







记录一下代码随想录中额外题目的图论部分
841.钥匙和房间
有 n 个房间,房间按从 0 到 n - 1 编号。最初,除 0 号房间外的其余所有房间都被锁住。你的目标是进入所有的房间。然而,你不能在没有获得钥匙的时候进入锁住的房间。
当你进入一个房间,你可能会在里面找到一套不同的钥匙,每把钥匙上都有对应的房间号,即表示钥匙可以打开的房间。你可以拿上所有钥匙去解锁其他房间。
给你一个数组 rooms 其中 rooms[i] 是你进入 i 号房间可以获得的钥匙集合。如果能进入 所有 房间返回 true,否则返回 false。
示例 1:
输入:rooms = [[1],[2],[3],[]]
输出:true
解释:
我们从 0 号房间开始,拿到钥匙 1。
之后我们去 1 号房间,拿到钥匙 2。
然后我们去 2 号房间,拿到钥匙 3。
最后我们去了 3 号房间。
由于我们能够进入每个房间,我们返回 true。
示例 2:
输入:rooms = [[1,3],[3,0,1],[2],[0]]
输出:false
解释:我们不能进入 2 号房间。
思路:
1.初次接触图论相关,自己一开始是完全没有思路的。在看到代码随想录里的讲解原图再联想到当初刚学数据结构与算法时在PPT中看到的图,突然间就想起了当初老师讲解图时也是教的DFS和BFS两种遍历方式,不过平时因为几乎没有接触过图所以已经忘掉了相关的思路方法;不过好在之前已经做过了回溯与二叉树相关章节,对于本题的思路基础还是有很大帮助。
2.如果在草稿纸或者在脑海中构思一下本题中的图,以每一个房间为一个结点,每一个房间中拥有的钥匙作为连接结点之间的单向箭头,可以发现在示例2中的房间2是被孤立的结点,没有其他房间能够指向它,所以我们相当于找到了一种满足的条件,即如果出现被孤立的结点那么一定返回false。
3.但实际上排除上述情况之后还有一种情况,以下引用代码随想录中的讲解原图
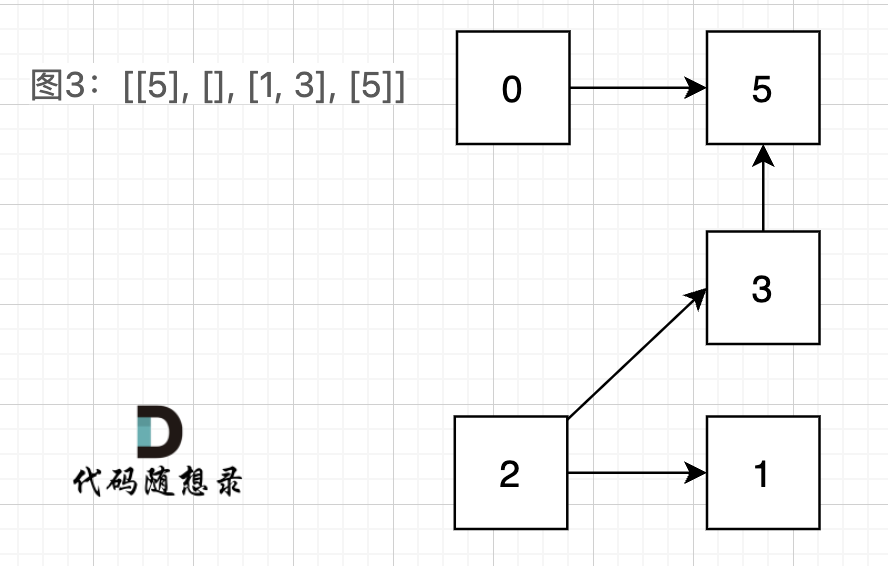
由此图我们可以发现,没有孤立的结点,但是房间5作为中转站,不能使房间0去往房间1、2、3,也不能使得房间1、2、3去往房间0,因此这种情况也是不满足题意的。
4.综合以上思路后,我们选择采取深度优先遍历来解决本题,套用二叉树和回溯算法中相关的模板即可写出如下代码:
class Solution {
public:
void dfs(vector<vector<int>>& rooms, int key, vector<bool>& visited){
//如果当前房屋已访问则返回
if(visited[key]) return;
//如果当前房屋之前未访问,如今访问到后将其设为true,并获得该房间的所有钥匙
visited[key] = true;
vector<int> keys = rooms[key];
for(int key : keys){
dfs(rooms, key, visited);
}
}
bool canVisitAllRooms(vector<vector<int>>& rooms) {
vector<bool> visited(rooms.size(), false);
dfs(rooms, 0, visited);
for(int i = 0; i < visited.size(); i++){
if(visited[i] == false) return false;
}
return true;
}
};启发:
1.本题第一点不容易想明白的地方在于递归的终止条件,到底是处理当前结点时终止还是处理下一个结点时终止?其实都可,只不过不同的思路不同的写法罢了,不过自己因为更习惯于前者。
2.关于图,建议还是在草稿纸上把情况画出来,这样能够更直观地看出问题所在,也方便我们转化问题。
127.单词接龙
字典 wordList 中从单词 beginWord 和 endWord 的 转换序列 是一个按下述规格形成的序列 beginWord -> s1 -> s2 -> ... -> sk:
每一对相邻的单词只差一个字母。
对于 1 <= i <= k 时,每个 si 都在 wordList 中。注意, beginWord 不需要在 wordList 中。
sk == endWord
给你两个单词 beginWord 和 endWord 和一个字典 wordList ,返回 从 beginWord 到 endWord 的 最短转换序列 中的 单词数目 。如果不存在这样的转换序列,返回 0 。
示例 1:
输入:beginWord = "hit", endWord = "cog", wordList = ["hot","dot","dog","lot","log","cog"]
输出:5
解释:一个最短转换序列是 "hit" -> "hot" -> "dot" -> "dog" -> "cog", 返回它的长度 5。
