_loaders/》(在线阅读),此部分github地址见Document loaders(github),其中示例文件在example_data。另外,本文只介绍了部分常用文件的加载,还有Arxiv、BiliBili、Email、GitHub、HuggingFace dataset、Jupyter Notebook、ppt、word、MongoDB、Wikipedia等等各种数据源的加载方式,详见《integrations/document_loaders》。
一、简介
1.1 BaseLoader
langchain.document_loaders有一个名为BaseLoader的抽象基类,用作其他加载器的基础。它定义了一些方法和接口,其他加载器可以继承和实现这些方法来实现自己的加载逻辑。BaseLoader的一些主要方法和接口包括:
__init__():初始化加载器。lazy_load():将数据延迟加载到内存中。load():将数据加载到Document对象中。load_and_split():加载文档并将其拆分为块。
lazy_load()示例
from langchain.document_loaders import UnstructuredHTMLLoader
loader = UnstructuredHTMLLoader("example.html")
documents = loader.lazy_load()
# 使用迭代器逐个加载文档
for document in documents:
# 处理每个文档
print(document.title)
print(document.text)
本示例中,我们使用lazy_load()方法延时加载HTML文件,返回的documents是一个迭代器,可以逐个加载文档。这种方式适用于处理大型文件或需要逐个处理文档的情况,可以节省内存和提高效率。
load_and_split()示例
from langchain.document_loaders import UnstructuredHTMLLoader, RecursiveCharacterTextSplitter
loader = UnstructuredHTMLLoader("example.html")
documents = loader.load_and_split(text_splitter=RecursiveCharacterTextSplitter())
# 处理拆分后的文档块
for document in documents:
# 处理每个文档块
print(document.title)
print(document.text)
此示例中,load_and_split()方法将HTML文件加载并拆分为文档块。通过指定text_splitter参数为RecursiveCharacterTextSplitter(),可以使用递归字符拆分器将文档拆分为更小的块进行后续处理和分析。
1.2 文本加载(TextLoader)
最简单的加载程序是将文件作为文本读入,并将其全部放入一个文档中。
from langchain.document_loaders import TextLoader
loader = TextLoader("./index.md")
loader.load()
[
Document(page_content='---\nsidebar_position: 0\n---\n# Document loaders\n\nUse document loaders to load data from a source as `Document`\'s. A `Document` is a piece of text\nand associated metadata. For example, there are document loaders for loading a simple `.txt` file, for loading the text\ncontents of any web page, or even for loading a transcript of a YouTube video.\n\nEvery document loader exposes two methods:\n1. "Load": load documents from the configured source\n2. "Load and split": load documents from the configured source and split them using the passed in text splitter\n\nThey optionally implement:\n\n3. "Lazy load": load documents into memory lazily\n', metadata={'source': '../docs/docs/modules/data_connection/document_loaders/index.md'})
]
二、 CSV(CSVLoader)
2.1 默认加载
默认情况下,直接加载是每行得到一个Document。以下示例文件来自mlb_teams_2012.csv:

from langchain.document_loaders.csv_loader import CSVLoader
loader = CSVLoader(file_path='./example_data/mlb_teams_2012.csv')
data = loader.load()
print(data)
[Document(page_content='Team: Nationals\n"Payroll (millions)": 81.34\n"Wins": 98', lookup_str='', metadata={'source': './example_data/mlb_teams_2012.csv', 'row': 0}, lookup_index=0),
Document(page_content='Team: Reds\n"Payroll (millions)": 82.20\n"Wins": 97', lookup_str='', metadata={'source': './example_data/mlb_teams_2012.csv', 'row': 1}, lookup_index=0),
...
Document(page_content='Team: Astros\n"Payroll (millions)": 60.65\n"Wins": 55', lookup_str='', metadata={'source': './example_data/mlb_teams_2012.csv', 'row': 29}, lookup_index=0)]
你可以指定参数来定义加载行为。例如,指定分隔符为逗号(delimiter: ','),引号字符为双引号(quotechar: '"'),以及字段名为['MLB Team', 'Payroll in millions', 'Wins']:
loader = CSVLoader(file_path='./example_data/mlb_teams_2012.csv', csv_args={
'delimiter': ',',
'quotechar': '"',
'fieldnames': ['MLB Team', 'Payroll in millions', 'Wins']
})
data = loader.load()
print(data)
[Document(page_content='MLB Team: Team\nPayroll in millions: "Payroll (millions)"\nWins: "Wins"', lookup_str='', metadata={'source': './example_data/mlb_teams_2012.csv', 'row': 0}, lookup_index=0),
Document(page_content='MLB Team: Nationals\nPayroll in millions: 81.34\nWins: 98', lookup_str='', metadata={'source': './example_data/mlb_teams_2012.csv', 'row': 1}, lookup_index=0),
...
Document(page_content='MLB Team: Astros\nPayroll in millions: 60.65\nWins: 55', lookup_str='', metadata={'source': './example_data/mlb_teams_2012.csv', 'row': 30}, lookup_index=0)]
更多CSV参数,请查看csv module 。
2.2 指定一列来标识文档来源
默认情况下, CSV 文件创建的所有文档的源(source )是 file_path,你可以使用 source_column 参数来指定创建的每行文档的来源。但使用sources进行问答链时,这非常有用。
loader = CSVLoader(file_path='./example_data/mlb_teams_2012.csv', source_column="Team")
data = loader.load()
[Document(page_content='Team: Nationals\n"Payroll (millions)": 81.34\n"Wins": 98', lookup_str='', metadata={'source': 'Nationals', 'row': 0}, lookup_index=0),
Document(page_content='Team: Reds\n"Payroll (millions)": 82.20\n"Wins": 97', lookup_str='', metadata={'source': 'Reds', 'row': 1}, lookup_index=0),
...
