






一、redis的五种存储结构分别对应那些场景或者在该场景下应用的是redis应用的那种数据存储结构?
1、String
(1)利用类似于map集合的存储方式,可以使用验证码。在每一个String 数据内放入验证码,键为每个用户的id,值为验证码,并且设置过期时间,在内存中的redis一旦过期就无效。
(2)在我们验证登录信息时会将验证信息存入session域,但是session对象是由服务器创建的,随着对象的过多,服务器的压力也会增大,所以我们使用将所有的session对象放入redis中,保证其在进行数据验证时不会发生失效即可,这样我们的服务器压力会减小,数据库的压力也会减小。
2、哈希
(1)哈希一般用来存储对象,常用的是购物车。我们将商品的信息放入redis,在其中我们可以将商品的信息视为对象的属性,每个商品都有对应的键保证不会重复。
(2)也可以用来进行网站的访问量统计、同时在线人数显示等。
3、set
由于set可以保证数据的键值不会重复,所以可以用来做一些抽奖的操作,每一个用户的id就是键,随机的数就是就是值,还可以用来做点赞的功能,知道哪一个用户的点赞在到哈希里统计。
4、列表
这个就是用的最多的一个数据结构,可以用作缓存、计数器、限流、消息队列
5、有序集合(zset)
利用加入分数后的排序将集合进行升序或者降序的排列,做热度榜、积分榜等。
二、缓存穿透、缓存雪崩、缓存击穿的原因和解决策略
1、缓存穿透
由于客户端的访问请求的数据资源在redis和数据库中都没有,因此当当大量请求到来时,数据库可能会被干倒,所以我们需要在数据库中加入返回为空对象的操作在将其加入事务,这样就当查询为空时就回滚避免重复查询;另外,我们还可以使用在客户端和redis之间添加布隆过滤器,在拦截响应(空返回对象),当第一次访问时,缓存中没有,到数据库中查询,没有,返回空对象,当响应经过布隆过滤器时,如果时空对象,将其拦截,并在redis中记录访问的用户请求,如果下次仍让是该请求,则不再让它访问,以避免缓存穿透的问题。
2、缓存雪崩
该问题的出现是由于redis的数据失效或者宕机而导致直接访问数据库,这样一来数据库直接挂掉。对应的解决策略是:在横向加入集群,其还有主从复制、哨兵模式等,
-
集群由多个节点(Node) 组成,Redis 的数据分布在这些节点中。
-
集群中的节点分为主节点和从节点;只有主节点负责读写请求和集群信息的维护;从节点只进行主节点数据和状态信息的复制
-
使用分布式锁
在纵向上可以设置多级缓存,用来减小访问压力。
3、缓存击穿
该问题的出现是由于访问redis里的某个不存在数据的访问过频繁(热点数据),导致数据库的崩溃。具体的解决策略是加入锁,这样使得资源的访问只能一一执行,很大程度上减小了数据库的压力。
三、数据一致的问题
我们的访问流程是:
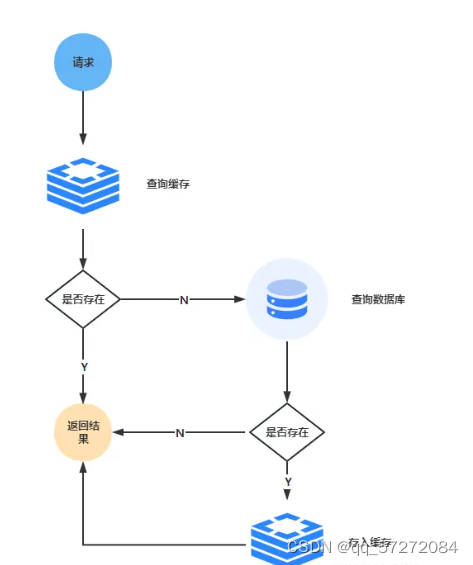
- 先更新缓存,再更新数据库
- 先更新数据库,再更新缓存
- 先删除缓存,再更新数据库
- 先更新数据库,再删除缓存
先更新缓存,再更新数据库
先更新缓存,再更新数据库这种情况下,如果业务执行正常,不出现网络等问题,这么操作不会有啥问题,两边都可以更新成功。但是,如果缓存更新成功了,但是当更新数据库时或者在更新数据库之前出现了异常,导致数据库无法更新。这种情况下,缓存中的数据变成了一条实际不存在的假数据。
先更新数据库,再更新缓存
先更新数据库,再更新缓存和先更新缓存,再更新数据库的情况基本一致,如果失败,会导致数据库中是最新的数据,缓存中是旧数据。还有一种极端情况,在高并发情况下容易出现数据覆盖的现象:A线程更新完数据库后,在要执行更新缓存的操作时,线程被阻塞了,这个时候线程B更新了数据库并成功更新了缓存,当B执行完成后线程A继续向下执行,那么最终线程B的数据会被覆盖。
先删除缓存,再更新数据库
先删除缓存,再更新数据库这种情况,如果并发量不大用起来不会有啥问题。但是在并发场景下会有这样的问题:线程A在删除缓存后,在写入数据库前发生了阻塞。这时线程B查询了这条数据,发现缓存中不存在,继而向数据库发起查询请求,并将查询结果缓存到了redis。当线程B执行完成后,线程A继续向下执行更新了数据库,那么这时缓存中的数据为旧数据,与数据库中的值不一致。
先更新数据库,再删除缓存
先更新数据库,再删除缓存也并不是绝对安全的,在高并发场景下,如果线程A查询一条在缓存中不存在的数据(这条数据有可能过期被删除了),查询数据库后在要将查询结果缓存到redis时发生了阻塞。这个时候线程B发起了更新请求,先更新了数据库,再次删除了缓存。当线程B执行成功后,线程A继续向下执行,将查询结果缓存到了redis中,那么此时缓存中的数据与数据库中的数据发生了不一致。















 170万+
170万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









