






目录
目录
一、Anaconda+pytorch(GPU版)安装及注意事项
教程参考视频:PyTorch深度学习快速入门教程(绝对通俗易懂!)【小土堆】_哔哩哔哩_bilibili
Anaconda官网:Anaconda | The World’s Most Popular Data Science Platform
pytorch官网:PyTorch
一、Anaconda+pytorch(GPU版)安装及注意事项
此处仅为大致的流程,详细请参考下面参考资料内容(推荐多浏览几个资料完整流程后再开始上手安装,可以避免很多大坑)
Anaconda
Anaconda安装版本:Anaconda3-5.3.0-Windows-x86_64.exe
--- Anaconda版本与后续安装torch等版本无较大关系,选择稳定版本即可---
各版本下载网站:Index of /
新建环境
通过conda创建一个名为:pytorch的虚拟“房间”,可以方便未来对不同版本的PyTorch进行管理,具体方法如下:
conda create -n 随便起名字(要英文) python=3.8(指定此环境中之后用的python版本)


安装pytorch(GPU版)
版本匹配
查看显卡算力
https://en.wikipedia.org/wiki/CUDA

根据型号找到自己显卡的算力,这里我是RTX3060,算力8.6

查看本机显卡CUDA版本等信息,在cmd中输入
nvidia-smi
下载的cuda版本要≤目前的版本
安装显卡驱动
如何在windows上 安装&更新 显卡的驱动_更新cuda驱动_chuanauc的博客-CSDN博客
清华源大坑!!!!
很多资料都没有提到,使用清华源安装的pytorch默认是CPU版本,后续还得手动替换内部包文件很麻烦,新手不推荐清华源!!!
用官网推荐的pip指令下载!!!!我不挂梯子可以跑满速
用官网推荐的pip指令下载!!!!
用官网推荐的pip指令下载!!!!

其中cu113即torch内部的cudatoolkit是cuda11.3版本。所需的Python版本优先选择3.7-3.9,除非演示代码告知具体版本。
●参考: torch.cuda.is_available()返回false——解决办法_Nefu_lyh的博客-CSDN博客
pycharm中切换终端环境

pycharm中终端默认环境是PS,需要切换为我们的pytorch环境


此处DL1为我创建的anaconda环境。
参考教程:
PyTorch安装最全流程_pycharm导入torch包_李坦(BNU远程教育学)的博客-CSDN博客
PyTorch深度学习快速入门教程(绝对通俗易懂!)【小土堆】_哔哩哔哩_bilibili
Python深度学习:安装Anaconda与PyTorch库(GPU版本)_哔哩哔哩_bilibili
清华源下载有问题!!不是GPU!!!Linux下安装pytorch_pytorch清华镜像源下载不了_蛋汤里的小葱花的博客-CSDN博客
清华源conda安装PyTorch的GPU版本总是下载CPU版本安装包怎么办_清华源下载pytorch_大卢在奔跑的博客-CSDN博客
二、TensorBoard数据可视化(可跳过)
就是一个网页UI界面的作图工具,可以以可视化的形式更好的分析图片、函数等数据。
2.1 安装
直接使用pip安装即可:
pip install tensorboard
安装后,在命令行输入:
tensorboard --help
若可以正常输出,则说明安装成功。
2.2 TensorBoard 使用流程
pytorch代码部分
Pytorch使用Tensorboard主要用到了三个API:
SummaryWriter:这个用来创建一个log文件,TensorBoard面板查看时,也是需要选择查看那个log文件。
需要new一个SummaryWriter对象:
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter(log_dir='缓存路径文件夹名')运行完后设定路径下会生成一个event日志文件
add_XXX: 根据需要向log文件里面增添数据。例如可以通过add_scalar增添折线图数据,add_image可以增添图片。

