







文章目录
- 一、数据清洗
- 二、数据丰富
- 三、函数
- 四、数据导入导出
- 五、案例
- 六、优化
本文内容整理自《PowerBI星球」内容合集(2024版)》中的 「B PowerQuery数据清洗」部分。

一、数据清洗
对导入的数据进行数据整理的过程一般称为「数据清洗」,之所以称之为清洗,是因为在数据分析师眼中,杂乱的数据就是脏数据,只有被清洗成干净的数据后才可以进行分析使用,这就要依赖Power Query 功能。
Excel作为日常办公软件在大数据时代明显有点扛不住,所以从Excel2010开始,推出了一个叫Power Query的插件,可以弥补Excel的不足,处理数据的能力边界大大提升。现在还在用Excel2010和2013的同学可以从微软官网下载power query插件使用。到了Excel2016,微软直接把PQ的功能嵌入进来,放在数据选项卡下。以下是Excel2019的界面:

PowerBI中的也集成了Power Query,专用于数据处理,所用的也都是M语言,而且其功能也更加丰富。下面是建立数据连接后 Power Query 编辑器的显示方式:
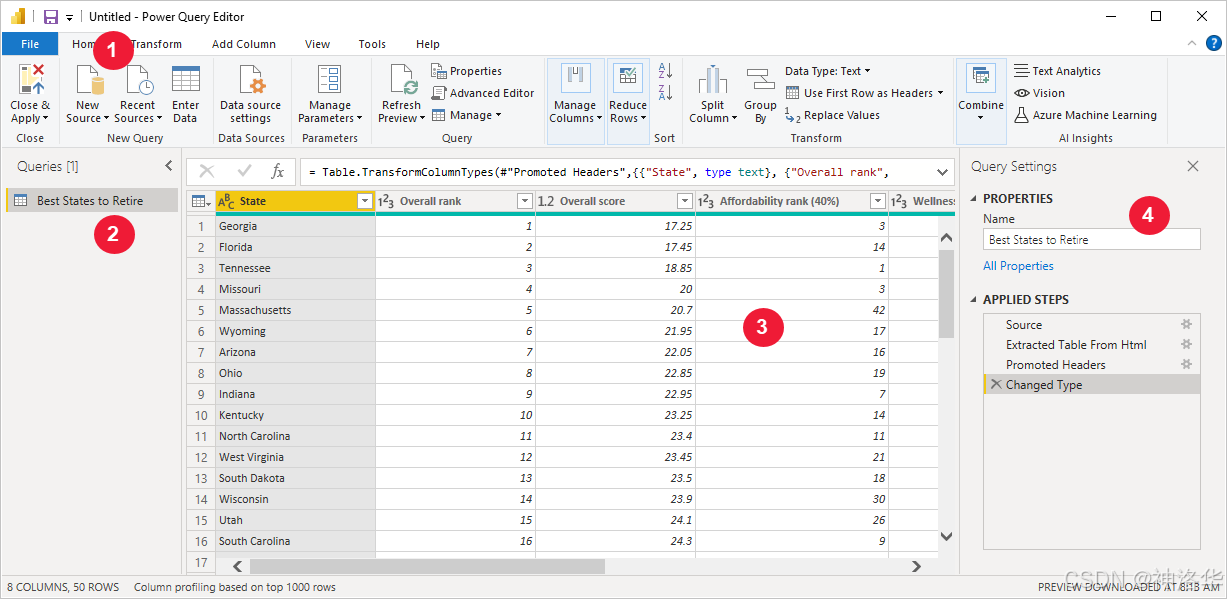
- 功能区:显示Power Query的所有功能选项卡和功能按钮。
- 查询窗格:显示活动查询数以及查询的名称,可供你选择、查看和调整。
- 中央(数据)窗格:显示已选择查询中的数据,可供你调整。
- 查询设置窗格:列出了查询的属性和已应用的步骤,可以根据你的需要重命名步骤、删除步骤,或对步骤重新排序。
- 高级编辑器:利用“高级编辑器”可以查看 Power Query 编辑器通过每个步骤创建的代码,后面会详细讲解。
- 数据保存:数据清洗完毕后,选择Power Query 编辑器主页选项卡下的”关闭并应用“即可保存工作并关闭Power Query 编辑器。

此时选择“文件”>“保存”(或“文件”>“另存为”),即可将工作保存为.pbix文件的形式。
1.1 基础操作
- 数据界面放大/缩小:使用:
CTRL+Shift+"+",CTRL+Shift+"-"来放大和缩小窗口。 - 快速定位到某列:
Ctrl+G,在弹出的窗口中选择列名,快速跳转到某列。用HOME,END键直接定位首列和尾列。 - 查看整行数据:当列很多时,查看某一行的记录不是很方便,可以单击该行的行号,然后在下方的窗口中可看到整行内容的列表。再次按↑↓箭头就可以在这个窗口中快速切换到其他行的记录。
- 修改加载方式:在Excel中,PowerQuery处理之后有两种加载方式,加载到表(默认)或者加载到连接。如果数据太多,比如超过Excel表格1048576行的限制,是无法完整加载到表格的,可选择后者。右键该查询,选择“加载到”:

- 数据导入重复:如果在导入Excel数据后发现数据重复,很可能是因为数据源Excel表格中存在筛选或定义的名称,导致导入到Power Query时出现缓存的sheet。在Power Query界面中,这些缓存的sheet可能会显示如下:

如果继续直接合并,数据就会重复。只需要在kind列,筛选“sheet”数据行;也可以把含有"_xInm._ "字符或者你没有见过的name筛选出去。 - 调出编辑栏:编辑栏是显示M公式的窗口,如果发现编辑栏不见了,只需要在视图中,勾选“编辑栏即可”。

- 调出步骤面板:在PowerQuery界面,最右侧是每一步的操作步骤面板(严格来说是查询设置面板),如果发现它消失了,可以通过点击“视图”选项卡中的"查询设置"来显示它。

- 显示列信息:在【视图】中的“数据预览”,勾选“列质量”、"列分发"等功能就可以显示下方这种列标题统计信息。


1.2 提升/拉低标题
在Excel中第一行为标题行,从第二行开始才是数据,但在PQ中,从第一行开始就需要是数据记录,标题在数据之上。因此从Excel导入数据的第一步就是要提升标题,点击「转换」,将第一行作为标题:

将第一行作为标题旁边的下拉按钮,还有个将标题作为第一行,实际上就是拉低标题,这个功能后续也会用到。

1.3 数据类型
1.3.1 自动识别并转换数据类型
设置正确的数据类型非常重要,后期数据建模和可视化过程中,很有可能会出现一些意想不到的错误,最后发现是数据类型设置的不对,所以一开始就要养成设置数据类型的好习惯。设置数据类型有两种方式:功能区的数据类型选项和点击列名左侧的ABC/123图标。
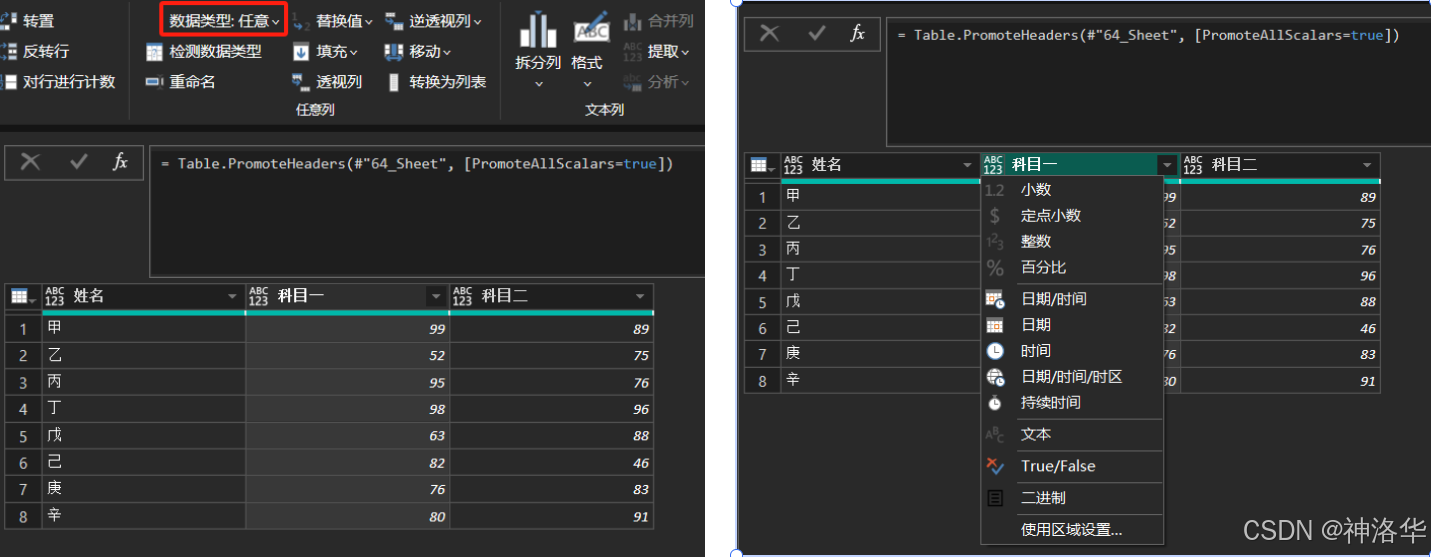
另外,Power BI 在导入时会自动识别并转换数据类型,比如将数字文本自动更改为整数类型,有时候,这并不是我们想要的结果,比如下图左侧的excel数据,导入之后因为自动改为整数类型,导致没有了前缀的0:

解决的办法也非常简单,直接把“更改的类型”这个步骤删掉,数据就恢复为与Excel一样的格式了:

如果不想自动检测数据类型的话,可以禁用此功能:在文件>选项>数据加载中,勾选“从不检测未结构化源的列类型和标题”。

1.3.2 四舍五入问题
当我们在 Power Query 中进行保留 2 位小数的操作,可以通过界面功能实现:

仔细检查会发现,部分结果并非是我们所预期的“四舍五入”,比如3.145 被舍入成了 3.14,而非 3.15。这是因为Power Query中的默认舍入方法是一种被称为“Banker‘s rounding”(银行家舍入)的舍入方法,也被称为 “四舍六入五成双”。
当遇到数值舍入位数的后一位是 5 时,它距离舍入位数两端的数值都相同,那它会被舍入到距离它最近的偶数。如果要进行四舍五入,可以使用Number.Round函数,他有两个参数:
digits:舍入位数roundingMode:舍入模式。
| 舍入模式 | 值 | 舍入的最后一位为5时 |
|---|---|---|
| RoundingMode.Up | 0 | 向上舍入。 |
| RoundingMode.Down | 1 | 向下舍入。 |
| RoundingMode.AwayFromZero | 2 | 向远离零的方向舍入。 |
| RoundingMode.TowardZero | 3 | 向零舍入。 |
| RoundingMode.ToEven,默认值 | 4 | 舍入到最接近的偶数。 |
RoundingMode.Up 和 RoundingMode.AwayFromZero 都可以做到对正数进行“四舍五入”,如果是负数,则应使用后者。另外还有其它几个函数:
| 函数名 | 描述 | 示例 | 示例结果 |
|---|---|---|---|
Number.RoundDown | 向下取整,忽略小数部分 | Number.RoundDown(3.14159) | 3 |
Number.RoundUp | 向上取整,忽略小数部分 | Number.RoundUp(3.14159) | 4 |
Number.Floor | 向下取整到最接近的整数 | Number.Floor(3.999) | 3 |
Number.Ceiling | 向上取整到最接近的整数 | Number.Ceiling(3.001) | 4 |
Number.Int | 截取整数部分,忽略小数部分 | Number.Int(3.999) | 3 |
1.4 列运算
1.4.1 删除空值/错误值/重复项
数据导入后,有可能出现错误(Error)或者空值(null),数据分析之前,就需要删除它们。选中需要清洗的列,右键菜单中进行操作就行:

对于重复项,选中需要删重的列,右键选择「删除重复项」即可。
1.4.2 空值运算
平时接触到的源数据常常有空值,比如Excel数据中的空白单元格,power query中会显示为null,大多数时候,我们并不能简单粗暴的删除其中的空值,而是需要在PQ中对数据进一步运算整理。但是在在Power Query运算中:null+数字=null,例如以下数据:

求两列相加,可以通过添加自定义列的方式(见本文2.1章节),直接用运算符"+";或者是选择一列,点击标准->添加进行快捷列运算:
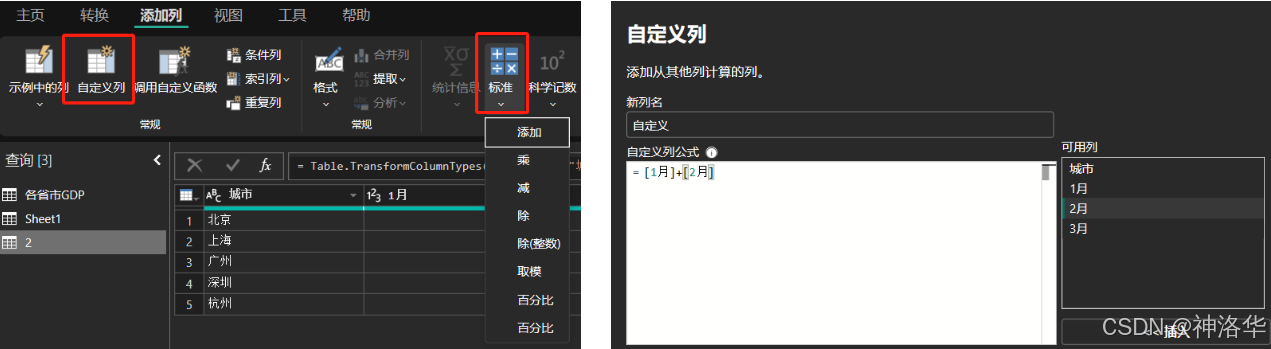

null参与运算的所有结果都成了null。如果将null用0来替换,加法结果正常,但是乘法会出错,所以不能简单的将其替换为0。可行的办法是使用List类函数。依然以两列相加为例,相加用List.Sum函数:

在List类函数的运算中,null无论与数字怎么运算,最终的结果都是数字。例如:
List.Max(null,数字) = 数字
List.Min(null,数字) = 数字
List.Product(null,数字) = 数字

1.4.3 快捷列运算
- 选中两列时,除了加法,还可以进行乘、除、减、百分比、取模等各种运算
- 选中三列及以上时,只有加法和乘法两种运算。
仔细查看计算时的M代码,前者使用的是运算符,这样当数据中含有null时,结果也是null;后者使用的是List类函数,结果会无视null的存在。


选择一列,选择“添加”,会弹出一个窗口,在数据框中输入一个数值后,生成的新列,就是这个数值和原列相加的结果:

比如输入100,结果如下:

总结:利用功能区的"标准"运算功能,可以实现快捷列计算。以加法为例:
-
选中一列时,以运算符的形式为该列加上同一个数;
-
选中两列时,以运算符的形式两列相加;
-
选中三列及以上时,以
List.Sum函数的逻辑多列相加。
1.4.4 添加/删除前缀
使用添加自定义列的方式,通过函数可进行前缀的添加和删除。
- 添加前缀字符,补齐位数:使用公式
Text.PadStart([编码],8,"0")可将不定长的数字前面补0,统一为8位数字。

- 删除前缀字符:使用公式
Text.TrimStart([8位编码],"0"),可删除前缀字符0

1.5 缺失值处理
1.5.1 填充缺失值
在Excel数据中经常会见到合并单元格的情况,导入后就变成了空值:

在PQ中直接向下填充即可,相当于pandas中的df.fillna(method='ffill')语句。

1.5.2 获取第一列非空数据
假设有以下产品销量数据,有些产品是从第一年就有数据,有些产品是从后面的某一年才产生业务,如何添加一列,来显示每个产品首年业务数据呢?

