







- 《OpenCV优秀文章集合》
- 《OpenCV系列课程一:图像处理入门(读写、拆分合并、变换、注释)、视频处理》
- 《OpenCV系列教程二:基本图像增强(数值运算)、滤波器(去噪、边缘检测)》
- 《OpenCV系列教程三:直方图、图像轮廓、形态学操作、车辆统计项目》
- 《OpenCV系列教程四:图像金字塔、特征检测与特征匹配,图像查找、对齐和拼接》
- 《OpenCV系列教程五:图像的分割与修复》
- 《OpenCV系列教程六:信用卡数字识别、人脸检测、车牌/答题卡识别、图片OCR》
- 《OpenCV系列教程七:虚拟计算器项目、目标追踪、SSD目标检测》
一、虚拟计算器项目
1.1 打开摄像头,正常显示画面
- 直接显示时窗口很小,可以通过resizeWindow调整显示窗口大小,也可以直接通过设置视频窗口大小达到同样的效果
- 摄像头显示的图像,和实际中的画面是呈镜面相反的,可以通过
flip函数进行翻转。
# 从打开摄像头, 显示每一帧图片开始
import numpy as np
import cv2
cap = cv2.VideoCapture(0)
# 设置窗口大小
cap.set(3, 1280)
cap.set(4, 720)
while True:
flag, img = cap.read()
if flag:
# 翻转摄像头显示的画面,flipCode>0表示水平翻转。
img = cv2.flip(img, 1)
cv2.imshow('img', img)
key = cv2.waitKey(1)
# 按下ESC键,关闭窗口
if key == 27:
break
else:
print('摄像头打开失败')
break
cap.release()
cv2.destroyAllWindows()
1.2 画出虚拟计算器
- 计算器的每个按键格子,通过先画灰色方框,再画黑色方框线的方式呈现
- 按键内部的数字通过
cv2.putText方法实现
下面是画出一个按键格的效果:
while True:
flag, img = cap.read()
if flag:
# 翻转摄像头显示的画面,flipCode>0表示水平翻转。
img = cv2.flip(img, 1)
# 先画一个实心的灰色矩形
cv2.rectangle(img, (1000, 300), (1000 + 100, 300 + 100), (225, 225, 225), -1)
# 再画矩形的边框
cv2.rectangle(img, (1000, 300), (1000 + 100, 300 + 100), (0, 0, 0), 3)
# 填入按键数字
cv2.putText(img, "0", (1000 + 30, 300 + 70), cv2.FONT_HERSHEY_PLAIN, 2, (50, 50, 50), 2)
cv2.imshow('img', img)
key = cv2.waitKey(1)
if key == 27:
break
else:
print('摄像头打开失败')
break
cap.release()
cv2.destroyAllWindows()

接下来,我们要通过画出多个按键的方式画出整个虚拟计算器,所以需要先创建一个button类来进行实现。
# 创建button类
class Button:
def __init__(self, pos, width, height, value):
self.pos = pos
self.width = width
self.height = height
self.value = value
def draw(self, img):
# 绘制一个计算器的小格子
# 先画一个实心的灰色矩形
cv2.rectangle(img, (self.pos[0], self.pos[1]), (self.pos[0] + self.width, self.pos[1] + self.height), (225, 225, 225), -1)
# 再画矩形的边框
cv2.rectangle(img, (self.pos[0], self.pos[1]), (self.pos[0] + self.width, self.pos[1] + self.height), (0, 0, 0), 3)
cv2.putText(img, self.value, (self.pos[0] + 30, self.pos[1] + 70), cv2.FONT_HERSHEY_PLAIN, 2, (50, 50, 50), 2)
测试一下,显示正常。
while True:
flag, img = cap.read()
if flag:
# 翻转摄像头显示的画面,flipCode>0表示水平翻转。
img = cv2.flip(img, 1)
Button((1000,300),100,100,'9').draw(img)
cv2.imshow('img', img)
...
...
下面通过for循环画出计算器的16格按键,最后通过硬编码方式画出计算器的结果显示窗格。
button_values = [['7', '8', '9', '*'],
['4', '5', '6', '-'],
['1', '2', '3', '+'],
['0', '/', '.', '=']]
button_list = []
for x in range(4):
for y in range(4):
x_pos = x * 100 + 800
y_pos = y * 100 + 150
button = Button((x_pos, y_pos), 100, 100, button_values[y][x])
button_list.append(button)
while True:
flag, img = cap.read()
if flag:
# 翻转摄像头显示的画面,flipCode>0表示水平翻转。
img = cv2.flip(img, 1)
for button in button_list:
button.draw(img)
# 创建显示结果的窗口,宽为1000*4,高度100不变
cv2.rectangle(img, (800, 70), (800 + 400, 70 + 100), (225, 225, 225), -1)
cv2.rectangle(img, (800, 70), (800 + 400, 70 + 100), (50, 50, 50), 3)
cv2.imshow('img', img)
...
...

1.3 检测手部动作
我们可以直接使用cvzone模块进行手的检测和追踪。CVZone 是一个开源的 Python 库,它基于 OpenCV 和 MediaPipe,简化了计算机视觉任务的实现,集成了多个计算机视觉库的功能,包括:
- 手部跟踪(Hand Tracking)
- 姿态估计(Pose Estimation)
- 面部检测(Face Detection)
- 物体跟踪(Object Tracking)
- 物体检测(Object Detection)
手部检测是 CVZone 的核心功能之一,手部检测功能基于 MediaPipe 的 Hand Tracking 模型,可以实时检测和跟踪手部的21个关键点。这些关键点包括手指的关节和手掌的部分。使用时,需要先初始化 HandDetector 对象:
detector = HandDetector(
staticMode=False, # 是否启用静态模式。对于实时视频处理,选择False;处理静态图片选择True
maxHands=2, # 设定一次可以检测的最大手数,如果你只需要检测一只手,可以将这个参数设为 1,这样可以提高检测效率。
modelComplexity=1, # 手部标记模型的复杂度,0或1
detectionCon=0.5, # 手部检测的最低置信度阈值,置信度越高,检测结果越可靠;置信度越低,可能导致检测不到手部或者误检测。
minTrackCon=0.5, # 跟踪置信度阈值,用此参数来控制追踪的可靠性。数值越高,要求手部的追踪效果越精确。
)
HandDetector 类提供了一系列方法,方便开发者获取手部的各种信息和处理手势识别:
findHands(image, draw=True,flipType=True):检测图像中的手部,返回手部关键点及其相关数据。draw=True表示在图像上绘制检测结果(关键点和包围框)。flipType=True:检测到的手的类型后,是否进行翻转。hands,image:返回值。前者是检测到的手部信息列表。每个手的信息包括lmList(21个关键点)、bbox(包围框)、center(中心点)、type: 手的类型(“Left” 或 “Right”)。image是带有绘制结果的图像。
findDistance(p1, p2, image=None):计算两个关键点之间的欧几里得距离。- 默认
image=None,如果提供,会在图像上显示这两个点的连接线和距离。 - 返回值为
distance, info, img,即计算出的距离、两个点及其中心点的点坐标信息和图像(如果有绘制)
- 默认
fingersUp(hand):判断手指的伸直与弯曲状态。- hand:包含手部信息的字典,即来自 findHands() 的返回值
- 返回一个列表,表示每根手指的状态,
1代表手指伸直,0代表手指弯曲
下面是简单的效果展示:
# 需要安装cvzone和mediapipe
# pip install cvzone mediapipe
from cvzone.HandTrackingModule import HandDetector
# 创建hand detector
detector = HandDetector(maxHands=1, detectionCon=0.8)
while True:
flag, img = cap.read()
if flag:
# 翻转摄像头显示的画面,flipCode>0表示水平翻转。
img = cv2.flip(img, 1)
# 画面已经被翻转过,所以需要设置flipType=False
hands, img = detector.findHands(img, flipType=False)
if hands:
print(hands)
# 获取第一只手的信息
hand1 = hands[0]
lmList = hand1["lmList"] # 21 个关键点坐标
bbox = hand1["bbox"] # 包围框
centerPoint = hand1["center"] # 手掌中心
handType = hand1["type"] # 左手或右手
# 显示手指状态
fingers = detector.fingersUp(hand1)
# 计算大拇指和食指之间的距离
distance, info, img = detector.findDistance(4, 8, img)
...
cv2.imshow('img', img)
...