close:养成好习惯,当训练结束后,我们可以通过writer.close()方法结束log写入
终端部分
运行启动命令即可:
需指定启动的event路径,默认端口是6006,若特殊情况此端口被某些软件占用不会正常显示,可加入参数--port XXX指定端口
tensorboard --logdir 项目文件夹名称(不加引号) (--port XXX)(可选端口)
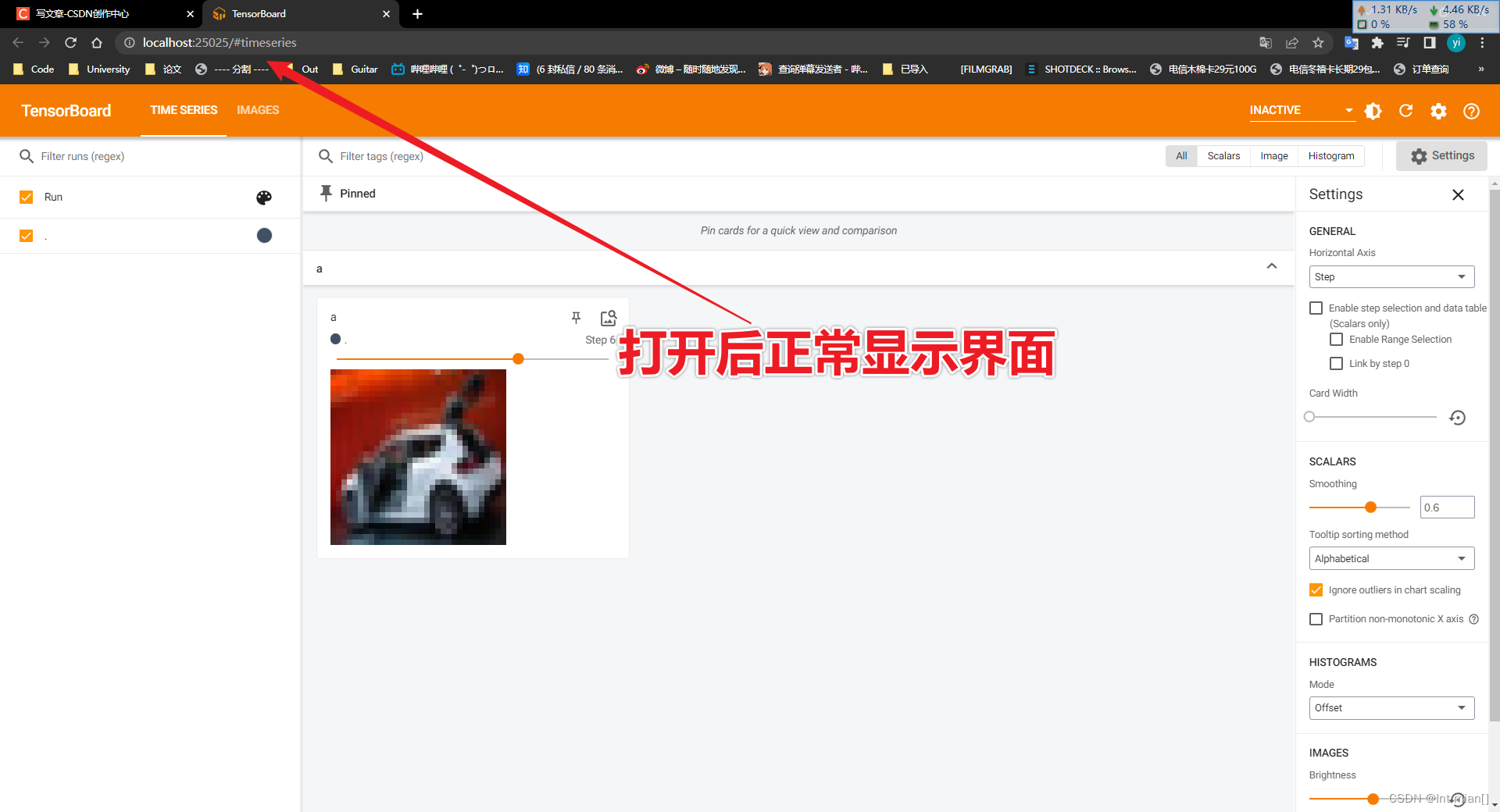
参考资料:TensorBoard快速入门(Pytorch使用TensorBoard)_iioSnail的博客-CSDN博客
2.3 官方帮助*
"""Writes entries directly to event files in the log_dir to be
consumed by TensorBoard.
The `SummaryWriter` class provides a high-level API to create an event file
in a given directory and add summaries and events to it. The class updates the
file contents asynchronously. This allows a training program to call methods
to add data to the file directly from the training loop, without slowing down
training.
将条目直接写入log_dir中的事件文件,供TensorBoard使用。“SummaryWriter”类提供了一个高级API,
用于在给定目录中创建事件文件,并向其中添加摘要和事件。该类异步更新文件内容。这允许训练程序调用
方法,将数据直接从训练循环添加到文件中,而不会减慢训练速度。
"""
def __init__(
self,
log_dir=None,
comment="",
purge_step=None,
max_queue=10,
flush_secs=120,
filename_suffix="",
):
"""Creates a `SummaryWriter` that will write out events and summaries
to the event file.
Args:
log_dir (string): Save directory location. Default is
runs/**CURRENT_DATETIME_HOSTNAME**, which changes after each run.
Use hierarchical folder structure to compare
between runs easily. e.g. pass in 'runs/exp1', 'runs/exp2', etc.
for each new experiment to compare across them.
comment (string): Comment log_dir suffix appended to the default
``log_dir``. If ``log_dir`` is assigned, this argument has no effect.
log_dir(字符串):保存目录位置。默认为runsCURRENT_DATETIME_HOSTNAME,每次运行后都会更改。使用
分层文件夹结构可以轻松地在运行之间进行比较。例如,为每个新实验输入“runsexp1”、“runsexp2”等,以便
在它们之间进行比较。comment(string):注释log_dir后缀附加到默认的`log_dir``。如果指定了
“log_dir”,则此参数无效。
purge_step (int):
When logging crashes at step :math:`T+X` and restarts at step :math:`T`,
any events whose global_step larger or equal to :math:`T` will be
purged and hidden from TensorBoard.
Note that crashed and resumed experiments should have the same ``log_dir``.
max_queue (int): Size of the queue for pending events and
summaries before one of the 'add' calls forces a flush to disk.
Default is ten items.
purge_step(int):当日志记录在步骤:math:`T+X'崩溃并在步骤:math:`T'重新启动时,global_step大
于或等于:math:`T'的任何事件都将被清除并从TensorBoard中隐藏。请注意,崩溃的实验和恢复的实验应该具
有相同的“log_dir”。max_queue(int):在其中一个“add”调用强制刷新磁盘之前,挂起事件和摘要的队列大
小。默认为十项。
flush_secs (int): How often, in seconds, to flush the
pending events and summaries to disk. Default is every two minutes.
filename_suffix (string): Suffix added to all event filenames in
the log_dir directory. More details on filename construction in
tensorboard.summary.writer.event_file_writer.EventFileWriter.
flush_secs(int):将挂起的事件和摘要刷新到磁盘的频率(以秒为单位)。默认值为每两分钟一次。
filename_suffix(字符串):添加到log_dir目录中所有事件文件名的后缀。
tensorboard.summary.writer.event_file_writer中文件名构造的更多详细信息。
Examples::
常用案例
from torch.utils.tensorboard import SummaryWriter
# create a summary writer with automatically generated folder name.
writer = SummaryWriter()
# folder location: runs/May04_22-14-54_s-MacBook-Pro.local/
# create a summary writer using the specified folder name.
writer = SummaryWriter("my_experiment")
# folder location: my_experiment
# create a summary writer with comment appended.
writer = SummaryWriter(comment="LR_0.1_BATCH_16")
# folder location: runs/May04_22-14-54_s-MacBook-Pro.localLR_0.1_BATCH_16/
"""三、Transforms使用
from torchvision import transforms3.1 结构及作用
transform. vt.使改变; 使改观; 使转换
transforms.py就像一个工具箱,里面定义的各种类就像各种工具,图片就是输入对象,经过工具处理,输出期望的图片结果。

