







文章目录
《「PowerBI星球」内容合集(2024版)》数据建模与DAX部分、《用户定义的聚合》、《管理存储模式》、《使用值筛选器》
一、度量值
度量值(报表级别)是用DAX公式创建一个虚拟字段的数据值,她不改变源数据,也不改变数据模型,只有拖到报表上才起作用。通过创建度量,模型设计者可以控制数据的汇总方式,确保数据的准确性和一致性。下面用一个示例来进行说明。
1.1 导入数据
假设有个电子产品专卖店,销售产品有三类:手机、电脑、平板,每一类又分别来自三个品牌:小米、苹果、三星,那么这个店销售的产品共计9个。



下面是门店城市表(全国8个门店)和销售日期表。

销售明细表记录了每个电子产品专卖店2016至2017年的销售明细数据:

整理完成后,模型关系如下:

1.2 显式度量和隐式度量
度量分为显式度量和隐式度量(自动度量):
- 显式度量:基于DAX公式创建,用于实现汇总等功能。
- 隐式度量:“字段”窗格中带(∑)图标 的任何字段(列)均为数值,可以聚合。当你将其拖到报表画布上时,Power BI 自动为该字段创建度量值计算其总和,而不是显示所有数据,这就是隐式度量值,旨在为模型开发者提供便利。你也可以点击字段名称右侧的下拉箭头,更改聚合方式(如平均值、最大值等)。

在 “数据 ”窗格中,显式度量值由计算器图标表示,而隐式度量值由 sigma 符号(∑)表示。

1.2 使用自定义度量值计算累计销售同比增长率
当你需要执行更复杂或独特的数据分析时,可以使用数据分析表达式(DAX)来创建自定义度量值。DAX 是一种公式语言,它使用了许多与 Excel 公式相同的函数、运算符和语法。与 Excel 不同,DAX 函数专门设计用于处理关系数据,并在你与报表进行交互时执行动态计算。这意味着度量值的计算结果会根据报表中的筛选条件和上下文动态变化。 通过这些度量值(报表级别),用户可以添加特定业务逻辑、创建视觉计算或执行与报表上下文相关的计算,而无需更改原始数据集。
1.2.1 新建度量值
- 新建度量值:要创建度量值,请在报表视图的建模选项卡中,选择新建度量值;或者点击主页功能区的新建度量值按钮。默认情况下,每个新度量值都会命名为”度量值“。如果不进行重命名,新度量值将被命名为”度量值2“、”度量值3“,依此类推。

- 编辑度量值:在公式栏中,输入
销售总额 = sum('销售明细'[销售额]),选择公式栏中的✔图标 或按 Enter 键即可完成创建。 - 可视化:在画布上添加矩阵表格可视化组件,把日期表中的[月份]列和刚创建的度量值分别放入行和值,每月的销售总额就出来了:

- 格式化:点击某个数值字段,在功能区面板中,可以设置数值格式,比如数值类型、百分比显示、小数位数、添加千分位逗号、显示为货币等。

1.2.2 切片器
因为没有加入年度筛选,这时候的每月销售额实际上是2016和2017年的两个月份的合计额,所以现在加入一个年度切片器。
- 新建切片器:点击可视化图表区的切片器,画布区出现一个图表,将年度字段拖入其中。

- 调整切片器样式:点击可视化对象格式区,在下拉菜单中选择磁贴样式,然后调整切片器大小和位置。

1.2.3 引用其它度量值
你可能会想,“这个度量值的功能不是与直接将销售总额 字段添加到我的报表中一样吗?”你确实可以这样做,但是度量值的一大优点,是我们可以将它当作参数用于其它度量值公式。
下面选择销售明细表,再次新建两个度量值,计算本年累计销售金额和上年累计销售金额。把这两个度量值也拖到表中,选中2017年,本年和上年截至每个月份的累计销售额就显示出来了。
本年累计销售额 = TOTALYTD([销售总额],'日期表'[日期])
上年累计销售额 = TOTALYTD([销售总额],SAMEPERIODLASTYEAR('日期表'[日期]))
这里用了两个DAX函数,TOTALYTD函数是统计从年初到本月的金额,SAMEPERIODLASTYEAR返回的是上年同期的日期表,关于DAX函数先有个印象就行,后面会专门介绍。
再添加个度量值[同比增长率],将其也拖入表中,同比增长率就计算出来了。
累计同比增长率 = divide([本年累计销售额],[上年累计销售额])-1

1.3 度量值的上下文
在Excel里面做个同比增长率非常简单,但是如果不只比较销售总额,还要分类别、分品牌、来比较,甚至更多变年份季度、更多门店数据进行对比,估计用传统Excel技能做要累吐血也做不完吧。而在刚才建立的模型里,无论有多少个维度,无论按哪个维度比较,只需要多建两个切片器,都是点点鼠标的事,这就是度量值的魅力。

只是简单建立了四个度量值,然后就神奇的实现了多维度的比较,这要归功于度量值的最重要的特征:上下文。上下文就是度量值计算时所处的环境,决定了度量值如何根据不同的筛选条件或数据范围动态计算结果。比如北京2017年截至5月的苹果手机累计销售额3424000,它的上下文就是下面这6个维度。
[城市]="北京市"
[品牌]="苹果"
[类别]="手机"
[年度]=2017
[月份]=5月
[值]=[本年累计销售额]
度量值另外还有两个主要特征:
-
不浪费内存:只有被拖到图表上才执行运算,如果数据量非常大的时候这点非常有利。
-
可作为其它度量值的参数:比如上面的建立的度量值,就是直接调用之前建立好的度量值,所以以后在模型中新建度量值的时候,推荐从最简单的度量值开始建。
本年累计销售额 = TOTALYTD([销售总额],'日期表'[日期]) 累计同比增长率 = divide([本年累计销售额],[上年累计销售额])-1,
1.4 使用快速度量执行常见计算
1.4.1 简介
快速度量是一种强大的工具,它允许用户无需编写复杂的 DAX(数据分析表达式)公式即可执行数据分析。用户可以通过右键单击数据窗格中或可视化框中的任意字段,或者点击其右边的小图标,都可以在弹出菜单中找到新建快读度量值选项。

创建快速度量后,用户可以在“快速度量”窗口中选择所需的计算类型和要对其运行计算的字段。拖动可视化-值区域的各个度量值字段,可以调整报表显示的字段顺序。

一共有五种快速度量的计算类型,包括:
- 每个类别的聚合:平均值、差异、最大值、最小值、加权平均等。
- 筛选器:已筛选的值、与已筛选值的差异、百分比差异、新客户的销售额等。
- 时间智能:本年迄今总计、本季度至今总计、本月至今总计、年增率变化等。
- 总数:汇总、类别总数(应用筛选器)、类别总数(未应用筛选器)等。
- 数学运算:加减乘除、百分比差异、相关系数等。
- 文本:星级评分、值连接列表等。
选择好计算类型和字段之后,就自动创建了度量值,并在公式栏显示其DAX 公式。用户可以直接查看和学习这些公式,根据需要进行修改。
1.4.2 示例
假设我们有一个销售表格矩阵视觉对象,其中包含按类别划分的销售总额,我们希望计算每个类别的平均单价,可以使用快速度量值。

-
创建快速度量值:在矩阵视觉对象中,右键单击或选择
TotalSales旁边的下拉箭头,选择“新建快速度量值”。 -
配置计算类型:在“快速度量值”窗口中,选择“按类别平均值”作为计算类型。将Average Unit Price从“字段”窗格拖动到Base value字段;将 Category字段保持为类别字段不变,点击确定。

-
查看效果:此时,矩阵视觉对象中会新增一列,显示按类别计算的平均单价
Average Unit Price average per Category。

-
应用于新的视觉对象:新建的快速度量值可用于报表中的任何视觉对象, 比如使用新建的快速度量字段创建柱形图。
快速度量值的一个重要优势是能够自动生成并显示其背后的DAX公式,为用户提供了学习和理解DAX公式的机会。例如,如果用户需要进行同比增长计算但不确定如何编写DAX公式,可以通过创建“同比增长”快速度量值,进行快速了解。
如果用户的Power BI Desktop语言版本使用逗号作为小数分隔符,快速度量值将无法正常工作,因为其DAX语句仅使用逗号作为参数分隔符。
1.5 度量值的数据类别
参考《数据类别》
当 Power BI Desktop 导入数据时,它会根据数据类型和列名等信息进行一些默认假设,以便在创建可视化时提供更好的体验。例如,数值列通常会被放置在“值”区域,而日期/时间列则可能被用作时间轴。
然而,某些数据可能具有多种解释。例如,一个包含地理位置代码(如“AL”“AR”“CA”)的列可能表示美国州名或国家名。如果不指定数据类别,Power BI 可能无法正确识别其含义。通过指定数据类别,可以明确告诉 Power BI 如何处理这些数据。
1.5.1 设置地理过滤器

假设有以上表格,AL 可以表示阿拉巴马州或阿尔巴尼亚;AR 可以表示阿肯色州或阿根廷;CA 可以表示加利福尼亚州或加拿大,为了明确分析,需要指定数据类别。
- 在“报表”视图或“表”视图中的“数据”窗格中,选择需要分类的字段。
- 切换到“列工具”选项卡,在“属性”区域中,点击“数据类别”旁边的下拉箭头,从下拉列表中选择合适的地理数据类别(如城市、州/省、国家/地区等)。
另外,如果你在 Power BI Desktop 中设置好地理数据类别(下图中,将City列设为City类别),当你的同事在 Power BI 移动应用中查看相应的报表时,Power BI 会自动提供与其所在地理位置匹配的地理位置筛选器。例如,在拜访客户时,可以通过地理过滤器快速查看当前客户所在地区的销售总额和收入。在外出工作时,可以通过地理过滤器快速找到附近的其他客户或工作地点。

- 地理过滤功能仅支持报告中的地理名称为英文,例如“New York”、“Germany”。
- 模型中每个地理数据类别只能设置一个列。例如,只能设置一个“城市”列、一个“州/省”列和一个“国家/地区”列,否则,移动应用将无法使用地理过滤功能。
- 创建包含地理数据的报表:使用地理字段创建可视化对象。例如,可以创建一个地图可视化,显示不同城市的销售数据,然后将报告发布到 Power BI 服务。下图中,
City+State是一个计算列。

- 在 Power BI 移动应用中查看报表:在 Power BI 移动应用中打开报告。如果你位于报表中数据相关的地理位置,则可以自动筛选到该位置。

1.5.2 指定URL类别
假设我们有一个度量值,用于显示产品的销售链接。我们希望在报表中点击这些链接时,能够直接跳转到相关产品的详细页面。在需要使用 URL 筛选器参数链接到其他 Power BI 报表时,这种方法非常有用。
-
创建度量值:
假设我们有一个表Products,其中包含ProductID和ProductName列。我们创建一个度量值ProductLink,用于生成每个产品的销售链接。ProductLink = "https://example.com/products/" & Products[ProductID] -
设置数据类别:
在 Power BI Desktop 中,选择ProductLink度量值,然后在“列工具”选项卡中,选择“数据类别”。从下拉菜单中选择“Web URL”。