这是一种很常见的需求,从上面的表格直观来看,就是如何找出第一个非空的数据。普通的做法可以通过IF嵌套判断,比如在PowerQuery中可以这样添加自定义列:
第一个非空数据=
if [2020]=null and [2021]=null and [2022]=null
then [2023]
else if [2020]=null and [2021]=null
then [2022]
else if [2020]=null
then [2021]
else [2020]
还有一种更简单的写法:
=[2020]??[2021]??[2022]??[2023]
双问号??是一种非空运算符,它会尝试返回符号前面的数据,如果前面的是空值,则返回后面的数据。

如果要同时获得首年的年份(非空列名),可以添加以下自定义列:

1.6 合并/拆分列
1.6.1 合并列
在PQ中选择需要合并的列,比如把[区域]和[城市]合并。只需要在「转换」中找到”合并列“,弹出合并列窗口进行设置即可:

1.6.2 模糊匹配
假设有两个表,分别是各省市2018和2019年的数据,两个年度的省份名称规则不一致,2019年全称,而2018年是简称。

这个问题用Excel公式或者M函数也能找到解决方案,更简单的方法则是直接使用Power Query的模糊匹配功能。将这两个表格导入到PowerBI中,进入Power Query编辑器,点击合并查询,以省份为关联列,联结种类选择为左外部,最重要的是在联结种类下面,勾选 “使用模糊匹配执行合并” 。

点击确定,并展开合并列,竟然都是空值:

在上面勾选模糊匹配时,你应该能注意到,下面还有个模糊匹配选项,打开后发现还有这些参数可以设置:

- 相似性阈值:默认
0.8,但是上面的数据,相似度最高才0.67(比如"北京"和"北京市"),所以默认匹配时全部没有匹配成功。而"新疆"和"新疆维吾尔自治区"的相似度更低,只有0.25,所以为了都能匹配成功,我们把这个阈值调到0.25,就OK了。

- 最大匹配数:如果不填,会把所有匹配行找出来。可以根据需要,想匹配出来几行就填写数字几。
- 转换表:可以通过查询中的另外一个表作为转换表进行匹配,在转换表中,可以提前定义好,不规范值和规范值的对应关系,相当于同义词表,特定场景下非常有用。
另外,不要因为有模糊匹配功能,就可以对源数据不加约束,依然应该尽量规范你的数据源,能保持一致最好。模糊匹配一方面是计算量特别大,另外既然是模糊查找,就很可能会有误差,当数据量比较大时,这种数据误差还很难被识别出来。
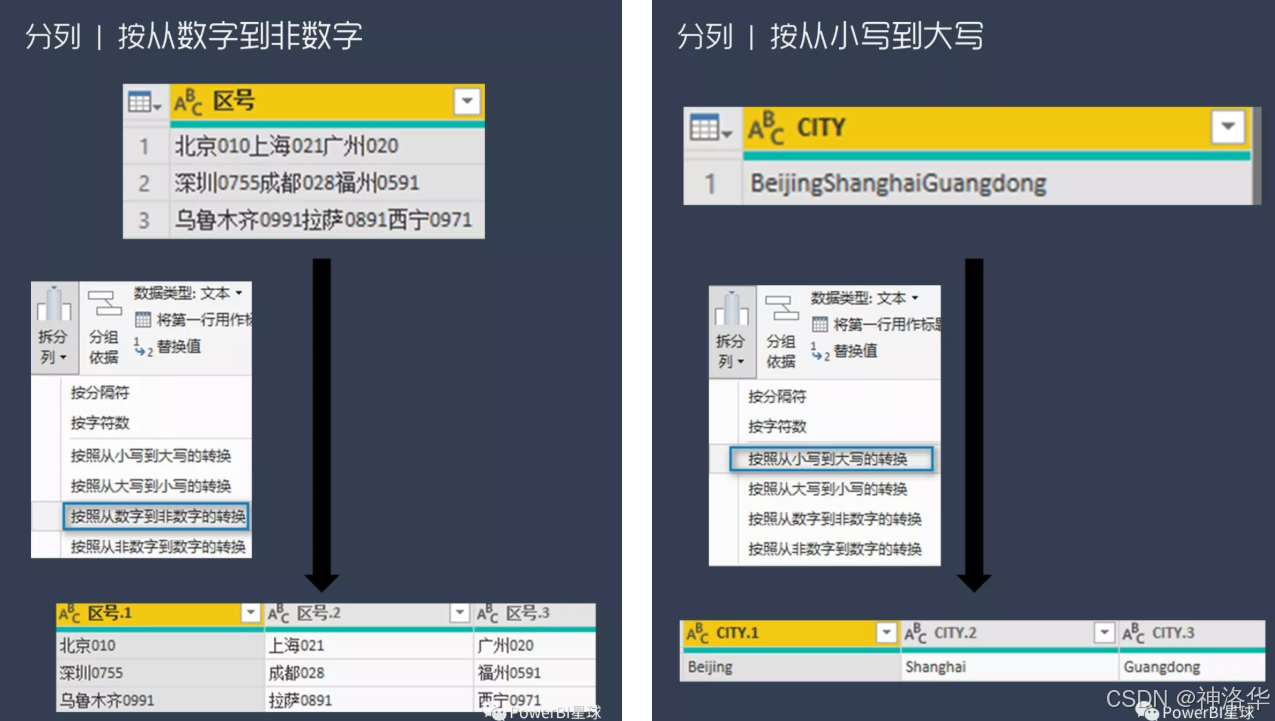
1.6.3 拆分列
拆分相当于是合并列的反动作,不过功能更丰富。点击转换->拆分列,可以按字符数分隔,也可以按分隔符分隔。如果列中包含多个分隔符,还可以选择按哪个位置的分隔符来分隔。比如把刚才的合并列再拆分一下,又变成合并前的格式了:


如果没有分割符怎么办?在Power query中还可以按从数字到非数字的转换来分列,或者按大小写字母的转换来进行分列:
1.6.4 分列到行&多种分隔符进行分列
有时候数据都挤在一个单元格里,直接拆分到不同的列使用起来很不方便。在PQ中,还可以直接将某一列的内容拆分到不同行中(左下图)。
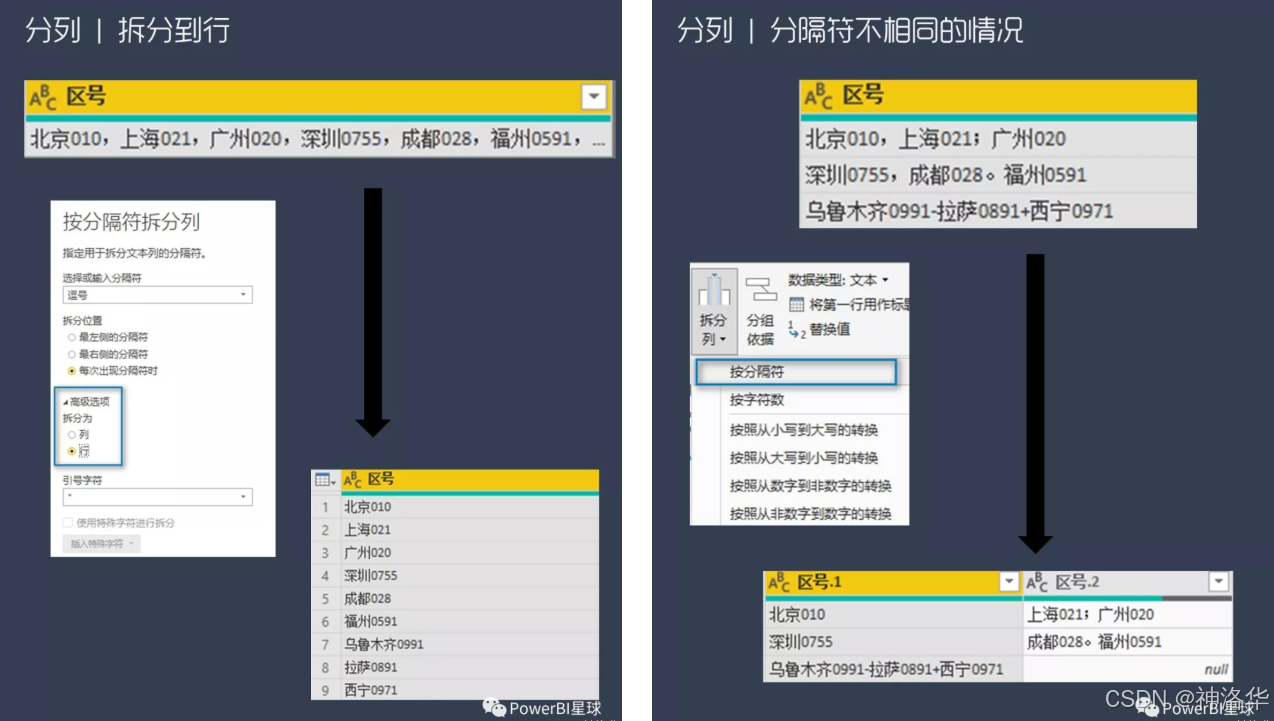
如果有多种分割符,无论选择哪个都没法直接分开(右上图)。这时候,仅靠界面功能就难以正确分列了,这里我们就需要用M函数来完成。直接添加步骤,编辑框中输入:
=Table.SplitColumn(
提升的标题, "区号",
Splitter.SplitTextByAnyDelimiter(
{",",";","-","+","。"},
QuoteStyle.Csv
)
)
其中提升的标题是上一个步骤的名称,使用时要更改为实际的步骤名,字符替换为实际数据的分隔符
看起来有点长,其实主要是使用了Splitter.SplitTextByAnyDelimiter函数,并把所有的分隔符做成一个列表,并将其作为该函数的第一个参数:

关于分列,主要是找出数据排列的规律,是有固定的分隔符、有固定的字符数,还是有规律的从数字到文本等等,找到规律以后,就按规律进行拆分就可以了。
1.6.5 连续分隔符分割

在复现《PowerQuery常见的5个问题》配图时,我将上图发给kimi,没有其它指示,结果识别成了下面这种格式,复制到excel中只有一列。
Content Name Data Item Kind Hidden
Binary sheet1 Table sheet1 Sheet FALSE
Binary _xlnm._FilterDatabase Table sheet1_xlnm._FilterDatabase DefinedName TRUE
Binary sheet1 Table sheet1 Sheet FALSE
Binary sheet1 Table sheet1 Sheet FALSE
加载到powerbi后,显示如下。如果直接选择按空格分割,因为存在连续空格,会分割成十几列(包含空格列)。

powerbi中并没有将多个分隔符视为单个的选项,所以只能使用M公式,添加自定义列的方式将多个空格转为1个。
= Table.AddColumn(更改的类型, "自定义", each Text.Combine(
List.RemoveItems(
Text.Split([Column1], " "),//文本按空格拆分为列表
{""} //使用RemoveItems函数移除列表中的空项
),
" " //Combine函数以单个空格分隔符合并列表,其实这时候你可以改成任意分隔符
))

后面删除原列,正常拆分自定义列,提升标题就行。

1.7 分组统计
1.7.1 数值汇总
相当于Excel中的分类汇总功能,比如刚才的数据,我们要计算各区域1月份的合计金额,点击转换->分组依据:


1.7.2 文本汇总

- 分组:对名称列,点击转换>分组依据,在弹出的窗口中,选择按类型分组,操作是“所有行”

