






KMP算法用于在一个字符串(文本串)查找另一个字符串(模式串)的位置。
核心思想是,在对模式串和文本串进行遍历对比时:
根据已知的已匹配成功字符的信息。在下一个字符不匹配时,尽可能将模式串后移多个字符,达到降低时间复杂度的目的。
如何能在合理的情况尽可能跳过多的字符,得到最低的时间复杂度。需要满足如下条件:
| 文本串 | 1 | 2 | 3 | 4 | 5 | 6 |
| 模式串 | 1 | 2 | 3 | 4 | 5 | 6 |
| 相等 | 相等 | 相等 | 相等 | 相等 | 不相等 |
条件:跳过尽可能多的字符并保证不错过某一可匹配情况(也就是假设跳过n个字符,且跳过<n个字符时,模式串和文本串必然不匹配。这就说明跳过n个字符是合理的,不会错过某种可匹配的情况)。(上方表格的123456仅表示当前正在匹配的字符的位置而不是实际字符)此时思考:如果跳过一个字符是合理的,如下
| 文本串 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 模式串 | 1 | 2 | 3 | 4 | 5 | 6 | |
| 相等 | 相等 | 相等 | 相等 | 未知 | 未知 |
此时必然有文本串的2345字符和模式串的1234字符相等,也就是模式串的2345字符和模式串的1234字符相等。也就是12345有个相等前后缀,长度为4。此时可以继续往后匹配,也就是模式串的5和文本串的6进行匹配,匹配能否成功在匹配前是未知的。
| 文本串 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 模式串 | 1 | 2 | 3 | 4 | 5 | 6 | ||
| 相等 | 相等 | 相等 | 未知 | 未知 | 未知 |
再思考:如果跳过两个字符是合理情况,首先文本串的345应和模式串的123相等。且文本串的2345不可和模式串的1234相等(否则跳过一个字符后就应该继续匹配,否则可能错过能匹配成功的情况)。换句话说,也就是12345有个相等前后缀,长度为4,且不可有相等前后缀长度为3。再换句话说,12345的最长相等前后缀长度为3(对于12345的字符串来说,12345不可称为前缀或后缀,最长前缀是1234,最长后缀是2345,即字符串的最长前缀或最长后缀的长度为字符串长度减一)。
以此类推:当,模式串和文本串已经匹配部分字符,而下一字符不匹配时。模式串的,合理且尽可能多的,可跳过字符数为,已匹配字符的(长度 - 最长前后缀长度)。
现在已经了解了KMP算法的核心思路,如何将其转化为算法逻辑?
首先我们有文本串和模式串。从两者的第一个字符开始进行匹配。成功则继续,不成功那么模式串应该可以向后移动多少个字符?应该和当前已匹配字符的情况有关(也就是模式串中该字符前面的字符串):已匹配0个字符?模式串直接后移一位继续比较;已匹配1个字符?模式串也后移一位(已匹配字符的(长度1-最长前后缀长度0)=1);已匹配2个字符?模式串后移(已匹配字符的(长度2-最长前后缀长度))位;... ...;已匹配n位字符... ...
很显然,按上述方法遍历到文本串结束为止。遍历前,自然需要提前求出模式串每种匹配情况的后移位数(由模式串中不匹配字符前的字符串的最长前后缀长度决定)。如下:
| 1 | 模式串 | a | a | b | a | a | f | 备注: |
| 2 | 下标 | 0 | 1 | 2 | 3 | 4 | 5 | 无 |
| 3 | 长度 | 1 | 2 | 3 | 4 | 5 | 6 | 无 |
| 4 | 最长前后缀长度(前缀表) | 0 | 1 | 0 | 1 | 2 | 0 | 这就是KMP算法中的前缀表 |
| 5 | 假设当前字符不匹配 对应的文本串字符情况: 对应的模式串字符情况: 后移位数 | b a 1 | ab aa 1 | aaa aab 1 | aabb aaba 3 | aabab aabaa 3 | aabaab aabaaf 3 | 就是上文所说的,已匹配0个、1个、2个... ...n个的情况 |
| 6 | 模式串应该如何移动? 模式串后移后继续和文本串那个不匹配字符比较的模式串字符下标(next数组) | -1 | 0 | 1 | 0 | 1 | 2 | 为 -1 时,文本串和模式串应该均下标+1再去比较 |
解释上表:
第四行是其他KMP算法讲解中经常出现的名词:前缀表。它表示的是,对应下标为止的字符串中,和后缀相同的最长前缀,的长度(其实就是最长相同前后缀的长度)。它的作用显而易见,可以确定字符不匹配时后移的位数。
第五行是对应下标的那个字符和文本串不匹配时,模式串后移的位数。这个其实用处不大,因为算法的逻辑中需要对这个值处理后再使用。他只是一个中间产物。看了下面就懂了。
第六行是next数组,什么叫next数组。非常好理解:发现模式串中某下标的字符不匹配。直接将这个下标换成另一个下标去和文本串继续匹配(next完全可以理解为下一个用来匹配的下标的意思)。这就是非常适合在算法逻辑中使用一个产物值了。仔细想想就知道如何计算该值:笨方法可以每种情况都手动尝试移动然后算出值(作为验证);第二种方法,显然下一步用来匹配的下标应该 = 当前字符下标 - 后移位数(所以说第五行的后移位数也不是完全没用);第三种方法,自己画个前缀表和匹配过程的图很容易看出next数组的值(下一步用来匹配的下标)就是该位置前的字符串的最长相等前后缀。因此next数组也就是前缀表后移一位,且第一位赋值 -1。为什么是 -1,没有什么原因,第一个位置是特殊位置,这个值算出来就是 -1。
next数组和KMP的原理无关,它只是一种实现方式。比如上述所说,将前缀表右移一位再初始值赋 -1 作为next数组,这样实现的next数组可以直接在代码中使用,每当发现不匹配就把遍历的下标换成next数组对应的值,如果下标是负一那么文本串和模式串的匹配下标都加一。这种实现方式在使用上非常方便。即使直接把前缀表当为nxet数组也是可以的。无非是代码使用next数组时多做一点处理。
还有最后一个问题:如何计算最长相等前后缀(后面简称等缀,其长度简称缀长)?