-
显示为 Web URL:
在报表视图中,将ProductLink度量值拖动到表格或卡片视觉对象中。此时,度量值将显示为可点击的链接。 -
使用 URL 筛选器参数:
如果需要使用 URL 筛选器参数链接到其他 Power BI 报表,可以在 URL 中添加筛选器参数。详见《通过在 URL 中添加查询字符串参数来筛选报表》
1.5.3 指定条形码字段
在 Power BI Desktop 中,可以将数据列标记为“条形码”类别,这样,用户可以通过 Power BI 移动应用(iOS 或 Android 设备)扫描产品上的条形码,直接查看包含该条形码的报告。打开报告时,报告会自动过滤到与扫描的条形码相关的数据。

- 将
Product Barcode设为条形码类别。

- 添加到可视化:在“报表视图”中,将条形码字段添加到需要通过条形码过滤的可视化对象中。
- 保存并发布:保存报告并将其发布到 Power BI 服务。
使用场景:
- 库存检查:在大型超市中检查库存时,可以通过扫描产品条形码快速获取该产品的库存数量、所在部门等信息。
- 工厂设备管理:在工厂车间检查设备状态时,扫描设备上的条形码,快速获取设备的性能和状态报告。
1.6 移动和组织度量值(文件夹管理)
移动度量值:度量值在数据中的位置并不重要。创建完毕后,Power BI 将新的度量值插入到您当前选定的表中。 在度量工具选项卡下,选定某个度量值并在主表下拉菜单中选择数据表,便可以轻松移动该度量值到另一个表中。
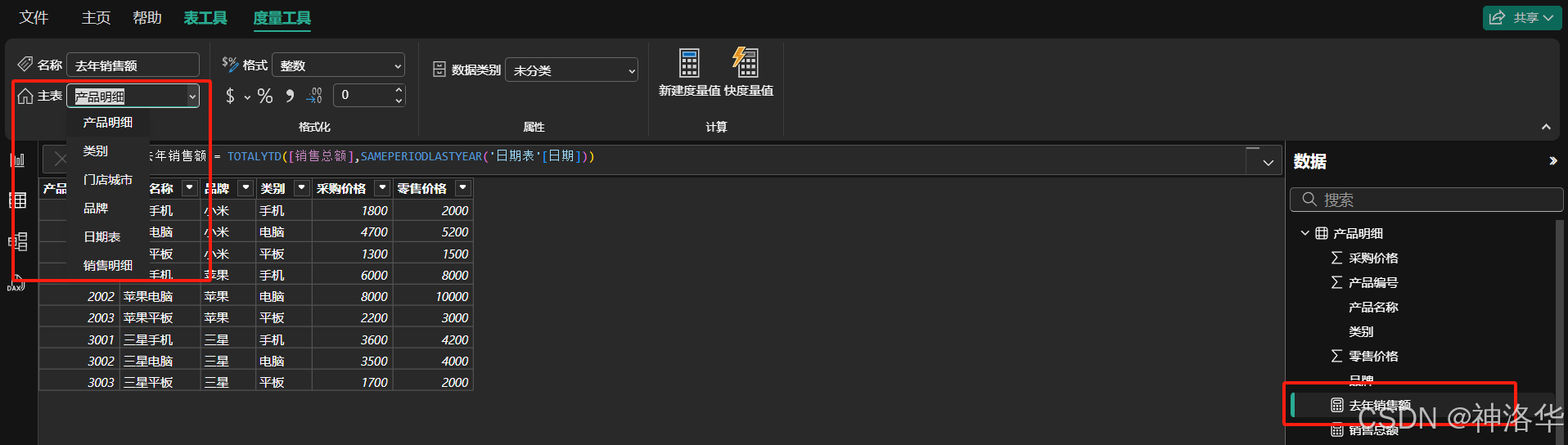
你也可以将度量值添加到文件夹中进行管理。

-
使用反斜杠字符创建子文件夹。 例如
Finance\Currencies会创建 Finance 文件夹,并在其中创建 Currencies 文件夹 。 -
使用分号分隔文件夹名称,使字段出现在多个文件夹中。 例如,
Products\Names;Departments会使字段出现在 Products 文件夹内的 Departments 文件夹以及 Products 文件夹中。
另外,还可以创建仅包含度量值的特殊表, 该表始终显示在“字段”顶部。选择输入数据创建新表,然后将度量值移动到该表。最后,隐藏该表创建时默认新建的列(或者干脆删除)。

1.7 动态格式字符串
1.7.1 FORMAT函数
FORMAT 函数主要用于将数值、日期时间等数据类型按照指定的格式转换为字符串。这对于在报表中以特定的格式显示数据非常有用,比如货币格式、日期格式、百分比格式等。其函数语法为:
FORMAT(<value>, <format_string>[, <locale_name>])
value:要格式化的值,可以是数值、日期时间、布尔值等。format_string:指定的格式字符串,用于定义如何格式化值。locale_name: 可选,表示区域设置的名称,详见视频
1.7.1.1 数字格式
| 基础格式符号 | 说明 | 示例 |
|---|---|---|
0 | 占位符,强制显示数字(无数字时显示 0) | 0000 → 0123(输入 123) |
# | 可选占位符,无数字时不显示 | ###-## → 12-34(输入 1234) |
. | 小数点分隔符 | 0.00 → 123.45 |
, | 千位分隔符或缩放数值(如 ,结尾表示千单位) | #,##0 → 1,234;0.0, → 1.2K(输入 1234) |
% | 百分比格式(自动乘以 100) | 0% → 123%(输入 1.23) |
$、€ 等 | 货币符号 | $#,##0.00 → $1,234.56 |
| 条件格式(分号 ;分隔) | 分三段定义正数、负数、零的格式 | +#,##0.00;-#,##0.00;"空" → 正数带加号,负数带负号,零显示"空" |
下面以12345.67为例,说明数字格式参数的作用。比如"Standard" 表示FORMAT(12345.67,"Standard" ),0% 表示FORMAT(12345.67,"0%" )。
| 常用数字格式 | 格式说明 | 返回值 |
|---|---|---|
| “0” | 整数格式,无小数位 | 12345 |
| “0.0” | 保留一位小数 | 12345.7 |
| “0%” | 百分比格式,乘以100并添加%符号 | 1234567% |
| “0.00%” | 百分比格式,保留两位小数 | 1234567.00% |
| “0.00E+00” | 科学计数法格式 | 1.23E+04 |
| “#,###” | 千位分隔符格式 | 12,345 |
| “#,## 0.00” | 千位分隔符格式,保留两位小数 | 1,234.56 |
| “¥#,## 0.00” | 带人民币符号的千位分隔符格式,保留两位小数 | ¥1,234.56 |
| “General Number” | 无格式化,直接显示数字 | 12345.67 |
| “Currency” | 按照本地货币格式显示,示例为美国货币格式 | $12,345.67 |
| “Fixed” | 小数点前至少一位,小数点后两位 | 12345.67 |
| “Standard” | 小数点前至少一位,小数点后两位,包含千位分隔符,示例为美国数字格式 | 12,345.67 |
| “Percent” | 以百分比形式显示,数值乘以 100,带有百分号 | 1,234,567.00% |
| “Scientific” | 以科学计数法显示,保留两位小数 | 1.23E+04 |
| “Yes/No” | 如果数字为 0,则显示NO;否则,显示YES。 | |
| “True/False” | 如果数字为 0,则显示False;否则,显示True。 | |
| “On/Off” | 如果数字为 0,则显示 Off;否则,显示“On。 |
1.7.1.2 日期/时间格式
| 日期/时间格式 | 说明 | 输出 |
|---|---|---|
| “General Date” | 显示当前区域的日期或时间 | 2025/3/24 19:23:57 |
| “Long Date” | 根据当前区域的长日期格式显示日期 | 2025年3月24日 |
| “Medium Date” | 根据当前区域的中日期格式显示日期 | 25-03-24 |
| “Short Date” | 根据当前区域的短日期格式显示日期 | 2025/3/24 |
| “Long Time” | 使用当前区域的长时间格式显示时间 | 19:23:57 |
| “Medium Time” | 使用当前区域的中时间格式显示时间 | 07:23 下午 |
| “Short Time” | 使用24小时格式显示时间 | 19:23 |
下面输出是以2018-1-1为例:
| 日期/时间格式 | 输出 | 格式参数 | 输出 |
|---|---|---|---|
| D | 1 | M | 1 |
| DD | 01 | MM | 01 |
| DDD | Mon | MMM | Jan |
| DDDDD | Monday | MMMM | January |
| AAA | 周一 | OOO | 1月 |
| AAAA | 星期一 | OOOO | 一月 |
| Q | 1 | YY | 18 |
| YYYY | 2018 | YYYYMM | 201801 |
| yyyy-mm-dd | 2018-01-01 | yyyy年m月d日 | 2018年1月1日 |
| dd/mm/yyyy | 欧洲日期格式,01/01-2018 | mm/dd/yyyy | 美国日期格式,01/01/2018 |
| yyyy-mm-dd hh:nn | 2018-01-01 13:45 | m月d日 | hh时nn分 1月1日 13时45分 |
1.7.1.3 自定义格式
除了以上预设的格式化函数,你也可以自定义格式。在自定义数字格式字符串时,格式模板可以有 一到三个部分,每个部分之间用分号分隔:
- 只有一个部分:格式表达式应用于所有值,例如
"$#,##0"。 - 有两个部分:第一部分应用于正数和零,第二部分应用于负数,例如
"$#,##0;($#,##0)"。 - 有三个部分:第一部分应用于正数,第二部分应用于负数,第三部分应用于零,例如
"$#,##0;($#,##0);Zero"
| 自定义格式 | 描述 | 示例 | 输出 |
|---|---|---|---|
| 货币格式 | 表示货币格式,千位分隔,两位小数 | FORMAT(1234.56, "$#,0.00") | $1,234.56 |
| 日期格式 | 表示完整的日期格式 | FORMAT(DATE(2023, 10, 11), "DDDD, MMMM DD, YYYY") | Wednesday, October 11, 2023 |
| 时间格式 | 表示12小时制的时间格式 | FORMAT(TIME(14, 30, 45), "HH:MM:SS AM/PM") | 02:30:45 PM |
1.7.2 创建动态格式字符串
尽管 FORMAT 函数很有用,但它会将度量值转换为字符串类型。这意味着原本应该是数值类型的度量值会被当作字符串处理,这可能会带来一些限制,比如不适用于需要数值的视觉对象(如图表)。
动态格式字符串功能允许你根据条件动态地应用格式字符串,自定义度量值的显示方式,而无需改变其数据类型。例如,可以根据度量值的大小显示不同的单位。
VAR vValue = SUM('Fact 订单'[单行折后销售额])
RETURN SWITCH(
TRUE(),
vValue >= 1000000, "0.0 百万元",
vValue >= 10000, "0.0 万元",
vValue >= 1000, "0.0 千元",
"0.0 元"
)
-
在“数据”窗格中,选择要为其指定动态格式字符串的度量值。
-
在“度量值工具”功能区>“格式设置”部分>“格式”列表框中,选择“动态”。 DAX 公式栏的左侧将出现一个已选中“格式”的新列表框。 通过此下拉列表可在静态度量值 DAX 表达式和动态格式字符串 DAX 表达式之间切换。

