







我是张晨,一转眼,我在新课已经学习了很长一段时间。回顾这几个月的时间,我收获了很多知识。这里是我的一点学习笔记。
一、urllib了解与使用
urllib是一个功能强大、条例清晰、用于HTTP客户端的Python库。它提供了许多Python标准库里所没有的特性:压缩编码、连接池、线程安全、SSL/TLS验证、HTTP和SCOCKS代理等。
# 更新pip
python -m pip install --upgrade pip
# 下载urllib模块
pip install urllib3
# 更新模块
pip install -U urllib3
# 使用清华源进行下载
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple urllib3
pip install urllib3 -i https://pypi.tuna.tsinghua.edu.cn/simple
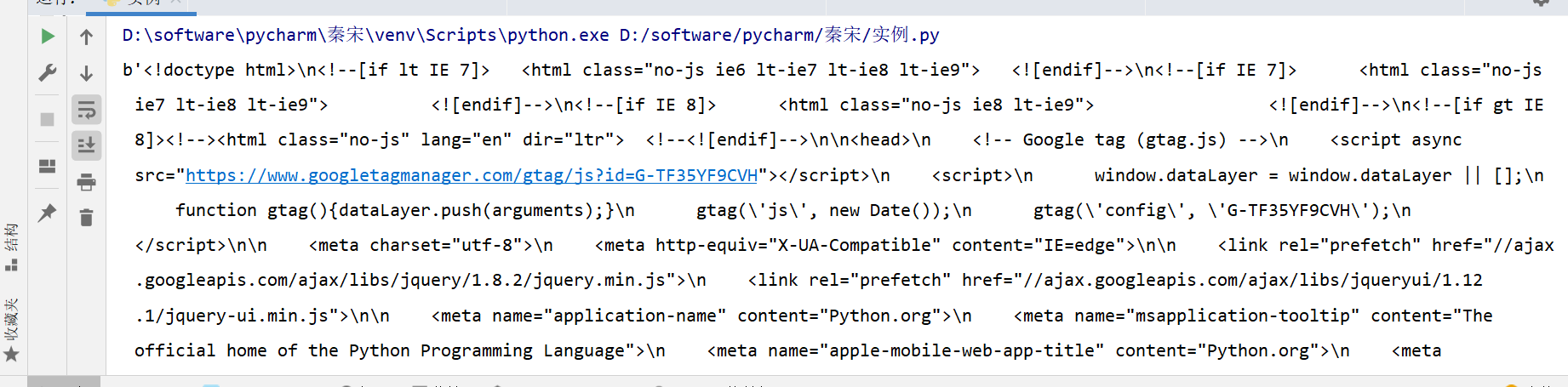
1.使用**urlopen( )**方法爬取网页源代码,url参数用于指定要请求的URL路径(未指定data参数时,默认使用GET请求方法)
示例:
import urllib.request # 导入urllib的请求模块
# 使用urlopen方法请求网址 默认使用get请求
response = urllib.request.urlopen("https://www.python.org")
# 读取请求的数据 字节数据
print(response.read())
运行结果:
2.urllib 编码
示例代码:
# https://www.baidu.com/s?wd=%E6%95%B0%E6%8D%AE
# parse.urlencode(字典数据) # 将数据进行编码
# parse.unquote() # 将数据进行解密
from urllib import parse
# 编码 将“wd=数据”转换为键值对
data = {
'wd': '数据'}
print(parse.urlencode(data))
# 解密
print(parse.unquote('%E6%95%B0%E6%8D%AE'))
print(parse.unquote('https://www.baidu.com/s?wd=%E6%95%B0%E6%8D%AE& 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 501
501











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









