







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新网络安全全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。






既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上网络安全知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip204888 (备注网络安全)

正文
option.add_experimental_option(“detach”, True)
将option作为参数添加到Chrome中
driver = webdriver.Chrome(chrome_options=option)
这样将上面的代码组合再打开浏览器就不会自动关闭了。
from selenium import webdriver
不自动关闭浏览器
option = webdriver.ChromeOptions()
option.add_experimental_option(“detach”, True)
注意此处添加了chrome_options参数
driver = webdriver.Chrome(chrome_options=option)
driver.get(‘https://www.csdn.net/’)
下面我们再来看看几种常见的页面元素定位方式。
#### id 定位
标签的 `id` 具有唯一性,就像人的身份证,假设有个 `input` 标签如下。
我们可以通过 `id` 定位到它,由于 `id` 的唯一性,我们可以不用管其他的标签的内容。
driver.find_element_by_id(“toolbar-search-input”)
#### name 定位
`name` 指定标签的名称,在页面中可以不唯一。假设有个 `meta` 标签如下
我们可以使用 `find_element_by_name` 定位到 `meta` 标签。
driver.find_element_by_name(“keywords”)
#### class 定位
`class` 指定标签的类名,在页面中可以不唯一。假设有个 `div` 标签如下
我们可以使用 `find_element_by_class_name` 定位到 `div` 标签。
driver.find_element_by_class_name(“toolbar-search-container”)
#### tag 定位
每个 `tag` 往往用来定义一类功能,所以通过 `tag` 来识别某个元素的成功率很低,每个页面一般都用很多相同的 `tag` ,比如:`\<div\>`、`\<input\>` 等。这里还是用上面的 `div` 作为例子。
我们可以使用 `find_element_by_class_name` 定位到 `div` 标签。
driver.find_element_by_tag_name(“div”)
#### xpath 定位
`xpath` 是一种在 `XML` 文档中定位元素的语言,它拥有多种定位方式,下面通过实例我们看一下它的几种使用方式。
根据上面的标签需要定位 最后一行 `input` 标签,以下列出了四种方式,`xpath` 定位的方式多样并不唯一,使用时根据情况进行解析即可。
绝对路径(层级关系)定位
driver.find_element_by_xpath(
“/html/body/div/div/div/div[2]/div/div/input[1]”)
利用元素属性定位
driver.find_element_by_xpath(
“//*[@id=‘toolbar-search-input’]”))
层级+元素属性定位
driver.find_element_by_xpath(
“//div[@id=‘csdn-toolbar’]/div/div/div[2]/div/div/input[1]”)
逻辑运算符定位
driver.find_element_by_xpath(
“//*[@id=‘toolbar-search-input’ and @autocomplete=‘off’]”)
#### css 定位
`CSS` 使用选择器来为页面元素绑定属性,它可以较为灵活的选择控件的任意属性,一般定位速度比 `xpath` 要快,但使用起来略有难度。
`CSS` 选择器常见语法:
| 方法 | 例子 | 描述 |
| --- | --- | --- |
| **.class** | `.toolbar-search-container` | 选择 `class = 'toolbar-search-container'` 的所有元素 |
| **#id** | `#toolbar-search-input` | 选择 `id = 'toolbar-search-input'` 的元素 |
| **\*** | `*` | 选择所有元素 |
| **element** | `input` | 选择所有 `<input\>` 元素 |
| **element>element** | `div>input` | 选择父元素为 `<div\>` 的所有 `<input\>` 元素 |
| **element+element** | `div+input` | 选择同一级中在 `<div\>` 之后的所有 `<input\>` 元素 |
