







简介
贪心算法(英语:greedy algorithm),是用计算机来模拟一个“贪心”的人做出决策的过程。这个人十分贪婪,每一步行动总是按某种指标选取最优的操作。而且他目光短浅,总是只看眼前,并不考虑以后可能造成的影响。
可想而知,并不是所有的时候贪心法都能获得最优解,所以一般使用贪心法的时候,都要确保自己能证明其正确性。
详细介绍
适用范围
贪心算法在有最优子结构的问题中尤为有效。最优子结构的意思是问题能够分解成子问题来解决,子问题的最优解能递推到最终问题的最优解。
证明方法
贪心算法有两种证明方法:反证法和归纳法。一般情况下,一道题只会用到其中的一种方法来证明。
- 反证法:如果交换方案中任意两个元素/相邻的两个元素后,答案不会变得更好,那么可以推定目前的解已经是最优解了。
- 归纳法:先算得出边界情况(例如 )的最优解 ,然后再证明:对于每个 , 都可以由 推导出结果。
要点
常见题型
在提高组难度以下的题目中,最常见的贪心有两种。
- 「我们将 XXX 按照某某顺序排序,然后按某种顺序(例如从小到大)选择。」。
- 「我们每次都取 XXX 中最大/小的东西,并更新 XXX。」(有时「XXX 中最大/小的东西」可以优化,比如用优先队列维护)
二者的区别在于一种是离线的,先处理后选择;一种是在线的,边处理边选择。
排序解法
用排序法常见的情况是输入一个包含几个(一般一到两个)权值的数组,通过排序然后遍历模拟计算的方法求出最优值。
后悔解法
思路是无论当前的选项是否最优都接受,然后进行比较,如果选择之后不是最优了,则反悔,舍弃掉这个选项;否则,正式接受。如此往复。
区别
与动态规划的区别
贪心算法与动态规划的不同在于它对每个子问题的解决方案都做出选择,不能回退。动态规划则会保存以前的运算结果,并根据以前的结果对当前进行选择,有回退功能。
后悔法例题详解
约翰的工作日从0 时刻开始,有 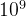 个单位时间。在任一单位时间,他都可以选择编号 1到N的N项工作中的任意一项工作来完成。工作i的截止时间是 Di,完成后获利是Pi 。在给定的工作利润和截止时间下,求约翰能够获得的利润最大为多少。
个单位时间。在任一单位时间,他都可以选择编号 1到N的N项工作中的任意一项工作来完成。工作i的截止时间是 Di,完成后获利是Pi 。在给定的工作利润和截止时间下,求约翰能够获得的利润最大为多少。
- 先假设每一项工作都做,将各项工作按截止时间排序后入队;
- 在判断第 i 项工作做与不做时,若其截至时间符合条件,则将其与队中报酬最小的元素比较,若第 i 项工作报酬较高(后悔),则
ans += a[i].p - q.top()。 用优先队列(小根堆)来维护队首元素最小。
#include <algorithm>
#include <cmath>
#include <cstdio>
#include <cstring>
#include <iostream>
#include <queue>
using namespace std;
struct f {
long long d;
long long x;
} a[100005];
bool cmp(f A, f B) { return A.d < B.d; }
priority_queue<long long, vector<long long>, greater<long long> >
q; // 小根堆维护最小值
int main() {
long long n, i, j;
cin >> n;
for (i = 1; i <= n; i++) {
cin >> a[i].d >> a[i].x;
}
sort(a + 1, a + n + 1, cmp);
long long ans = 0;
for (i = 1; i <= n; i++) {
if (a[i].d <= q.size()) { // 超过截止时间
if (q.top() < a[i].x) { // 后悔
ans += a[i].x - q.top();
q.pop();
q.push(a[i].x);
}
} else { // 直接加入队列
ans += a[i].x;
q.push(a[i].x);
}
}
cout << ans << endl;
return 0;
}















 1380
1380











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