3.2 常用类
官方教学:torchvision.transforms — Torchvision master documentation
Compose

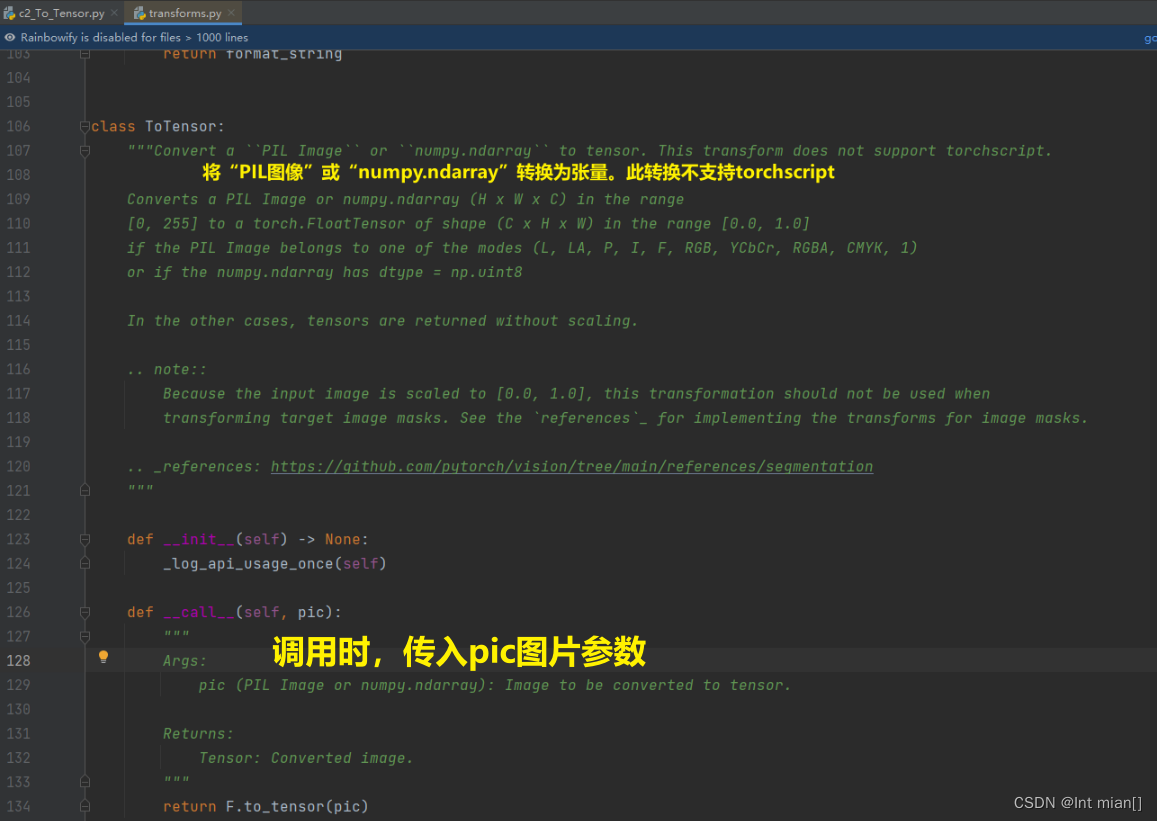
ToTensor
使用流程
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms as tf
# 打开图片
img_path = './dataset/train/ants/0013035.jpg' # 打开图片
img = Image.open(img_path)
# print(img.size)
# new可视化工具
wr = SummaryWriter('logs')
# 新建ToTensor,传入图片对象,转化为Tensor类型
to_tensor = tf.ToTensor()
tensor_img = to_tensor(img)
wr.add_image('ant2', tensor_img, global_step=2)
wr.close()3.3 为什么需要Tensor类型?
PyTorch中的Tensor是深度学习中广泛使用的数据结构,本质上就是一个高维的矩阵,甚至将其理解为NumPy中array的推广和升级也不为过。但由于其支持的一些特殊特性(详见后文第3小节),Tensor在用于支撑深度学习模型和训练时更为便利。
一般而言,描述Tensor的高维特性通常用三维及以上的矩阵来描述,例如下图所示:单个元素叫标量(scalar),一个序列叫向量(vector),多个序列组成的平面叫矩阵(matrix),多个平面组成的立方体叫张量(tensor)。当然,就像矩阵有一维矩阵和二维矩阵乃至多维矩阵一样,张量也无需严格限制在三维以上才叫张量,在深度学习的范畴内,标量、向量和矩阵都统称为张量。
参考资料:
PyTorch 学习笔记:transforms的二十二个方法(transforms用法非常详细)_transforms.scale_liangbaqiang的博客-CSDN博客
四、数据集使用 Dataset、DataLoader
4.1 官方数据集
0.9版本torchvision数据集:torchvision — Torchvision master documentation