| **[attribute=value]** | `type='text'` | 选择 `type = 'text'` 的所有元素 |
举个简单的例子,同样定位上面实例中的 `input` 标签。
driver.find_element_by_css_selector(‘#toolbar-search-input’)
driver.find_element_by_css_selector(‘html>body>div>div>div>div>div>div>input’)
#### link 定位
`link` 专门用来定位文本链接,假如要定位下面这一标签。
我们使用 `find_element_by_link_text` 并指明标签内全部文本即可定位。
driver.find_element_by_link_text(“加入!每日一练”)
#### partial\_link 定位
`partial_link` 翻译过来就是“部分链接”,对于有些文本很长,这时候就可以只指定部分文本即可定位,同样使用刚才的例子。
我们使用 `find_element_by_partial_link_text` 并指明标签内部分文本进行定位。
driver.find_element_by_partial_link_text(“加入”)
---
### 浏览器控制
#### 修改浏览器窗口大小
`webdriver` 提供 `set_window_size()` 方法来修改浏览器窗口的大小。
from selenium import webdriver
Chrome浏览器
driver = webdriver.Chrome()
driver.get(‘https://www.csdn.net/’)
设置浏览器浏览器的宽高为:600x800
driver.set_window_size(600, 800)
也可以使用 `maximize_window()` 方法可以实现浏览器全屏显示。
from selenium import webdriver
Chrome浏览器
driver = webdriver.Chrome()
driver.get(‘https://www.csdn.net/’)
设置浏览器浏览器的宽高为:600x800
driver.maximize_window()
#### 浏览器前进&后退
`webdriver` 提供 `back` 和 `forward` 方法来实现页面的后退与前进。下面我们 ①进入CSDN首页,②打开CSDN个人主页,③`back` 返回到CSDN首页,④ `forward` 前进到个人主页。
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
访问CSDN首页
driver.get(‘https://www.csdn.net/’)
sleep(2)
#访问CSDN个人主页
driver.get(‘https://blog.csdn.net/qq_43965708’)
sleep(2)
#返回(后退)到CSDN首页
driver.back()
sleep(2)
#前进到个人主页
driver.forward()
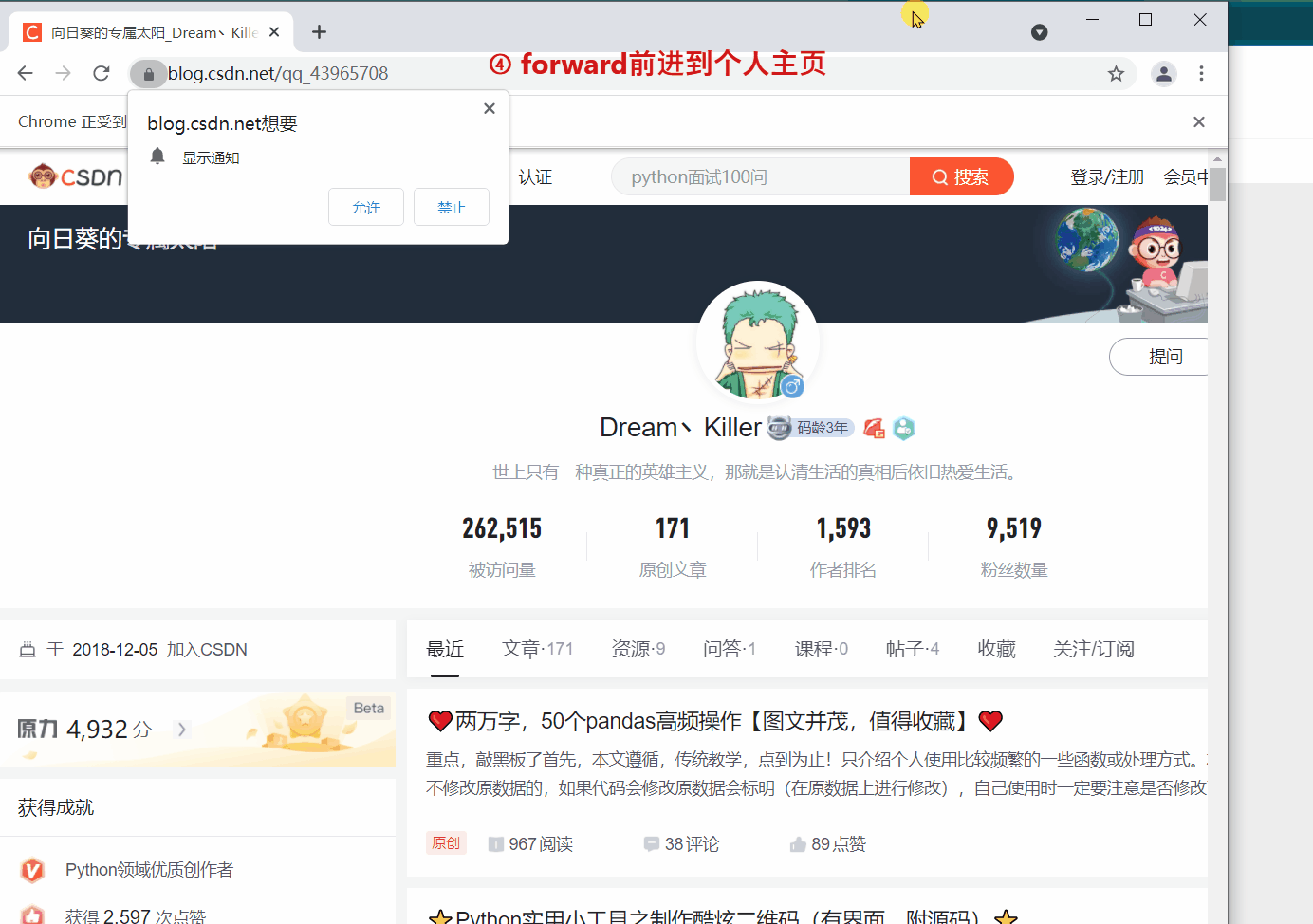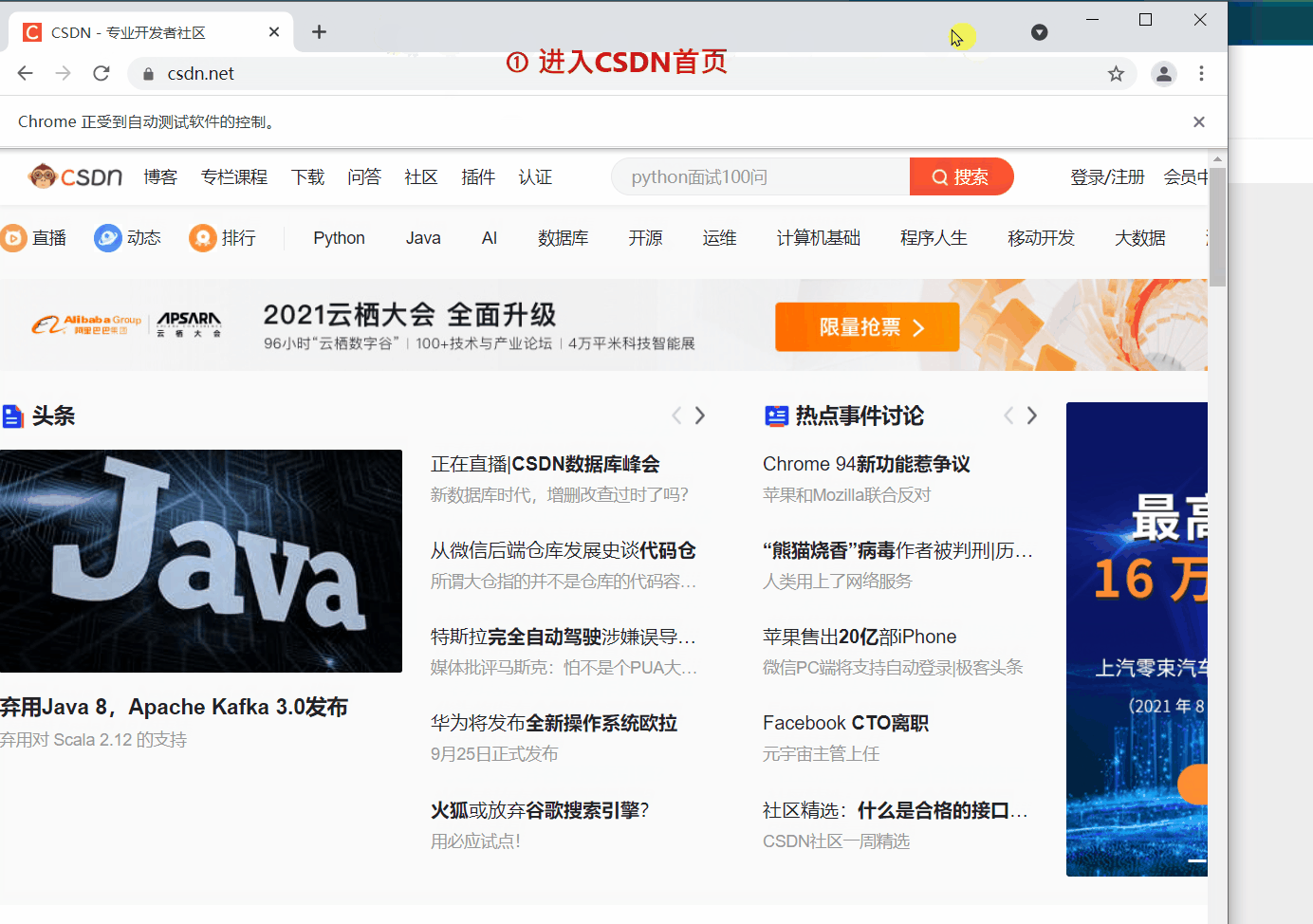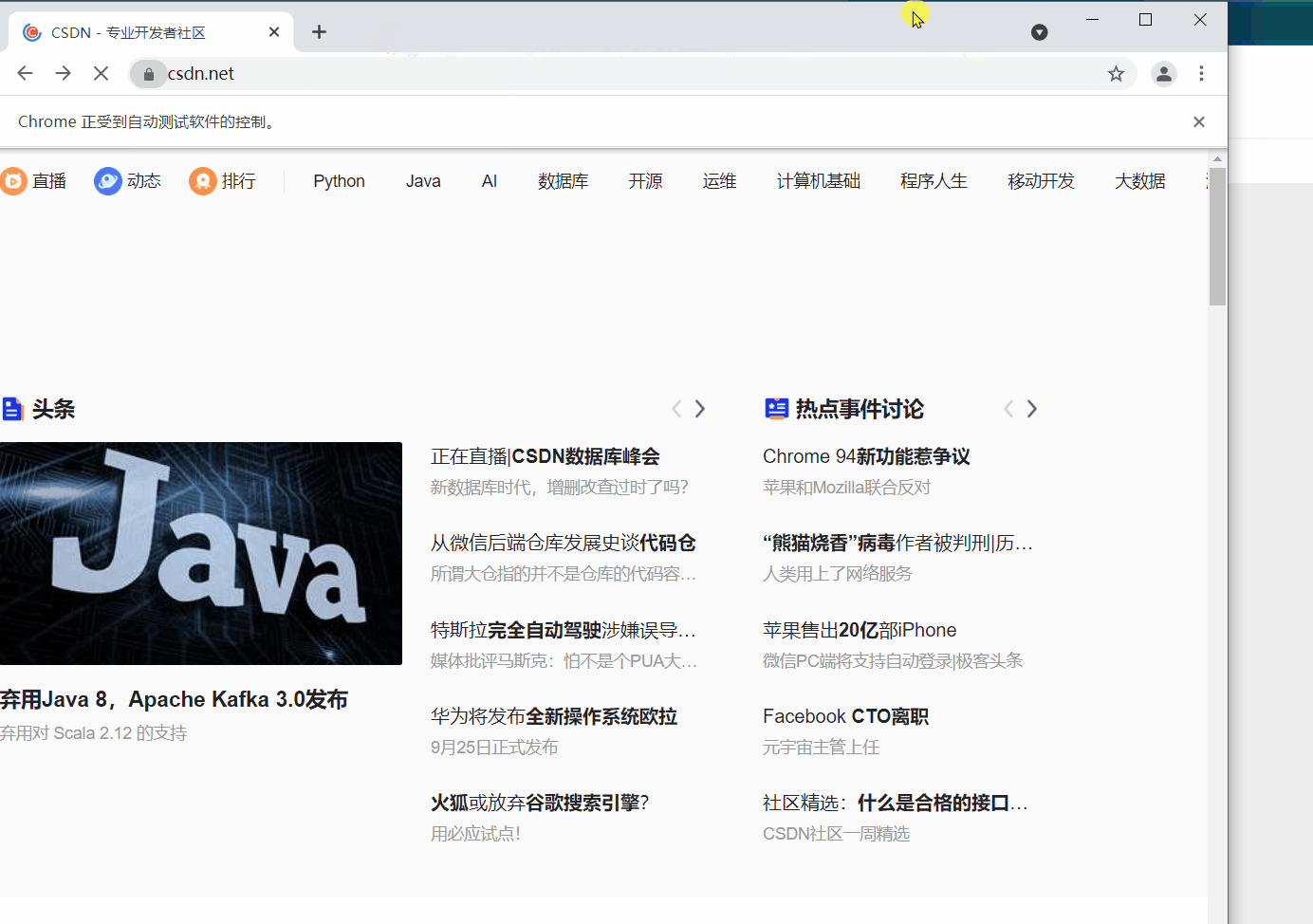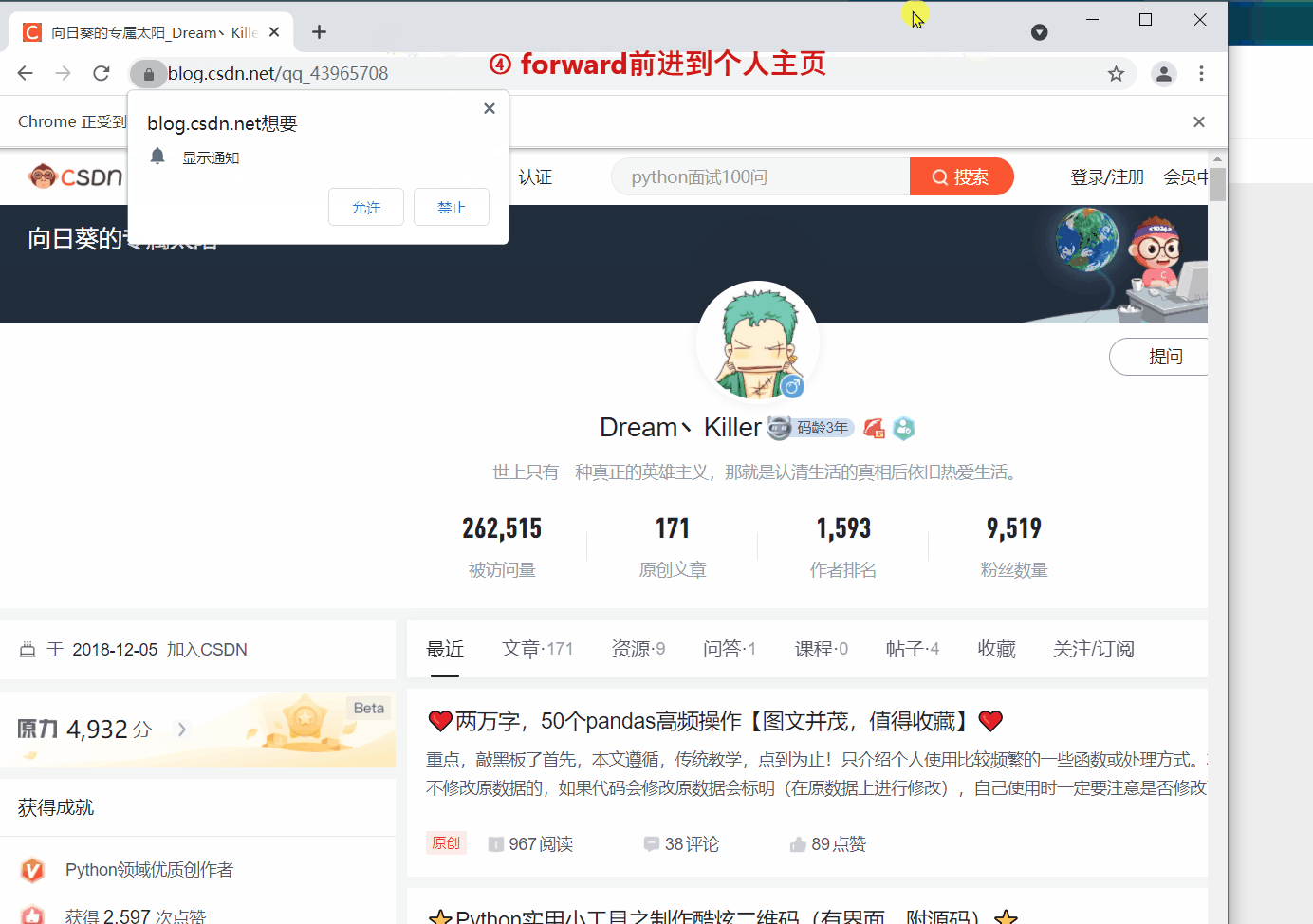
细心的读者会发现第二次 `get()` 打开新页面时,会在原来的页面打开,而不是在新标签中打开。如果想的话也可以在新的标签页中打开新的链接,但需要更改一下代码,执行 `js` 语句来打开新的标签。
在原页面打开
driver.get(‘https://blog.csdn.net/qq_43965708’)
新标签中打开
js = “window.open(‘https://blog.csdn.net/qq_43965708’)”
driver.execute_script(js)
#### 浏览器刷新
在一些特殊情况下我们可能需要刷新页面来获取最新的页面数据,这时我们可以使用 `refresh()` 来刷新当前页面。
刷新页面
driver.refresh()
#### 浏览器窗口切换
在很多时候我们都需要用到窗口切换,比如:当我们点击注册按钮时,它一般会打开一个新的标签页,但实际上代码并没有切换到最新页面中,这时你如果要定位注册页面的标签就会发现定位不到,这时就需要将实际窗口切换到最新打开的那个窗口。我们先获取当前各个窗口的句柄,这些信息的保存顺序是按照**时间**来的,最新打开的窗口放在数组的**末尾**,这时我们就可以定位到最新打开的那个窗口了。
获取打开的多个窗口句柄
windows = driver.window_handles
切换到当前最新打开的窗口
driver.switch_to.window(windows[-1])
#### 常见操作
webdriver中的常见操作有:
| 方法 | 描述 |
| --- | --- |
| `send_keys()` | 模拟输入指定内容 |
| `clear()` | 清除文本内容 |
| `is_displayed()` | 判断该元素是否可见 |
| `get_attribute()` | 获取标签属性值 |
| `size` | 返回元素的尺寸 |
| `text` | 返回元素文本 |
接下来还是用 CSDN 首页为例,需要用到的就是搜素框和搜索按钮。通过下面的例子就可以气息的了解各个操作的用法了。

