







Python爬虫 —— urllib库的使用(get/post请求+模拟超时/浏览器)
这里写目录标题
-
- Python爬虫 —— urllib库的使用(get/post请求+模拟超时/浏览器)
- 1.Python爬虫的工作过程
-
- 1.1 获取网页
- 1.2 提取信息
- 1.3 保存数据
- 2.获取一个 POST / GET 请求
-
- 2.1 获取一个GET请求
- 2.2 获取一个POST请求
- 3.模拟访问页面超时
- 4.假装自己是一个genuine browser
1.Python爬虫的工作过程
爬虫简介:网络爬虫就是按照一定规则,自动抓取互联网信息的程序或脚本,由于互联网数据的多样性和资源的有限性,根据用户需求定向抓取相关网页并分析就是爬虫要做的工作
为什么我们把它称为爬虫(Spider)嘞?互联网就像是一张大网,而每一个网页就是这张大网上的每一个结点,这些结点间的通信和跳转通过链接来实现,而这个链接就是互联网这张大网上结点之间的连线,爬虫到达一个结点就意味着可以爬取这个页面的信息,当爬虫顺着这些连线(链接)爬向不同的结点(网页)时,就可以爬取到整个网站的信息
只要你能通过浏览器访问的数据都能通过爬虫获取
爬虫的主要工作就是获取网页信息,它其实就是一个获取网页并提取和保存信息的自动化程序,它的工作流程可分为:获取网页 --> 提取信息 --> 保存数据
1.1 获取网页
在拿到我们想要爬取的网页的链接之后,我们要做的第一件事情就是获取这个网页的源代码,网页就是用HTML和CSS以及一些内嵌的JS代码编写成的,这些代码信息中就蕴含着我们想要爬取的信息
我们怎么获取网页的源代码,这就是问题的关键,我们作为一个用户(浏览器)向这个网站的服务器发送请求Request时,服务器就会给我们返回网页的源代码在解析后用于在浏览器呈现完整的页面,Python为我们提供了很多库来帮助我们实现这个操作在获取源代码后我们对其中的数据做一系列的数据解析即可
1.2 提取信息
在获取到页面的源代码后,就要开始获取其中的信息了,分析网页源代码并从中提取信息,我们提取信息可以用正则表达式,也可以用根据网页结点属性、CSS选择器或者Xpath来提取信息的库:Beautiful Soup(漂亮汤)、pyquery和lxml等,通过这些库我们可以高校地从网页源代码中提取网页信息
正则表达式不太受欢迎,或者说它并不好用,因为它在构造时很复杂而且容错率较低
1.3 保存数据
在提取到我们指定的信息后,我们通常会把这些信息保存起来方便后续使用,而数据的保存我们第一个想到的就是数据库MySQL和MongDB,当然我们还能简单地保存为txt文本或json文本
2.获取一个 POST / GET 请求
这一部分我们来看看怎么以GET和POST的方式向服务器发送请求并取得回应
2.1 获取一个GET请求
urllib库中的request对象有一个urlopen()方法,它可以帮助我们打开一个网页并向服务器发送请求然后获取源代码
我们定义一个response来接收urlopen方法返回的信息并用read()方法把源代码读取出来
response = urllib.request.urlopen("http://www.baidu.com")
print(response.read().decode('utf-8'))

使用urllib访问一个页面时,建议对返回的内容用decode()方法做一个解码,相对应的,encode()就是指定编码方式
2.2 获取一个POST请求
对于获取一个POST请求我们要用到一个网站:http://httpbin.org,这是一个专门用来测试的网站,当我们以post方式向这个网站的服务器发送请求时,它会给我们返回响应的特定信息

