







目录
背景
元数据服务可扩展性是大规模分布式存储系统的瓶颈,即单个实例相对的元数据处理能力有限,所以很多公司数据中心都使用了多个集群(实例)来实现。例如:
- 阿里云维护了近数千个盘古分布式文件系统,以共同支持数据中心中多达数百亿个文件。
- 由于每个HDFS集群最多支持1亿个文件,Facebook需要许多HDFS集群将数据集存储在一个数据中心。
然而,跨越整个数据中心的大型文件系统更为理想,每个数据中心一个大型文件系统在以下方面优于小型文件系统集群:
(1)全局数据共享: 全局的namespace,使数据中心能够更好地共享数据。 对比:专门的数据放置策略,数据迁移策略,因为需要进行数据的切分,计算服务逻辑也变复杂。
(2)高资源利用: 消除多个集群的重复数据,提升磁盘空间利用,实现更好的资源共享。 对比:单个集群的空闲资源没法释放给其他集群。
(3)操作复杂度低: 只需要维护一个系统 对比:维护多个系统必然是劳动密集型的,而且出错概率高。
实际工作负载的特点
为了了解超大规模分布式文件系统的特性,作者从最大的云提供商之一阿里云追踪生产部署中的元数据操作。从支持不同服务的三个Pangu文件系统实例中捕获工作负载:数据处理和分析服务、对象存储服务和块存储服务。其中合并了这些不同服务的工作负载,以表示跨整个数据中心的大型文件系统的工作负载。

观察到:
文件操作占所有操作的约95.8%;
目录readdir是最频繁的目录操作,占所有目录操作的约93.3%;
目录rename和目录set_permission操作很少发生,仅占所有元数据操作的约0.0083%。