from selenium import webdriver
driver = webdriver.Chrome()
driver.get(‘https://www.csdn.net/’)
sleep(2)
定位搜索输入框
text_label = driver.find_element_by_xpath(‘//*[@id=“toolbar-search-input”]’)
在搜索框中输入 Dream丶Killer
text_label.send_keys(‘Dream丶Killer’)
sleep(2)
清除搜索框中的内容
text_label.clear()
输出搜索框元素是否可见
print(text_label.is_displayed())
输出placeholder的值
print(text_label.get_attribute(‘placeholder’))
定位搜索按钮
button = driver.find_element_by_xpath(‘//*[@id=“toolbar-search-button”]/span’)
输出按钮的大小
print(button.size)
输出按钮上的文本
print(button.text)
‘’‘输出内容
True
python面试100问
{‘height’: 32, ‘width’: 28}
搜索
‘’’
---
### 鼠标控制
在webdriver 中,鼠标操作都封装在ActionChains类中,常见方法如下:
| 方法 | 描述 |
| --- | --- |
| `click()` | 单击左键 |
| `context_click()` | 单击右键 |
| `double_click()` | 双击 |
| `drag_and_drop()` | 拖动 |
| `move_to_element()` | 鼠标悬停 |
| `perform()` | 执行所有ActionChains中存储的动作 |
#### 单击左键
模拟完成单击鼠标左键的操作,一般点击进入子页面等会用到,左键不需要用到 `ActionChains` 。
定位搜索按钮
button = driver.find_element_by_xpath(‘//*[@id=“toolbar-search-button”]/span’)
执行单击操作
button.click()
#### 单击右键
鼠标右击的操作与左击有很大不同,需要使用 `ActionChains` 。
from selenium.webdriver.common.action_chains import ActionChains
定位搜索按钮
button = driver.find_element_by_xpath(‘//*[@id=“toolbar-search-button”]/span’)
右键搜索按钮
ActionChains(driver).context_click(button).perform()
#### 双击
模拟鼠标双击操作。
定位搜索按钮
button = driver.find_element_by_xpath(‘//*[@id=“toolbar-search-button”]/span’)
执行双击动作
ActionChains(driver).double_click(button).perform()
#### 拖动
模拟鼠标拖动操作,该操作有两个必要参数,
* **source**:鼠标拖动的元素
* **target**:鼠标拖至并释放的目标元素
定位要拖动的元素
source = driver.find_element_by_xpath(‘xxx’)
定位目标元素
target = driver.find_element_by_xpath(‘xxx’)
执行拖动动作
ActionChains(driver).drag_and_drop(source, target).perform()
#### 鼠标悬停
模拟悬停的作用一般是为了显示隐藏的下拉框,比如 CSDN 主页的收藏栏,我们看一下效果。
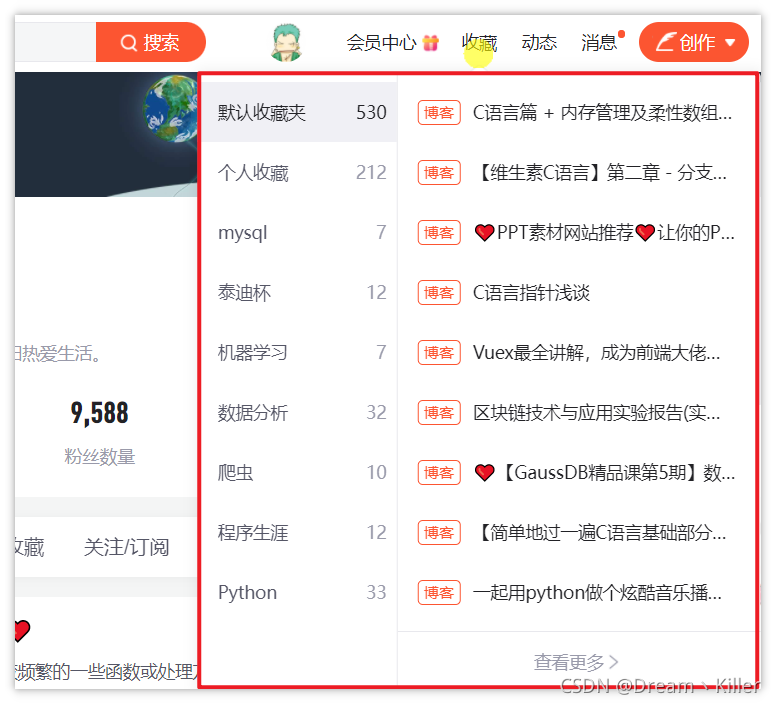
定位收藏栏
collect = driver.find_element_by_xpath(‘//*[@id=“csdn-toolbar”]/div/div/div[3]/div/div[3]/a’)
悬停至收藏标签处
ActionChains(driver).move_to_element(collect).perform()
---
### 键盘控制
`webdriver` 中 `Keys` 类几乎提供了键盘上的所有按键方法,我们可以使用 `send_keys + Keys` 实现输出键盘上的组合按键如 **“Ctrl + C”、“Ctrl + V”** 等。
from selenium.webdriver.common.keys import Keys
定位输入框并输入文本
driver.find_element_by_id(‘xxx’).send_keys(‘Dream丶killer’)
模拟回车键进行跳转(输入内容后)
driver.find_element_by_id(‘xxx’).send_keys(Keys.ENTER)
使用 Backspace 来删除一个字符
driver.find_element_by_id(‘xxx’).send_keys(Keys.BACK_SPACE)
Ctrl + A 全选输入框中内容
driver.find_element_by_id(‘xxx’).send_keys(Keys.CONTROL, ‘a’)
Ctrl + C 复制输入框中内容
driver.find_element_by_id(‘xxx’).send_keys(Keys.CONTROL, ‘c’)
Ctrl + V 粘贴输入框中内容
driver.find_element_by_id(‘xxx’).send_keys(Keys.CONTROL, ‘v’)
其他常见键盘操作:
| 操作 | 描述 |
| --- | --- |
| `Keys.F1` | F1键 |
| `Keys.SPACE` | 空格 |
| `Keys.TAB` | Tab键 |
| `Keys.ESCAPE` | ESC键 |
| `Keys.ALT` | Alt键 |
| `Keys.SHIFT` | Shift键 |
| `Keys.ARROW_DOWN` | 向下箭头 |
| `Keys.ARROW_LEFT` | 向左箭头 |
| `Keys.ARROW_RIGHT` | 向右箭头 |
| `Keys.ARROW_UP` | 向上箭头 |
---
### 设置元素等待
很多页面都使用 `ajax` 技术,页面的元素不是同时被加载出来的,为了防止定位这些尚在加载的元素报错,可以设置元素等来增加脚本的稳定性。`webdriver` 中的等待分为 显式等待 和 隐式等待。
#### 显式等待
显式等待:设置一个超时时间,每个一段时间就去检测一次该元素是否存在,如果存在则执行后续内容,如果超过最大时间(超时时间)则抛出超时异常(`TimeoutException`)。显示等待需要使用 `WebDriverWait`,同时配合 `until` 或 `not until` 。下面详细讲解一下。
>
> WebDriverWait(driver, timeout, poll\_frequency=0.5, ignored\_exceptions=None)
>
>
>
* `driver`:浏览器驱动
* `timeout`:超时时间,单位秒
* `poll_frequency`:每次检测的间隔时间,默认为0.5秒
* `ignored_exceptions`:指定忽略的异常,如果在调用 `until` 或 `until_not` 的过程中抛出指定忽略的异常,则不中断代码,默认忽略的只有 `NoSuchElementException` 。
>
> until(method, message=’ ‘)
> until\_not(method, message=’ ')
>
>
>
* `method`:指定预期条件的判断方法,在等待期间,每隔一段时间调用该方法,判断元素是否存在,直到元素出现。`until_not` 正好相反,当元素消失或指定条件不成立,则继续执行后续代码
* `message`: 如果超时,抛出 `TimeoutException` ,并显示 `message` 中的内容
`method` 中的预期条件判断方法是由 `expected_conditions` 提供,下面列举常用方法。
先定义一个定位器
from selenium.webdriver.common.by import By
from selenium import webdriver
driver = webdriver.Chrome()
locator = (By.ID, ‘kw’)
element = driver.find_element_by_id(‘kw’)
| 方法 | 描述 |
| --- | --- |
| title\_is(‘百度一下’) | 判断当前页面的 title 是否等于预期 |
| title\_contains(‘百度’) | 判断当前页面的 title 是否包含预期字符串 |
| presence\_of\_element\_located(locator) | 判断元素是否被加到了 dom 树里,并不代表该元素一定可见 |
| visibility\_of\_element\_located(locator) | 判断元素是否可见,可见代表元素非隐藏,并且元素的宽和高都不等于0 |
| visibility\_of(element) | 跟上一个方法作用相同,但传入参数为 element |
| text\_to\_be\_present\_in\_element(locator , ‘百度’) | 判断元素中的 text 是否包含了预期的字符串 |
| text\_to\_be\_present\_in\_element\_value(locator , ‘某值’) | 判断元素中的 value 属性是否包含了预期的字符串 |
| frame\_to\_be\_available\_and\_switch\_to\_it(locator) | 判断该 frame 是否可以 switch 进去,True 则 switch 进去,反之 False |
| invisibility\_of\_element\_located(locator) | 判断元素中是否不存在于 dom 树或不可见 |
| element\_to\_be\_clickable(locator) | 判断元素中是否可见并且是可点击的 |
| staleness\_of(element) | 等待元素从 dom 树中移除 |
| element\_to\_be\_selected(element) | 判断元素是否被选中,一般用在下拉列表 |
| element\_selection\_state\_to\_be(element, True) | 判断元素的选中状态是否符合预期,参数 element,第二个参数为 True/False |
| element\_located\_selection\_state\_to\_be(locator, True) | 跟上一个方法作用相同,但传入参数为 locator |
| alert\_is\_present() | 判断页面上是否存在 alert |
下面写一个简单的例子,这里定位一个页面不存在的元素,抛出的异常信息正是我们指定的内容。
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
element = WebDriverWait(driver, 5, 0.5).until(
EC.presence_of_element_located((By.ID, ‘kw’)),
message=‘超时啦!’)

