






- Fake News Detection Landscape: Datasets, Data Modalities, AI Approaches, Their Challenges, and Future Perspectives
论文till February 2024 ;2025 年 2 月 20 日收到,2025 年 3 月 15 日接受,2025 年 3 月 25 日出版
- A Survey of Multimodal Fake News Detection: A Cross-Modal Interaction Perspective
2024 年 4 月 19 日收到;2024 年 9 月 23 日和 2024 年 12 月 7 日修订;2025 年 1 月 20 日接受

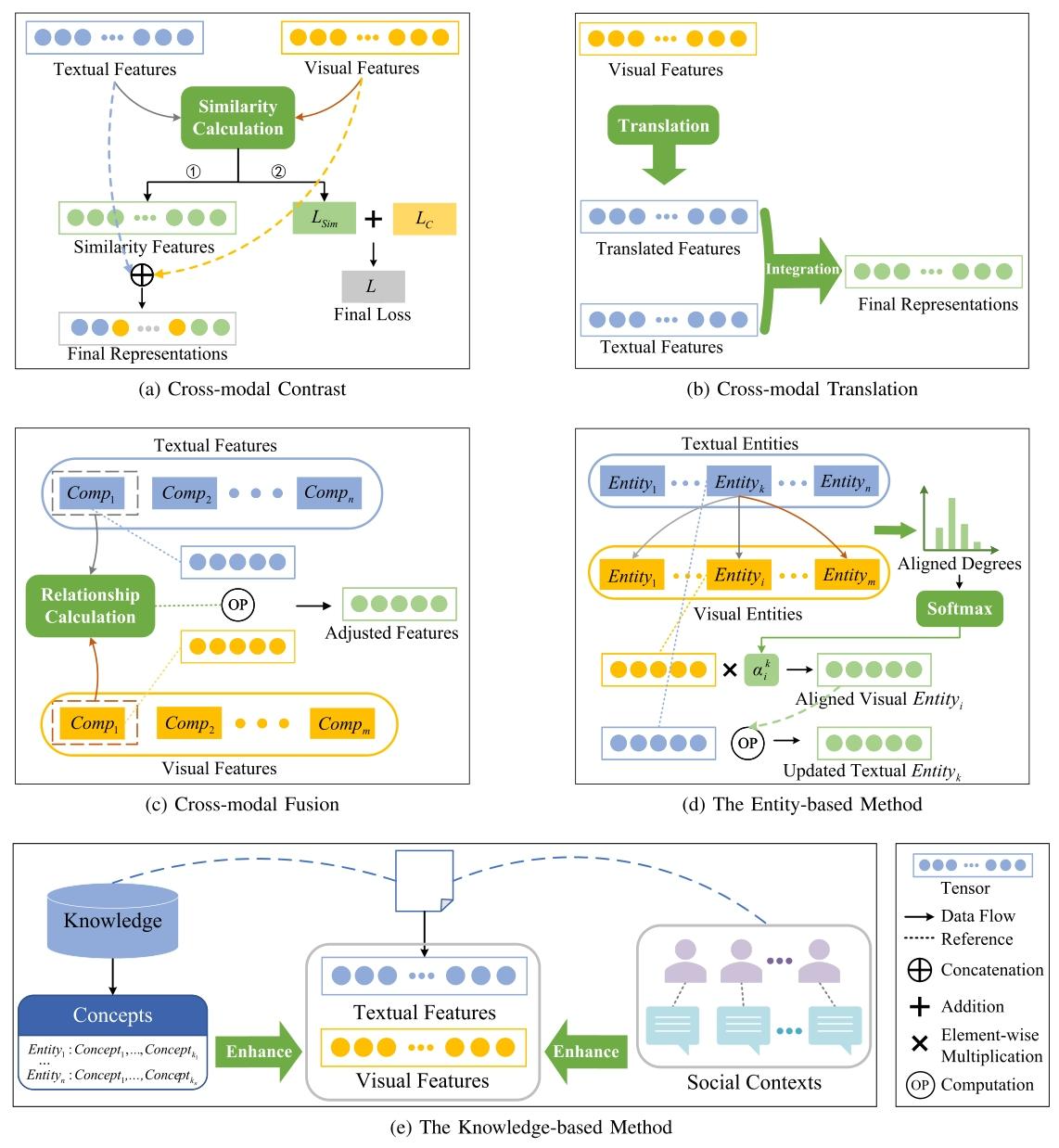
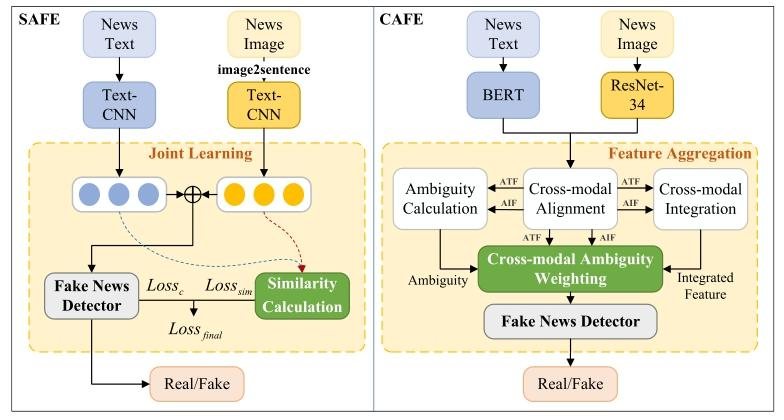
- Multimodal Fake News Detection: A Survey of Text and Visual Content Integration Methods
Received: 30 Dec 2024 ;
Revised: 28 Feb 2025;
Accepted: 28 Apr 2025
- A systematic review of multimodal fake news detection on social media using deep learning models
2024 年 12 月 14 日收到;2025 年 3 月 13 日收到修订稿;2025 年 3 月 28 日接受
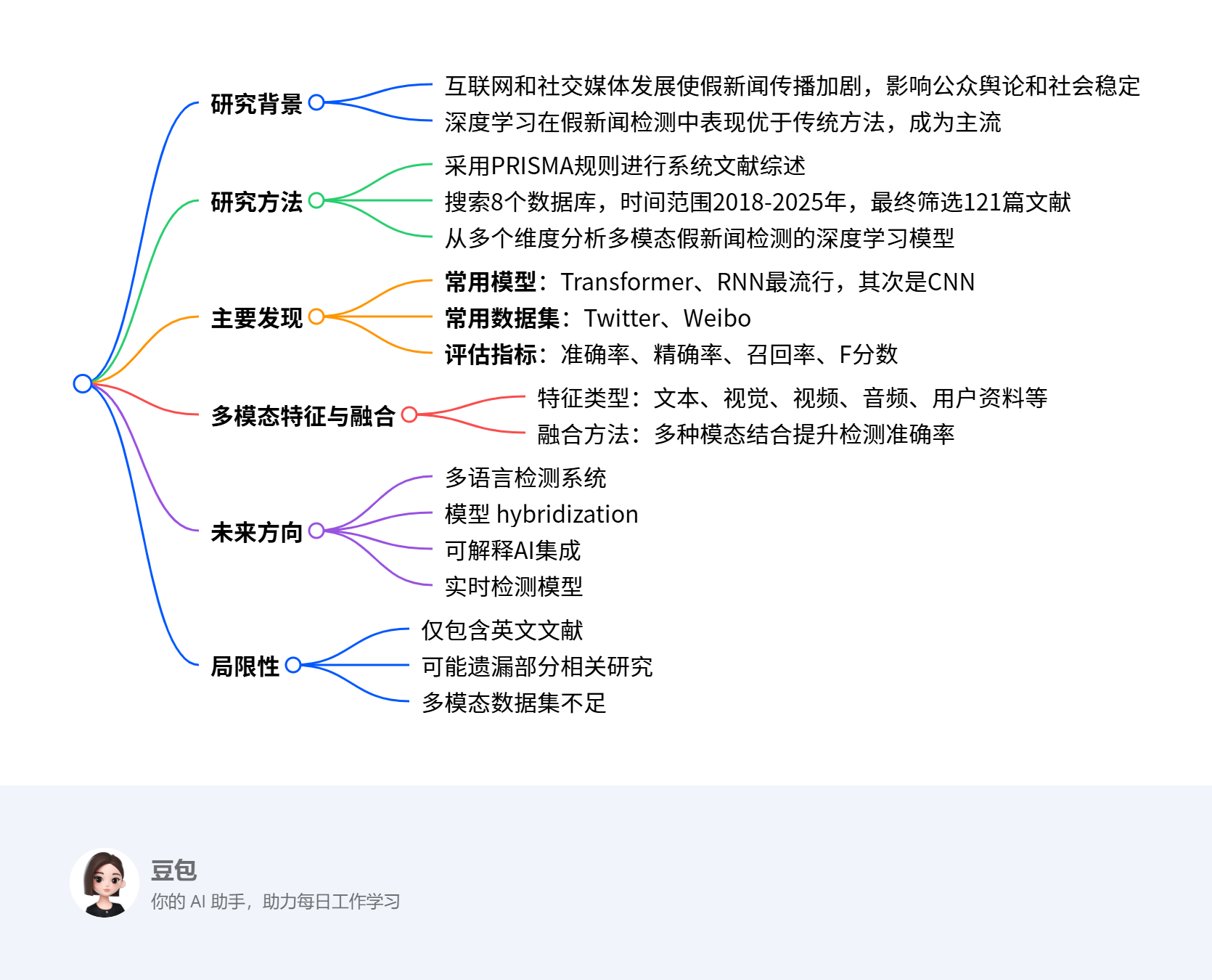
表4 多模态假新闻检测中基于深度学习方法的对比
| 模型 | 描述 | 优势 | 劣势 | 参考文献 |
|---|---|---|---|---|
