







整体代码,直接去用,注意修改邮箱
############################################################################
### 以下是邮件发送类 ###
############################################################################
import smtplib
import os
from email.mime.text import MIMEText
from email.mime.image import MIMEImage
from email.mime.multipart import MIMEMultipart
from email.utils import parseaddr,formataddr
from email.header import Header
from regex import P # 解析邮件,得到邮件内容
############################################################################
### 以下是邮件接收类 ###
############################################################################
import poplib
# 解析邮件
from email.parser import Parser
from email.header import decode_header
from re import I
'''
发送邮件,封装为Esend类
'''
class Esend(object):
# 使用args的目的是为了后续扩展多参数传递(虽然这里只用了一个文件路径的参数)
def __init__(self,user,password,send_name,subject,receive_name,receive_addr,*args):
self.smtp_server=args[2] # stmp服务器地址
self.user=user
self.receive_name=receive_name
self.password=password
self.send_name=send_name
self.receive_addr=receive_addr
self.subject=subject # 主题
self.base=os.path.dirname(__file__) # 文件工作路径
self.attached=args[0] # 文件路径列表,attached[0]:正文,attached[1]:附件
self.msg = args[1] # 直接文本
print(f"文件基本路径:{self.base}")
def MakeUp(self,s):
# parseaddr()函数将地址解析为姓名和邮件地址,并返回一个元组
'''
将带姓名的Email格式作为参数,给parseaddr函数,得到name和addr。
name就是姓名,addr就是纯Email.
然后formataddr函数再将name和addr转换成标准Email地址格式。
'''
name,addr=parseaddr(s)
# Header: Create a MIME-compliant header that can contain many character sets.
return formataddr((Header(name,'utf-8').encode(),addr))
'''
构造message对象:
1. 主题
2. From
3. To
4. 正文
5. 附件
'''
def message_config(self):
# Creates a multipart/* type message
# 创建一个带附件的实例,可以添加附件
message=MIMEMultipart()
message['Subject']=self.subject
# 这里输入的是中文格式,但是实际上需要转换为MIME-compliant header
message['From']=self.MakeUp(f"{self.send_name}<{self.user}>")
message['To']=self.MakeUp(f"{self.receive_name}<{self.receive_name}>")
part=[] # 将来需要向part中加入文件信息或直接文本信息
############################ 正文 ####################################
## 1.直接传输文本
## 2.传输文件
if self.msg != "": # 不需要附件
part.append(MIMEText(self.msg,'plain','utf-8'))
else:
with open(os.path.join(self.base,self.attached[0]),'rb') as f:
content=f.read() # 读取正文
# Split the extension from a pathname,分离扩展名,判断正文传输文件的类型
'''
text/html的意思是将文件的content-type设置为text/html的形式,浏览器在获取到这种文件时会自动调用html的解析器对文件进行相应的处理。
text/plain的意思是将文件设置为纯文本的形式,浏览器在获取到这种文件时并不会对其进行处理 '''
if os.path.splitext(self.attached[0])[1] !='html':
part.append(MIMEText(content,'plain','utf-8'))
else:
part.append(MIMEText(content,'html','utf-8'))
############################ 附件 ####################################
for fj in self.attached[1:]:
if os.path.splitext(fj)[1] == '.jpg' or os.path.splitext(fj)[1] =='.png':
with open(os.path.join(self.base, fj),'rb') as f:
p=MIMEImage(f.read())
p['Content-Type']='application/octet-stream'
p['Content-Disposition']='attachment;filename="%s"'%(fj)
print("图片文件",fj)
part.append(p)
else:
with open(os.path.join(self.base, fj),'rb') as f:
content = f.read()
p=MIMEText(content,'plain','utf-8')
p['Content-Type']='application/octet-stream' # 类别信息
# p['Content-Disposition']=f'attachment;filename="{fj}{os.path.splitext(fj)[1]}"' # 描述信息
p.add_header('Content-Disposition', 'attachment', filename=fj) # 解决文件.bin的问题,增加路径
part.append(p)
print("其他文件",fj)
for i in part:
message.attach(i) # 加入邮件中
return message
def smtp_config(self):
smtp=smtplib.SMTP() # 创建一个SMTP对象
smtp.connect(self.smtp_server,25) # 连接smtp服务器,端口默认是25
smtp.login(self.user,self.password) # 登录邮箱
message=self.message_config() # 调用message_config()方法,获取邮件内容,并返回message对象
smtp.sendmail(self.user,self.receive_addr,message.as_string()) # 发送邮件到另一个smtp服务器
smtp.quit()
print('发送成功')
def email_send_init(user,password,send_name,subject,receive_name,receive_addr,smtp_sever):
'''邮件基本信息输入:
1.发送邮箱
2.邮箱的授权码
3.发送方name
4.发送主题
5.接受者name
6.接受者邮箱
'''
'''发送信息输入,选择文件或直接传输正文
'''
file_list=[] # file_list[0]是正文文件路径,file_list[1]是附件文件路径
msg = ""
choice = input("请选择,正文发送纯文本还是文件\n1. 文本发送\n2. 文件发送")
if choice == '1':
msg = input("输入文本信息:")
file_list.append("")
elif choice == '2':
f=input('正文文件(程序所在文件夹):')
file_list.append(f)
# 输入多个附件
while True:
f=input('附件文件,输入q结束(程序所在文件夹):')
if f != 'q':
file_list.append(f)
else:
break
# message作为参数解包传输到Esend的构造函数中用于初始化
message=[user,password,send_name,subject,receive_name,receive_addr,file_list,msg,smtp_sever]
return message
'''
-----------------------------------------------------------------
'''
# 解析消息头中的字符串
# 没有这个函数,print出来的会使乱码的头部信息。如'=?gb18030?B?yrXWpL3hufsueGxz?='这种
# 通过decode,将其变为中文
def decode_str(s):
'''
Returns a list of (string, charset) pairs
containing each of the decoded parts of the header.