Document(page_content='Team: Astros\n"Payroll (millions)": 60.65\n"Wins": 55', lookup_str='', metadata={'source': 'Astros', 'row': 29}, lookup_index=0)]
三、 HTML loader
Langchain提供了多种HTML加载器,例如UnstructuredHTMLLoader和BSHTMLLoader。
-
UnstructuredHTMLLoader:基于Unstructured库的HTML加载器。它将HTML文件加载为一个Document对象,并提取出页面内容和元数据。它可以在单个模式或元素模式下运行,元素模式将HTML文档拆分为不同的元素,如标题和正文文本。 -
BSHTMLLoader:基于BeautifulSoup库的HTML加载器。它将HTML文件加载为BeautifulSoup对象,并提供了一些额外的功能,如获取文本内容和元数据。它还可以指定打开文件时的编码和其他BeautifulSoup对象的参数
以下示例文件来自fake-content.html:
<!DOCTYPE html>
<html>
<head><title>Test Title</title>
</head>
<body>
<h1>My First Heading</h1>
<p>My first paragraph.</p>
</body>
</html>
- UnstructuredHTMLLoader
from langchain.document_loaders import UnstructuredHTMLLoader
loader = UnstructuredHTMLLoader("example_data/fake-content.html")
data = loader.load()
data
[Document(page_content='My First Heading\n\nMy first paragraph.', lookup_str='', metadata={'source': 'example_data/fake-content.html'}, lookup_index=0)]
- BSHTMLLoader
from langchain.document_loaders import BSHTMLLoader
loader = BSHTMLLoader("example_data/fake-content.html")
data = loader.load()
data
[Document(page_content='\n\nTest Title\n\n\nMy First Heading\nMy first paragraph.\n\n\n', metadata={'source': 'example_data/fake-content.html', 'title': 'Test Title'})]
除此之外,Langchain还提供了其他HTML加载器:
SeleniumURLLoader:使用Selenium库加载HTML页面,可以处理需要JavaScript渲染的页面PlaywrightURLLoader:使用Playwright库加载HTML页面,也可以处理需要JavaScript渲染的页面
四、 JSON
参考文档《JSON》、JSONLoader API
4.1 使用json库加载JSON文件
JSON (JavaScript Object Notation) 是一种开放标准文件格式和数据交换格式,它使用人类可读的文本来存储和传输由属性值对和数组(或其他可序列化值)组成的数据对象。
JSONLoader 使用指定的 jq schema 来解析 JSON 文件,具体来说,是使用 jq python 包来进行解析( jq 语法详见此文档)。
#!pip install jq
示例文件facebook_chat.json显示如下:
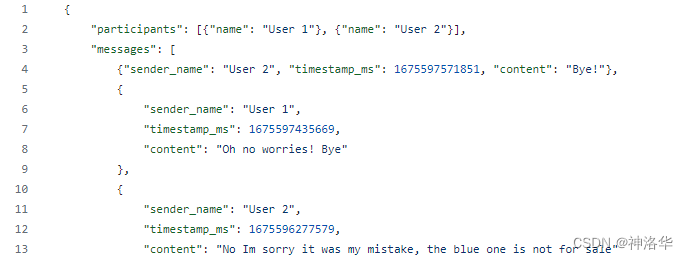
使用json读取并查看文件:
import json
from pathlib import Path
from pprint import pprint
file_path='./example_data/facebook_chat.json'
data = json.loads(Path(file_path).read_text())
pprint(data)
{'image': {'creation_timestamp': 1675549016, 'uri': 'image_of_the_chat.jpg'},
'is_still_participant': True,
'joinable_mode': {'link': '', 'mode': 1},
'magic_words': [],
'messages': [{'content': 'Bye!',
'sender_name': 'User 2',
'timestamp_ms': 1675597571851},
{'content': 'Oh no worries! Bye',
'sender_name': 'User 1',
'timestamp_ms': 1675597435669},
{'content': 'No Im sorry it was my mistake, the blue one is not '
'for sale',
'sender_name': 'User 2',
'timestamp_ms': 1675596277579},
{'content': 'I thought you were selling the blue one!',
'sender_name': 'User 1',
'timestamp_ms': 1675595140251},
{'content': 'Im not interested in this bag. Im interested in the '
'blue one!',
'sender_name': 'User 1',
'timestamp_ms': 1675595109305},
{'content': 'Here is $129',
'sender_name': 'User 2',
'timestamp_ms': 1675595068468},
{'photos': [{'creation_timestamp': 1675595059,
'uri': 'url_of_some_picture.jpg'}],
'sender_name': 'User 2',
'timestamp_ms': 1675595060730},
{'content': 'Online is at least $100',
'sender_name': 'User 2',
'timestamp_ms': 1675595045152},
{'content': 'How much do you want?',
'sender_name': 'User 1',
'timestamp_ms': 1675594799696},
{'content': 'Goodmorning! $50 is too low.',
'sender_name': 'User 2',
'timestamp_ms': 1675577876645},
{'content': 'Hi! Im interested in your bag. Im offering $50. Let '
'me know if you are interested. Thanks!',
'sender_name': 'User 1',
'timestamp_ms': 1675549022673}],
'participants': [{'name': 'User 1'}, {'name': 'User 2'}],
'thread_path': 'inbox/User 1 and User 2 chat',
'title': 'User 1 and User 2 chat'}
4.2 使用JSONLoader加载JSON文件
4.2.1 JSONLoader参数解析
langchain.document_loaders.json_loader.JSONLoader 是一个用于加载 JSON 文件的类。它有以下参数:
class langchain.document_loaders.json_loader.JSONLoader(file_path: Union[str, Path], jq_schema: str,
content_key: Optional[str] = None, metadata_func: Optional[Callable[[Dict, Dict], Dict]] = None,
text_content: bool = True, json_lines: bool = False)
file_path:JSON 文件的路径或文件名。jq_schema:用于从 JSON 中提取数据或文本的 jq schema。content_key:如果 jq_schema 的结果是一个dict,那么content_key 参数指定了要从该字典中提取哪些key的值,这对于处理包含嵌套结构的 JSON 数据非常有用。metadata_func:一个函数,用于从 jq_schema 提取的 JSON 对象和默认元数据中获取更新后的元数据。text_content:布尔类型,内容是否为字符串格式,默认为 True。json_lines:布尔类型,输入是否为 JSON Lines 格式,默认为False。
jq schema 是用于解析和提取 复杂JSON 数据的查询语言,它是基于 jq 工具的语法。通过一系列过滤器和操作符来过滤、映射和转换 JSON 数据,jq schema可以根据特定的查询需求从复杂的 JSON 数据结构中提取所需的信息。下面给出一些常见的 JSON 结构及相应的 jq_schema示例:
JSON -> [{"text": ...}, {"text": ...}, {"text": ...}]
jq_schema -> ".[].text"
JSON -> {"key": [{"text": ...}, {"text": ...}, {"text": ...}]}
jq_schema -> ".key[].text"
JSON -> ["...", "...", "..."]
jq_schema -> ".[]"
- 如果 JSON 数据是一个包含多个对象的列表,每个对象都有一个 text 字段,那么可以使用 jq_schema:
.[].text来提取所有对象的 text 字段的值 - 使用 jq_schema:
.key[].text来提取key中所有对象的 text 字段的值。 - 如果 JSON 数据是一个包含多个字符串的列表,那么可以使用 jq_schema:
.[]来提取列表中的所有字符串
4.2.2 JSONLoader`加载示例
我们可以通过可以通过 JSONLoader轻松提取以上JSON数据里messages键中 content 字段下的值:
from langchain.document_loaders import JSONLoader
loader = JSONLoader(
file_path='./example_data/facebook_chat.json',
jq_schema='.messages[].content',
text_content=False)
data = loader.load()
pprint(data)
[Document(page_content='Bye!', metadata={'source': '/Users/avsolatorio/WBG/langchain/docs/modules/indexes/document_loaders/examples/example_data/facebook_chat.json', 'seq_num': 1}),
Document(page_content='Oh no worries! Bye', metadata={'source': '/Users/avsolatorio/WBG/langchain/docs/modules/indexes/document_loaders/examples/example_data/facebook_chat.json', 'seq_num': 2}),
Document(page_content='No Im sorry it was my mistake, the blue one is not for sale', metadata={'source': '/Users/avsolatorio/WBG/langchain/docs/modules/indexes/document_loaders/examples/example_data/facebook_chat.json', 'seq_num': 3}),
Document(page_content='I thought you were selling the blue one!', metadata={'source': '/Users/avsolatorio/WBG/langchain/docs/modules/indexes/document_loaders/examples/example_data/facebook_chat.json', 'seq_num': 4}),
Document(page_content='Im not interested in this bag. Im interested in the blue one!', metadata={'source': '/Users/avsolatorio/WBG/langchain/docs/modules/indexes/document_loaders/examples/example_data/facebook_chat.json', 'seq_num': 5}),
Document(page_content='Here is $129', metadata={'source': '/Users/avsolatorio/WBG/langchain/docs/modules/indexes/document_loaders/examples/example_data/facebook_chat.json', 'seq_num': 6}),
Document(page_content='', metadata={'source': '/Users/avsolatorio/WBG/langchain/docs/modules/indexes/document_loaders/examples/example_data/facebook_chat.json', 'seq_num': 7}),
Document(page_content='Online is at least $100', metadata={'source': '/Users/avsolatorio/WBG/langchain/docs/modules/indexes/document_loaders/examples/example_data/facebook_chat.json', 'seq_num': 8}),
Document(page_content='How much do you want?', metadata={'source': '/Users/avsolatorio/WBG/langchain/docs/modules/indexes/document_loaders/examples/example_data/facebook_chat.json', 'seq_num': 9}),
Document(page_content='Goodmorning! $50 is too low.', metadata={'source': '/Users/avsolatorio/WBG/langchain/docs/modules/indexes/document_loaders/examples/example_data/facebook_chat.json', 'seq_num': 10}),
Document(page_content='Hi! Im interested in your bag. Im offering $50. Let me know if you are interested. Thanks!', metadata={'source': '/Users/avsolatorio/WBG/langchain/docs/modules/indexes/document_loaders/examples/example_data/facebook_chat.json', 'seq_num': 11})]
4.3 提取元数据
当使用JSONLoader加载JSON文件时,我们通常希望将JSON文件中的元数据也包含在文档中。上一节的示例中,我们没有收集元数据,只是通过.messages[].content提取了所有context字段的内容。。
本节示例中,我们需要同时提取JSON文件的元数据,因此jq_schema应该设为.messages[],然后将records (dict)传递给metadata_func函数,该函数负责确定记录中的哪些信息应该包含在最终的Document对象的元数据中。