| 注意力机制 | 通过有选择地聚焦于关键输入组件来增强人工智能模型 | 注意力机制能够聚焦于最具信息量的数据,从而增强对上下文的理解 | 注意力机制可能具有较高的计算成本,尤其是对于非常大的数据集或长序列,因为需要为每对输入元素计算注意力分数 | [58, 106, 85, 59, 110, 63, 95] |
| 自动编码器(AE) | 自动编码器用于无监督学习,其主要目的是学习高维数据的低维表示,本质上是将输入数据压缩成紧凑形式,同时保留关键特征 | 自动编码器可以降低数据维度,使其更易于管理和处理 | 自动编码器可能难以处理非常复杂的数据,因为它们可能无法有效捕捉复杂模式 | [69, 118, 92-94] |
| 循环神经网络(RNN) | RNN是一种特殊的神经网络,用于处理时间序列数据或序列 | RNN专门设计用于处理序列数据,使其成为时间序列分析、自然语言处理(NLP)和语音识别等任务的理想选择 | RNN在训练过程中容易出现梯度消失和爆炸问题,这会阻碍学习并使捕捉长期依赖关系变得困难 | [42, 88, 41, 60, 89] |
| 递归神经网络(RvNN) | 递归神经网络(RvNN)是一种特殊的神经网络,用于处理层次数据结构,如自然语言处理中的解析树 | RvNN在处理层次数据结构方面具有卓越的效率,非常适合句法分析和情感分析等任务 | 训练RvNN可能很复杂且计算成本高,尤其是对于大型数据集或非常深的层次结构 | [90, 91] |
| 卷积神经网络(CNN) | CNN通过每层识别输入的更大块,随着数据在层中移动,开始识别对象的更大部分,早期层专注于更简单的特征 | CNN在处理图像方面效率极高,因为它们能够应用捕捉数据中空间层次结构的卷积滤波器 | 训练CNN可能需要大量的计算资源,需要强大的处理能力和内存,尤其是对于大型模型和数据集 | [8, 84, 85, 87, 42, 84, 85] |
