






一、在IDEA中下载插件
在设置->插件中找到scala,并下载。
下载完成后重启idea
二、在idea中创建spark的RDD操作项目
新建项目选中Scala。
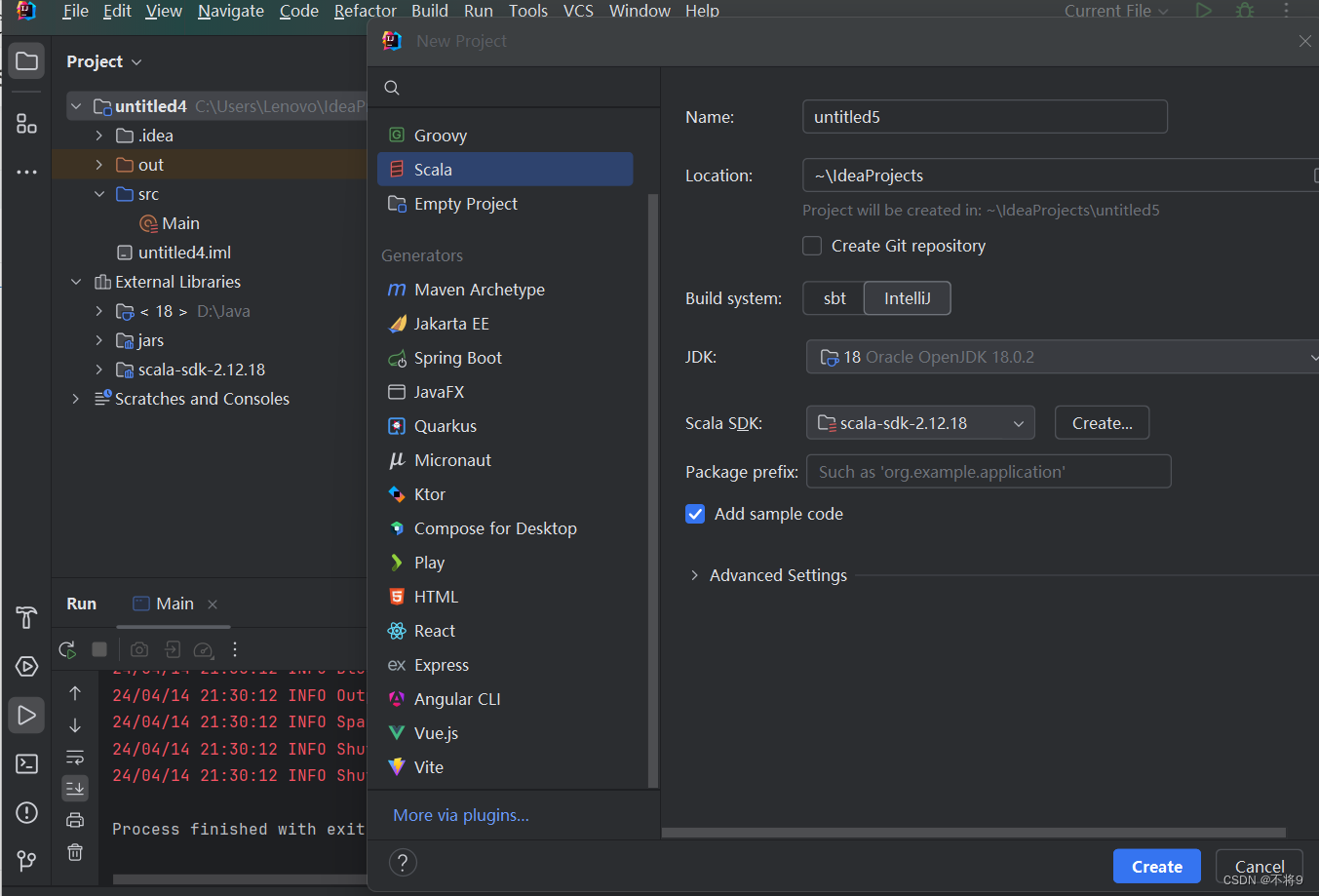
创建完成后为项目添加java包,这个添加的是spark安装包中jars目录下的所有jar包
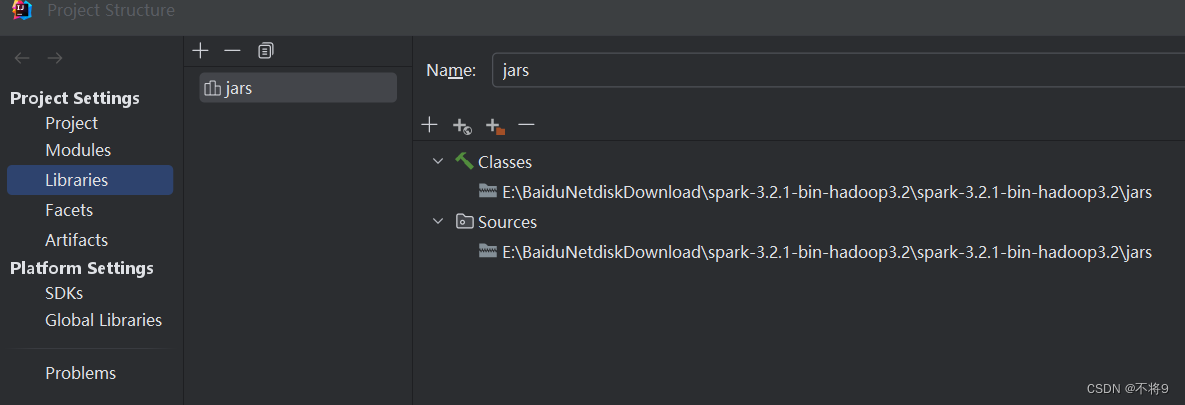
然后编写RDD操作
import org.apache.spark.{SparkConf, SparkContext}
object Main {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf()
sparkConf.setMaster("local") //本地单线程运行
sparkConf.setAppName("Main")
val sc = new SparkContext(sparkConf)