可以看到,画面中没有手的时候,hands为空列表;画面检测出手之后,hands列表里,是图中手部那些检测点的位置坐标等信息。另外需要注意的是,一定要在画出计算器之前进行手的检测,否则当手移动到计算器里面,会检测失败。
1.4 计算逻辑
- 点击动作判断:当食指和中指夹紧一次(距离变短)就认为是点击了一次按键。如果是左手的话,食指和中指指尖的坐标是
lmList中的第8个和第12个元素。通过detector.findDistance可以直接计算其距离。测试中两指张开距离为90-110左右,两指夹紧距离为38-45左右。 - 在Button类中添加一个方法
check_click(self, x, y),- 判断食指坐标是否在某个按键框内。
- 如果在某个按键框,且食指和中指夹紧(距离小于50),就认为是点击了此按键,在按键内部填充一个白色的矩形,以此显示点击成功。
- 使用注释的方法,在计算结果显示框显示此按键的值。
- 初始化空字符串
equation,用于存储计算式。当遇到"="号时,使用eval(equation)可直接计算字符串数字的算式结果。
# 创建button类
class Button:
...
def check_click(self, x, y):
if self.pos[0] < x < self.pos[0] +self.width and self.pos[1] < y < self.pos[1] + self.height:
cv2.rectangle(img, (self.pos[0] + 3, self.pos[1] + 3),
(self.pos[0] + self.width -3, self.pos[1]+self.height -3),
(255, 255, 255), -1)
cv2.putText(img, self.value, (self.pos[0]+25, self.pos[1] + 80), cv2.FONT_HERSHEY_PLAIN, 5, (0, 0, 0), 5)
return True
else:
return False
1.5 完整代码
# 创建button类
class Button:
def __init__(self, pos, width, height, value):
self.pos = pos
self.width = width
self.height = height
self.value = value
def draw(self, img):
# 绘制一个计算器的小格子
# 先画一个实心的灰色矩形
cv2.rectangle(img, (self.pos[0], self.pos[1]), (self.pos[0] + self.width, self.pos[1] + self.height), (225, 225, 225), -1)
# 再画矩形的边框
cv2.rectangle(img, (self.pos[0], self.pos[1]), (self.pos[0] + self.width, self.pos[1] + self.height), (0, 0, 0), 3)
cv2.putText(img, self.value, (self.pos[0] + 30, self.pos[1] + 70), cv2.FONT_HERSHEY_PLAIN, 2, (50, 50, 50), 2)
def check_click(self, x, y):
if self.pos[0] < x < self.pos[0] +self.width and self.pos[1] < y < self.pos[1] + self.height:
cv2.rectangle(img, (self.pos[0] + 3, self.pos[1] + 3),
(self.pos[0] + self.width -3, self.pos[1]+self.height -3),
(255, 255, 255), -1)
cv2.putText(img, self.value, (self.pos[0]+25, self.pos[1] + 80), cv2.FONT_HERSHEY_PLAIN, 5, (0, 0, 0), 5)
return True
else:
return False
当前代码运行时还有一个问题,即当手指夹紧时,按键会被不停的重复点击,因为检测点击动作只是简单的判断手指距离小于50且在按键框内。有两个改进思路:
- 手指张开之后再夹紧才被算作一次点击动作。这样需要重写check_click方法,并加入distance参数,每一帧都不停的进行检测、计算。
- 添加一个延迟计数变量
delay_counter并初始化为0,当第一次检测到手指在某个按键框内时,delay_counter=0,点击有效,正常进行后续操作。完毕之后,设置delay_counter=1。然后再设置一个使delay_counter可以重新归零的代码就行。
import numpy as np
import cv2
from cvzone.HandTrackingModule import HandDetector
import time
cap = cv2.VideoCapture(0)
# 设置窗口大小.
cap.set(3, 1280)
cap.set(4, 720)
button_values = [['7', '8', '9', '*'],
['4', '5', '6', '-'],
['1', '2', '3', '+'],
['0', '/', '.', '=']]
button_list = []
for x in range(4):
for y in range(4):
x_pos = x * 100 + 800
y_pos = y * 100 + 150
button = Button((x_pos, y_pos), 100, 100, button_values[y][x])
button_list.append(button)
# 创建hand detector
detector = HandDetector(maxHands=1, detectionCon=0.8)
equation = ''
delay_counter = 0
while True:
flag, img = cap.read()
# 摄像头显示的画面和真实画面反掉了,要进行水平翻转
img = cv2.flip(img, 1)
# 检测手, 注意一定要在还没有绘制button之前去检测手.
hands, img = detector.findHands(img, flipType=False)
if flag:
# 绘制计算器
for button in button_list:
button.draw(img)
# 创建计算器结果显示窗口
cv2.rectangle(img, (800, 70), (800 + 400, 70 + 100), (225, 225, 225), -1)
cv2.rectangle(img, (800, 70), (800 + 400, 70 + 100), (50, 50, 50), 3)
if hands:
# 取出食指和中值的点, 计算两者的距离
lmlist = hands[0]['lmList']
# 最新版本的cvzone中,lmList坐标是三个值x,y,z,取出前两个值。
lmlist =[x[:2] for x in lmlist]
length, _, img = detector.findDistance(lmlist[8], lmlist[12], img)
# 取出食指坐标
x, y = lmlist[8]
# 根据食指和中指之间的距离进行判断, 如果小于50, 我们认为是进行了点击操作.
if length < 50 and delay_counter == 0:
for i, button in enumerate(button_list):
if button.check_click(x, y):
# 说明是一个正确点击. 应该要把点中的数字显示在窗口上.
value = button_values[int(i % 4)][int(i / 4)]
# 如果是'=', 说明要计算了.
if value == '=':
try:
equation = str(eval(equation))
except Exception:
# 非法的数学公式,需要重新输入
equation = ''
else:
# 字符串的拼接
equation += value
# sleep并不能完全解决重复点击的问题
# time.sleep(0.1)
delay_counter = 1
# 重置delay_counter, 避免短时间重复点击
# cv2.waitKey(1)是每毫秒检测一次,设置10毫秒之后才归零一次。
if delay_counter != 0:
delay_counter += 1
if delay_counter > 10:
delay_counter = 0
cv2.putText(img, equation, (810, 130), cv2.FONT_HERSHEY_PLAIN, 3, (0, 0, 0), 3)
cv2.imshow('img', img)
key = cv2.waitKey(1)
if key == ord('q'):
break
elif key == ord('c'):
# 清空输出框
equation = ''
else:
print('摄像头打开失败')
break
cap.release()
cv2.destroyAllWindows()
二、目标追踪
2.1 目标追踪简介
2.1.1 评测数据集——OTB&VOT
目标视觉跟踪(Visual Object Tracking)是计算机视觉领域的一个重要问题,目前广泛应用在体育赛事转播、安防监控和无人机、无人车、机器人等领域。
OTB50是一个包含50个视频序列的数据集,都经过人工标注,首次于2013年提出。这些视频序列涵盖了各种挑战,如光照变化、尺度变化、遮挡等。2015年提出了OTB100,包含了100个视频序列,其中涵盖了OTB50的所有序列。相关的数据集和测试代码库可以在Visual Tracker Benchmark的官方网站下载。