| 门控循环单元(GRU) | 与LSTM一样,GRU是循环神经网络中使用的门控机制,但与LSTM不同,它不包含输出门,已证明GRU在某些较小和不太常见的数据集上表现更好 | 与LSTM相比,GRU结构更简单,门更少(重置门和更新门) | 虽然GRU比传统RNN更好地处理长期依赖关系,但在某些复杂任务中可能无法像LSTM那样有效地捕捉它们 | [119-122, 111, 89] |
| 生成对抗网络(GAN) | GAN用于无监督学习,由两个神经网络组成:生成器和判别器。生成器创建类似于真实数据的人工数据,而判别器区分真实数据和虚假数据 | GAN能够生成高度逼真的数据,如图像、视频和音频,几乎无法与真实数据区分 | 由于生成器和判别器之间需要微妙的平衡,GAN可能难以训练 | [95, 96, 115, 123] |
| Transformer | Transformer,特别是在神经网络的背景下,已经彻底改变了各个领域,尤其是自然语言处理 | Transformer可以同时处理整个数据序列,不像RNN那样按顺序处理数据 | Transformer需要大量的计算资源,包括高性能GPU和大量内存,尤其是在训练大型模型时 | [97, 124, 98, 99-101, 102, 125, 65, 126-128, 32] |
| 玻尔兹曼机 | 这是一种随机网络,能够学习输入的复杂分布 | 玻尔兹曼机可以从未标记的数据中学习,使其对无监督学习任务(如特征提取和降维)很有用 | 训练玻尔兹曼机的计算成本很高且速度很慢,尤其是对于具有多层或多个单元的网络 | [58, 106, 85, 59, 110, 63, 95] |
| 集成方法 | 这涉及融合各个深度学习模型的优势,以提高最终模型的整体性能 | 集成方法通常比单个模型实现更高的准确性 | 与单个模型相比,集成模型构建和解释更为复杂 | [113, 9, 33, 129, 113, 116, 3, 115, 117] |
Received 25 April 2025, accepted 14 May 2025, date of publication 21 May 2025, date of current version 30 May 2025.