Charset is None for non-encoded parts of the header,
otherwise a lower-case string
containing the name of the character set specified in the encoded string.
'''
value, charset = decode_header(s)[0] # Decode a message header value without converting charset
if charset: # 通用模板,如果可编码才能编码
value = value.decode(charset) # Decode the bytes using the codec registered for encoding
return value
# 解码邮件信息分为两个步骤,第一个是取出头部信息
# 首先取头部信息
# 主要取出['From','To','Subject']
'''
From: "=?gb18030?B?anVzdHpjYw==?=" <justonezcc@sina.com>
To: "=?gb18030?B?ztLX1Ly6tcTTys/k?=" <392361639@qq.com>
Subject: =?gb18030?B?dGV4dMTjusM=?=
'''
# 如上述样式,均需要解码
def get_header(msg):
for header in ['From', 'To', 'Subject']:
value = msg.get(header, '')
if value:
# 文章的标题有专门的处理方法
if header == 'Subject':
value = decode_str(value)
elif header in ['From', 'To']:
# 地址也有专门的处理方法
hdr, addr = parseaddr(value)
name = decode_str(addr)
# value = name + ' < ' + addr + ' > '
value = name
print(header + ':' + value)
# 头部信息已取出
# 获取邮件的字符编码,首先在message中寻找编码,如果没有,就在header的Content-Type中寻找
def guess_charset(msg):
charset = msg.get_charset() # 获取字符编码
if charset is None:
content_type = msg.get('Content-Type', '').lower()
pos = content_type.find('charset=')
# content_type: text/html; charset="utf-8"
# charset: "utf-8"
# print("content_type:",content_type)
if pos >= 0:
charset = content_type[pos + 8:].strip() # charset="utf-8"中得到utf-8
# print("charset:", charset)
return charset
# 邮件正文部分
# 取附件
# 邮件的正文部分在生成器中,msg.walk()
# 如果存在附件,则可以通过.get_filename()的方式获取文件名称
def get_file(msg):
for part in msg.walk():
filename = part.get_filename()
if filename != None: # 如果存在附件
filename = decode_str(filename) # 获取的文件是乱码名称,通过一开始定义的函数解码
# get_payload()获取附件的内容
data = part.get_payload(decode=True) # 取出文件正文内容
# 此处可以自己定义文件保存位置
path = "D:\\Python程序\\网络\\邮箱附件\\" + filename
f = open(path, 'wb')
f.write(data) # 下载附件
f.close()
print("存在附件:",filename)
def get_content(msg):
for part in msg.walk(): # walk()方法可以遍历所有的子对象,包括文本、附件
content_type = part.get_content_type() # 获取邮件的类型
charset = guess_charset(part) # 获取字符编码
# 如果有附件,则直接跳过
if part.get_filename() != None:
continue
############ 获取内容类型 ############
