







目录
一 线程说明
Linux 实现线程的机制非常独特。从内核的角度来说,它并没有线程这个概念。 Linux 把所有的线程都当做进程来实现。内核并没有准备特别的调度算法或是定义特别的数据结构来表示线程。线程只被视为一个与其他进程共享某些资源的轻量级进程。所以在内核中,它看起来就像是一个普通的进程(只是线程和其他一些进程共享某些资源,如地址空间)
①线程与进程:
①所有的轻量级进程(线程)都是在进程的内部运行;
②进程是资源分配的最小单位,线程是程序执行的最小单位;
③进程具有独立性,可以有部分共享资源(比如:管道,IPC资源);
④线程大部分资源是共享的(例如:代码、进程数据、文件描述符、信号处理方式),可以有部分资源是私有的(例如:PCB、栈、上下文);
★ 每个线程是有自己的独立栈,保存线程运行时形成的临时数据;上下文中保存的是CPU调度时存放在寄存器中的临时数据。
| 线程 | 进程 | |
| 标识符类型 | pthread_t | pid_t |
| 获取id | pthread_self() | getpid() |
| 创建 | pthread_create() | fork() |
②线程优点:
① 创建一个新线程的代价要比创建一个新进程小得多;
② 与进程之间的切换相比,线程之间的切换需要操作系统做的工作要少很多;
③ 线程占用的资源要比进程少很多;
④ 能充分利用多处理器的可并行数量;
⑥ 在等待慢速I/O操作结束的同时,程序可执行其他的计算任务;
⑦ 计算密集型应用,为了能在多处理器系统上运行,将计算分解到多个线程中实现;
⑧ I/O密集型应用,为了提高性能,将I/O等待就绪操作重叠。线程可以同时等待不同的I/O操作;
③线程缺点:
① 性能损失:一个很少被外部事件阻塞的计算密集型线程往往无法与共它线程共享同一个处理器。如果计算密集型 线程的数量比可用的处理器多,那么可能会有较大的性能损失,这里的性能损失指的是增加了额外的 同步和调度开销,而可用的资源不变;
② 健壮性降低:编写多线程需要更全面更深入的考虑,在一个多线程程序里,因时间分配上的细微偏差或者因共享了 不该共享的变量而造成不良影响的可能性是很大的,换句话说线程之间是缺乏保护的;
③ 缺乏访问控制:进程是访问控制的基本粒度,在一个线程中调用某些OS函数会对整个进程造成影响;
④ 编程难度提高:编写与调试一个多线程程序比单线程程序困难得多。
二 线程开发API概要
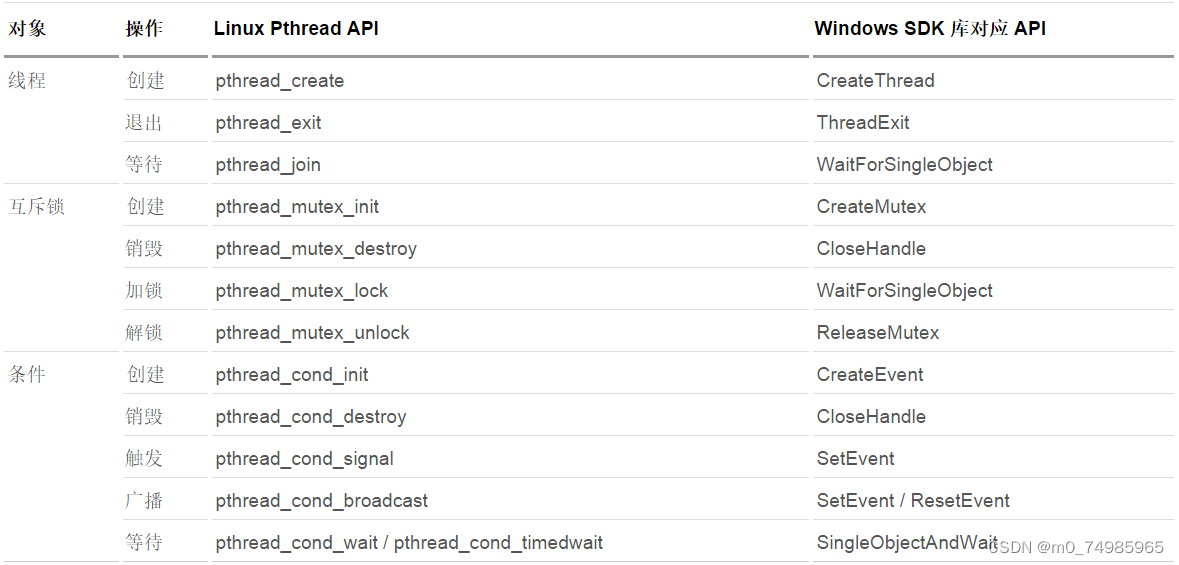
多线程开发在 Linux 平台上已经有成熟的 pthread 库支持。其涉及的多线程开发的最基本概念主要包含三点:线程,互斥锁,条件。其中,线程操作又分线程的创建,退出,等待 3 种。互斥锁则包括 4 种操作,分别是创建,销毁,加锁和解锁。条件操作有 5 种操作:创建,销毁,触发,广播和等待。其他的一些线程扩展概念,如信号灯等,都可以通过上面的三个基本元素的基本操作封装出来。详细请见下表:
三 线程控制流程
本篇文章先说明线程的创建,等待,退出这三个API;
-
使用-pthread编译和链接。
① 线程创建(pthread_create)
#include <pthread.h> int pthread_create(pthread_t *thread, const pthread_attr_t *attr,void *(*start_routine) (void *), void *arg); //返回值:成功返回0,失败返回错误编号pthread_t *thread:线程ID,由函数pthread_self()获取,类似获取进程pid使用getpid()函数;
const pthread_attr_t *attr:用于定制各种不同的线程属性,暂可以把它设置为NULL,以创建默认属性的线程;
void *(*start_routine) (void *):线程中执行函数。新创建的线程从start_rtn函数的地址开始运行,该函数只有一个无类型指针参数arg
void *arg:执行函数中中参数。如果需要向start_rtn函数传递的参数不止一个,那么需要把这些参数放到一个结构体中,然后把这个结构的地址作为arg参数传入
② 线程退出(pthread_exit)
单个线程可以通过以下三种方式退出,在不终止整个进程的情况下停止它的控制流:
1)线程只是从启动例程中返回,返回值是线程的退出码。
2)线程可以被同一进程中的其他线程取消。
