







逻辑回归与鸢尾花分类:One-vs-Rest方法的实践
在机器学习领域,分类问题一直是研究的核心任务之一。尤其是多分类问题,如何高效地将数据划分为多个类别,是许多实际应用中的关键。本文将通过一个具体的案例——使用逻辑回归(Logistic Regression)和 One-vs-Rest(OvR)方法对鸢尾花(Iris)数据集进行分类,来深入探讨这一问题。
一、背景与数据集介绍
鸢尾花数据集(Iris Dataset)是机器学习领域中最为经典的数据集之一,由英国统计学家和生物学家罗纳德·费舍尔(Ronald Fisher)在 1936 年首次引入。该数据集包含了 150 个样本,每个样本有 4 个特征:花萼长度(sepal length)、花萼宽度(sepal width)、花瓣长度(petal length)和花瓣宽度(petal width)。样本分为三个类别:Iris-Setosa、Iris-Versicolour 和 Iris-Virginica,每个类别各有 50 个样本。
鸢尾花数据集具有以下特点:
-
特征数量少:仅包含 4 个特征,便于理解和可视化。
-
类别线性可分:其中 Iris-Setosa 类别与其他两个类别线性可分,而 Iris-Versicolour 和 Iris-Virginica 类别之间则不是线性可分的。
-
数据质量高:数据没有缺失值,特征之间相关性明显。
这些特点使得鸢尾花数据集成为机器学习入门和算法实验的理想选择。
二、逻辑回归与 One-vs-Rest 方法
(一)逻辑回归
逻辑回归是一种用于二分类问题的广义线性回归模型。它的目标是通过学习特征与目标变量之间的关系,预测样本属于某一类别的概率。逻辑回归的输出是一个概率值,范围在 [0,1] 之间,通常通过 Sigmoid 函数将线性回归的输出映射到概率空间。
逻辑回归的数学表达式为:
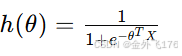
其中,θ 是模型参数,X 是特征向量。
逻辑回归的一个重要特点是默认进行了 L2 正则化(Ridge Regularization),这有助于防止模型过拟合。
(二)One-vs-Rest 方法
在多分类问题中,One-vs-Rest(OvR)是一种常用的策略。其基本思想是将多分类问题分解为多个二分类问题。对于 m 个类别,OvR 方法会训练 m 个二分类模型,每个模型将一个类别与其他所有类别区分开来。最终,通过比较每个模型的预测概率,选择概率最高的类别作为预测结果。
OvR 方法的优点是简单直观,适用于类别数量较多的情况。然而,它的缺点是计算量较大,尤其是当类别数量增加时。
三、实验过程
(一)数据预处理
实验中使用了 Python 的 scikit-learn 库来加载和处理鸢尾花数据集。具体代码如下:
Python复制
from sklearn import datasets
iris = datasets.load_iris()
X = iris['data'][:, 3:] # 仅使用花瓣宽度作为特征
y = iris['target']这里,我们只选择了花瓣宽度作为特征,以简化问题。实际应用中,通常会使用所有特征进行训练。
(二)模型训练
为了实现 One-vs-Rest 分类,我们使用了 scikit-learn 中的 OneVsRestClassifier 类,并将其与逻辑回归模型结合:
Python复制
from sklearn.linear_model import LogisticRegression
from sklearn.multiclass import OneVsRestClassifier
multi_classifier = LogisticRegression(solver='sag', max_iter=1000)
multi_classifier = OneVsRestClassifier(multi_classifier)
multi_classifier.fit(X, y)在上述代码中,LogisticRegression 是逻辑回归模型,OneVsRestClassifier 将其封装为 OvR 多分类模型。solver='sag' 表示使用随机平均梯度下降法(Stochastic Average Gradient Descent)作为优化算法,max_iter=1000 表示最大迭代次数为 1000。
(三)预测与结果分析
训练完成后,我们使用模型对新的数据进行预测,并输出预测概率和预测类别:
Python复制
import numpy as np
X_new = np.linspace(0, 3, 1000).reshape(-1, 1)
y_proba = multi_classifier.predict_proba(X_new)
y_hat = multi_classifier.predict(X_new)预测结果如下:
-
y_proba是每个类别的预测概率,每一行对应一个样本,每一列对应一个类别的概率。 -
y_hat是最终的预测类别。
从结果可以看出,随着花瓣宽度的增加,模型逐渐将样本从类别 0 划分为类别 1 和类别 2。这与鸢尾花数据集的特性一致:Iris-Setosa 类别与其他两个类别可以通过花瓣宽度较好地区分。
四、总结与展望
通过本次实验,我们成功地使用逻辑回归和 One-vs-Rest 方法对鸢尾花数据集进行了分类。实验结果表明,逻辑回归模型在处理多分类问题时,结合 OvR 策略可以取得较好的效果。然而,该方法也存在一些局限性,例如计算量较大,且对类别不平衡问题较为敏感。
在未来的工作中,我们可以尝试以下改进方向:
-
特征工程:使用更多特征或进行特征组合,以提高模型的性能。
-
其他多分类方法:尝试使用 One-vs-One 或 Softmax 回归等方法,比较不同策略的优缺点。
-
模型优化:调整逻辑回归的正则化参数或优化算法,以进一步提升模型的泛化能力。
总之,逻辑回归和 One-vs-Rest 方法为多分类问题提供了一种简单而有效的解决方案。通过不断探索和优化,我们可以在更多实际问题中发挥其价值。
源码地址:逻辑回归/逻辑回归-鸢尾花one_vs_rest分类.ipynb · 金外飞/artificial-intelligence-project - Gitee.com
希望这篇文章能帮助你更好地理解逻辑回归和 One-vs-Rest 方法在多分类问题中的应用。如果你对本文有任何疑问或建议,欢迎在评论区留言交流!

















 7254
7254

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









