







目录
0.进程创建
相比大家对下面这段代码已经不陌生了,我们在介绍fork()的时候就已经写过一遍了,fork()有两个返回值,同一个pid会有不同的值,这是上篇我们说到的伪内存问题。而本篇我们要看看fork()创建时,操作系统会干什么事情?
#include <unistd.h>
pid_t fork(void); 返回值:自进程中返回0,父进程返回子进程id,出错返回-1
进程调用fork,当控制转移到内核中的fork代码后,内核做:
- 分配新的内存块和内核数据结构给子进程
- 将父进程部分数据结构内容拷贝至子进程
- 添加子进程到系统进程列表当中
- fork返回,开始调度器调度
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int main()
{
pid_t id = fork();
if(id == 0)
{
//child
while(1)
{
printf("我是子进程,pid = %d,ppid = %d\n",getpid(),getppid());
sleep(1);
}
}
else
{
while(1)
{
printf("我是父进程,pid = %d,ppid = %d\n",getpid(),getppid());
sleep(1);
}
}
return 0;
}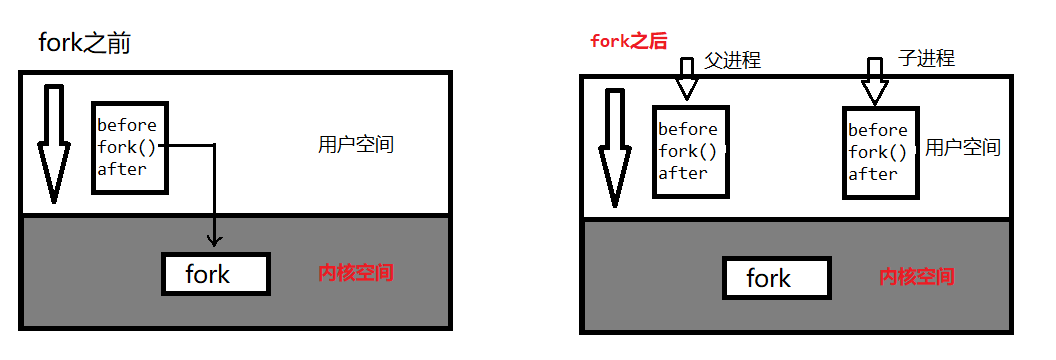
当一个进程调用fork之后,就有两个二进制代码相同的进程,而且他们都运行在相同的地方。但是每个进程都将可以开始他们自己的旅程。
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int main()
{
printf("我是一个进程:pid = %d\n",getpid());
fork();
printf("我依旧是一个进程:pid = %d\n",getpid());
return 0;
}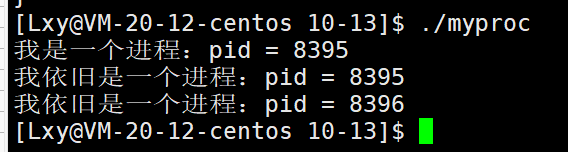
当我们运行完时发现,fork()之后代码共享。
fork()之前父进程独立执行,fork()之后,父子两个执行流分别执行。
那么fork()之后是否之后fork()之后的代码被父子进程共享的??
结论:一般情况下,fork()之后,父子共享所有的代码 ,因此fork()之后,父进程共享了全部的代码,只不过子进程只能从fork开始执行。子进程继承了父进程的eip(程序计数器),但是如果子进程想找到之前的代码也是可以的。
fork()之后,操作系统做了什么?