-
编辑DAX 表达式,设置正确的格式化字符串。
-
取消动态格式字符串
在“格式设置”部分>“格式”列表框中,选择其他格式选项,即可删除动态格式字符串效果。 由于此操作无法撤消,因此将出现一个对话框。

1.7.3 示例:货币格式转换
1.7.3.1 数据预处理
- 加载Adventure Works 模型。数据说明见《AdventureWorks Readme》
- 在“主页”功能区,选择“输入数据”,创建
Country Currency Format Strings表,用于存储不同国家货币的格式信息。
| Country | Currency | Format |
|---|---|---|
| Australia | Dollar | AU$#,0.00 |
| Canada | Dollar | C$#,0.00 |
| Denmark | Krone | kr#,0 |
| Euro Zone | Euro | € #,0.00 |
| Japan | Yen | ¥ #,0 |
| Sweden | Krona | kr#,0 |
| Switzerland | Franc | CHF#,0.00 |
| United Kingdom | Pound | £ #,0 |
| United States | Dollar | US$#,0.00 |
- 同样的方式创建年均汇率表——Yearly Average Exchange Rates,用于存储各国货币与美元的年均汇率数据。
- 添加年份列。单击“日期”表,然后选择“新建列”,输入DAX表达式:
Year = YEAR([Date]) - 创建关系:在模型视图中,建立“Country Currency Format Strings ”表与年均汇率表(Country列,单向一对多)、年均汇率表与日期表( Year列,单向多对多)之间的关系。

- 新建度量组表:通过输入数据的方式,创建一个名为
“Sales measures”的表,用于组织不同度量。 - 新建度量值:在
“Sales measures”表中,新建以下度量值:
-
销售金额:
Sales Amount = SUM(Sales[Sales Amount]) -
汇率(年均)。
Exchange Rate (Yearly Avg) = IF ( ISBLANK ( SELECTEDVALUE ( 'Country Currency Format Strings'[Country] ) ) || SELECTEDVALUE ( 'Country Currency Format Strings'[Country] ) = "United States", 1, AVERAGE ( 'Yearly Average Exchange Rates'[Yearly Average Exchange Rate] ) ) -
汇率转换后的销售额:
Converted Sales Amount = SUMX('Date', CALCULATE( [Sales Amount] * [Exchange Rate (Yearly Avg)]))
1.7.3.2 创建报表
-
添加折线图:新建报表,添加折线图,字段分别为
Converted Sales Amount和Year。 -
添加表格:将上一个折线图复制粘贴,然后改为表格类型。
-
添加切片器:字段为
Country Currency Format Strings表中 的Country列。 -
美化报表:调整视觉对象布局和格式,使报表更美观。
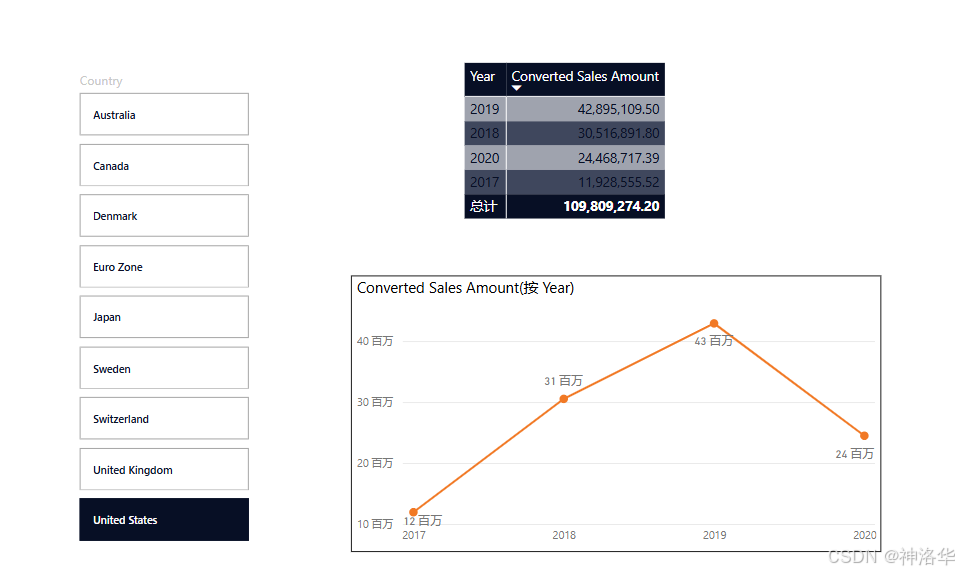
-
使用动态格式字符串。选中度量值
Converted Sales Amount,按上一节的方式,设置格式为动态,DAX表达式为:SELECTEDVALUE ( 'Country Currency Format Strings'[Format], "\$#,0.00;(\$#,0.00);\$#,0.00" )。此时通过切片器选择不同国家,销售额会自动显示为其对应的货币格式。

1.8 使用参数进行动态分析
1.8.1 基础示例
在 Power BI Desktop 中,通过创建参数,可以为报告引入变量,以实现交互式分析和可视化,例如通过一个切片器,随意选择销售折扣(0.5-1),得到计算折扣后的销售额。

-
新建参数:在“建模”选项卡中,点击“新建参数”按钮,此时会弹出一个对话框,有“字段”或“数值范围”两种类型的参数可供配置。

-
配置参数:按下图配置参数,选择“将切片器添加到此页”复选框,创建之后,会在报表页面创建一个参数切片器,同时在数据窗格中,创建了一个度量值。

创建参数后,参数和其关联的度量值将成为数据模型的一部分。这意味着它们不仅可以在当前报告页面上使用,还可以在其他报告页面上使用。
- 创建度量值:新建度量值,表示折扣后的销售额。
Sales after Discount = SUM(Sales[Sales Amount]) - (SUM(Sales[Sales Amount]) * 'Discount percentage' [Discount percentage Value])
- 创建柱状图:以OrderDate字段为X轴,
Sales Amount和Sales after Discount作为值。这样,柱状图将同时显示原始销售额和折扣后的销售额。当移动筛选器中的滑块时,折扣值会对应调整,Sales after Discount列也会对应变化。
1.8.2 使用SELECTEDVALUE优化动态计算
在动态的计算中,如果切片器没有选择任何值或者选择了多个值时,可能会导致错误。为了避免这种情况,可以使用函数进行处理。在以前的版本,通常使用 IF,HASONEVALUE,VALUES 这三个函数的组合来测试列是否按特定值进行筛选,比如:
Australian Sales Tax =
IF(
HASONEVALUE(Customer[Country-Region]),
IF(
VALUES(Customer[Country-Region]) = "Australia",
[Sales] * 0.10
)
)
HASONEVALUE:检查当前筛选器上下文中是否只有一个值,避免VALUES对多值列进行操作返回一个表(这样下一步与标量比较就会报错)。VALUES:如果只有一个值,使用 VALUES 检查这个值是否为"Australia";IF:如果值为"Australia",则计算销售税为销售额的 10%;否则,返回空白。
SELECTEDVALUE 函数会自动检查某个列是否是单个值,如果是,则返回该值;否则返回空白(默认),所以SELECTEDVALUE函数等价于:
IF(HASONEVALUE(<columnName>), VALUES(<columnName>), <alternateResult>)
使用SELECTEDVALUE可以更简洁高效地处理这个问题:
Australian Sales Tax =
IF(
SELECTEDVALUE(Customer[Country-Region]) = "Australia",
SUM(Sales[SalesAmount]) * 0.10
)
注意事项:
- 参数最多只能有 1,000 个唯一值,如果超过1000,Power BI 将对参数值进行均匀采样。此时,参数的值可能无法完全覆盖所有可能的选项,但通常足以满足大多数分析需求。
- 参数主要用于视觉对象中的度量值计算。当在维度计算中使用参数时,可能会出现计算不准确的情况。
1.9 值筛选行为
在 Power BI 中,当筛选同一表中的多个列时,DAX会自动排除无效的值组合,这种行为被称为Auto-Exist,它会影响报表筛选器的筛选结果。
假设有一个Catalog表,现在需要统计各年份各颜色的产品数量,先制作一个简单的矩阵,并添加一个卡片图,展示的度量值为:Number of Products = COUNTROWS( 'Catalog' )

接着,制作颜色切片器和年份切片器,并新建度量值计算所有年份的产品总数:
// 使用ALL函数清除Year字段上的所有筛选,包括切片器的筛选
Number of Products All Years = CALCULATE ( [Number of Products], ALL ( 'Catalog'[Year] ) )
我们筛选2023年,且产品为蓝色和红色的数据,可以看到,两个卡片图的结果分别是4和6,符合我们的预期:

如果我们将年份切换到 2024 年,则Number of Products结果应是2,Number of Products All Years 结果应该还是6,毕竟我们使用ALL函数清除所有筛选,保证计算结果包含所有年份,但实际结果为:

这是因为,在同一表上筛选多个列时,DAX 会将这些筛选器合并为一个,仅考虑存在的组合。在筛选 2024 年的产品时,因为 2024 年没有红色产品,所以将其自动剔除了,计算结果变成了5。为了解决Auto-Exist带来的潜在问题,PowerBI提供了对值筛选行为的控制选项,在模型视图的属性窗格中,用户可以在【值筛选器行为】选择以下三种行为:

- 自动:默认设置,表示启用
Auto-Exist,Number of Products All Years = 5; - 独立:强制对同一表的筛选器保持独立,不会合并为一个筛选器。使用此设置后,
Number of Products All Years = 6,度量值的计算结果将符合预期; - 合并:强制启用合并行为,将同一表中的筛选器合并为一个,
Number of Products All Years = 5。
除了利用“值筛选行为”来控制Auto-Exist行为,其实更有效的做法是优化模型,通过维度表建立星型模型,不同类型的筛选器来自于不同的维度表,就不会出现多个筛选器来自一个表的情况,也就能从根本上避免Auto-Exist引起的问题。
二、Power BI Desktop 中的计算选项
在 Power BI 中,可添加的计算选项有以下五种:
| 方面 | 自定义列 (Power Query) | 计算列 | 计算表 | 度量值 | 视觉计算 |
|---|---|---|---|---|---|
| 语言 | M | DAX | DAX | DAX | DAX |
| 计算于 | 数据刷新 | 数据刷新 | 数据刷新 | 按需 | 按需 |
| 持久性 | 存储在模型文件中 | 存储在模型文件中 | 存储在模型文件中 | 根据需要计算, 度量结果不会预先计算或存储在磁盘上 | 根据需要计算 |
| 上下文 | 行 | 行 | 行 | 筛选器 | 可视 |
| 存储在 | 表 | 模型 | 模型 | 模型 | 可视 |
| 交互性 | 静态的,不会随报表上的用户交互而更改 | 否 | 否 | 是 | 是 |
| 使用情况 | 切片器、筛选器、行、列 | 切片器、筛选器、行、列 | 在度量值、计算列或视觉计算定义中 | 视觉对象和视觉对象级别筛选器中的值 | 视觉对象和视觉对象级别筛选器中的值 |
2.1 自定义列 (略)
2.2 计算列

