






1 基本思想
广度优先遍历算法类似于二叉树的层次遍历算法。首先访问起始顶点v,接着由v1的各个未访问过的邻接顶点w1,w2,w3,……,wi,然后依次访问w1,w2,w3,……,wi的所有未被访问过的邻接顶点;在从这些访问过的顶点出发,访问它们所有未被访问过的邻接顶点,直至图中所有顶点都被访问过为止。若此时图中尚有顶点未被访问,则另选图中一个未曾被访问的顶点作为始点,重复上述过程,直至图中所有顶点都被访问到为止。
2 实例
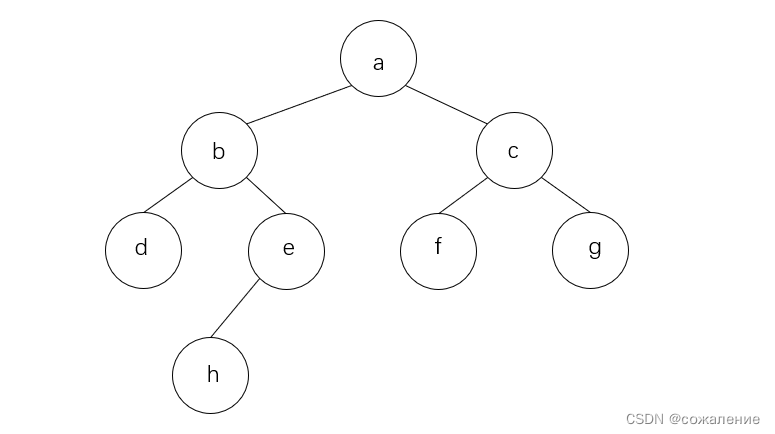
假设从a结点开始访问,首先队列为空,a先入队:
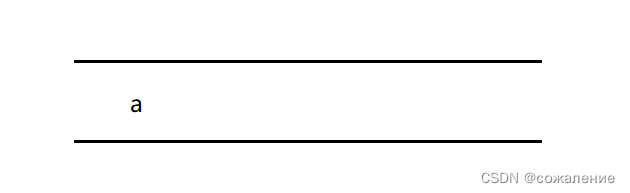
取出队头元素a,因为b,c与a邻接且未被访问,则b,c入队:
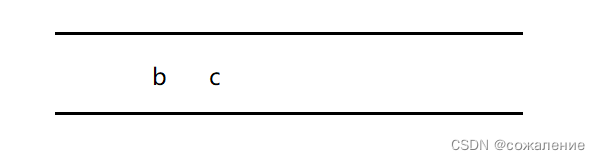
取出队头元素b,因为d,e,a与b邻接,但a已被访问,则d,e入队:
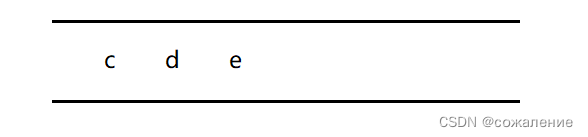
取出队头元素c,因为f,g,a与c邻接,但a已被访问,则f,g入队:
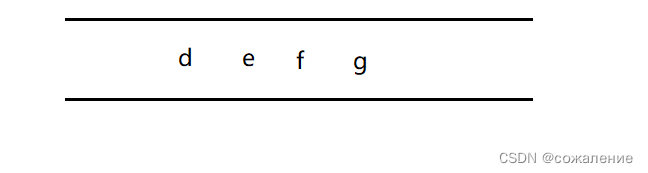
取出队头元素d,因为b与其邻接,但b已被访问,所以不做任何操作。
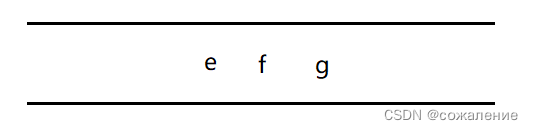
取出队头元素e,因为h,b与其邻接,但b已被访问,所以将h入队:
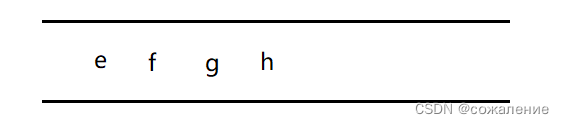
取出队头元素f,因为c与其邻接,但c已被访问,所以不做任何操作。
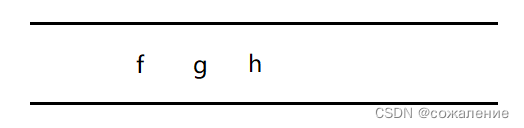
取出队头元素g,因为c与其邻接,但c已被访问,所以不做任何操作。
取出队头元素h,因为e与其邻接,但e已被访问,所以不做任何操作。

此时,队列已经为空,所有结点已被遍历一次。遍历结果是:abcdefgh。
3 算法
public static void bfs(Node node){
if(node==null){
return;
}
Queue<Node> queue=new LinkedList<>();
HashSet<Node> map=new HashSet<>();
queue.add(node);
map.add(node);
while(!queue.isEmpty()){
Node cur=queue.poll();
System.out.println(cur.value);
for(Node next:cur.nexts){
if(!map.contains(next)){
map.add(next);
queue.add(next);
}
}
}
}4 性能分析
(1)空间复杂度:O(|V|)
(2)时间复杂度
- 采用邻接矩阵存储方式:
- 采用邻接表存储方式:
5 广度优先生成树
同一个图的邻接矩阵存储表示是唯一的,故其广度优先生成树也是唯一的。
但邻接表存储表示不唯一,故其广度优先生成树不唯一的。















 1174
1174











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