此外,通过content_key参数,指定从记录中需要提取哪些键,以确保提取正确的内容。
# Define the metadata extraction function.
def metadata_func(record: dict, metadata: dict) -> dict:
metadata["sender_name"] = record.get("sender_name")
metadata["timestamp_ms"] = record.get("timestamp_ms")
return metadata
loader = JSONLoader(
file_path='./example_data/facebook_chat.json',
jq_schema='.messages[]',
content_key="content",
metadata_func=metadata_func
)
data = loader.load()
pprint(data)
[Document(page_content='Bye!', metadata={'source': '/Users/avsolatorio/WBG/langchain/docs/modules/indexes/document_loaders/examples/example_data/facebook_chat.json', 'seq_num': 1, 'sender_name': 'User 2', 'timestamp_ms': 1675597571851}),
Document(page_content='Oh no worries! Bye', metadata={'source': '/Users/avsolatorio/WBG/langchain/docs/modules/indexes/document_loaders/examples/example_data/facebook_chat.json', 'seq_num': 2, 'sender_name': 'User 1', 'timestamp_ms': 1675597435669}),
Document(page_content='No Im sorry it was my mistake, the blue one is not for sale', metadata={'source': '/Users/avsolatorio/WBG/langchain/docs/modules/indexes/document_loaders/examples/example_data/facebook_chat.json', 'seq_num': 3, 'sender_name': 'User 2', 'timestamp_ms': 1675596277579}),
Document(page_content='I thought you were selling the blue one!', metadata={'source': '/Users/avsolatorio/WBG/langchain/docs/modules/indexes/document_loaders/examples/example_data/facebook_chat.json', 'seq_num': 4, 'sender_name': 'User 1', 'timestamp_ms': 1675595140251}),
Document(page_content='Im not interested in this bag. Im interested in the blue one!', metadata={'source': '/Users/avsolatorio/WBG/langchain/docs/modules/indexes/document_loaders/examples/example_data/facebook_chat.json', 'seq_num': 5, 'sender_name': 'User 1', 'timestamp_ms': 1675595109305}),
Document(page_content='Here is $129', metadata={'source': '/Users/avsolatorio/WBG/langchain/docs/modules/indexes/document_loaders/examples/example_data/facebook_chat.json', 'seq_num': 6, 'sender_name': 'User 2', 'timestamp_ms': 1675595068468}),
Document(page_content='', metadata={'source': '/Users/avsolatorio/WBG/langchain/docs/modules/indexes/document_loaders/examples/example_data/facebook_chat.json', 'seq_num': 7, 'sender_name': 'User 2', 'timestamp_ms': 1675595060730}),
Document(page_content='Online is at least $100', metadata={'source': '/Users/avsolatorio/WBG/langchain/docs/modules/indexes/document_loaders/examples/example_data/facebook_chat.json', 'seq_num': 8, 'sender_name': 'User 2', 'timestamp_ms': 1675595045152}),
Document(page_content='How much do you want?', metadata={'source': '/Users/avsolatorio/WBG/langchain/docs/modules/indexes/document_loaders/examples/example_data/facebook_chat.json', 'seq_num': 9, 'sender_name': 'User 1', 'timestamp_ms': 1675594799696}),
Document(page_content='Goodmorning! $50 is too low.', metadata={'source': '/Users/avsolatorio/WBG/langchain/docs/modules/indexes/document_loaders/examples/example_data/facebook_chat.json', 'seq_num': 10, 'sender_name': 'User 2', 'timestamp_ms': 1675577876645}),
Document(page_content='Hi! Im interested in your bag. Im offering $50. Let me know if you are interested. Thanks!', metadata={'source': '/Users/avsolatorio/WBG/langchain/docs/modules/indexes/document_loaders/examples/example_data/facebook_chat.json', 'seq_num': 11, 'sender_name': 'User 1', 'timestamp_ms': 1675549022673})]
现在,文档包含与我们提取的内容关联的元数据。
4.4 元数据处理
metadata_func 允许用户根据需要自定义元数据的格式和内容。用户可以利用 metadata_func 对默认元数据进行修改,以满足特定的需求。例如,您可以添加、删除或修改元数据的特定字段,或者根据提取的数据生成新的元数据。
metadata_func接受两个参数:record 和 metadata,分别表示 从JSON 数据中提取的对象以及默认的元数据。默认元数据包含 source 和 seq_num 两个键,然而JSON 数据中也可能包含这些键。此时,你可以利用 metadata_func 来修改source键的默认值,使其仅包含与 langchain 目录相关的文件来源信息。