val line = sc.textFile("C:/Users/Lenovo/Downloads/Volleyball_Players.csv")
line.foreach(println)
}
}如果你引入不了spark,可能就是你的jar包没导入
此时执行程序发下报错java.io.FileNotFoundException: HADOOP_HOME and hadoop.home.dir are unset......
三、解决方法:
如果你的spark是在本机windows下可以参考
java.io.FileNotFoundException: HADOOP_HOME and hadoop.home.dir are unset. - 简书
如果你的spark是在虚拟机Linux下可以使用以下方法,
1.下载winutils文件
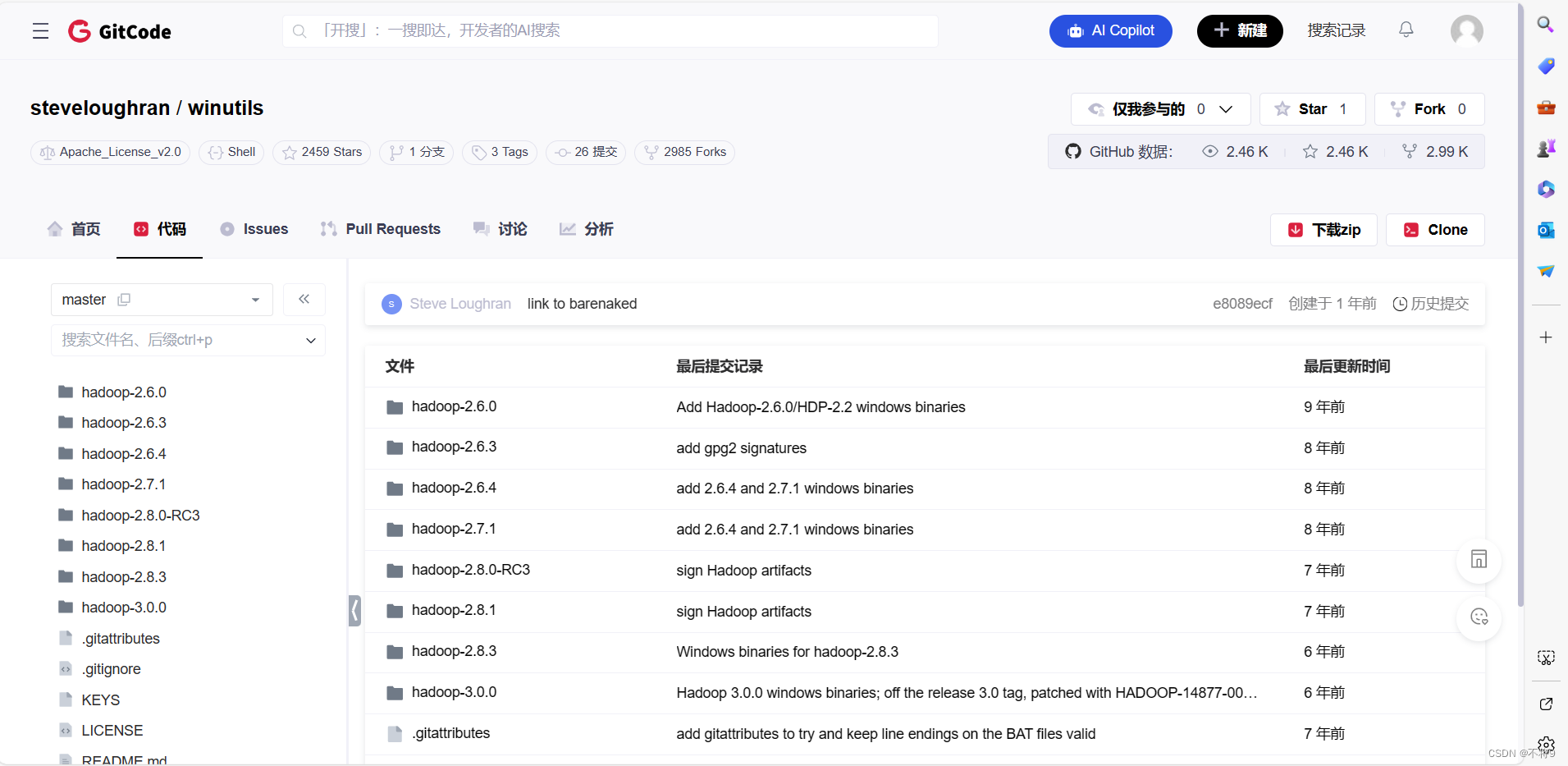
下载与自己虚拟中hadoop版本相近的,我的是3.2.4所以下载3.0版本
2. 配置环境变量
配置系统环境变量:
新增 变量名:HADOOP_HOME 变量值:就是你上面下载的hadoop版本文件夹的所在位置