4.2 使用方法(以CIFAR为例)
CIFAR-10数据集(介绍、下载读取、可视化显示、另存为图片)_cifar10数据集_qq_40755283的博客-CSDN博客
官方文档
以CIFAR为例:torchvision.datasets — Torchvision master documentation
CLASS
torchvision.datasets.CIFAR10(root: str, train: bool = True, transform: Union[Callable, NoneType] = None, target_transform: Union[Callable, NoneType] = None, download: bool = False) → None
- root ( string ) –如果download设置为 True,cifar-10-batches-py目录存在或将保存到的数据集的根目录 。
- train ( bool , optional ) – 如果为真,则从训练集中创建训练数据集,否则从中创建测试集。
- transform ( callable , optional ) – 接受 PIL 图像并返回转换后版本的函数/转换。例如,
transforms.RandomCrop- target_transform ( callable , optional ) – 接受目标并对其进行转换的函数/转换。
- download ( bool , optional ) – 如果为真,则从互联网下载数据集并将其放在根目录中。如果数据集已经下载,则不会再次下载。
使用代码
train_set = tv.datasets.CIFAR10(root='./dataset/CIFAR/train',transform=dataset_transform, train=True, download=True)
test_set = tv.datasets.CIFAR10(root='./dataset/CIFAR/test',transform=dataset_transform, train=False, download=True)
完整使用示例
import torchvision
from torch.utils.tensorboard import SummaryWriter
# 获取数据集,进行一个ToTensor变换
train_set = torchvision.datasets.CIFAR10(root='./dataset/CIFAR/train',transform=torchvision.transforms.ToTensor(), train=True, download=True)
test_set = torchvision.datasets.CIFAR10(root='./dataset/CIFAR/test',transform=torchvision.transforms.ToTensor(), train=False, download=True)
# 前10个投射到可视化面板中
wr = SummaryWriter('logs')
for i in range(10):
# 每个test_set[i]中包含一张图片和一个标签
img, target = test_set[i]
wr.add_image('img', img, i)
wr.close()
4.3 dataloader参数
数据集( Dataset ) – 从中加载数据的数据集。
batch_size ( int , optional ) – 每批要加载多少个样本(默认值:)1。
shuffle ( bool , optional ) – 设置True为在每个时期重新洗牌数据(默认值:)False。
采样器(Sampler或Iterable ,可选)——定义从数据集中抽取样本的策略。可以是任何Iterable已__len__ 实施的。如果指定,shuffle则不得指定。
batch_sampler ( Sampler or Iterable , optional ) – 类似sampler,但一次返回一批索引。batch_size与、shuffle、sampler和互斥 drop_last。
num_workers ( int , optional ) – 用于数据加载的子进程数。0意味着数据将在主进程中加载。(默认值0:)
collate_fn ( Callable , optional ) – 合并样本列表以形成一个小批量的张量。在使用地图样式数据集的批量加载时使用。
pin_memory ( bool , optional ) – 如果True,数据加载器将在返回张量之前将其复制到设备/CUDA 固定内存中。如果您的数据元素是自定义类型,或者您collate_fn返回的批次是自定义类型,请参见下面的示例。
drop_last ( bool , optionalTrue ) –如果数据集大小不能被批次大小整除,则设置为删除最后一个不完整的批次。如果False数据集的大小不能被批量大小整除,那么最后一批会更小。(默认值False:)
timeout ( numeric , optional ) – 如果为正,则为从 worker 收集批次的超时值。应始终为非负数。(默认值0:)
worker_init_fn ( Callable , optional ) – 如果不是None,这将在每个 worker 子进程上被调用,并将 worker id(一个 int in )作为输入,在播种之后和数据加载之前。(默认值:)[0, num_workers - 1]None
generator ( torch.Generator , optional ) – 如果不是None,这个 RNG 将被 RandomSampler 用来生成随机索引和 multiprocessing 来 为 worker生成base_seed 。(默认值None:)
prefetch_factor ( int , optional , keyword-only arg ) – 每个工作人员提前加载的批次数。2意味着将有总共 2 * num_workers 个批次预取给所有的工人。(默认值取决于 num_workers 的设置值。如果 num_workers=0 的值默认为None。否则如果 num_workers>0 的值默认为2)。
persistent_workers ( bool , optional ) – 如果True,数据加载器将不会在数据集被使用一次后关闭工作进程。这允许使工作人员数据集实例保持活动状态。(默认值False:)
pin_memory_device ( str , optional ) – 如果 pin_memory 设置为 true,数据加载器将在返回它们之前将张量复制到设备固定内存中。参考资料:
PyTorch学习笔记(4)--DataLoader的使用_我这一次的博客-CSDN博客
系统学习Pytorch笔记三:Pytorch数据读取机制(DataLoader)与图像预处理模块(transforms)_pytorch dataloader读取数据_翻滚的小@强的博客-CSDN博客
五、神经网络
网络相关api:torch.nn — PyTorch 2.0 documentation