- 修改M公式:分组后先不展开,将原公式
Table.Group(源,{"类型"},{{"名称", each _, type table [类型=nullable text, 名称=nullable text]}})
改为:
Table.Group(源, {"类型"}, {{"名称", each Text.Combine([名称],","), type table [类型=nullable text, 名称=nullable text]}})
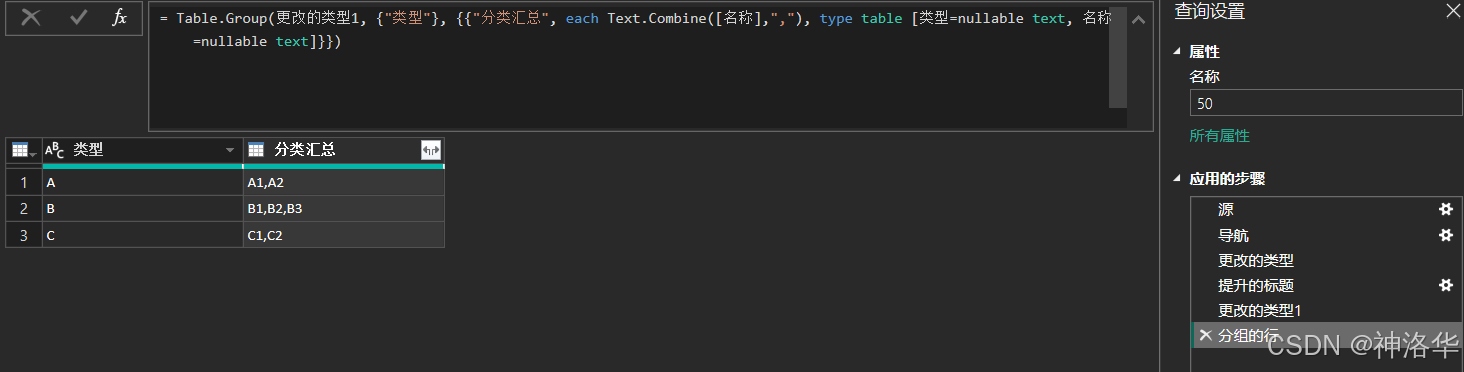
如果不想在合并后的文本中出现重复值,只需要名称字段外面套一个List.Distinct就可以了,上面的Text.Combine表达式改成:
Text.Combine( List.Distinct( [名称] ),"," )
另外,使用CONCATENATEX函数,只需要写一个度量值就可以直接实现这个需求,详见《用一个度量值返回列表》
名称列表 =
CONCATENATEX(
'示例数据',
[名称],
","
)
1.8 提取
PQ的提取功能可以按照长度、首字符、尾字符、范围等来提取,比如下面这个例子,提取前2个字符:

1.9 行列转置(日期不见了)
比如下面这个表,直接行列转置会发现标题“月份”不见了。

这是因为转置的时候,只转数据的部分,月份并不在数据区,我们要想保留月份,先要把月份标题降下来,即”将标题作为第一行“,然后再转置。
1.10 行列操作

1.11 逆透视(二维表->一维表)
由于数据分析的需要,常常需要将二维表变成一维表,在Excel中需要很多操作步骤才能完成,而通过逆透视功能,可以一键降为一维表。
1.11.1 一维表和二维表
在Excel中常见的是二维表,你可能天天都在用:

而一维表是长这样的:

简单来说:
-
一维表的每一列就是一个维度,列名就是该列值的共同属性
-
一维表的每一行就是一条独立的记录
二维表更符合我们日常的阅读习惯,信息更浓缩,适合展示分析结果,但作为源数据进行数据分析时,就需要一维表。一维表的每一列是一个独立的维度,列名或者字段名就是数据分析的基础,比如利用列名与其他表建立关系;编写DAX时直接使用列名;数据可视化时直接把字段拖入到某个属性框中,等等。
1.11.2 简单情形
比如,需要把下表中三个产业结构的数据转化为一个字段,只需要选中地区和年度列(按住“Shift”键可选择多个相邻的列,按住“Ctrl”键可选择非相邻列 ),右键单击,选择逆透视其他列即可(如果列名不是第一行数据,而是类似column1,column2...,需要先提升标题):


1.11.3 行标题带有层级结构

将上表导入到PowerQuery编辑器后,先把年度列向下填充,将年度数据补齐,然后再进行逆透视:

1.11.4 列标题带有层级结构的
这种表格可以先转置,转置以后,就是第二种情形,然后再进行逆透视就可以了。


1.11.5 行标题和列标题均带有层次结构

- 将年度列向下填充,补齐数据

- 将年度列和季度列合并,生成年度季度列,这种结构就变成第三种情形

- 转置表、把第一列向下填充,并提升标题,就变成了第二种情形

- 选中前两列,逆透视其他列,就变成了一维表

- 为了和源数据维度一致,将年度季度列进行分列:

如果有更复杂的表格,比如更多层级的行、列名,也同样可以按照以上的套路通过来分步完成:
- 将行层级先合并,转换成第三种情形
- 转置,变成第二种情形
- 逆透视指定的的列
1.11.6 字段中有多个值

假设有以上简单表格,需要转为一维表。型号和数量是多个数据挤在一个单元格里,需要将他们按顺序拆分成行,得到下面的格式。可以考虑用Text.Split和List.Zip函数来做。

1.11.6.1 List.Zip函数
List.Zip 函数语法为:List.Zip(lists as list) as list。
lists:一个包含多个列表的列表。例如,{list1, list2, list3}- 返回值:返回一个新的列表,其中每个元素是一个包含输入列表中对应元素的列表。如果输入列表的长度不一致,较短的列表会在末尾用
null填充。
使用场景:
- 组合数据:当你需要将多个列表的元素一一对应组合时,List.Zip 非常有用。例如,将学生名单和成绩列表组合起来。
- 数据对齐:在处理不同长度的数据时,List.Zip 可以自动对齐数据,并用 null 填充较短的列表。
- 多列数据处理:在 Power Query 中,List.Zip 常用于处理多列数据,方便后续的转换和分析。
假设我们有以下两个列表:
let
list1 = {10, 20, 30},
list2 = {"apple", "banana", "cherry"}
in
List.Zip({list1, list2})
运行结果是:
{{10, "apple"}, {20, "banana"}, {30, "cherry"}}
如果我们将 list2 改为 { "apple", "banana" },运行结果是:
{{10, "apple"}, {20, "banana"}, {30, null}}
1.11.6.2 操作步骤
- 使用
Text.Split函数,以添加自定义列的方式,拆分型号和数量列:

- 使用
List.Zip({[自定义],[自定义.1]}))函数,组合两列,点击扩展到新行。扩展后再次点击提取值。



- 使用逗号拆分自定义列.2
上面前2个步骤,其实也可以合并为一个步骤,直接添加一个这样的自定义列就可以了:
List.Zip(
{
Text.Split([型号],","),
Text.Split([数量],",")
}
)
这次处理时,在提取值步骤莫名出现前导空格,可以使用休整功能进行清除。

1.11.6 多列情形一(批量合并多列自定义函数)

上图结构也很常见,课程和成绩都有多个列,无法直接通过逆透视来实现,此时可以先合并相同类型的列。
- 合并课程1和成绩1两列,分割符可以任选一个,比如选空格。同样的方式把课程2和成绩2、课程3和成绩3合并。


2. 选中“姓名”列,逆透视其他列

3. 删除不必要的“属性”列,拆分“值”列。

上面的步骤很简单,不过如果列数特别多,第一步合并列将会非常繁琐。通过下面这个自定义函数 “批量多列合并” ,可以一次性将这种结构的表转换为一维表。右键该查询,选择创建函数。弹出“未找到参数”窗口,点击确认。创建后清楚M公式内容,输入以下代码:
=let
多列组合=(需要操作的表 as table, x as number, y as number, optional 固定列终点 as number) as table=>
Table.Combine(List.Transform({1..x},
each Table.FromColumns(
List.Range( Table.ToColumns(需要操作的表),0,
if 固定列终点=null then 1 else 固定列终点
)&
List.Range( Table.ToColumns(需要操作的表),((_-1)*y+固定列终点),y)
)
)
),
元数据=[Documentation.Name="批量多列合并",
Documentation.Description="可以把多列相同的数据合并到一起。
第1参数是需要操作的表,第2参数x代表的是循环几次,第3参数代表的是多少列循环,第4参数是固定标题的结束位置",
Documentation.Examples={[Description="第1列为固定列,每3列进行合并存放,一共循环2次",
Code="批量多列合并(源,2,3,1)",
Result=" "]
}
]
in
Value.ReplaceType(多列组合,Value.Type(多列组合) meta 元数据)
点击调用自定义函数,就可以直接得到多列合并的结果:

- 参数1:需要处理的表
- 参数2:做几次循环合并(本示例做3次合并列)
- 参数3:每次合并几列(本示例是每次进行课程和成绩2列的合并)
- 参数4:前面固定几列不做合并(本示例中第1列姓名不需要合并)

1.11.7 多列情形二

-
合并列

-
添加索引列后,点击索引列点击标准>取模,输入2,然后删除其他列

-
对取模列进行透视,得到[1]和[0]两列


-
对[1]列进行向下填充,对[0]列筛选不为空的行

-
使用List.Zip函数,添加自定义列:
= Table.AddColumn(筛选的行, "自定义", each List.Zip(
{
Text.Split([0],","),
Text.Split([1],",")
}
))

-
选择自定义列,点击扩展到新行,然后点击提取值,选择一个分隔符

-
使用分隔符拆分自定义列,然后重命名,删除其他列。然后将日期列转为日期格式。
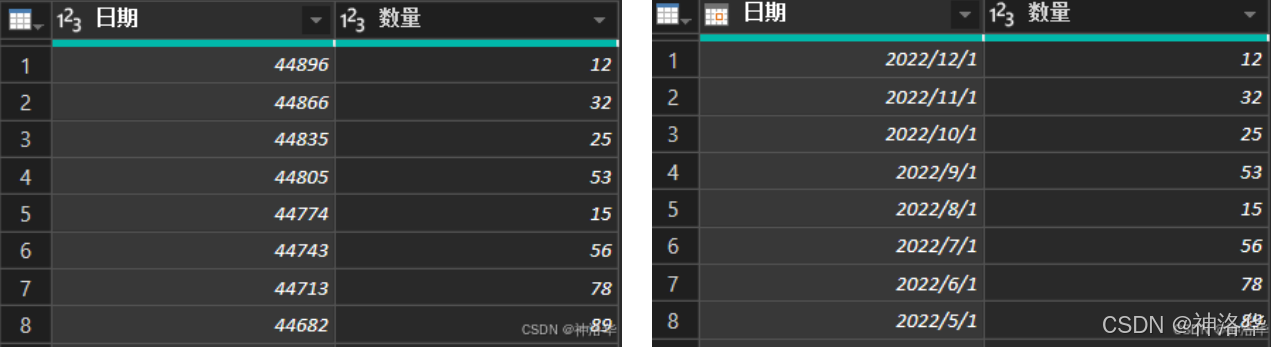
-
选择日期列,点击转换选项卡下的日期,下拉框中随便选择一个,将弹出的公式使用Date.ToText函数进行更改即可:

= Table.TransformColumns(更改的类型2,{{"日期", each Date.ToText(_,"yyyy年M月"), type text}})

1.12 透视表(一维表->二维表)
1.12.1 基本流程
做分析需要一维表,而为了展现的需要,常常还要把一维表变成二维表(相当于Excel中的数据透视)。在PQ中同样可以一键透视,比如把下面的一维表变成二维表,只需要选择数据之外的列,选择透视列:

聚合方式选择无:


1.12.2 重复值放在同一个单元格
不过当分类有重复值时,选择不要聚合就会报错。比如将上表的B都改成A,重复值的单元格报错:
Expression.Error: 枚举中用于完成该操作的元素过多。
如果你想把重复的多个值显示在一个单元格中,可以先根据类别进行分组,再进行透视。
- 数据列改为text类型,因为后续此列要调用Text.Combine函数
- 点击主页->分组依据,弹出以下界面。在分组区选择年度和产品两个列作为类别分组列;将数据列取最大值,即此时重复行取的最大值。


- 修改M公式,将
List.Max([数据])改为Text.Combine([数据],","):

- 透视数据列,选择不要聚合:

1.12.3 重复值分放多行
对于有重复的情况,如果需求不是放到一个单元格中,而是分别放到多行中,可以先添加一个辅助列。
- 按上一节步骤操作,在第三步中将
List.Max([数据])改为Table.AddIndexColumn( _,"索引",1,1 ),得到索引列,然后进行展开数据和索引列:


- 对数据列进行透视,选择不要聚合,这样就实现了重复值用多行显示的效果。

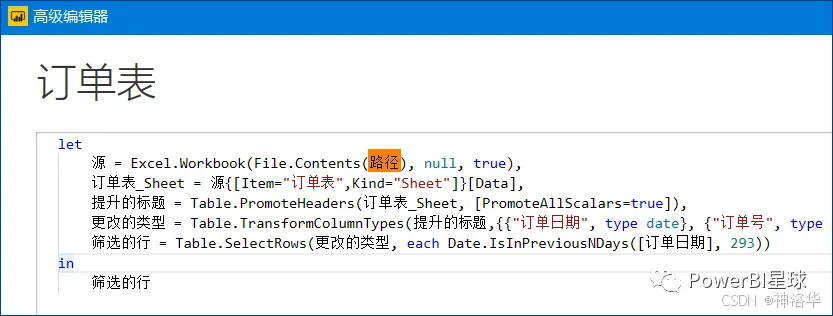
1.13 日期筛选器
1.13.1 展示最近N天数据
利用DAX可动态的显示最近N天数据,详见《Power BI动态显示最近N天的数据》。但如果在报告中只需要分析最近N天的数据,其实也可以不用这么麻烦,利用Power Query的日期筛选器,可以更方便的实现。比如这个订单表,只需要点击订单日期列右侧的下拉箭头,即可找到日期筛选器:

在日期筛选器中内置有各种粒度的筛选,比如昨天、今天、本周、上周、本月、本年等等,甚至也可以细化到按小时、分钟、秒来筛选行,还可以自定义筛选。比如显示前5天的数据:

这里不包括今天的数据,如果要包含今天,可以这样设置:之前的4天以及今天。

如果打算修改为最近15天的数据,点击“转换数据”进入PowerQuery编辑器,点击筛选行这个步骤旁边的小齿轮,可以再次进入筛选行的按钮,将5修改为15就可以了。或者直接修改这个步骤的M代码,将其中的5改为15。

1.13.2 动态化展示最近N天数据
在Power Query中建个参数:

然后修改M代码,就可以根据参数的值来动态的筛选最近N天的数据了。如果你的历史数据非常多,而你只需要分析最近3年的,同样可以利用日期筛选器来动态的提取最近3年的数据,而无需将全部历史数据都加载到数据模型中,这样可以显著的提升模型性能。