论文《Object tracking benchmark》总结了2012年及之前的29个顶尖的tracker,其速度与发表时间为:

在OTB100数据集上的结果为:

Struck, SCM, ASLA的性能比较高,排在前三;CSK第一次向世人展示了相关滤波的潜力,排第四还有362FPS。
目前比较常用的数据库除了OTB,还有VOT。VOT2015和VOT2016都包括60个序列,区别是OTB包括25%的灰度序列,但VOT都是彩色序列,这也是造成很多颜色特征算法性能差异的原因,两个库的评价指标不一样。对于一个tracker,如果论文在两个库(最好是OTB100和VOT2016)上都结果上佳,那肯定是非常优秀的。如果只跑了一个,个人更偏向于VOT2016,因为序列都是精细标注,且评价指标更好。
2012年以前的算法基本就是这样,自从2012年AlexNet问世以后,CV各个领域都有了巨大变化。按照时间顺序,目标跟踪的方法经历了从经典算法到基于核相关滤波算法,再到基于深度学习的跟踪算法的过程。
2.1.2 经典跟踪算法
早期的目标跟踪算法主要根据目标建模或者对目标特征进行跟踪,主要有两种:基于目标模型建模的方法和基于搜索的方法。
基于目标模型建模的方法:这种方法的核心在于建立一个目标的外观模型,并在后续帧中匹配该模型以定位目标。
- 区域匹配:
- 模板匹配:将目标在初始帧中的图像区域作为模板,在后续帧中通过滑动窗口的方式搜索与模板最相似的区域。
- 相关匹配:计算目标模板与搜索区域之间的相关性,通过相关性评分来确定目标位置。
- 特征点跟踪:
- SIFT(尺度不变特征变换):提取图像中的关键点,并生成这些点的描述符,这些描述符在图像缩放和旋转时保持不变。
- SURF(加速稳健特征):类似于SIFT,但计算更快,对图像的噪声和光照变化更加稳健。
- Harris角点检测:检测图像中的角点,这些角点在目标跟踪中作为特征点进行匹配。
- 基于主动轮廓的跟踪算法:
- snakes算法:通过能量最小化过程使轮廓形变,以匹配目标边缘。
- 光流法:利用图像序列中像素亮度的时空连续性,估计像素的运动轨迹,从而跟踪目标。光流法适用的范围较小, 需要满足三种假设:
- 图像的光照强度保持不变;
- 空间一致性, 即每个像素在不同帧中相邻点的位置不变, 这样便于求得最终的运动矢量;
- 时间连续.光流法适用于目标运动相对于帧率是缓慢的, 也就是两帧之间的目标位移不能太大。
基于搜索的方法:这种方法不是直接在整个图像上搜索目标,而是在预测的目标位置附近进行搜索,从而提高实时性。
- 预测算法:
- Kalman滤波:一种最优估计算法,可以预测目标在下一帧的位置,并减少搜索范围。
- 粒子滤波(Particle Filter):通过一系列随机样本(粒子)来表示目标的状态后验概率分布,适合处理非线性非高斯的动态系统。以跟踪为例,首先对跟踪目标进行建模,并定义一种相似度度量确定粒子与目标的匹配程度。在目标搜索的过程中,它会按照一定的分布(比如均匀分布或高斯分布)撒一些粒子,统计这些粒子的相似度,确定目标可能的位置。在这些位置上,下一帧加入更多新的粒子,确保在更大概率上跟踪上目标。
- 内核方法:
- Meanshift:通过迭代方式寻找数据集中最密集的区域,用于跟踪目标。该方法利用目标的颜色直方图,通过迭代逐步收敛到目标位置。Meanshift 适用于目标的色彩模型和背景差异比较大的情形,早期也用于人脸跟踪。由于 Meanshift 方法的快速计算,它的很多改进方法也一直适用至今。
- Camshift(连续自适应均值漂移):在Meanshift的基础上加入了目标大小和方向的变化,使其能够适应目标外观的变化。
基于目标模型建模的方法在目标外观变化不大时效果较好,但计算量大,实时性较差。基于搜索的方法通过缩小搜索范围,提高了实时性,但在目标快速运动或外观发生较大变化时,跟踪效果可能受到影响。
另外,这些方法没有将背景信息考虑在内, 导致在目标遮挡, 光照变化以及运动模糊等干扰下容易出现跟踪失败。随着技术的发展,基于深度学习的跟踪算法逐渐成为主流,它们在处理复杂场景和目标外观变化方面表现出色。
2.1.3 基于核相关滤波的跟踪算法
人们将通信领域的相关滤波(衡量两个信号的相似程度)引入到了目标跟踪中,一些基于相关滤波的跟踪算法(MOSSE、CSK、KCF、BACF、SAMF)也随之产生, 速度可以达到数百帧每秒,可以广泛地应用于实时跟踪系统中。
经典的高速相关滤波类跟踪算法有CSK,KCF/DCF,CN。KCF/DCF算法在OTB50上Precision和FPS碾压了OTB50上最好的Struck,是目标跟踪领域的第一篇相关滤波类方法,真正第一次显示了相关滤波的潜力。

和KCF同一时期的还有个CN,在2014’CVPR上引起剧烈反响的颜色特征方法,其实也是CSK的多通道颜色特征改进算法。从MOSSE(615)到 CSK(362) 再到 KCF(172FPS),DCF(292FPS),CN(152FPS),CN2(202FPS),速度虽然是越来越慢,但效果越来越好,而且始终保持在高速水平。
到了VOT2014竞赛 VOT2014 Benchmark 。这一年有25个精挑细选的序列,38个算法。此时深度学习的战火还没有烧到tracking,前三名都是相关滤波CF类方法,区别就是加了多尺度检测和子像素峰值估计:

前三名除了特征略有差异,核心都是KCF为基础扩展了多尺度检测。尺度变化是跟踪中比较基础和常见的问题,前面介绍的KCF/DCF和CN都没有尺度更新,如果目标缩小,滤波器就会学习到大量背景信息,如果目标扩大,滤波器就跟着目标局部纹理走了,这两种情况都很可能出现非预期的结果,导致漂移和失败。
SAMF 基于KCF,特征是HOG+CN,多尺度方法是平移滤波器在多尺度缩放的图像块上进行目标检测,取响应最大的那个平移位置及所在尺度。另外DSST只用了HOG特征,DCF用于平移位置检测,又专门训练类似MOSSE的相关滤波器检测尺度变化,开创了平移滤波+尺度滤波。