它的意思是说当我们访问http://httpbin.org时加个/post后缀再访问,就意味着我们是通过post获取响应,而post我们也不能直接使用,因为这种方式通常用于给服务器传递账号密码等表单信息,所有我们要加一个表单信息在里面,而表单信息我们通过键值对的方式传递
然后我们再看一个urllib库的对象parse,它是一个解析器,用于对我们的表单信息进行解析,它提供了一个urlencode()方法放置我们的表单信息,还需要一个指定encoding属性,对我们的表单信息做一个编码然后传递给服务器
data = bytes(urllib.parse.urlencode({"hello": "world"}), encoding="utf-8")
# 需要使用urllib的parse对象,它是一个解析器,对我们的表单信息进行解析
response02 = urllib.request.urlopen("http://httpbin.org/post", data=data)
print(response02.read().decode('utf-8'))

3.模拟访问页面超时
有时候我们长时间访问不到一个页面,可能是因为网速有限或者被发现我们是一个爬虫
# 模拟超时(网速有限或对方发现你是爬虫)
try:
response03 = urllib.request.urlopen("http://httpbin.org/get", timeout=0.01)
print(response03.read().decode('utf-8'))
except urllib.error.URLError as e:
print("访问已超时 !!!!")
这个timeout就是一个超时信息,如果访问页面的时间超过了这个时间就会被认定为访问超时,此时网页服务器有可能会作出相应的操作

4.假装自己是一个genuine browser
但是一般的网站都会有各种反爬机制,这个时候我们就要假装自己不是爬虫,我们是一个真正的浏览器是一个用户,当我们以正常用户的形式访问某个页面的时候,就可以获取页面中的信息
如果这个网站发现了我们是一个爬虫,就会给我们一个418的状态码
# 响应头(被别人发现你是爬虫会爆418)
response04 = urllib.request.urlopen("http://httpbin.org/get")
print(response04.status)
# 状态码,被别人发现你是爬虫会爆418
print(response04.getheader("Server"))
# 这个就是浏览器在NetWork中response Header中的信息
# 在getHeader()中传入参数,例如Server,就会返回指定的信息
上述代码我们是用get请求访问了http://httpbin.org/get,这个网页的反爬机制不是那么的严格敏感,所以我们可以正常爬取其中的源代码信息

但是我们把网站换成豆瓣试试

瞧瞧,这样咱就很没面子,出现了HTTPError,被对方发现了我们是一个爬虫
那如何让对方发现不了我们是一个爬虫呢?就是上面所说的,我们要伪装成一个浏览器(用户),在发出响应时传递该传递给服务器的信息,这个时候服务器就会认为我们是一个正经用户,我们就能正常爬取网页信息了,对于需要传递账号密码表单信息的网页,我们把这些信息正常传递进去就能访问了
url = "http://httpbin.org/post"
headers = { # 注意键和值
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.84 Safari/537.36"
}
data = bytes(urllib.parse.urlencode({'name': 'MJJ'}), encoding="utf-8")
req = urllib.request.Request(url=url, data=data, headers=headers, method="POST")
# 上述就是我们的请求,内部包含了我们模拟的浏览器的信息
response05 = urllib.request.urlopen(req)
# User-Agent(用户代理)是最能体现的,这个在任意一个网页的Request-Header的User-Agent
print(response05.read().decode("utf-8"))
上面的代码就是一个比较完整的过程,先指定了基本的url,即我们要访问的网址,然后设置headers信息,注意headers信息是键值对的形式,而data就对应了data信息,req是我们定义的一个请求,其中包含了url、headers、data和method这些信息,此时我们想获取网页的响应,就把我们的req请求放在urlopen()方法中即可

关于Python技术储备
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
包括:Python激活码+安装包、Python web开发,Python爬虫,Python数据分析学习等教程。带你从零基础系统性的学好Python!
一、Python学习大纲
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
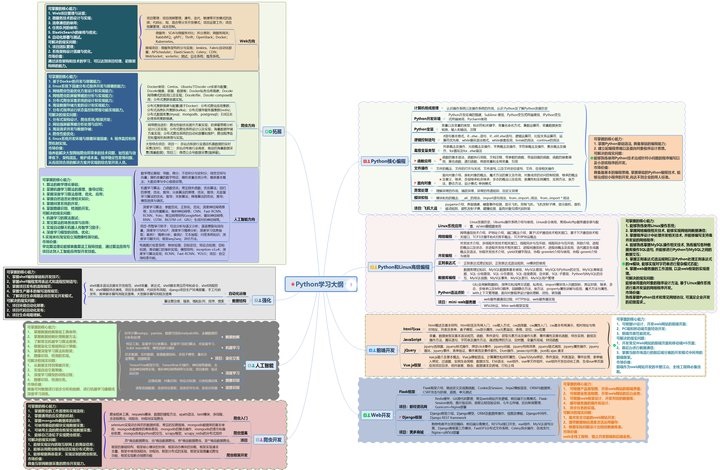
二、Python必备开发工具

