







目录
广义表存储结构构思:
通过上节广义表的定义 , 我相信大家对广义表有了大致的了解 , 广义表可以有多层嵌套 ,灵活多变 , 纵观四种表示方式 ,我们认为图解最直观 .
所以我们接下来的操作 ,就是在图的基础上来进行操作的.
广义表的相关操作分析,进而对图示进行改进:
数据操作:
(1) CreatGL(s): 创建广义表
(2) GLLength(L): 求广义表长度;
(3) GLDepth(L): 求广义表深度;
(4) DisGL(L): 输出广义表L;
(5) Head(L): 求表头
(6) Tail(L): 求表尾
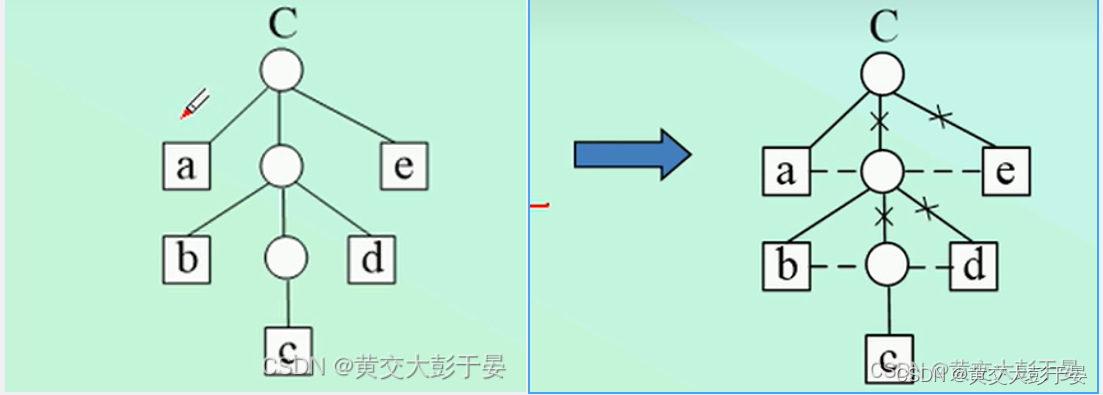
通过观察左图 ,纵然直观 ,可以看出从 节点C出发,进行分叉 , 但是结合具体操作 ,我们会发现 ,有多出口 , 多入口 , 造成程序运行的多变性 , 不利于机器语言的模式化设计 , 多出口 ,给语言设计带来不确定性 , 检索困难 .
改进方案 :
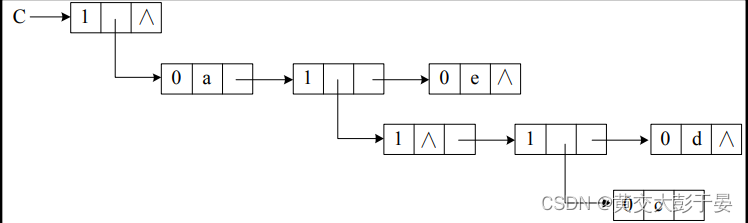
所以我们要在直观的基础上 ,对广义表图示存储结构进行一些牺牲 , 根据广义表的定义 , 广义表是有先后顺序的 ,所以我们每一层都只保存一个出口 ,让每一层的第一个节点(也称表头节点 )当作链接入口节点 , 其他的同一层的节点 ,称作其的兄弟,如右图 :
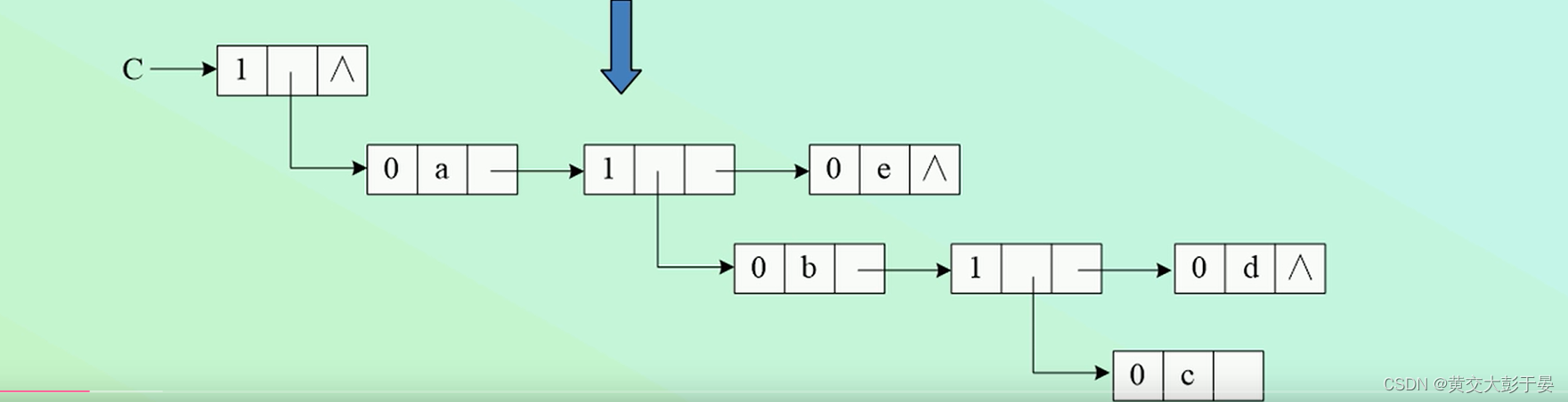
所以我们就形成了 ,逻辑上的多层链表结构 ,如下图:
广义表节点的定义:
通过观察上面的广义表结构 , 广义表在同一层级的数据元素包括 单个数据元素(原子) 和 广义表的子表
所以我们需要对这两种类型的节点进行定义
我们可以为这两种节点设置类型标识 :
1 ---子表 , 0----原子
