







一、决策树概述
1.决策树的概念:
分类决策树模型是一种描述对实例进行分类的树形结构。决策树由结点和有向边组成。结点有两种类型:内部结点和叶节点。内部结点表示一个特征或属性,叶节点表示一个类。如:
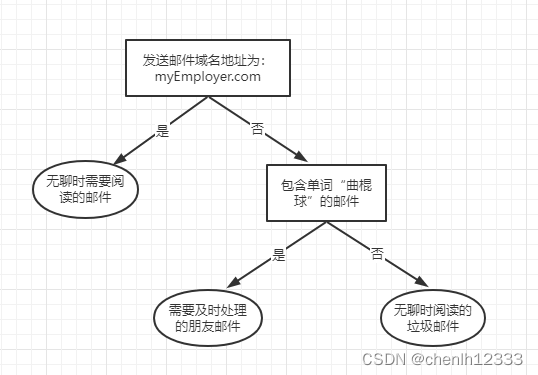
上图中长方形代表判断模块,椭圆形代表终止模块,表示已经得出结论,可以终止运行。从判断模块中引出的箭头是分支,它可以到达另一个模块。
2.决策树的优缺点及适用范围:
优点:计算复杂度不高,数据形式容易理解,对中间值的缺失不敏感,可以处理一些不相关的特征数据。
缺点:可能会产生过度匹配的问题。
适用数据类型:数值型和标称型。
二、决策树的构造
1.流程:
(1)评估每个特征,找到在当前数据集上划分数据分类时起决定作用的特征。并以此决定性的特征将原始数据集划分为几个数据子集,使得这些数据子集有一个当前条件下最好的分类。
(2)将这些数据子集分到第一个决策点的所有分支上。
(3)如果某分支下的数据属于同一个类型,则无需进一步对数据集进行划分。
(4)如果某分支下的数据不属于同一个类型,则重复划分数据子集的过程。方法与划分原始数据集类似,直到所有具有相同数据类型的数据都处于一个数据子集内。
(5)这样就生成了一颗决策树。
2.创建分支的伪代码 createBranch() 如下所示:
检测数据集中每个子项是否属于同一类:
If so return 类标签:
Else
寻找划分数据集的最好特征
划分数据集
创建分支节点
for 每个划分的子集
调用函数createBranch()并增加返回结果到分支节点中
return 分支节点
3.划分选择:
决策树学习的关键在于如何选择最优划分属性,本节使用ID3算法来划分数据集,该算法处理如何划分数据集,何时停止划分数据集。
4.信息增益:
信息增益,即在划分数据集之前之后信息发生的变化。知道如何计算信息增益,我们就可以计算每个特征值划分数据集获得的信息增益,获得信息增益最高的特征就是最好的选择。
熵定义为信息的期望值,如果待分类的事物可能划分在多个类之中,则符号 的信息定义为:
其中,是选择该分类的概率,即
。
为了计算熵,我们需要计算所有类别所有可能值所包含的信息期望值,通过下式得到:
其中,n为分类数目。随机变量的不确定性就越大,熵越大。
5.数据集的准备:
数据集如下图:

对数据集进行属性标注:
- 家庭收入:0代表一般,1代表较差,2代表很差;
- 是否努力:0代表否,1代表是;
- 平时生活状况:0代表良好,1代表一般;
- 类别(是否通过):yes代表是,no代表否。
6.编写代码:
(1)计算数据集的信息熵
from math import log
def creatDataSet():
# 数据集
dataSet=[[0, 1, 0, 'no'],
[0, 0, 0, 'no'],
[0, 0, 1, 'no'],
[0, 0, 0, 'no'],
[0, 1, 1, 'yes'],
[1, 1, 0, 'yes'],
[1, 1, 1, 'yes'],
[1, 0, 0, 'no'],
[1, 1, 0, 'yes'],
[1, 0, 1, 'no'],
[1, 1, 1, 'yes'],
[2, 1, 0, 'yes'],
[2, 1, 0, 'yes'],
[2, 1, 1, 'yes'],
[2, 0, 1, 'no']]
# 分类属性
labels=['家庭收入','是否努力','平时生活状况']
# 返回数据集和分类属性
return dataSet,labels
# 计算给定数据集的香农熵
def calcShannonEnt(dataSet):
numEntries=len(dataSet)
# 为所有可能分类创建字典
labelCounts={}
# 对每组特征向量进行统计
for featVec in dataSet:
currentLabel=featVec[-1] #最后一列的数值作为键值
if currentLabel not in labelCounts.keys(): #如果当前键值不存在字典中,则扩展字典并将当前键值加入字典
labelCounts[currentLabel]=0
labelCounts[currentLabel]+=1 #每个键值都记录了当前类别出现的次数
shannonEnt=0.0
for key in labelCounts:
prob=float(labelCounts[key])/numEntries
shannonEnt-=prob*log(prob,2)
return shannonEnt (2)编写代码划分数据集
def chooseBestFeatureToSplit(dataSet):
numFeatures = len(dataSet[0]) - 1
baseEntropy = calcShannonEnt(dataSet)
bestInfoGain = 0.0
bestFeature = -1
for i in range(numFeatures):
featList = [example[i] for example in dataSet]
uniqueVals = set(featList)
newEntropy = 0.0
for value in uniqueVals:
subDataSet = splitDataSet(dataSet, i, value)
prob = len(subDataSet) / float(len(dataSet))
newEntropy += prob * calcShannonEnt((subDataSet))
infoGain = baseEntropy - newEntropy
print("第%d个特征的增益为%.3f" % (i, infoGain))
if (infoGain > bestInfoGain):
bestInfoGain = infoGain
bestFeature = i
return bestFeature
def splitDataSet(dataSet,axis,value):
retDataSet=[]
for featVec in dataSet:
if featVec[axis]==value:
reducedFeatVec=featVec[:axis]
reducedFeatVec.extend(featVec[axis+1:])
retDataSet.append(reducedFeatVec)
return retDataSet
(3)递归构建决策树
def majorityCnt(classList):
classCount={}
for vote in classList:
if vote not in classCount.keys():
classCount[vote]=0
classCount[vote]+=1
sortedClassCount=sorted(classCount.items(),key=operator.itemgetter(1),reverse=True)
return sortedClassCount[0][0]
def createTree(dataSet,labels,featLabels):
classList=[example[-1] for example in dataSet]
if classList.count(classList[0])==len(classList):
return classList[0]
if len(dataSet[0])==1:
return majorityCnt(classList)
bestFeat=chooseBestFeatureToSplit(dataSet)
bestFeatLabel=labels[bestFeat]
featLabels.append(bestFeatLabel)
myTree={bestFeatLabel:{}}
del(labels[bestFeat])
featValues=[example[bestFeat] for example in dataSet]
uniqueVls=set(featValues)
for value in uniqueVls:
myTree[bestFeatLabel][value]=createTree(splitDataSet(dataSet,bestFeat,value),
labels,featLabels)
return myTree(4)测试运行
if __name__=='__main__':
dataSet,labels=creatDataSet()
featLabels=[]
myTree=createTree(dataSet,labels,featLabels)
print(myTree)(5)运行结果

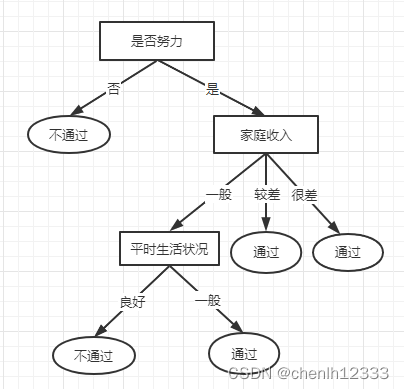
7.决策树的图形表示:
8.实验总结:
通过比较数据集中的数据,可以看出数据集中的所有数据都能代入决策树。通过该决策树,将复杂的数据集变得易于理解。
9.参考教材:
机器学习实战















 380
380











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









