







前言
作为 Kubernetes 里的核心概念和原子调度单位,Pod 的主要职责是管理容器,以逻辑主机、容器集合、进程组的形式来代表应用,它的重要性是不言而喻的。
看看在 Kubernetes 里配置 Pod 的两种方法:资源配额 Resources、检查探 针 Probe,它们能够给 Pod 添加各种运行保障,让应用运行得更健康。
一、容器资源配额
我们知道创建容器有三大隔离技术:namespace、cgroup、chroot。其中的 namespace 实现了独立的进程空间,chroot 实现了独立的文件系统,但唯独没有看到 cgroup 的具体应用。
cgroup 的作用是管控 CPU、内存,保证容器不会无节制地占用基础资源,进而影响到系统里的其他应用。
不过,容器总是要使用 CPU 和内存的,该怎么处理好需求与限制这两者之间的关系呢?
Kubernetes 的做法与我们在【k8s】PersistentVolume解决数据持久化问题(十三)里提到的 PersistentVolumeClaim 用法有些类似,就是容器需要先提出一个书面申请,Kubernetes 再依据这个申请决定资源是否分配和如何分配。
但是 CPU、内存与存储卷有明显的不同,因为它是直接内置在系统里的,不像硬盘那样需要外挂,所以申请和管理的过程也就会简单很多。
具体的申请方法很简单,只要在 Pod 容器的描述部分添加一个新字段 resources 就可以了,它就相当于申请资源的 Claim。
来看一个 YAML 示例:
apiVersion: v1
kind: Pod
metadata:
name: ngx-pod-resources
spec:
containers:
- image: nginx:alpine
name: ngx
resources:
requests:
cpu: 10m
memory: 100Mi
limits:
cpu: 20m
memory: 200Mi
这个 YAML 文件定义了一个 Nginx Pod,我们需要重点学习的是 containers.resources,它下面有两个字段:
requests,意思是容器要申请的资源,也就是说要求 Kubernetes 在创建 Pod 的时候必须分配这里列出的资源,否则容器就无法运行。limits,意思是容器使用资源的上限,不能超过设定值,否则就有可能被强制停止运行。
在请求 cpu 和 memory 这两种资源的时候,你需要特别注意它们的表示方式。
内存的写法和磁盘容量一样,使用 Ki、Mi、Gi 来表示 KB、MB、GB,比如 512Ki、100Mi、0.5Gi 等。
而 CPU 因为在计算机中数量有限,非常宝贵,所以 Kubernetes 允许容器精细分割 CPU,即可以 1 个、2 个地完整使用 CPU,也可以用小数 0.1、0.2 的方式来部分使用 CPU。这其实是效仿了 UNIX“时间片”的用法,意思是进程最多可以占用多少 CPU 时间。
不过 CPU 时间也不能无限分割,Kubernetes 里 CPU 的最小使用单位是 0.001,为了方便表示用了一个特别的单位 m,也就是milli 毫的意思,比如说 500m 就相当于 0.5。
现在我们再来看这个 YAML,你就应该明白了,它向系统申请的是 1% 的 CPU 时间和 100MB 的内存,运行时的资源上限是 2%CPU 时间和 200MB 内存。有了这个申请,Kubernetes 就会在集群中查找最符合这个资源要求的节点去运行 Pod。
如果 Pod 不写 resources 字段,Kubernetes 会如何处理呢?
这就意味着 Pod 对运行的资源要求既没有下限,也没有上限,Kubernetes 不用管 CPU 和内存是否足够,可以把 Pod 调度到任意的节点上,而且后续 Pod 运行时也可以无限制地使用 CPU 和内存。
如果是生产环境就很危险了,Pod 可能会因为资源不足而运行缓慢,或者是占用太多资源而影响其他应用,所以我们应当合理评估 Pod 的资源使用情况,尽量为 Pod 加上限制。
让我们来试一下吧,先删除 Pod 的资源限制 resources.limits,把 resources.request.cpu 改成比较极端的10,也就是要求 10 个 CPU:
apiVersion: v1
kind: Pod
metadata:
name: ngx-pod-resources
spec:
containers:
- image: nginx:alpine
name: ngx
resources:
requests:
cpu: 10
memory: 100Mi
# limits:
# cpu: 20m
# memory: 200Mi
你会发现pod是可以创建成功即使环境没有那么多资源。
不过我们再用 kubectl get pod 去查看的话,就会发现它处于Pending状态,实际上并没有真正被调度运行:

使用命令 kubectl describe 来查看具体原因,会发现有这么一句提示:

这就很明确地告诉我们 Kubernetes 调度失败,当前集群里的所有节点都无法运行这个 Pod,因为它要求的 CPU 实在是太多了。
二、容器探针状态
现在,我们使用 resources 字段加上资源配额之后,Pod 在 Kubernetes 里的运行就有了初步保障,Kubernetes 会监控 Pod 的资源使用情况,让它既不会饿死也不会撑死。
但这只是最初级的运行保障,如果你开发或者运维过实际的后台服务就会知道,一个程序即使正常启动了,它也有可能因为某些原因无法对外提供服务。其中最常见的情况就是运行时发生死锁或者死循环的故障,这个时候从外部来看进程一切都是正常的,但内部已经是一团糟了。
那该用什么手段来检查应用的健康状态呢?