以上就是两种推荐的尺度检测方法,以后简称为类似DSST的多尺度和类似SAMF的多尺度。如果更看重速度,加速版的fDSST,和仅3个尺度的SAMF(如VOT2014中的KCF)就是比较好的选择;如果更看重精确,33个尺度的DSST,及7个尺度的SAMF就比较合适。
2.1.4 深度学习算法
总体来说,相关滤波类方法对快速变形和快速运动情况的跟踪效果不好。随着深度学习方法的广泛应用, 人们开始考虑将其应用到目标跟踪中。在大数据背景下,利用深度学习训练网络模型,得到的卷积特征输出表达能力更强。
VOT2015竞赛 VOT2015 Challenge | Home ,这一年有60个精挑细选的序列,62个tracker。最大看点是深度学习开始进击tracking领域,MDNet直接拿下当年的冠军,而结合深度特征的相关滤波方法DeepSRDCF是第二名,主要解决边界效应的SRDCF仅HOG特征排在第四:

除了上面介绍的深度学习和相关滤波,还有结合object proposals(类物体区域检测)的EBT排第三。实时算法推荐Mean-Shift类颜色算法ASMS和DAT。此时排在第9的那个Struck已经不是原来的Struck了。除此之外,经典方法如OAB, STC, CMT, CT, NCC等都排在倒数位置, 已经被远远甩在后面。
到了VOT2016竞赛,深度学习已经雄霸天下了,8个纯CNN方法和6个结合深度特征的CF方法大都名列前茅,还有一片的CF方法。举办方公开了他们能拿到的38个tracker,部分tracker代码和主页下载地址为VOT2016 Challenge | Trackers。

高亮标出来了前面介绍过的或比较重要的方法,结合多层深度特征的相关滤波C-COT排第一名,而CNN方法TCNN是VOT2016的冠军,作者也是VOT2015冠军MDNet,纯颜色方法DAT和ASMS都在中等水平(其实两种方法实测表现非常接近)。
再来看速度,SMACF(排名25)和ASMS(排名32))都非常快,排在前10的方法中也有两个速度比较快,分别是Staple(排名第5),和其改进算法排第9的STAPLE+(排名第9,推荐实时算法)。
下图是相关滤波和是深度学习两类算法的介绍简图:

- 相比于光流法、Kalman、Meanshift等传统算法,相关滤波类算法跟踪速度更快,深度学习类方法精度高.
- 具有多特征融合以及深度特征的追踪器在跟踪精度方面的效果更好.
- 使用强大的分类器是实现良好跟踪的基础.
- 尺度的自适应以及模型的更新机制也影响着跟踪的精度.
2.1.5 long-term
以前提到的很多CF算法,也包括VOT竞赛,都是针对短期(short-term,100~500帧)的跟踪问题。但在实际应用场合,我们希望正确跟踪时间长一点,如几分钟或十几分钟,这就是长期(long-term)跟踪问题。前面介绍的方法不适合这种应用场合,必须是short-term tracker + detecter配合才能实现正确的长期跟踪,给普通tracker配一个detecter,在发现跟踪出错的时候调用自带detecter重新检测并矫正tracker。
CF方向一篇比较有代表性的long-term方法是Chao Ma的LCT。LCT在DSST一个平移相关滤波Rc和一个尺度相关滤波的基础上,又加入第三个负责检测目标置信度的相关滤波Rt,检测模块Online Detector是TLD中所用的随机蔟分类器(random fern),在代码中改为SVM。第三个置信度滤波类似MOSSE不加padding,而且特征也不加cosine窗,放在平移检测之后。
- 如果最大响应小于第一个阈值(叫运动阈值),说明平移检测不可靠,调用检测模块重新检测。注意,重新检测的结果并不是都采纳的,只有第二次检测的最大响应值比第一次检测大1.5倍时才接纳,否则,依然采用平移检测的结果。
- 如果最大响应大于第二个阈值(叫外观阈值),说明平移检测足够可信,这时候才以固定学习率在线更新第三个相关滤波器和随机蔟分类器。注意,前两个相关滤波的更新与DSST一样,固定学习率在线每帧更新。
LCT加入检测机制,对遮挡和出视野等情况理论上较好,速度27fps,实验只跑了OTB-2013,跟踪精度非常高。另外TLD也可以期待。
跟踪算法需要能反映每一次跟踪结果的可靠程度,这一点非常重要,不然就可能造成跟丢了还不知道的情况,也就是跟踪置信度。LMCF提出了多峰检测和高置信度更新。
2.1.6 Opencv目标追踪算法简介
OpenCV 提供了多种用于目标追踪(Object Tracking)的算法,以下是简单总结:
| 算法 | 算法类别 | 精度 | 速度 | 适用场景 |
|---|---|---|---|---|
| BOOSTING | 基于目标模型建模的方法 | 低 | 慢 | 早期算法,适合简单场景 |
| MIL | 基于目标模型建模的方法 | 中 | 中 | 可以处理跟踪过程中的部分遮挡、旋转或尺度变化,复杂背景下表现不佳,计算资源消耗较高 |
| KCF | 基于核相关滤波的跟踪算法 | 中 | 快 | 速度快,性能良好,适合实时应用。处理目标快速变化或大范围移动时效果不佳 |
| TLD | 结合基于模型和搜索方法 | 高 | 慢 | 能够检测和重新识别目标,即使目标短暂消失或遮挡后也能重新捕捉。缺点是处理复杂场景时,容易产生误检 |
| MEDIANFLOW | 基于搜索的方法(点轨迹和运动估计) | 高 | 慢 | 在目标缓慢移动和变化较少的情况下表现优异 |
| MOSSE | 基于相关滤波的跟踪算法(简化版本) | 低 | 非常快 | 极快的追踪速度,适用于实时应用和计算资源有限的场景。精度低,对光照变化和目标变形的鲁棒性较差。 |
| CSRT | 增强的核相关滤波的算法 | 高 | 较慢 | 比 KCF,CSRT 更加准确,能够处理尺度变化、部分遮挡、光照变化等复杂场景 |
| GOTURN | 基于深度学习的跟踪算法 | 中 | 中 | 深度学习方法,适合少量变化的场景。对于旋转、遮挡效果不佳 |
| DaSiamRPN | 基于孪生网络的目标跟踪 | 高 | 中 | 可以处理复杂、尺度和外观变化的场景 ,但是计算资源消耗大,对硬件要求较高 |
在OpenCV中,cv2.Tracker类是一个用于目标跟踪的高级接口。它提供了一种简便的方式来实现视频中对象的跟踪。使用时,你需要创建并初始化目标追踪器,定义目标的初始位置。随后,逐帧读取视频帧,并在每一帧中更新目标位置(update方法)。
2.2 示例一:车辆追踪
# 在jupyter中直接显示视频
from IPython.display import HTML
HTML("""
<video width=1024 controls>
<source src="race_car_preview.mp4" type="video/mp4">
</video>
""")