#### 隐式等待
隐式等待也是指定一个超时时间,如果超出这个时间指定元素还没有被加载出来,就会抛出 `NoSuchElementException` 异常。
除了抛出的异常不同外,还有一点,隐式等待是全局性的,即运行过程中,如果元素可以定位到,它不会影响代码运行,但如果定位不到,则它会以轮询的方式不断地访问元素直到元素被找到,若超过指定时间,则抛出异常。
使用 `implicitly_wait()` 来实现隐式等待,使用难度相对于显式等待要简单很多。
示例:打开个人主页,设置一个隐式等待时间 5s,通过 `id` 定位一个不存在的元素,最后打印 抛出的异常 与 运行时间。
from selenium import webdriver
from time import time
driver = webdriver.Chrome()
driver.get(‘https://blog.csdn.net/qq_43965708’)
start = time()
driver.implicitly_wait(5)
try:
driver.find_element_by_id(‘kw’)
except Exception as e:
print(e)
print(f’耗时:{time()-start}')

代码运行到 `driver.find_element_by_id('kw')` 这句之后触发隐式等待,在轮询检查 5s 后仍然没有定位到元素,抛出异常。
#### 强制等待
使用 `time.sleep()` 强制等待,设置固定的休眠时间,对于代码的运行效率会有影响。以上面的例子作为参照,将 隐式等待 改为 强制等待。
from selenium import webdriver
from time import time, sleep
driver = webdriver.Chrome()
driver.get(‘https://blog.csdn.net/qq_43965708’)
start = time()
sleep(5)
try:
driver.find_element_by_id(‘kw’)
except Exception as e:
print(e)
print(f’耗时:{time()-start}')