三个挑战
现代数据中心元数据量很大, 数以百亿甚至数千亿的文件,用一个大规模的文件系统来管理所有的文件元数据就会遇到挑战。
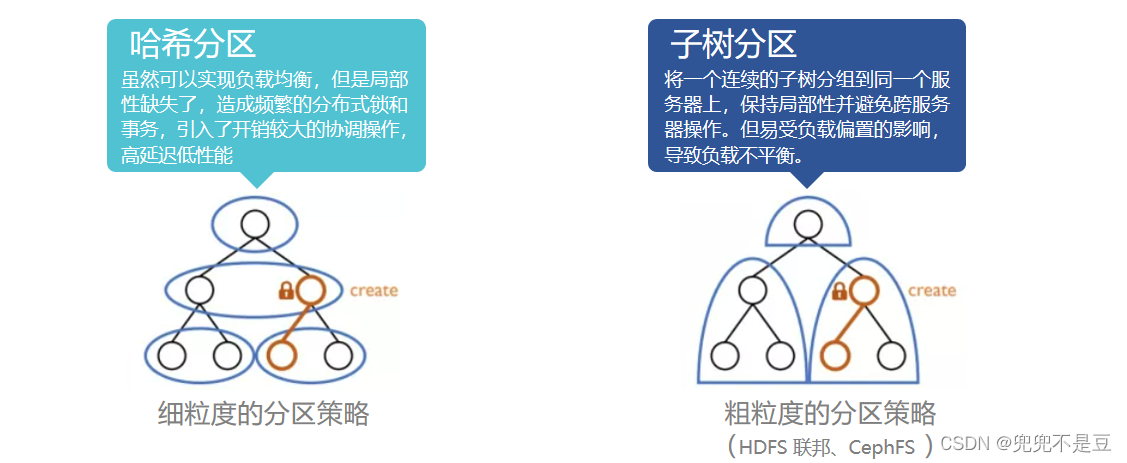
- 目录树分区:由于目录树的扩展和工作负载的多样性,目录树分区在实现高元数据局部性和良好的负载均衡方面具有挑战性。
- 路径解析:路径解析的延迟可能很高,因为在极其大规模的文件系统中,文件深度很深。
- 元数据缓存:客户端元数据缓存一致性维护开销变得巨大,因为非常大规模的文件系统通常需要为大量并发客户端提供服务。
总体解决方案
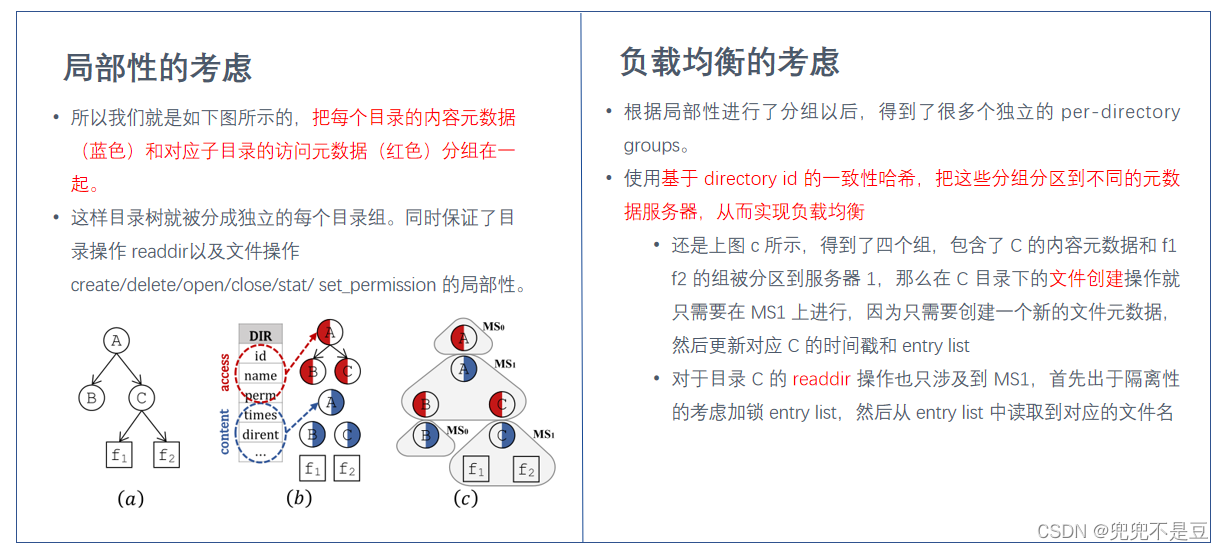
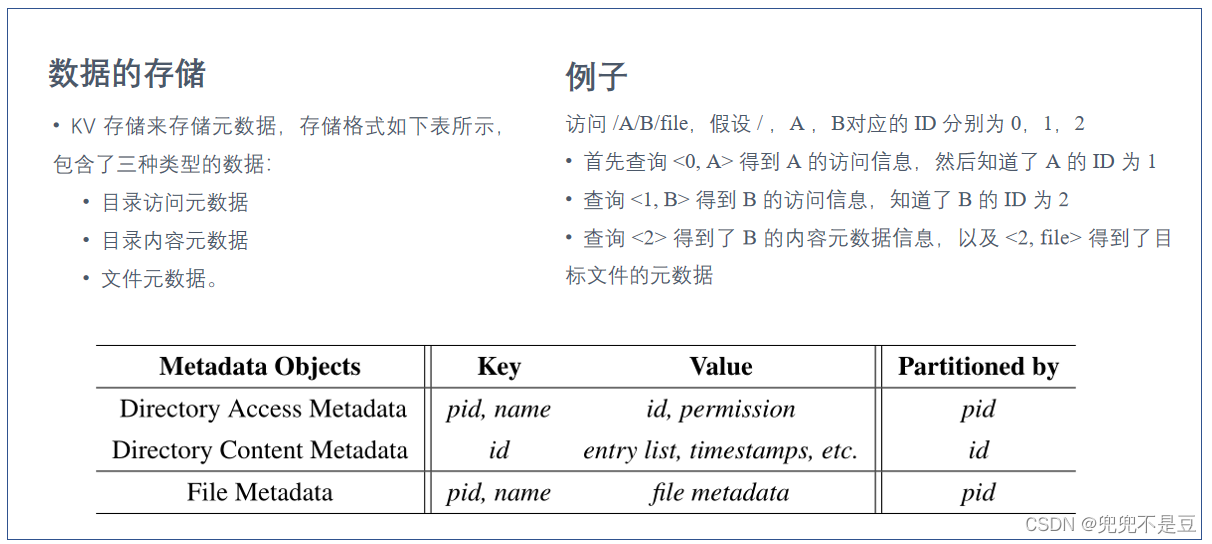
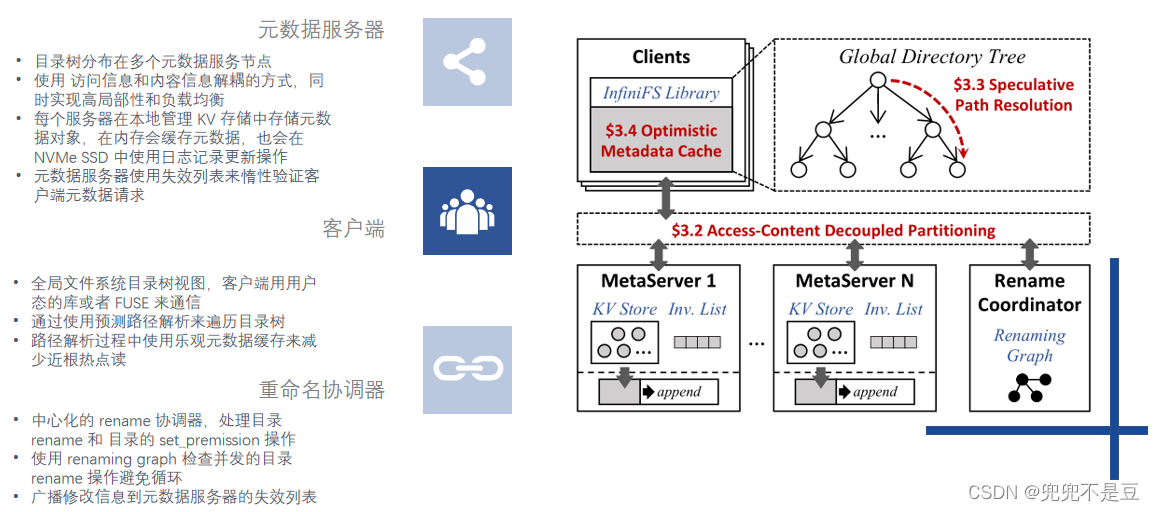
(1)元数据分区:访问数据和内容数据解耦的元数据分区方法,来兼顾局部性和负载均衡。
访问信息 name, ID, and permissions,
内容信息 entry list and timestamps;
细粒度分区:
内部分区(高局部性) 访问元数据和其父目录分区在一起 内容元数据和孩子节点数据分布在一起。
细粒度分组使用对于 directory id 的一致性哈希来分布(负载均衡)。
(2)推测路径解析:预测路径解析来并行遍历目录树,减小了元数据操作的延迟。
每个目录分配一个 predictable id,客户端可以通过计算预测出中间目录的 ID;