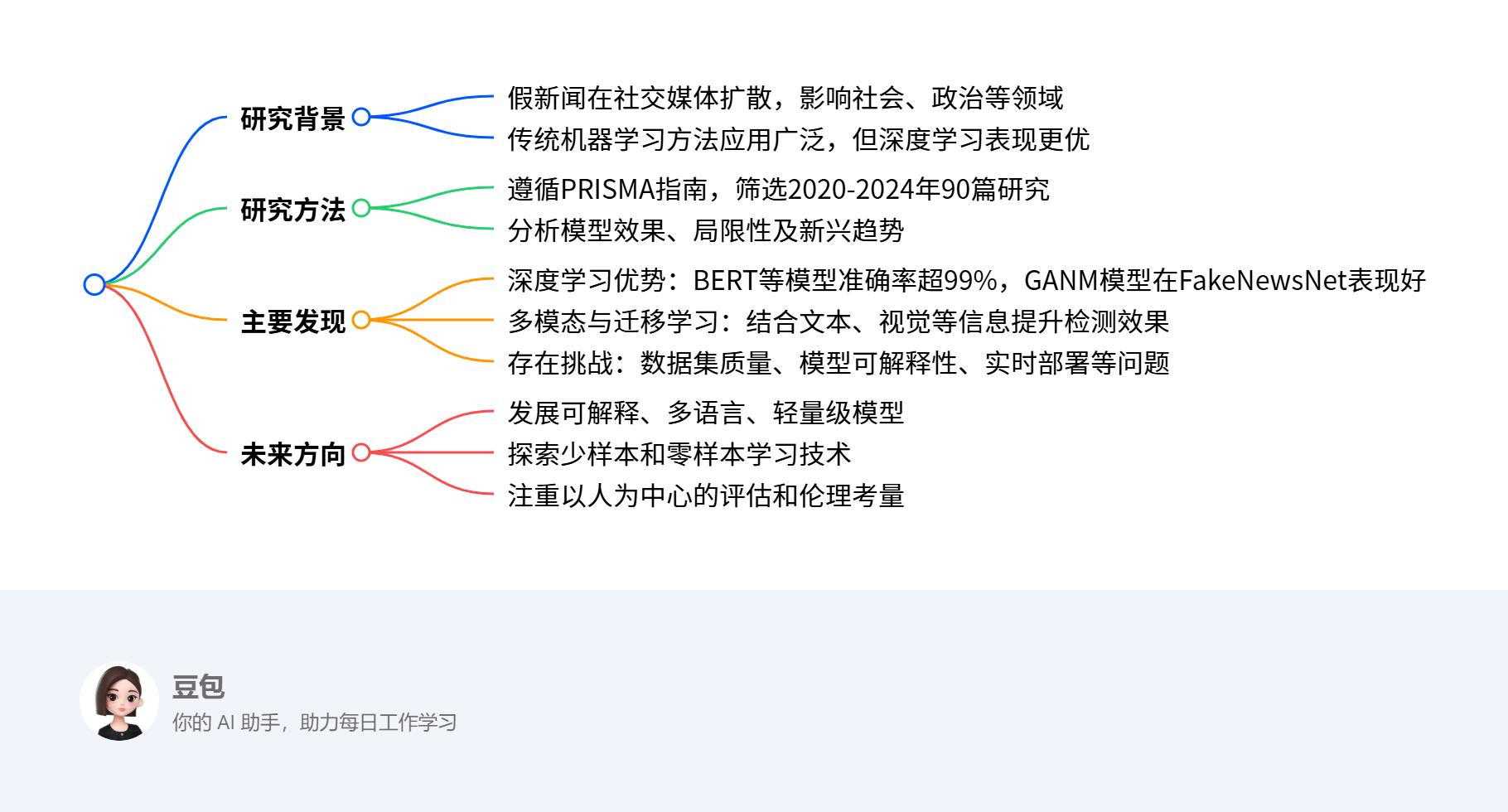
未来研究方向
- 模型发展:可解释、多语言、轻量级模型。
- 学习技术:少样本和零样本学习,用最少训练数据处理新出现的错误信息。
- 评估与伦理:以人为本的评估,注重伦理考量。
6. Unmasking Digital Falsehoods: A Comparative Analysis of LLM-Based Misinformation Detection Strategies (ICAACE, 被引用29次)
摘要:
本文对基于大型语言模型(LLMs) 的虚假信息检测策略进行了比较分析,探讨了文本型、多模态和智能体方法在公共卫生、政治、金融等领域的效果,评估了微调模型、零样本学习和系统事实核查机制的表现,指出混合方法(结合结构化验证协议与自适应学习技术)对提升检测准确性和可解释性的重要性,同时识别了幻觉、对抗攻击、计算资源等关键挑战,并提出实时跟踪、联邦学习等未来研究方向。
思维导图(mindmap):

详细总结:
一、研究背景与目标
- 背景:社交媒体的普及加速了虚假信息传播,LLMs既加剧了这一问题(大规模生成可信虚假信息),也为检测提供了可能(基于先进自然语言理解能力)。
- 研究目标:
- 分析LLMs在不同领域(政治、公共卫生、金融)检测虚假信息的可用性;
- 比较文本型与多模态方法的有效性;
- 基于标准化数据集(如FakeNewsNet、SciNews、MMCOVID)评估模型性能。
二、虚假信息分类与检测挑战
-
虚假信息类型与特征(表1):
类型 定义 特征 假新闻 故意编造或误导性信息,伪装成合法新闻 利用耸人听闻内容和情感吸引力,旨在欺骗受众 谣言 未经证实的信息快速传播 由不确定性和猜测推动,缺乏可信来源 阴谋论 声称重大事件背后有恶意隐藏力量 缺乏可信证据,但能迎合寻求解释的人群 -
检测挑战:
- 语境模糊与意图检测:讽刺、观点与故意虚假信息难区分;
- 可扩展性与泛化性:模型需适应不断演变的虚假信息,跨语言/领域/平台泛化难;
- 资源限制:实时检测需大量计算资源;
- 方法特有挑战:文本方法难处理讽刺,多模态方法面临跨模态整合问题,混合方法应用复杂。
三、LLM-based检测方法比较
-
文本型vs多模态vs智能体方法:
- 文本型:依赖语言信号和事实核查,如混合注意力框架(整合统计与语义特征)、FactAgent(分步拆解任务);
- 多模态:处理文本+视觉/听觉输入,如SNIFFER(提升检测质量但增加特征匹配复杂度);
- 智能体模型(如FactAgent):分步推理、可解释但响应慢;非智能体模型(如GPT-4):端到端处理、速度快但黑箱化。
-
零样本vs微调:
- 零样本(如GPT-4):跨域适应性强,无需微调;
- 微调模型(如SciNews):特定领域(科学/医学)精度更高,但泛化性差。
四、性能评估
-
评估指标:
- 标准指标:准确率、precision、召回率、F1分数;
- 可靠性指标:Cohen’s Kappa、Matthews相关系数(MCC,适用于不平衡数据);
- 效率指标:推理速度、资源消耗。
-
基准数据集:
- 文本数据集:SciNews(科学领域)、LIAR(政治虚假信息);
- 多模态数据集:MM-COVID、PHEME(含文本、图像、元数据)。
-
模型性能对比(表3):
模型 数据集 准确率(%) F1分数(%) 可解释性 GPT-4 SciNews 85.3 81.5 低 FactAgent LIAR 91.2 87.8 高 SNIFFER MM-COVID 88.9 85.2 中
五、可解释性与未来方向
- 可解释性方法:LIME(局部近似)、SHAP(特征重要性评分)、集成梯度(文本归因);
- 未来方向:实时跟踪虚假信息、联邦学习、跨平台检测模型、混合方法优化。
关键问题
-
问题:不同类型的LLM-based虚假信息检测方法在性能与适用场景上有何核心差异?