因为应用程序各式各样,对于外界来说就是一个黑盒子,只能看到启动、运行、停止这三个基本状态,此外就没有什么好的办法来知道它内部是否正常了。
所以,我们必须把应用变成灰盒子,让部分内部信息对外可见,这样 Kubernetes 才能够探查到内部的状态。
这么说起来,检查的过程倒是有点像现在我们很熟悉的核酸检测,Kubernetes 用一根小棉签在应用的检查口里提取点数据,就可以从这些信息来判断应用是否健康了,这项功能也就被形象地命名为探针(Probe),也可以叫探测器。
Kubernetes 为检查应用状态定义了三种探针,它们分别对应容器不同的状态:
Startup,启动探针,用来检查应用是否已经启动成功,适合那些有大量初始化工作要做,启动很慢的应用。Liveness,存活探针,用来检查应用是否正常运行,是否存在死锁、死循环Readiness,就绪探针,用来检查应用是否可以接收流量,是否能够对外提供服务。
你需要注意这三种探针是递进的关系:应用程序先启动,加载完配置文件等基本的初始化数据就进入了 Startup 状态,之后如果没有什么异常就是 Liveness 存活状态,但可能有一些准备工作没有完成,还不一定能对外提供服务,只有到最后的 Readiness 状态才是一个容器最健康可用的状态。
这三种状态可能有点难理解,我画了一张图,你可以看一下状态与探针的对应关系:
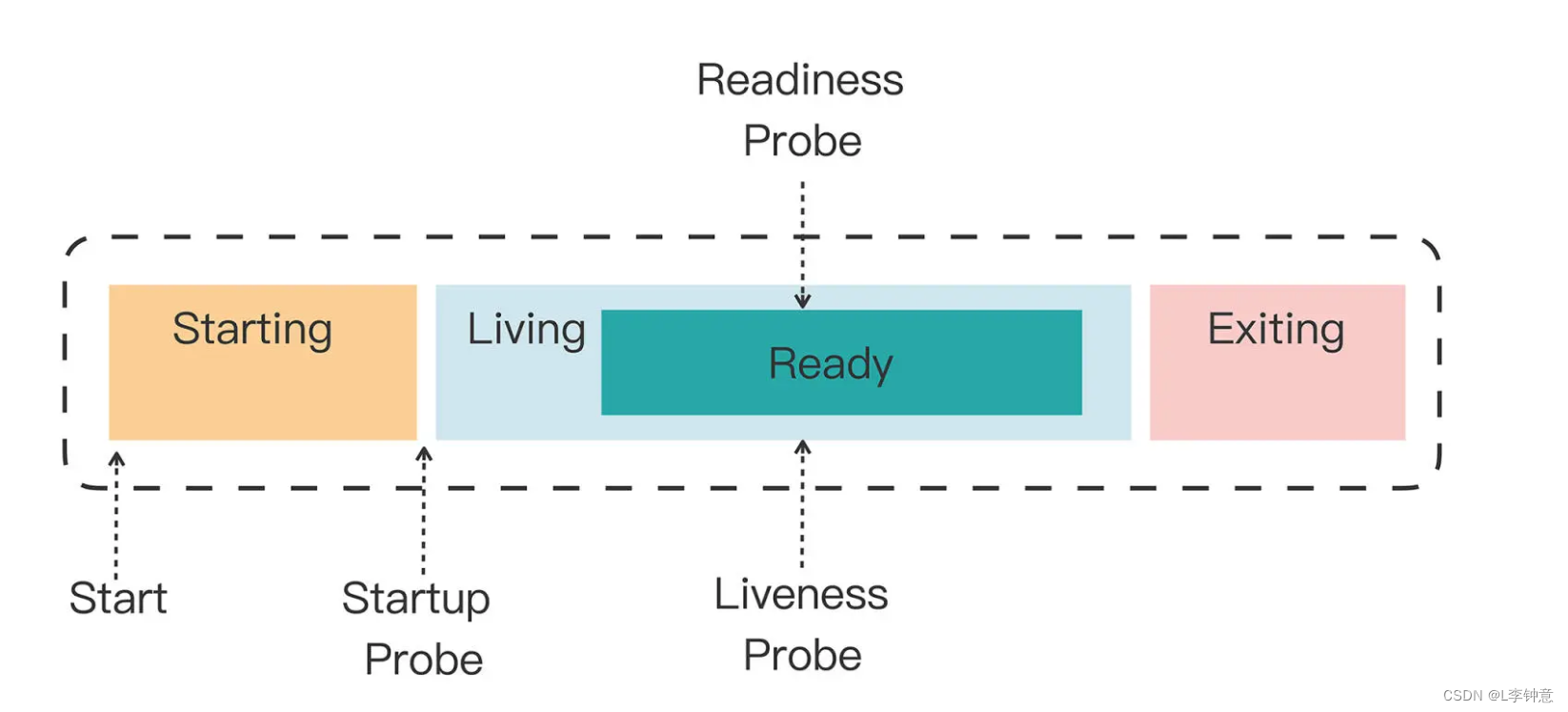
那 Kubernetes 具体是如何使用状态和探针来管理容器的呢?