多个组件的路径执行并行查询。
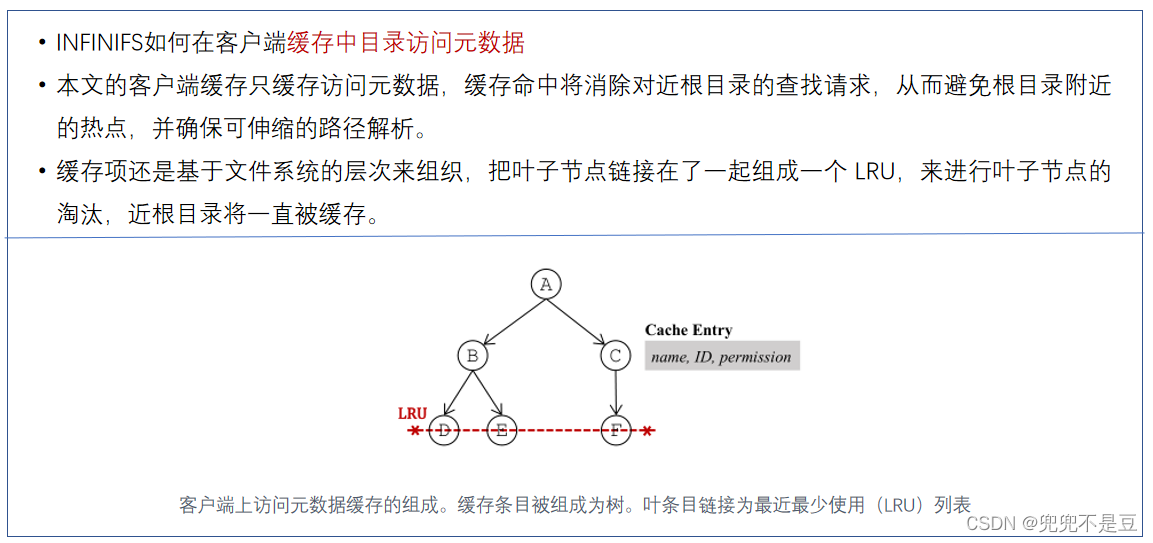
(3)乐观访问元数据缓存:乐观访问元数据缓存来缓解近根节点的热点问题,实现可扩展的路径解析。
客户端缓存目录的访问元数据信息,来吸收近根节点的查询压力。
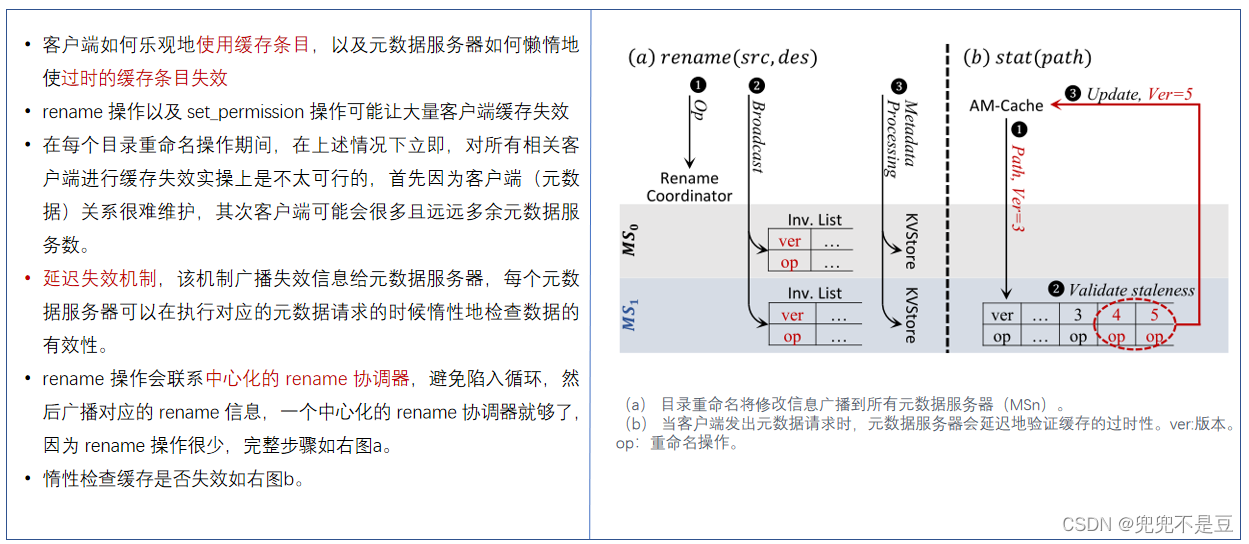
低开销的惰性缓存失效策略:
即针对访问元数据信息的修改操作,将发送一个失效通知给元数据服务器,而不是通知客户端,
每个服务器可以在处理客户端请求的时候验证对应的缓存的状态(惰性)。
挑战1:
局部性和负载均衡
- 局部性:文件系统操作经常都需要同时处理多个元数据对象。分布式文件系统中有了局部性,就可以避免分布式锁和分布式事务,从而实现低延迟和高吞吐。例如 文件创建操作首先加锁父目录,然后原子更新三个元数据对象(目录的 entry list,新建的文件元数据,目录时间戳)。
- 负载均衡:目录树中的元数据操作通常导致不均衡。 真实的数据中心负载经常把相关文件分组到一个子树,连续子树中的文件和目录可能在短时间内被大量访问,导致存储该子树的元数据服务器出现性能瓶颈。
目录树分区方案
现有分区方案很难兼顾两个特性。管理数据中心中的所有文件可以使目录树在深度和广度上迅速扩展。而且文件系统面对的负载特征经常变化。
解决思路
挑战2:
路径解析延迟
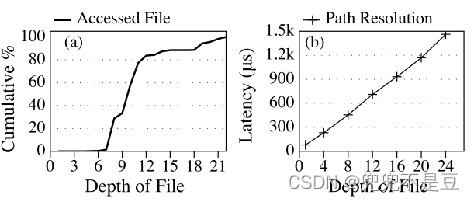
作者发现当将所有服务整合到一个文件系统中时,文件的深度会迅速增加。