2.2.1 定义辅助函数
import cv2
import sys
import os
import matplotlib.pyplot as plt
from matplotlib.animation import FuncAnimation
from IPython.display import HTML
import urllib
video_input_file_name = "race_car.mp4"
# 标注矩形
def drawRectangle(frame, bbox):
p1 = (int(bbox[0]), int(bbox[1]))
p2 = (int(bbox[0] + bbox[2]), int(bbox[1] + bbox[3]))
# 以p1/p2为左上右下角点画矩形,颜色为蓝色。线条宽度为2,类型为1
cv2.rectangle(frame, p1, p2, (255,0,0), 2, 1)
# 显示标注图像
def displayRectangle(frame, bbox):
plt.figure(figsize=(20,10))
frameCopy = frame.copy()
drawRectangle(frameCopy, bbox)
frameCopy = cv2.cvtColor(frameCopy, cv2.COLOR_RGB2BGR)
plt.imshow(frameCopy); plt.axis('off')
# 添加注释,字体类型cv2.FONT_HERSHEY_SIMPLEX,字体比例=1,宽度为3
def drawText(frame, txt, location, color = (50,170,50)):
cv2.putText(frame, txt, location, cv2.FONT_HERSHEY_SIMPLEX, 1, color, 3)
2.2.2 创建Tracker实例
首先要安装tracker包,版本号要和自己的opencv-python版本一致
pip install opencv-contrib-python==4.5.2.54
cv2.Tracker类本身是一个抽象基类,它不能直接实例化。相反,你需要使用特定的跟踪器创建函数来创建一个具体的跟踪器实例。下面创建跟踪器类型的列表tracker_types,可以通过修改索引来选择不同的跟踪器类型,并创建相应的跟踪器对象。
tracker_types = ['BOOSTING', 'MIL','KCF', 'CSRT', 'TLD', 'MEDIANFLOW', 'GOTURN','MOSSE']
# Change the index to change the tracker type
tracker_type = tracker_types[2]
if tracker_type == 'BOOSTING':
tracker = cv2.legacy_TrackerBoosting.create()
elif tracker_type == 'MIL':
tracker = cv2.TrackerMIL_create()
elif tracker_type == 'KCF':
tracker = cv2.TrackerKCF_create()
elif tracker_type == 'CSRT':
tracker = cv2.legacy_TrackerCSRT.create()
elif tracker_type == 'TLD':
tracker = cv2.legacy_TrackerTLD.create()
elif tracker_type == 'MEDIANFLOW':
tracker = cv2.legacy_TrackerMedianFlow.create()
elif tracker_type == 'GOTURN':
tracker = cv2.TrackerGOTURN_create()
else:
tracker = cv2.legacy_TrackerMOSSE.create()
2.2.3 读取视频,定义初始边界框
# 读取视频
video = cv2.VideoCapture(video_input_file_name)
flag, frame = video.read()
# 如果视频没有打开
if not video.isOpened():
print("Could not open video")
sys.exit()
# 获取帧的宽高
else :
width = int(video.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(video.get(cv2.CAP_PROP_FRAME_HEIGHT))
# 定义输出视频的文件名,并创建一个cv2.VideoWriter对象用于写入处理后的帧
video_output_file_name = 'race_car-' + tracker_type + '.mp4'
video_out = cv2.VideoWriter(video_output_file_name,cv2.VideoWriter_fourcc(*'avc1'), 10, (width, height))
# 定义第一帧的边界框,或者使用cv2.selectROI让用户选择
bbox = (1300, 405, 160, 120)
#bbox = cv2.selectROI(frame, False)
#print(bbox)
displayRectangle(frame,bbox)
# 初始化边界框(init方法,返回一个布尔值,表示是否完成初始化)
ok = tracker.init(frame, bbox)

2.2.4 逐帧读取并追踪目标
while True:
flag, frame = video.read()
if not flag:
break
# Start timer
timer = cv2.getTickCount()
# Update tracker
ok, bbox = tracker.update(frame)
# 计算帧率 (FPS)
fps = cv2.getTickFrequency() / (cv2.getTickCount() - timer);
# 画出边界框
if ok:
drawRectangle(frame, bbox)
else :
drawText(frame, "Tracking failure detected", (80,140), (0, 0, 255))
# 在帧上绘制跟踪器类型和帧率信息
drawText(frame, tracker_type + " Tracker", (80,60))
drawText(frame, "FPS : " + str(int(fps)), (80,100))
# 将处理后的帧写入输出视频
video_out.write(frame)
video.release()
video_out.release()
查看跟着效果
# Tracker: KCF
HTML("""
<video width=1024 controls>
<source src="race_car-KCF.mp4" type="video/mp4">
</video>
""")

改进:在实际应用中,可能需要添加异常处理来确保代码的健壮性。
2.3 案例二:体育赛事
import cv2
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('-v', '--video', type=str, help='path to input video file')
parser.add_argument('-t', '--tracker', type=str, default='kcf', help='OpenCV object tracker type')
args = vars(ap.parse_args())
# 定义OpenCV中的七种目标追踪算法
OPENCV_OBJECT_TRACKERS = {
'boosting': cv2.legacy_TrackerBoosting.create,
'csrt': cv2.legacy_TrackerCSRT.create,
'kcf': cv2.legacy.TrackerKCF.create,
'mil': cv2.legacy.TrackerMIL.create,
'tld': cv2.legacy_TrackerTLD.create,
'medianflow': cv2.legacy_TrackerMedianFlow.create,
'mosse': cv2.legacy_TrackerMOSSE.create
}
trackers = cv2.legacy.MultiTracker_create()
cap = cv2.VideoCapture(args['video'])
while True:
flag, frame = cap.read()
if frame is None:
break
# 追踪目标
success, boxes = trackers.update(frame)
# 绘制追踪到的矩形区域
for box in boxes:
# box是个浮点型, 画图需要整型
(x, y, w, h) = [int(v) for v in box]
cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 255, 0), 2)
cv2.imshow('frame', frame)
key = cv2.waitKey(100)
if key == ord('s'):
# 框选ROI区域
roi = cv2.selectROI('frame', frame, showCrosshair=True, fromCenter=False)
# print(roi)
# 创建一个实际的目标追踪器
tracker = OPENCV_OBJECT_TRACKERS[args['tracker']]()
trackers.add(tracker, frame, roi)
elif key == 27:
break
cap.release()
cv2.destroyAllWindows()
# 直接在命令行运行:
C:\Users\LS\Desktop\opencv\代码>python 目标追踪.py -v ./videos/soccer_01.mp4 -t csrt

- 代码中我们使用了
selectROI函数。此函数允许用户交互式地选择图像中的感兴趣区域(ROI),其函数签名为:
selectROI(windowName, img[, showCrosshair[, fromCenter[, printNotice]]]) -> retval
windowName:这是显示选择过程的窗口的名称。img:这是用于选择 ROI 的图像。showCrosshair:可选,如果设置为 True,则会显示用于选择矩形的十字准线。fromCenter:可选,如果设置为 True,则选择的原点将匹配初始鼠标位置,一般不用。
当我们按下s键并使用鼠标左键框选之后,这个函数会返回所选区域的坐标,格式为 [x, y, width, height]。此时查看jupyter启动窗口,显示:

即鼠标左键框选ROI区域之后,按下空格键或enter键进行确认,按下c键可以取消。
cv2.legacy是 OpenCV 4.5 及以上版本中的一个命名空间,专门用于包含旧版(legacy)API 的功能。这些旧版功能在新版本中可能已经被修改或替换,但为了向后兼容,OpenCV 仍然提供了这些旧版 API 的访问方式。上述代码中,cv::legacy.MultiTracker需要使用cv::legacy.Tracker类型的追踪器,如果不写这个会报错。
三、使用深度学习模型进行目标检测(SSD)
YOLOv8项目实践——目标检测、实例分割、姿态估计、目标追踪算法原理及模型部署(Python实现带界面)、
AI项目十九:YOLOV8实现目标追踪
3.1 在opencv中使用深度学习模块
cv2.dnn 是 OpenCV 的深度学习模块,用于加载和运行深度学习模型。它支持多种流行的框架(如 TensorFlow、Caffe 和 ONNX),使得在计算机视觉应用中集成深度学习变得更加简单。以下是 cv2.dnn 的一些关键功能和使用方法:
-
加载模型:使用
cv2.dnn.readNet加载预训练的模型及其配置文件,支持多种格式(如.caffemodel,.pb,.onnx等),最终返回一个网络。- model: 字符串,模型文件的路径(例如
.caffemodel,.pb,.onnx)。 - config: 字符串,模型的配置文件路径(例如 Caffe 的
.prototxt文件)。 - framework: 字符串(可选),指定框架类型,如
'caffe'、'tensorflow'、'onnx'等。根据文件类型自动推断时,该参数可以省略。
- model: 字符串,模型文件的路径(例如
-
创建Blob:使用
cv2.dnn.blobFromImage函数将图像转换为深度学习模型所需的输入格式,包括尺寸调整、归一化等操作。最终返回一个“Blob”对象,用作模型的输入。- image: 输入图像,可以是 NumPy 数组(如从
cv2.imread读取的图像)。 - scalefactor: 浮点数,缩放因子,通常用于将像素值从 [0, 255] 转换到 [0, 1]。
- size: 元组,目标尺寸(宽度,高度),通常为模型的输入尺寸(如
(416, 416))。 - mean: 元组,均值值,用于从图像中减去均值,通常用于归一化。
- swapRB: 布尔值,是否交换 R 和 B 通道。YOLO 模型一般需要设置为
True。 - crop: 布尔值,是否裁剪图像。一般设置为
False。
- image: 输入图像,可以是 NumPy 数组(如从
-
前向传播:通过
net.forward()方法执行模型的前向传播,获取输出。可以指定特定的层进行输出。 -
非极大值抑制:结合
cv2.dnn.NMSBoxes使用,帮助过滤重复的检测结果,提高目标检测的精度。最后返回被选择框的索引列表,表示通过非极大值抑制后保留的框。- boxes: 列表,每个元素是一个检测框(格式为
[x, y, w, h])。 - scores: 列表,检测框的置信度分数。
- score_threshold: 浮点数,置信度的阈值,低于该值的框将被忽略。
- nms_threshold: 浮点数,用于决定框的重叠程度。IoU(交并比)大于此值的框将被视为重复框。
- boxes: 列表,每个元素是一个检测框(格式为
3.2 使用SSD模型进行目标检测
3.2.1 从 Tensorflow 模型 ZOO 下载模型文件
你可以直接从TensorFlow 2 Detection Model Zoo下载TF的目标检测模型,比如ssd_mobilenet_v2模型,解压后放入models 文件夹:
ssd_mobilenet_v2_coco_2018_03_29
|─ checkpoint
|─ frozen_inference_graph.pb
|─ model.ckpt.data-00000-of-00001
|─ model.ckpt.index
|─ model.ckpt.meta
|─ pipeline.config
|─ saved_model
|─── saved_model.pb
|─── variables
或者直接运行以下代码自动下载:
import os
import cv2
import numpy as np
import urllib
import matplotlib.pyplot as plt
%matplotlib inline
modelFile = "models/ssd_mobilenet_v2_coco_2018_03_29/frozen_inference_graph.pb"
configFile = "models/ssd_mobilenet_v2_coco_2018_03_29.pbtxt"
classFile = "coco_class_labels.txt"
if not os.path.isdir('models'):
os.mkdir("models")
if not os.path.isfile(modelFile):
os.chdir("models")
# Download the tensorflow Model
urllib.request.urlretrieve('http://download.tensorflow.org/models/object_detection/ssd_mobilenet_v2_coco_2018_03_29.tar.gz', 'ssd_mobilenet_v2_coco_2018_03_29.tar.gz')
# Uncompress the file
!tar -xvf ssd_mobilenet_v2_coco_2018_03_29.tar.gz
# Delete the tar.gz file
os.remove('ssd_mobilenet_v2_coco_2018_03_29.tar.gz')
# Come back to the previous directory
os.chdir("..")
# 检测class labels
with open(classFile) as fp:
labels = fp.read().split("\n")
print(labels)
['unlabeled', 'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light', 'fire hydrant', 'street sign', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow', 'elephant', 'bear', 'zebra', 'giraffe', 'hat', 'backpack', 'umbrella', 'shoe', 'eye glasses', 'handbag', 'tie', 'suitcase', 'frisbee', 'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard', 'tennis racket', 'bottle', 'plate', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple', 'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch', 'potted plant', 'bed', 'mirror', 'dining table', 'window', 'desk', 'toilet', 'door', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone', 'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'blender', 'book', 'clock', 'vase', 'scissors', 'teddy bear', 'hair drier', 'toothbrush', 'hair brush', '']
3.2.2 定义检测函数
# 定义检测函数
def detect_objects(net, im):
dim = 300
blob = cv2.dnn.blobFromImage(im, 1.0, size=(dim, dim), mean=(0,0,0), swapRB=True, crop=False)
net.setInput(blob)
objects = net.forward()
return objects
# 定义注释函数,展示结果
def display_text(im, text, x, y):
# Get text size
textSize = cv2.getTextSize(text, FONTFACE, FONT_SCALE, THICKNESS)
dim = textSize[0]
baseline = textSize[1]
# Use text size to create a black rectangle
cv2.rectangle(im, (x,y-dim[1] - baseline), (x + dim[0], y + baseline), (0,0,0), cv2.FILLED);
# Display text inside the rectangle
cv2.putText(im, text, (x, y-5 ), FONTFACE, FONT_SCALE, (0, 255, 255), THICKNESS, cv2.LINE_AA)
def display_objects(im, objects, threshold = 0.25):
rows = im.shape[0]; cols = im.shape[1]
# For every Detected Object
for i in range(objects.shape[2]):
# Find the class and confidence
classId = int(objects[0, 0, i, 1])
score = float(objects[0, 0, i, 2])
# Recover original cordinates from normalized coordinates
x = int(objects[0, 0, i, 3] * cols)
y = int(objects[0, 0, i, 4] * rows)
w = int(objects[0, 0, i, 5] * cols - x)
h = int(objects[0, 0, i, 6] * rows - y)
# Check if the detection is of good quality
if score > threshold:
display_text(im, "{}".format(labels[classId]), x, y)
cv2.rectangle(im, (x, y), (x + w, y + h), (255, 255, 255), 2)
# Convert Image to RGB since we are using Matplotlib for displaying image
mp_img = cv2.cvtColor(im, cv2.COLOR_BGR2RGB)
plt.figure(figsize=(30,10)); plt.imshow(mp_img); plt.show();
3.2.3 推理
FONTFACE = cv2.FONT_HERSHEY_SIMPLEX
FONT_SCALE = 0.7
THICKNESS = 1
net = cv2.dnn.readNetFromTensorflow(modelFile, configFile)
im = cv2.imread('images/street.jpg')
objects = detect_objects(net, im)
display_objects(im, objects)
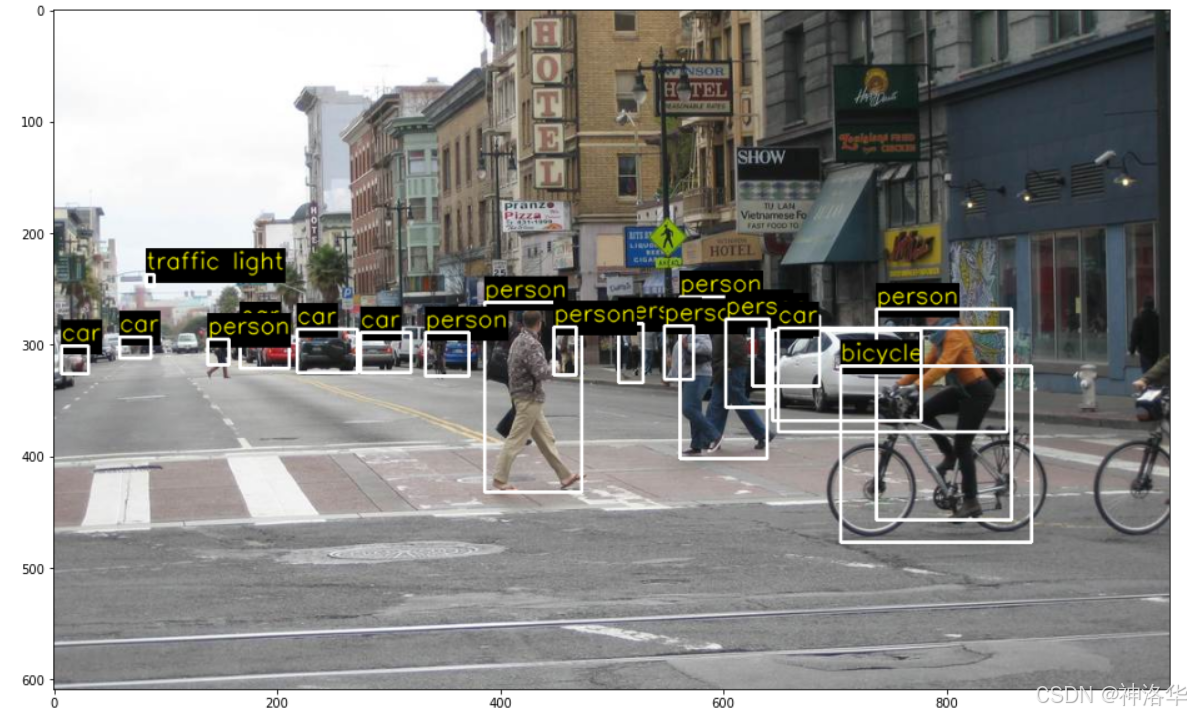
im = cv2.imread('images/baseball.jpg')
objects = detect_objects(net, im)
display_objects(im, objects, 0.2)