因为 原子和广义表子表的存储的数据也不一样 , 原子存放的是 数据data, 广义表子表节点存放的是指向下一个元素的指针数据
typedef struct lnode { int tag; //节点类型标识🤣: 1-1子表,0-原子 union { ElemType data; //子表指向下一级的数据节点 struct lnode *sublist; }val; //同级指向 struct lnode *link; //指向下一个元素 }GLNode;

广义表链式存储实例:
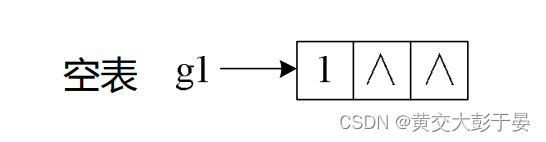
当广义表是空表的时候 ,即 :()
即, 传入的广义表的数据区为空 ,即为空表
当广义表为非空表时 , 头结点的数据区指向 下一层节点


每一层级的节点(原子或子表) ,构成单链表 , 各级之间的联系 ,只通过每一级的表头节点和上一级联系 ,其余同级节点互相成为兄弟 .
节点的数据类型区分:
根据数据节点的标识 , 具体进行对应的数据区赋值

求广义表的长度
● 原理:
• 在广义表中 ,同一层次的每个节点是通过link 域链接起来的 ,所以可把它看作是由 link域链接起来的单链表
● 算法:
• 求广义表的长度 就是第一层单链表的长度 ,求单链表长度得到广义表长度
● 代码演示:
//传入广义表 int GLLength(GLNode *g) { int n = 0; //g指向第一层,然后遍历即可 g = g->val.sublist; //注意分别数据节点链接(sublist标识不同级的表, link链接的是同一级的表) while(g!=NULL) { n++; g = g->link; } //返回数量即可 return n; }
求广义表的深度:
● 原理:
• 对于带头结点的广义表 g , 其深度等于所有子表中的最大深度加一 ; 若g 为原子 ,其深度为0 ; g 为空表 ,其深度为 1.