- 路径解析的延迟可能很高,因为在极其大规模的文件系统中,文件深度非常深;
- 超过一半的访问对应的深度大于了 10;
- 基于 Tectonic(Facebook's tectonic filesystem: Efficiency from exascale)的机制实现了原生的路径解析,发现随着深度增加,延迟也几乎线性增加。Tectonic 将目录分区到不同元数据服务器,基于对应的目录 ID,解析深度为 N 的路径需要解析 N−1 个中间目录,从而导致 N−1 个顺序的网络请求。
相关研究
所有目录元数据存储在单个元数据服务器上,以减少路径解析的延迟,但是,它存在单节点瓶颈。 一些分布式文件系统使用对完整路径名的哈希来索引文件,然而,它们使层次结构的语义难以实现。例如,目录重命名(rename)操作的成本非常高,因为它改变了所有后代的完整路径名,导致所有后代的元数据必须迁移到新的位置。
因此,InfiniFS设计了一种推断式的路径解析机制实现目录树的并行遍历,可以缩短元数据访问延迟。
解决思路


挑战3:
客户端元数据缓存
路径解析需要从根遍历目录树,并依次检查路径中所有中间目录的权限。这将导致大量读取接近根目录,即使是为了平衡元数据操作工作负载。文件系统的吞吐量将受到存储近根目录的服务器的限制。在本文中,称之为近根热点。许多分布式文件系统依赖于客户端元数据缓存来缓解接近根的热点。
发现,以前的客户端缓存机制在大量客户端的大规模场景中不能很好地工作。 例如,
- 基于租约的机制为每个在固定期限后将过期的缓存条目授予租约。当租期到期时,相应的缓存条目将自动失效。