三、入门学习视频
四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
五、python副业兼职与全职路线
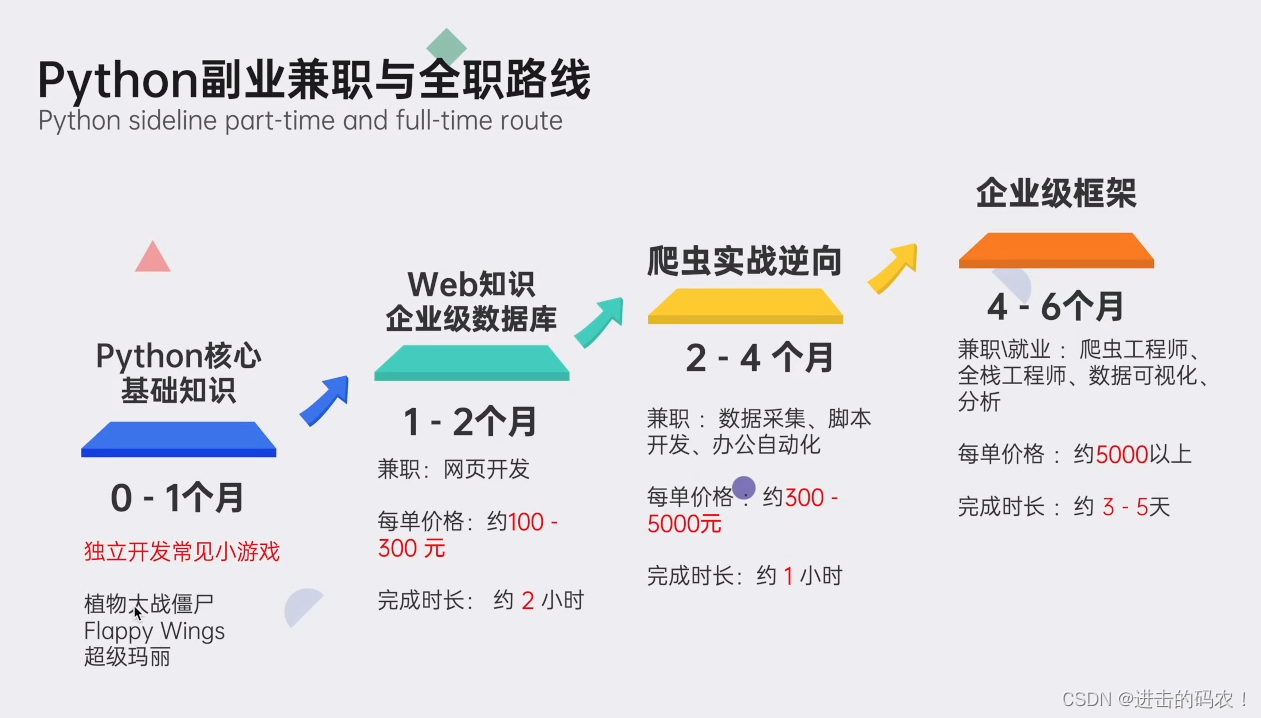
上述这份完整版的Python全套学习资料已经上传CSDN官方,如果需要可以微信扫描下方CSDN官方认证二维码 即可领取
👉[[CSDN大礼包:《python兼职资源&全套学习资料》免费分享]](安全链接,放心点击)
















 2785
2785











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