# Define the metadata extraction function.
def metadata_func(record: dict, metadata: dict) -> dict:
metadata["sender_name"] = record.get("sender_name")
metadata["timestamp_ms"] = record.get("timestamp_ms")
if "source" in metadata:
source = metadata["source"].split("/")
source = source[source.index("langchain"):]
metadata["source"] = "/".join(source)
return metadata
loader = JSONLoader(
file_path='./example_data/facebook_chat.json',
jq_schema='.messages[]',
content_key="content",
metadata_func=metadata_func
)
data = loader.load()
pprint(data)
[Document(page_content='Bye!', metadata={'source': 'langchain/docs/modules/indexes/document_loaders/examples/example_data/facebook_chat.json', 'seq_num': 1, 'sender_name': 'User 2', 'timestamp_ms': 1675597571851}),
Document(page_content='Oh no worries! Bye', metadata={'source': 'langchain/docs/modules/indexes/document_loaders/examples/example_data/facebook_chat.json', 'seq_num': 2, 'sender_name': 'User 1', 'timestamp_ms': 1675597435669}),
Document(page_content='No Im sorry it was my mistake, the blue one is not for sale', metadata={'source': 'langchain/docs/modules/indexes/document_loaders/examples/example_data/facebook_chat.json', 'seq_num': 3, 'sender_name': 'User 2', 'timestamp_ms': 1675596277579}),
Document(page_content='I thought you were selling the blue one!', metadata={'source': 'langchain/docs/modules/indexes/document_loaders/examples/example_data/facebook_chat.json', 'seq_num': 4, 'sender_name': 'User 1', 'timestamp_ms': 1675595140251}),
Document(page_content='Im not interested in this bag. Im interested in the blue one!', metadata={'source': 'langchain/docs/modules/indexes/document_loaders/examples/example_data/facebook_chat.json', 'seq_num': 5, 'sender_name': 'User 1', 'timestamp_ms': 1675595109305}),
Document(page_content='Here is $129', metadata={'source': 'langchain/docs/modules/indexes/document_loaders/examples/example_data/facebook_chat.json', 'seq_num': 6, 'sender_name': 'User 2', 'timestamp_ms': 1675595068468}),
Document(page_content='', metadata={'source': 'langchain/docs/modules/indexes/document_loaders/examples/example_data/facebook_chat.json', 'seq_num': 7, 'sender_name': 'User 2', 'timestamp_ms': 1675595060730}),
Document(page_content='Online is at least $100', metadata={'source': 'langchain/docs/modules/indexes/document_loaders/examples/example_data/facebook_chat.json', 'seq_num': 8, 'sender_name': 'User 2', 'timestamp_ms': 1675595045152}),
Document(page_content='How much do you want?', metadata={'source': 'langchain/docs/modules/indexes/document_loaders/examples/example_data/facebook_chat.json', 'seq_num': 9, 'sender_name': 'User 1', 'timestamp_ms': 1675594799696}),
Document(page_content='Goodmorning! $50 is too low.', metadata={'source': 'langchain/docs/modules/indexes/document_loaders/examples/example_data/facebook_chat.json', 'seq_num': 10, 'sender_name': 'User 2', 'timestamp_ms': 1675577876645}),
Document(page_content='Hi! Im interested in your bag. Im offering $50. Let me know if you are interested. Thanks!', metadata={'source': 'langchain/docs/modules/indexes/document_loaders/examples/example_data/facebook_chat.json', 'seq_num': 11, 'sender_name': 'User 1', 'timestamp_ms': 1675549022673})]
- 使用
record.get()方法,将sender_name和timestamp_ms字段从 record 中提取出来,并将它们添加到metadata中。 - 检查
metadata中是否存在source字段。如果存在,将其按照/分割为列表,并找到列表中包含"langchain"的部分。 - 将该部分重新组合为字符串,并将其赋值给
metadata中的source字段。这样可以确保source字段仅包含与"langchain"相关的文件来源信息。 - 最后,将更新后的 metadata 返回
4.5 JSON Lines file
JSON Lines 是一种文件格式,其中每一行都是有效的 JSON 值。如果要从 JSON Lines 文件加载文档,需设置:
json_lines=True:表示JSONLoader类根据每一行的JSON值加载文件,并将其解析为相应的数据对象- 指定
jq_schema:从单个 JSON 对象中提取 page_content 。
json_lines=True的设置非常适用于处理大型的JSON Lines文件,因为我们可以进行逐行处理,而不需要一次性加载整个文件到内存中。
示例文件facebook_chat_messages.jsonl显示如下:

file_path = './example_data/facebook_chat_messages.jsonl'
pprint(Path(file_path).read_text())
('{"sender_name": "User 2", "timestamp_ms": 1675597571851, "content": "Bye!"}\n'
'{"sender_name": "User 1", "timestamp_ms": 1675597435669, "content": "Oh no '
'worries! Bye"}\n'
'{"sender_name": "User 2", "timestamp_ms": 1675596277579, "content": "No Im '
'sorry it was my mistake, the blue one is not for sale"}\n')
loader = JSONLoader(
file_path='./example_data/facebook_chat_messages.jsonl',
jq_schema='.content',
text_content=False,
json_lines=True)
data = loader.load()
pprint(data)
[Document(page_content='Bye!', metadata={'source': 'langchain/docs/modules/indexes/document_loaders/examples/example_data/facebook_chat_messages.jsonl', 'seq_num': 1}),
Document(page_content='Oh no worries! Bye', metadata={'source': 'langchain/docs/modules/indexes/document_loaders/examples/example_data/facebook_chat_messages.jsonl', 'seq_num': 2}),
Document(page_content='No Im sorry it was my mistake, the blue one is not for sale', metadata={'source': 'langchain/docs/modules/indexes/document_loaders/examples/example_data/facebook_chat_messages.jsonl', 'seq_num': 3})]
也可以设置 jq_schema='.' 并提供 content_key:
loader = JSONLoader(
file_path='./example_data/facebook_chat_messages.jsonl',
jq_schema='.',
content_key='sender_name',
json_lines=True)
data = loader.load()
pprint(data)
[Document(page_content='User 2', metadata={'source': 'langchain/docs/modules/indexes/document_loaders/examples/example_data/facebook_chat_messages.jsonl', 'seq_num': 1}),
Document(page_content='User 1', metadata={'source': 'langchain/docs/modules/indexes/document_loaders/examples/example_data/facebook_chat_messages.jsonl', 'seq_num': 2}),
Document(page_content='User 2', metadata={'source': 'langchain/docs/modules/indexes/document_loaders/examples/example_data/facebook_chat_messages.jsonl', 'seq_num': 3})]
五、 Markdown
参考llm-universe《第一章、知识库文档处理》
5.1 使用UnstructuredMarkdownLoader加载
from langchain.document_loaders import UnstructuredMarkdownLoader
markdown_path = "../../../../../README.md"
loader = UnstructuredMarkdownLoader(markdown_path)
data = loader.load()
data