神经网络基本模板
CLASS torch.nn.Module(*args, **kwargs)
所有神经网络模块的基类。
你的模型也应该继承这个类。
模块可以包含其他模块,允许将它们嵌套在树结构中。可以将子模块分配为常规属性:
forward(*input)
定义每次调用时执行的计算。
应该被所有子类重写。
import torch.nn as nn
import torch.nn.functional as F
class Model(nn.Module):
def __init__(self): # 对父类进行初始化
super().__init__()
# 操作
self.conv1 = nn.Conv2d(1, 20, 5)
self.conv2 = nn.Conv2d(20, 20, 5)
# 网络向前传播
def forward(self, x):
x = F.relu(self.conv1(x))
return F.relu(self.conv2(x))
小案例
import torch
from torch import nn
class MyNet(nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
output = x + 1
return output
yuan = MyNet()
x = torch.tensor(1.0)
a = yuan(x)
print(a) # 输出tensor(2.)卷积 Conv2d(二维卷积)
参考资料:
Pytorch中dilation(Conv2d)参数详解_conv2d参数解释_MaZhe丶的博客-CSDN博客
CLASS
torch.nn.Conv2d(in_channels, out_channels, kernel_size,stride=1, padding=0, dilation=1, groups=1,
bias=True, padding_mode='zeros')
该模块支持TensorFloat32。
卷积参数可视化:conv_arithmetic/README.md at master · vdumoulin/conv_arithmetic · GitHub
in_channels ( int ) – 输入图像中的通道数
out_channels ( int ) – 卷积产生的通道数
padding_mode ( string , optional ) –
'zeros','reflect','replicate'或'circular'. 默认:'zeros'groups ( int , optional ) – 从输入通道到输出通道的阻塞连接数。默认值:1
bias ( bool , optional ) – 如果
True, 向输出添加可学习的偏差。默认:True参数
kernel_size,stride,padding,dilation可以是:
一个
int——在这种情况下,相同的值用于高度和宽度尺寸a
tupleof two ints – 在这种情况下,第一个int用于高度维度,第二个int用于宽度维度


案例一


案例二
"""
in_channels (int) – Number of channels in the input image
out_channels (int) – Number of channels produced by the convolution
kernel_size (int or tuple) – Size of the convolving kernel
stride (int or tuple, optional) – 步长. Default: 1
padding (int, tuple or str, optional) – 边界延伸. Default: 0
padding_mode (str, optional) – 填充模式'zeros', 'reflect', 'replicate' or 'circular'. Default: 'zeros'
dilation (int or tuple, optional) – 卷积核之间的距离,空洞卷积,一般不常用. Default: 1
groups (int, optional) – Number of blocked connections from input channels to output channels. Default: 1
bias (bool, optional) – If True, 增加一个可以学习的偏置 to the output. Default: True
"""
import torch
import torchvision as tv
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = tv.datasets.CIFAR10(root='./dataset/CIFAR/test',transform=tv.transforms.ToTensor(), train=True
, download=True)
dataloader = DataLoader(dataset, batch_size=32)
class Yuange(nn.Module):
def __init__(self):
super(Yuange, self).__init__()
self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, padding=0, stride=1)
def forward(self, x):
x = self.conv1(x)
return x
yuan = Yuange()
print(yuan)
wr = SummaryWriter('nn')
step = 0
for data in dataloader:
img, target = data
out = yuan(img)
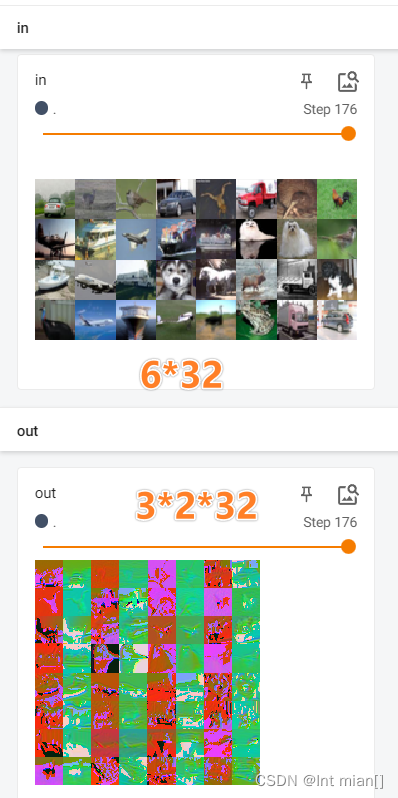
print(img.shape) # torch.Size([32, 3, 32, 32]) 上面的块设置成32
print(out.shape) # torch.Size([32, 6, 30, 30]) 卷积后30*30
wr.add_images('in', img, step)
out = torch.reshape(out, (-1,3,30,30)) # 默认块-1,改成3通道,块自己算,看上图
wr.add_images('out', out, step)
step += 1
wr.close()最大池化 MaxPool(二维)
MaxPool2d — PyTorch 1.8.1 documentation
对由多个输入平面组成的输入信号应用 2D 最大池化。
CLASS
torch.nn.MaxPool2d(kernel_size, stride=None,padding=0, dilation=1, return_indices=False, ceil_mode=False)
参数可视化:https://github.com/vdumoulin/conv_arithmetic/blob/master/README.md
kernel_size – 取最大值的窗口大小
stride——窗口的步幅。默认值为
kernel_sizepadding——在两侧添加隐式零填充
dilation——控制窗口中元素步幅的参数
return_indices – 如果
True,将返回最大索引和输出。torch.nn.MaxUnpool2d以后有用ceil_mode – 当为 True 时,边上没有padding,将使用ceil取大而不是floor舍弃来计算输出形状
案例一