3.2.4 py文件
# This file is a part of OpenCV project.
# It is a subject to the license terms in the LICENSE file found in the top-level directory
# of this distribution and at http://opencv.org/license.html.
#
# Copyright (C) 2018, Intel Corporation, all rights reserved.
# Third party copyrights are property of their respective owners.
#
# Use this script to get the text graph representation (.pbtxt) of SSD-based
# deep learning network trained in TensorFlow Object Detection API.
# Then you can import it with a binary frozen graph (.pb) using readNetFromTensorflow() function.
# See details and examples on the following wiki page: https://github.com/opencv/opencv/wiki/TensorFlow-Object-Detection-API
import tensorflow as tf
import argparse
from math import sqrt
from tensorflow.core.framework.node_def_pb2 import NodeDef
from tensorflow.tools.graph_transforms import TransformGraph
from google.protobuf import text_format
parser = argparse.ArgumentParser(description='Run this script to get a text graph of '
'SSD model from TensorFlow Object Detection API. '
'Then pass it with .pb file to cv::dnn::readNetFromTensorflow function.')
parser.add_argument('--input', required=True, help='Path to frozen TensorFlow graph.')
parser.add_argument('--output', required=True, help='Path to output text graph.')
parser.add_argument('--num_classes', default=90, type=int, help='Number of trained classes.')
parser.add_argument('--min_scale', default=0.2, type=float, help='Hyper-parameter of ssd_anchor_generator from config file.')
parser.add_argument('--max_scale', default=0.95, type=float, help='Hyper-parameter of ssd_anchor_generator from config file.')
parser.add_argument('--num_layers', default=6, type=int, help='Hyper-parameter of ssd_anchor_generator from config file.')
parser.add_argument('--aspect_ratios', default=[1.0, 2.0, 0.5, 3.0, 0.333], type=float, nargs='+',
help='Hyper-parameter of ssd_anchor_generator from config file.')
parser.add_argument('--image_width', default=300, type=int, help='Training images width.')
parser.add_argument('--image_height', default=300, type=int, help='Training images height.')
args = parser.parse_args()
# Nodes that should be kept.
keepOps = ['Conv2D', 'BiasAdd', 'Add', 'Relu6', 'Placeholder', 'FusedBatchNorm',
'DepthwiseConv2dNative', 'ConcatV2', 'Mul', 'MaxPool', 'AvgPool', 'Identity']
# Nodes attributes that could be removed because they are not used during import.
unusedAttrs = ['T', 'data_format', 'Tshape', 'N', 'Tidx', 'Tdim', 'use_cudnn_on_gpu',
'Index', 'Tperm', 'is_training', 'Tpaddings']
# Node with which prefixes should be removed
prefixesToRemove = ('MultipleGridAnchorGenerator/', 'Postprocessor/', 'Preprocessor/')
# Read the graph.
with tf.gfile.FastGFile(args.input, 'rb') as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
inpNames = ['image_tensor']
outNames = ['num_detections', 'detection_scores', 'detection_boxes', 'detection_classes']
graph_def = TransformGraph(graph_def, inpNames, outNames, ['sort_by_execution_order'])
def getUnconnectedNodes():
unconnected = []
for node in graph_def.node:
unconnected.append(node.name)
for inp in node.input:
if inp in unconnected:
unconnected.remove(inp)
return unconnected
removedNodes = []
# Detect unfused batch normalization nodes and fuse them.
def fuse_batch_normalization():
# Add_0 <-- moving_variance, add_y
# Rsqrt <-- Add_0
# Mul_0 <-- Rsqrt, gamma
# Mul_1 <-- input, Mul_0
# Mul_2 <-- moving_mean, Mul_0
# Sub_0 <-- beta, Mul_2
# Add_1 <-- Mul_1, Sub_0
nodesMap = {node.name: node for node in graph_def.node}
subgraph = ['Add',
['Mul', 'input', ['Mul', ['Rsqrt', ['Add', 'moving_variance', 'add_y']], 'gamma']],
['Sub', 'beta', ['Mul', 'moving_mean', 'Mul_0']]]
def checkSubgraph(node, targetNode, inputs, fusedNodes):
op = targetNode[0]
if node.op == op and (len(node.input) >= len(targetNode) - 1):
fusedNodes.append(node)
for i, inpOp in enumerate(targetNode[1:]):
if isinstance(inpOp, list):
if not node.input[i] in nodesMap or \
not checkSubgraph(nodesMap[node.input[i]], inpOp, inputs, fusedNodes):
return False
else:
inputs[inpOp] = node.input[i]
return True
else:
return False
nodesToRemove = []
for node in graph_def.node:
inputs = {}
fusedNodes = []
if checkSubgraph(node, subgraph, inputs, fusedNodes):
name = node.name
node.Clear()
node.name = name
node.op = 'FusedBatchNorm'
node.input.append(inputs['input'])
node.input.append(inputs['gamma'])
node.input.append(inputs['beta'])
node.input.append(inputs['moving_mean'])
node.input.append(inputs['moving_variance'])
text_format.Merge('f: 0.001', node.attr["epsilon"])
nodesToRemove += fusedNodes[1:]
for node in nodesToRemove:
graph_def.node.remove(node)
fuse_batch_normalization()
# Removes Identity nodes
def removeIdentity():
identities = {}
for node in graph_def.node:
if node.op == 'Identity':
identities[node.name] = node.input[0]
graph_def.node.remove(node)
for node in graph_def.node:
for i in range(len(node.input)):
if node.input[i] in identities:
node.input[i] = identities[node.input[i]]
removeIdentity()
# Remove extra nodes and attributes.
for i in reversed(range(len(graph_def.node))):
op = graph_def.node[i].op
name = graph_def.node[i].name
if (not op in keepOps) or name.startswith(prefixesToRemove):
if op != 'Const':
removedNodes.append(name)
del graph_def.node[i]