email_content_type = ''
if content_type == 'text/plain':
email_content_type = 'text'
elif content_type == 'text/html':
print('.....passing html')
continue # 不要html格式的邮件、
############ 获取内容,解码 ############
content = ''
if charset:
try:
content = part.get_payload(decode=True).decode(charset) # 获取邮件正文内容
except AttributeError: # 如果解码失败,则直接跳过
print('type error')
except LookupError:
print("unknown encoding: utf-8")
if email_content_type == '':
continue
print("---------------------内容---------------------:")
print("正文类型-",email_content_type + ' : ' + content)
def Receiving_email(eml,pwd,popSever):
email = eml
password = pwd
######## 连接pop3服务器 #########
server = poplib.POP3(popSever)
server.user(email)
server.pass_(password)
# stat是获取邮件数量和邮件大小,返回一个元组,第一个是邮件数量,第二个是邮件大小
mails, totalsize = server.stat()
index = mails
page = (mails,)
print('邮箱共有%d封邮件'%mails)
print('1.选择单封邮件')
print('2.选择多封邮箱')
c1=input('选择:')
if c1 == '1':
print('----------------------')
c2=input('输入邮件编号,最近的编号即为邮件数量:')
page = (c2,)
elif c1 == '2':
data=input('输入邮件编号,最近的编号即为邮件数量(使用,分开):')
data=data.split(',')
page = data
else:
print("输入错误")
'''
此处的循环是取最近的几封邮件
注意到POP3协议收取的不是一个已经可以阅读的邮件本身,
而是邮件的原始文本,这和SMTP协议很像,SMTP发送的也是经过编码后的一大段文本。
要把POP3收取的文本变成可以阅读的邮件,还需要用email模块提供的各种类来解析原始文本,
变成可阅读的邮件对象。
'''
for i in page:
# retr是取邮件的方法,参数是邮件的编号,返回一个列表,列表中存储了邮件的原始文本
# lines存储了邮件的原始文本的每一行,每一行都是二进制数据,后面要拼接和译码
resp, lines, octets = server.retr(i)
msg_content = b'\r\n'.join(lines).decode('utf-8', 'ignore') # ignore是忽略错误的字符
#print("加工前:", msg_content)
# Parser of RFC 2822 and MIME email messages.
msg = Parser().parsestr(msg_content) # 解析邮件,对应encode_base64
#print("\n\n\n加工后:" , msg)
'''
From:2918589839@qq.com
To:Hanfeijiang_edu@163.com
Subject:第三个邮件
'''
get_header(msg)
'''
正文类型- text : xxxxx
'''
get_content(msg)
# 把附件文件存到指定目录
get_file(msg)
server.quit()
################################################################
def EmailUserAgency():
tuser=input('输入你的邮箱:')
if tuser =='':
tuser = "xxxx@163.com"
tpassword=input('输入授权码:')
if tpassword == "":
tpassword = "xxxxx"
choice = input("-----选择发送还是接收-----\n1. 发送邮件\n2. 接收邮件\n")
if choice == '1':