值得一提的是,对于定位不到元素的时候,从耗时方面隐式等待和强制等待没什么区别。但如果元素经过 2s 后被加载出来,这时隐式等待就会继续执行下面的代码,但 sleep还要继续等待 3s。
---
### 定位一组元素
上篇讲述了定位一个元素的 8 种方法,定位一组元素使用的方法只需要将 `element` 改为 `elements` 即可,它的使用场景一般是为了批量操作元素。
* `find_elements_by_id()`
* `find_elements_by_name()`
* `find_elements_by_class_name()`
* `find_elements_by_tag_name()`
* `find_elements_by_xpath()`
* `find_elements_by_css_selector()`
* `find_elements_by_link_text()`
* `find_elements_by_partial_link_text()`
这里以 CSDN 首页的一个 博客专家栏 为例。
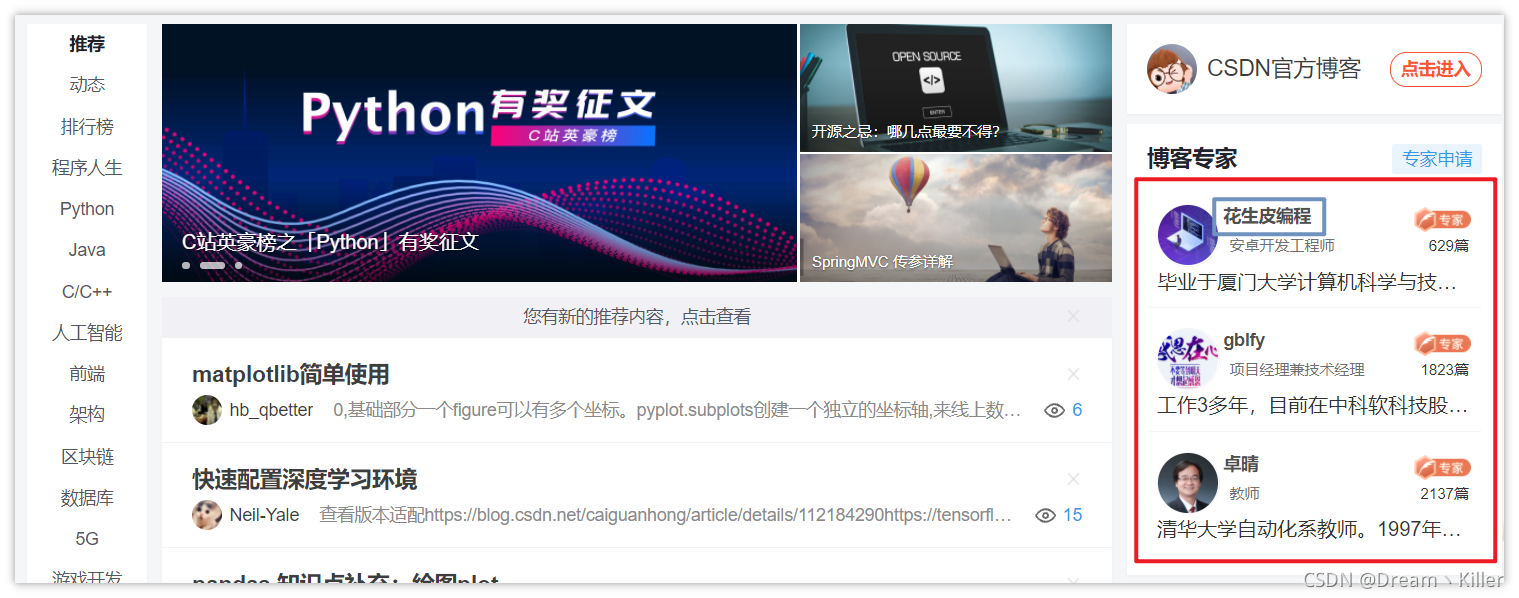
下面使用 `find_elements_by_xpath` 来定位三位专家的名称。

这是专家名称部分的页面代码,不知各位有没有想到如何通过 `xpath` 定位这一组专家的名称呢?
from selenium import webdriver
设置无头浏览器
option = webdriver.ChromeOptions()
option.add_argument(‘–headless’)
driver = webdriver.Chrome(options=option)
driver.get(‘https://blog.csdn.net/’)
p_list = driver.find_elements_by_xpath(“//p[@class=‘name’]”)
name = [p.text for p in p_list]
name

---
### 切换操作
#### 窗口切换
在 `selenium` 操作页面的时候,可能会因为点击某个链接而跳转到一个新的页面(打开了一个新标签页),这时候 `selenium` 实际还是处于上一个页面的,需要我们进行切换才能够定位最新页面上的元素。
窗口切换需要使用 `switch_to.windows()` 方法。
首先我们先看看下面的代码。
代码流程:先进入 【**CSDN首页**】,保存当前页面的句柄,然后再点击左侧 【**CSDN官方博客**】跳转进入新的标签页,再次保存页面的句柄,我们验证一下 `selenium` 会不会自动定位到新打开的窗口。
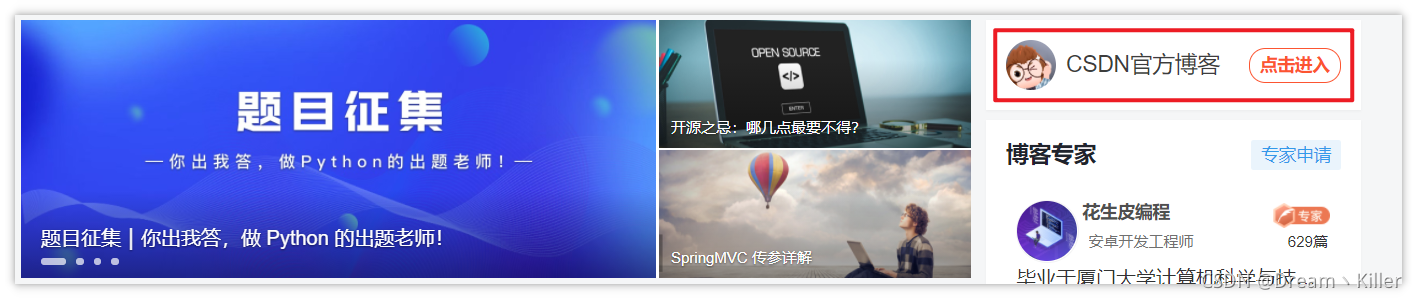
from selenium import webdriver
handles = []
driver = webdriver.Chrome()
driver.get(‘https://blog.csdn.net/’)
设置隐式等待
driver.implicitly_wait(3)
获取当前窗口的句柄
handles.append(driver.current_window_handle)
点击 python,进入分类页面
driver.find_element_by_xpath(‘//*[@id=“mainContent”]/aside/div[1]/div’).click()
获取当前窗口的句柄
handles.append(driver.current_window_handle)
print(handles)
获取当前所有窗口的句柄
print(driver.window_handles)

可以看到第一个列表 `handle` 是相同的,说明 `selenium` 实际操作的还是 CSDN首页 ,并未切换到新页面。
下面使用 `switch_to.windows()` 进行切换。
from selenium import webdriver
handles = []
driver = webdriver.Chrome()
driver.get(‘https://blog.csdn.net/’)
设置隐式等待
driver.implicitly_wait(3)
获取当前窗口的句柄
handles.append(driver.current_window_handle)
点击 python,进入分类页面
driver.find_element_by_xpath(‘//*[@id=“mainContent”]/aside/div[1]/div’).click()
切换窗口
driver.switch_to.window(driver.window_handles[-1])
获取当前窗口的句柄
handles.append(driver.current_window_handle)
print(handles)
print(driver.window_handles)

上面代码在点击跳转后,使用 `switch_to` 切换窗口,**`window_handles` 返回的 `handle` 列表是按照页面出现时间进行排序的**,最新打开的页面肯定是最后一个,这样用 `driver.window_handles[-1]` + `switch_to` 即可跳转到最新打开的页面了。
那如果打开的窗口有多个,如何跳转到之前打开的窗口,如果确实有这个需求,那么打开窗口是就需要记录每一个窗口的 `key`(别名) 与 `value`(`handle`),保存到字典中,后续根据 `key` 来取 `handle` 。
#### 表单切换
很多页面也会用带 `frame/iframe` 表单嵌套,对于这种内嵌的页面 `selenium` 是无法直接定位的,需要使用 `switch_to.frame()` 方法将当前操作的对象切换成 `frame/iframe` 内嵌的页面。
`switch_to.frame()` 默认可以用的 `id` 或 `name` 属性直接定位,但如果 `iframe` 没有 `id` 或 `name` ,这时就需要使用 `xpath` 进行定位。下面先写一个包含 `iframe` 的页面做测试用。
公众号:Python新视野
CSDN:Dream丶Killer
微信:python-sun
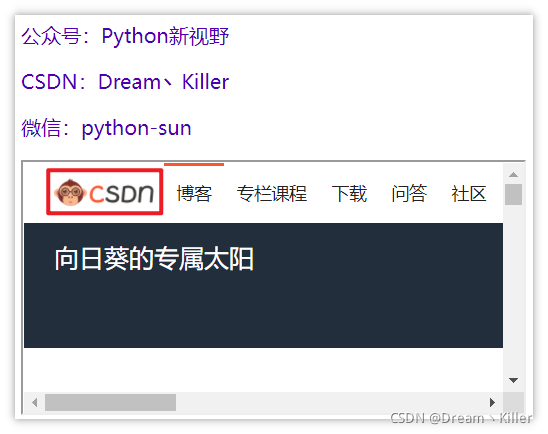
现在我们定位红框中的 CSDN 按钮,可以跳转到 CSDN 首页。
from selenium import webdriver
from pathlib import Path
driver = webdriver.Chrome()
读取本地html文件
driver.get(‘file:///’ + str(Path(Path.cwd(), ‘iframe测试.html’)))
1.通过id定位
driver.switch_to.frame(‘CSDN_info’)
2.通过name定位
driver.switch_to.frame(‘Dream丶Killer’)
通过xpath定位
3.iframe_label = driver.find_element_by_xpath(‘/html/body/iframe’)
driver.switch_to.frame(iframe_label)
driver.find_element_by_xpath(‘//*[@id=“csdn-toolbar”]/div/div/div[1]/div/a/img’).click()
这里列举了三种定位方式,都可以定位 `iframe` 。