答案:文本型方法擅长处理语言信号,但难应对讽刺等语境 subtleties;多模态方法(如SNIFFER)通过整合文本与视觉输入提升准确性,适用于含图像/视频的虚假信息,但需大量计算资源;智能体模型(如FactAgent)可解释性强,适合需要透明流程的场景,非智能体模型(如GPT-4)速度快,适合实时检测但黑箱化。零样本方法跨域适应性强,微调模型在特定领域(如科学)精度更高(准确率:FactAgent在LIAR上达91.2%,GPT-4在SciNews上为85.3%)。 -
问题:LLM-based虚假信息检测面临的主要挑战及潜在解决思路是什么?
答案:主要挑战包括语境模糊(难区分讽刺与故意虚假信息)、泛化性差(模型在训练外领域表现不佳)、计算资源需求高(实时检测压力大)、对抗攻击等。解决思路包括采用混合方法(结合结构化验证与自适应学习)、利用联邦学习减少数据依赖、开发跨模态整合技术(如SNIFFER的文本-视觉对齐)、引入人类参与的循环机制应对演变的虚假信息趋势。 -
问题:可解释性在虚假信息检测中为何重要?不同模型在可解释性上有何差异?
答案:可解释性是建立用户信任、实现系统审计的关键,能帮助识别模型的偏差与错误。智能体模型(如FactAgent)通过分步结构化验证流程,可解释性高;非智能体模型(如GPT-4)为黑箱模型,透明度低;多模态模型(如SNIFFER)虽因跨模态分析增加解释难度,但通过视觉-文本对齐模块提升了可理解性,总体可解释性中等。
7. Forensics-Bench: A Comprehensive Forgery Detection Benchmark Suite for Large Vision Language Models (CVPR)
摘要:
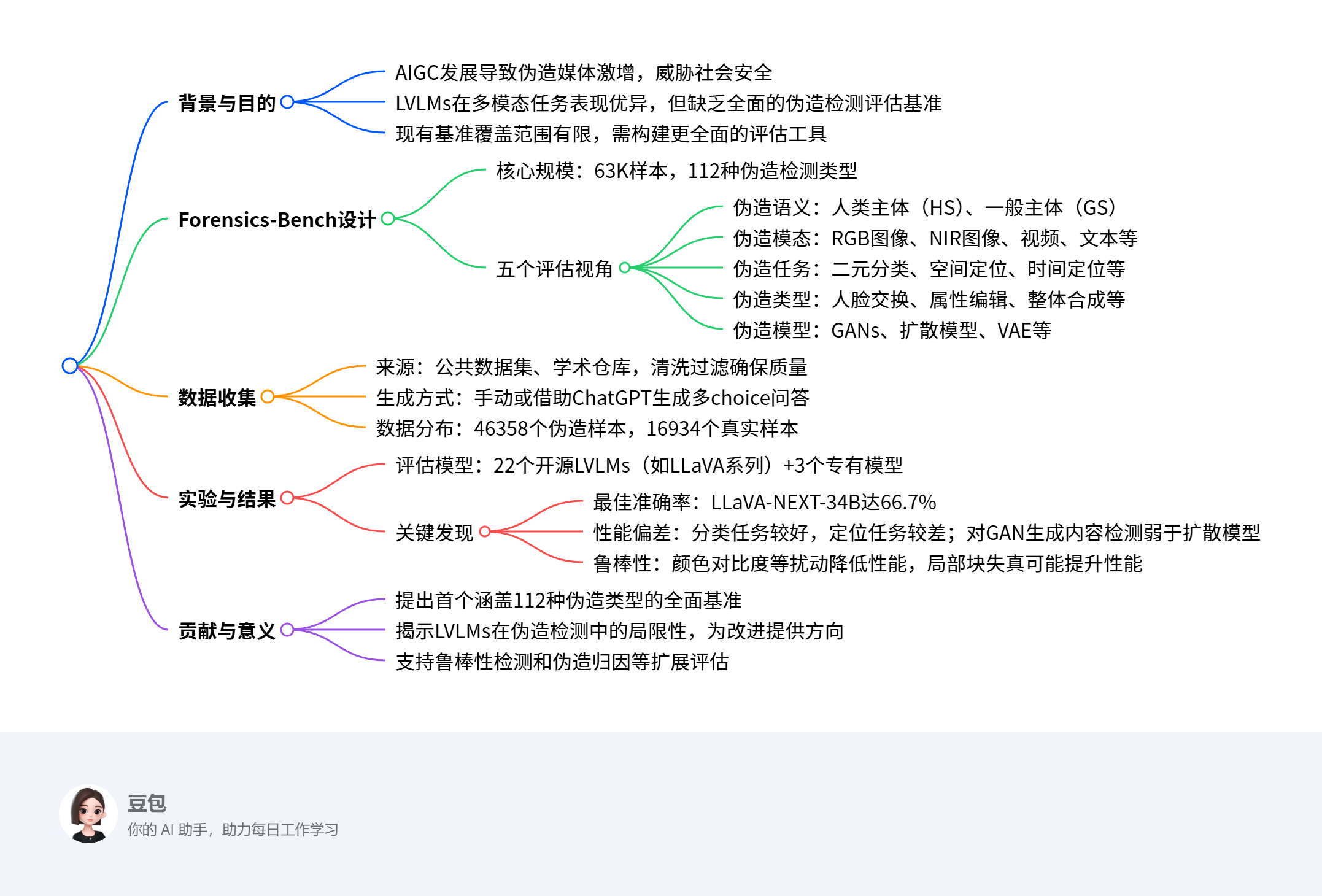
Forensics-Bench是一个用于全面评估大型视觉语言模型(LVLMs)伪造检测能力的基准套件,包含63,292个精心设计的多 choice视觉问题,覆盖从伪造语义、模态、任务、类型和模型五个视角划分的112种独特伪造检测类型。研究通过该基准对22个开源LVLMs和3个专有模型(如GPT-4o、Gemini 1.5 Pro)进行评估,发现最先进的LVLMs在该基准上的最佳整体准确率仅为66.7%,且存在显著性能偏差——在分类任务上表现较好,而在空间和时间定位任务上表现不佳,对不同伪造类型(如人脸交换)和生成模型(如GANs)的检测能力差异较大。该基准旨在推动LVLMs在AIGC时代朝着全面伪造检测能力发展。
思维导图:
详细总结:
1. 研究背景与目的