这种方式无法灵活的根据用户交互来展示某个日期之前的最近N天,也无法仅利用这张表做其他的分析,比如同期对比分析等。
1.14 列排名
DAX函数中有RANKX来计算排名(详见《RANKX排名示例》),其实PowerQuery中的也有一个M函数可以排名:Table.AddRankColumn。函数语法:
Table.AddRankColumn(table as table, newColumnName as text, comparisonCriteria as any, optional options as nullable record) as table
- 参数1:
table,需要排序的表 - 参数2:
newColumnName,添加的新列列名 - 参数3:
comparisonCriteria,排名依据,可以是一个或多个列 - 参数4:
options,可选。高级用户可以使用options中的RankKind选项来选择更具针对性的排名方法。Order.Descending:默认升序排列,Order.Descending表示按降序排列RankKind=RankKind.Dense:默认并列时排名不连续(比如有两个第一名拍为1,1,3),此时改为连续排名(1,2,3)。
假设有以下数据,需要按金额进行排序:

1.14.1 插入步骤的两种方式
先添加个步骤,使用M公式来处理。PowerQuery中添加步骤,有两种方式:
- 点击编辑栏旁边的
fx - 点击上一个步骤,右键>插入步骤后
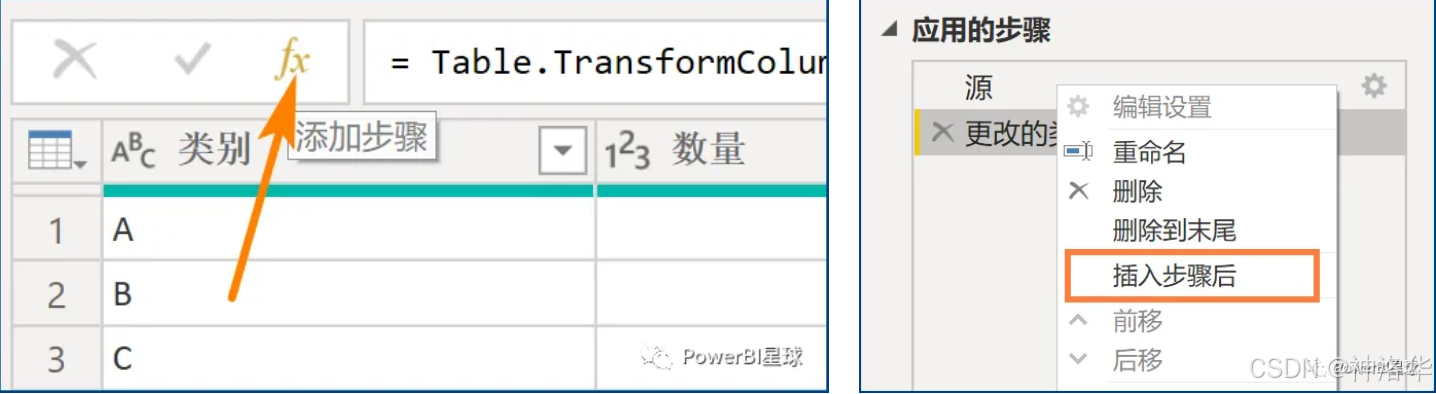
1.14.2 编辑M公式
在插入步骤的编辑栏中,输入
Table.AddRankColumn(
更改的类型,
"排名",{"金额"}
)
其中,“更改的类型”是上一个步骤,参数2和参数3分别是新列的列名和排名依据。



这里计算的排名都是静态的,如果你想在报告中实现动态的排名,还是应该用
RANKX函数写度量值来实现。
二、数据丰富
上一章都是在原表数据基础上调整格式,但做数据分析的时候还经常需要在原有数据的基础上增加一些辅助数据,比如加入新列、新行,或者从其他表中添加进来更多维度的数据,这些就是数据丰富的过程。
2.1 列添加
Power Query中添加列有四种形式,重复列、索引列、条件列、自定义列:

2.1.1 重复列
复制一列的数据,以便对该列的数据进行处理而不损坏原有列的数据。

2.1.2 索引列&分类索引
为每行增加个序号,可以从0或者1开始

如果要按类别添加索引列,可以对类别进行排序,然后添加正常的索引。最后使用公式Number.RoundDown(([索引]-1)/3)+1得到类别索引:

上述表格的数据还是有一定规律的,每三行一个类别,如果完全没有规律,每个类别的行数不一致,就需要先进行类别分组。
-
分组:点击转换>分组依据,按类别分组。

-
修改M公式:对于上面的分组,你会在编辑栏看到M公式
= Table.Group(源, {"类别"}, {{"计数", each _, type table [类别=nullable text]}})。

修改此公式,将下划线_,替换为Table.AddIndexColumn( _,"索引",1,1 );将[类别=nullable text]删掉。

点击每一行的Table,你就能看到带有索引的表:

这里用的
Table.AddIndexColumn其实与正常添加索引用到的函数一样,只是这里的用法,是在分组后未展开的Table中,添加一列索引。
- 点击计数列右侧的展开按钮,勾选“索引”列即可得到最终的结果。

2.1.3 条件列
对于简单的条件判断,可以通过添加条件列来实现。比如有以下成绩表,通过添加条件列,可以实现评级结果:


其M公式为嵌套的if 语句:
if [科目一] >= 90
then "优秀"
else if [科目一] >= 75
then "良好"
else if [科目一] >= 60
then "及格"
else "不及格"
如果有两列数据,需要多个判断条件来判定,就无法直接通过添加条件列来实现,而要用IF语句来完成(用 and/or 来连接多个条件)。另外,对于非空数据的判断,还可以用??来简化多重条件的判断(见本文1.5.2)。

2.1.4. 添加自定义列
使用M函数生成新的一列,此功能经常会用到。右侧列名可双击插入公式区来调用。

2.2 列处理
2.2.1 批量添加多列
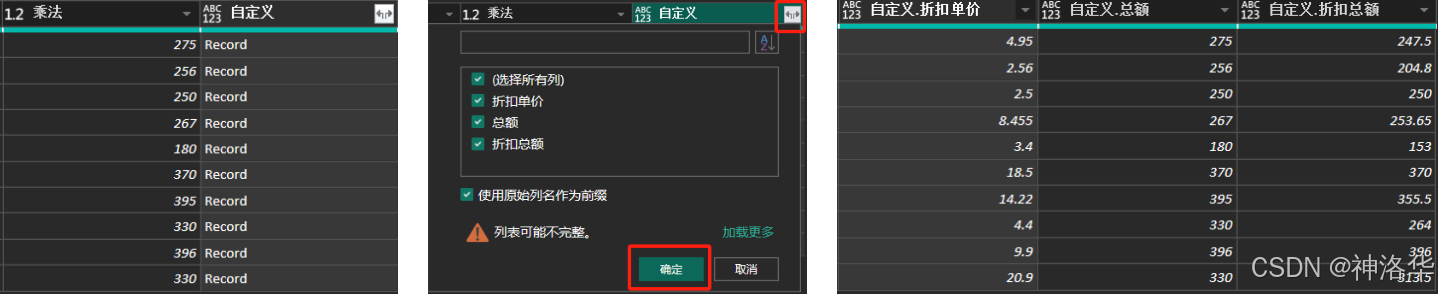
以上方式一次只能添加一列,如果要添加多列该怎么办?假设有以下表格,我们需要在这份数据上添加"折扣单价","总额"以及”折扣总额"三列。一般情况下,以添加总额列为例,它的逻辑是单价乘以数量,可以添加自定义列[price] * [quantity]。
此操作可以使用M函数,也可以选中price列和quantity列,然后点击上面功能区中的添加列->标准->乘,快速添加一列:

如果要批量添加,可以使用以下方式添加三列:
[
折扣单价 = [price] * [discount],
总额 = [price] * [quantity],
折扣总额 = [price] * [quantity] * [discount]
]
这个公式里并没有用到M函数,只是简单的写出目标列的计算逻辑,不同的是最外层套了中括号[ ],这是批量生成多列的关键。然后就生成了一个Record自定义列,然后直接展开此列就行:
2.2.2 批量列处理
Table.TransformColumns允许你针对一个表格的特定列进行操作、修改或转换,而不影响其他列的内容,其语法为:
Table.TransformColumns(
table as table,
transformOperations as list,
optional default as any
) as table
table: 表示要进行转换的原始表格数据。transformOperations: 列表,每个元素指定要转换的列名以及应用的转换函数。default: 可选,指定当某些列不在转换操作中时如何处理(默认为null),这包括transformOperations之外其它列的处理方式- 缺失值的处理
假设有以下表格:

- 在
transformOperations中指定列处理:类别列添加个前缀“产品”,指标1列的数据乘以100

- 指定其它列的处理:除类别列以外的4个指标列都乘以100

- 缺失列处理
如果在在公式中输入表中不存在的列名,将会报错,比如你把“类别”错写成了“名称”,它将会报错并提示:找不到表的"名称"列,此时可以启用第四个参数,它有两个值MissingField.UseNull:为不存在的列创建一个空值列MissingField.Ignore:忽略不存在的列,其他列正常操作

如果你想对某些特定列执行同样的操作,除了将这些列按照上面的方式一个个写出来,还可以结合List.Transform函数更快捷地实现。比如打算对指标1、指标3、指标4这三列分别乘以100,可以先创建个这三个列名的列表,命名为指标:

然后添加步骤输入公式,就可以将指定列表中的列一次性处理完成,当数据表中的列特别多的时候,利用这种方式可以大幅提升效率。
= Table.TransformColumns(
源,
List.Transform(指标, each {_, each _*100})
)
2.2.3 条件替换(Table.ReplaceValue)
如果换成按某列的条件,来处理另一列该怎么做呢?正常情况下可以通过添加条件列来简单实现。而如果要直接在原表上操作,可以使用Table.ReplaceValue函数。
Table.ReplaceValue 可以在指定的列中查找和替换值,支持复杂的替换操作,常用于数据清洗中,如将错误值或旧的分类替换为新的值。其语法为:
Table.ReplaceValue(table as table, oldValue as any, newValue as any, replacer as function, columns as list) as table
table:原始表格。oldValue:替换前的值。newValue:替换后的值。replacer:一个函数,指定如何替换(通常使用Replacer.ReplaceValue)。columns:指定要替换的列,可以是列名的列表。
还是以上一节的数据表为例,假设需求是当指标1大于2时,让指标2乘以100,可以添加个步骤:
Table.ReplaceValue(
源,
each [指标2],
each if [指标1]>2 then [指标2]*100 else [指标2],
Replacer.ReplaceValue,
{"指标2"}
)

其实这种需求用添加自定义列的方式也很简单。虽然使用上述的M函数看起来很简洁,一步实现最终结果,但是从性能上来看,相对于简单的添加自定义列再删除原列的方式,可能并没有性能优势甚至更差,并不总是步骤越少越好。
更多示例:匿名化美国员工的姓名
Table.ReplaceValue(
Table.FromRecords({
[Name = "Cindy", Country = "US"],
[Name = "Bob", Country = "CA"]
}),
each if [Country] = "US" then [Name] else false,
each Text.Repeat("*", Text.Length([Name])),
Replacer.ReplaceValue,
{"Name"}
)
输出:

匿名化美国员工的所有列:
Table.ReplaceValue(
Table.FromRecords({
[Name = "Cindy", Country = "US"],
[Name = "Bob", Country = "CA"]
}),
each [Country] = "US",
"?",
(currentValue, isUS, replacementValue) =>
if isUS then
Text.Repeat(replacementValue, Text.Length(currentValue))
else
currentValue,
{"Name", "Country"}
)

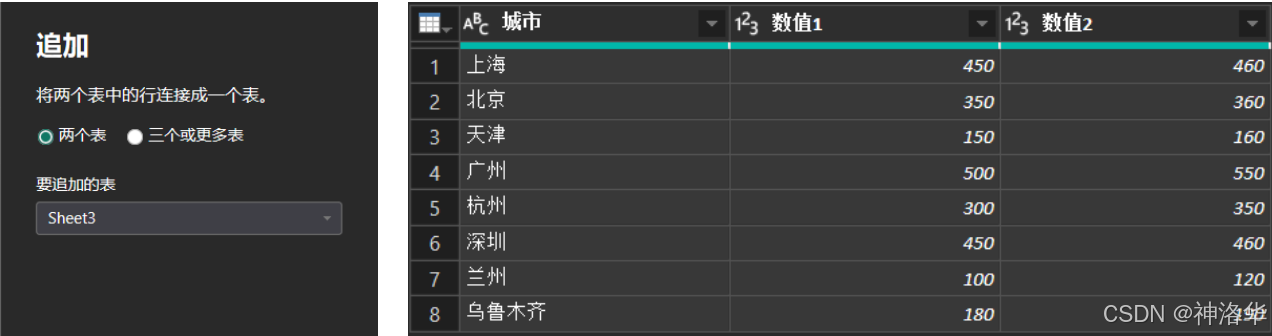
2.3 合并行(追加查询)
比如有两个表格式相同,需要合并为一个表,点击“追加查询”,就可以在原数据基础上添加新的行数据。

2.4 合并列(合并查询)
2.4.1 合并查询流程
合并查询就是横向合并,相当于Excel的VLOOKUP功能,它允许用户将两个表,通过匹配一个或多个列,将数据整合在一起,形成一个新的表。假设有A、B两个表,有匹配列“产品”。

点击主页->合并查询,弹出窗口选择要查询的两个表,并分别点选要匹配的列,然后选择联接方式,默认为左外部。

点击确定,就得到了下面这张表:

展开需要的列,就完成了。

2.4.2 合并查询方式
合并查询使用的是Table.NestedJoin函数,其中参数JoinKind.Type控制其联接方式,共有8种。前6种可以在合并查询界面下拉菜单选择,最后两种只能使用公式。


-
JoinKind.Type:左外,A表所有行+B表匹配行
-
JoinKind.LeftAnti:左反:只在A中出现的行,B表全为null。

-
JoinKind.LeftSemi:左半:A的匹配行,也就是左外中的A表部分,B表为null,所以叫左半。

2.4.3 要合并的表有重复值
如果合并前B表中匹配列有重复值,比如:

此时使用左外方式合并,展开后多了一行:

解决的办法是在展开前选择聚合函数,对重复值进行进一步的操作:

对于文本的聚合,有计数、最小值、最大值这几种方式。如果只添加一列,对于右表有重复的情况,微修改M公式,还可以将匹配的值合并到一起。
- 在聚合时,可以先选择一种聚合方式,比如最大值。然后在编辑栏可以看到这个步骤的M公式:
= Table.AggregateTableColumn(源, "表4", {{"子产品", List.Max, "子产品 的最大值"}})
- 将最大值的聚合公式
List.Max改成each Text.Combine( _ , "," ):

关于文本的聚合,也可以通过分组的方式来实现
2.4.4 航班索引问题(不同步骤之间进行合并查询,71)

现在有一份航班表,"北京-上海"和"上海-北京"视为同一条航线,需要添加相同的序号。我们可以分两步进行:
- 将两个城市按升序/降序合并在一起,然后再添加序号。
在PQ中添加自定义列,将两个城市字段组成一个列表,并利用 List.Sort对这个列表排序,然后再用Text.Combine连成一个字符串:
Text.Combine(
List.Sort({[起飞],[到达]},Order.Ascending)
)

选中自定义列,删除重复项,再添加索引列。

2. 合并查询。
之前我们都是在两个查询中来操作合并查询的,其实在一个查询中,对于不同的步骤表,利用M函数同样可以实现合并查询的效果。插入步骤,在编辑栏输入以下公式,得到Table列。将其展开,只选择索引列即可:
= Table.NestedJoin(
已添加自定义, {"自定义"}, 已添加索引, {"自定义"},
" 合并查询", JoinKind.LeftOuter
)

三、函数
四、数据导入导出
4.1 在PowerBI和Excel中导出导入PowerQuery查询
在Excel的Power Query中已经把数据处理好了,如何将这些查询导入到PowerBI Desktop中而不用再处理一遍?只需要简单的两个步骤:
- 在Excel的Power Query编辑器中,选中全部查询,或者按住Ctrl键选择部分查询,右键复制

- 打开PowerBI Desktop,点击“转换数据”进入Power Query编辑器,在左侧的查询面板中,右键>粘贴。此时所有的查询就一次性导入进来了,并且Power Query的操作步骤也全部导入,数据源更新时,直接刷新即可。

如果要将从PowerBI中的查询导出到Excel,步骤正好相反:
-
在PowerBI中的PowerQuery编辑器中选中多个查询,右键复制;
-
打开Excel,点击数据>查询和连接,在查询面板中粘贴。
导出后,查询会默认上载到Excel表格中,但Excel中的表格有行数限制,如果数据量超过1048576行,在Excel中会显示不全,但不影响使用。为避免引起误解,你还可以在Excel中的查询面板中,右键数据量大的查询,改变数据的加载方式:

然后在弹出的窗口中,选择“仅创建连接":

这样数据就只存储在Excel数据库中,而不会在表格中显示,对于超过百万行的数据,显示出来并没有什么意义,需要的时候,直接从数据库中提取目标数据行即可。
4.2 导出PowerBI数据模型(pbix文件)中的数据
4.3 Excel中批量插入文件超链接
假设需要管理的文档存放于三个文件夹中,每个文件夹中有4个文件,如何把这些文档地址和目录批量导入的Excel中?

这个问题的方法很多,一个简便且高效的方法,利用Power Query。
- 从文件夹获取数据,选择文档所在的路径:


- 加载时点击转换数据:

- 在PQ编辑器中删除无关列:这里只保留了文件名和文件路径,其实导入的文档数据还有格式、文档创建时间等数据,可以根据需要保留相关数据。

- 上载数据到Excel工作表:

- Excel中增加链接列:使用
HYPERLINK函数,生成可点击的地址链接

这样就建好了每个文档的目录,在Excel中不仅查找起来很快,并且找到以后,可以直接通过这个链接打开该文档。使用Power Query还有个好处是,源文件夹中的文档有修改、删除或者新增,在Excel中仅需要点一下刷新,就可以直接更改为最新的文档目录和链接了,而无需再次操作上述步骤。
4.4 PDF转Excel
PDF格式的好处是一旦编辑完成,无论是任何操作系统、任何尺寸和分辨率的显示屏,也无论是怎么打印,排版格式都不会乱,所以经常把Excel等文档转换成PDF格式。那么如何将PDF格式的表格转换成Excel以便进行分析呢?两种方式,详见《PDF转Excel,两个秘籍》
4.5 在excel中批量合并Excel数据
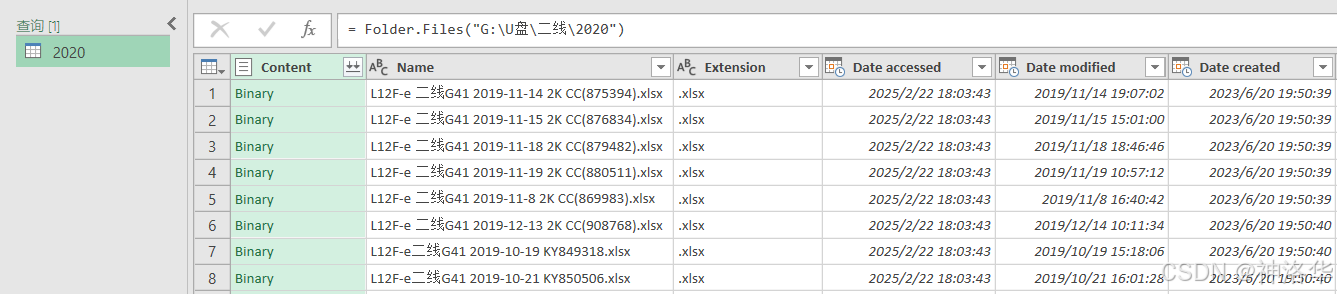
下面使用Excel2019进行演示(Power BI Desktop中的操作也都是一样的)。首先点击"数据"选项卡下"新建查询",从文件夹获取数据:

输入或选择文件夹路径,弹出以下界面:

点击"编辑",进入查询编辑器,数据就储存在[Content]列,其他列都是每个工作簿的信息。
4.5.1 合并指定工作表、指定类型表
点击Name这一列可筛选指定工作表,点击Extension这一列可筛选指定格式(比如.xlsx和.csv文件)的工作表。
4.5.2 提取数据
现在要做的就是把Content的内容提取出来,点击"添加列"选项卡,添加自定义列。自定义列中输入提取Excel格式数据的M函数=Excel.Workbook([Content]),确认后就出现了一个自定义列:

自定义列每一行都是一个Table,点击自定义列右上角的双箭头展开数据,弹出以下窗口:

直接点击确定,可以看到新增加了几列数据:

上面添加自定义列时用的是Excel.Workbook,是专门用来解析Excel格式的。如果数据还包含csv文件和txt文件时,应使用Csv.Document函数:
=Csv.Document([Content],[Delimiter=",", Encoding=936])
Delimiter=",":根据逗号进行数据分隔Encoding=936:中文编码一般为936,Encoding=936可避免中文乱码问题。
4.5.3 合并指定工作薄、指定列
其中新增的第一列自定义.Name是每个excel的工作簿名称,可以进行筛选,只统计每张表需要的工作簿数据。新增的第二列 [自定义.Data] 用于筛选所需的列。筛选完毕后,点确认,数据就全部出来了。

此时,Date列中还有一些不需要的数据(比如下图非数字部分),可以进一步进行列筛选,最后删除不必要的列,更改列名:

数据汇总完成,点击上载数据,数据就整理到excel中了:


4.6 使用PowerBI合并excel数据
假设有一个连锁型零售商店,有北京、广州、杭州三个城市门店,总部每月需要汇总每个城市门店销售明细数据,现在需要汇总2016年1-3月的销售明细,共9个工作簿,保存在一个文件夹内,结构如下:

4.6.1 合并方式一:汇总excel数据后再整理
如果使用PowerBI,应该选择转换数据,删除不需要的列等编辑操作再合并数据。



导入到PowerQuery中的数据默认都是类型为binary类型,需要用函数将它解析出来。同样添加自定义列,对于Excel工作簿文件,输入:=Excel.Workbook([Content],true)。其中,参数true表示自动将Excel的第一行用作标题,接下来的步骤是一样的。

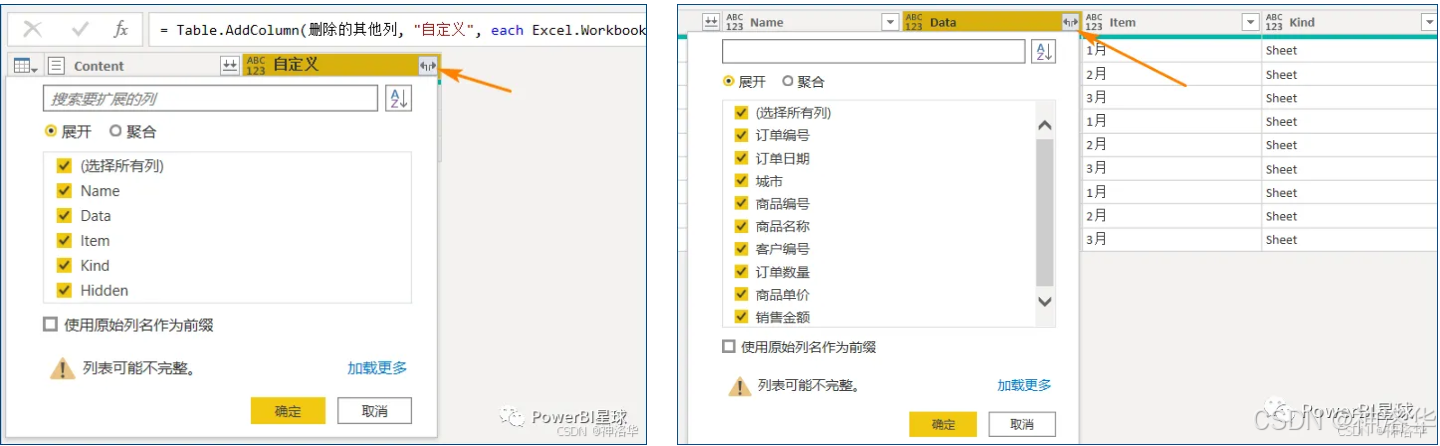

4.6.2 合并方式二:先整理excel数据再汇总(自定义函数)
这种方式思路是:先对文件夹中的一个文件进行整理,并将处理的步骤封装成自定义函数,然后对文件夹中的所有文件调用该函数,最终实现所有文件的合并整理。比如有以下三个excel文件:

这三个表数据为:



每个表的列名都是该年的月份,如果简单合并,就丢失了年月维度的信息,并且2021年的列数与其他两年还是不等的,所以不能简单地进行合并。
4.6.2.1 二维表转一维表处理
由于上面几个表都是二维表,最后肯定要转换为一维表使用,那么,我们可以换个思路,先将每个表转换为一维表,一维表格式是完全相同的,最后再合并即可。
-
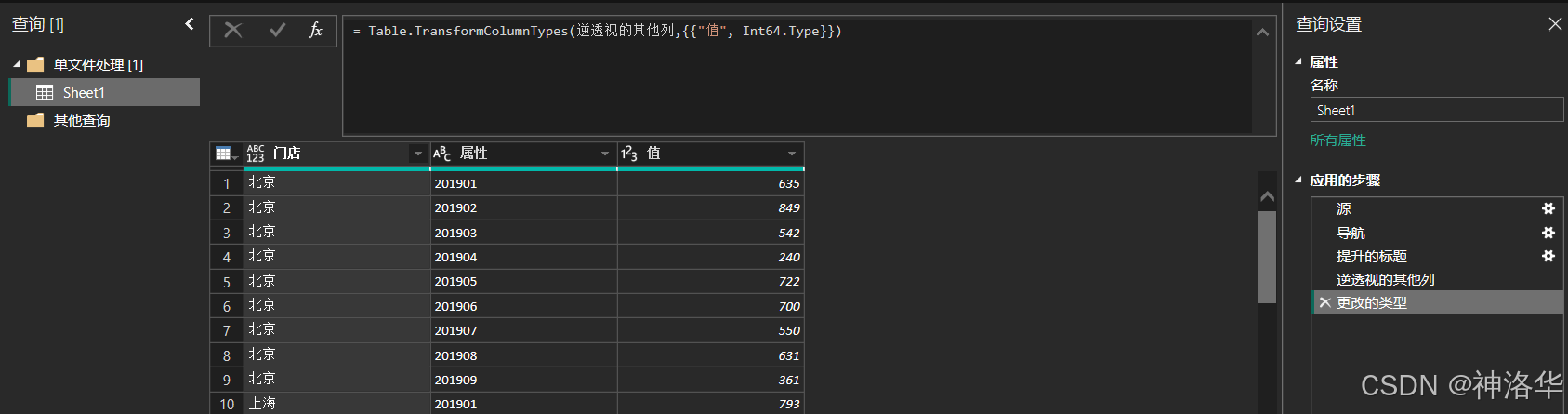
整理任意一个表:比如先将2019年的表,导入并逆透视为一维表(第一行提升标题,逆透视门店之外的其他列,再更改类型)。
-
封装自定义函数:将第一步的查询封装成自定义函数。右键该查询,点击创建函数,命名为"单文件处理",并添加filename参数,改为如下格式:
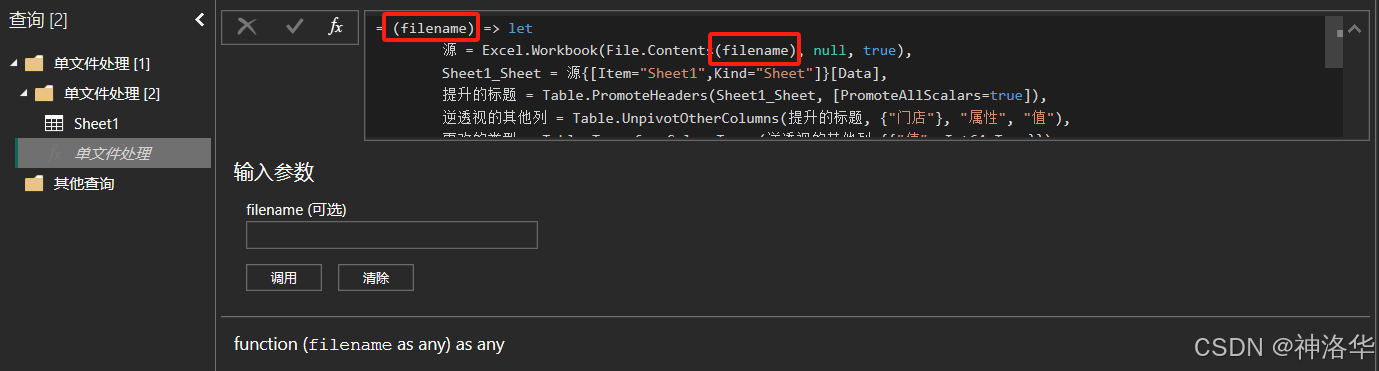
如果创建函数时没有自动出现sheet1的所有处理步骤函数,可以在其高级编辑器中找到,粘贴过来就行。 -
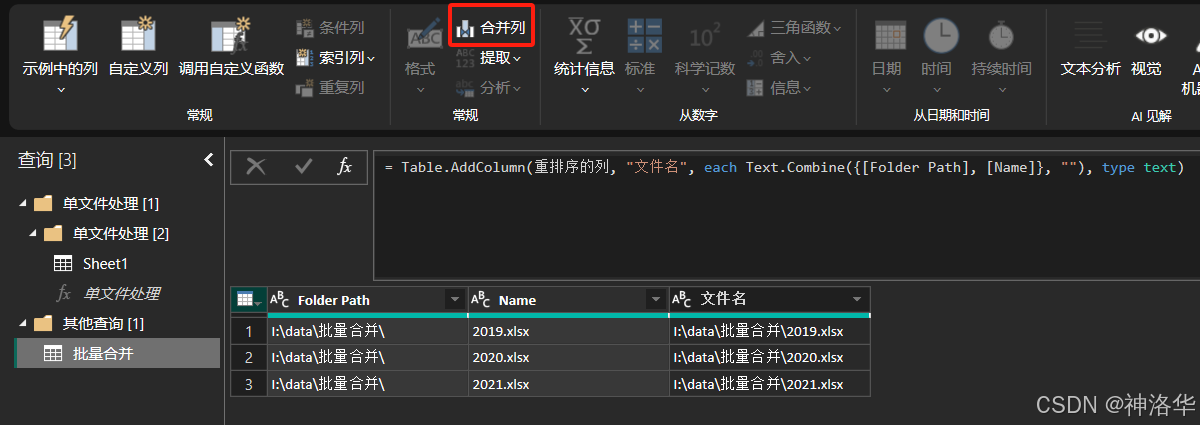
获取每个文件的路径:导入文件夹,删除其他列,只保留
Name和FolderPath列,然后将这两列合并,就得到了每个文件的完整路径。
-
调用自定义函数,合并完成
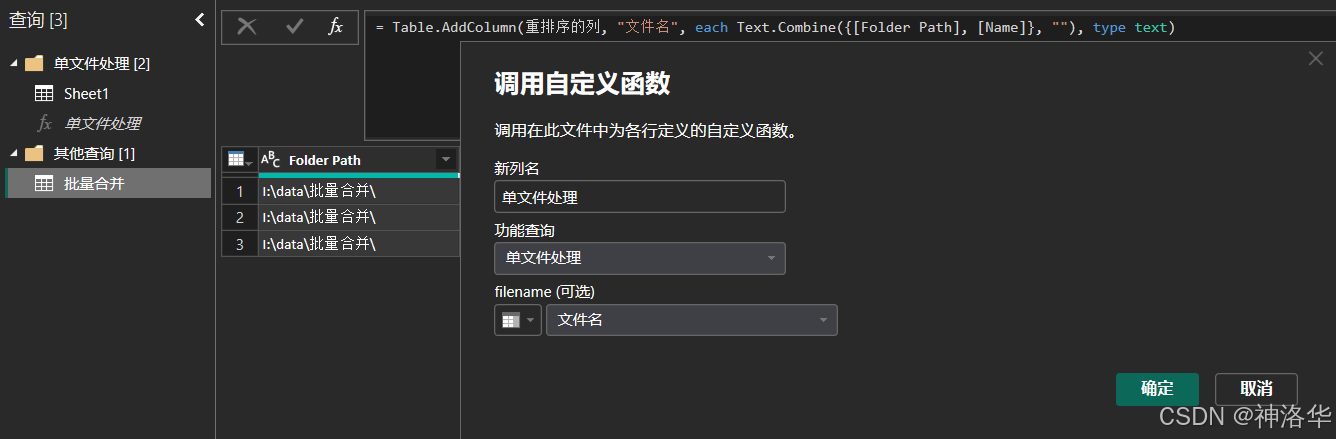
展开数据,就直接得到了3个文件汇总并整理好的一维表:
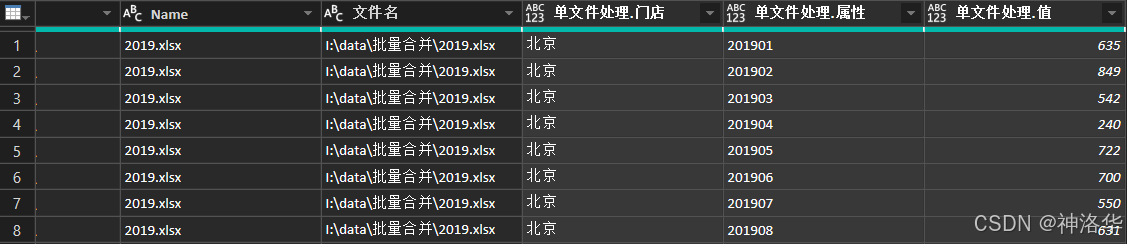
这种方法的优点如下:
-
更加灵活:对于不能直接简单的合并的(如本文示例),也可以处理;
-
速度更快:先对一个文件进行整理,然后再汇总,相比先汇总再整理,更节省时间,对于文件多、数据量大、以及需要较为复杂处理的合并尤为如此。
4.6.2.2 提前逆透视
上一节的方式可以实现,但是发布后如果想设置计划刷新时,会有下面这个提示:

关于动态数据源,有些情况可以通过修改M公式解决,但并不总是都能找到方法,上面的情况就不容易解决,所以如果需要设置计划刷新,就不要使用自定义函数的方法了,现在提供一个更简洁的方法。
- 添加自定义列,读取
Content列的内容

- 筛选其中的
Data列:

此时点击Table可以看到具体的数据:

- 逆透视:添加自定义列,使用M函数进行逆透视操作,最后再展开自定义列就行。其中,Table.UnpivotOtherColumns是逆透视其他列的M函数

这个方法的基本思路是在展开数据前,对数据进行逆透视,让每一行的Table变成同样的格式以后再进行合并。如果你的数据需要在展开Table前进行一定的操作,都可以参考这个方法。
4.6.3 批量合并Excel表的指定列(列顺序不同)
假设有以下三个表,有共同列订单日期、商品名称、客户编号和销售额,但列的顺序不同,而且还有其它不相同的列。

- 读取数据,添加自定义列(一定要加上参数true,将表的第一行作为标题)。


2. 使用M代码*合并指定列
合并指定列=
Table.Combine(
List.Transform(
Table.Combine(已添加自定义[数据])[Data],
each Table.SelectColumns(_,
{"订单日期","商品名称","客户编号","销售额"})))
大功告成,只包含这四列的表格合并好了,主要是利用了 List.Transform和Table.SelectColumns函数组合来提取需要的列,然后再利用Table.Combine函数把提取后的列合并起来。

- 直接合并(需要先提升标题):点击Data列右上角的展开按钮后,就会看到每张表的字段列表,想合并哪些列,直接勾选列名,点击确定,就会自动将每张表的所选字段按顺序合并到一起。

展开自定义列

如果这三个表的列名只是相似而非相同,可参考本文3.5章节《批量修改列名》的方式,先修改成统一的列名,再进行操作。
4.6.4 批量合并Excel表的指定行(除去不需要的表头信息)
大多数Excel表都会有个表头信息,具体的明细数据从下面的某行才开始,比如下面三张表,数据都是从第5行才开始的,并且数据字段的顺序也不一致。

-
批量导入excel表,删除无关列,然后添加自定义列。
这里的Excel.Workbook无需加第二个参数,因为第一行本来也不是标题行,将表的第一行作为标题没有意义。


-
添加第二个自定义列。
不再接着展开[Data]列,而是使用M代码再添加一个自定义列。由于原始数据表格是从第5行开始的,所以先跳过前4行数据,并将第五行数据,作为表的标题行Table.PromoteHeaders( Table.Skip([Data],4) )

3. 展开这个新的自定义列,就可以正常提取并合并特定的列了。


4.6.5 批量合并Excel表的不定行(表头格式不一致)

上面三张表数据前面都有空行,且空行数量都不相等。同上一节一样,先添加自定义列:

展开以后,添加一个自定义列来解析[Data]列:
Table.PromoteHeaders( //提升标题行
Table.Skip([Data], //跳过表的前 x 行
Table.PositionOf( //计算 x
[Data],
[Column1="订单日期"],
Occurrence.First,
"Column1"
)
)
)

与上一节相比,只是多了 Table.PositionOf 函 数,该函数通过查询某个列名出现的位置,来计算每张表前面有多少空行,利用这个函数的计算结果,来动态返回空行的数量。接下来的操作不变。
4.7 动态更改源文件路径
4.7.1 PowerBI中更改
PowerBI可以很方便的从Excel等文件中获取数据,但这个路径是绝对地址,如果源文件路径发生变动,在PowerBI中就无法刷新了,并且进入PowerQuery编辑器中也会报错,看不到数据处理步骤。比如C盘的文件移到了D盘,再打开PowerQuery编辑器,会弹出:

4.7.1.1 修改单个表路径
亦或是收到别人发来的pbix文件或Excel数据源文件,你保存的Excel文件地址与对方在pbix中设置的不同,导致无法刷新。这时需要手动更改源文件地址,有下面几种方式:
- 在【源】中重新选择文件路径
点击【源】旁边的小齿轮按钮,即可在弹出的窗口中浏览路径,选择数据源文件所在的新路径即可。

- 在编辑栏直接修改路径地址

- 打开高级编辑器修改路径地址

4.7.1.2 批量修改路径
如果表比较多,一个个单独修改就很麻烦,利用Power Query中的参数可以快速修改路径地址。
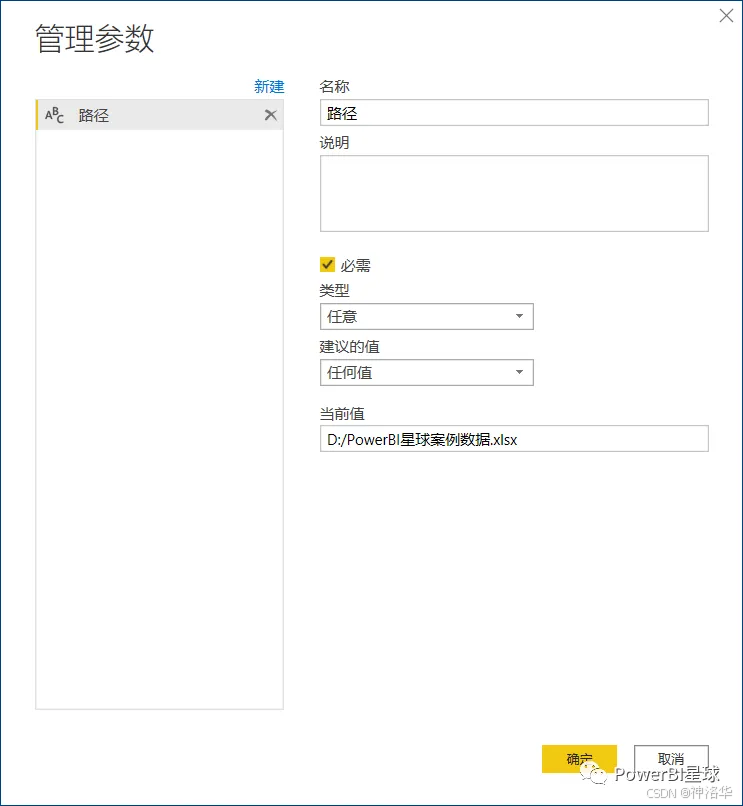
- 新建参数:在Power Query编辑器中,点击管理参数>新建参数。
输入参数的名称,类型可以选择任意,当前值输入源文件的路径地址。

- 在编辑栏或者高级编辑器中,将绝对地址修改为新建的参数名称。
注意原来的绝对路径地址需要加双引号,改成参数后不需要再加引号。
如果源文件路径发生变动,或者你保存的源文件地址与pbix文件不一致时,只需要修改这个参数值即可。

如果文件存储地址有好几个,可以构建参数列表。在【建议的值】选择“值列表”,输入所有的路径:

比如把每个盘的路径都数据进去,这样无论将源文件存放在哪个路径,直接在下拉框中选择就行:

4.7.2 Excel中更改(全自动)
上一节在PowerBI中动态修改路径时,还是需要手动调整路径参数。但是如果是在Excel中利用Power Query来清洗数据,是可以做到全自动更改路径地址的。假设有以下路径的excel表(= Excel.Workbook(File.Contents("D:\PowerBI星球\PowerQuery动态路径\示例数据.xlsx"), null, true)):

现在只需要用Excel公式将当前的路径提取出来就行。
- 新建工作簿:在PowerQuery查询所在的Excel工作簿中新建一个sheet,分别录入文件名称和公式两列(
=LEFT(CELL("filename"),FIND("[",CELL("filename"))-1)&A2):