[Document(page_content="ð\x9f¦\x9cï¸\x8fð\x9f”\x97 LangChain\n\nâ\x9a¡ Building applications with LLMs through composability â\x9a¡\n\nLooking for the JS/TS version? Check out LangChain.js.\n\nProduction Support: As you move your LangChains into production, we'd love to offer more comprehensive support.\nPlease fill out this form and we'll set up a dedicated support Slack channel.\n\nQuick Install\n\npip install langchain\nor\nconda install langchain -c conda-forge\n\nð\x9f¤” What is this?\n\nLarge language models (LLMs) are emerging as a transformative technology, enabling developers to build applications that they previously could not. However, using these LLMs in isolation is often insufficient for creating a truly powerful app - the real power comes when you can combine them with other sources of computation or knowledge.\n\nThis library aims to assist in the development of those types of applications. Common examples of these applications include:\n\nâ\x9d“ Question Answering over specific documents\n\nDocumentation\n\nEnd-to-end Example: Question Answering over Notion Database\n\nð\x9f’¬ Chatbots\n\nDocumentation\n\nEnd-to-end Example: Chat-LangChain\n\nð\x9f¤\x96 Agents\n\nDocumentation\n\nEnd-to-end Example: GPT+WolframAlpha\n\nð\x9f“\x96 Documentation\n\nPlease see here for full documentation on:\n\nGetting started (installation, setting up the environment, simple examples)\n\nHow-To examples (demos, integrations, helper functions)\n\nReference (full API docs)\n\nResources (high-level explanation of core concepts)\n\nð\x9f\x9a\x80 What can this help with?\n\nThere are six main areas that LangChain is designed to help with.\nThese are, in increasing order of complexity:\n\nð\x9f“\x83 LLMs and Prompts:\n\nThis includes prompt management, prompt optimization, a generic interface for all LLMs, and common utilities for working with LLMs.\n\nð\x9f”\x97 Chains:\n\nChains go beyond a single LLM call and involve sequences of calls (whether to an LLM or a different utility). LangChain provides a standard interface for chains, lots of integrations with other tools, and end-to-end chains for common applications.\n\nð\x9f“\x9a Data Augmented Generation:\n\nData Augmented Generation involves specific types of chains that first interact with an external data source to fetch data for use in the generation step. Examples include summarization of long pieces of text and question/answering over specific data sources.\n\nð\x9f¤\x96 Agents:\n\nAgents involve an LLM making decisions about which Actions to take, taking that Action, seeing an Observation, and repeating that until done. LangChain provides a standard interface for agents, a selection of agents to choose from, and examples of end-to-end agents.\n\nð\x9f§\xa0 Memory:\n\nMemory refers to persisting state between calls of a chain/agent. LangChain provides a standard interface for memory, a collection of memory implementations, and examples of chains/agents that use memory.\n\nð\x9f§\x90 Evaluation:\n\n[BETA] Generative models are notoriously hard to evaluate with traditional metrics. One new way of evaluating them is using language models themselves to do the evaluation. LangChain provides some prompts/chains for assisting in this.\n\nFor more information on these concepts, please see our full documentation.\n\nð\x9f’\x81 Contributing\n\nAs an open-source project in a rapidly developing field, we are extremely open to contributions, whether it be in the form of a new feature, improved infrastructure, or better documentation.\n\nFor detailed information on how to contribute, see here.", metadata={'source': '../../../../../README.md'})]
5.2 保留元素
在使用Unstructured加载Markdown文件时,默认情况下,不同文本块会被合并在一起形成一个整体的文档。但是,你可以通过指定mode="elements"来保持这些文本块的分离。这样,Unstructured库会将文档拆分为不同的元素,例如标题和叙述文本,以便更灵活地处理和使用这些元素。
loader = UnstructuredMarkdownLoader(markdown_path, mode="elements")
data = loader.load()
data[0]
Document(page_content='ð\x9f¦\x9cï¸\x8fð\x9f”\x97 LangChain', metadata={'source': '../../../../../README.md', 'page_number': 1, 'category': 'Title'})
5.3 探索加载的数据
from langchain.document_loaders import UnstructuredMarkdownLoader
loader = UnstructuredMarkdownLoader("../../data_base/knowledge_db/prompt_engineering/1. 简介 Introduction.md")
pages = loader.load()
读取的对象和 PDF 文档读取出来是完全一致的:
print(f"载入后的变量类型为:{type(pages)},", f"该 Markdown 一共包含 {len(pages)} 页")
载入后的变量类型为:<class 'list'>, 该 Markdown 一共包含 1 页
page = pages[0]
print(f"每一个元素的类型:{type(page)}.",
f"该文档的描述性数据:{page.metadata}",
f"查看该文档的内容:\n{page.page_content[0:]}",
sep="\n------\n")
每一个元素的类型:<class 'langchain.schema.document.Document'>.
------
该文档的描述性数据:{'source': '../../data_base/knowledge_db/prompt_engineering/1. 简介 Introduction.md'}
------
查看该文档的内容:
第一章 简介
欢迎来到面向开发者的提示工程部分,本部分内容基于吴恩达老师的《Prompt Engineering for Developer》课程进行编写。《Prompt Engineering for Developer》课程是由吴恩达老师与 OpenAI 技术团队成员 Isa Fulford 老师合作授课,Isa 老师曾开发过受欢迎的 ChatGPT 检索插件,并且在教授 LLM (Large Language Model, 大语言模型)技术在产品中的应用方面做出了很大贡献。她还参与编写了教授人们使用 Prompt 的 OpenAI cookbook。我们希望通过本模块的学习,与大家分享使用提示词开发 LLM 应用的最佳实践和技巧。
网络上有许多关于提示词(Prompt, 本教程中将保留该术语)设计的材料,例如《30 prompts everyone has to know》之类的文章,这些文章主要集中在 ChatGPT 的 Web 界面上,许多人在使用它执行特定的、通常是一次性的任务。但我们认为,对于开发人员,大语言模型(LLM) 的更强大功能是能通过 API 接口调用,从而快速构建软件应用程序。实际上,我们了解到 DeepLearning.AI 的姊妹公司 AI Fund 的团队一直在与许多初创公司合作,将这些技术应用于诸多应用程序上。很兴奋能看到 LLM API 能够让开发人员非常快速地构建应用程序。
在本模块,我们将与读者分享提升大语言模型应用效果的各种技巧和最佳实践。书中内容涵盖广泛,包括软件开发提示词设计、文本总结、推理、转换、扩展以及构建聊天机器人等语言模型典型应用场景。我们衷心希望该课程能激发读者的想象力,开发出更出色的语言模型应用。
随着 LLM 的发展,其大致可以分为两种类型,后续称为基础 LLM 和指令微调(Instruction Tuned)LLM。基础LLM是基于文本训练数据,训练出预测下一个单词能力的模型。其通常通过在互联网和其他来源的大量数据上训练,来确定紧接着出现的最可能的词。例如,如果你以“从前,有一只独角兽”作为 Prompt ,基础 LLM 可能会继续预测“她与独角兽朋友共同生活在一片神奇森林中”。但是,如果你以“法国的首都是什么”为 Prompt ,则基础 LLM 可能会根据互联网上的文章,将回答预测为“法国最大的城市是什么?法国的人口是多少?”,因为互联网上的文章很可能是有关法国国家的问答题目列表。
与基础语言模型不同,指令微调 LLM 通过专门的训练,可以更好地理解并遵循指令。举个例子,当询问“法国的首都是什么?”时,这类模型很可能直接回答“法国的首都是巴黎”。指令微调 LLM 的训练通常基于预训练语言模型,先在大规模文本数据上进行预训练,掌握语言的基本规律。在此基础上进行进一步的训练与微调(finetune),输入是指令,输出是对这些指令的正确回复。有时还会采用RLHF(reinforcement learning from human feedback,人类反馈强化学习)技术,根据人类对模型输出的反馈进一步增强模型遵循指令的能力。通过这种受控的训练过程。指令微调 LLM 可以生成对指令高度敏感、更安全可靠的输出,较少无关和损害性内容。因此。许多实际应用已经转向使用这类大语言模型。
因此,本课程将重点介绍针对指令微调 LLM 的最佳实践,我们也建议您将其用于大多数使用场景。当您使用指令微调 LLM 时,您可以类比为向另一个人提供指令(假设他很聪明但不知道您任务的具体细节)。因此,当 LLM 无法正常工作时,有时是因为指令不够清晰。例如,如果您想问“请为我写一些关于阿兰·图灵( Alan Turing )的东西”,在此基础上清楚表明您希望文本专注于他的科学工作、个人生活、历史角色或其他方面可能会更有帮助。另外您还可以指定回答的语调, 来更加满足您的需求,可选项包括专业记者写作,或者向朋友写的随笔等。
如果你将 LLM 视为一名新毕业的大学生,要求他完成这个任务,你甚至可以提前指定他们应该阅读哪些文本片段来写关于阿兰·图灵的文本,这样能够帮助这位新毕业的大学生更好地完成这项任务。本书的下一章将详细阐释提示词设计的两个关键原则:清晰明确和给予充足思考时间。
六、 PDF
在langchain库中提供了不同的PDF加载器,以适应不同的需求和场景:
| 加载器 | 加载库 | 描述 |
|---|---|---|
PyPDFLoader | PyPDF | 用于加载本地简单的的PDF文件 |
MathpixPDFLoader | MathPix | 加载后使用Mathpix OCR服务进行文本提取, 适用于需要进行OCR的PDF文档 |