案例二(图片)
"""
kernel_size ( Union [ int , Tuple [ int , int ] ] ) – 取最大值的窗口大小
stride ( Union [ int , Tuple [ int , int ] ] ) – 窗口的步幅。默认值为kernel_size
padding ( Union [ int , Tuple [ int , int ] ] ) – 要在两侧添加的隐式负无穷大填充
dilation ( Union [ int , Tuple [ int , int ] ] ) – 控制窗口中元素步幅的参数
return_indices ( bool ) – 如果True,将返回最大索引和输出。torch.nn.MaxUnpool2d以后有用
ceil_mode ( bool ) – 当为真时,卷积核到边上,有空值将使用ceil保留而不是floor舍弃来计算输出形状
"""
import torch
from torch import nn
from torch.nn import MaxPool2d
import torchvision as tv
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = tv.datasets.CIFAR10(root='./dataset/CIFAR/test',transform=tv.transforms.ToTensor(), train=True
, download=True)
dataloader = DataLoader(dataset, batch_size=64)
input = torch.tensor([[1,2,0,3,1],
[0,1,2,3,1],
[1,2,1,0,0],
[5,2,3,1,1],
[2,1,0,1,1]], dtype=torch.float32)
# print(input.shape) # torch.Size([5, 5])
# input = torch.reshape(input, (-1,1,5,5))
# print(input.shape) # torch.Size([1, 1, 5, 5])
class Yuange(nn.Module):
def __init__(self):
super(Yuange, self).__init__()
self.pool = MaxPool2d(kernel_size=3, ceil_mode=True)
def forward(self, input):
out = self.pool(input)
return out
yuan = Yuange()
wr = SummaryWriter('./tb_cache/pool')
step = 0
for data in dataloader:
imgs, target = data
print(imgs.shape)
print(target)
wr.add_images('in', imgs, step)
out = yuan(imgs)
wr.add_images('out', out, step)
step += 1
wr.close()

非线性激活(Non-linear Activations)
为什么需要激活函数?为什么激活函数非线性?
ReLU
CLASS
torch.nn.ReLU(inplace=False)ReLU(x) = max(0,x)
输入:( ñ ,*) 其中*表示任意数量的附加维度
输出:(否,*)( ñ ,*) , 与输入相同的形状

>>> m = nn.ReLU()
>>> input = torch.randn(2)
>>> output = m(input)其他非线性激活
torch.nn — PyTorch 1.8.1 documentation
线性层 Linear Layers
一般将卷积神经网络看成两部分:
- 特征提取层,有一系列的 Conv、ReLU、Pool 等网络层串联或并联,最终得到特征图
- 任务相关层,比如用全连接层对得到的特征图做回归任务,拟合分布等
在图像分类中,经常使用全连接层输出每个类别的概率,但全连接层也有说法是线性变换层 + 激活函数 + 线性变换层 + ...... ,多层感知机


Sequential使用

不使用Sequential
class Yuange(nn.Module):
def __init__(self):
super(Yuange, self).__init__()
self.conv1 = Conv2d(3, 32, 5, padding=2) # 入通道,出通道,卷积核,padding
self.maxpool1 = MaxPool2d(2)
self.conv2 = Conv2d(32, 32, 5, padding=2)
self.maxpool2 = MaxPool2d(2)
self.conv3 = Conv2d(32, 64, 5, padding=2)
self.maxpool3 = MaxPool2d(2)
self.flatten = Flatten()
self.linear1 = Linear(1024, 64)
self.linear2 = Linear(64, 10)
def forward(self, x):
x = self.conv1(x)
x = self.maxpool1(x)
x = self.conv2(x)
x = self.maxpool2(x)
x = self.conv3(x)
x = self.maxpool3(x)
x = self.flatten(x)
x = self.linear1(x)
x = self.linear2(x)
return x使用Sequential
class Yuange(nn.Module):
def __init__(self):
super(Yuange, self).__init__()
# 使用Sequential
self.seq = nn.Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
# !!!!!!!
x = self.seq(x)
return x计算Padding