- 选定改sheet任意单元格,在【数据】选项卡下,点击“来自表/区域”,将这个表导入到PowerQuery编辑器中,这样就得到了文件路径表。


- 修改上一个步骤的函数参数,将绝对路径替换为“文件路径{0}[路径]”。

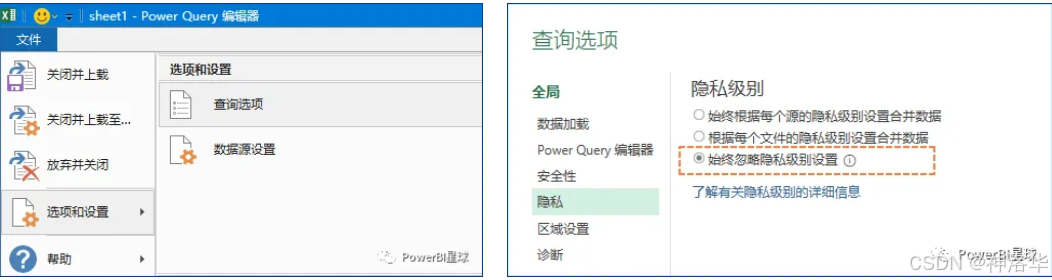
修改完参数后,可能会出现如下报错信息:

此时需要在文件>选项和设置>查询选项>隐私中,将隐藏级别更改为“始终忽略隐私级别设置”,然后点击刷新即可。
如果源文件是文件夹,同样可以利用这种方法,先获取文件夹的地址:

按上述方式导入到PQ后,然后将获取文件夹数据的查询【源】代码中的路径更改为文件夹的路径即可。这样处理以后,无论将文件移动到哪里,还是发给别人,都不用调整代码、直接刷新而不会出错。

Tips:该方法的关键是必须将PowerQuery查询所在的工作簿与源文件放到同一个路径下,这样获取本文件的路径,同时也就是源文件的路径。
为什么强大的PowerBI反而没有这个功能呢?因为在PowerBI中,还没有函数获取本文件的路径地址,而Excel通过cell函数就可以实现。
4.8 数据源变更(文件↔文件夹)
当数据源更改时,可以通过修改M公式来处理。
4.8.1 文件类型变更
以Excel文件变更为csv文件为例,对于导入的Excel文件,打开高级编辑器,记录有这个数据从导入到处理的每个步骤的M代码。从Excel工作簿获取数据时,导入数据的步骤是前两行,将其进行修改就行。

如果你不记得csv文件的导入公式,可以直接导入一个csv文件,打开高级编辑器即可查看:

将之前的代码修改为:

这里要注意的是,原先的Excel查询中,“提升的标题”这个步骤引用的是上个查询的步骤名sheet1_sheet,这里替换后只有一个步骤,所以直接改成“源”即可。
4.8.2 文件变更为文件夹
前期可能只有一个Excel文件,随着数据量的增加,有很多相同格式Excel文件需要先合并到一起,这种情况可以所有的文件放到一个文件夹里面,我们就需要将原来的Excel数据源替换为文件夹数据源。
替换与上面的思路一样,同样新建个查询,从文件夹获取数据,并将文件夹中的表解析出来,合并成一个表(不用做进一步的整理,因为整理步骤原来的查询已经做过了),关于从文件夹合并Excel的具体的步骤,之前已经讲过了。
- 导入文件夹中的文件并并合并,打开高级编辑器,复制相关代码

- 修改原先的M代码,注意更改下一个步骤中所引用的上一个步骤的名称:

上面主要是介绍替换的思路,其中高级编辑器的公式也不一定完全照搬,具体情况还需要微调。
4.9 Power BI连接OneDrive数据源
五、案例
5.1 批量爬取网页数据
本章节以智联招聘网站为例,采集工作地点在上海的职位发布信息。
5.1.1 分析网址结构
打开智联招聘网站,搜索工作地点在上海的数据。下拉页面到最下面,找到显示页码的地方,点击前三页,网址分别为:
-
http://sou.zhaopin.com/jobs/searchresult.ashx?jl=%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=1
-
http://sou.zhaopin.com/jobs/searchresult.ashx?jl=%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=2
-
http://sou.zhaopin.com/jobs/searchresult.ashx?jl=%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=3
可以看出最后一个数字就是页码的ID,是控制分页数据的变量。
5.1.2 使用PowerBI采集第一页的数据
打开PowerBI Desktop,从网页获取数据,从弹出的窗口中选择【高级】,根据上面分析的网址结构,把除了最后一个页码ID的网址输入第一行,页码输入第二行。


从这里可以看出,智联招聘网站上每一条招聘信息都是一个表格,不用管它,任意选择一个表格,比如勾选Table0,点击编辑进入Power Query编辑器。在PQ编辑器中直接删除掉【源】之后的所有步骤,然后展开数据,并把前面没有的几列数据删除,这样第一页的数据就采集完了。

对这一页的数据进行整理,删除掉无用信息,添加字段名,可以看出一页包含60条招聘信息。如果要大批量的抓取网页数据,为了节省时间,对第一页的数据可以先不整理,可以等到采集所有网页数据后一起整理。
5.1.3 根据页码参数设置自定义函数
还是刚才第一页数据的PQ编辑器窗口,打开【高级编辑器】,在let前输入函数:(p as number) as table =>:
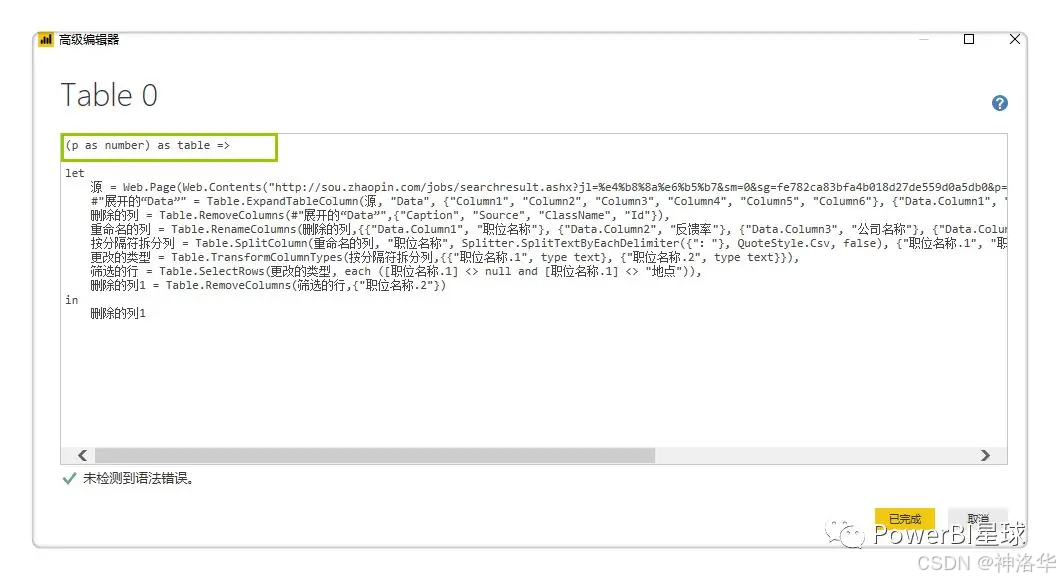
并把let后面第一行的网址中,&后面的"1"改为:(Number.ToText(p))。更改后【源】的网址变为:
"http://sou.zhaopin.com/jobs/searchresult.ashx?jl=%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p="&(Number.ToText(p))))
确定以后,刚才第一页数据的查询窗口直接变成了自定义函数的输入参数窗口,Table0表格也变成了函数的样式。为了更直观,把这个函数重命名为Data_Zhaopin。到这里自定义函数完成,p是该函数的变量,用来控制页码,随便输入一个数字,比如7,将抓取第7页的数据。

5.1.4 批量调用自定义函数
输入参数只能一次抓取一个网页,要想批量抓取,就需要批量调用自定义函数。首先使用空查询建立一个数字序列,如果想抓取前100页的数据,就建立从1到100的序列。在空查询中输入:={1..100}。回车就生成了从1到100的序列,然后转为表格:

然后调用自定义函数,在弹出的窗口中点击【功能查询】下拉框,选择刚才建立的自定义函数Data_Zhaopin,其他都选默认就行。点击确定,就开始批量抓取网页了,因为100页数据比较多,耗时5分钟左右(第二步提前数据整理造成的后果,导致抓取比较慢)。展开这一个表格,就是这100页的数据

网页的数据是不断更新的,在操作完以上的步骤之后,在PQ中点击刷新,可以更新到最新的数据。在可以使用PQ功能的Excel中也是可以同样操作的。
PowerBI并不是专业的爬取工具,如果网页比较复杂或者有防爬机制,还是得用专业的工具,比如R或者Python。在用PowerBI批量抓取某网站数据之前,先尝试着采集一页试试,如果可以采集到,再使用以上的步骤。
5.2 获取网页中的链接
对于网页中可见的规范化数据,提取很简单,但对于网页中可以再次点击的链接,怎么提取呢?以豆瓣读书中的TOP250 为例(https://book.douban.com/top250?icn=index-book250-all),在这个网页中,不仅显示书名、评分、作者等信息列表,还可以通过点击封面或者书名,进入该书的详情页。下面介绍如何提取这个链接。

在PowerBI Desktop中,选择用web获取数据:

在表视图中你看不到可以提取的数据,没有关系,你可以点击左下角的“使用示例添加表”,然后你就能看到这个网页了:

在这里,只要手动输入前两条信息,PowerBI就会判断你要提取的字段,并自动把该网页中剩余的同类数据添加进来,比如输入前两个书名:

同样的方式,你也可以提取评分、作者、出版社等信息。但网址在这个网页是不可见的,你可以在网页上手动打开链接,把前两名的链接网址输入进来,就能得到所有的链接网址。

上面的步骤只是提取一页25条信息,你还可以根据前面文章中介绍的方法,利用Power Query自定义函数批量提取Top250条的图书信息。提取后简单处理,就可以在PowerBI Desktop中使用了,记得将链接的数据类型设置为“Web URL",才可以点击。

5.3 获取豆瓣电影数据
打开豆瓣首页——https://movie.douban.com:

利用从web获取数据的功能,将这个网址放进去,就可以轻松获取这些影片的评分:

这种方式抓取的只有一个评分数据,其实在每部电影的详情页,有更丰富的数据,比如电影的导演、主演、评分人数、影评条数等。如何能批量抓取每一部电影详情页中的这些数据?

5.3.1 批量获取电影的详情页网址
先打开前两部电影的详情页并将网址复制下来,然后利用"使用示例添加表"的功能,将前两行数据粘贴到前两行,系统就可以自动识别并补全剩余的信息。

或许是豆瓣电影网页的数据结构不够规范,所以提取出来的数据,与网站实际看到的略有出入,将重复的、以及不正确的数据删除即可。

5.3.2 提取一部电影详情页数据
比如提取出《姜子牙》的导演、主演、评分人数等数据,依然"使用示例添加表",将这些数据提取成一行,然后将这一行数据清洗成规范的数据。


5.3.3 建立自定义函数
右键上一步的查询->创建函数,将函数重命名为movieinfo,并修改前两行代码,定义网址为参数:

5.3.4 调用自定义函数
调用创建好的自定义函数:

然后展开数据即可获得每一部电影的详细数据:
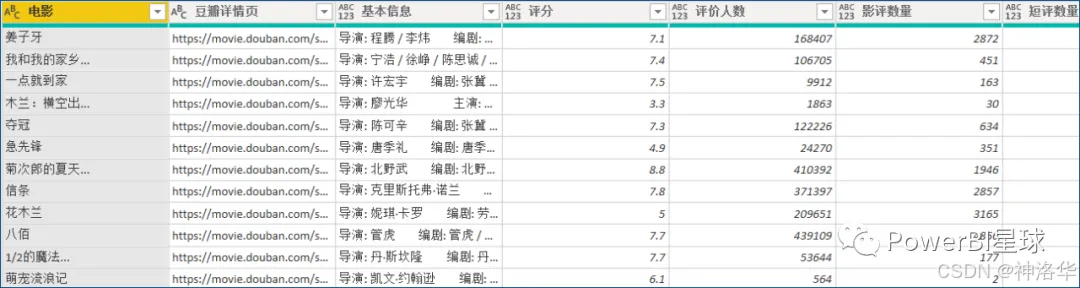
将抓取到的数据上载到数据模型中就可以进行分析了:
5.4 获取股票历史交易数据
5.4.1 手动下载
- 中证指数:提供各类股票指数的编制、发布和管理服务。
选择你感兴趣的指数,比如上证综指,选择一个时间段或者自定义时间范围后,点击“导出行情”,就可以得到一个Excel格式的历史行情数据。

- 英为财情:提供全球250多家交易所逾30万种金融资产的实时行情数据,包括股票、外汇、商品、债券等。用个人邮箱注册登录后,随便选择一只个股,选择历史数据,即可下载。

5.4.2 使用STOCKHISTORY函数下载(excel)
excel内置了STOCKHISTORY函数,用于检索有关金融工具的历史数据并将其作为数组加载,其语法为:
=STOCKHISTORY(stock, start_date, [end_date], [interval], [headers], [property0], [property1], [property2], [property3], [property4], [property5])
STOCKHISTORY函数需要 Microsoft 365 个人版、Microsoft 365 家庭版、Microsoft 365 商业标准版 或 Microsoft 365 商业高级版 订阅。
| 参数 | 参数类型 | 说明 | 取值范围 |
|---|---|---|---|
stock | 必选 | 股票的标识符 | 股票代码,比如“MSFT”代表微软;或“XNAS:MSFT” 来指向特定交易所 |
start_date | 必选 | 历史数据的起始日期 | 日期值或文本格式 |
end_date | 可选 | 历史数据的结束日期 | 默认值为 start_date |
interval | 可选 | 数据的间隔 | 0:每日数据,1:每周数据,2:每月数据 |
headers | 可选 | 是否显示列标题 | 0:不显示标题,1:显示标题,2:显示标题和标识符 |
property1, property2... | 可选 | 需要获取的股票属性 | 0:日期,1:收盘价,2:开盘价,3:最高价,4:最低价,5:成交量 |
- 获取微软(股票代码:MSFT)2023年1月1日至2023年12月31日的每日收盘价数据:
# 按日获取数据,显示列标题,获取日期和收盘价 =STOCKHISTORY("MSFT", "2023-01-01", "2023-12-31", 0, 1, 0, 1)

2. 获取苹果公司(AAPL)2024年上半年的周线开盘价、收盘价、最高价、最低价以及成交量
=STOCKHISTORY("AAPL", "2024-01-01", "2024-06-30", 1, 1, 0, 1,2,3, 4,5)