UnstructuredPDFLoader | Unstructured | 加载后转换为Unstructured文档对象,适用于需要对PDF文档进行结构化处理和分析的场景。 |
PyMuPDFLoader | PyMuPDF | 最快的 PDF 解析器,包含有关 PDF 及其页面的详细元数据,并且每页返回一个文档。 |
PDFPlumberLoader | PDFPlumber | 同 PyMuPDF |
PyPDFDirectoryLoader | 从目录中加载 PDF | |
PDFMinerLoader | PDFMiner | 适用于需要更高级的PDF处理功能的场景。 |
PyPDFium2Loader | PyPDFium2 | 适用于需要更高级的PDF处理功能的场景。 |
AmazonTextractPDFParser | 调用Amazon Textract Service | 需要配置 AWS ,同时还支持 JPEG、PNG 和 TIFF 以及非原生 PDF 格式 |
OnlinePDFLoader | Unstructured | 从在线URL加载PDF文件,旧版本功能,不推荐使用 |
最常用的加载器取决于具体的应用场景和需求。例如,如果需要进行OCR文本提取,MathpixPDFLoader可能是最常用的;如果需要对PDF文档进行结构化处理和分析,UnstructuredPDFLoader可能更适合。
6.1 PyPDFLoader
6.1.1 使用faiss_index进行相似性搜索
可使用 pypdf 将 PDF 加载到文档中,其中每个文档包含页面内容和带有 page 编号的元数据。这种方法的优点是可以使用页码检索文档。
pip install pypdf
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("example_data/layout-parser-paper.pdf")
pages = loader.load_and_split()
pages[0]
下面演示使用langchain库中的FAISS和QianfanEmbeddingsEndpoint模块来进行文本相似性搜索。
# 使用openai、智谱ChatGLM、百度文心需要分别安装openai,zhipuai,qianfan
import os
import qianfan
from langchain.embeddings import QianfanEmbeddingsEndpoint
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env file
qianfan.qianfan_ak=os.environ['QIANFAN_AK']
qianfan.qianfan_sk=os.environ['QIANFAN_SK']
from langchain.vectorstores import FAISS
faiss_index = FAISS.from_documents(pages, QianfanEmbeddingsEndpoint())
docs = faiss_index.similarity_search("How will the community be engaged?", k=2)
for doc in docs:
print(str(doc.metadata["page"]) + ":", doc.page_content[:300])
- 创建了一个FAISS索引对象
faiss_index,并使用QianfanEmbeddingsEndpoint作为嵌入模型,将上述加载的PDF文档内容嵌入化。 - 使用
faiss_index进行相似性搜索,搜索与给定查询文本"How will the community be engaged?"相似的文档,返回前2个最相似的文档 - 遍历搜索结果,并打印每个文档的元数据和前300个字符内容
6.1.2 提取图像
使用 rapidocr-onnxruntime 我们也可以将图像提取为文本:
pip install rapidocr-onnxruntime
loader = PyPDFLoader("https://arxiv.org/pdf/2103.15348.pdf", extract_images=True)
pages = loader.load()
pages[4].page_content
6.2 PyMuPDF
这是最快的 PDF 解析选项,包含有关 PDF 及其页面的详细元数据,并且每页返回一个文档。
from langchain.document_loaders import PyMuPDFLoader
loader = PyMuPDFLoader("example_data/layout-parser-paper.pdf")
pages = loader.load()
pages[0]
文档加载后储存在 pages 变量中,其类型为 List,打印 pages 的长度可以看到 pdf 一共包含多少页。
print(f"载入后的变量类型为:{type(pages)},", f"该 PDF 一共包含 {len(pages)} 页")
载入后的变量类型为:<class 'list'>, 该 PDF 一共包含 196 页
page 中的每一元素为一个文档,变量类型为 langchain.schema.document.Document, 文档变量类型包含两个属性:
- page_content 包含该文档的内容。
- meta_data 为文档相关的描述性数据。
page = pages[1]
print(f"每一个元素的类型:{type(page)}.",
f"该文档的描述性数据:{page.metadata}",
f"查看该文档的内容:\n{page.page_content[0:1000]}",
sep="\n------\n")
此外,您可以将 PyMuPDF 文档中的任何选项作为 load 调用中的关键字参数传递,并且它将传递给 get_text() 调用。
6.3 UnstructuredPDFLoader
from langchain.document_loaders import UnstructuredPDFLoader
loader = UnstructuredPDFLoader("example_data/layout-parser-paper.pdf")
data = loader.load()
同UnstructuredMarkdownLoader一样,默认情况下,不同文本块会被合并在一起形成一个整体的文档,您也可以通过指定 mode="elements" 来保持这些文本块的分离。
loader = UnstructuredPDFLoader("example_data/layout-parser-paper.pdf", mode="elements")
data = loader.load()
data[0]
6.4 PyPDF 目录
从目录中加载 PDF:
from langchain.document_loaders import PyPDFDirectoryLoader
loader = PyPDFDirectoryLoader("example_data/")
docs = loader.load()
6.5 PDFMiner
from langchain.document_loaders import PDFMinerLoader
loader = PDFMinerLoader("example_data/layout-parser-paper.pdf")
data = loader.load()
下面演示使用使用 PDFMiner 生成 HTML 文本,后续可以通过 BeautifulSoup 解析输出 html 内容,以获得有关字体大小、页码、PDF 页眉/页脚等的更结构化和丰富的信息。
from langchain.document_loaders import PDFMinerPDFasHTMLLoader
loader = PDFMinerPDFasHTMLLoader("example_data/layout-parser-paper.pdf")
data = loader.load()[0] # entire PDF is loaded as a single Document
from bs4 import BeautifulSoup
soup = BeautifulSoup(data.page_content,'html.parser')
content = soup.find_all('div')
import re
cur_fs = None
cur_text = ''
snippets = [] # first collect all snippets that have the same font size
for c in content:
sp = c.find('span')
if not sp:
continue
st = sp.get('style')
if not st:
continue
fs = re.findall('font-size:(\d+)px',st)
if not fs:
continue
fs = int(fs[0])
if not cur_fs:
cur_fs = fs
if fs == cur_fs:
cur_text += c.text
else:
snippets.append((cur_text,cur_fs))
cur_fs = fs
cur_text = c.text
snippets.append((cur_text,cur_fs))
# Note: The above logic is very straightforward. One can also add more strategies such as removing duplicate snippets (as
# headers/footers in a PDF appear on multiple pages so if we find duplicates it's safe to assume that it is redundant info)
from langchain.docstore.document import Document
cur_idx = -1
semantic_snippets = []
# Assumption: headings have higher font size than their respective content
for s in snippets:
# if current snippet's font size > previous section's heading => it is a new heading
if not semantic_snippets or s[1] > semantic_snippets[cur_idx].metadata['heading_font']:
metadata={'heading':s[0], 'content_font': 0, 'heading_font': s[1]}
metadata.update(data.metadata)
semantic_snippets.append(Document(page_content='',metadata=metadata))
cur_idx += 1
continue
# if current snippet's font size <= previous section's content => content belongs to the same section (one can also create
# a tree like structure for sub sections if needed but that may require some more thinking and may be data specific)
if not semantic_snippets[cur_idx].metadata['content_font'] or s[1] <= semantic_snippets[cur_idx].metadata['content_font']:
semantic_snippets[cur_idx].page_content += s[0]
semantic_snippets[cur_idx].metadata['content_font'] = max(s[1], semantic_snippets[cur_idx].metadata['content_font'])
continue
# if current snippet's font size > previous section's content but less than previous section's heading than also make a new
# section (e.g. title of a PDF will have the highest font size but we don't want it to subsume all sections)
metadata={'heading':s[0], 'content_font': 0, 'heading_font': s[1]}
metadata.update(data.metadata)
semantic_snippets.append(Document(page_content='',metadata=metadata))
cur_idx += 1
semantic_snippets[4]
6.6 其它加载器
- MathpixPDFLoader
from langchain.document_loaders import MathpixPDFLoader
loader = MathpixPDFLoader("example_data/layout-parser-paper.pdf")
data = loader.load()
- PyPDFium2
from langchain.document_loaders import PyPDFium2Loader
loader = PyPDFium2Loader("example_data/layout-parser-paper.pdf")
data = loader.load()
- PDFPlumber
与 PyMuPDF 一样,输出文档包含有关 PDF 及其页面的详细元数据,并每页返回一个文档。