tsmtp_sever = input("请输入smtp服务器地址:")
if tsmtp_sever == '':
tsmtp_sever = 'smtp.163.com'
tsend_name=input('你的名字:')
if tsend_name == '':
tsend_name = "xxxx"
tsubject=input('发送主题:')
if tsubject == '':
tsubject = "test"
treceive_name=input('接收者名字:')
if treceive_name == '':
treceive_name = "xxxx"
treceive_addr=input('接收者邮箱:')
if treceive_addr == '':
treceive_addr = "xxxx@qq.com"
message=email_send_init(tuser,tpassword,tsend_name,tsubject,treceive_name,treceive_addr,tsmtp_sever)
esend=Esend(*message) # 注意!!!一定是*message,不能是message
esend.smtp_config()
elif choice == '2':
pop_sever = input("请输入pop服务器地址:")
if pop_sever == '':
pop_sever = 'pop.163.com'
# 参数:邮箱,密码,pop服务器
Receiving_email(tuser,tpassword,pop_sever)
else:
print("输入错误,请重新输入")
if __name__ == '__main__':
EmailUserAgency()
'''
日志:
1.完成 邮件发送,封装类 5.10
2.完成 邮件接受 5.20
3.组合发送和接受 5.20
4.优化输入控制 5.23
5.优化解码操作 5.25
'''
实验原理和内容
(一) 邮件收发原理

邮件的收发过程
一般情况下,一封邮件的发送和接收过程如下。
- 发信人在用户代理里编辑邮件,包括填写发信人邮箱、收信人邮箱和邮件标题等等。
- 用户代理提取发信人编辑的信息,生成一封符合邮件格式标准(RFC822)的邮件。
- 用户代理用SMTP将邮件发送到发送端邮件服务器(即发信人邮箱所对应的邮件服务器)。
- 发送端邮件服务器用SMTP将邮件发送到接收端邮件服务器(即收信人邮箱所对应的邮件服务器)。
- 收信人调用用户代理。用户代理用POP3协议从接收端邮件服务器取回邮件。
- 用户代理解析收到的邮件,以适当的形式呈现在收信人面前。
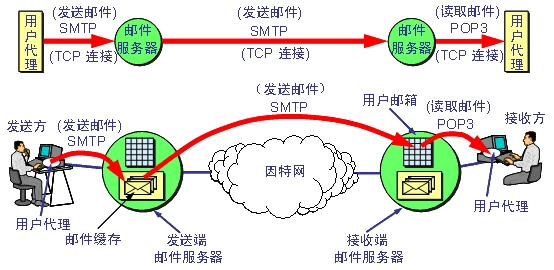
图. 来源于网络
本实验在163邮箱和qq邮箱之间收发邮件,大致需要进行如下核心操作:
- 输入参数,比如收发的邮箱、服务器域名、发送的信息、接受的信息区间、附件信息、收发件人信息等等,通过这些信息建立通信。
- 输入发送的信息后要进行加工,生成符合传输规范的邮件报文,Python中有一系列函数可以实现这些操作。
- 服务器之间的SMPT协议通信被python隐藏封装了,因此我们只要在UA中建立通信即可。
- 收邮件时注意首先对邮件的编码格式进行解析,然后对收到的二进制比特流数据解码,再通过一些格式的修改才能得到最终可视化的邮件。
- 收发文件时都要注意文件读取和写入时是以二进制比特流的形式写入和读的,因此在最终生成文件时要注意命名
(二)文件通过邮件传输
经过试验,在邮件中传输文件有以下注意事项:
- 从UA发送文件到接收端时,注意指定接受时的文件后缀保持一致,否则会出现.bot的错误文件格式。文件后缀可以通过pythonOs模块的函数得到。
- 如果正文发送邮件,则邮件在接收端还需要是以文本格式显示
- 附件传输图片和传输其他文件不一样,传输图片有独特的类,别的文件统一选择其他类。
- 接受邮件的时候要先判断是否有附件,如果收到html文件则忽略,接受其他类型的文件放入指定文件夹。
实验具体设计和结果
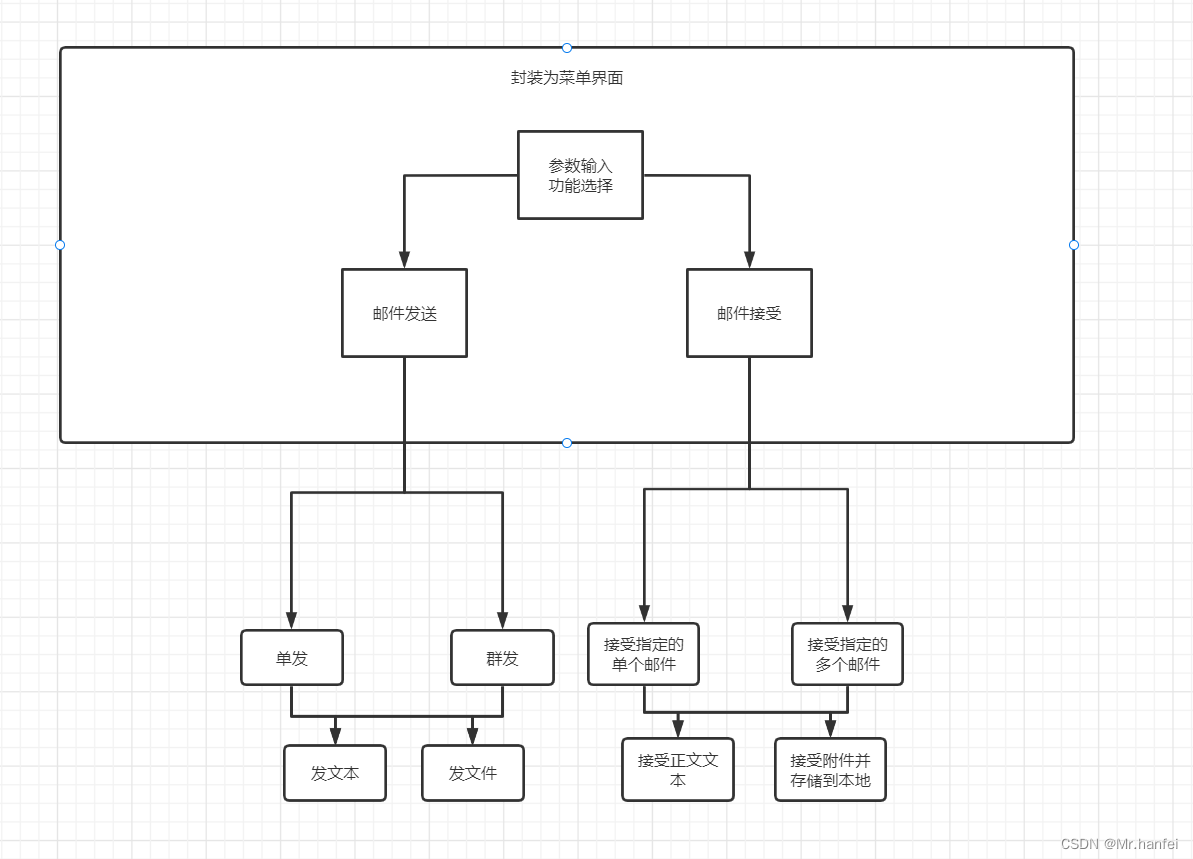
邮件接受
1.解码
核心:利用decode_header函数解析收到的邮件头,邮件头里面含有这个邮件的编码。函数返回值就是一个元组,第二个值就是charset了
返回值:解码后的邮件信息
# 解析消息头中的字符串
# 没有这个函数,print出来的会使乱码的头部信息。如'=?gb18030?B?yrXWpL3hufsueGxz?='这种
# 通过decode,将其变为中文
def decode_str(s):
'''
Returns a list of (string, charset) pairs
containing each of the decoded parts of the header.