我们都知道进程=内核的进程数据结构+进程的代码和数据。当fork()创建的时候是创建子进程的内核数据结构(struct tast_struct + struct mm_struct... + 页表) + 代码继承父进程,数据以写实拷贝的形式来共享或者独立!因此,fork()之后,操作系统创建结构,代码以共享的形式,数据以是写实拷贝的形式来实现两个进程整体保持独立性!也就是说,父进程或者子进程如果有一方进程挂掉,不会影响另一方。
写时拷贝
通常,父子代码共享,父子再不写入时,数据也是共享的,当任意一方试图写入,便以写时拷贝的方式各自一份副本。具体见下图:
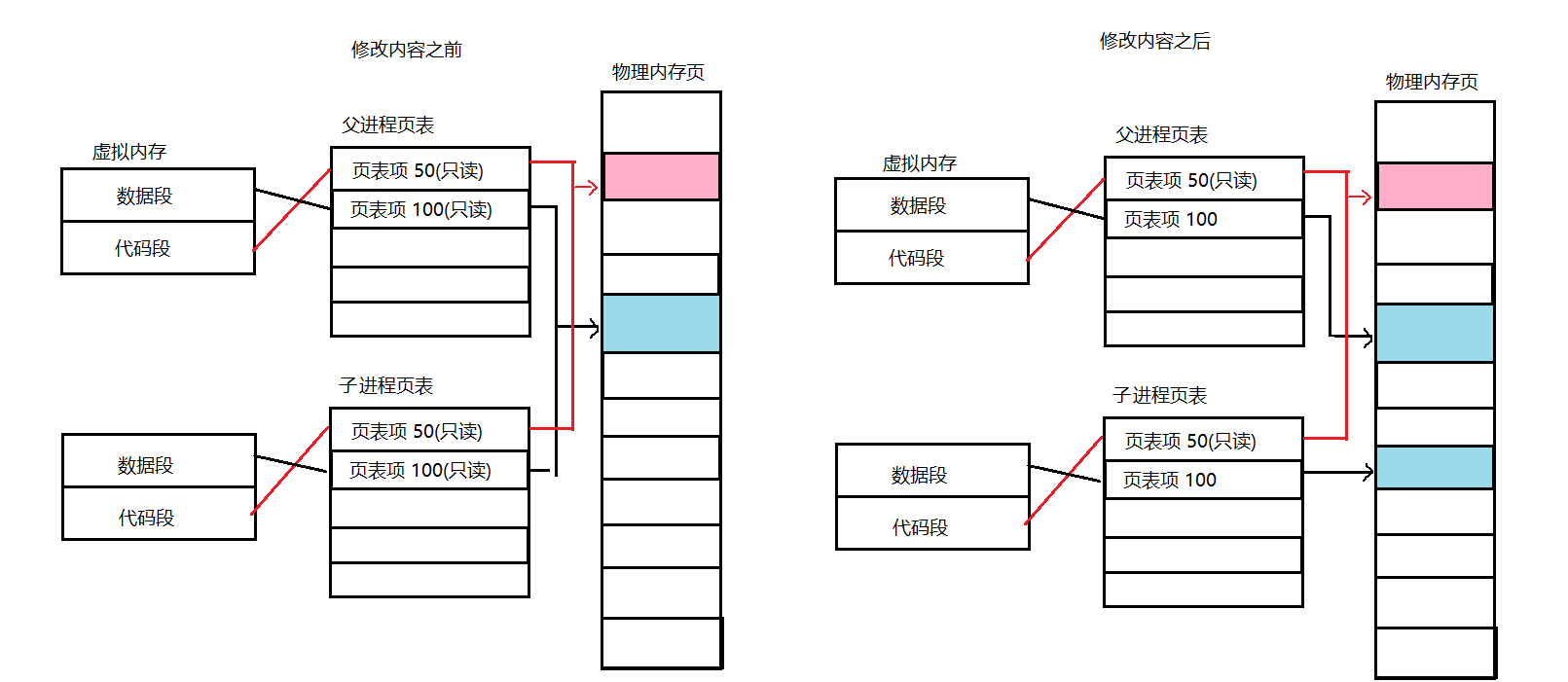
那么为什么要写时拷贝?在创建子进程的时候就把数据分开不行吗?
答案是不行的,具体原因有一下三点:
- 父进程的数据,子进程不一定全用,即使使用,也不一定全部写入 ,因此会有浪费空间的嫌疑
- 最理想的情况,只有会被父子修改的数据进行分离拷贝,不需要修改的共享即可--但是从技术角度实现很复杂
- 如果fork的时候,就无脑拷贝数据的子进程,会增加fork的成本(内存和时间)
所以最终采用写时拷贝。只会拷贝父子修改的数据,变相的就是拷贝数据的最小成本,但是拷贝的成本依然存在。之所以写时,是因为这是延迟拷贝的策略,只有真正使用的时候操作系统再给你分配资源。因此这种写时拷贝变相的提高内存的使用率。
fork调用失败的原因
- 系统中有太多的进程
- 实际用户的进程数超过了限制
1.进程终止
关于终止的认识
我们在写C/C++程序的时候,每个程序都有一个main函数,这个函数也叫做入口函数。我们经常会习惯的写上
return 0 ,那么这里将会产生两个问题:
- return 0 给谁返回?