损失函数与反向传播
损失函数是什么?
损失函数(loss function)就是用来度量模型的预测值f(x)与真实值Y的差异程度的运算函数,它是一个非负实值函数,通常使用L(Y, f(x))来表示,损失函数越小,模型的鲁棒性就越好。
损失函数使用主要是在模型的训练阶段,每个批次的训练数据送入模型后,通过前向传播输出预测值,然后损失函数会计算出预测值和真实值之间的差异值,也就是损失值。得到损失值之后,模型通过反向传播去更新各个参数,来降低真实值与预测值之间的损失,使得模型生成的预测值往真实值方向靠拢,从而达到学习的目的。
常用损失函数官网文档:torch.nn — PyTorch 1.8.1 documentation
优化器
torch.optim — PyTorch 1.8.1 documentation
优化器就是在深度学习反向传播过程中,指引损失函数(目标函数)的各个参数往正确的方向更新合适的大小,使得更新后的各个参数让损失函数(目标函数)值不断逼近全局最小。
没有优化器,则参数不变,每一轮loss不变,白训练!
Example:
for input, target in dataset:
optimizer.zero_grad() # 优化器参数清零
output = model(input) # 经过模型
loss = loss_fn(output, target) # 求此轮训练的loss
loss.backward() # 反向传播
optimizer.step() # 优化器循环 优化器使用案例(SGD为例)
CLASS
torch.optim.SGD(params, lr=<required parameter>, momentum=0, dampening=0, weight_decay=0, nesterov=False)实现随机梯度下降(可选动量)。
import torch
import torchvision
from torch import nn
from torch.nn import Linear, Conv2d, MaxPool2d, Flatten
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10(root="./dataset/CIFAR/test", download=False,
transform=torchvision.transforms.ToTensor()
, train=False)
dataloder = DataLoader(dataset, batch_size=64, drop_last=True)
class Yuange(nn.Module):
def __init__(self):
super(Yuange, self).__init__()
self.seq = nn.Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.seq(x)
return x
yuan = Yuange()
loss = nn.CrossEntropyLoss()
optim = torch.optim.SGD(yuan.parameters(), lr=0.01 )
step = 0
wr = SummaryWriter("./tb_cache/line")
# 20轮训练
for epch in range(20):
loss_start = 0.0 # 每一轮开始loss为0
for data in dataloder:
imgs, target = data
output = yuan(imgs)
lo = loss(output, target) # 损失
optim.zero_grad() # 梯度设置0
lo.backward() # 反向传播
optim.step() # 优化进行
loss_start = lo + loss_start
print(loss_start)
wr.close()
# tensor(358.9487, grad_fn=<AddBackward0>)
# tensor(356.8564, grad_fn=<AddBackward0>)
# tensor(350.8759, grad_fn=<AddBackward0>)
# tensor(328.3651, grad_fn=<AddBackward0>)
# tensor(314.7161, grad_fn=<AddBackward0>)
现有模型使用、保存、读取
官网提供一些torchvision模型:torchvision.models — Torchvision master documentation
vgg16
文档:vgg16 — Torchvision 0.15 documentation
torchvision.models.vgg16(*, weights: Optional[VGG16_Weights] = None, progress: bool = True, **kwargs: Any) → VGG
weights ( VGG16_Weights, optional) – 要使用的预训练权重。VGG16_Weights有关详细信息和可能的值,请参见 下文。默认情况下,不使用预训练的权重。
progress ( bool , optional ) – 如果为真,则显示下载的进度条。默认为真。
**kwargs——传递给
torchvision.models.vgg.VGG基类的参数。 有关此类的更多详细信息,请参阅源代码。上面的模型构建器接受以下值作为
weights参数。VGG16_Weights.DEFAULT相当于VGG16_Weights.IMAGENET1K_V1. 您还可以使用字符串,例如weights='DEFAULT'orweights='IMAGENET1K_V1'。
模型下载
vgg16_false = torchvision.models.vgg16(weights=None)
vgg16_true = torchvision.models.vgg16(weights=VGG16_Weights.DEFAULT)修改现有模型
# 加一个线性层
vgg16_true.classifier.add_module("add_line", nn.Linear(1000, 10))
# 修改现有模型
vgg16_false.classifier[6] = nn.Linear(4096, 10)保存、加载
# 下载现有的模型
vgg16_false = torchvision.models.vgg16(weights=None)
# vgg16_true = torchvision.models.vgg16(weights=VGG16_Weights.DEFAULT)
# 1 大
torch.save(vgg16_false, "vgg16false.pth")
vgg = torch.load("./vgg16false.pth")
print(vgg)
# 2 字典,小,小不了多少。。
torch.save(vgg16_false.state_dict(), "./vggdic.pth")
vgg16 = torchvision.models.vgg16(weights=None)
vgg16.load_state_dict(torch.load("./vggdic.pth"))模型训练套路(CIFAR图像分类数据集)
# 准备数据集
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear
