







该数据集(douyin.csv)主要截取了200000条抖音电商平台上的商品销售情况。本文的分析将先根据数据集的结构选取分析目标,再通过可视化来展示各项分析目标的结果,从而挖掘出影响销售各个指标的因素及程度、进行商业预测。
一、表结构观察,确立分析目标
import pandas as pd
import numpy as np
import os
import matplotlib as plt
import pyecharts
from chart_studio import plotly as py
df=pd.read_csv('D:/CCCCCC/KDD/douyin.csv',encoding='utf-8')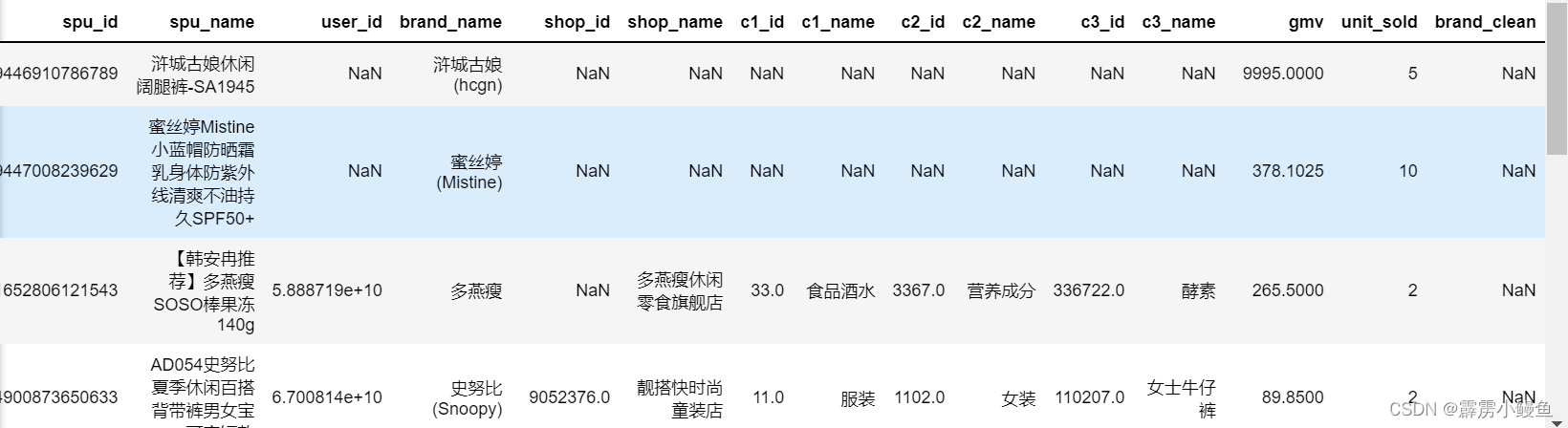 数据表有很多字段,有些无法批量补充的缺失值,需要根据结构判断使用哪些字段进行何种分析:
数据表有很多字段,有些无法批量补充的缺失值,需要根据结构判断使用哪些字段进行何种分析:
print(df.info())
df.isnull().any()
如图所示 ,商品id和名称、品牌、成交总额(gmv)、单位销量的数据是几乎齐全的;c1到c3的字段指的是商品分类的三个层次,依次为上一个的子层次;brand_clean相当于从数据集的所有品牌中精选出知名品牌;而店铺信息在该数据表中缺失值较多。
根据以上的结构分析,本文将从三个方面做分析处理:使用c1到c3字段中有的16万多条数据进行商品分类的销量分析;用品牌忠诚度、消费额、消费频率作用户价值分析;最后作出知名品牌带来效益的商业预测。
二、分类指标可视化
- 初步想法是利用三个层次的关联数据绘制一个多分类的对比图表,于是选用了矩形树图(TreeMap);首先先进行数据预处理,将只含有c1-c3分类以及对应销量的字段从原数据表中剥离出来。
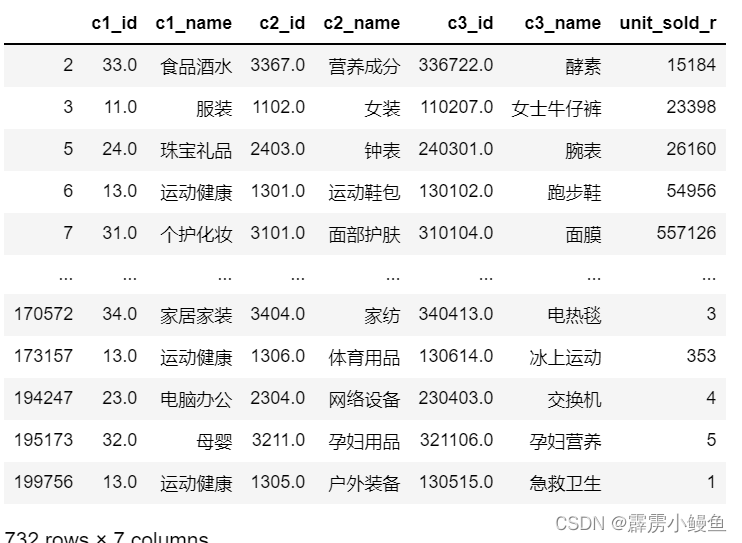
from pyecharts.charts import Page,TreeMap from pyecharts import options as opts import math df1=df.copy() df1=df1.dropna(subset=['c1_id']) df5=df1[["c1_id","c1_name","c2_id","c2_name","c3_id","c3_name"
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 221
221

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