from langchain.document_loaders import PDFPlumberLoader
loader = PDFPlumberLoader("example_data/layout-parser-paper.pdf")
data = loader.load()
data[0]
- OnlinePDFLoader
使用OnlinePDFLoader可加载远程的在线文档,例如网站https://open.umn.edu/opentextbooks/textbooks/ 和 https://arxiv.org/archive/。另外,它是一个旧版本的函数,不再推荐使用。相反,所有其他的PDF加载器也可以用于获取远程的PDF文件,如UnstructuredPDFLoader。
from langchain.document_loaders import OnlinePDFLoader
loader = OnlinePDFLoader("https://arxiv.org/pdf/2302.03803.pdf")
data = loader.load()
print(data)
- AmazonTextractPDFParser
-
AmazonTextractPDFLoader 调用 Amazon Textract Service 将 PDF 转换为文档结构。该加载程序目前执行纯 OCR,并根据需求计划提供更多功能,例如布局支持。支持最多 3000 页和 512 MB 大小的单页和多页文档。
-
使用前,需要一个 AWS 账户,类似于 AWS CLI 要求。除了 AWS 配置之外,AmazonTextractPDFParser与其他 PDF 加载器非常相似,同时还支持 JPEG、PNG 和 TIFF 以及非原生 PDF 格式。
-
from langchain.document_loaders import AmazonTextractPDFLoader
loader = AmazonTextractPDFLoader("example_data/alejandro_rosalez_sample-small.jpeg")
documents = loader.load()
七、MP4 视频
7.1 处理YouTube视频
你可以使用 YoutubeAudioLoader下载YouTube视频音频,并使用 OpenAIWhisperParse将音频转录为文本。首先安装必要的库:
! pip install yt_dlp
! pip install pydub
! pip install librosa
其中, yt_dlp 用于下载 YouTube 网址的音频, pydub 用于分割下载的音频文件。下面以Andrej Karpathy的YouTube课程第一讲为例:
from langchain.document_loaders.blob_loaders.youtube_audio import YoutubeAudioLoader
from langchain.document_loaders.generic import GenericLoader
from langchain.document_loaders.parsers import OpenAIWhisperParser,OpenAIWhisperParserLocal
# se
t a flag to switch between local and remote parsing
# change this to True if you want to use local parsing
local = False
注意:您需要提供 OPENAI_API_KEY
# Two Karpathy lecture videos
urls = ["https://youtu.be/kCc8FmEb1nY", "https://youtu.be/VMj-3S1tku0"]
# Directory to save audio files
save_dir = "~/Downloads/YouTube"
# Transcribe the videos to text
if local:
loader = GenericLoader(
YoutubeAudioLoader(urls, save_dir), OpenAIWhisperParserLocal()
)
else:
loader = GenericLoader(YoutubeAudioLoader(urls, save_dir), OpenAIWhisperParser())
docs = loader.load()
[youtube] Extracting URL: https://youtu.be/kCc8FmEb1nY
[youtube] kCc8FmEb1nY: Downloading webpage
[youtube] kCc8FmEb1nY: Downloading android player API JSON
[info] kCc8FmEb1nY: Downloading 1 format(s): 140
[dashsegments] Total fragments: 11
[download] Destination: /Users/31treehaus/Desktop/AI/langchain-fork/docs/modules/indexes/document_loaders/examples/Let's build GPT: from scratch, in code, spelled out..m4a
[download] 100% of 107.73MiB in 00:00:18 at 5.92MiB/s
[FixupM4a] Correcting container of "/Users/31treehaus/Desktop/AI/langchain-fork/docs/modules/indexes/document_loaders/examples/Let's build GPT: from scratch, in code, spelled out..m4a"
[ExtractAudio] Not converting audio /Users/31treehaus/Desktop/AI/langchain-fork/docs/modules/indexes/document_loaders/examples/Let's build GPT: from scratch, in code, spelled out..m4a; file is already in target format m4a
[youtube] Extracting URL: https://youtu.be/VMj-3S1tku0
[youtube] VMj-3S1tku0: Downloading webpage
[youtube] VMj-3S1tku0: Downloading android player API JSON
[info] VMj-3S1tku0: Downloading 1 format(s): 140
[download] /Users/31treehaus/Desktop/AI/langchain-fork/docs/modules/indexes/document_loaders/examples/The spelled-out intro to neural networks and backpropagation: building micrograd.m4a has already been downloaded
[download] 100% of 134.98MiB
[ExtractAudio] Not converting audio /Users/31treehaus/Desktop/AI/langchain-fork/docs/modules/indexes/document_loaders/examples/The spelled-out intro to neural networks and backpropagation: building micrograd.m4a; file is already in target format m4a
# Returns a list of Documents, which can be easily viewed or parsed
docs[0].page_content[0:500]
"Hello, my name is Andrej and I've been training deep neural networks for a bit more than a decade. And in this lecture I'd like to show you what neural network training looks like under the hood. So in particular we are going to start with a blank Jupyter notebook and by the end of this lecture we will define and train a neural net and you'll get to see everything that goes on under the hood and exactly sort of how that works on an intuitive level. Now specifically what I would like to do is I w"
7.2 从 YouTube 视频构建聊天应用程序
给定 Documents ,我们可以轻松启用chat / question+answering.。
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
from langchain.embeddings import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import FAISS
# Combine doc
combined_docs = [doc.page_content for doc in docs]
text = " ".join(combined_docs)
# Split them
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1500, chunk_overlap=150)
splits = text_splitter.split_text(text)
# Build an index
embeddings = OpenAIEmbeddings()
vectordb = FAISS.from_texts(splits, embeddings)
# Build a QA chain
qa_chain = RetrievalQA.from_chain_type(
llm=ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0),
chain_type="stuff",
retriever=vectordb.as_retriever(),
)
# Ask a question!
query = "Why do we need to zero out the gradient before backprop at each step?"
qa_chain.run(query)
"We need to zero out the gradient before backprop at each step because the backward pass accumulates gradients in the grad attribute of each parameter. If we don't reset the grad to zero before each backward pass, the gradients will accumulate and add up, leading to incorrect updates and slower convergence. By resetting the grad to zero before each backward pass, we ensure that the gradients are calculated correctly and that the optimization process works as intended."
query = "What is the difference between an encoder and decoder?"
qa_chain.run(query)
'In the context of transformers, an encoder is a component that reads in a sequence of input tokens and generates a sequence of hidden representations. On the other hand, a decoder is a component that takes in a sequence of hidden representations and generates a sequence of output tokens. The main difference between the two is that the encoder is used to encode the input sequence into a fixed-length representation, while the decoder is used to decode the fixed-length representation into an output sequence. In machine translation, for example, the encoder reads in the source language sentence and generates a fixed-length representation, which is then used by the decoder to generate the target language sentence.'