如果一个 Pod 里的容器配置了探针,Kubernetes 在启动容器后就会不断地调用探针来检查容器的状态:
-
如果 Startup 探针失败,Kubernetes 会认为容器没有正常启动,就会尝试反复重启,当然其后面的 Liveness 探针和 Readiness 探针也不会启动。
-
如果 Liveness 探针失败,Kubernetes 就会认为容器发生了异常,也会重启容器。
-
如果 Readiness 探针失败,Kubernetes 会认为容器虽然在运行,但内部有错误,不能正常提供服务,就会把容器从 Service 对象的负载均衡集合中排除,不会给它分配流量。
知道了 Kubernetes 对这三种状态的处理方式,我们就可以在开发应用的时候编写适当的检查机制,让 Kubernetes 用探针定时为应用做体检了。
在刚才图的基础上,我又补充了 Kubernetes 的处理动作,看这张图你就能很好地理解容器探针的工作流程了:
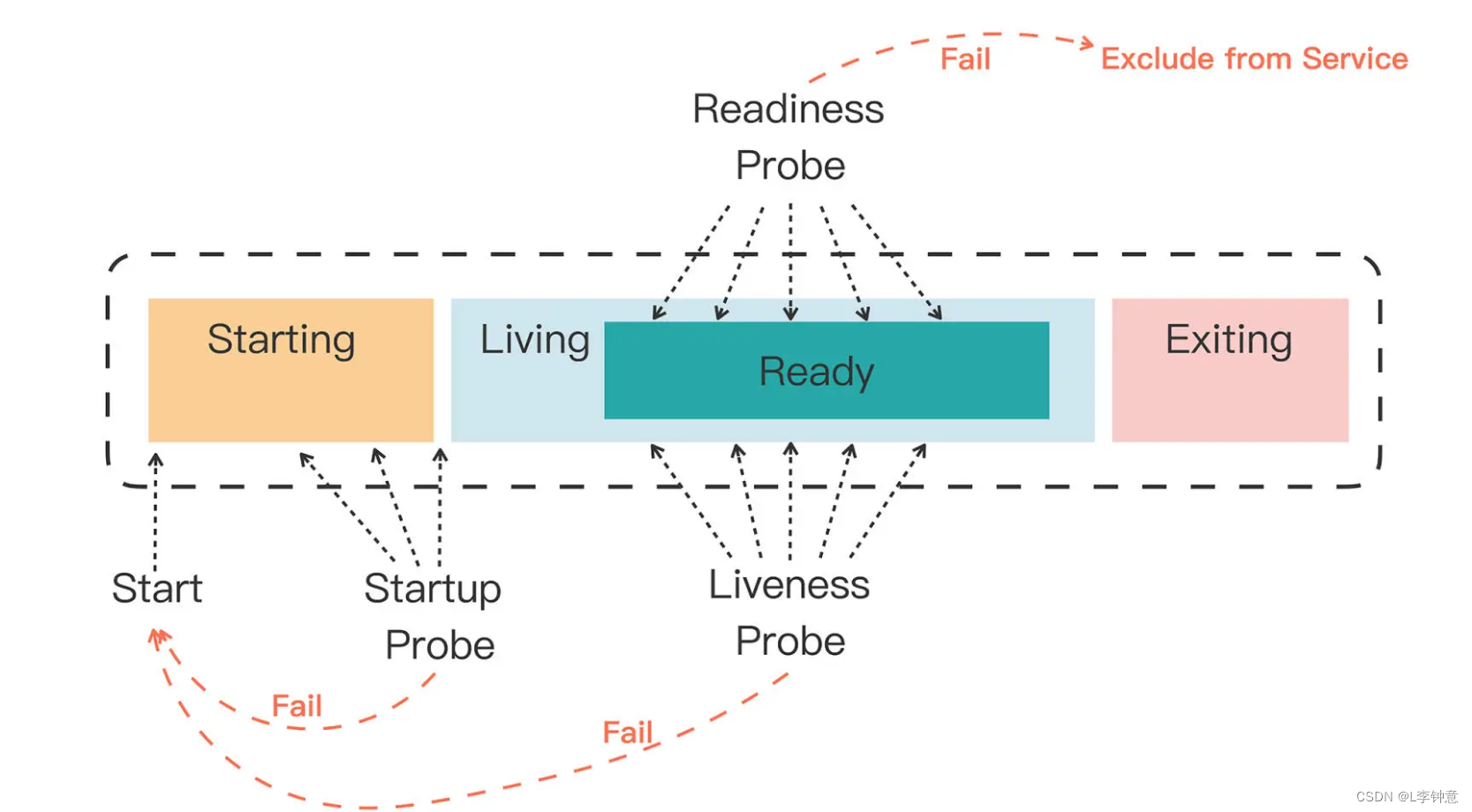
三、使用容器状态探针
掌握了资源配额和检查探针的概念,我们进入今天的高潮部分,看看如何在 Pod 的 YAML 描述文件里定义探针。
startupProbe、livenessProbe、readinessProbe 这三种探针的配置方式都是一样的,关键字段有这么几个:
periodSeconds,执行探测动作的时间间隔,默认是 10 秒探测一次。timeoutSeconds,探测动作的超时时间,如果超时就认为探测失败,默认是 1 秒。successThreshold,连续几次探测成功才认为是正常,对于 startupProbe 和 livenessProbe 来说它只能是 1。failureThreshold,连续探测失败几次才认为是真正发生了异常,默认是 3 次。
至于探测方式,Kubernetes 支持 3 种:Shell、TCP Socket、HTTP GET,它们也需要在探针里配置:
exec,执行一个 Linux 命令,比如 ps、cat 等等,和 container 的 command 字段很类似。tcpSocket,使用 TCP 协议尝试连接容器的指定端口。httpGet,连接端口并发送 HTTP GET 请求。
要使用这些探针,我们必须要在开发应用时预留出检查口,这样 Kubernetes 才能调用探针获取信息。这里我还是以 Nginx 作为示例,用 ConfigMap 编写一个配置文件:
apiVersion: v1
kind: ConfigMap
metadata:
name: ngx-conf
data:
default.conf: |
server {
listen 80;