from torch.utils.data import DataLoader
import torchvision
train_dataset = torchvision.datasets.CIFAR10(root="../dataset/CIFAR/train", train=True,
transform=torchvision.transforms.ToTensor(),
download=True)
test_dataset = torchvision.datasets.CIFAR10(root="../dataset/CIFAR/test", train=False,
transform=torchvision.transforms.ToTensor(),
download=True)
# print(len(train_dataset))
# print(len(test_dataset))
train_dataset_dataloader = DataLoader(train_dataset, batch_size=64)
test_dataset_dataloader = DataLoader(test_dataset , batch_size=64)
# 搭建神经网络 nn
from model import *
yuange = Yuange()
# 准备loss函数
loss_fn = nn.CrossEntropyLoss()
# 创建优化器optim
optimizer = torch.optim.SGD(yuange.parameters(), lr=0.01)
# record
train_step = 0
test_step = 0
# 训练
for i in range(10):
print(f'第 {i+1} 轮训练ing。。。')
for data in train_dataset_dataloader:
imgs, target = data
outputs = yuange(imgs)
loss = loss_fn(outputs, target) # loss
optimizer.zero_grad() # 优化器初始化
loss.backward() # 反向传播
optimizer.step() # 优化
train_step += 1
print(f'第 {train_step} 轮训练 -- loss = {loss.item()}')
# 无梯度测试(节约资源)
# 在使用pytorch时,并不是所有的操作都需要进行计算图的生成(计算过程的构建,以便梯度反向传播等操作)。
total_loss = 0
total_accuracy = 0
with torch.no_grad():
for data in test_dataset_dataloader:
imgs, target = data
outputs = yuange(imgs)
loss = loss_fn(outputs, target)
total_loss += loss.item()
# argmax(1)横向看最大值的位置
total_accuracy += (outputs.argmax(1) == target).sum()
print('total_loss: '+str(total_loss))
print('total_accuracy: '+str(total_accuracy/len(test_dataset)))
验证
import torchvision.transforms
from PIL import Image
from torch.utils.data import DataLoader
test_dataset = torchvision.datasets.CIFAR10(root="../dataset/CIFAR/test", train=False,
transform=torchvision.transforms.ToTensor(),
download=True)
# 随便找了个飞机图片
img_path = './img_1.png'
img = Image.open(img_path)
# 处理图片格式
image = img.convert('RGB')
trans = torchvision.transforms.Compose([torchvision.transforms.Resize((32,32)),
torchvision.transforms.ToTensor()])
image = trans(image)
print(image.shape)
# 加载模型
from model import *
model = torch.load('./train3060_49.pth')
image = torch.reshape(image, (1, 3, 32, 32))
image = image.cuda()
# 过模型
output = model(image)
print(output)
# tensor([[ 5.7348, 0.7806, 1.1206, -0.7647, 0.1586, -1.0726, -3.0348, -1.7060,
# 4.8508, 0.1198]], device='cuda:0', grad_fn=<AddmmBackward0>)
# 找最大识别概率
index = output.argmax(1).item() # 0
# for k, v in test_dataset.class_to_idx.items():
# print(str(k)+' : '+str(v), end=' ')
print(index)
[print('图片是'+k) for k, v in test_dataset.class_to_idx.items() if v == index]使用GPU训练
上述模型训练套路中的神经网络,损失函数,数据集内容后增加内容:
XXX.cuda()
# nn
yuange = Yuange()
yuange = yuange.cuda()
# loss
loss_fn = nn.CrossEntropyLoss()
loss_fn = loss_fn.cuda()
for:
imgs, target = data
imgs = imgs.cuda()
target = target.cuda()或
myGPU = torch.device("cuda")上述模型训练套路中的神经网络,损失函数,数据集内容后增加内容:
XXX.to( myGPU )
# 设置device
device = torch.device("cuda")
# 搭建网络
yuange = Yuange()
yuange = yuange.to(device)
# loss
loss_fn = nn.CrossEntropyLoss()
loss_fn = loss_fn.to(device)
for:
imgs, target = data
imgs = imgs.to(device)
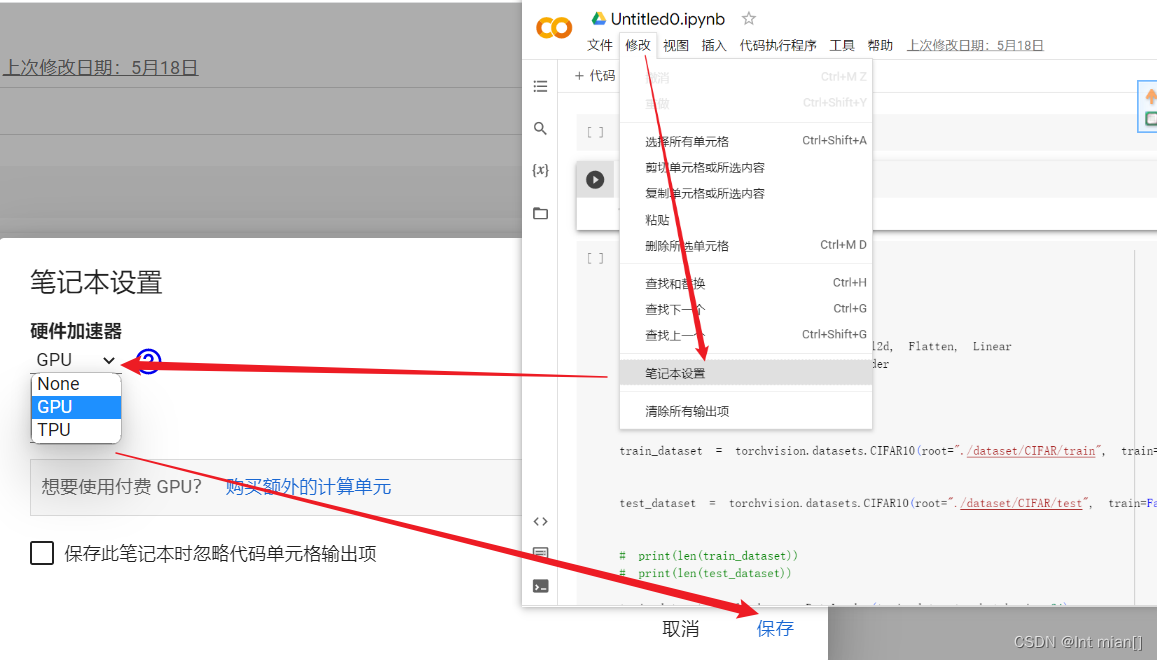
target = target.to(device)白嫖谷歌提供的显卡
谷歌colaboratory实验室:https://colab.research.google.com/
登录谷歌账号即可免费试用!















 350
350











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