Charset is None for non-encoded parts of the header,
otherwise a lower-case string
containing the name of the character set specified in the encoded string.
'''
value, charset = decode_header(s)[0] # Decode a message header value without converting charset
if charset: # 通用模板,如果可编码才能编码
value = value.decode(charset) # Decode the bytes using the codec registered for encoding
return value
2.解析信息
From: “=?gb18030?B?anVzdHpjYw==?=” xxxx@sina.com
To: “=?gb18030?B?ztLX1Ly6tcTTys/k?=” xxxx@qq.com
Subject: =?gb18030?B?dGV4dMTjusM=?=
上面这些东西就是解码后的邮件信息,我们收到的信息需要经过再次加工,分离邮件头和邮件体,邮件头包含from to subject,邮件体就是发送的邮件信息。
# 解码邮件信息分为两个步骤,第一个是取出头部信息
# 首先取头部信息
# 主要取出['From','To','Subject']
'''
From: "=?gb18030?B?anVzdHpjYw==?=" <justonezcc@sina.com>
To: "=?gb18030?B?ztLX1Ly6tcTTys/k?=" <392361639@qq.com>
Subject: =?gb18030?B?dGV4dMTjusM=?=
'''
# 如上述样式,均需要解码
def get_header(msg):
for header in ['From', 'To', 'Subject']:
value = msg.get(header, '')
if value:
# 文章的标题有专门的处理方法
if header == 'Subject':
value = decode_str(value)
elif header in ['From', 'To']:
# 地址也有专门的处理方法
hdr, addr = parseaddr(value)
name = decode_str(addr)
# value = name + ' < ' + addr + ' > '
value = name
print(header + ':' + value)
3.获取正文编码格式
首先通过get_charset()尝试获取编码,如果没有就在Content-Type中找。
content-type格式如下:content_type: text/html; charset=“utf-8”
因此还需要charset = content_type[pos + 8:].strip(),才能得到最后的编码:utf-8
# 头部信息已取出
# 获取邮件的字符编码,首先在message中寻找编码,如果没有,就在header的Content-Type中寻找
def guess_charset(msg):
charset = msg.get_charset() # 获取字符编码
if charset is None:
content_type = msg.get('Content-Type', '').lower()
pos = content_type.find('charset=')
# content_type: text/html; charset="utf-8"
# charset: "utf-8"
# print("content_type:",content_type)
if pos >= 0:
charset = content_type[pos + 8:].strip() # charset="utf-8"中得到utf-8
# print("charset:", charset)
return charset
4.下载邮件文件
# 邮件正文部分
# 取附件
# 邮件的正文部分在生成器中,msg.walk()
# 如果存在附件,则可以通过.get_filename()的方式获取文件名称
def get_file(msg):
for part in msg.walk():
filename = part.get_filename()
if filename != None: # 如果存在附件
filename = decode_str(filename) # 获取的文件是乱码名称,通过一开始定义的函数解码
# get_payload()获取附件的内容
data = part.get_payload(decode=True) # 取出文件正文内容
# 此处可以自己定义文件保存位置
path = "D:\\Python程序\\网络\\邮箱附件\\" + filename
f = open(path, 'wb')
f.write(data) # 下载附件
f.close()
print("存在附件:",filename)
5.得到邮件正文并输出格式
- 这里注意如果是html就不显示了,因为会乱码
- 显示text文本信息即可
def get_content(msg):
for part in msg.walk(): # walk()方法可以遍历所有的子对象,包括文本、附件