location = /ready {
return 200 'I am ready';
}
}
你可能不是太熟悉 Nginx 的配置语法,我简单解释一下。
在这个配置文件里,我们启用了 80 端口,然后用 location 指令定义了 HTTP 路径/ready,它作为对外暴露的检查口,用来检测就绪状态,返回简单的 200 状态码和一个字符串表示工作正常。
现在我们来看一下 Pod 里三种探针的具体定义:
apiVersion: v1
kind: Pod
metadata:
name: ngx-pod-probe
spec:
volumes:
- name: ngx-conf-vol
configMap:
name: ngx-conf
containers:
- image: nginx:alpine
name: ngx
ports:
- containerPort: 80
volumeMounts:
- mountPath: /etc/nginx/conf.d
name: ngx-conf-vol
startupProbe:
periodSeconds: 1
exec:
command: ["cat", "/var/run/nginx.pid"]
livenessProbe:
periodSeconds: 10
tcpSocket:
port: 80
readinessProbe:
periodSeconds: 5
httpGet:
path: /ready
port: 80
StartupProbe 使用了 Shell 方式,使用 cat 命令检查 Nginx 存在磁盘上的进程号文件(/var/run/nginx.pid),如果存在就认为是启动成功,它的执行频率是每秒探测一次。
LivenessProbe 使用了 TCP Socket 方式,尝试连接 Nginx 的 80 端口,每 10 秒探测一次。
ReadinessProbe 使用的是HTTP GET方式,访问容器的 /ready 路径,每 5 秒发一次请求。
现在我们用 kubectl apply 创建这个 Pod,然后查看它的状态:

当然,因为这个 Nginx 应用非常简单,它启动后探针的检查都会是正常的,你可以用 kubectl logs 来查看 Nginx 的访问日志,里面会记录 HTTP GET 探针的执行情况:
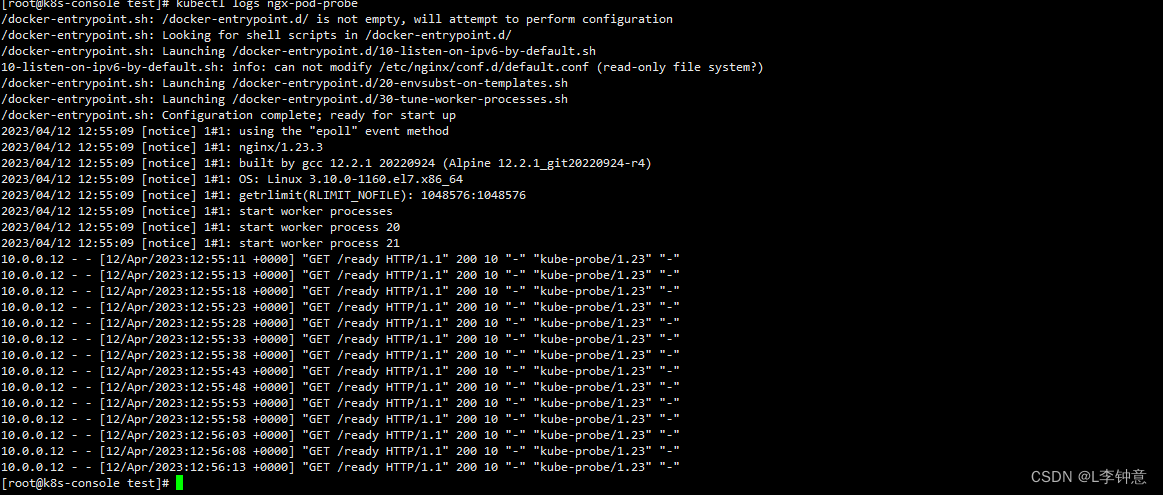 从截图中你可以看到,Kubernetes 正是以大约 5 秒一次的频率,向 URI /ready 发送 HTTP 请求,不断地检查容器是否处于就绪状态。
从截图中你可以看到,Kubernetes 正是以大约 5 秒一次的频率,向 URI /ready 发送 HTTP 请求,不断地检查容器是否处于就绪状态。