DAX 可以在 Power BI Desktop 的数据建模和 Power Pivot 中使用。除了创建度量值,DAX 还可以用来创建计算列(报表试图、表视图、模型视图中均可以)。计算列是添加到现有表中的列,并使用 DAX 公式定义列的值。
计算列一般用于在表之间建立关系:当不存在唯一字段时,可以创建计算列作为唯一键,例如,在 Geography 表和 Sales 表中通过组合 Country 和 Zip 列中的值来创建新的计算列 CountryZip,,它们可以用作唯一键来在两个表之间建立关系。

又比如,想把这个日期表上的月用两位数字表示,即7月用07表示,在功能区选择新建列,然后编辑栏输入以下公式即可。这将会为表中的每一行计算值,并将值存储在内存中的数据模型中。

不过除非特别有必要,不建议用新建列的方式做数据丰富,这样更占用内存。如果想增加一列,可以在源数据上,回到查询编辑器里面增加一列然后上载到数据模型中使用。另外,新建列字段图标有一个fx,而度量值字段图标是一个计算器,二者的实质区别,以后也会讲解。

计算列的值是静态的,也就是说,它们在数据加载时计算一次,并在后续的查询中保持不变,直到任何相关表的数据被刷新;或者模型从内存中卸载然后重新加载时(如关闭并重新打开 Power BI Desktop 文件),列值才会重新计算。
在 Excel 中,可以为表中的每一行使用不同的公式。 在 Power BI 中,为新列创建 DAX 公式时,它将计算表中每一行的结果。
| 特性 | 计算列 (Calculated Column) | Power Query 数据转换 |
|---|---|---|
| 作用时间 | 数据加载到数据模型后进行计算 | 数据加载前进行计算和转换 |
| 计算语言 | 使用 DAX 语言 | 使用 M 语言 |
| 计算结果 | 计算列的值是静态的,基于当前数据进行计算,直到数据刷新 | Power Query 转换结果在每次数据刷新时动态执行 |
| 数据依赖性 | 依赖于数据模型中的列,适用于数据模型内的分析和聚合 | 依赖于原始数据源,适用于数据清洗和预处理 |
| 创建位置 | 数据模型中创建 | 在 Power Query 编辑器中创建 |
| 典型应用场景 | 进行基于现有数据列的计算,例如利润计算、分类计算等 | 数据清洗、格式转换、数据合并等,例如拆分列、合并数据表等 |
2.3 计算表(Calculated Tables)

计算表不是从数据源中直接加载的,而是使用DAX 公式动态生成的。计算表允许你基于已经加载到模型中的数据来添加新表,即使用数据分析表达式(DAX)公式来定义表的值,这在某些情况下很有用,尤其当你需要进行中间计算或者想要将数据作为模型的一部分存储起来时(计算表存储为模型的一部分),例如,计算表可以用来交叉联接两个表。
计算表与其他表一样完全可操作,比如与其它表建立关系,将其字段可添加到报告可视化中。计算表中的列具有数据类型、格式,并可以属于数据类别。计算表可以命名,并且可以像任何其他表一样显示或隐藏。
假设你是一个人事经理,并且有一个“西北部员工”表和一个“西南部员工”表 。 你想要将这两个表合并为一个名为“西部地区员工”的表。

- 新建表:在 Power BI Desktop 的报表视图、表视图或模型视图中,在“计算” 组中,选择“新建表”。

- 创建计算表:在公式栏中输入以下公式,即创建了名为“西部地区员工”的新表。

计算表在角色扮演维度中很有帮助,例如日期表,可以作为订单日期、发货日期或到期日期,取决于外键关系。创建明确的计算表(如发货日期)可以得到一个独立的表,可用于查询。
同计算列一样,如果有关数据被刷新或更新,计算表将重新计算。通过任何会返回表(包括对另一个表的简单引用)的 DAX 表达式都可以定义计算表。 例如:
New Western Region Employees = 'Western Region Employees'
| 常见表函数 | 说明 | 简单示例 |
|---|---|---|
| DISTINCT | 返回表中列的不重复值。 | DISTINCT(Sales[ProductKey]) :返回 Sales 表中 ProductKey 列的所有不重复值。 |
| VALUES | 返回列中所有唯一值的列表。 | VALUES(Sales[ProductKey]) :返回 Sales 表中 ProductKey 列的所有唯一值。 |
| UNION | 合并两个或多个表中的行,要求列结构相同。 | UNION(Table1, Table2) |
| NATURALINNERJOIN | 创建两个表的自然内连接,基于具有相同名称的列。 | NATURALINNERJOIN(TableName1, TableName2) |
| NATURALLEFTOUTERJOIN | 创建两个表的自然左外连接,基于具有相同名称的列。 | NATURALLEFTOUTERJOIN(TableName1, TableName2) |
| INTERSECT | 返回两个表中都存在的行。 | INTERSECT(Table1, Table2) |
| CALENDAR | 创建一个从开始日期到结束日期的日期表。 | CALENDAR(StartDate, EndDate) |
| CALENDARAUTO | 创建一个自动日历表,通常用于时间智能计算。 | CALENDARAUTO() |
2.4 度量值 vs 计算列 vs 计算表
2.4.1 度量值 vs 计算列:计算客户最后下单日期
计算列和度量值有什么区别?以下面这个简化的订单表为例,如何计算出每个客户的最后下单时间?

-
计算列
如果是使用计算列,直接写客户最后下单日期=MAX('订单表'[订单日期]),结果都是订单表中最后一个订单日期。虽然计算列的上下文就是当前行,但是MAX等聚合函数并不能将行上下文转化为筛选上下文,也就是说当前行没有起到筛选作用,它就会返回整个表的最大订单日期。如何让当前行发生筛选作用呢?在MAX函数外围再套个CALCULATE函数就可以了。

此时,计算列的上下文就是当前行,包括当前行的每一个值,在上表中,每一行的数据是唯一的,都只能返回当前行的订单日期。如果要返回当前客户的最后下单日期,需要使用ALLEXCEPT,只保留客户列的筛选。

在计算列中使用列,可以直接使用,默认就是该列的当前行,比如返回当前订单日期的前一天,可以直接写:

-
计算表
使用新建表的方式也可以完成此功能。使用VALUES('订单表'[客户]),返回客户的不重复列表,给后面的代码提供上下文。

-
度量值
如果是在报表中使用度量值展现客户的最后一个订单日期,可以写作:最后下单日期=MAX('订单表'[订单日期])

在度量值中使用列,必须在列上套一个聚合函数,否则不能自动转换为筛选上下文,计算订单日期前一天的度量值应该这样写:
订单日期前一天 = MAX('订单表'[订单日期])-1

- 计算列只能利用当前行上下文,并且可以根据需要缩小为当前行的某一列
- 新建表可以使用DAX构建上下文
- 度量值最灵活,编写时并没有明确的上下文,写好之后,并不会立即计算。之后放到什么上下文中,就执行什么运算;或者说需要什么计算,就给度量值提供什么上下文。
所以利用DAX解决问题时,首先应想到上下文是什么,新建列时如何利用当前行的上下文?在建度量值之前,也首先应该想清楚,我需要构建怎样的上下文环境才能得到期望的结果,然后根据这个上下文环境,来编写对应的度量值代码。
一般来说,为了性能考虑,能用度量值解决的问题就尽量不用计算列,有三种情况除外:
- 需要利用新建的计算列生成切片器(度量值不能用于切片器)
- 需要用这个字段与其他表建立关系时。
- 需要创建很复杂的字段。复杂字段需要时间来运算,所以最好创建新建列提前进行计算,而不是使用度量值在需要用的时候再进行计算,这样可以带来更流畅的体验。
2.4.2 度量值 vs 计算表:统计客户表

对于上表,仅购买过一个产品类目的客户有哪些?购买过多个产品类目的客户有哪些?分别购买了哪些类目?这个问题的关键是先统计出每个客户购买了几个类目(使用SUMMARIZE进行统计),然后使用FILTER返回返回购买了一个和多个类目的客户列表就行了。

对于购买了多个类目的客户,还要列出来购买了哪些类目,可以在上面这个代码的基础上优化一下:

但是通过这种方式返回的客户列表是固定的,因为它的上下文已经被固化了如果想要动态的实现需求,比如按照日期切片器,计算不同时间段的客户列表,只需要建两个简单度量值:
类目数量 = DISTINCTCOUNT('订单表'[产品类目])
类目列表 =
CONCATENATEX(
SUMMARIZE('订单表','客户表'[客户],'订单表'[产品类目]),
'订单表'[产品类目],"、")
把这两个度量值放入到矩阵中,客户名称作为行标题,就可以实现动态筛选:

通过上面的示例,应该可以看出二者的区别,虽然都能返回一个特定的结果,但度量值更有优势:
- 代码更加简短,因为无需在代码中指明上下文;
- 计算更加灵活,因为它可以根据不同的上下文,实现动态的计算。
所以当你有了一个分析需求,想用PowerBI实现时,不要一上来就想DAX怎么写,而是先梳理自己的需求,审视自己的数据,最终的落脚点还是数据建模。
- 想要静态还是动态的效果?是用新建表、计算列还是度量值来实现?
- 不同方式下,能提供的上下文是什么?
- 这个上下文是否有对应的维度表?维度表与事实表是否已经建立了正确的关系?
2.5 视觉计算
视觉计算是一种直接在视觉对象上定义和执行的 DAX 计算。与传统 DAX 计算不同,视觉计算不存储在模型中,而是存储在视觉对象上,只能引用视觉对象上的内容(包括列、度量值或其他视觉对象计算), 这意味着视觉对象计算不必担心筛选器上下文和模型的复杂性,简化了编写 DAX 的过程,便于维护且性能更优。可以使用视觉计算来完成常见的业务计算,例如累加总和或移动平均。
视觉计算结合了计算列的简单性(引用视觉结构,更直观)和度量值的按需计算灵活性,且在聚合数据上操作(而不是细节级别),通常会带来性能优势。如果你的模型中建了太多的度量值,导致模型变得臃肿而混乱,那么可以尝试可视化计算,它只使用于当前的视觉对象,不会存储在模型中。
2024 年 9 月之前,需在“选项和设置”>“选项”>“预览功能”中启用“视觉计算”,之后重启 Power BI Desktop。从 2024 年 9 月起,视觉计算默认启用,但仍处于预览阶段,可通过上述设置禁用。
2.5.1 添加视觉计算
- 新建视觉计算:选择视觉对象,点击功能区中的“新建视觉计算”按钮(或者右键单击视觉对象,弹出菜单中也会显示此选项)打开视觉计算窗口,开启编辑模式。编辑模式屏幕由三个主要部分组成:
- 视觉预览:显示你正在使用的视觉对象
- 公式栏:用于添加视觉计算
- 视觉矩阵:显示视觉对象中的数据,并显示视觉对象计算结果。注意,应用于视觉对象的任何样式或主题都不适用于视觉对象矩阵。
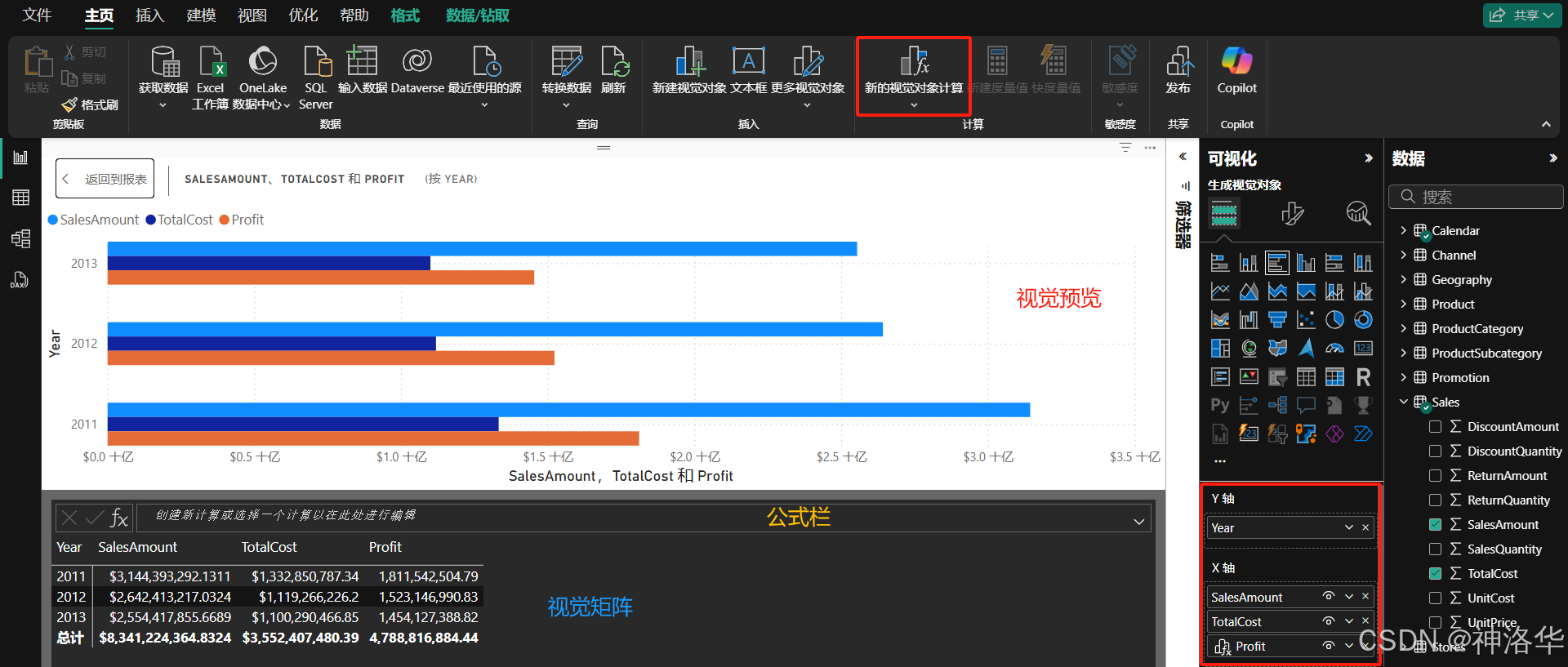
- 编辑视觉计算:下面是一个视觉计算示例,用于定义销售金额的累加和。在包含 Sales Amount 和 Total Product Cost by Fiscal Year 的视觉对象中,输入
Profit = [SalesAmount] – [TotalCost],添加视觉计算,计算每年利润。

- 特性:视觉计算在默认情况下会逐行计算,而不需要额外的聚合操作,这使得它与度量值的计算方式有所不同,并且更加简洁和直观(如果无需聚合,最好不要像在度量中那样添加诸如SUM这样的聚合函数)。本例中,对于视觉矩阵的每一行,会将当前行的“销售额”和“总产品成本”相减,然后将结果返回到“利润”列中,就像是生成一个计算列一样。
- 限制:由于视觉计算在视觉矩阵的范围内工作,因此依赖于模型关系(RELATIONSHIP、RELATED 或 RELATEDTABLE)的函数不可用。
2.5.2 隐藏视觉中的字段
添加视觉计算时,它们将显示在视觉对象的字段列表中,可以像在建模视图中一样隐藏视觉中的字段。隐藏字段不会从视觉或视觉矩阵中移除,视觉计算仍可引用它们,但不会显示在最终视觉中。比如隐藏“销售额”和“总产品成本”字段,只显示“利润”字段。

2.5.3 快捷模板
视觉计算提供模板简化常用计算编写。点击模板按钮选择模板,或从“新建视觉计算”按钮底部创建带模板的视觉计算。可用模板包括累计和、移动平均、父级百分比等。

| 模板名称 | 描述 | 使用函数 |
|---|---|---|
| Running sum | 计算累计和,将当前值加到前面的值上。 | RUNNINGSUM |
| Moving average | 在给定窗口中计算一组值的移动平均值,通过将值的总和除以窗口大小来实现。 | MOVINGAVERAGE |
| Percent of parent | 计算值相对于其父级的百分比。 | COLLAPSE |
| Percent of grand total | 计算值相对于所有值的百分比。 | COLLAPSEALL |
| Average of children | 计算一组子值的平均值。 | EXPAND |
| Versus previous | 将值与前面的值进行比较。 | PREVIOUS |
| Versus next | 将值与后面的值进行比较。 | NEXT |
| Versus first | 将值与第一个值进行比较。 | FIRST |
| Versus last | 将值与最后一个值进行比较。 | LAST |
2.5.4 可选参数
2.5.4.1 Axis参数(轴)
许多函数有可选的 Axis 参数,仅能在视觉计算中使用,影响视觉计算如何遍历视觉矩阵。Axis 参数默认设置为视觉的第一个轴(通常是行),这意味着视觉计算在视觉矩阵中是逐行从上到下进行计算的。

2.5.4.2 Reset参数(重置)
许多函数有可选的 Reset 参数,仅在视觉计算中可用,用在设置函数在遍历视觉矩阵时是否将其值重置为 0,或者切换到不同的范围进行计算,默认为 None(不重置)。
NONE:默认值,不会重置计算。HIGHESTPARENT:当轴上最高级别的父级值发生变化时,重置计算。LOWESTPARENT:当轴上最低级别的父级值发生变化时,重置计算。- 数值:通过数值来指定轴上的字段,以确定重置计算的位置。
- 为零或省略:不重置,等同于 NONE。
- 为正数:从最高级别的列开始标识,不依赖于粒度。数值 1 等同于 HIGHESTPARENT。
- 为负数:从最低级别的列开始标识,相对于当前粒度。数值 -1 等同于 LOWESTPARENT。
- 字段引用:只要字段在视觉上可用,就可以通过字段引用进行重置,根据指定字段的值变化来重置计算。
假设轴上有三个字段,分别位于多个级别:年(Year)、季度(Quarter)和月份(Month)。在这种情况下,HIGHESTPARENT 是年(Year),LOWESTPARENT 是季度(Quarter)。
-
按年重置累计和:以下视觉计算是等效的,都返回每个年份从 0 开始的销售金额累计和。
RUNNINGSUM([Sales Amount], HIGHESTPARENT) RUNNINGSUM([Sales Amount], 1) RUNNINGSUM([Sales Amount], -2) RUNNINGSUM([Sales Amount], [Year]) -
按季度重置累计和
RUNNINGSUM([Sales Amount], LOWESTPARENT) RUNNINGSUM([Sales Amount], 2) RUNNINGSUM([Sales Amount], -1) -
不重置累计和:持续将每个月的销售金额值添加到之前的值上,不会重新开始
RUNNINGSUM([Sales Amount])
2.5.4.3 对比 ORDERBY 和 PARTITIONBY
Axis(轴)和Reset(重置)、ORDERBY(排序依据)和 PARTITIONBY(分区依据)都影响计算评估方式,但是它们的抽象级别不同:
- 前者仅用于视觉计算,因为是引用的视觉结构
- 后者可以在计算列、度量值和视觉计算中使用,它们通过显式指定字段来执行排序和分区
另外,Axis 和 Reset 更灵活,因为它们不依赖于具体的字段。当轴上没有多个级别(例如只有一个字段或多个字段在同一个级别上)时,可以使用 PARTITIONBY。
组合使用时,可以同时指定 Axis,ORDERBY, PARTITIONBY,此时 ORDERBY 和 PARTITIONBY 的设置会覆盖 Axis 的设置。Reset 不能与 ORDERBY 和 PARTITIONBY 一起使用。
2.5.5 设置视觉对象计算的格式
可通过数据类型和格式选项格式化视觉计算,比如在视觉格式窗格的常规部分中,使用数据格式选项设置格式。
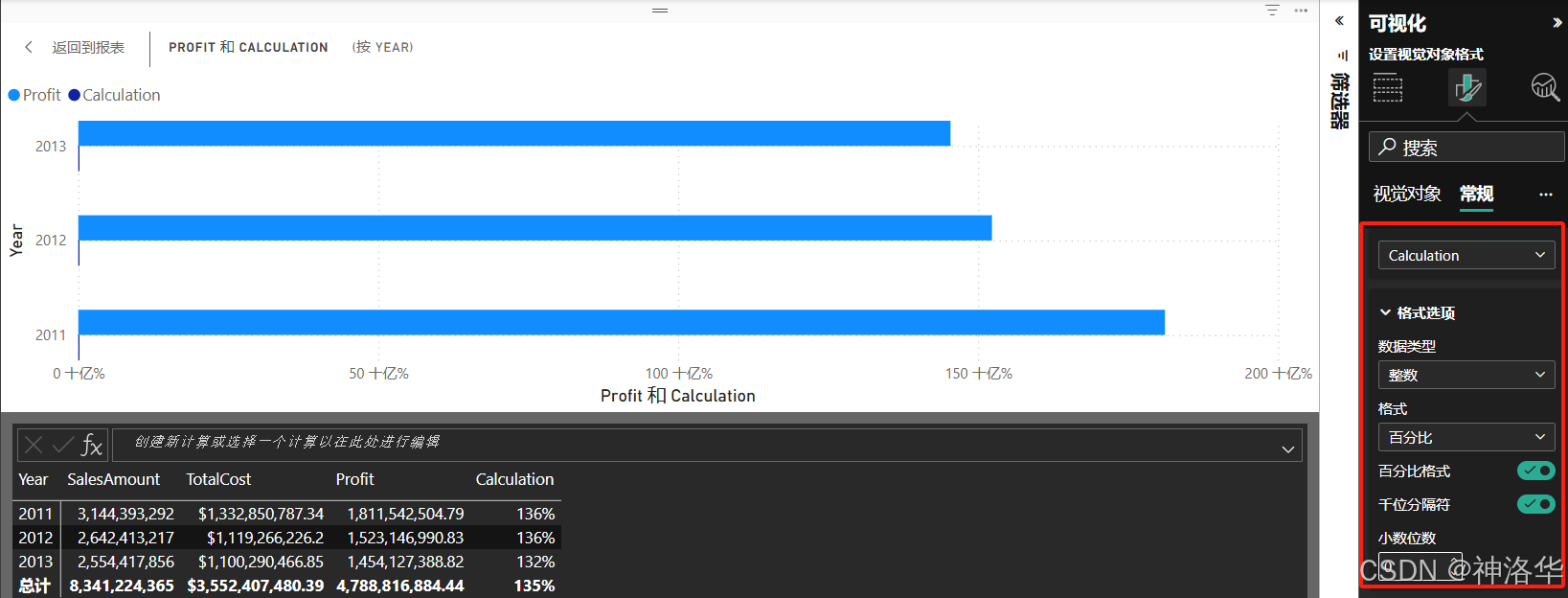
也可使用FORMAT函数来显示格式:

2.5.6 预览期间的限制
-
不支持所有视觉类型,某些视觉类型和属性不兼容;

-
无法通过复制粘贴重用;无法筛选视觉计算;
-
不能以相同或不同的详细信息级别引用自身;
-
视觉计算或隐藏字段的个性化设置不可用;
-
无法固定到到仪表板;无法使用“发布到 Web”功能;
-
数据导出不包含视觉计算结果; 隐藏字段永远不会包含在导出中,除非导出基础数据。
-
无法使用“查看记录”钻取功能;
-
无法设置数据类别;无法更改聚合、无法更改排序顺序;
-
Power BI Embedded 和 SQL Server Analysis Services 的实时连接不支持;
-
尽管可以对视觉计算使用 字段参数 ,但它们有一些限制;
-
显示无数据的项目选项不可用;
三、 计算组( Calculation Groups)
3.1 计算组简介
计算组是在 Analysis Services 表格模型(兼容级别 1500 及更高版本)以及 Power BI 模型中提供的一项重要功能,其主要目的是通过将通用的度量值表达式组织为计算项,从而显著减少模型中冗余度量值的数量 。计算组能够简化复杂模型,尤其是在处理如时间智能等需要大量类似计算的场景时。总结起来,计算组的优势有:
- 减少冗余度量值: 例如,分析师想要查看2012-2013年销售总额和订单的年初至今 (YTD)、季度至今 (QTD)、月度至今 (MTD) 以及去年同期 (YTD) 等结果时,如果没有计算组,用户需要为每种计算创建单独的度量值,将它们进行排序,并单独应用于报表。如果创建了时间智能计算组,将其拖到列区域,将自动生成不同的时间智能结果。

- 简化用户体验:报表用户不再需要在众多的相似度量值中筛选。通过计算组,用户只需将一个计算组列拖到可视化效果中,即可动态应用不同的计算
- 提高模型维护性:当需要修改通用计算逻辑时,只需要更新计算组中的计算项,而无需修改多个独立的度量值
- 支持 MDX 查询:Excel 等使用 MDX 查询表格模型的工具可以充分利用计算组的功能
以上时间智能示例,来自Analysis Services 计算组,,该示例可以添加到按日期和标记为日期表的 Date 表的任何模型,也可以从 DAX 示例模型下载 Adventure Works DW 2020 PBIX - DAX。
3.2 计算组的工作原理
-
计算项 (Calculation Items):计算组由一个或多个计算项组成,每个计算项都包含一个 DAX 表达式,这些表达式定义了如何修改应用了该计算项的基础度量值的计算 。
-
显式度量值 (Explicit Measures):计算组只能应用于模型中已存在的显式 DAX 度量值,不能直接应用于隐式度量值(自动度量值) 。
显式度量值即通过使用 DAX 公式(例如
SUM,AVERAGE)明确创建的度量值。隐式度量值 (Implicit Measures) 是在报表视图中,用户直接将数据列拖拽到可视化效果并进行聚合时,Power BI 自动创建的度量值 -
报表呈现:在 Power BI 等报表工具中,计算组在“数据”窗格中显示为一个表,其中包含一个或多个计算项 。通常会将计算组的列拖拽到可视化效果的“列”区域或用作切片器,以动态地将相应的计算项应用于已添加到“值”区域的度量值。
3.3 创建计算组
- Power BI Desktop:
-
在模型视图中,选择功能区中的计算组按钮 ,如果“阻止隐式度量值”属性未启用,系统会提示启用 。启用后,数据窗格中的数据列将不再显示求和符号,并且无法直接将数据列拖到可视化组件的聚合轴或值字段中。不过,已经创建的隐式度量仍然可以正常工作。


-
创建后,可以在 DAX 公式栏中为第一个计算项定义 DAX 表达式,通常使用
SELECTEDMEASURE()函数作为基础度量值的占位符。
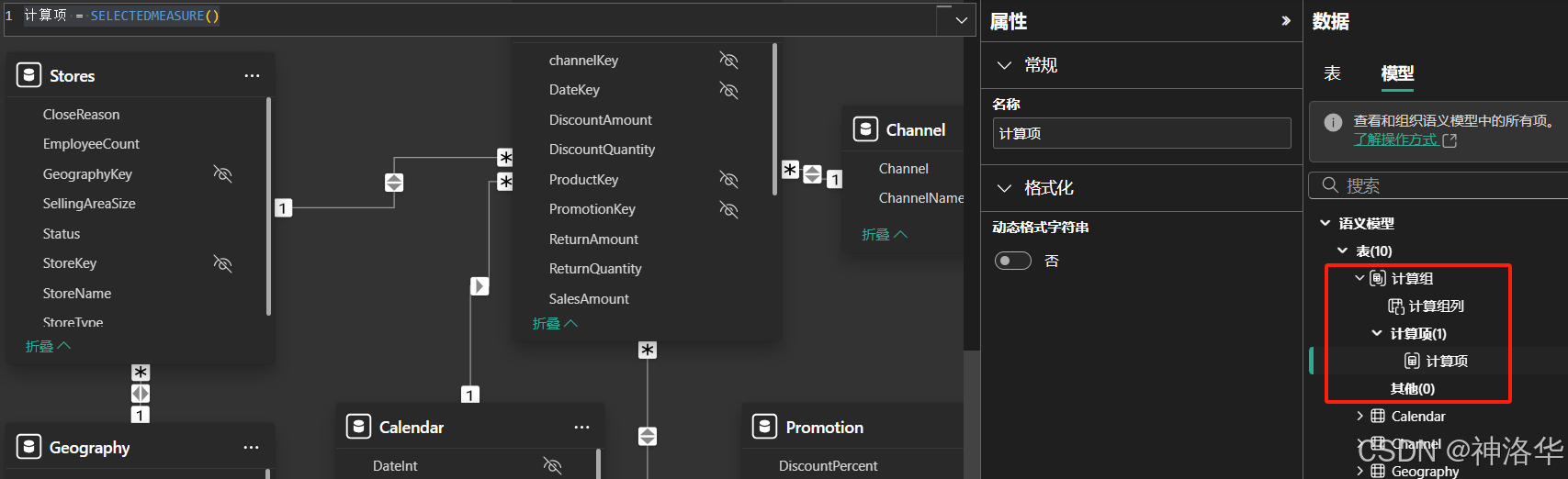
-
如果你不想让计算项改变某些度量值,你可以通过度量值名称,指定计算项忽略这个显式度量。
-
- 其他工具: Visual Studio with Analysis Services Projects、表格模型脚本语言 (TMSL) 和 Tabular Editor 也支持创建计算组
3.4 管理和使用计算项
-
重命名: 可以通过在数据窗格中双击字段、或在“属性”窗格来修改计算组、计算组列和计算项的名称。

-
添加计算项: 通过右键单击计算组或“计算项”部分;或者通过计算项的属性窗格来添加计算项。

-
编辑 DAX 表达式: 为每个计算项输入或修改 DAX 表达式。例如,时间智能计算项可以使用
DATESYTD(),DATESQTD(),DATESMTD(),SAMEPERIODLASTYEAR()等函数 -
重新排序: 在“属性”窗格的“计算项”部分、或使用右键菜单,可以调整计算项在报表中的显示顺序 。这仅影响显示顺序,不影响计算逻辑的优先级。

-
在报表中使用计算项:
- 切换到报表视图,创建一个矩阵可视化组件。
- 将日期表(Date table)中的月份列(Month column)添加到行区域。
- 时间智能计算组(Time Intelligence calculation group)中的时间计算(Time Calculation)添加到列区域
- 新建订单度量值(“Sales Order”表中不同销售订单的数量),
Orders = DISTINCTCOUNT('Sales Order'[Sales Order]),将其添加到值区域。

你也可以通过将计算组列添加到切片器(Slicer)可视化中,将单个计算项应用于多个度量值。

-
在度量值中使用计算项:可以使用 DAX 表达式来利用特定度量值上的计算项。例如,要创建一个“订单年同比百分比”(Orders YOY%)度量值,可以使用以下 DAX 表达式:
Orders YOY% = CALCULATE( [Orders], 'Time Intelligence'[Time Calculation] = "YOY%" )
3.5 计算项函数
| 关键 DAX 函数 | 描述 |
|---|---|
SELECTEDMEASURE() | 在计算项的 DAX 表达式中,引用当前上下文中的基础度量值 |
SELECTEDMEASURENAME() | 返回当前上下文中基础度量值的名称 |
ISSELECTEDMEASURE(<度量值名称>[, <其他度量值名称>]) | 判断当前上下文中的基础度量值是否在指定的列表中 |
SELECTEDMEASUREFORMATSTRING() | 返回当前上下文中基础度量值的格式字符串 |
| 时间智能计算项(优先级20) | 函数描述 | DAX 表达式 |
|---|---|---|
| Current | 当前时间段的值 | SELECTEDMEASURE() |
| MTD (Month to Date) | 月初至今的累计值 | CALCULATE(SELECTEDMEASURE(), DATESMTD(DimDate[Date])) |
| QTD (Quarter to Date) | 季度初至今的累计值 | CALCULATE(SELECTEDMEASURE(), DATESQTD(DimDate[Date])) |
| YTD (Year to Date) | 年初至今的累计值 | CALCULATE(SELECTEDMEASURE(), DATESYTD(DimDate[Date])) |
| PY (Previous Year) | 去年同期的值 | CALCULATE(SELECTEDMEASURE(), SAMEPERIODLASTYEAR(DimDate[Date])) |
另外还包括:
-
PY MTD:
CALCULATE( SELECTEDMEASURE(), SAMEPERIODLASTYEAR(DimDate[Date]), 'Time Intelligence'[Time Calculation] = "MTD" ) -
PY QTD:
CALCULATE( SELECTEDMEASURE(), SAMEPERIODLASTYEAR(DimDate[Date]), 'Time Intelligence'[Time Calculation] = "QTD" ) -
PY YTD:
CALCULATE( SELECTEDMEASURE(), SAMEPERIODLASTYEAR(DimDate[Date]), 'Time Intelligence'[Time Calculation] = "YTD" ) -
YOY:
SELECTEDMEASURE() - CALCULATE( SELECTEDMEASURE(), 'Time Intelligence'[Time Calculation] = "PY" ) -
YOY%:
DIVIDE( CALCULATE( SELECTEDMEASURE(), 'Time Intelligence'[Time Calculation]="YOY" ), CALCULATE( SELECTEDMEASURE(), 'Time Intelligence'[Time Calculation]="PY" ) ) -
时间智能查询
EVALUATE CALCULATETABLE ( SUMMARIZECOLUMNS ( DimDate[CalendarYear], DimDate[EnglishMonthName], "Current", CALCULATE ( [Sales], 'Time Intelligence'[Time Calculation] = "Current" ), "QTD", CALCULATE ( [Sales], 'Time Intelligence'[Time Calculation] = "QTD" ), "YTD", CALCULATE ( [Sales], 'Time Intelligence'[Time Calculation] = "YTD" ), "PY", CALCULATE ( [Sales], 'Time Intelligence'[Time Calculation] = "PY" ), "PY QTD", CALCULATE ( [Sales], 'Time Intelligence'[Time Calculation] = "PY QTD" ), "PY YTD", CALCULATE ( [Sales], 'Time Intelligence'[Time Calculation] = "PY YTD" ) ), DimDate[CalendarYear] IN { 2012, 2013 } )时间智能查询返回应用的每个计算项的计算表:

3.6 动态格式字符串
传统的FORMAT函数可以根据条件改变数值的显示格式,例如,将数字格式化为货币、百分比或带有千位分隔符的数字,但它会将度量值转换为字符串类型。这意味着原本应该是数值类型的度量值会被当作字符串处理,这可能会带来一些限制(大多数依赖于数值的 Power BI 可视化无法正确处理字符串类型的数据)。
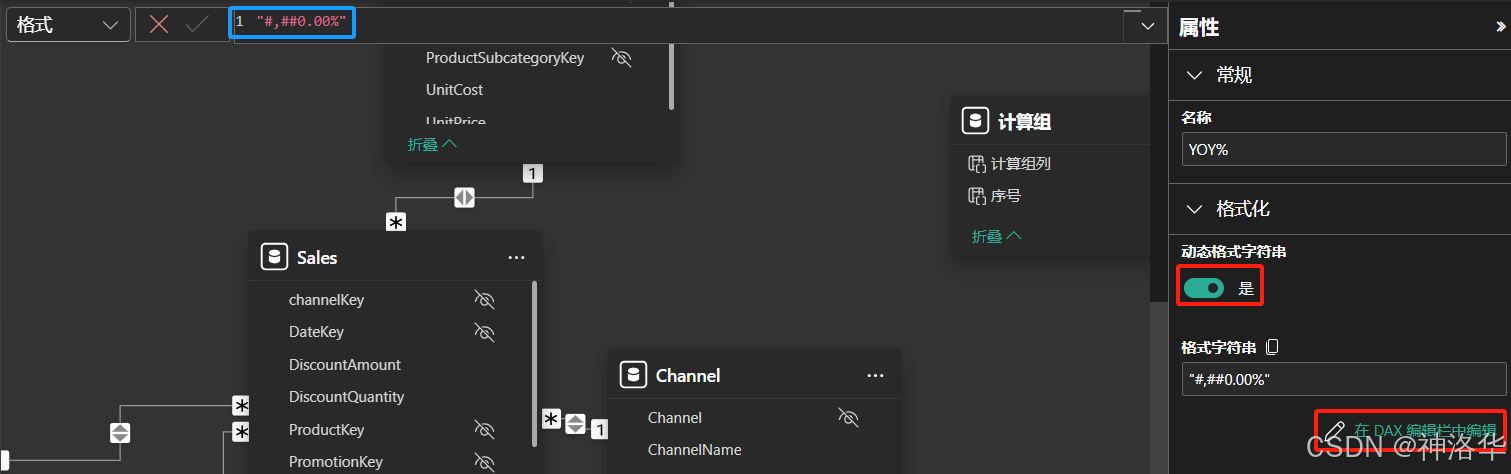
动态格式字符串允许对特定度量值有条件地应用格式,而不需要将度量值转换为字符串类型,此功能也适用于计算组。若要详细了解格式字符串表达式属性,请参阅FORMAT STRING。
选中一个计算项,然后在“属性”窗格中启用“动态格式字符串”,即可使用 DAX 表达式定义格式 。例如,可以将 YOY% 计算项的格式设置为百分比 (#,##0.00%),而不管基础度量值(如销售额或订单数)的原始格式如何。

货币转换场景中,可以根据上下文中的货币信息动态设置格式,详见《货币换算示例》
3.7 选择表达式 (预览功能)
选择表达式是为计算组定义的可选属性。目前,共有两种类型的选择表达式:
multipleOrEmptySelectionExpression:未定义时默认不进行筛选 , 你也可以通过此表达式返回自定义文本或执行特定计算。以下三种情况触发:- 选择了多个计算项;
- 选择了不存在的计算项;
- 进行了冲突的选择。
noSelectionExpression:当计算组未被筛选时触发,可用于实现默认行为。例如在没有选择任何货币时自动转换为基准货币 。
这两个选择表达式还可以关联一个 formatStringDefinition 来定义动态格式字符串 ,例如:
...
"calculationGroup": {
"multipleOrEmptySelectionExpression": {
"expression": "",
"formatStringDefinition": {...}
},
"noSelectionExpression": {
"expression": "",
"formatStringDefinition": {...}
}
...
}
这些表达式(如果指定)仅适用于上述特定情况。 单个计算项的选择不受这些表达式的影响。
3.7.1 未定义选择表达式
下表概述了在未定义选择表达式时不同选择类型的默认行为:
| 选择类型 | 未定义选择表达式(默认) |
|---|---|
| 单个选择 | 应用所选内容 |
| 多个选择 | 计算组不被筛选 |
| 空选择 | 计算组不被筛选 |
| 没有选择 | 计算组不被筛选 |
3.7.2 已定义选择表达式
如果对同一计算组进行了多个选择,则计算组将计算并返回 multipleOrEmptySelectionExpression定义的结果。 如果尚未定义此表达式,则计算组将返回SELECTEDMEASURE()。
假设有一个名为 “MyCalcGroup” 的计算组,并配置了以下 multipleOrEmptySelectionExpression:
IF (
ISFILTERED ( 'MyCalcGroup' ),
"Filters: "
& CONCATENATEX (
FILTERS ( 'MyCalcGroup'[Name] ),
'MyCalcGroup'[Name],
", "
)
)
-
多项选择:使用以下查询,选择了 “item1” 和 “item2” 这两个计算项,将返回**“Filters: item1, item2”**。
EVALUATE { CALCULATE ( [MyMeasure], 'MyCalcGroup'[Name] = "item1" || 'MyCalcGroup'[Name] = "item2" ) } -
空选择:执行以下查询,选择了不存在的 “item4”,将返回:"Filters: "。
EVALUATE { CALCULATE ( [MyMeasure], 'MyCalcGroup'[Name] = "item4" -- item4 does not exists ) } -
当计算组没有被筛选时,将应用
noSelectionExpression。它主要用于在用户未采取任何操作的情况下执行默认操作,同时仍然为用户提供了覆盖默认操作的灵活性。
例如,以美元作为中心枢轴货币的自动货币转换,可以设置一个具有以下noSelectionExpression的计算组:IF ( //检查上下文中是否只有一种货币且不是作为枢轴货币的美元: SELECTEDVALUE ( DimCurrency[CurrencyName], "US Dollar" ) = "US Dollar", SELECTEDMEASURE (), SUMX ( VALUES ( DimDate[DateKey] ), CALCULATE ( DIVIDE ( SELECTEDMEASURE (), MAX ( FactCurrencyRate[EndOfDayRate] ) ) ) ) )同时为此表达式设置
formatStringDefinition:SELECTEDVALUE( DimCurrency[FormatString], SELECTEDMEASUREFORMATSTRING() )现在,如果没有选择任何货币,所有货币将根据需要自动转换为枢轴货币(美元)。此外,用户仍然可以选择其他货币进行转换,而无需像没有
noSelectionExpression那样切换计算项。
总而言之,选择表达式为处理计算组在特定选择场景下的行为提供了额外的控制和灵活性。multipleOrEmptySelectionExpression 用于管理多选、空选或无效选择的情况,而 noSelectionExpression 则用于定义在计算组未被筛选时的默认行为,例如在货币转换场景中自动应用枢轴货币。
3.8 优先级 (Precedence)
优先级是计算组的一个属性,用于确定当多个计算组应用于同一个基础度量值时,它们的计算顺序 ,数值越高,优先级越高 。
在计算时,优先级较高的计算组的计算项首先被应用。其 SELECTEDMEASURE() 会被替换为下一个优先级较低的计算组的表达式,依此类推,直到原始的基础度量值。 动态格式字符串的优先级: 只有优先级最高的计算组的动态格式字符串会被应用到最终结果 ,基础度量值自身的动态格式字符串优先级最低 。
如果有一个优先级为 100 的计算组执行“加 2”操作,另一个优先级为 200 的计算组执行“乘以 2”的操作,那么对于一个值为 10 的基础度量值,最终的计算将是 ((10) + 2) * 2 = 24 。
'Measure group'[Measure] = 10 //基础度量值
'Calc Group 1 (Precedence 100)'[Calc item (Plus 2)] = SELECTEDMEASURE() + 2 //计算组1,优先级100
'Calc Group 2 (Precedence 200)'[Calc item (Times 2)] = SELECTEDMEASURE() * 2 //计算组2,优先级200
( SELECTEDMEASURE() + 2 ) * 2 //选择两个切片器之后,合并 DAX 表达式
在 Power BI Desktop 中,我们有一个卡视觉对象,其中显示了报表视图中每个计算组的度量值和切片器。选择这两个切片器后,需要合并 DAX 表达式。 为此,我们从优先级最高的计算项 200 开始,然后将 SELECTEDMEASURE () 参数替换为下一个最高的 100,继续操作,直到到达基础度量值为止。整个计算过程为:
SELECTEDMEASURE() * 2
( SELECTEDMEASURE() + 2 ) * 2
( ( 10 ) + 2 ) * 2 = 24