content_type = part.get_content_type() # 获取邮件的类型
charset = guess_charset(part) # 获取字符编码
# 如果有附件,则直接跳过
if part.get_filename() != None:
continue
############ 获取内容类型 ############
email_content_type = ''
if content_type == 'text/plain':
email_content_type = 'text'
elif content_type == 'text/html':
print('.....passing html')
continue # 不要html格式的邮件、
############ 获取内容,解码 ############
content = ''
if charset:
try:
content = part.get_payload(decode=True).decode(charset) # 获取邮件正文内容
except AttributeError: # 如果解码失败,则直接跳过
print('type error')
except LookupError:
print("unknown encoding: utf-8")
if email_content_type == '':
continue
print("---------------------内容---------------------:")
print("正文类型-",email_content_type + ' : ' + content)
6.功能选择和输出
def Receiving_email(eml,pwd,popSever):
email = eml
password = pwd
######## 连接pop3服务器 #########
server = poplib.POP3(popSever)
server.user(email)
server.pass_(password)
# stat是获取邮件数量和邮件大小,返回一个元组,第一个是邮件数量,第二个是邮件大小
mails, totalsize = server.stat()
index = mails
page = (mails,)
print('邮箱共有%d封邮件'%mails)
print('1.选择单封邮件')
print('2.选择多封邮箱')
c1=input('选择:')
if c1 == '1':
print('----------------------')
c2=input('输入邮件编号,最近的编号即为邮件数量:')
page = (c2,)
elif c1 == '2':
data=input('输入邮件编号,最近的编号即为邮件数量(使用,分开):')
data=data.split(',')
page = data
else:
print("输入错误")
'''
此处的循环是取最近的几封邮件
注意到POP3协议收取的不是一个已经可以阅读的邮件本身,
而是邮件的原始文本,这和SMTP协议很像,SMTP发送的也是经过编码后的一大段文本。
要把POP3收取的文本变成可以阅读的邮件,还需要用email模块提供的各种类来解析原始文本,
变成可阅读的邮件对象。
'''
for i in page:
# retr是取邮件的方法,参数是邮件的编号,返回一个列表,列表中存储了邮件的原始文本
# lines存储了邮件的原始文本的每一行,每一行都是二进制数据,后面要拼接和译码
resp, lines, octets = server.retr(i)
msg_content = b'\r\n'.join(lines).decode('utf-8', 'ignore') # ignore是忽略错误的字符
#print("加工前:", msg_content)
# Parser of RFC 2822 and MIME email messages.
msg = Parser().parsestr(msg_content) # 解析邮件,对应encode_base64
#print("\n\n\n加工后:" , msg)
'''
From:2918589839@qq.com
To:Hanfeijiang_edu@163.com
Subject:第三个邮件
'''
get_header(msg)
'''
正文类型- text : xxxxx
'''
get_content(msg)
# 把附件文件存到指定目录
get_file(msg)
server.quit()
邮件发送
将邮件发送封装为一个类,输入参数即可构建一个MIMEMultipart对象,然后向这个对象中添加MIMEImage和MIMEText即可实现正文和附件的传输。
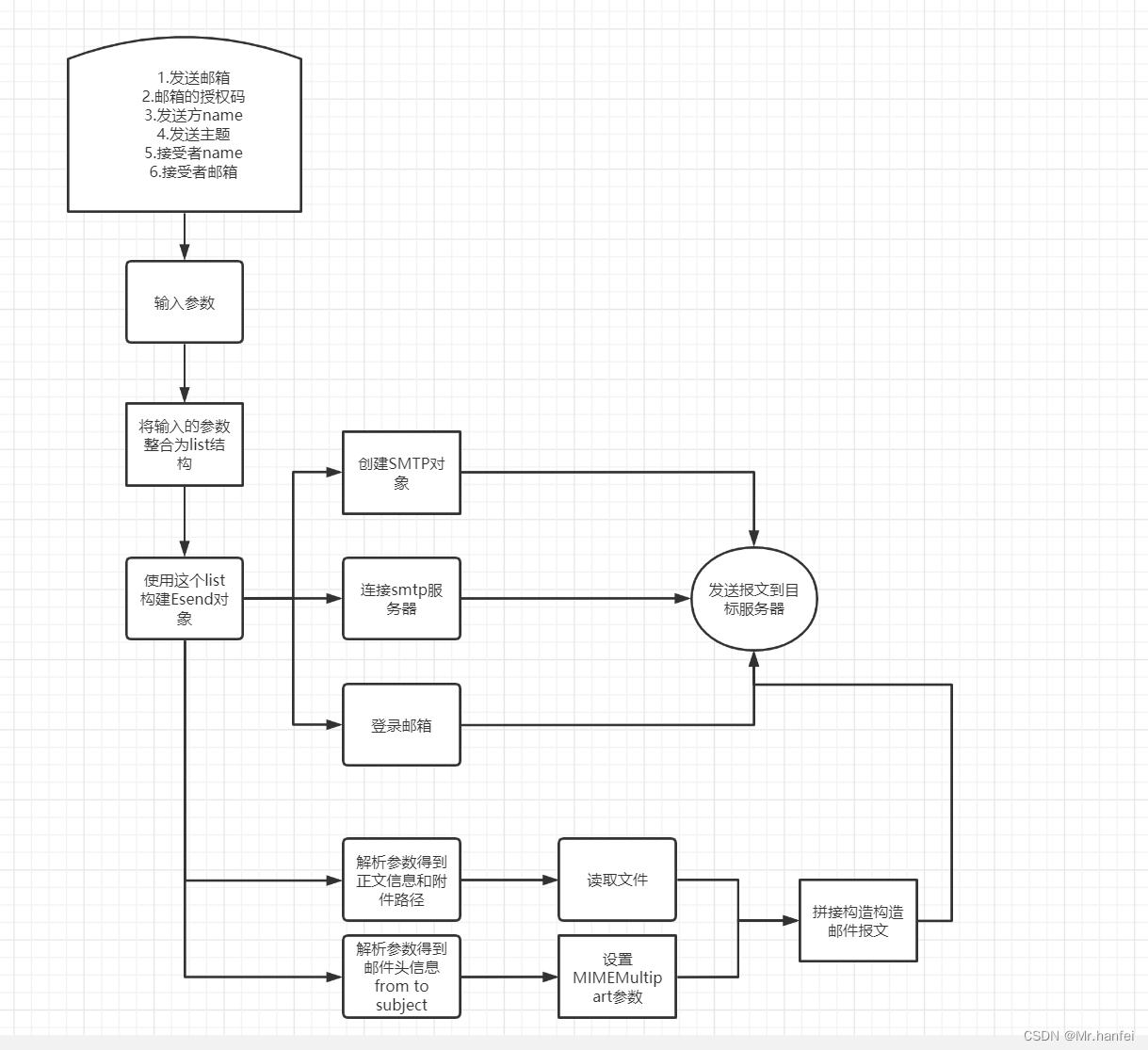
'''
发送邮件,封装为Esend类
'''
class Esend(object):
# 使用args的目的是为了后续扩展多参数传递(虽然这里只用了一个文件路径的参数)
def __init__(self,user,password,send_name,subject,receive_name,receive_addr,*args):
self.smtp_server=args[2] # stmp服务器地址
self.user=user
self.receive_name=receive_name
self.password=password