● 广义表深度 f(g) 的递归定义
• 原子 : 没有深度 ,不带括号
• 空表 : 有一个括号 ,所以深度为1
• 对于有子表的广义表 , 其自身最外层的括号算一层, 然后其子表的深度也算 ,所以加起来就是如上图:
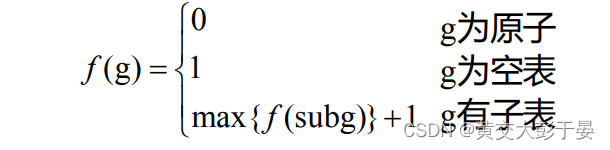
代码分析:
对于递归求深度 , 我们只需要把同一层级的原子和子表元素遍历 , 比较出深度最大的节点 ,然后返回 max+1 即可
当 传入的广义表的第一个元素的表示是 0 时, 代表传入的是一个原子 ,返回 深度为 0 即可
if(g->tag == 0) { return 0; }否则 ,传入的就是一个广义表,让其指向下一层级的节点 , 继续求下一层级的元素的深度 (此时, 我们刚把广义表的头结点指向了下一层级, 所以下一层级的节点的最大深度 ,再加上1 ,返回就是我们所需要的最大深度了)
g = g->val.sublist;如果, 下一个节点是空 ,则代表此广义表是空表 ,返回 1
if(g == NULL) { return 1; }如果不为空的话 ,
我们就接着判断此级的节点类型 , 此时我们注意到 ,我们的深度是在此层级的基础上加一
while(g != NULL) { if(g->tag == 1) { dep = GLDepth(g); if(dep > max) { max = dep; } g = g->link; } return (max+1); }
如果此节点是子表 ,我们就接着求此节点的深度 , 然后就和本层次的 max 对比, 然后比较出最大深度 ,存储在 max中 ,
那如何求此子表的深度呢 ? 难道我们要再重新构造一个求深度的函数吗? 不用的, 调用自身 ,我们就可以返回此节点的深度了 , 难道我们此时构造的函数 ,不是求广义表的深度的吗?
我们就让
dep = GLDepth(g);
比较出此子表中的最大深度 ,返回到此层级即可 .
然后我们再拿其深度和 同一级别的其他 节点深度对比即可 ,最后返回 max + 1
注意 : 我们返回的是广义表的头结点指向的第一层级 的节点的最大深度 ,然后再在其基础 max 上 ,加一
至于递归 ,我们依然是求同一层次的最大深度 ,然后返回的时候 max+1 ,意思是带上子表头结点的深度
完整代码如下:
int GLDepth(GLNode *g) { int max = 0,dep; if(g->tag == 0) { return 0; } g = g->val.sublist; if(g == NULL) { return 1; } while(g!=NULL) { if(g->tag == 1) { dep = GLDepth(g); if(dep>max) { max = dep; } } //接着遍历同级的下一个节点 g = g->link; } return (max+1); }
输出广义表
● 方案
• 对子表递归式输出
当我们遇见一个广义表 ,我们首先要输出的是他们这一级的同级元素
同级元素的构成:
• 原子
• 子表
遇到各个类型的元素的处理方式:
• 遇到原子 ,我们直接输出即可
• 遇到子表 ,就相当于 ,我们现在又遇到了子表 ,我们就需要把此子表当成广义表了,先判断其是否为空 ,为空 ,直接在本层处理 , 不为空 ,我们就直接调用自身 ,把自身当作广义表输出

开始代码实操 :
首先传入广义表:
void DispGL(GLNode *g){传入广义表 ,第一步 , 如果此广义表是 NULL ,(意思就是什么也没有 )
if(g != NULL) {
注意 :空表 和 广义表是空 ,不是一个概念 ,
空表 : 表内无元素 ,但其起码是一个表 ,还有一对括号 ,例如 :
" ( )"
表是空 : 传入的是一个寂寞 ,是 NULL
不为空 ,我们就接着处理, 我们先判断此表的头结点是哪种类型的数据 ,是原子还是子表?
