






0数据百度网盘(1.2G,不建议下载)
提取码:mejc
train.csv表格数据(wps最高行数为1048576,所以只能显示1048576调)
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
# pandas.csv() 函数将逗号分离的值 (csv) 文件读入数据框架。还支持可选地将文件读入块或将其分解。
data = pd.read_csv("F:/机器学习/FBlocation/train.csv",sep=',')
# 数据太多了,运行太慢,缩减一下数据,筛选1.0<x<1.25并且2.5<y<2.75的数据
data=data.query("x>1.0&x<1.25&y>2.5&y<2.75")
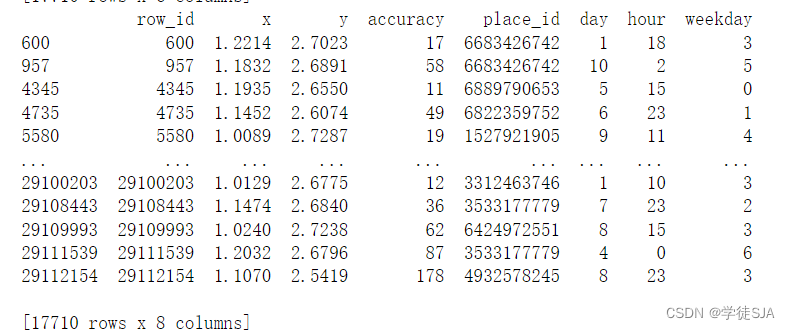
#看一下筛选后的数据
print(data)

#2、处理时间的数据
time_data=pd.to_datetime(data["time"],unit="s")
#3、把日期格式转换成字典
time_data=pd.DatetimeIndex(time_data)
#4、构造一些特征
data["day"]=time_data.day
data["hour"] = time_data.hour
data["weekday"] = time_data.weekday
#5、把time特征删除
data= data.drop(["time"],axis=1)
# 将place_id次数较少的数据删除
# 分组并统计字数
place_count=data.groupby("place_id").count()
#.reset_index()函数:用索引重置生成一个新的DataFrame或Series。当索引需要被视为列,或者索引没有意义,需要在另一个操作之前重置为默认值时。在机器学习中常常会对索引进行一定的处理,用于是否保留原有的索引。
# 把place_count里row_id>3的重置索引
tf=place_count[place_count.row_id>3].reset_index()
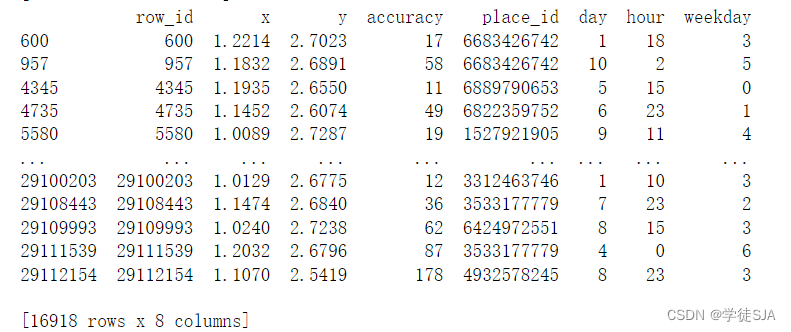
# 筛选出data表和tf表具有相同place_id的数据
data=data[data["place_id"].isin(tf.place_id)]分组统计字数place_count:

重置索引:

data数据:
# 数据集的特征值
X=data.drop(["place_id"],axis=1)
# 数据集的目标值
y=data["place_id"]
# x_train,x_test,y_train,y_test为训练集特征值,测试集特征值,训练集目标值,测试集目标值
# x:数据集的特征值
# y:数据集的目标值
# test_size:测试集的大小,一般为float
# random_state:随机数种子,不同的种子会造成不同的随机采样结果,相同的种子结果相同
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=22)
# 3.特征工程:标准化
# 必须要对数据进行标准化,因为是使用距离进行计算,如果没有标准化,那么预测结果就会被一些极大值或极小值影响。
transfer = StandardScaler()
# fit_transform方法是fit和transform的结合,fit_transform(X_train) 意思是找出X_train的均值和标准差,并应用在X_train上。这时对于X_test,我们就可以直接使用transform方法。因为此StandardScaler已经保存了X_train的均值和标准差
X_train = transfer.fit_transform(X_train)
X_test = transfer.transform(X_test)
#进行算法流程
# 机器学习(模型训练)
estimator=KNeighborsClassifier(n_neighbors=5)
estimator.fit(X_train,y_train)
#得出预测结果
y_predict=estimator.predict(X_test)
print("预测的目标签到位置为:",y_predict)
#得出准确率
print("预测的准确率:",estimator.score(X_test,y_test))结果:

完整代码:
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
data = pd.read_csv("F:/机器学习/FBlocation/train.csv",sep=',')
# 数据太多了,运行太慢,缩减一下数据
data=data.query("x>1.0&x<1.25&y>2.5&y<2.75")
#2、处理时间的数据
time_data=pd.to_datetime(data["time"],unit="s")
#3、把日期格式转换成字典
time_data=pd.DatetimeIndex(time_data)
#4、构造一些特征
data["day"]=time_data.day
data["hour"] = time_data.hour
data["weekday"] = time_data.weekday
#5、把time特征删除
data= data.drop(["time"],axis=1)
# 将place_id次数较少的数据删除
# 分组并统计字数
place_count=data.groupby("place_id").count()
#.reset_index()函数:用索引重置生成一个新的DataFrame或Series。当索引需要被视为列,或者索引没有意义,需要在另一个操作之前重置为默认值时。在机器学习中常常会对索引进行一定的处理,用于是否保留原有的索引。
# 把place_count里row_id>3的重置索引
tf=place_count[place_count.row_id>3].reset_index()
# 筛选出data表和tf表具有相同place_id的数据
data=data[data["place_id"].isin(tf.place_id)]
# 数据集的特征值
X=data.drop(["place_id"],axis=1)
# 数据集的目标值
y=data["place_id"]
# x_train,x_test,y_train,y_test为训练集特征值,测试集特征值,训练集目标值,测试集目标值
# x:数据集的特征值
# y:数据集的目标值
# test_size:测试集的大小,一般为float
# random_state:随机数种子,不同的种子会造成不同的随机采样结果,相同的种子结果相同
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=22)
# 3.特征工程:标准化
# 必须要对数据进行标准化,因为是使用距离进行计算,如果没有标准化,那么预测结果就会被一些极大值或极小值影响。
transfer = StandardScaler()
# fit_transform方法是fit和transform的结合,fit_transform(X_train) 意思是找出X_train的均值和标准差,并应用在X_train上。这时对于X_test,我们就可以直接使用transform方法。因为此StandardScaler已经保存了X_train的均值和标准差
X_train = transfer.fit_transform(X_train)
X_test = transfer.transform(X_test)
#进行算法流程
# 机器学习(模型训练)
estimator=KNeighborsClassifier(n_neighbors=5)
estimator.fit(X_train,y_train)
#得出预测结果
y_predict=estimator.predict(X_test)
print("预测的目标签到位置为:",y_predict)
#得出准确率
print("预测的准确率:",estimator.score(X_test,y_test))K值参数调优
from sklearn.model_selection import train_test_split,GridSearchCV
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsRegressor
# 实例化一个估计器
estimator = KNeighborsRegressor(n_neighbors=5)
# 模型调优——交叉验证,网格搜索
param_grid = {"n_neighbors": [1,3,5,7]}
estimator = GridSearchCV(estimator,param_grid=param_grid,cv=5)
# 模型训练
estimator.fit(X_train,y_train)
#模型评估
#预测值结果输出
y_pre = estimator.predict(X_test)
print("预测值是:\n",y_pre)
#准确率计算
score = estimator.score(X_test,y_test)
print("准确率为:\n",score)
#查看交叉验证,网格搜索的一些属性
print("在交叉验证中验证的最好结果:\n",estimator.best_score_)
print("最好的参数模型:\n",estimator.best_estimator_)
print("交叉验证后的准确率结果:\n",estimator.cv_results_)结果:

如有错误之处,请在评论留言!















 1167
1167











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