- 必须返回0吗?返回别的数字可以吗?
此时我们首先要了解到进程退出的场景:
- 代码跑完,结果正确
- 代码跑完,结果不正确
- 代码没跑完,程序异常了
任何一个程序无外乎这三种退出场景,本篇文章主要介绍前两种场景。我们将举一个例子来加什么对这两种场景的认识和理解:假设张三要参加期末考试,他无非就3中情况:1.正常参加考试,考了100分。2.正常参加考试,考了20分。3.为正常参考,原因也多种多样。类比到这里,我们也能够理解,一个程序也无外乎这三种情况,代码跑完,结果正确;代码跑完,结果不正确;代码未跑完,程序发生异常。就好比我们写一个排序算法要将一组数据进行排序要么代码跑完,排序成功;要么程序跑完,排序失败;要么程序都压根没跑完。
我们用0表示sucess结果正确,非0表示结果失败。(非0标识不同的原因也不同)
因此retun X(X叫做进程退出码)进程退出码表征了进程退出的信息,这个进程退出信息将来要将父进程读取的。因此这个退出信息码非常的重要。因此我们这里回答了return是给父进程返回
我们写一段程序验证一下
#include <stdio.h>
int main()
{
return 123;
}
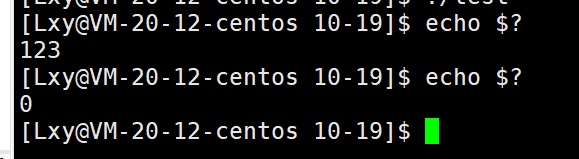
当我们运行这个代码的时候,该进程的父进程是bash,因此这个程序的退出码我们可以使用bash下的命令echo来查看退出码
echo $?
$?
这个$?表示在bash中,最近一次执行完毕时,对应进程的退出码!当我们再查看一次的时候发现是0,大家也不要觉得奇怪。这是因为在shell看来,echo $?这条命令也被当成是一个进程(虽然他不是),因此就会变成了0