(因为我们传入了一个广义表 ,不代表此表就自带括号,我们要判断头节点的类型的,是子表接着往下处理 ,是原子就输出 , 传入的是寂寞, 我们就跳过 )
判断类型
if(g->tag == 0) { printf("%c",g->val.data); }如果此时传入的所谓的广义表是一个原子,那我们就把他直接输出就可以了 , 然后接着判断此原子后面是否有数据节点
● 那如果 , 我们处理的广义表 ,不为空 ,并且传入的广义表是一个带着括号的子表呢?
如果我们传入的是一个有深度的表 ,我们就判断其下一级的表内元素是否为空 ,为空则输出一个括号加代表空的字符
"( # )"
● 如果此子表内有元素 ,我们就接着传入其 g -> val.sublist 表指向的下一级数据节点 ,然后进行处理, 重复调用自身 , (注意我们进入调用此子表时 , 在调用之前 ,需要把此子表用括号括住,代表此处是一个子表的输出)
我们接着上面代码加上:
//先处理g 的元素 if(g->tag == 0) { printf("%c",g->val.data); } else { printf("("); if(g->val.sublist == NULL) { printf("#"); } else { DispGL(g->val.sublist); } printf(")"); }上面 ,我们已经处理完同一级别的 一个元素了 ,我们还要处理同一级别的兄弟节点
我们就先判断其是否有兄弟 ,然后再把其兄弟当作一个广义表 ,调用自身即可:
//再处理g的兄弟 if(g->link != NULL) { printf(","); DispGL(g->link); }上面的完整代码如下:
void DispGL(GLNode *g) { if(g!=NULL) { //先处理g 的元素 if(g->tag == 0) { printf("%c",g->val.data); } else { printf("("); if(g->val.sublist == NULL) { printf("#"); } else { DispGL(g->val.sublist); } printf(")"); } //再处理g的兄弟 if(g->link != NULL) { printf(","); DispGL(g->link); } } }

建立广义表的链式存储结构:
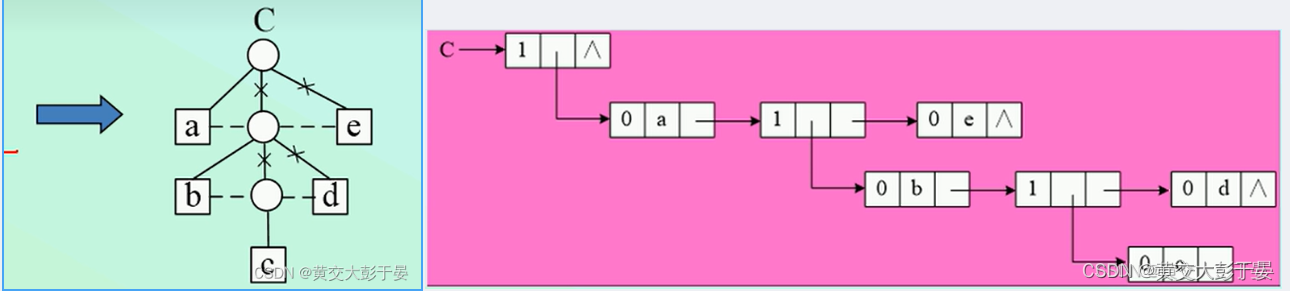
建立广义表之前 , 我们已经根据图示 , 模拟出了我们想要的表 ,并且从我们模拟出的表中 , 设计输出表 ,求表深度,表长度的成员方法 , 我们根据需求 , 设计我们所需要的表
