






在开始之前,首先介绍下语法结构:select-from-where-group by-having-order by-limit
运行结构:from-where-group by-having-order by-limit-select
一、基础语句
1.select
select name,continent from world

2.where
3.select as
同1。as可以用空格代替。
4.distinct去重
加在select后,不是字段前(会报错)。

5.多字段提取

6.提取全部列
select * from world
7.where用法

!= 不等于
between and 介于x和y之间
='null' / is null 是空值(一个是字符串一个是数值型空值)
例如:

二、其他
1.模糊查询
like用法
通配符:%表示任意位数组字母;占位符: _ 表示一位数字字母。

2.排序
order by用法

若按A和B排序,那么A排序后成A1A2A3后,B1B2B3将在A1A2A3内分别排序。
desc:降序从大到小;asc:默认的升序,从小到大。

order by subject in ('chemistry')——按subject排序,in后的chemistry记为1,其他即为0,其他科目在0内排序,0和1按升序,先0后1,从小到大排序。
3.limit
limit x,取前x位
limit x,n 从x+1开始取n行
例:取面积前三的国家

取人口排名4-7的国家

4.聚合函数
聚合函数group by 常与avg(平均),count(*)(所有行),sum(总和)等函数组合运算。
sum/avg/min/max这些函数必须指定字段运算,无法使用通配符*。
在单独使用groupby时,运行逻辑为同样的字符会分区,然后对各个分区去重后分组:

然后根据group by运行结果进行聚合运算,如:怎么查询每个大洲的国家数量?

group by运行逻辑就是先对字段分区,再对每个区分成各个组,形成含有不同个区的各个组,order by再对这个新形成的表进行运算(当要求select这个新表中没有的字段时,会报错)。
group by含有多个字段时,就是先对前面的字段分区分组,再在新形成的表里,对第二个字段分区分组。
5.例题
求三个国家的总人口

求各大洲人口超过一千万的国家的数量。
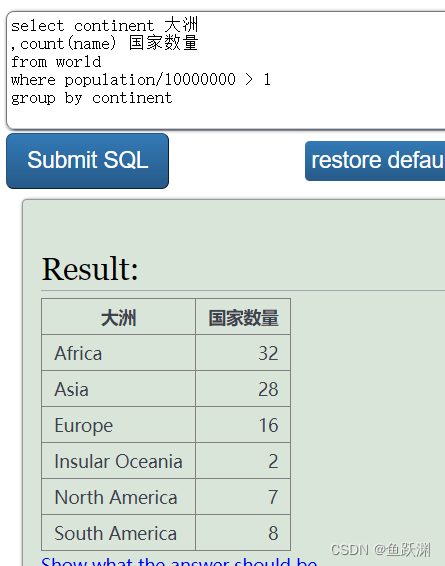
6.聚合后查询函数
having在groupby形成的新表中进行聚合查询
例题:给出人均gdp大于3000的大洲和人口,仅gdp在2百亿到3百亿之间的国家纳入计算。

三、部分常用函数
round(x,y)——对x四舍五入,y为保留小数点后y位;y<0则保留小数点左边相应位数为0,不四舍五入。
concat(s1,s2,..)——链接字符串,eg:concat('my',' ','sql')返回'my sql';当任意s为null值返回null。
replace(s,s1,s2)——用s2代替s中的所有s1。
left(s,n)、right(s,n)、substring(s,n,length)——left函数返回字符串s最左边n个字符;right返回字符串s最右边n个字符;substring返回字符串第n个字符起,取长度为length的子字符串,n为负数则是倒数第n个取长度为length的子字符串,没有length值则从第n个字符起取到最后一位。
year()、month()、day()——分别取其的年、月、日。
date_add(date,interval expr type)——date_add(日期,改变的时间间隔 被解释的方式 年月日时分秒)——eg:date_add('2012-08-03 23:59:59',interval 1 second)返回2012-08-04 24:00:00
date_sub()——比上述唯一的区别是上述为增加时间,sub为减少时间。
date_diff(date1,date2)——计算两个日期的间隔,前者减后者,只返回年月日,可返回负数。
date_format(date,format)——将日期和时间替换成想要的格式。(每种格式有对应表达式)。
if(expr,v1,v2)——输入条件,true返回v1,否则返回v2.
case when——case expr when v1 then r1 [when v2 then r2]..[else rn] end
eg:case 2 when 1 then '啊expr=v1' else ’不A不等于B‘ end由于2!=1则返回 不A不等于B
eg2:case when 1<0 then 'T' else 'F' 返回F——即expr为空值,只需要根据是否满足v1返回结果。
四、窗口函数
1.标准语法
over([partition by 字段名][order by 字段名 asc/desc])
over()中两个字句为可选项,partition为分区依据,order为排序依据。
2.排序窗口函数
rank()over()跳跃式排序:99,99,98,97返回1,1,3,4
dense_rank()over()并列连续型排序:99,99,98,97返回1,1,2,3
row_number()over()连续型排序:99,99,98,97返回1,2,3,4
3.偏移分析函数
lag(字段名,偏移量[,默认值])over();
lead(字段名,偏移量[,默认值])over()
4.例题
查询Italy每周新增确诊数(显示每周一的数值weekday(whn)=0)
显示国家名,标准日期(2021-07-21),每周新增人数
按照时间顺序排列

运行逻辑是:先运行where函数,提取每周一的数据,再运行窗口函数,将每周一的数据表进行处理,最后按日期whn排序。而不是:confirmed-lag(confirmed,7),注意逻辑的转换。
五、表连接
1.内连接
select 字段名
from 表名1 inner join 表名2 on 表名1.字段名 =表名2.字段名
inner可省略,直接使用join默认内连接。
2.左连接
from 表名1 left join 表名2 on 表名1.字段名 =表名2.字段名
左接入表有null值也可写入连接表,右表null值会被去除。
3.右连接
from 表名1 right join 表名2 on 表名1.字段名 =表名2.字段名
与左连接表接入逻辑相反。
六、子查询
子查询是可以独立运行的完整的查询语句,然后将查询结果作为主查询的一部分,故子查询优先于主查询进行。
例如:

from子查询后必须加别名"as 别名",否则会报错,as可省略。
七、云端数据库配置;Excel/Tableau连接数据库
参考b站阿婆🐖戴戴戴师兄。















 643
643











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









