







注释
1 #
2 ''' ... ''' / """ .... """
行尾的冒号和下一行的缩进代表一个代码块,缩进通常为4个空格
关键字

变量
定义:不用说明类型,自动类型
可以随时改变(重新赋值时) 弱类型语言
id()可以获取变量的地址
字符串
''' ''' 可以跨行
前缀加上r或R 将原样输出 ,转义符不就行转义
+ 拼接字符串:只能字符串类型拼接
srt(num)将整数转换为字符串
len()计算字符串长度:utf-8 编码中文占三个字节
str[start:end:step]:可以用来截取字符串
str.split(sep,maxSplit):分割字符串 sep用来指定分隔字符,默认为所有空字符 返回字符串列表
str.count(sub):用来返回子字符串(sub)出现的次数
str.find(sub):若不存在返回 -1,否则返回首次出现的索引 /也可以 用 in 关键字
str.index():跟find一样,只不过不存在会抛出异常
str.startswitch(pre):返回bool值 是否以pre开头
str.endswitch(end):检查是否以end结尾
str.lower()/upper():转换为大小写
str.strip(' string' ):用来除去字符串两端的指定字符,默认为除去特殊字符和空格
str.l/r+strip('string'):用来除去一端的指定字符
格式化字符串:\

赋值时用{:+s/d..}来占位,str.format(对应元素)来替换
str='im {:s}'
print(str.format('sb'))#输出 im sb
print(str)#还是按照原来显示#输出 im {:s}---------------------------------------------------------------------
正则表达式:
元字符:
正则表达式 – 元字符 | 菜鸟教程 (runoob.com)
[]:表示匹配的字符集合 最前面+^表示排除的意思---非(整个集合排除)
\转义字符 ,或者加 R或r代表原字符串
类型转换函数

运算符
python 可以连续比较 如: 0<a<100
逻辑与:and 逻辑或:or 逻辑非:not (不支持符号逻辑表达了 ||等)
for循环
range(),返回的是一个可迭代对象 : 只有一个参数时,表示指定end,并不包括end
Python3 range() 函数用法 | 菜鸟教程 (runoob.com)
for x in range(4): # 相当于for(int x;x<4;x++)
print(x) # cout<<x;注意: 可以迭代 列表,元组,集合,字典等
pass空语句:占位符,不作任何作用
re模块实现正则表达式
import rere.match(pattern,string,[flags]):只在开始出进行匹配,失败返回none 成功返回Match对象re.search(pattern,string,[flags]):整个字符串中搜索 第一个 匹配的值,返回match对象re.findall(pattern,string,[flags]):匹配整个字符串中所有符合的子字符串,返回列表pattern:模式字符串--正则表达式
string:原文本
flags:可选参数,如不区分大小写
match.span():返回匹配位置的元组-不可变序列re.split(pattern,string,[maxsplit],[flags])//pattern 为 用正则表达式来代表分隔符re.sub(pattern,repl,string,count,flags)//repl 为替换的字符串序列
Python有6个序列的内置类型,但最常见的是列表和元组。
索引:
可以为负数 ,倒数第一个为-1 ,以此类推
特殊:
序列可切片 【start:end:step】
序列可以乘法: *3 内容为重复三次的结果
检查元素是否属于某个序列:
value in sequence
或
value not in sequence
都会返回bool值len()返回序列的长度
max() min() 分别返回序列的最大值,和最小值 {只能是纯srt类型,或纯数字类型}
列表
[] 表示
元素类型可以不同!
list() :可以将可迭代类型数据转换成列表
del listname :删除列表
for循环 与 enumerate()函数 同时输出索引 和元素值
for index,item in enumerate(listName):
print(index,item)列表添加方法(调用对象的方法)
添加元素:lsitname.append(value)
添加整个列表:lsitName.extend(list)
都是添加在末尾
删除:
按索引来删除或修改:
del list[index]根据元素值删除:必须存在该元素,否则会抛出异常
listName.remove(value)基本方法:
.count():返回元素出现次数
.index(): 返回元素首次出现的index
sum(listname):统计元素总和
.sort() :默认升序,可以有参数
sorted(listName):返回的是一个副本,原不变
列表推导式子
list = [函数/式子 for 变量 in 可以迭代对象 +条件(*)]
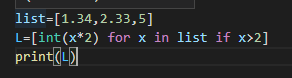
结果为[4,10] 先执行条件 ,再执行表达式
元组 (tuple)
不可变序列---不可变列表:用()表示
创建
空元组:
tuple=()tuple()函数:参数是可迭代对象
一个元素的tuple:
tuple=('123',)#要加一个逗号,不然是str
推导式子:不能直接像列表一样一次性赋值,必须先产生对象(如range()),再用tuple()赋值
改变
不能改变,删除单个元素:也就不支持一些方法如append()
要么重新对整个tuple进行赋值,要么在后面连接一个新的元组
列表与元组区别:

字典(dictionary)
用{key:value} 表示
字典中的key是不可变的,所以可以用数字,字符串,元组,不能用列表
通过key来读取,而不是索引下标
创建:
直接赋值
=dict()创建空字典
= dict(zip(list1,list2) ) :zip函数将多个元组或列表组合起来,返回一个zip对象,再用dict转换为字典
={name_tauple:list}:会自动一一对应
推导式:={i:random.randint(10,100) for i in range(1,5)}
删除:
del dictionary :删除整个字典
del dictionary[key]:删除单个元素
添加:
dictionary[key] = value :增加元素,若key重复,则覆盖
访问:
通过key查询:dictionary[key]
print直接打印
dictiona.get(key):来获取值
遍历:
for item in dictionary.items():
pritn(item)区别

异常处理
1try +except
2)try + except +else
3)try +except +else +finally
try: #要测试异常的代码块1
fh = open("testfile", "w")
fh.write("这是一个测试文件,用于测试异常!!")
except IOError: #抛出异常执行这 代码块2
print "Error: 没有找到文件或读取文件失败"
else:
print "内容写入文件成功" #没抛出异常执行这 可以省略
fh.close()
finally:
print("不管怎么样这里都执行'') #不管怎么样都执行 标准格式需要finally4)raise :抛出一个异常
5)assert :断言 如果 条件为假则抛出AssertionError异常
message可省略
assert 条件表达式 ,'message'6)assert + try + except:配合使用,捕获assertionError异常
try:
assert 1<0 ,"断言"
except AssertionError :#补货了
print("捕获了断言异常")
print("能继续执行")注意:
1)try..except 捕获异常后 ,可以继续执行下去
2)assert单独使用,程序会中断,不会执行下去
函数
关与_main_属性:
Python main() 函数 - 菜鸟教程 (cainiaojc.com)
def max(b,a=6):#默认赋值的参数要在最后
'提供注释'
if a>3:
print(a)
print(max.__defaults__)#返回默认参数值,是元组
max(3)1)定义函数的第二行可以提供注释 ,调用时,会有提示
2)形参可以使用默认值,有默认值的形参必须在最后定义---配合调用规范
赋值的对象最好是不可变对象(如常数6),不然默认值改变,就失去了默认值的意义
3)函数名.__defaults__可以返回默认参数的元组
不定长参数
类似于传指针?
4) 定义形参时
*parameter :表示接受任意多个实际参数并放到一个元组中 parameter相当于一个可迭代对象
**parameter:接受任意多个 键对值 参数,并将其放到一个字典中-------------
5) 局部变量加 global 该变量就变成全局变量/ 或函数体内声明已有的全局变量
匿名函数 lambda
result= lambad (参数):expression6) 参数能有多个,但表达式只能有一个且只能返回一个值
对象程序设计
跟其他语言的类差不多
python天生就是面向对象的
类是封装对象属性和行为的载体,对象是类的实例。
class A: #定义类
'提供注释'
def __init__(self,a,b) : #定义构造函数 默认为__init__
print(a+b)
C=A(2,4);#实例化,带参数
print(C)1) 构造函数固定为__init__
2)定义__init__时第一个形参必须是self,相当于c++里的this,是一个自身的引用,但传参时不用理会
类属性 与 对象属性
都可以用时再定义,用.访问
类名.定义--->类属性
实例对象名.定义--->对象属性
【python】详解类class的属性:类数据属性、实例数据属性、特殊的类属性、属性隐藏(二)_brucewong0516的博客-CSDN博客_python 定义类属性
类属性
1)定义类内函数体外的成员,通过类名访问,而不是实例化后的对象名
2)被所有实例共享,指向同一个值
对象属性
1)定义在函数体内部(包括__init__),通过对象名访问
2)不共享
私有成员
私有变量的作用:确保了外部代码不能随意修改对象内部的状态(通过调用内部方法来访问),这样通过访问限制的保护,代码更加健壮。
(1) 一个下划线开头,如_name
这种形式的私有变量外部是可以访问的,但是,按照约定俗成的规定,当你看到这样的变量时,意思是:“虽然我可以被访问,但是,请把我视为私有变量,不要随意访问。”
(2)两个下划线开头,如__name
问题:双下划线开头的实例变量是不是一定不能从外部访问呢?
答:也不是,只是不能直接访问__name,是因为python解释器对外把__name变量改成了_Student__name,所以,仍然可以通过实例名._Student__name来访问__name变量。
但是强烈建议不要这么做,因为不同版本的Python解释器可能会把__name改成不同的变量名。
>>>总的来说,Python本身没有任何机制阻止你干坏事,一切全靠自觉。
http://www.136.la/python/show-63029.html
装饰器@property
把方法装饰成实列属性---通过方法名来访问方法,从而不需要添加一对小括号。
只能读,不能修改这种属性(因为实际是一种方法)--可以利用这种机制设置为只读成员
....//定义类
@property //装饰为属性area,通过实例名直接访问,返回的是计算的结果
def area(self):
return self.width*self.height继承
class ClassName(父类列表,用逗号隔开):
类体1)成员/方法会被继承
2)方法不适合时,可以重写--重写定义,方法名一样
3)关于派生的__init__函数
python中super().__init__()_BeanInJ的博客-CSDN博客_super().__init__()
派生类中若无init函数
则会自动调用父类的__init__()构造函数
或者利用super().__init__()语句主动调用父类的__init__函数。
class A:
def __init__(self) -> None:
print('我是父类')
class B(A):
"a的子类"
def __init__(self) -> None:
super().__init__() ##这样主动调用 或者 省略子类的init函数都将 执行父类的init函数
c=B()模块(库)
类比为其他语言的库
模块名+.py的形式
有标准库,第三方库,包等
导入模块
1) import 模块名
每导入一个模块,都会创建一个新的命名空间--以辨别不同库的重名
调用模块里面的 成员/方法都要
用模块名.进行访问
2) from 模块名 import 成员/方法 列表
用这种方式导入的特定成员/方法 前面不用加库名就能访问
但要小心与已有的名字重名-会覆盖
导入自定义模块的三种方法
sys库中 sys.pyth 变量中有 path目录
1)通过 sys.path.append() 一次性添加目录
2)增加 .pth 文件
3)通过设置环境变量
python如何导入自己的模块_python_脚本之家 (jb51.net)
模块属性名:
每个模块定义中都有变量 __name__,可以通过值确定在哪个模块中执行
顶级模块(主程序,当前py文件)中的变量值内容为__main__
if __name__=='__main__':
...包
为了避免模块重名和分层次管路---引入了包的概念
包是一个分层次的目录结构---就是一个文件夹,内含子包和子模块