7.3 转录本地视频文件
参考llm-universe《知识库文档处理》
LangChain 提供了对 Youtube 视频进行爬取并转写的处理接口,但是如果我们想直接对我们的本地 MP4 视频进行处理,需要首先经过转录加载成文本格式,再加载到 LangChain 中。具体来说,我们使用 Whisper 实现视频的转写。
首先参考Whisper 官网来安装Whisper:
- 运行
sudo apt update && sudo apt install ffmpeg安装ffmpeg - 运行
pip install -U openai-whisper安装whisper
然后就可以在命令行使用whisper转录视频了。但是这样会先下载所用的whisper模型,有时候即使科学上网,下载速度也只有几十kb。运行whisper -h显示:
optional arguments:
-h, --help show this help message and exit
--model MODEL name of the Whisper model to use (default: small)
--model_dir MODEL_DIR
the path to save model files; uses ~/.cache/whisper by default (default: None)
可见模型会自动下载到~/.cache/whisper文件夹。接下来就在网好的时候运行以下代码下载模型
whisper ../../data_base/knowledge_db/easy_rl/强化学习入门指南.mp4 --model large --language zh --output_dir ../../data_base/knowledge_db/easy_rl
然后将缓存的模型复制到本地文件夹,接下来就可以使用本地模型来使用了(不知道为啥,运行总是中断,保错killed)。
cp -r ~/.cache/whisper /root/autodl-tmp/model/whisper
whisper ../../data_base/knowledge_db/easy_rl/强化学习入门指南.mp4 --model large --model_dir /root/autodl-tmp/model/whisper --language zh --output_dir ../../data_base/knowledge_db/easy_rl
八、File Directory
8.1 UnstructedLoader
在底层,默认情况下使用 UnstructedLoader加载目录下的文件。我们可以使用 glob 参数来控制加载哪些文件。请注意,此处它不会加载 .rst 文件或 .html 文件。
from langchain.document_loaders import DirectoryLoader
loader = DirectoryLoader('../', glob="**/*.md")
docs = loader.load()
len(docs)
1
此段代码中,glob参数用于指定要加载的文件的匹配模式。glob参数接受一个字符串,其中包含通配符和模式匹配规则,用于筛选要加载的文件。具体用法如下:
| 符号 | 描述 |
|---|---|
** | 匹配任意目录层级 |
* | 匹配任意字符(不包括目录分隔符) |
? | 匹配单个字符 |
[] | 匹配指定范围内的字符 |
! | 排除指定的字符或范围 |
在上述代码中,glob="**/*.md"表示要加载所有扩展名为.md的Markdown文件。**表示匹配任意目录层级,*表示匹配任意字符(不包括目录分隔符),.md表示匹配扩展名为.md的文件。
UnstructuredLoader提供了许多加载器,用于加载各种类型的文件,例如:
| 文件类型 | 加载器 | 支持情况 |
|---|---|---|
| HTML文件 | UnstructuredHTMLLoader | 可以加载 |
| RTF文件 | UnstructuredRTFLoader | 可以加载 |
| Markdown文件 | UnstructuredMarkdownLoader | 可以加载 |
| EPub文件 | UnstructuredEPubLoader | 可以加载 |
| Excel文件 | UnstructuredExcelLoader | 可以加载 |
| CSV文件 | UnstructuredCSVLoader | 可以加载 |
| JSON文件 | JSONLoader | 可以加载 |
| 图像文件 | UnstructuredImageLoader | 可以加载PNG和JPG |
| 音频文件 | YoutubeAudioLoader | 可以加载YouTube音频 |
| 视频字幕文件 | BiliBiliLoader | 可以加载BiliBili视频字幕 |
| 源代码文件 | PythonLoader | 可以加载Python源代码文件 |
8.2 显示进度条
要显示进度条,请安装 tqdm 库,并将 show_progress 参数设置为 True 。
loader = DirectoryLoader('../', glob="**/*.md", show_progress=True)
docs = loader.load()
Requirement already satisfied: tqdm in /Users/jon/.pyenv/versions/3.9.16/envs/microbiome-app/lib/python3.9/site-packages (4.65.0)
0it [00:00, ?it/s]
8.3 多线程加载
默认情况下是单线程加载,要使用多个线程,请设置 use_multithreading=true。
loader = DirectoryLoader('../', glob="**/*.md", use_multithreading=True)
docs = loader.load()
8.4 更改加载器
默认情况下,它使用 UnstructuredLoader 类。但是,您可以很容易地更改其它类型的加载器。
from langchain.document_loaders import TextLoader
loader = DirectoryLoader('../', glob="**/*.md", loader_cls=TextLoader)
docs = loader.load()
len(docs)
1
如果需要加载Python源代码文件,请使用 PythonLoader
from langchain.document_loaders import PythonLoader
loader = DirectoryLoader('../../../../../', glob="**/*.py", loader_cls=PythonLoader)
docs = loader.load()
len(docs)
691
8.5 加载文件时自动检测文件编码
在使用 TextLoader 从目录加载大量任意编码的多个文件时,可能会失败:
path = '../../../../../tests/integration_tests/examples'
loader = DirectoryLoader(path, glob="**/*.txt", loader_cls=TextLoader)
loader.load()
<pre style="white-space:pre;overflow-x:auto;line-height:normal;font-family:Menlo,'DejaVu Sans Mono',consolas,'Courier New',monospace"><span style="color: #800000; text-decoration-color: #800000">╭─────────────────────────────── </span><span style="color: #800000; text-decoration-color: #800000; font-weight: bold">Traceback </span><span
...
...
<span style="color: #ff0000; text-decoration-color: #ff0000; font-weight: bold">RuntimeError: </span>Error loading ..<span style="color: #800080; text-decoration-color: #800080">/../../../../tests/integration_tests/examples/</span><span style="color: #ff00ff; text-decoration-color: #ff00ff">example-non-utf8.txt</span>
</pre>
上述日志显示文件 example-non-utf8.txt load失败(因为使用了不同的编码),而TextLoader在默认情况下,任何加载失败的行为都会导致整个加载过程中断。我们可以在DirectoryLoader 中设置silent_errors=True,来跳过无法加载的文件并继续加载。
loader = DirectoryLoader(path, glob="**/*.txt", loader_cls=TextLoader, silent_errors=True)
docs = loader.load()
Error loading ../../../../../tests/integration_tests/examples/example-non-utf8.txt
doc_sources = [doc.metadata['source'] for doc in docs]
doc_sources
['../../../../../tests/integration_tests/examples/whatsapp_chat.txt',
'../../../../../tests/integration_tests/examples/example-utf8.txt']
更好的方式是向 DirectoryLoader传递autodetect_encoding参数,要求其在加载文件之前,自动检测文件编码。
text_loader_kwargs={'autodetect_encoding': True}
loader = DirectoryLoader(path, glob="**/*.txt", loader_cls=TextLoader, loader_kwargs=text_loader_kwargs)
docs = loader.load()
doc_sources = [doc.metadata['source'] for doc in docs]
doc_sources
['../../../../../tests/integration_tests/examples/example-non-utf8.txt',
'../../../../../tests/integration_tests/examples/whatsapp_chat.txt',
'../../../../../tests/integration_tests/examples/example-utf8.txt']



















 806
806

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