---
### 弹窗处理
`JavaScript` 有三种弹窗 `alert`(确认)、`confirm`(确认、取消)、`prompt`(文本框、确认、取消)。
处理方式:先定位(`switch_to.alert`自动获取当前弹窗),再使用 `text`、`accept`、`dismiss`、`send_keys` 等方法进行操作
| 方法 | 描述 |
| --- | --- |
| `text` | 获取弹窗中的文字 |
| `accept` | 接受(确认)弹窗内容 |
| `dismiss` | 解除(取消)弹窗 |
| `send_keys` | 发送文本至警告框 |
这里写一个简单的测试页面,其中包含三个按钮,分别对应三个弹窗。
<script type="text/javascript">
const dom1 = document.getElementById(“alert”)
dom1.addEventListener(‘click’, function(){
alert(“alert hello”)
})
const dom2 = document.getElementById(“confirm”)
dom2.addEventListener(‘click’, function(){
confirm(“confirm hello”)
})
const dom3 = document.getElementById(“prompt”)
dom3.addEventListener(‘click’, function(){
prompt(“prompt hello”)
})

下面使用上面的方法进行测试。为了防止弹窗操作过快,每次操作弹窗,都使用 `sleep` 强制等待一段时间。
from selenium import webdriver
from pathlib import Path
from time import sleep
driver = webdriver.Firefox()
driver.get(‘file:///’ + str(Path(Path.cwd(), ‘弹窗.html’)))
sleep(2)
点击alert按钮
driver.find_element_by_xpath(‘//*[@id=“alert”]’).click()
sleep(1)
alert = driver.switch_to.alert
打印alert弹窗的文本
print(alert.text)
确认
alert.accept()
sleep(2)
点击confirm按钮
driver.find_element_by_xpath(‘//*[@id=“confirm”]’).click()
sleep(1)
confirm = driver.switch_to.alert
print(confirm.text)
取消
confirm.dismiss()
sleep(2)
点击confirm按钮
driver.find_element_by_xpath(‘//*[@id=“prompt”]’).click()
sleep(1)
prompt = driver.switch_to.alert
print(prompt.text)
向prompt的输入框中传入文本
prompt.send_keys(“Dream丶Killer”)
sleep(2)
prompt.accept()
‘’‘输出
alert hello
confirm hello
prompt hello
‘’’

>
> 注:细心地读者应该会发现这次操作的浏览器是 `Firefox` ,为什么不用 `Chrome` 呢?原因是测试时发现执行 `prompt` 的 `send_keys` 时,不能将文本填入输入框。尝试了各种方法并查看源码后确认不是代码的问题,之后通过其他渠道得知原因可能是 `Chrome` 的版本与 `selenium` 版本的问题,但也没有很方便的解决方案,因此没有继续深究,改用 `Firefox` 可成功运行。这里记录一下我的 `Chrome` 版本,如果有大佬懂得如何在 `Chrome` 上解决这个问题,请在评论区指导一下,提前感谢!
> selenium:3.141.0
> Chrome:94.0.4606.71
> 
>
>
>
---
### 上传 & 下载文件
#### 上传文件
常见的 web 页面的上传,一般使用 `input` 标签或是插件(`JavaScript`、`Ajax`),对于 `input` 标签的上传,可以直接使用 `send_keys(路径)` 来进行上传。
先写一个测试用的页面。

下面通过 `xpath` 定位 `input` 标签,然后使用 `send_keys(str(file_path)` 上传文件。
from selenium import webdriver
from pathlib import Path
from time import sleep
driver = webdriver.Chrome()
file_path = Path(Path.cwd(), ‘上传下载.html’)
driver.get(‘file:///’ + str(file_path))
driver.find_element_by_xpath(‘//*[@name=“upload”]’).send_keys(str(file_path))