和KMP的核心思路有部分相似之处。同样利用已知的信息去减少时间复杂度。
常规的计算方法是遍历每个子串的每个长度的前后缀检查是否相等。但我们可以使用递推,从长度较小的字符串的缀长推导长度较大的字符串的缀长。
假设已知字符串a1的缀长,那么对于a1加一个字符产生的字符串a2。只需比较a2的尾部字符和a1等缀的后一个字符。
如果相等,a2的缀长 = a1的缀长 + 1(为什么a2的等缀不可能更长些?反证法,假设a2有个更长的前后缀,去掉尾部的字符会发现a1也有更长的前后缀)。
如果不相等,应该用a1的等缀的等缀。假设a1为aabaa,如下图。a1的等缀的等缀相当于a1的二级等缀,如果a2的尾部字符 = a1二级等缀的后一个字符,a2的缀长 = a1二级缀长 + 1。(a2的等缀有没有可能更长些?同样是反证法,不可能)
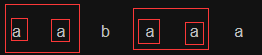
如果仍不相等,使用三级等缀,四级等缀,直到缀长为0了。此时比较a2的尾部字符和n级等缀的后一个字符,相等则a2的缀长为1,否则为0。
现在已经很清楚如何实现KMP算法,下面给出java代码实现:
package com.yt.string;
import java.util.Arrays;
import java.util.Objects;
/**
* @类描述: 找出字符串中第一个匹配的下标,LeetCode 28
* @作者: **
* @日期: ***
*/
public class StrStr {
public static int strStr(String haystack, String needle) {
//KMP算法
System.out.println("haystack: " + haystack);
System.out.println("needle: " + needle);
//如果模式串为空返回0
Objects.requireNonNull(haystack);
Objects.requireNonNull(needle);
if ("".equals(needle)) {
return 0;
}
int[] prefixTable = calculatePrefixTable(needle);
int[] next = convertToNext(prefixTable);
int res = doStrStr(haystack, needle, next);
System.out.println(" 结果:" + res);
return res;
}
/**
* @param needle 模式串
* @return 前缀表
*/
private static int[] calculatePrefixTable(String needle) {
int[] prefixTable = new int[needle.length()];
prefixTable[0] = 0;
for (int i = 1; i < prefixTable.length; i++) {
int nIndex = i - 1;// 第i个字符前的字符串的n级等缀在前缀表的索引
int nLength = prefixTable[nIndex];// 第i个字符前的字符串的n级缀长
while (true) {
if (needle.charAt(i) == needle.charAt(nLength)) {
prefixTable[i] = nLength + 1;
break;
} else {
if (nLength == 0) {
prefixTable[i] = 0;
break;
}
nLength = prefixTable[nLength - 1];
}
}
}
System.out.println(" 前缀表: " + Arrays.toString(prefixTable));
return prefixTable;
}
/**
* 将前缀表转换为next数组,使用前缀表右移一位并初始值赋-1实现
*
* @param prefixTable 前缀表
* @return next数组
*/
private static int[] convertToNext(int[] prefixTable) {
int[] next = new int[prefixTable.length];
next[0] = -1;
System.arraycopy(prefixTable, 0, next, 1, next.length - 1);
System.out.println(" next数组:" + Arrays.toString(next));
return next;
}
/**
* 找出字符串中第1个匹配项的下标
*
* @param haystack 文本串
* @param needle 模式串
* @param next next数组
* @return 匹配项的下标,如果没有匹配项返回-1
*/
private static int doStrStr(String haystack, String needle, int[] next) {
int i = 0, j = 0;// i为haystack下标,j为needle下标
while (i < haystack.length() && j < needle.length()) {
if (haystack.charAt(i) == needle.charAt(j)) {
i++;
j++;
if (j == needle.length()) {
return i - needle.length();
}
} else {
j = next[j];
if (j == -1) {
i++;
j++;
}
}
}
return -1;
}
}
自行编写测试,可多插入一些提示输出助于理解。















 810
810











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