进程退出码
在我们刚刚说正常退出 进程退出码是0 0表示success,那么异常退出的时候其他的退出码都表示什么含义呢?
比如这里看一个ls 跟上一串随机字符,我们查看退出码就为2(非0)

因此,一般而言,失败的零值该如何设置呢?以及默认表达的含义?这里我们大家也不需要刻意记忆每个进程退出码对应的含义,因为我们可以自定义来设置,或者用的时候查一查就行。那么我们现在看看系统的代码是什么含义,我们可以使用strerror函数进行查看(下图为man帮助手册查看的strerror的作用及其用法)

#include <stdio.h>
#include <string.h>
int main()
{
int i = 0;
for(;i<100;++i)
{
printf("%d:%s\n",i,strerror(i));
}
return 0;
}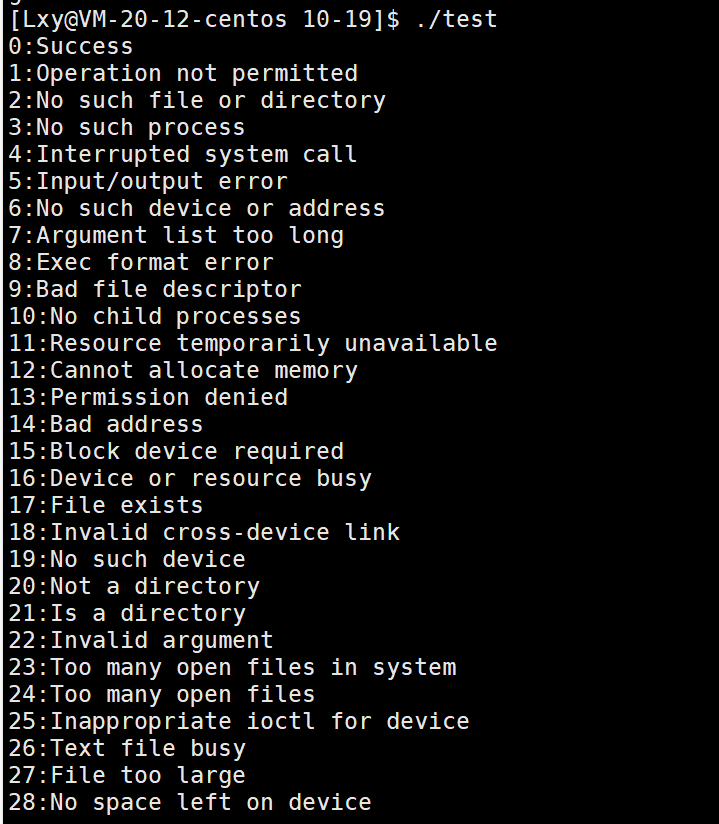
我们在这里大概看几个,我们看到0表示success,1表示权限不允许(可执行程序),2表示找不到文件
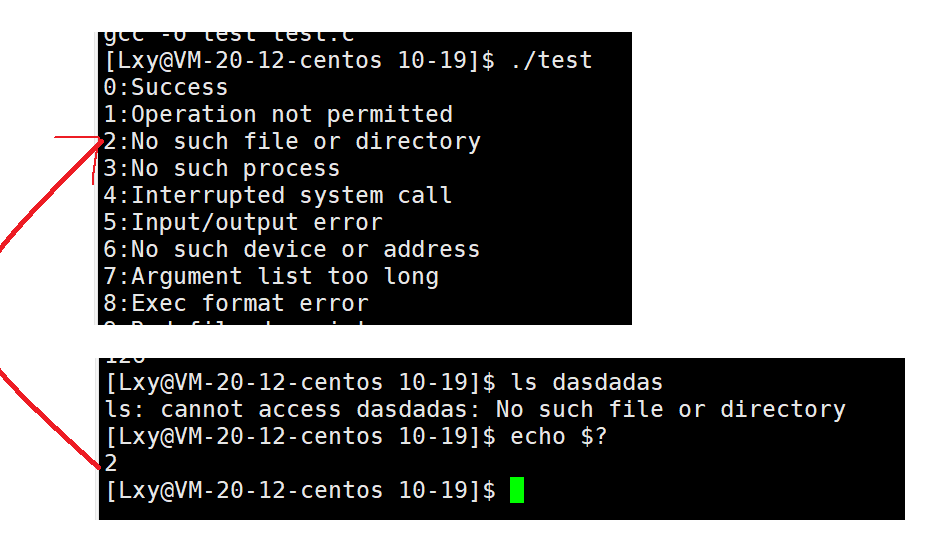
因此我们可以得出结论:不同的进程退出码可以对应不同错误原因。
进程终止的常见做法
一般我们有两种做法最常见:
- 在main函数中return,代表进程结束,非main函数return表示函数调用结束,为什么其他函数不行呢?
- 在自己的代码中任意地点中,调用exit(),即使非main函数也可以退出
exit