#### 下载文件
##### Chrome浏览器
`Firefox` 浏览器要想实现文件下载,需要通过 `add_experimental_option` 添加 `prefs` 参数。
* `download.default_directory`:设置下载路径。
* `profile.default_content_settings.popups`:0 禁止弹出窗口。
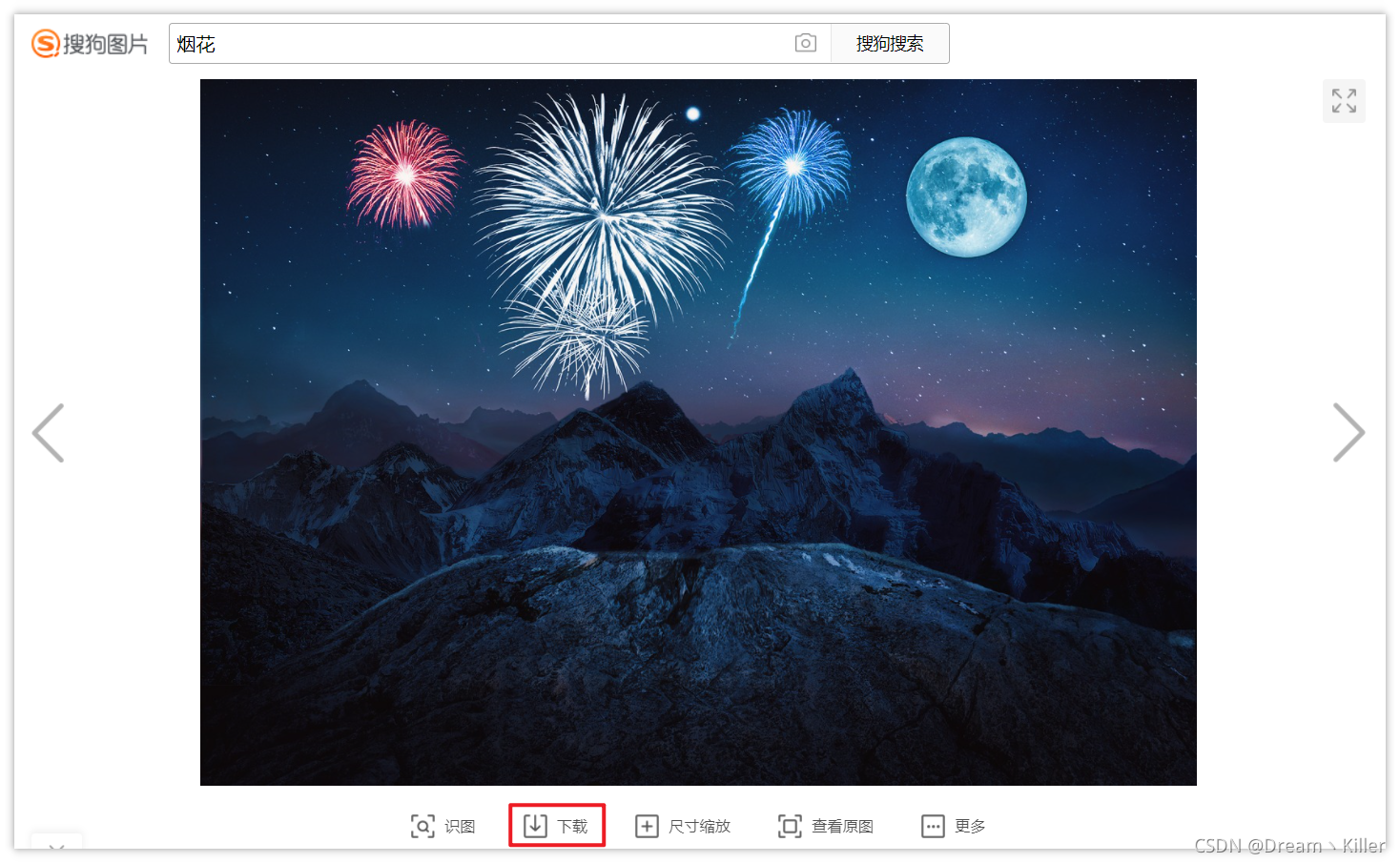
下面测试下载搜狗图片。指定保存路径为代码所在路径。
from selenium import webdriver
prefs = {‘profile.default_content_settings.popups’: 0,
‘download.default_directory’: str(Path.cwd())}
option = webdriver.ChromeOptions()
option.add_experimental_option(‘prefs’, prefs)
driver = webdriver.Chrome(options=option)
driver.get(“https://pic.sogou.com/d?query=%E7%83%9F%E8%8A%B1&did=4&category_from=copyright”)
driver.find_element_by_xpath(‘/html/body/div/div/div/div[2]/div[1]/div[2]/div[1]/div[2]/a’).click()
driver.switch_to.window(driver.window_handles[-1])
driver.find_element_by_xpath(‘./html’).send_keys(‘thisisunsafe’)
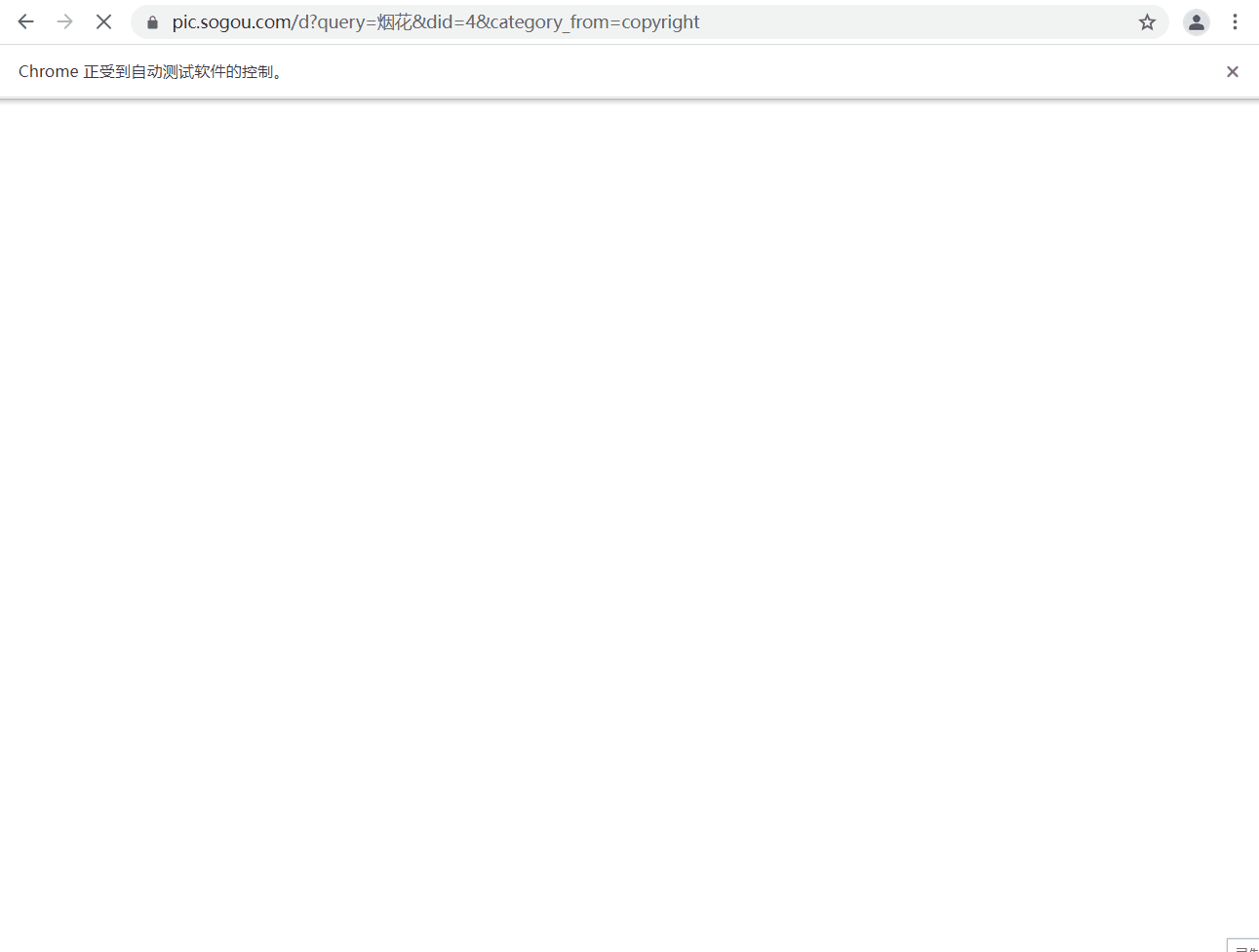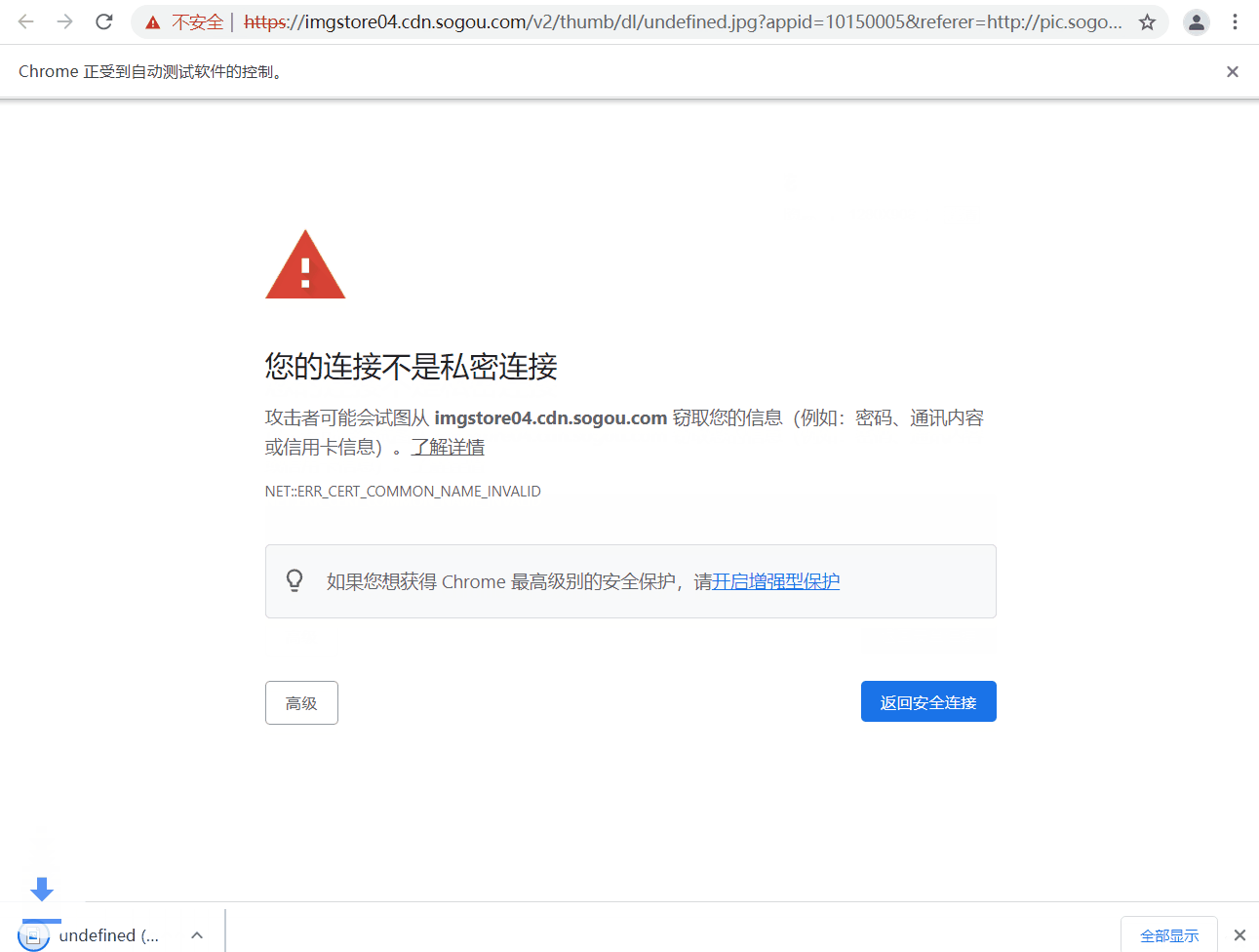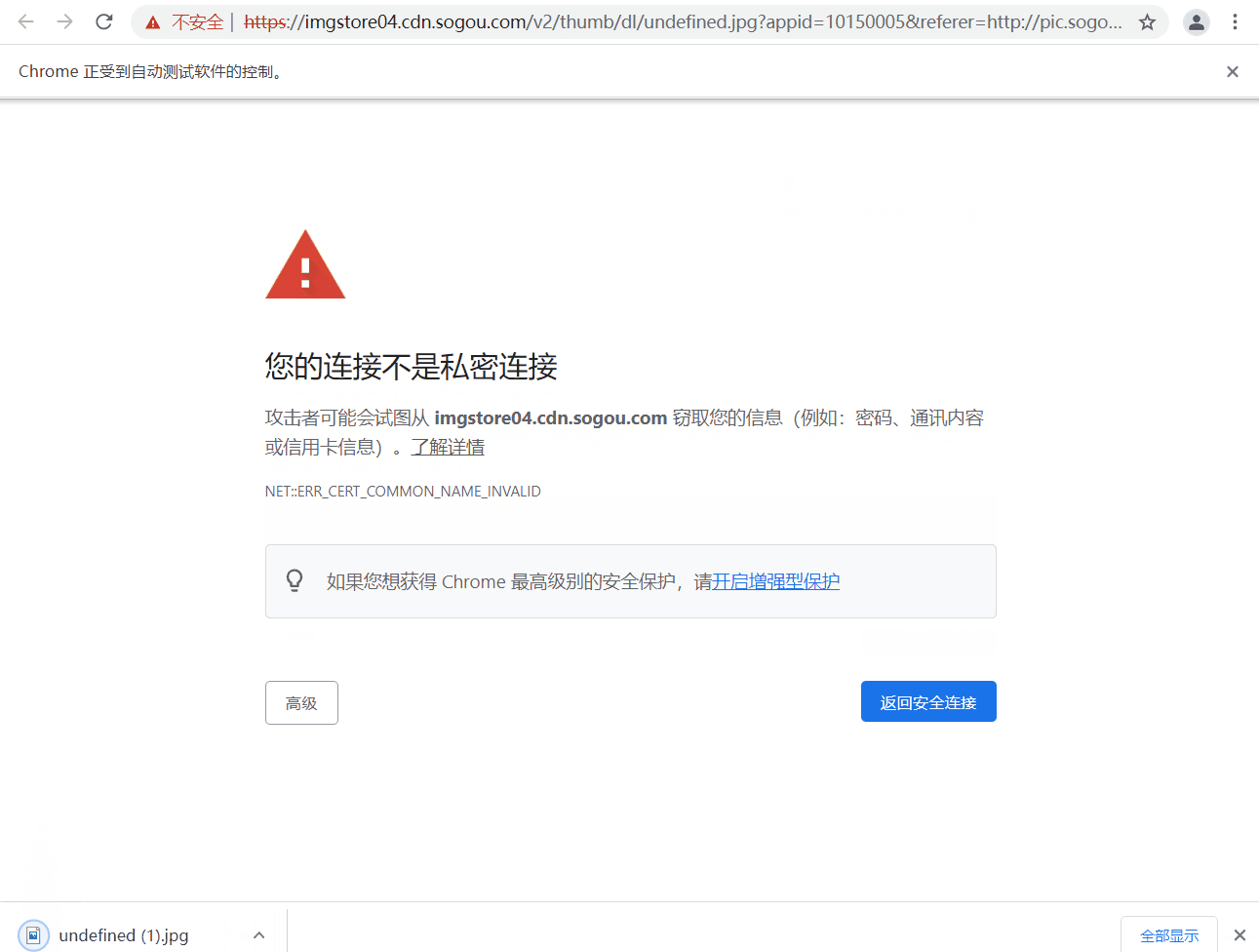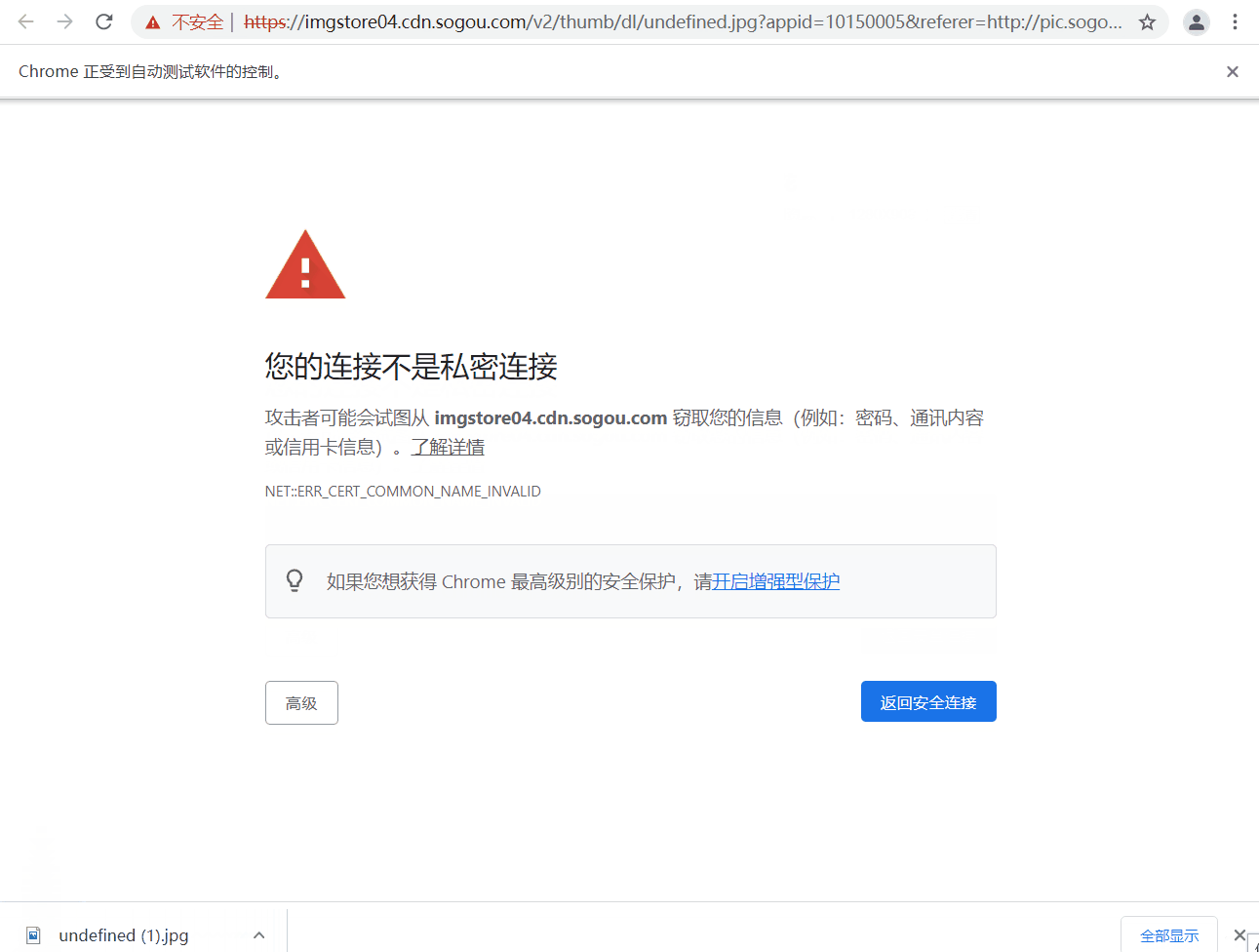
>
> 代码最后两句猜测有理解什么意思的吗~,哈哈,实际作用是当你弹出像下面的页面 “您的连接不是私密连接” 时,可以直接键盘输入 “thisisunsafe” 直接访问链接。那么这个键盘输入字符串的操作就是之间讲到的 `send_keys`,但由于该标签页是新打开的,所以要通过 `switch_to.window()` 将窗口切换到最新的标签页。
>
>
>
##### Firefox浏览器
`Firefox` 浏览器要想实现文件下载,需要通过 `set_preference` 设置 `FirefoxProfile()` 的一些属性。
* `browser.download.foladerList`:0 代表按浏览器默认下载路径;2 保存到指定的目录。
* `browser.download.dir`:指定下载目录。
* `browser.download.manager.showWhenStarting`:是否显示开始,`boolean` 类型。
## 写在最后
**在结束之际,我想重申的是,学习并非如攀登险峻高峰,而是如滴水穿石般的持久累积。尤其当我们步入工作岗位之后,持之以恒的学习变得愈发不易,如同在茫茫大海中独自划舟,稍有松懈便可能被巨浪吞噬。然而,对于我们程序员而言,学习是生存之本,是我们在激烈市场竞争中立于不败之地的关键。一旦停止学习,我们便如同逆水行舟,不进则退,终将被时代的洪流所淘汰。因此,不断汲取新知识,不仅是对自己的提升,更是对自己的一份珍贵投资。让我们不断磨砺自己,与时代共同进步,书写属于我们的辉煌篇章。**
需要完整版PDF学习资源私我
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注网络安全)**