我们就是要构造像右图所示的表 ,
我们现在开始构思:
● 输入 :
• 由括号表示的 s 的广义表
• 原子值为字符
• 空表为 #
● 返回 :
• 指向链式结构的指针
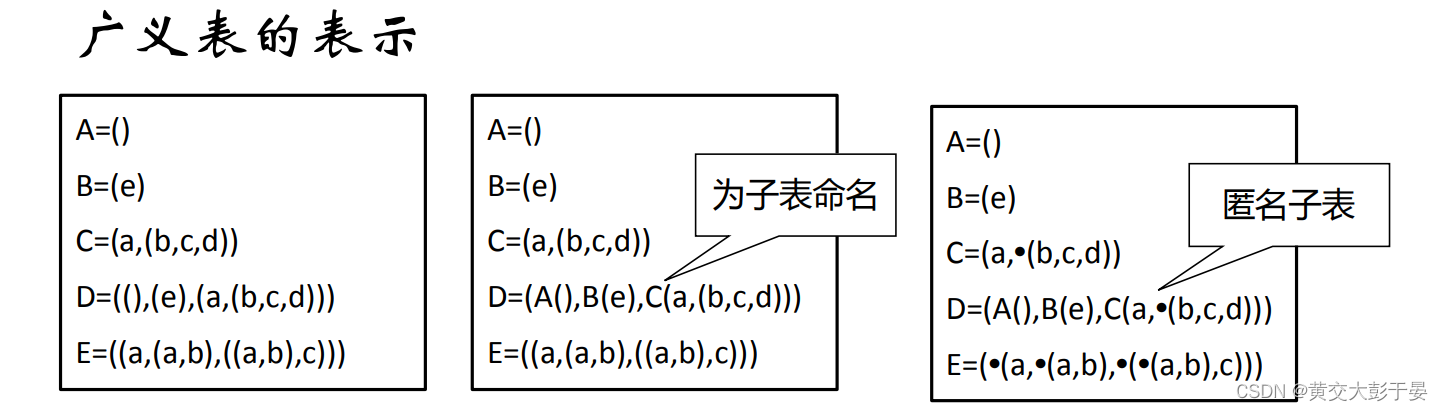
● 输入样式:
• (a , ( b , c , d ) , ( # ))
构造思路:
我们的广义表的同一级数据类型 ,有 原子 和 子表
所以, 我们先处理同一级的元素数据 , 至于遇到子表 , 再把他当成广义表 ,调用自身即可 ,我们先把一级搞定
遇到的转换难题 :当我们传入了一串字符串 , 我们怎样判断其是广义表 , 从哪里开始 , 又从哪里结束呢?
遇到不同字符应该怎样处理呢?
对特殊情况 , 进行分析 :
传入的如果是 空的字符串 ,, 那我们构建的广义表为空 ,直接返回即可 (传入的就是空 , 所以构造的表就是 NULL)
GLNode *CreateGL(char *&s) { GLNode *g; char ch = *s++; if(ch!='\0') { } else { g = NULL; // 传入的是空,所以广义表为空 } return g; }
如果传入的字符串 ,不为空 ,那就代表 ,起码会有一个字符 ,那我们就需要为节点申请空间了
g = (GLNode *)malloc(sizeof(GLNode));
那我们需要判断此时字符串的第一个元素是什么类型的 , 是原子呢 ? 还是子表呢 ?
那怎么判断字符时上面两种类型呢?
通过观察 , 一个广义表的分隔是用括号 ,所以我们每遇到一个 " ( " , 就说明这是新的广义表的开始 , 那 " ( " 后面的元素也就可以当成表头节点了
那 我们刚开始创建的 g , 就是一个广义表了 , 我们需要定义其相关标识
if(ch == '(') { g->tag = 1; g->val.sublist = CreateGL(s); }其中 , g 的下一级的表头节点就是 " ( " 右边的数据 ,
g ->val.sublist = CreateGL(s); ||新节点作为表头节点, 再次调用自身 ,进入下一级的广义表
注意 : 我们刚才判断 "(" 的时候 ,使用的是 char ch = *s++ ;
先判断 ,再累加 , 所以我们传入的" s "是 " ( "的下一个字符 ,

特殊情况汇总 :
( 一 )我们现在已经又调用了自身了 , 那传入的广义表 , 里面的元素如果是 " ) " 呢 ?
