







最大最小值归一化原理、实现与应用详解
在机器学习和数据处理中,数据归一化是一个非常重要的预处理步骤。今天,我们来详细探讨一种常用的数据归一化方法——最大最小值归一化(Min-Max Normalization)。
一、什么是最大最小值归一化?
最大最小值归一化(Min-Max Normalization) 是一种简单而有效的方法,它将数据线性映射到 [0, 1] 区间内。这种方法的核心思想是消除数据特征间的量纲差异,使得不同特征的数值范围一致,从而提升机器学习模型的训练效率和精度。
数学公式
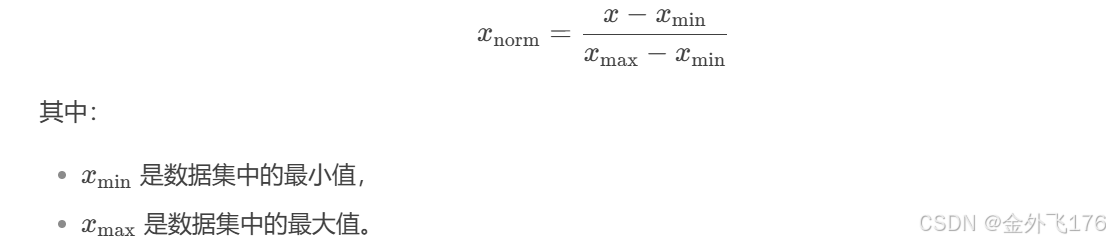
通过这个公式,我们可以将任意范围的数据缩放到 [0, 1] 区间内。
二、手动实现最大最小值归一化
接下来,我们通过一个简单的Python代码示例来手动实现最大最小值归一化。
代码示例
Python复制
import numpy as np
def min_max_normalization(data):
min_val = np.min(data) # 全局最小值
max_val = np.max(data) # 全局最大值
normalized_data = (data - min_val) / (max_val - min_val)
return normalized_data
# 生成示例数据
x = np.random.uniform(0, 4, (7, 5))
n_x = min_max_normalization(x)
print("原始数据:\n", x)
print("归一化结果:\n", n_x)输出说明
假设原始数据范围在 [0, 4],归一化后所有值会被缩放到 [0, 1]。例如:
plaintext复制
原始数据:
[[3.70299662 0.62200969 0.4175691 3.25277893 2.70704255]]
归一化结果:
[[0.96042099 0.1447594 0.09063573 0.84123019 0.69675175]]三、使用 Scikit-learn 实现
除了手动实现,我们还可以使用 scikit-learn 提供的 MinMaxScaler 工具类来实现最大最小值归一化。MinMaxScaler 支持批量数据转换,并且可以保存归一化参数,方便后续使用。
代码示例
Python复制
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
ns_x = scaler.fit_transform(x) # 自动计算 min 和 max
print("使用 Scikit-learn 的归一化结果:\n", ns_x)对比手动实现
手动实现与 MinMaxScaler 的结果是一致的,但 MinMaxScaler 更加便捷,而且支持特征范围自定义(例如可以映射到 [-1, 1])。
四、离群值对归一化的影响
在实际应用中,数据中可能会存在离群值,这些离群值会对最大最小值归一化产生较大的影响。我们来看一个示例。
示例场景
假设数据中存在一个极端离群值(如 10086):
Python复制
x1 = np.array([1, -12, 10086, 7, 5]).reshape(-1, 1)
n_x1 = scaler.fit_transform(x1)
print("原始数据:\n", x1)
print("归一化结果:\n", n_x1)输出结果
plaintext复制
原始数据:
[[ 1]
[-12]
[10086]
[ 7]
[ 5]]
归一化结果:
[[0.00009914]
[0.00000000]
[1.00000000]
[0.00069409]
[0.00049591]]由于最大值被离群值拉高,其他数据归一化后接近 0,导致有效信息丢失。
解决方案
-
离群值检测与处理:可以使用箱线图、Z-Score 等方法识别并剔除异常值。
-
鲁棒归一化方法:改用
RobustScaler(基于四分位数缩放),它对离群值的敏感度较低。
五、归一化的作用与优缺点
核心作用
-
消除量纲差异:使不同特征的数值范围一致。
-
加速模型收敛:在梯度下降算法中,归一化后各参数更新步长更加均衡。
-
提升模型精度:避免某些特征因数值过大而主导模型训练。
优缺点
-
优点:
-
简单高效,适用于大多数数值型数据。
-
-
缺点:
-
对离群值敏感,可能导致数据分布失真。
-
六、实际应用建议
-
适用场景:
-
神经网络、KNN、SVM 等对数据范围敏感的模型。
-
特征数值差异较大时(如年龄 vs 收入)。
-
-
注意事项:
-
训练集和测试集应使用相同的归一化参数。
-
若数据分布不稳定(如实时数据流),需定期更新归一化参数。
-
七、总结
最大最小值归一化是数据预处理的基础步骤,能有效提升模型性能,但对离群值敏感。在实际应用中,需要结合数据特点选择合适的归一化方法,必要时配合异常检测技术。通过手动实现或调用 scikit-learn 工具,均可轻松完成归一化操作。
如果你对最大最小值归一化还有其他疑问,或者想了解更多数据预处理的方法,欢迎在评论区留言交流!

















 538
538

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