self.send_name=send_name
self.receive_addr=receive_addr
self.subject=subject # 主题
self.base=os.path.dirname(__file__) # 文件工作路径
self.attached=args[0] # 文件路径列表,attached[0]:正文,attached[1]:附件
self.msg = args[1] # 直接文本
print(f"文件基本路径:{self.base}")
def MakeUp(self,s):
# parseaddr()函数将地址解析为姓名和邮件地址,并返回一个元组
'''
将带姓名的Email格式作为参数,给parseaddr函数,得到name和addr。
name就是姓名,addr就是纯Email.
然后formataddr函数再将name和addr转换成标准Email地址格式。
'''
name,addr=parseaddr(s)
# Header: Create a MIME-compliant header that can contain many character sets.
return formataddr((Header(name,'utf-8').encode(),addr))
'''
构造message对象:
1. 主题
2. From
3. To
4. 正文
5. 附件
'''
def message_config(self):
# Creates a multipart/* type message
# 创建一个带附件的实例,可以添加附件
message=MIMEMultipart()
message['Subject']=self.subject
# 这里输入的是中文格式,但是实际上需要转换为MIME-compliant header
message['From']=self.MakeUp(f"{self.send_name}<{self.user}>")
message['To']=self.MakeUp(f"{self.receive_name}<{self.receive_name}>")
part=[] # 将来需要向part中加入文件信息或直接文本信息
############################ 正文 ####################################
## 1.直接传输文本
## 2.传输文件
if self.msg != "": # 不需要附件
part.append(MIMEText(self.msg,'plain','utf-8'))
else:
with open(os.path.join(self.base,self.attached[0]),'rb') as f:
content=f.read() # 读取正文
# Split the extension from a pathname,分离扩展名,判断正文传输文件的类型
'''
text/html的意思是将文件的content-type设置为text/html的形式,浏览器在获取到这种文件时会自动调用html的解析器对文件进行相应的处理。
text/plain的意思是将文件设置为纯文本的形式,浏览器在获取到这种文件时并不会对其进行处理 '''
if os.path.splitext(self.attached[0])[1] !='html':
part.append(MIMEText(content,'plain','utf-8'))
else:
part.append(MIMEText(content,'html','utf-8'))
############################ 附件 ####################################
for fj in self.attached[1:]:
if os.path.splitext(fj)[1] == '.jpg' or os.path.splitext(fj)[1] =='.png':
with open(os.path.join(self.base, fj),'rb') as f:
p=MIMEImage(f.read())
p['Content-Type']='application/octet-stream'
p['Content-Disposition']='attachment;filename="%s"'%(fj)
print("图片文件",fj)
part.append(p)
else:
with open(os.path.join(self.base, fj),'rb') as f:
content = f.read()
p=MIMEText(content,'plain','utf-8')
p['Content-Type']='application/octet-stream' # 类别信息
# p['Content-Disposition']=f'attachment;filename="{fj}{os.path.splitext(fj)[1]}"' # 描述信息
p.add_header('Content-Disposition', 'attachment', filename=fj) # 解决文件.bin的问题,增加路径
part.append(p)
print("其他文件",fj)
for i in part:
message.attach(i) # 加入邮件中
return message
def smtp_config(self):