3. 获取深交所万科A(股票代码:000002)从2023至今的每日交易数据:
=STOCKHISTORY("XSHE:000002", "2023-01-01", TODAY(), 0, 1, 0, 1,2,3, 4,5)
对于国内大陆上市公司,目前只支持深交所(代码XSHE)的上市公司,不支持上交所

STOCKHISTORY函数优势:
- 实时性:通过Excel内置的数据服务,能够获取实时更新的股票历史数据。
- 便捷性:只需要简单的函数调用,无需编写复杂的脚本或使用外部API。特别适合那些不具备编程技能的用户。
- 可扩展性:它的参数可以引用其他单元格来实现动态化,并且获取的数据可以进一步与Excel的其他强大功能结合,如透视表、图表等,进一步进行深度分析和可视化展示。
5.5 通过API获取数据(powerbi)
在5.4章节中,介绍了如何通过资源网站和Excel来获取金融数据。其实更普遍的场景是通过API来获取相关数据。
API(Application Programming Interface,应用程序编程接口)是一套预先定义的函数、协议和工具集,用于构建软件和应用程序。API充当不同软件间的中介,允许它们相互通信。通过API,用户可以访问某个服务或应用程序的功能或数据,而无需了解其内部工作机制。
以沧海数据为例,该网站提供全球主要国家的金融数据服务。注册登录后会有自己的token,免费版可以获取最近3年数据、每天调用30次的额度。下面以免费版为例,来介绍PowerBI通过它的API获取数据的方法。
5.5.1 分析API结构
了解API的详细信息。阅读文档是关键步骤,它将告诉你如何构造请求,需要哪些参数。以获取股票日线数据为例,选择网站首页上方文档->股票->基本行情->实时日线,找到该数据的API文档说明。

上面网址中{ }内容要替换为你的信息,通过Request参数列表,可以看出exchange_code表示交易所的代码,token在你注册登录后会看到的一串代码,ticker表示股票代码。假如你要获取上交所贵州茅台的历史数据,网址就改成:
https://tsanghi.com/api/fin/stock/XSHG/daily?token={你的token}&ticker=600519

Request参数是指在发送HTTP请求时,需要传递给API服务器的参数。这些参数通常用于告诉API服务器你请求的具体数据是什么,以及你希望以何种形式接收这些数据。
这就是获取某只股票的基本网址,如果要指定历史数据的起止期间,比如获取贵州茅台2024年9月的交易记录,根据上面的Request参数,输入start_date和end_date参数,并用&连接起来就可以了,网址构造如下:
https://tsanghi.com/api/fin/stock/XSHG/daily?token={你的token}&ticker=600519&start_date=2024-09-01&end_date=2024-09-30
填入token字段时,不需要花括号
5.5.2 通过PowerBI获取股票历史数据
有了上面构造的网址,我们就可以在PowerBI中点击获取数据>Web。将该网址输入进去,就可以得到贵州茅台2024年9月的交易数据(匿名连接就行):

这样获取的数据是该网站提供的全部字段,如果只想得到某些字段,就要用到该API的Response参数:

Response参数指的是当API请求成功处理后,API服务器返回给客户端的数据字段。这些参数定义了响应数据的结构和内容,使用户可以了解他们将接收到什么样的数据。
假如我们只需要获取贵州茅台2024年9月交易数据的股票代码、日期、开盘价和收盘价,Response参数名称就是ticker,date,open,close,网址构造如下:
https://tsanghi.com/api/fin/stock/XSHG/daily?token={你的token}&ticker=600519&start_date=2024-09-01&end_date=2024-09-30&columns=ticker,date,open,close
将上面的网址输入进去,得到的数据就是下面的样式,只有指定的字段:

PowerBI获取API数据非常简单,关键是分析API参数构成,通过这些参数和具体需求,构造出特定的URL,然后利用PowerBI的从web获取数据的功能,就可以轻松获取数据。
5.5.3 批量调用
PowerBI也可以实现批量调取,仍然以上篇文章的案例为例,来看看如何一次性获取多只股票的历史交易数据。
- 获取单只股票数据。这里以获取贵州茅台2024年9月的交易记录为例,构造网址为:
https://tsanghi.com/api/fin/stock/XSHG/daily?token={你的token}&ticker=600519&start_date=2024-09-01&end_date=2024-09-30
- 将单只股票的查询封装成自定义函数。
右键该查询,创建函数,弹出窗口,提示未找到参数,可以不用理会,直接点击“创建”。函数重命名为"股票历史数据"。然后打开编辑栏,将“源”这个步骤以及前面的字符:
= () => let
源 = Json.Document(Web.Contents("https://tsanghi.com/api/fin/stock/XSHG/daily?token=你的token&ticker=600519&&start_date=2024-09-01&end_date=2024-09-30"))
改为:
= (exchange_code,ticker,start_date,end_date) =>
let 源 = Json.Document(Web.Contents("https://tsanghi.com/api/fin/stock/"&exchange_code&"/daily?token=你的token&ticker="&ticker&"&&start_date="&start_date&"&end_date="&end_date))
也就是将网址中的交易所代码、股票代码、开始日期、结束日期参数化,并用&将它们合并成一个完整的网址。这样就制作完成了自定义函数。

3. 调用自定义函数,批量获取数据。
将要调用的股票的交易数据,先做好一个表,比如:

由于我们在自定义函数中没有指定参数类型,默认都是文本,所以这个列表中的每列字段类型也都改成文本型。

点击添加列->调用自定义函数,在弹出的窗口中,"功能查询"选择上面建好的自定义函数,并在每个参数中选择相应的列:

然后表中就新增了一列,展开即可得到这个列表中每只股票的交易数据。

5.5.4 调用API,获取任意地点的经纬度信息
对于结构化的地址,比如“北京市海淀区丹棱街5号”,可以通过分列或者文本函数提取出该地址所处的省份、城市等信息。但是如果一个特定的地址,比如“中央电视台总部大楼”,该如何自动找出所在的位置信息呢?
更进一步的,我们还想返回这些地址的经纬度信息,这种需求也很普遍,但通过简单的文本函数已无法实现,一种简单的实现方式是使用Power Query调用地图网站的API,返回位置信息。
各大地图网站都有可供调用的API,这里以高德地图的API为例,点击注册高德开放平台。登录后,创建一个新的应用,并在应用详情中添加唯一的 API Key(详见示例)。
-
获取web数据:输入网址
https://restapi.amap.com/v3/geocode/geo?address=中央电视台总部大楼&output=XML&key=你申请的key -
进入编辑模式:点击编辑,进入Power Query:

-
数据处理:逐步展开Table中的数据,并删除不必要的列,就可以得到我们想要的信息(包括国家、区号、结构化地址等信息,可以根据自己的需要来选择保留哪些列)。

-
创建自定义函数:右键该查询->创建函数,函数名设为
location -
调用函数:
- 直接调用:如果想找到上海东方明珠的位置信息,直接输入参数框并调用即可。

- 批量调用:通过添加列来批量调用自定义函数
location。

- 直接调用:如果想找到上海东方明珠的位置信息,直接输入参数框并调用即可。
5.5.5 动态数据源问题优化
上一节操作完成后,如果发布这个报告到PowerBI服务中,并设置自动刷新时,很可能会遇到下面这个问题:

点击“发现数据源”,会看到更具体的提示:

根据微软官方文档的介绍:动态数据源中的部分或所有信息在 Power Query 运行查询之后才能确定是否需要连接,因为数据是在代码中生成的或从其他数据源返回的。动态数据源主要会出现在下面几种情况:
- SQL Server 数据库的实例名称和数据库;
- CSV 文件的路径;
- Web 服务的 URL
通过API获取经纬度信息的案例,就是第三种情况,利用了 Web 服务的 URL,在自定义函数中,对URL设置了参数,静态的直接访问这个有参数的URL是无法访问的,所以导致了这种报错,只需要稍微调整一下网址的写法就可以了。
- 选中自定义函数,打开高级编辑器:

原公式为:
let
源 = (x) => let
源 = Xml.Tables(
Web.Contents(
"https://restapi.amap.com/v3/geocode/geo?address="&x&"&output=XML&key=你自己的key"
)
),
/后面的公式省略……
上面 Web.Contents函数中的URL中是含有参数的,只需要将网址部分改成下面的形式,利用Web.Contents函数的query选项,将网址中"?"后面的部分,分别用查询参数的形式来表达,并且保证Web.Contents函数第一个参数的网址是可访问的。
let
源 = (x) => let
源 = Xml.Tables(
Web.Contents(
"https://restapi.amap.com/v3/geocode/geo",
[
Query=[
address=x,
output="XML",
key="你自己的key"
]
]
)
),
/后面的公式省略……
调整以后,你再对这个报表设置计划刷新时,就不会再提示“动态数据源”的错误了。
5.6 部门人员变动下的统计分析
之前对于数据处理,都假定维度表不会随时间发生变动,但实际情况并不总是如此。比如每个人员所属的部门,随着时间的推移很可能会发生变动,那么在统计变动前后的部门数据时,就有点困难。

有四个业务员分别归属于AB两个部门,利用上面两个表,计算每个部门的销量很简单,只需要通过业务员将两个表建立关系就行了。如果人员发生变动:

5.6.1 使用DAX
此时,最直接的做法是,在销售表中添加一列部门属性,记录每笔销售业务发生时,该业务员的所属部门,即通过销售表每一行的日期和业务员名称,去部门人员表中筛选匹配对应的部门。
部门 =
VAR date_=[日期]
VAR name_=[业务员]
RETURN
CALCULATE(
MAX('部门人员表'[所属部门]),
FILTER(
'部门人员表',
'部门人员表'[业务员]=name_&&'部门人员表'[开始日期]<=date_&&'部门人员表'[结束日期]>=date_)
)

除了使用计算列,也可以用度量值实现的。度量值的好处是,可以在不对模型中的表做任何改动的前提下,来实现分析目的。

计算列是在销售表上直接添加可见的部门列,而这个度量值是构造了一个虚拟销售表,在虚拟表中添加了一列部门,然后利用当前上下文来筛选虚拟表中的部门,返回销量合计。
将部门人员表中的部门作为上下文,这个度量值就可以计算出该部门的销量:

5.6.2 使用Power Query进行多条件匹配
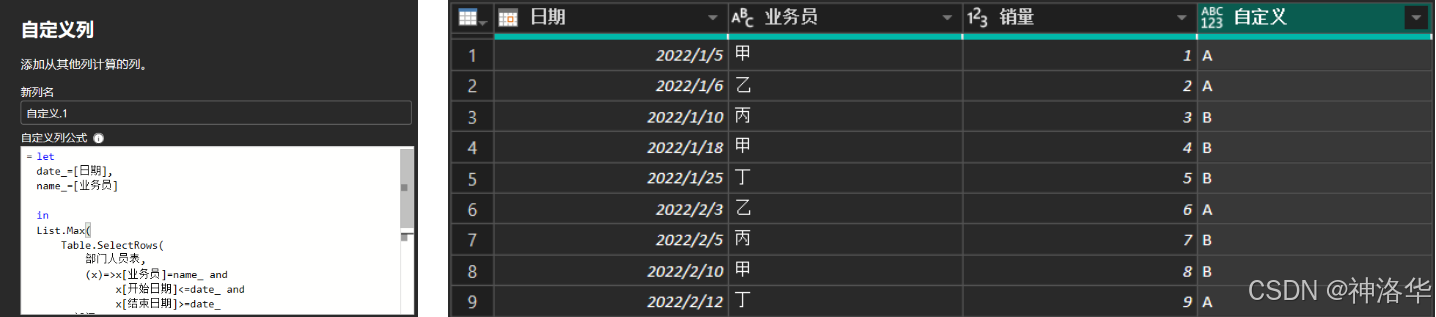
- 在销售表中添加一个自定义列:
let date_=[日期], name_=[业务员] in List.Max( Table.SelectRows( 部门人员表, (x)=>x[业务员]=name_ and x[开始日期]<=date_ and x[结束日期]>=date_ )[部门] )
- 分组统计
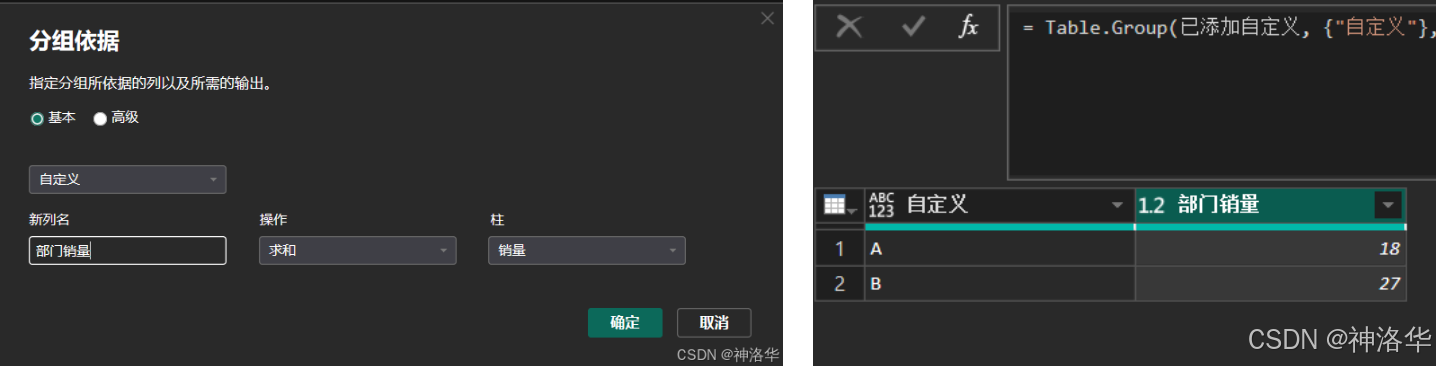
实现逻辑和上一节是一样的,只是DAX用的是FILTER函数来进行筛选,而M用的是 Table.SelectRows而已。如果你遇到需要用PowerQuery进行多条件的、无法用合并查询解决的匹配问题,都可以参考上面的思路。



















 2177
2177

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