- 然而,由于近根目录的缓存更新,租约机制存在负载失衡的问题。
- 这是因为所有客户端都必须反复更新它们的近根目录的缓存条目,以进行路径解析。随着客户端数量的增加,这种近根目录上的负载不平衡最终将成为性能瓶颈,并削弱总体吞吐量 。
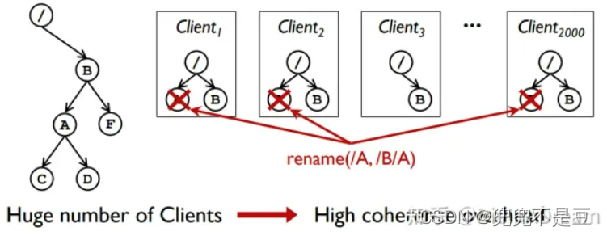
因此,InfiniFS将目录访问元数据缓存在客户端的内存中以缓解近根热点。
解决思路
总体概括
总结
本文介绍了INFINIFS,这是一种用于大规模分布式文件系统的高效元数据服务。 INFINIFS将目录的访问和内容元数据解耦,从而可以在高元数据位置和良好的负载平衡下对目录树进行分区; 然后将路径解析与推测并行化,以显著减少元数据操作的延迟; 最后,乐观地在客户端缓存访问元数据,并延迟失效。
自我思考: 访问内容解耦只能解决父子局部性问题,祖孙依然可能跨服务器所以需要多次网络交互才能解析完整的目录;如果按子目录树分区,至少子孙的修改都在一个服务器上,InfiniFS 只是是在利用元数据的访问的局部性和负载均衡两个指标上做了折衷,不可能做到能解决所有的局部性问题。
下一篇https://blog.csdn.net/qq_58034031/article/details/129624137总结了目前主流分布式文件系统元数据服务管理方式。















 630
630











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









