






1、引言
我已经发过一期爬取百度网盘共享文件夹数据的文章,但是用文件名来存储数据毕竟有很大的限制,最大的缺陷就是存储的数据量小,为了解决这个问题,这里我将提供蓝奏云网盘真实下载链接解析的方法,用于存储比较大的数据,而且由于蓝奏云网盘下载不限速,用来做服务器存储扩展再合适不过了,源码下载链接我会放在文章末尾,如果需要网站数据爬取的相关服务,也可以通过文章末尾提供的联系方式联系我。
2、实现原理
通过主动触发下载按钮,让自定义浏览器自动获取真实的下载链接,然后可通过真实下载链接直接下载文件,或者读取数据直接显示,这里我就演示下载效果。
3、实现步骤
3.1、对浏览器进行配置
首先要对浏览器进行三个关键配置,分别是设置js支持,设置代理为pc端模式,这里以火狐浏览器代理为例,最后是提供java代码对js的支持,相关代码如下:
settings.setJavaScriptEnabled(true);// 表示webview可以执行服务器端的js代码
settings.setUserAgentString("Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 " +
"(KHTML, like Gecko) Chrome/43.0.2357.134 Safari/537.36");//为了避免广告
wb_reptile.setDownloadListener(new DownloadListener() {
@Override
public void onDownloadStart(String url, String userAgent, String contentDisposition, String mimetype, long contentLength) {
down_data(url);//自己的方式
string = url;
handler.sendEmptyMessage(0);
// downloadySystem(url, contentDisposition, mimetype);//调用系统模式
}
});//设置下载监听3.2、主动触发点击下载按钮
触发下载的函数如下:
download();//调用这个函数就会触发下载3.3、处理下载响应
我这里是直接下载文件,下载完成后会进行提示操作,代码如下:
/**
* 根据传入的地址下载数据
*
* @param path
*/
private void down_data(String path) {
new Thread() {
@Override
public void run() {
try {
URL url = new URL(path);
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
connection.setConnectTimeout(2000);
connection.setReadTimeout(2000);
connection.setRequestMethod("GET");
int len;
byte[] buffer = new byte[1024];
InputStream is = connection.getInputStream();
File file = new File(getExternalFilesDir(null), "test.txt");
FileOutputStream fos = new FileOutputStream(file);
if (connection.getResponseCode() == 200) {
while ((len = is.read(buffer)) != -1) {
fos.write(buffer, 0, len);
}
is.close();
connection.disconnect();
fos.close();
handler.sendEmptyMessage(2);//下载完成后需要进行的操作
}
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}.start();
}4、效果演示
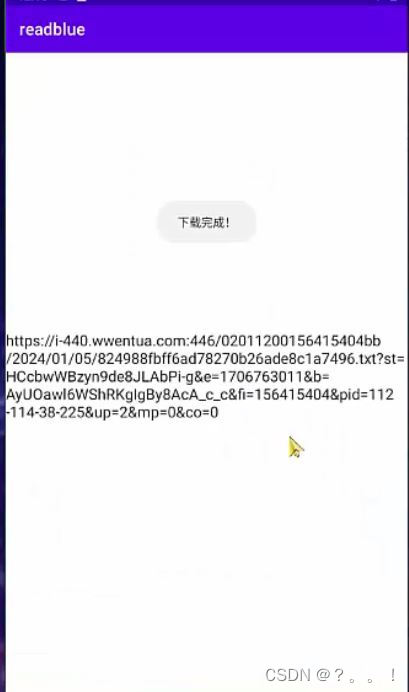
5、源码下载及联系方式
5.1、源码下载地址
//源码下载地址
//http://45.8.158.178/downCode?id=35.2、联系方式
//访问下方链接联系我
//http://45.8.158.178














 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