else:
for attr in unusedAttrs:
if attr in graph_def.node[i].attr:
del graph_def.node[i].attr[attr]
# Remove references to removed nodes except Const nodes.
for node in graph_def.node:
for i in reversed(range(len(node.input))):
if node.input[i] in removedNodes:
del node.input[i]
# Connect input node to the first layer
assert(graph_def.node[0].op == 'Placeholder')
# assert(graph_def.node[1].op == 'Conv2D')
weights = graph_def.node[1].input[0]
for i in range(len(graph_def.node[1].input)):
graph_def.node[1].input.pop()
graph_def.node[1].input.append(graph_def.node[0].name)
graph_def.node[1].input.append(weights)
# Create SSD postprocessing head ###############################################
# Concatenate predictions of classes, predictions of bounding boxes and proposals.
def tensorMsg(values):
if all([isinstance(v, float) for v in values]):
dtype = 'DT_FLOAT'
field = 'float_val'
elif all([isinstance(v, int) for v in values]):
dtype = 'DT_INT32'
field = 'int_val'
else:
raise Exception('Wrong values types')
msg = 'tensor { dtype: ' + dtype + ' tensor_shape { dim { size: %d } }' % len(values)
for value in values:
msg += '%s: %s ' % (field, str(value))
return msg + '}'
def addConstNode(name, values):
node = NodeDef()
node.name = name
node.op = 'Const'
text_format.Merge(tensorMsg(values), node.attr["value"])
graph_def.node.extend([node])
def addConcatNode(name, inputs, axisNodeName):
concat = NodeDef()
concat.name = name
concat.op = 'ConcatV2'
for inp in inputs:
concat.input.append(inp)
concat.input.append(axisNodeName)
graph_def.node.extend([concat])
addConstNode('concat/axis_flatten', [-1])
addConstNode('PriorBox/concat/axis', [-2])
for label in ['ClassPredictor', 'BoxEncodingPredictor']:
concatInputs = []
for i in range(args.num_layers):
# Flatten predictions
flatten = NodeDef()
inpName = 'BoxPredictor_%d/%s/BiasAdd' % (i, label)
flatten.input.append(inpName)
flatten.name = inpName + '/Flatten'
flatten.op = 'Flatten'
concatInputs.append(flatten.name)
graph_def.node.extend([flatten])
addConcatNode('%s/concat' % label, concatInputs, 'concat/axis_flatten')
# Add layers that generate anchors (bounding boxes proposals).
scales = [args.min_scale + (args.max_scale - args.min_scale) * i / (args.num_layers - 1)
for i in range(args.num_layers)] + [1.0]
priorBoxes = []
addConstNode('reshape_prior_boxes_to_4d', [1, 2, -1, 1])
for i in range(args.num_layers):
priorBox = NodeDef()
priorBox.name = 'PriorBox_%d' % i
priorBox.op = 'PriorBox'
priorBox.input.append('BoxPredictor_%d/BoxEncodingPredictor/BiasAdd' % i)
priorBox.input.append(graph_def.node[0].name) # image_tensor
text_format.Merge('b: false', priorBox.attr["flip"])
text_format.Merge('b: false', priorBox.attr["clip"])
if i == 0:
widths = [0.1, args.min_scale * sqrt(2.0), args.min_scale * sqrt(0.5)]
heights = [0.1, args.min_scale / sqrt(2.0), args.min_scale / sqrt(0.5)]
else:
widths = [scales[i] * sqrt(ar) for ar in args.aspect_ratios]
heights = [scales[i] / sqrt(ar) for ar in args.aspect_ratios]
widths += [sqrt(scales[i] * scales[i + 1])]
heights += [sqrt(scales[i] * scales[i + 1])]
widths = [w * args.image_width for w in widths]
heights = [h * args.image_height for h in heights]
text_format.Merge(tensorMsg(widths), priorBox.attr["width"])
text_format.Merge(tensorMsg(heights), priorBox.attr["height"])
text_format.Merge(tensorMsg([0.1, 0.1, 0.2, 0.2]), priorBox.attr["variance"])
graph_def.node.extend([priorBox])
# Reshape from 1x2xN to 1x2xNx1
reshape = NodeDef()
reshape.name = priorBox.name + '/4d'
reshape.op = 'Reshape'
reshape.input.append(priorBox.name)
reshape.input.append('reshape_prior_boxes_to_4d')
graph_def.node.extend([reshape])
priorBoxes.append(reshape.name)
addConcatNode('PriorBox/concat', priorBoxes, 'PriorBox/concat/axis')
# Sigmoid for classes predictions and DetectionOutput layer
sigmoid = NodeDef()
sigmoid.name = 'ClassPredictor/concat/sigmoid'
sigmoid.op = 'Sigmoid'
sigmoid.input.append('ClassPredictor/concat')
graph_def.node.extend([sigmoid])
detectionOut = NodeDef()
detectionOut.name = 'detection_out'
detectionOut.op = 'DetectionOutput'
detectionOut.input.append('BoxEncodingPredictor/concat')
detectionOut.input.append(sigmoid.name)
detectionOut.input.append('PriorBox/concat')
text_format.Merge('i: %d' % (args.num_classes + 1), detectionOut.attr['num_classes'])
text_format.Merge('b: true', detectionOut.attr['share_location'])
text_format.Merge('i: 0', detectionOut.attr['background_label_id'])
text_format.Merge('f: 0.6', detectionOut.attr['nms_threshold'])
text_format.Merge('i: 100', detectionOut.attr['top_k'])
text_format.Merge('s: "CENTER_SIZE"', detectionOut.attr['code_type'])
text_format.Merge('i: 100', detectionOut.attr['keep_top_k'])
text_format.Merge('f: 0.01', detectionOut.attr['confidence_threshold'])
text_format.Merge('b: true', detectionOut.attr['loc_pred_transposed'])
graph_def.node.extend([detectionOut])
while True:
unconnectedNodes = getUnconnectedNodes()
unconnectedNodes.remove(detectionOut.name)
if not unconnectedNodes:
break
for name in unconnectedNodes:
for i in range(len(graph_def.node)):
if graph_def.node[i].name == name:
del graph_def.node[i]
break
# Save as text.
tf.train.write_graph(graph_def, "", args.output, as_text=True)



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