3)线程调用pthread_exit:
#include <pthread.h> int pthread_exit(void *rval_ptr);rval_ptr:是一个无类型指针,与传给启动例程的单个参数类似。进程中的其他线程可以通过调用pthread_join函数访问到这个指针。
③ 线程等待(pthread_join)
#include <pthread.h> int pthread_join(pthread_t thread, void **rval_ptr); // 返回:若成功返回0,否则返回错误编号调用这个函数的线程将一直阻塞,直到指定的线程调用pthread_exit、从启动例程中返回或者被取消。如果例程只是从它的启动例程返回,rval_ptr将包含返回码。如果线程被取消,由rval_ptr指定的内存单元就置为PTHREAD_CANCELED。①可以通过调用pthread_join自动把线程置于分离状态,这样资源就可以恢复。如果线程已经处于分离状态,pthread_join调用就会失败,返回EINVAL。②如果对线程的返回值不感兴趣,可以把rval_ptr置为NULL。在这种情况下,调用pthread_join函数将等待指定的线程终止,但并不获得线程的终止状态。
④ 线程脱离(pthread_detach)
一个线程或者是可汇合(joinable,默认值),或者是脱离的(detached)。当一个可汇合的线程终止时,它的线程ID和退出状态将留存到另一个线程对它调用pthread_join。脱离的线程却像守护进程,当它们终止时,所有相关的资源都被释放,我们不能等待它们终止。如果一个线程需要知道另一线程什么时候终止,那就最好保持第二个线程的可汇合状态。
pthread_detach函数把指定的线程转变为脱离状态。
#include <pthread.h> int pthread_detach(pthread_t thread); // 返回:若成功返回0,否则返回错误编号本函数通常由想让自己脱离的线程使用,就如以下语句:
pthread_detach(pthread_self());
⑤ 线程ID获取(pthread_self)
#include <pthread.h>
pthread_t pthread_self(void);
// 返回:调用线程的ID四 完整代码示例
#include <pthread.h>
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
void *func(void *arg)//定义执行函数func
{
static int ret = 10;//定义tid2线程退出码
printf("tid2:%lu\n",pthread_self());//
printf("pid2:%d\n",getpid());//进程id
pthread_exit((void *)&ret);//结束线程tid2
}
int main()
{
int *pret;
pthread_t tid1;//定义主线程
pthread_t tid2;//定义子线程
pid_t pid1;//进程id
pid_t pid2;//进程id
printf("tid1:%lu\n",pthread_self());//打印主线程id
printf("pid1:%d\n",getpid());//打印进程id
pthread_create(&tid2,NULL,func,NULL);//创建线程tid2
pthread_join(tid2,(void **)&pret);//等待线程tid2退出,获取退出状态码
printf("tid2 exit retval:%d\n",*pret);//打印线程退出的状态码
return 0;
}代码执行结果:进程id一样,线程id不一样,说明在同一个进程中执行了两条不同的线程,获取到已经定义好的退出状态码10。
dhw@dhw-virtual-machine:~/thread$ ./a.out
tid1:140212273063744
pid1:6791
tid2:140212273059392
pid2:6791
tid2 exit retval:10

















 5265
5265











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