我们来看看exit的用法
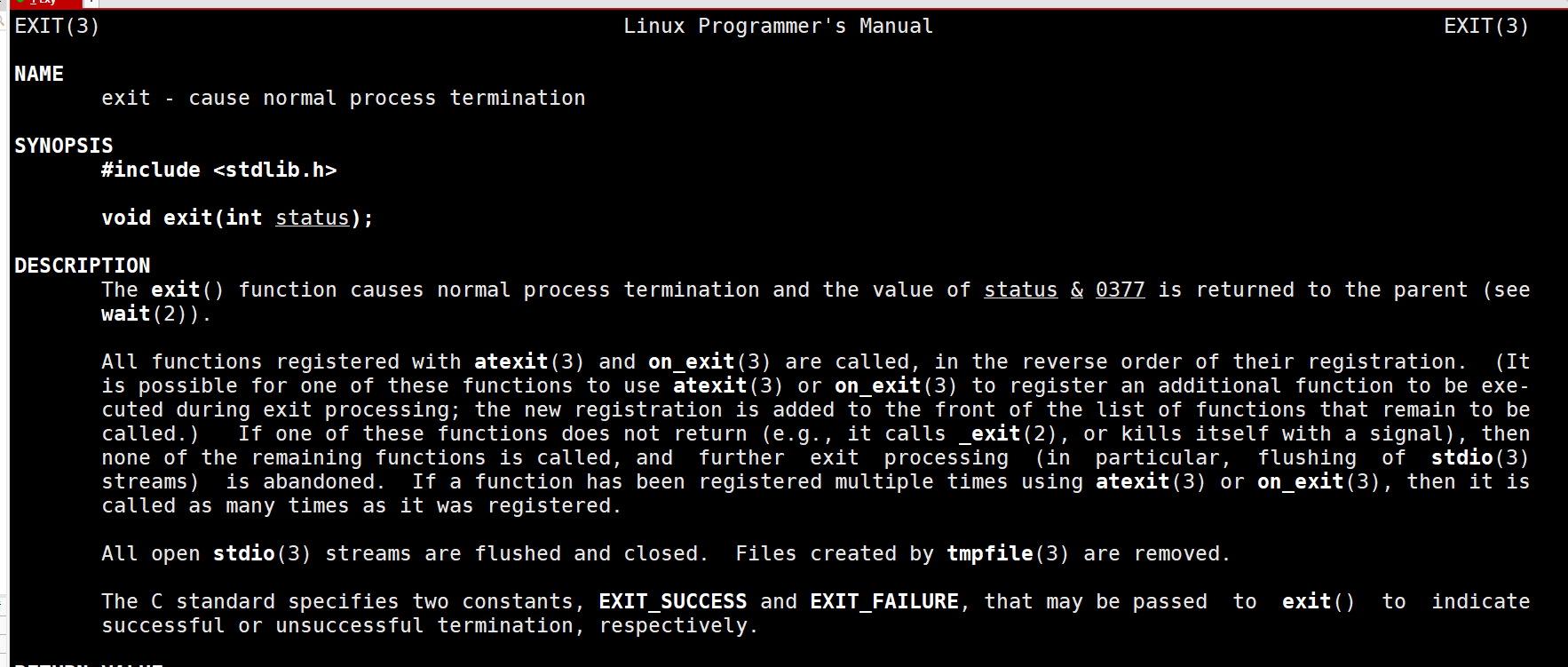
我们写一段简单的程序看看
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
void fun()
{
printf("fun()\n");
exit(20);
}
int main()
{
fun();
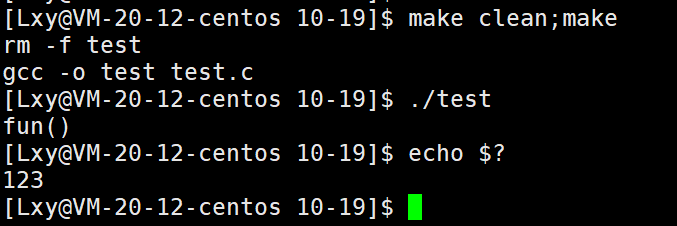
return 123;
}我们执行这段代码,我们通过查看进程退出码可以确定该程序是从exit推出的还是return出去的。通过结果我们可以看到,程序是从exit退出的。
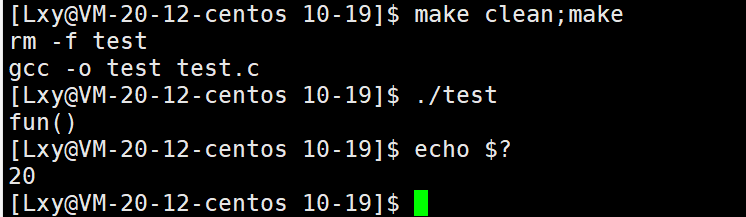
因此如果以后我们想终止一个进程,可以在想终止的地方调用exit()。
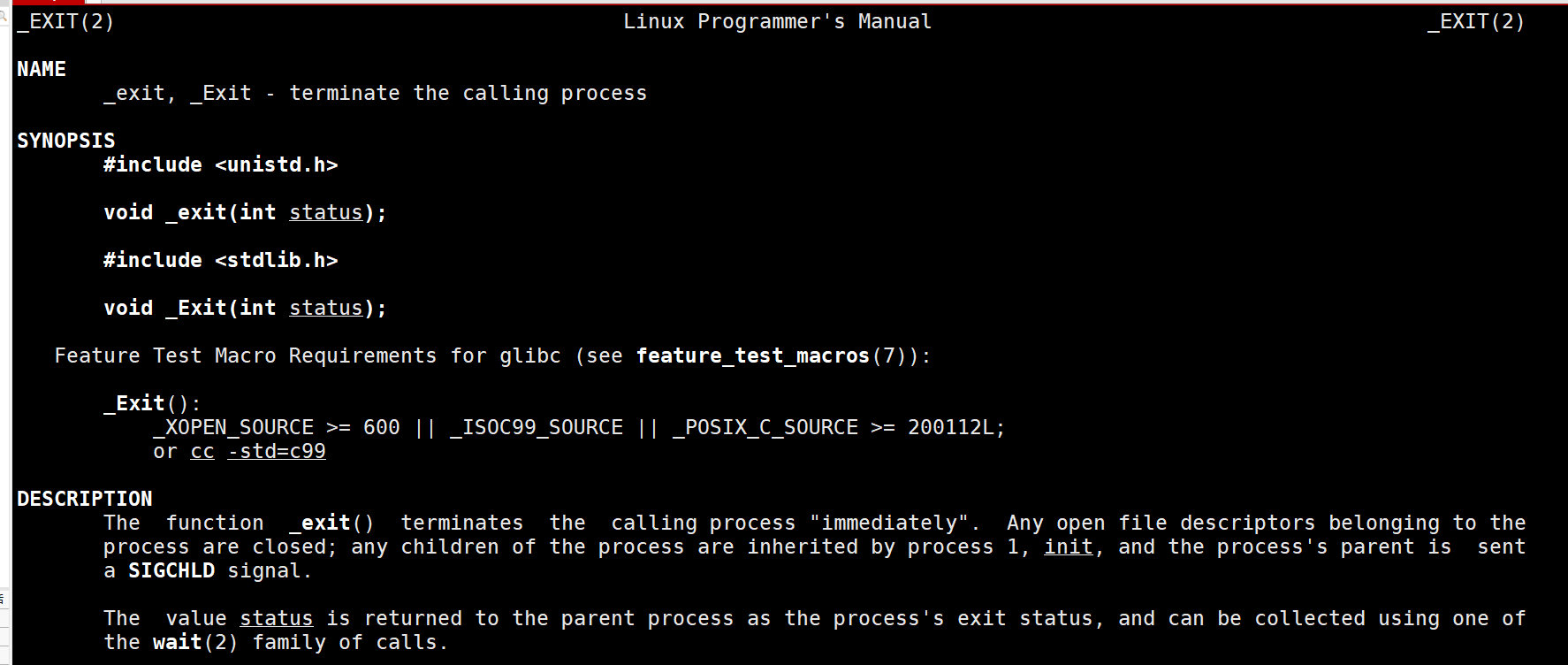
_exit
这里我们之所以介绍_exit仅仅是因为他和我们刚刚介绍的exit长得很像,我们在这里也不需要特别记忆_exit的用法。在此处,我们就简单介绍一下_exit如何使用,以及_exit和exit的区别。
我们通过查看_exit发现,_exit是一个系统调用,其实exit调用了_exit。
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <unistd.h>
void fun()
{
printf("fun()\n");
_exit(123);
}
int main()
{
fun();
return 20;
}
此时我们发现_exit和exit好像没有什么区别,实际上他俩还是有区别的,我们来看看下面这段代码
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <unistd.h>
int main()
{
printf("hello world");
sleep(1);
exit(111);
return 20;
}我们首先使用exit来提前终止进程,我们查看结果发现hello world能够被刷新出来

而当我们在调用_exit时,显示器什么也没输出。
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <unistd.h>
int main()
{
printf("hello world");
sleep(1);
_exit(111);
return 20;
}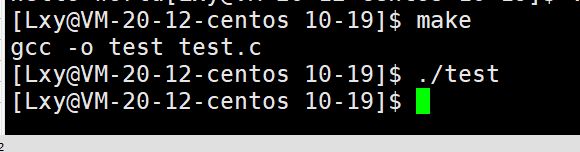
结论:exit终止进程会刷新缓冲区 _exit终止进程不会刷新缓冲区(_exit我们就了解这么多)
关于终止,内核做了什么?
进程 = 内核结构 + 进程代码和数据
当进程终止时,代码和数据一定会被释放掉。对于内核结构(tast_struct && mm_struct),操作系统可能并不会释放该进程的内核数据结构。
(本篇完)
















 315
315











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