为了验证另两个探针的工作情况,我们可以修改探针,比如把命令改成检查错误的文件、错误的端口号:
startupProbe:
exec:
command: ["cat", "nginx.pid"] #错误的文件
livenessProbe:
tcpSocket:
port: 8080 #错误的端口号
当 StartupProbe 探测失败的时候,Kubernetes 就会不停地重启容器,现象就是 RESTARTS 次数不停地增加,而 livenessProbe和 readinessProbePod 没有执行,Pod 虽然是 Running 状态,也永远不会 READY:
[root@k8s-console test]# kubectl get pod|grep -Ei "status|probe"
NAME READY STATUS RESTARTS AGE
ngx-pod-probe 0/1 Running 24 (38s ago) 36s
[root@k8s-console test]# vim ngx-pod.yaml
因为 failureThreshold 的次数默认是三次,所以 Kubernetes 会连续执行三次 livenessProbe TCP Socket 探测,每次间隔 10 秒,30 秒之后都失败才重启容器:

我们把启动探针改为正确的,存活探针依然是错的在看看效果:

因为 failureThreshold 的次数默认是三次,所以 Kubernetes 会连续执行三次 livenessProbe TCP Socket 探测,每次间隔 10 秒,30 秒之后都失败才重启容器:
总结
今天我们学习了两种为 Pod 配置运行保障的方式:Resources 和 Probe。Resources 就是为容器加上资源限制,而 Probe 就是主动健康检查,让 Kubernetes 实时地监控应用的运行状态。
- 资源配额使用的是 cgroup 技术,可以限制容器使用的 CPU 和内存数量,让 Pod 合理利用系统资源,也能够让 Kubernetes 更容易调度 Pod。
- Kubernetes 定义了 Startup、Liveness、Readiness 三种健康探针,它们分别探测应用的启动、存活和就绪状态。
- 探测状态可以使用 Shell、TCP Socket、HTTP Get 三种方式,还可以调整探测的频率和超时时间等参数。















 1186
1186











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