smtp=smtplib.SMTP() # 创建一个SMTP对象
smtp.connect(self.smtp_server,25) # 连接smtp服务器,端口默认是25
smtp.login(self.user,self.password) # 登录邮箱
message=self.message_config() # 调用message_config()方法,获取邮件内容,并返回message对象
smtp.sendmail(self.user,self.receive_addr,message.as_string()) # 发送邮件到另一个smtp服务器
smtp.quit()
print('发送成功')
def email_send_init(user,password,send_name,subject,receive_name,receive_addr,smtp_sever):
'''邮件基本信息输入:
1.发送邮箱
2.邮箱的授权码
3.发送方name
4.发送主题
5.接受者name
6.接受者邮箱
'''
'''发送信息输入,选择文件或直接传输正文
'''
file_list=[] # file_list[0]是正文文件路径,file_list[1]是附件文件路径
msg = ""
choice = input("请选择,正文发送纯文本还是文件\n1. 文本发送\n2. 文件发送")
if choice == '1':
msg = input("输入文本信息:")
file_list.append("")
elif choice == '2':
f=input('正文文件(程序所在文件夹):')
file_list.append(f)
# 输入多个附件
while True:
f=input('附件文件,输入q结束(程序所在文件夹):')
if f != 'q':
file_list.append(f)
else:
break
# message作为参数解包传输到Esend的构造函数中用于初始化
message=[user,password,send_name,subject,receive_name,receive_addr,file_list,msg,smtp_sever]
return message
功能整合、扩展名
功能如下:
1.首先输入邮箱和授权码,如果想用默认的就直接Enter换行即可
2.功能选择:发送 还是 接收
3.如果是发送,则还要输入name,subject,recvname,recvmail,也可以自己指定smtp服务器,但是需要和发送方一致
4.如果是接收,还需要输入邮箱,密码,pop服务器
5.分别调用接收和发送的函数即可
################################################################
def EmailUserAgency():
tuser=input('输入你的邮箱:')
if tuser =='':
tuser = "xxxx@163.com"
tpassword=input('输入授权码:')
if tpassword == "":
tpassword = "xxxx"
choice = input("-----选择发送还是接收-----\n1. 发送邮件\n2. 接收邮件\n")
if choice == '1':
tsmtp_sever = input("请输入smtp服务器地址:")
if tsmtp_sever == '':
tsmtp_sever = 'smtp.163.com'
tsend_name=input('你的名字:')
if tsend_name == '':
tsend_name = "xxxx"
tsubject=input('发送主题:')
if tsubject == '':
tsubject = "test"
treceive_name=input('接收者名字:')
if treceive_name == '':
treceive_name = "xxxx"
treceive_addr=input('接收者邮箱:')
if treceive_addr == '':
treceive_addr = "xxxx@qq.com"
message=email_send_init(tuser,tpassword,tsend_name,tsubject,treceive_name,treceive_addr,tsmtp_sever)
esend=Esend(*message) # 注意!!!一定是*message,不能是message
esend.smtp_config()
elif choice == '2':
pop_sever = input("请输入pop服务器地址:")
if pop_sever == '':
pop_sever = 'pop.163.com'
# 参数:邮箱,密码,pop服务器
Receiving_email(tuser,tpassword,pop_sever)
else:
print("输入错误,请重新输入")
if __name__ == '__main__':
EmailUserAgency()
'''
日志:
1.完成 邮件发送,封装类 5.10
2.完成 邮件接受 5.20
3.组合发送和接受 5.20
4.优化输入控制 5.23
5.优化解码操作 5.25
'''

















 8167
8167

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