就表明 , 广义表里面没有任何东西 ,只有一对括号 :
else if(ch ==')') { g = NULL; }//当我们期待传入的广义表是元素时,可是来了当头一棒,直接识别出是右括号,右括号就是结束,所以刚才创建的空间置空即可 ,节省空间
( 二 ) 当传入的元素是 " # " 的时候 , 说明我们传入了一个空表 ,空表就是一个括号 ,传入了深度为 1 的括号 ,我们也让 刚才创建的空间置空即可
else if(ch == '#') { g = NULL; }
( 三 ) 当传入的元素是 原子的时候 , 我们就 把创建的节点 g 的标识置为 0 ,然后数据区赋值 ch 里面存放的字符即可
else { g->tag = 0; || 传入 ch ,而不是 s ,此时 s 已经跳转到下一个字符了,不是需要的字符 g->val.data = ch; }
这时候 ,会有同学疑问 ,为什么剩下的就确定是原子呢 ?
我们会发现 ,我们如果第一次直接遇到原子的话 ,会进行到最后一步 ,
如果 我们发现第一次,遇到的是 " ( " , 我们再调用 CreateGL(s)
那下一级的元素 ,通过上面 " (" , " ) " , " # ", 的验证 , 剩下的 , 第一个广义表 ,第一个出现的必然是 原子了
通过上面的重复调用 ,我们必然会处理完第一个字符 , 接下来 ,我们当然是处理下一个同级的元素了
//继续处理后续字符
ch = *s++;如果 g 不是空 , 说明后面可能还有字符 ,为空我们当然是跳出了
if(g!=NULL) { || 如果后续字符还有逗号的话,说明后续还有同级原子或子表 if(ch == ',') { || 我们接着把后续的字符当作广义表传入即可,调用自身,先处理再说 g->link = CreateGL(s); } else { || 没有的话, 我们将 g 的指向兄弟的后继指针link 置空即可 g->link = NULL; } }我们就这样 ,循环往复的不停指向, 我们把同一级的每个元素都当做广义表 ,进行指向处理 ,我们就可以把此节点 ,链接成我们需要的广义表
最后返回 g
return g;
构建广义表链式存储结构 ,完整代码:
GLNode *CreateGL(char *&s)
{
GLNode *g;
char ch = *s++;
if(ch!='\0')
{
g = (GLNode *)malloc(sizeof(GLNode));
if(ch == '(')
{
g->tag = 1;
g->val.sublist = CreateGL(s);
}
else if(ch ==')')
{
g = NULL; //当我们期待传入的广义表是元素时,可是来了当头一棒,直接识别出是右括号,右括号就是结束,所以传入的表就置空
}
else if(ch == '#')
{
g = NULL;
}
else
{
g->tag = 0;
g->val.data = ch;
}
}
else
{
g = NULL; // 传入的是空,所以广义表为空
}
//继续处理后续字符
ch = *s++;
if(g!=NULL)
{
if(ch == ',')
{
g->link = CreateGL(s);
}
else
{
g->link = NULL;
}
}
return g;
}答疑环节:
1 , 为什么我们递归就可以链接成广义表了呢 ? 我们递归一般不是返回值吗?
( 1 )我们的目的是通过传入的广义表串 ,遍历此字符串 ,然后根据我们构建的模型 ,构建出我们想要的广义表的链式存储结构 , 因为广义表是表中套表的结构 , 所以我们每次遇到新的同级元素 , 我们就需要重新构造一个新表 , 我们自身正在创建的表就是广义表的结构 , 所以我们直接调用自身 , 就可以处理完所有可能的情况 .
( 2 )我们递归调用 , 每次形成的效果 , 就是链接到广义表后的结点 ,递归利用返回值解决问题的话 ,一次只能保存一个数值 ,我们创建的是链表 ,我们是利用递归的机制 ,节省代码的复杂度 , 每次链接到广义表后面的节点 , 就是我们递归所返回的结果 ,也就是利用递归来建立链式存储结构 .















 5534
5534











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