在Path 中新增 变量值:%HADOOP_HOME%\bin

3.把hadoop.dll放到C:/windows/system32文件夹下
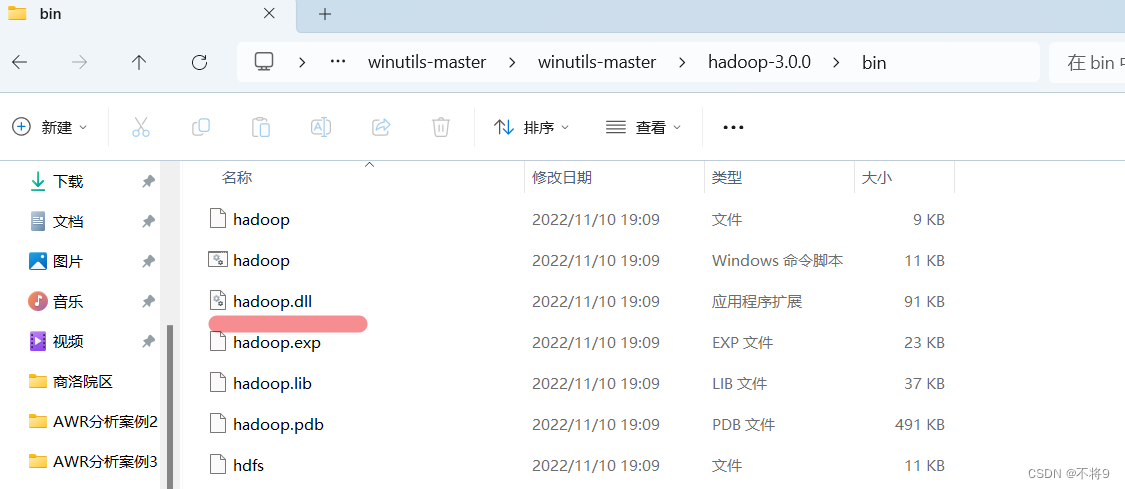

4.重启IDEA,再次运行代码
此时发现又报新错误
Exception in thread "main" java.lang.IllegalAccessError: class org.apache.spark.storage.StorageUtils$ (in unnamed module @0x3cd3e762) cannot access class sun.nio.ch.DirectBuffer (in module java.base) because module java.base does not export sun.nio...............................
解决方法:
5. 需要在环境变量中设置 JAVA_OPT 和 JAVA_TOOL_OPTIONS 为 --add-exports=java.base/sun.nio.ch=ALL-UNNAMED

重启idea,再次运行代码
此时代码成功运行
















 2873
2873











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