导入包/子模块
1) 必须有个__init__.py的PY文件,此模块在导入包时会自动执行
2)导入指定模块 ,访问时需要加入前缀--包名.模块名
import 包名.模块名 2)导入指定模块,访问时需要加模块名
from 包名 import 模块名3)可直接使用,不用加前缀
from 包名 import 模块名.变量名文件操作
跟c一样
打开,关闭
一般打开必须及时关闭
f=open('TEXT1.txt','a+',encoding='utf-8')
f.write('好好好')
f.close()读取文件
1)读取指定个数,如果省略size则一次性读取所有内容
file.read(size)2) 移动文件指针
file.seek(往后移的个数,whenceCode)
0代表从文件头开始,1当前位置,2尾开始3)读取一行
file.readline()4) 读取整行 :返回时一个字符串列表
file.readlines()删除文件
利用os模块,如果文件不存在会报错
import os
os.remove(path)目录(文件夹操作)操作
可以对应linux下的命令,是利用函数库联系操作系统进行操作,因而执行结果与操作系统有关
基本操作(os模块)
使用内置OS模块进行操作
1)os.name :获取操作系统类型
nt表示windows,posix表示UNIX类系统
2)os.linesep:获取换行符
3)os.sep:获取路径分隔符 :windows为\
路径
基本操作
注意:需要用\对\进行转义-->\\
1)os.getcwd():获得当前工作目录 -current working directory
2) os.abspath(相对路径/文件名):获得绝对路径
3)os.path.join(path1,path2...):拼接多个路径
a 只会单纯拼接,不会检查该路径是否存在
b 如果没有一个绝对路径,那拼接成的也是相对路径
c 如果有多个绝对路径,只取最后一个绝对路径,前面的全部忽略
4)os.path.exists(path):判断路径是否存在 返回bool值
创建
1)创建最次级目录,如果该目录的上一级不存在-抛出异常
os.mkdir('path',mode=...)
此mode是linux下的文件权限,其他操作系统可忽略
2)创建多级目录(递归创建),会一级一级的从高级目录到最次级目录创建
os.makedirs(name,mode=...)相当于linux下的 -r参数
删除
1)目录里内容为空才可删除
必须存在该目录且内容为空
os.rmdir('path')2) 删除该目录及子内容-- 利用shutil模块
import shutil
shutil.rmtree('path')遍历目录-walk
walk:返回一个包含三个元素的元组-->
第一个:目录字符串
第二个:子目录列表
第三个返回元素:子文件列表
os.walk(top,topdown,onerror,followlinks)top:用于指定要遍历的根目录
topdown:指定遍历顺序,如果为TRUE 则从上而下,FALSE则从下到上
onerror:错误处理方式
followlinks:与符号连接有关
例子-->
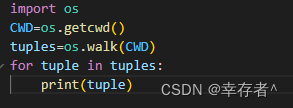

重命名文件或目录
os.rename(src,dst)可以为目录或文件名,必须要存在
获取文件基本信息
如最后一次访问时间等,返回的是一个对象
os.stat(path)
--->

Py与SQL
还不会等待学
通过pymysql与其连接
pymysql的安装及使用_珂鸣玉的博客-CSDN博客_pymysql安装
Python3 MySQL 数据库连接 – PyMySQL 驱动 | 菜鸟教程 (runoob.com)
------------------------------------------
基础语法完结















 140
140











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