你也可以使用 SSMS 或 Tabular Editor 等工具通过 XMLA 脚本设置计算组的优先级。另外还有平均值的优先级示例等,详见《优先级》。
3.9 横向递归 (Sideways Recursion)
在同一计算组中,某些计算项可能引用了组内的其他计算项,这种现象称为横向递归,仅当这些引用位于不同的 CALCULATE 语句中时才被支持,因为每个 CALCULATE 会创建不同的筛选器上下文并独立评估表达式 ,不支持其他类型的递归。例如,YOY% 计算项引用了同一个计算组中的 YOY 和 PY 计算项。
DIVIDE(
CALCULATE(
SELECTEDMEASURE(),
'Time Intelligence'[Time Calculation]="YOY"
),
CALCULATE(
SELECTEDMEASURE(),
'Time Intelligence'[Time Calculation]="PY"
)
)
3.10 筛选器上下文中的单个计算项
在时间智能示例中,PY YTD(去年同期至今年)计算项有一个单一的 CALCULATE 表达式:
CALCULATE(
SELECTEDMEASURE(),
SAMEPERIODLASTYEAR(DimDate[Date]),
'Time Intelligence'[Time Calculation] = "YTD"
)
CALCULATE() 函数中的 YTD 参数覆盖了过滤上下文,重用了 YTD 计算项中已经定义的逻辑。在单个评估中不可能同时应用 PY 和 YTD。只有当计算组中的单个计算项在过滤上下文中时,计算组才会被应用。
3.11 排序 (Ordering)
默认情况下,报表中的计算项按其名称的字母顺序排序 。可以通过为计算项设置 Ordinal 属性来改变其在报表中的显示顺序(仅影响显示顺序,不影响计算优先级 ) 。
要使用 Ordinal 属性,需要在计算组中添加一个额外的列,数据类型为“整数”,最好将隐藏属性设置为 True。 Ordinal 属性值越小,显示越靠前。默认值为 -1 的未排序计算项将显示在已排序的项之前。
3.12 局限性
- 不支持在计算组表上定义对象级别安全性 (OLS) ;
- 不支持行级别安全性 (RLS) 直接应用于计算组 ;
- 不支持详细信息行表达式 (Detail Rows Expressions) ;
- Power BI 中的智能叙述视觉对象 (Smart narrative visuals) 不支持计算组 ;
- 对于包含计算组的模型,Power BI 中不支持隐式列聚合即使“阻止隐式度量值”属性设置为 false,聚合选项也会显示但无法应用;如果设置为 true,则不显示 ;
- 使用 LiveConnection 创建 Power BI 报表时,动态格式字符串不会应用于报表级别的度量值
四、 模型资源管理器
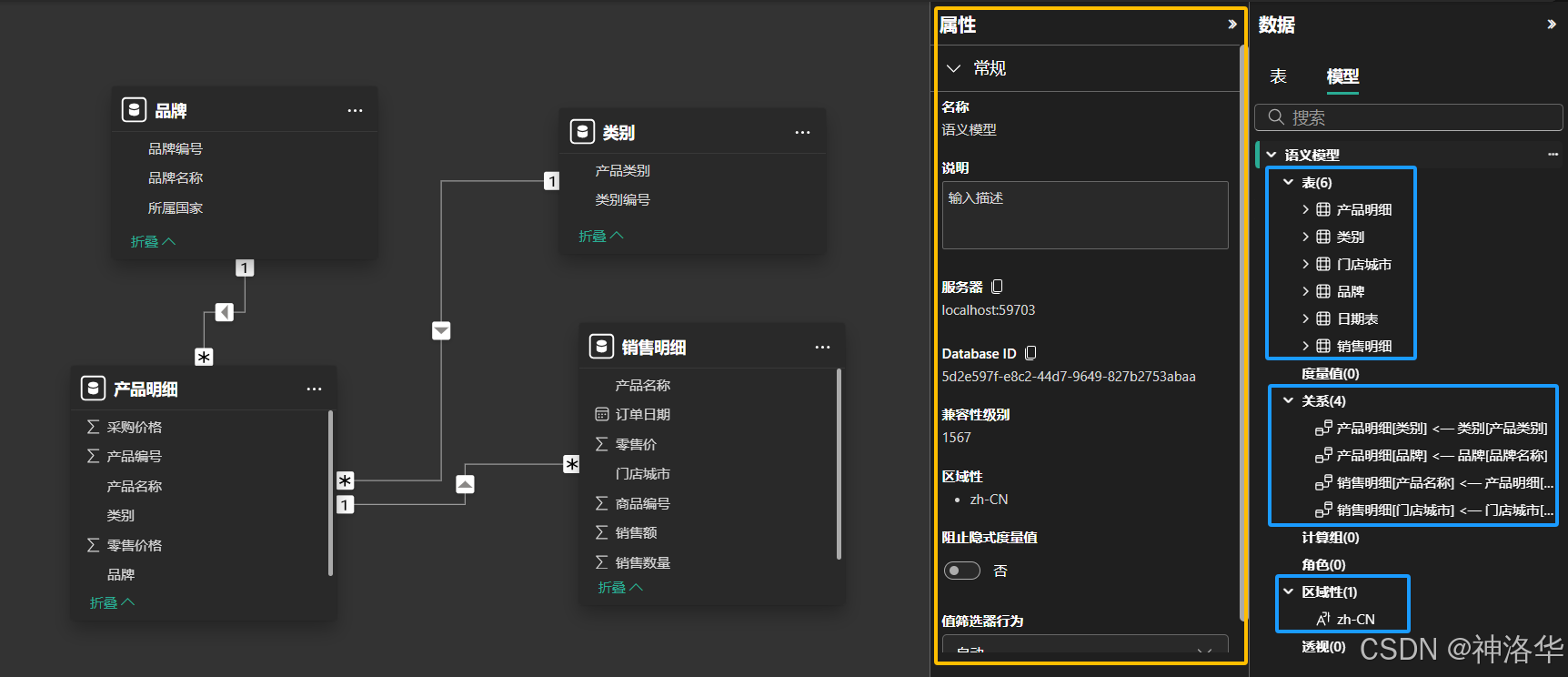
在模型视图的数据窗格顶部,可以看到表和模型两个选项。点击模型即可查看模型资源管理器。
模型资源管理器以树视图形式显示语义模型或数据模型,并显示每个节点中的项数。用户可以通过它查看和操作包含许多表格、关系、度量值、角色、计算组、翻译和透视的复杂语义模型。
-
语义模型:是有关数据的所有元数据,它影响您的数据在报告和 DAX 查询中的显示方式。属性窗格显示语义模型的属性。
-
语义模型的项:
- 语义模型可以有许多不同的项,这些项不会显示在数据窗格中,因为它们不会直接用于视觉效果,但这些项会影响报告和模型数据的行为方式,对于报告作者和消费者来说非常重要。
- 通过搜索可以快速找到项,通过展开和折叠不同的项部分来专注于您想要执行的操作。每个部分的计数显示您拥有的每种项的数量。
-
表:您可以在模型资源管理器中创建或编辑模型中的表。方法类似于数据窗格中的“表”区域,但这里的信息包括每个表的子部分,从而对行进行整理。
- 在“常规”选项卡下,你可以:
- 编辑列的名称和描述
- 添加可在使用问答功能时用于标识列的同义词。
- 在文件夹中添加列用于进一步整理表结构。
- 隐藏或显示列。
- 在“格式设置”选项卡下,你可以更改数据类型,设置日期格式。
- 在“高级”选项卡下,你可以:
- 按特定列排序
- 为数据分配特定类别
- 汇总数据。
- 确定列或表是否包含 null 值。

- 在“常规”选项卡下,你可以:
-
计算组:您可以创建或编辑计算组以减少冗余度量,详见《创建计算组》、《在 Power BI Desktop 中使用计算选项》
-
度量值:您可以创建或编辑度量值,并一起查看模型中的所有度量值,即使它们位于不同的表或文件夹中。详见《在 Power BI Desktop 中创建你自己的度量值》

-
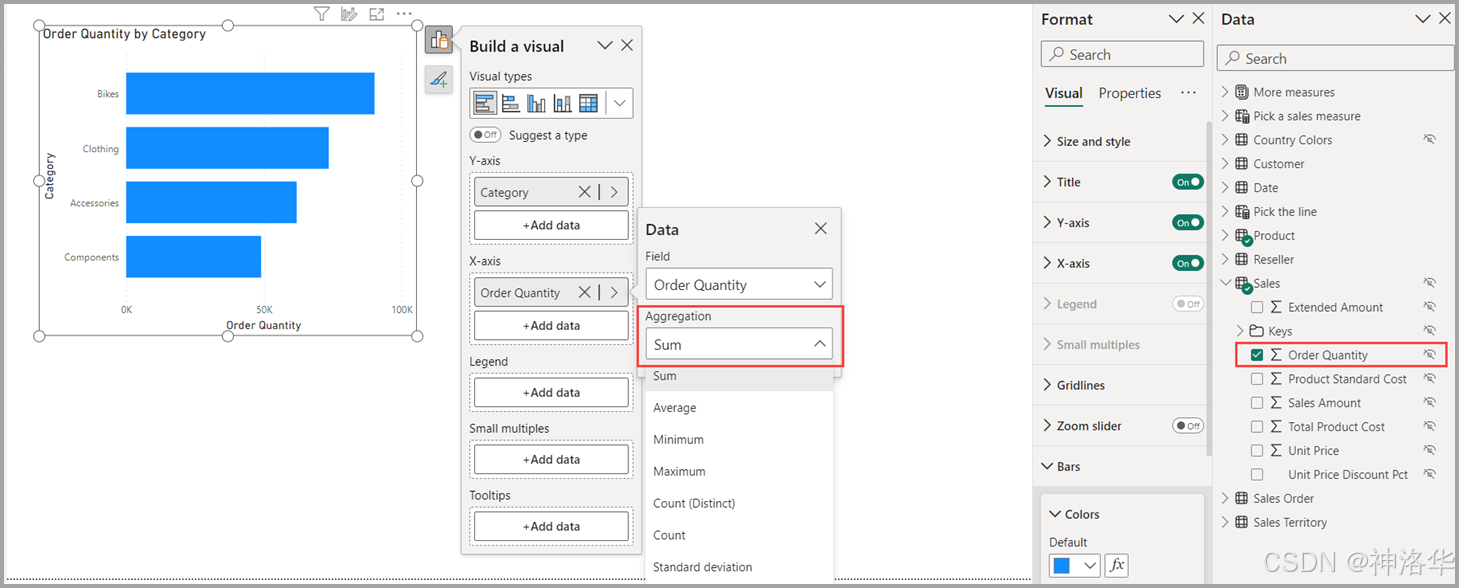
隐式度量:
- 隐式度量的创建:当您在 Power BI 的报告视图中直接将数据窗格中的某个数据列拖拽到视觉效果(如图表、表格等)中时,就会创建一个隐式度量。Power BI 自动为该数据列生成的聚合操作,如总和(SUM)、平均值(AVERAGE)、最小值(MIN)、最大值(MAX)等基本聚合函数。
- 隐式度量的影响:隐式度量虽然方便,但可能会无意中创建过多的度量,导致模型变得复杂和难以管理。
- 阻止隐式度量:在语义模型上启用“阻止隐式度量”属性后,用户不能直接将数据列拖拽到视觉效果的聚合轴或作为值来创建隐式度量。此外,视觉效果的条件格式中也不会直接使用这些数据列,但是已经创建的现有隐式度量仍然会继续工作,不会受到影响。
-
区域性:查看数据模型的所有翻译版本,更多内容详见《表格模型中的翻译》
-
透视:透视允许用户通过隐藏不相关的表、列或度量值,来查看模型中感兴趣的部分内容,提高数据分析的效率和相关性。详见《表格模型中的透视》
-
关系:右键点击关系项,选择创建或管理关系,即可在属性窗格中看到编辑窗口。更多内容详见《在 Power BI Desktop 中创建和管理关系》

之前创建关系可能需要执行查询来获取数据预览,验证所选列之间是否存在有效的关联,确保这些关联符合预期的逻辑。在模型资源管理器中创建表之间的关系时,用户可以直接在图形界面中看到关系的创建效果,不需要运行查询,在处理大型数据集时可以节省时间和计算资源。
-
角色:在模型资源管理器中,您可以创建或编辑安全角色,以实现对数据模型中特定表的访问控制。这包括定义哪些用户可以访问哪些数据,以及他们可以对这些数据执行哪些操作。通过这种方式,即使用户可以访问模型,也只能看到他们被授权查看的数据,从而保护敏感信息不被未授权者访问,详见《Power BI 行级别安全性 (RLS)》。


















 6664
6664

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