- 随着AIGC技术的快速发展,伪造媒体(如深度伪造、虚假信息)泛滥,对政治、法律和社会安全构成前所未有的威胁。
- 大型视觉语言模型(LVLMs)在多模态任务中表现出色,被视为检测多样化伪造媒体的潜在解决方案,但缺乏全面的评估基准,阻碍了其在伪造检测中的应用和发展。
- 现有基准(如FakeBench、MMFakeBench)覆盖的伪造类型有限,无法全面评估LVLMs的伪造检测能力,因此需要构建更全面的基准套件——Forensics-Bench。
2. Forensics-Bench的设计与规模
- 核心规模:包含63,292个多 choice视觉问题,覆盖112种独特的伪造检测类型,其中伪造样本46,358个,真实样本16,934个。
- 五个评估视角(如图1所示):
- 伪造语义:分为人类主体(HS)和一般主体(GS),评估LVLMs对不同内容的检测偏差。
- 伪造模态:包括RGB图像、NIR图像、视频、文本等,评估LVLMs在不同模态下的性能差异。
- 伪造任务:涵盖二元分类(判断真伪)、空间定位(分割掩码/边界框)、时间定位(视频伪造帧定位)等,覆盖主流伪造检测场景。
- 伪造类型:包括人脸交换(单/多脸)、属性编辑、整体合成、风格转换等21种类型。
- 伪造模型:涉及GANs、扩散模型(DF)、VAE等22种生成模型,评估LVLMs对不同生成来源的识别能力。
3. 数据收集与构建
- 数据来源:从公共数据集和学术仓库中检索相关数据,涵盖多种伪造类型,同时包含合成数据和真实数据,以反映实际挑战。
- 构建流程:
- 整理检索到的数据集为统一元数据格式;
- 手动或借助ChatGPT生成多 choice问答样本,确保问题与答案的相关性和公平性。
4. 与现有基准的对比
| 基准名称 | 样本量 | 语义覆盖 | 模态数量 | 任务数量 | 类型数量 | 模型数量 |
|---|---|---|---|---|---|---|
| FakeBench | 54K | 人类&一般主体 | 1 | 2 | - | - |
| MMFakeBench | 11K | 人类主体 | 12 | 2 | - | - |
| MFC-Bench | 35K | 人类&一般主体 | 9 | - | - | - |
| Forensics-Bench | 63K | 人类&一般主体 | 21 | 22 | 21 | 22 |
5. 实验设置与结果
- 评估模型:22个开源LVLMs(如LLaVA-NEXT-34B、InternVL-Chat-V1-2)和3个专有模型(GPT-4o、Gemini 1.5 Pro、Claude 3.5 Sonnet)。
- 关键发现:
- 整体性能:最佳模型LLaVA-NEXT-34B的整体准确率仅为66.7%,表明Forensics-Bench对现有LVLMs构成显著挑战。
- 性能偏差:
- 伪造类型:在欺骗(spoofing)、风格转换等类型上表现接近100%,但在多脸交换、人脸编辑等类型上准确率低于55%。
- 任务类型:在分类任务上表现较好,在空间和时间定位任务上表现较差。
- 生成模型:对扩散模型生成的伪造内容检测效果优于GANs。
- 专有模型vs开源模型:开源模型(如LLaVA系列)整体表现优于专有模型,因专有模型回答更保守。
6. 扩展评估协议
- 鲁棒性检测:评估LVLMs在6种扰动(如颜色饱和度变化、局部块失真)下的性能,发现颜色对比度变化对性能影响较大,而局部块失真可能提升性能。
- 伪造归因:评估LVLMs识别伪造媒体生成模型的能力,结果显示现有模型在该任务上表现有限(最佳准确率44.0%)。
7. 研究贡献
- 提出首个涵盖112种伪造检测类型的全面基准Forensics-Bench;
- 对25个先进LVLMs进行全面评估,揭示其性能局限性和偏差;
- 提供鲁棒性检测和伪造归因等扩展评估视角,为LVLMs的改进提供方向。
关键问题:
-
Forensics-Bench与现有伪造检测基准相比,核心优势是什么?
答:Forensics-Bench的核心优势在于其全面性,具体表现为:样本量更大(63K),覆盖的伪造语义更全(人类主体+一般主体),模态更多(21种),任务类型更丰富(22种),涵盖的伪造类型(21种)和生成模型(22种)更多,能更全面评估LVLMs的伪造检测能力,而现有基准在这些维度上覆盖有限。 -
现有LVLMs在伪造检测任务中存在哪些主要局限性?
答:现有LVLMs的主要局限性包括:整体准确率较低(最佳仅66.7%);对不同伪造类型存在显著性能偏差(如多脸交换准确率低于55%);在空间和时间定位任务上表现不佳;对GANs生成的伪造内容检测能力弱于扩散模型;在面对颜色对比度等扰动时性能下降明显,且伪造归因能力有限。 -
Forensics-Bench的构建对AIGC时代的伪造检测研究有何意义?
答:其意义在于:为LVLMs提供了一个全面的评估工具,揭示了现有模型在伪造检测中的局限性和偏差,有助于研究者更深入理解LVLMs的能力边界;推动社区开发更鲁棒、全面的伪造检测器,以应对AIGC技术带来的多样化伪造威胁,助力LVLMs向更高级的AGI发展。


















 495
495

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