**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
div[2]/a').click()
driver.switch_to.window(driver.window_handles[-1])
driver.find_element_by_xpath('./html').send_keys('thisisunsafe')
代码最后两句猜测有理解什么意思的吗~,哈哈,实际作用是当你弹出像下面的页面 “您的连接不是私密连接” 时,可以直接键盘输入 “thisisunsafe” 直接访问链接。那么这个键盘输入字符串的操作就是之间讲到的
send_keys,但由于该标签页是新打开的,所以要通过switch_to.window()将窗口切换到最新的标签页。

Firefox浏览器
Firefox 浏览器要想实现文件下载,需要通过 set_preference 设置 FirefoxProfile() 的一些属性。
browser.download.foladerList:0 代表按浏览器默认下载路径;2 保存到指定的目录。browser.download.dir:指定下载目录。browser.download.manager.showWhenStarting:是否显示开始,boolean类型。
写在最后
在结束之际,我想重申的是,学习并非如攀登险峻高峰,而是如滴水穿石般的持久累积。尤其当我们步入工作岗位之后,持之以恒的学习变得愈发不易,如同在茫茫大海中独自划舟,稍有松懈便可能被巨浪吞噬。然而,对于我们程序员而言,学习是生存之本,是我们在激烈市场竞争中立于不败之地的关键。一旦停止学习,我们便如同逆水行舟,不进则退,终将被时代的洪流所淘汰。因此,不断汲取新知识,不仅是对自己的提升,更是对自己的一份珍贵投资。让我们不断磨砺自己,与时代共同进步,书写属于我们的辉煌篇章。
需要完整版PDF学习资源私我
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注网络安全)
[外链图片转存中…(img-4p1WGaW7-1713401952147)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 325
325

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