示例 2:
输入:beginWord = "hit", endWord = "cog", wordList = ["hot","dot","dog","lot","log"]
输出:0
解释:endWord "cog" 不在字典中,所以无法进行转换。
思路:
1.本题难度瞬间就上了一个档次。在草稿纸上把大致的图画出来后发现我们要解决的问题主要在于:(1)如何连接图中的两个点,即连线的建立条件是什么;(2)如何找到最短的转换序列。
2.针对问题一,可以发现建立连线的条件是两个字符串之间只有一个字符不同。这一点看上去挺简单,但要在代码中实现还是有一定难度。首先我们需要判定当前字符串是否已经被访问过,因此我们需要一个哈希表来存储当前字符串,又因为我们最后要求最短路径长度,因此采用unordered_map,通过键值对的方式来进行存储,其中键代表字符串,值代表从beginWord到达该字符串的路径长度。
3.针对问题二,实质上就是本题选择的遍历方式。我们纵观DFS和BFS两种方式不难发现,DFS倾向于一条路走到底,走不通后再折返(回溯),适合遍历所有的路径;而BFS是到达一个结点就优先遍历其连接的结点,倾向于找到一种满足条件的情况,因此我们选择采取BFS来解决该题。
class Solution {
public:
int ladderLength(string beginWord, string endWord, vector<string>& wordList) {
unordered_set<string> wordSet(wordList.begin(), wordList.end());//转化为哈希表方便查询
//如果字符集中没找到endWord,直接返回0
if(wordSet.find(endWord) == wordSet.end()) return 0;
unordered_map<string, int> visitMap;//存储字符串及到达该字符串的路径长度的哈希表
queue<string> que;
que.push(beginWord);
visitMap.insert(pair<string, int>(beginWord, 1));
//开始广度遍历
while(!que.empty()){
string word = que.front();
que.pop();
int path = visitMap[word];//记录当前路径的长度
for(int i = 0; i < word.size(); i++){
//用一个临时变量来代表改变单个字符后的新字符串,随后开始挨个替换当前字符串中的单个字符
string newWord = word;
for(int j = 0; j < 26; j++){
newWord[i] = j + 'a';
//如果新字符串恰好就是endWord,返回当前路径长度+1
if(newWord == endWord) return path + 1;
//如果当前字符串出现在了原字符集中,并且仍未访问过该字符串,那么将其记录进入哈希表中
if(wordSet.find(newWord) != wordSet.end() && visitMap.find(newWord) == visitMap.end()){
visitMap.insert(pair<string, int>(newWord, path + 1));
que.push(newWord);
}
}
}
}
//如果遍历完都没找到,那么就返回0
return 0;
}
};启发:
1.本题的细节性问题实际上还是很多的,如一开始就将题目所给的wordList用unordered_set转化,方便我们后续进行查询(因为字符串相当于还是数组,用数组查询就必然要用到遍历,代码会更加冗杂)。
2.其次,在实际进行广度遍历的代码中,我们并不是遍历原字符串数组中的每一个字符串并与当前字符串挨个比较字符,满足只有一个字符不同的情况下才将其加入队列和记录进入哈希表中,这种情况光是口述就可以想象得出极其复杂。
我们选择的是换一种思路,直接用一个临时变量复制当前字符串,然后依次遍历临时变量中的每个字符并且用所有小写字母替换一遍单个字符,如果当前字符替换后的新字符能够在集合中找到,并且在哈希表中没有存储过(即没有到达过),那么我们就将该新字符加入队列并且记录进入哈希表。这种想法非常巧妙,避免了我们实际去遍历比较每个字符串在单个字符不同的情况下还要在原字符集里面。
3.本题虽然理论上来说DFS也能做,但DFS会比较复杂,而BFS正契合本题的情况,因为BFS一旦找到当前结点就一定是最短长度。















 776
776

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









